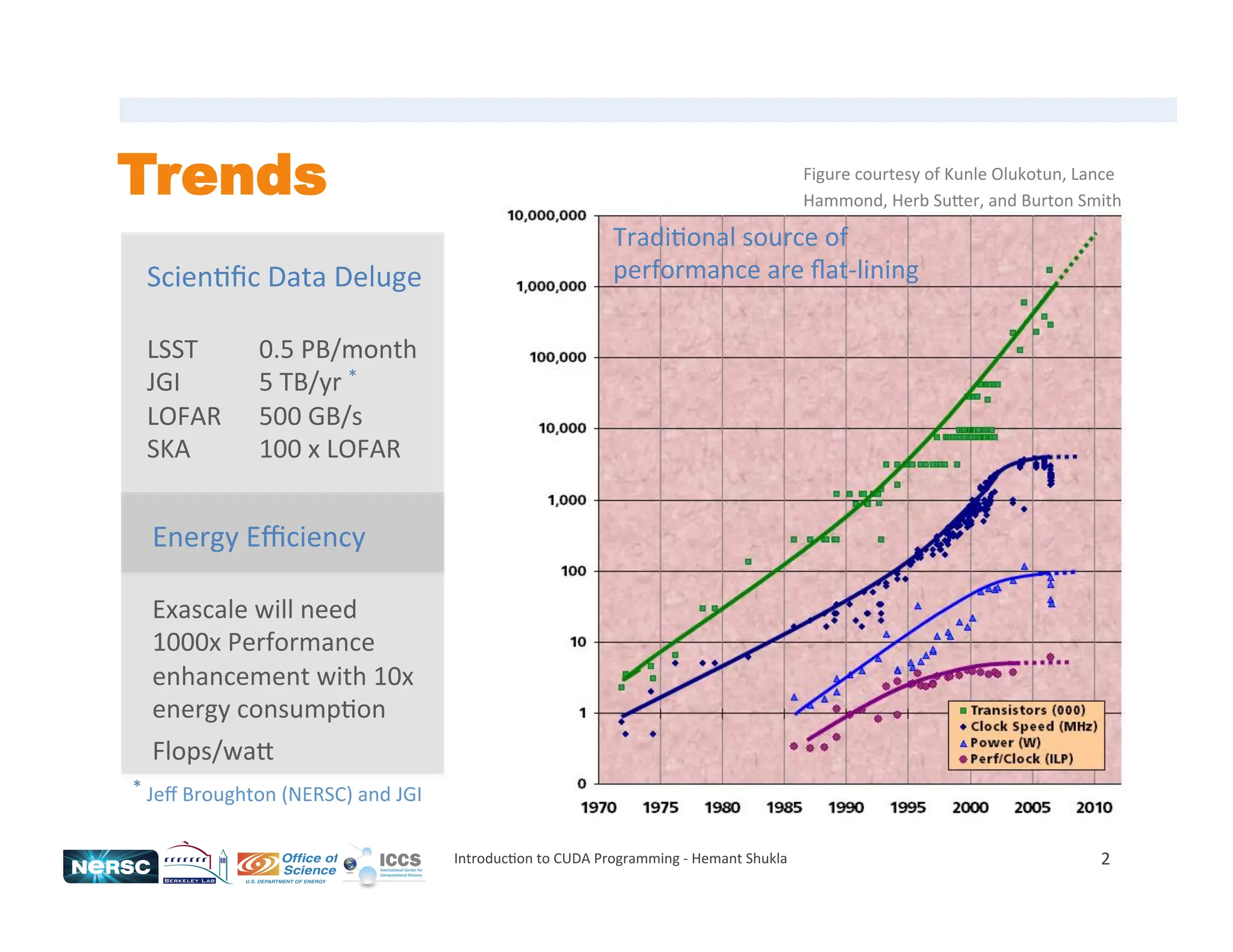
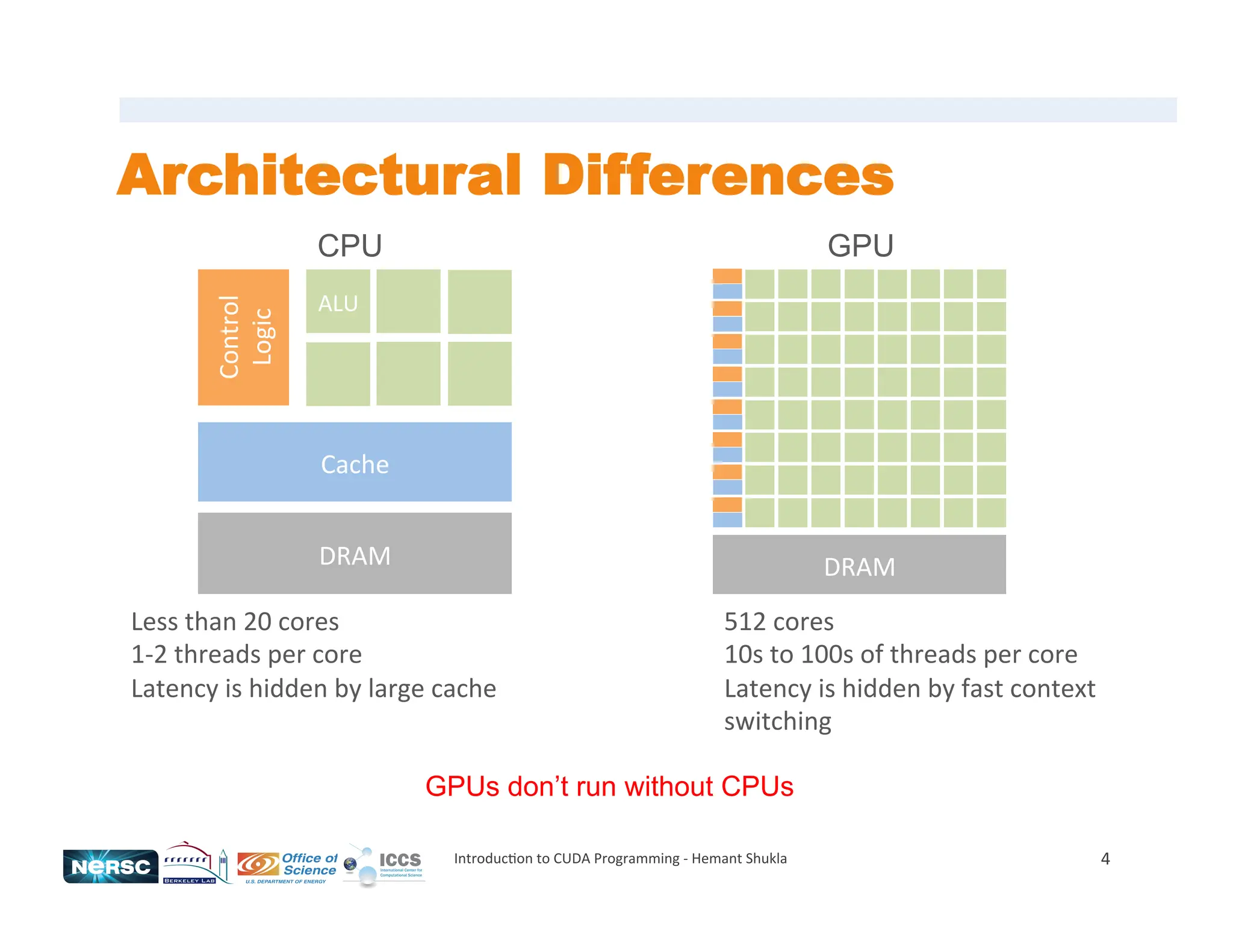
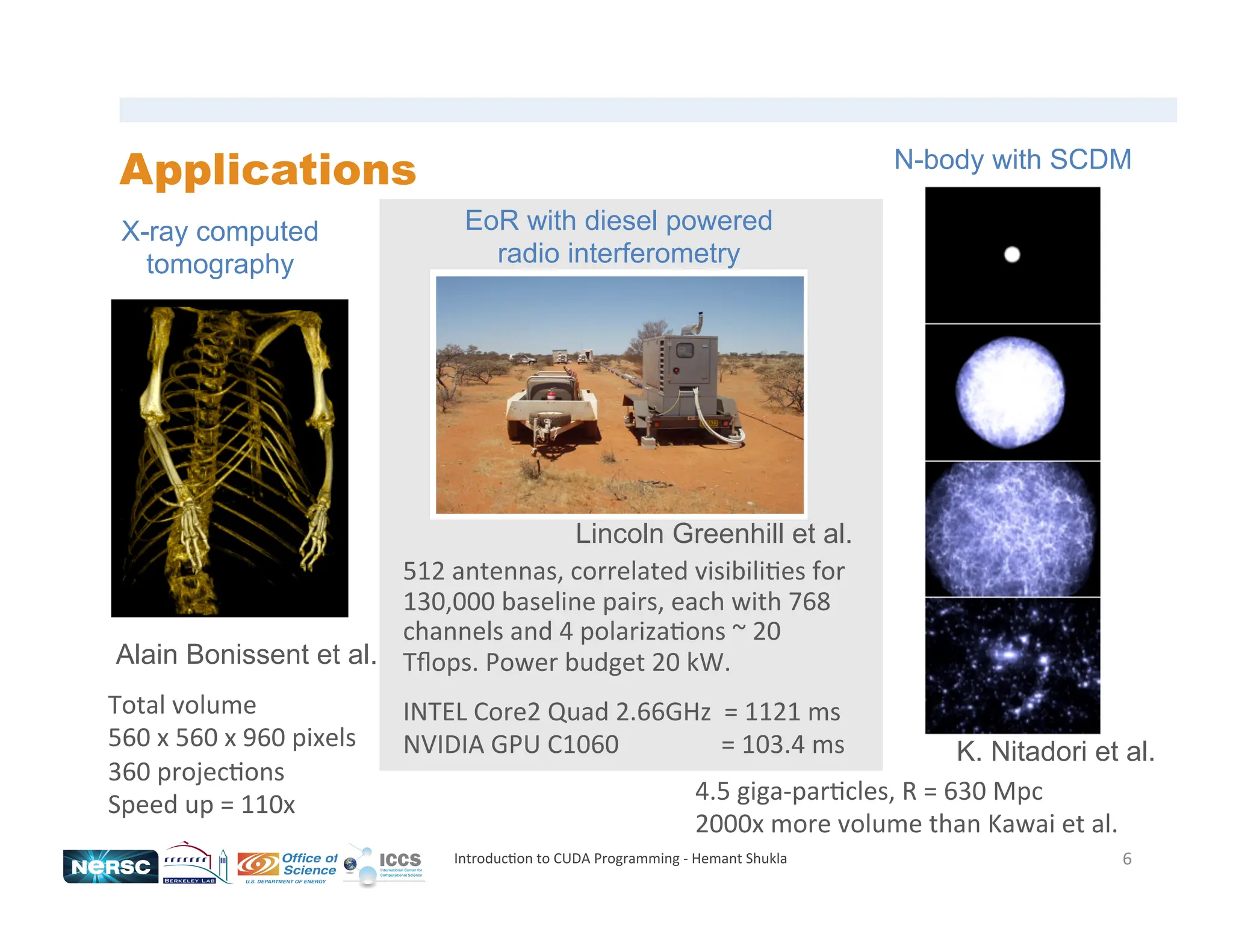
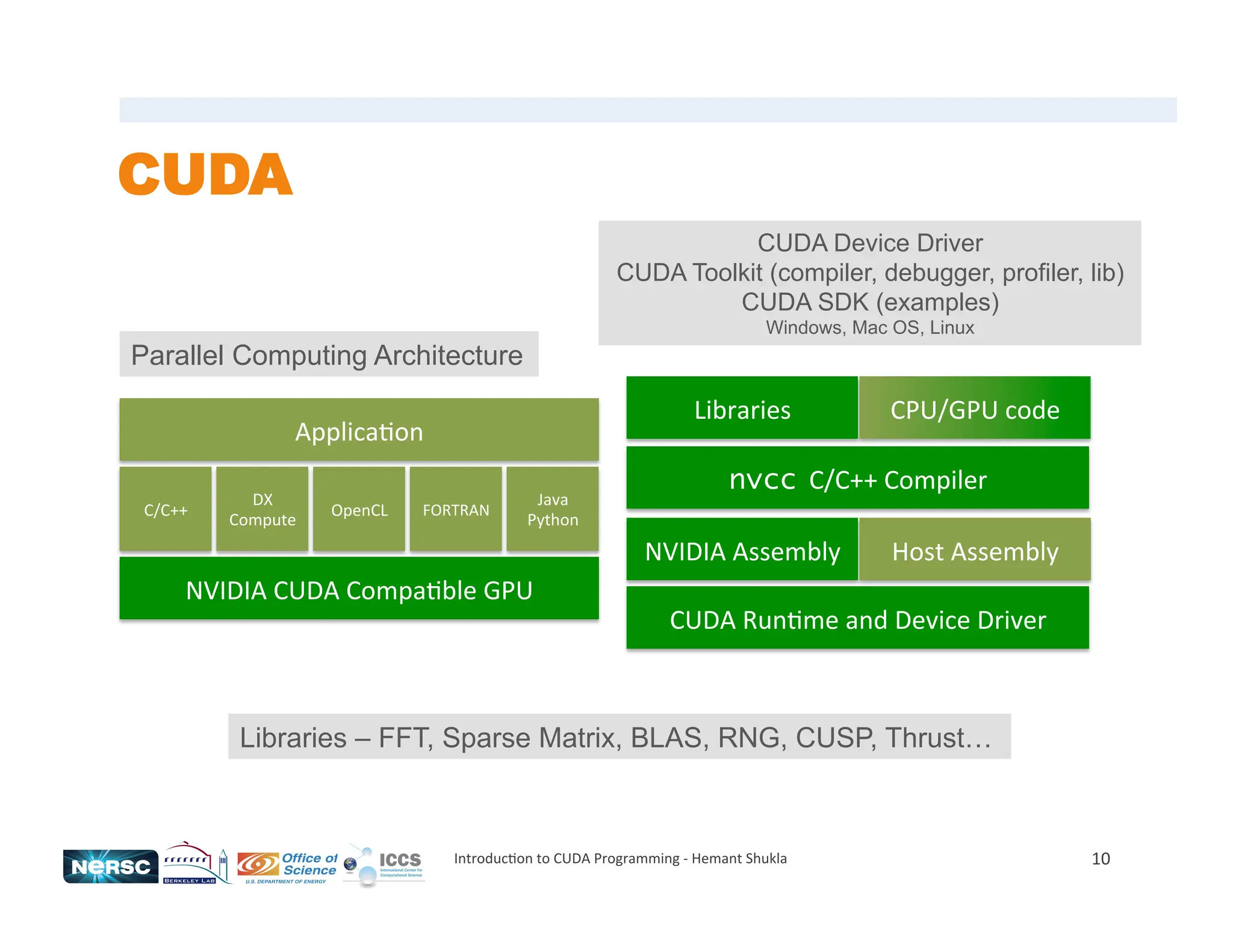
The document provides an introduction to CUDA programming, detailing the architecture, programming models, and performance considerations for utilizing GPUs in high-performance computing. It emphasizes the necessity for parallel programming and highlights the advantages of using CUDA for computational tasks like matrix multiplication and inner product calculations. Additionally, it discusses memory management, kernel execution, and efficient coding practices to optimize performance in massively parallel systems.






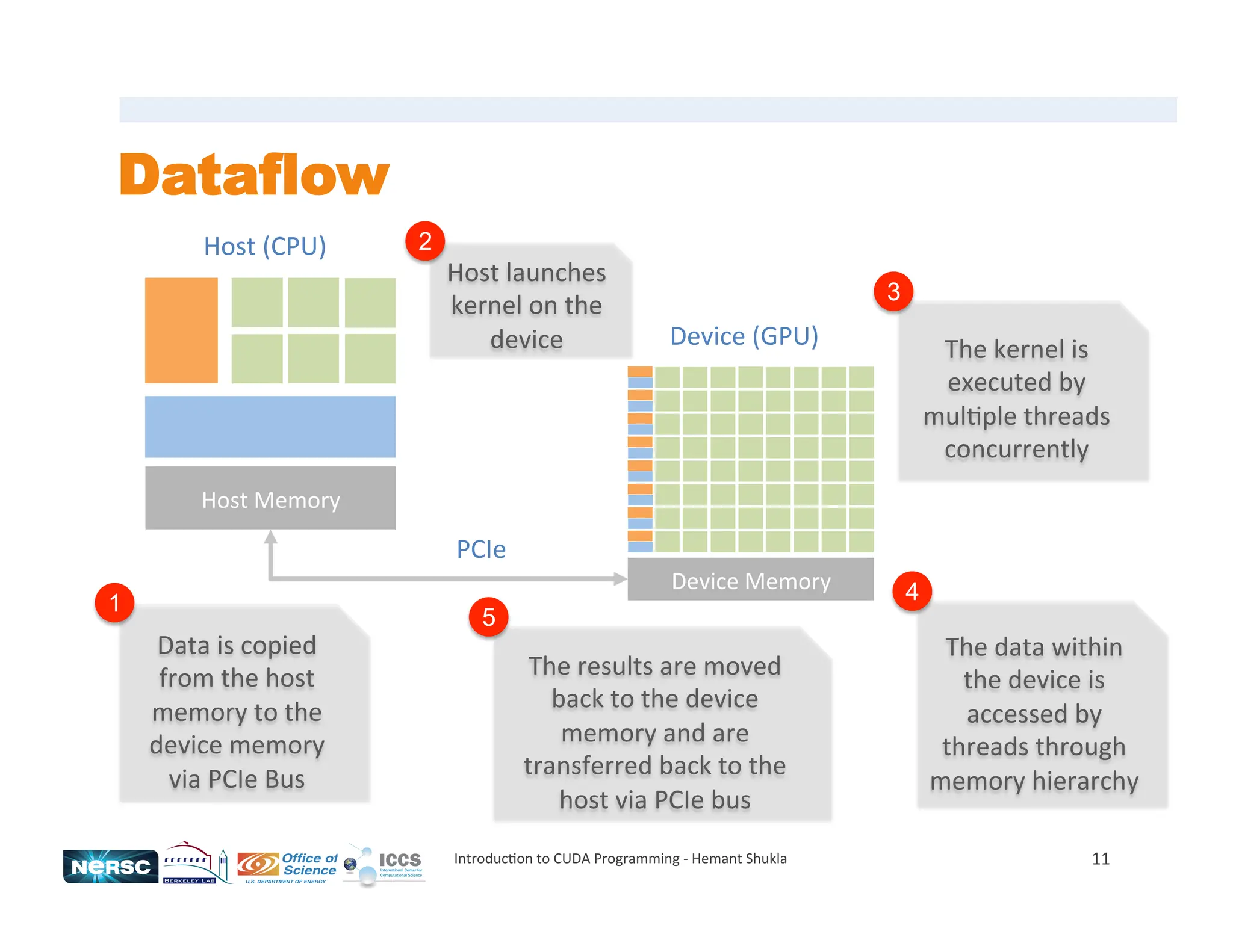

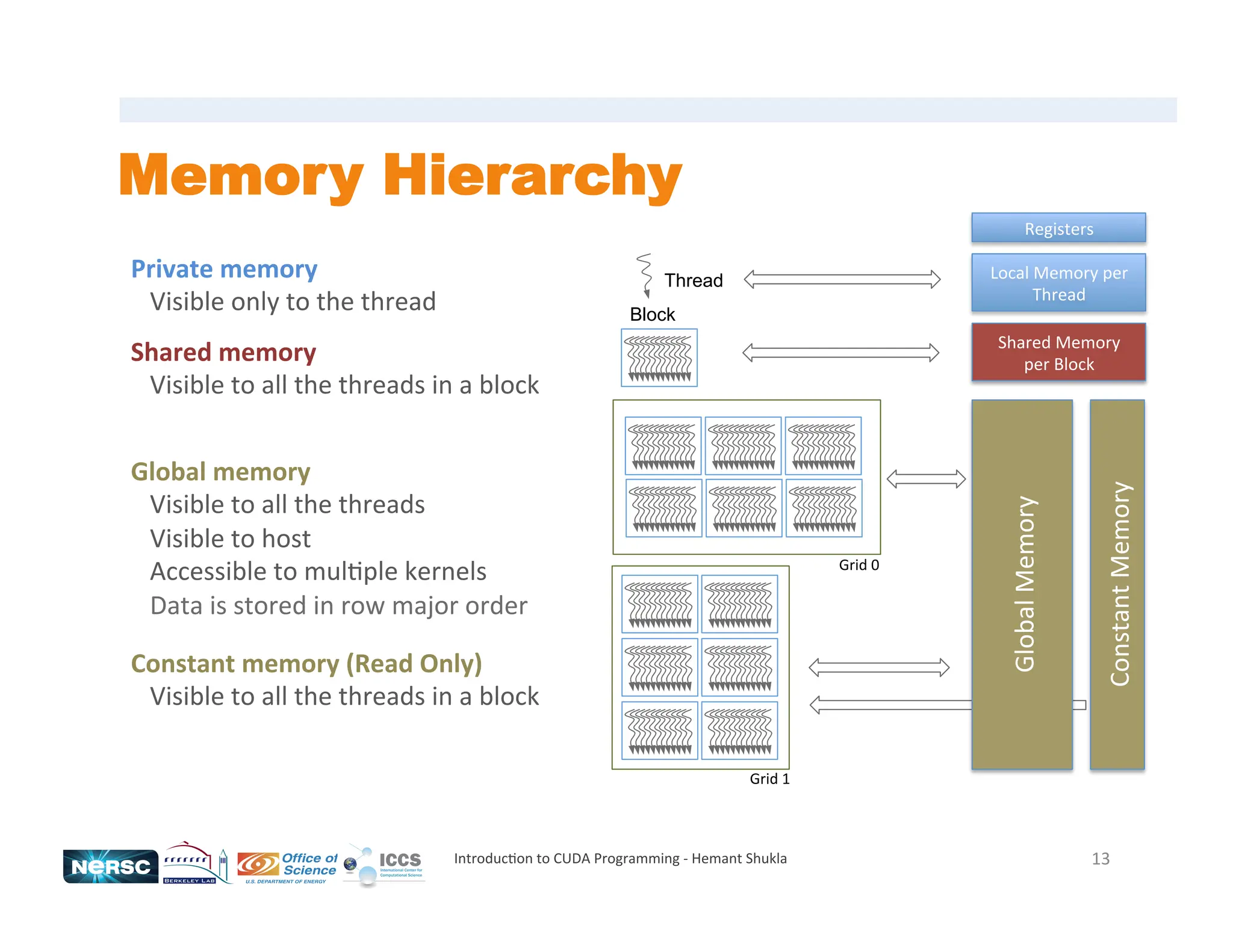



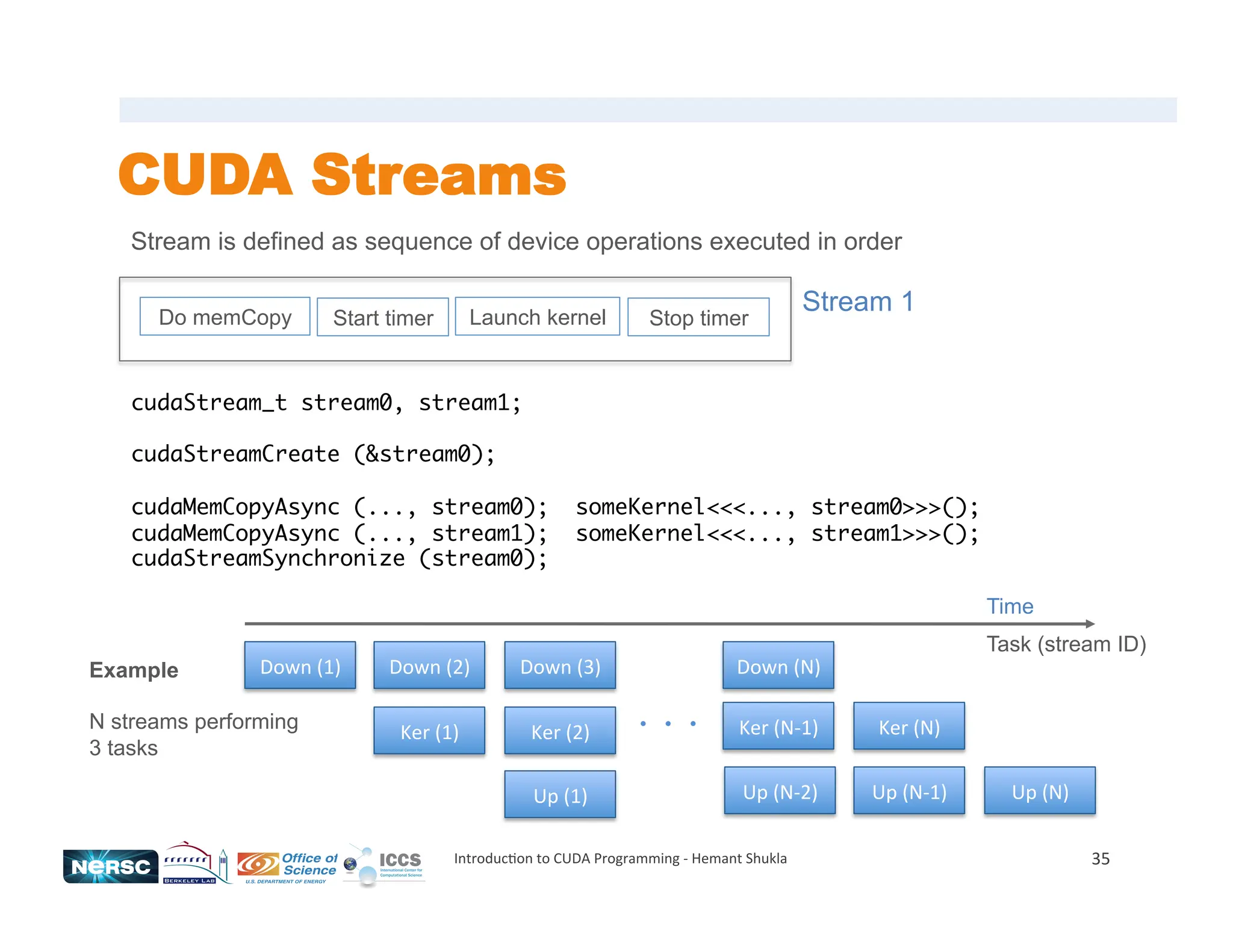
![Memory Allocations / Copies
17
Introduc+on
to
CUDA
Programming
-‐
Hemant
Shukla
int main ()
{
...
float host_signal[N]; host_result[N];
float *device_signal, *device_result;
//allocate memory on the device (GPU)
cudaMalloc ((void**) &device_signal, N * sizeof(float));
cudaMalloc ((void**) &device_result, N * sizeof(float));
... Get data for the host_signal array
// copy host_signal array to the device
cudaMemcpy (device_signal, host_signal , N * sizeof(float),
cudaMemcpyHostToDevice);
someKernel <<<< >>> (...);
//copy the result back from device to the host
cudaMemcpy (host_result, device_result, N * sizeof(float),
cudaMemcpyDeviceToHost);
//display the results
...
cudaFree (device_signal); cudaFree (device_result) ;
}
Host and device have separate physical memory
Cannot
dereference
host
pointers
on
device
and
vice
versa](https://image.slidesharecdn.com/introductiontocudaprogramming-250126180859-2334ee97/75/Introduction-to-CUDA-programming-in-C-language-17-2048.jpg)





![Example
23
Introduc+on
to
CUDA
Programming
-‐
Hemant
Shukla
c = aibi
i
∑
a
b
×
+
c
Multiplications are done in parallel
Summation is sequential
double c = 0.0;
for (int i = 0; i < SIZE; i++)
c += a[i] * b[i];
Serial representation
Simple parallelization strategy](https://image.slidesharecdn.com/introductiontocudaprogramming-250126180859-2334ee97/75/Introduction-to-CUDA-programming-in-C-language-23-2048.jpg)
![Example
24
Introduc+on
to
CUDA
Programming
-‐
Hemant
Shukla
__global__ void innerProduct (int *a, int *b, int *c)
{
int product[SIZE];
int i = threadIdx.x;
if (i < SIZE)
product[i] = a[i] * b[i];
}
__global__ void innerProduct (...)
{
...
}
int main ()
{
...
innerProduct<<<grid, block>>> (...);
...
}
CUDA Kernel
Called in the host code](https://image.slidesharecdn.com/introductiontocudaprogramming-250126180859-2334ee97/75/Introduction-to-CUDA-programming-in-C-language-24-2048.jpg)
![Example
25
Introduc+on
to
CUDA
Programming
-‐
Hemant
Shukla
__global__ void innerProduct (int *a, int *b, int *c)
{
int product[SIZE];
int i = threadIdx.x;
if (i < SIZE)
product[i] = a[i] * b[i];
}
Qualifier __global__ encapsulates
device specific code that runs on the
device and is called by the host
Other qualifiers are,
__device__, __host__,
host__and__device
threadIdx is a built in iterator for
threads. It has 3 dimensions x, y and
z.
Each thread with a unique threadIdx.x
runs the kernel code in parallel.](https://image.slidesharecdn.com/introductiontocudaprogramming-250126180859-2334ee97/75/Introduction-to-CUDA-programming-in-C-language-25-2048.jpg)
![Example
26
Introduc+on
to
CUDA
Programming
-‐
Hemant
Shukla
__global__ void innerProduct (int *a, int *b, int *c)
{
int product[SIZE];
int i = threadIdx.x;
if (i < SIZE)
product[i] = a[i] * b[i];
int sum = 0;
for (int k = 0; k < N; k++)
sum += product[k];
*c = sum;
}
Now we can sum the all the products to get
the scalar c
Unfortunately this won’t work for following reasons,
- product[i] is local to each thread
- Threads are not visible to each other](https://image.slidesharecdn.com/introductiontocudaprogramming-250126180859-2334ee97/75/Introduction-to-CUDA-programming-in-C-language-26-2048.jpg)
![Example
27
Introduc+on
to
CUDA
Programming
-‐
Hemant
Shukla
__global__ void innerProduct (int *a, int *b, int *c)
{
__shared__ int product[SIZE];
int i = threadIdx.x;
if (i < SIZE)
product[i] = a[i] * b[i];
__syncthreads();
if (threadIdx.x == 0)
{
int sum = 0;
for (int k = 0; k < SIZE; k++)
sum += product[k];
*c = sum;
}
}
First we make the product[i] visible to all the
threads by copying it to shared memory
Next we make sure that all the threads are
synchronized. In other words each thread has
finished its workload before we move ahead. We do
this by calling __syncthreads()
Finally we assign summation to one thread
(extremely inefficient reduction)
Aside: cudaThreadSynchronize() is used
on the host side to synchronize host and device](https://image.slidesharecdn.com/introductiontocudaprogramming-250126180859-2334ee97/75/Introduction-to-CUDA-programming-in-C-language-27-2048.jpg)
![Example
28
Introduc+on
to
CUDA
Programming
-‐
Hemant
Shukla
__global__ void innerProduct (int *a, int *b, int *c)
{
__shared__ int product[SIZE];
int i = threadIdx.x;
if (i < SIZE)
product[i] = a[i] * b[i];
__syncthreads();
// Efficient reduction call
*c = someEfficientLibrary_reduce (product);
}](https://image.slidesharecdn.com/introductiontocudaprogramming-250126180859-2334ee97/75/Introduction-to-CUDA-programming-in-C-language-28-2048.jpg)

![Memory Bandwidth
30
Introduc+on
to
CUDA
Programming
-‐
Hemant
Shukla
Memory bandwidth – rate at which the data is transferred – is a valuable
metric to gauge the performance of an application
Memory bandwidth (GB/s) = Memory clock rate (Hz) × interface width (bytes) / 109
Theoretical Bandwidth
Bandwidth (GB/s) = [(bytes read + bytes written) / 109 ] / execution time
Real Bandwidth (Effective Bandwidth)
May also use profilers to estimate bandwidth and bottlenecks
If real bandwidth is much lower than the theoretical then code may need review
Optimize on Real Bandwidth](https://image.slidesharecdn.com/introductiontocudaprogramming-250126180859-2334ee97/75/Introduction-to-CUDA-programming-in-C-language-30-2048.jpg)

![Example revisited
32
Introduc+on
to
CUDA
Programming
-‐
Hemant
Shukla
__global__ void innerProduct (int *a, int *b, int *c)
{
__shared__ int product[SIZE];
int i = threadIdx.x;
if (i < SIZE)
product[i] = a[i] * b[i];
__syncthreads();
if (threadIdx.x == 0)
{
int sum = 0;
for (int k = 0; k < SIZE; k++)
sum += product[k];
*c = sum;
}
}
Contrast this with inner product example where for
every 2 memory (data ai and bi) accesses only two
operations (multiplication and add) are performed.
That is ratio of 1 as opposed to 28 that is required for
peak throughput.
Room for algorithm improvement!
Aside: Not all performance will be peak performance](https://image.slidesharecdn.com/introductiontocudaprogramming-250126180859-2334ee97/75/Introduction-to-CUDA-programming-in-C-language-32-2048.jpg)


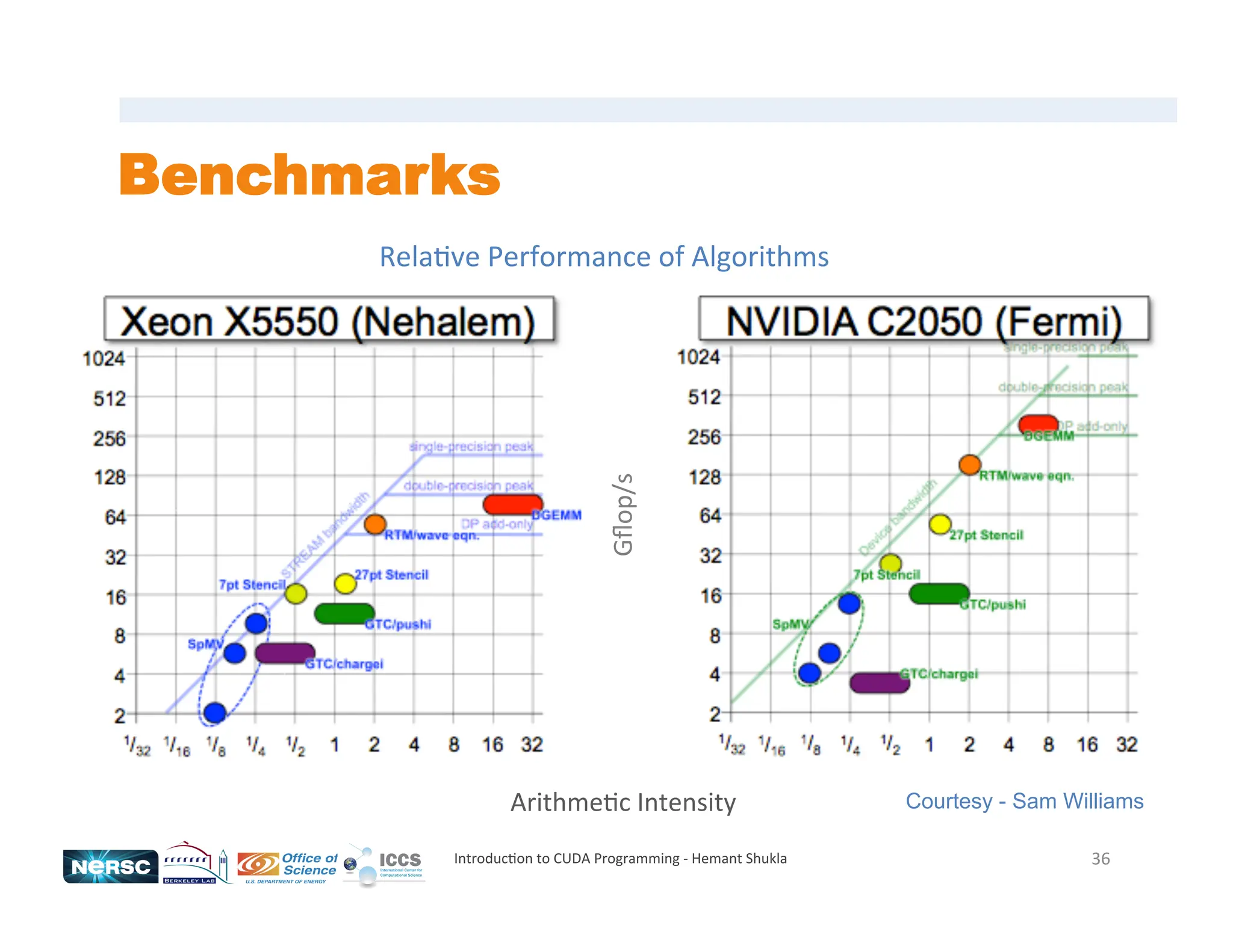








![Matrix Multiplication...
47
Introduc+on
to
CUDA
Programming
-‐
Hemant
Shukla
__global__ void matrixMultiplication (float* A, float* B, float* C, int WIDTH)
{
int i = blockIdx.y * WIDTH + threadIdx.y;
int j = blockIdx.x * WIDTH + threadIdx.x;
// each thread computes one element of product matrix C
for (k 0 : k)
sum += A[i][k] * B[k][j];
C[i][j] = sum;
}
GPU Version (Memory locations)
Constant memory
Shared memory
Global memory (read)
Global memory (write)](https://image.slidesharecdn.com/introductiontocudaprogramming-250126180859-2334ee97/75/Introduction-to-CUDA-programming-in-C-language-47-2048.jpg)



![Matrix Multiplication...
52
Introduc+on
to
CUDA
Programming
-‐
Hemant
Shukla
__global__ void matrixMultiplication(float* A, float* B, float* C, int WIDTH,
int TILE_WIDTH)
{
__shared__float A_S[TILE_WIDTH][TILE_WIDTH];
__shared__float B_S[TILE_WIDTH][TILE_WIDTH];
int bx = blockIdx.x; int by = blockIdx.y;
int tx = threadIdx.x; int ty = threadIdx.y;
// row and column of the C element to calculate
int Row = by * TILE_WIDTH + ty;
int Col = bx * TILE_WIDTH + tx;
float sum = 0;
// Loop over the A and B tiles required to compute the C element
for (int m = 0; m < Width/TILE_WIDTH; ++m) {
// Collectively Load A and B tiles from the global memory into shared memory
A_S[tx][ty] = A[(m*TILE_WIDTH + tx)*Width+Row];
B_S[tx][ty] = B[Col*Width+(m*TILE_WIDTH + ty)];
__syncthreads();
for (int k = 0; k < TILE_WIDTH; ++k)
sum += A_S[tx][k] * B_C[k][ty];
__synchthreads();
}
C [Row*Width+Col] = sum;
}](https://image.slidesharecdn.com/introductiontocudaprogramming-250126180859-2334ee97/75/Introduction-to-CUDA-programming-in-C-language-52-2048.jpg)






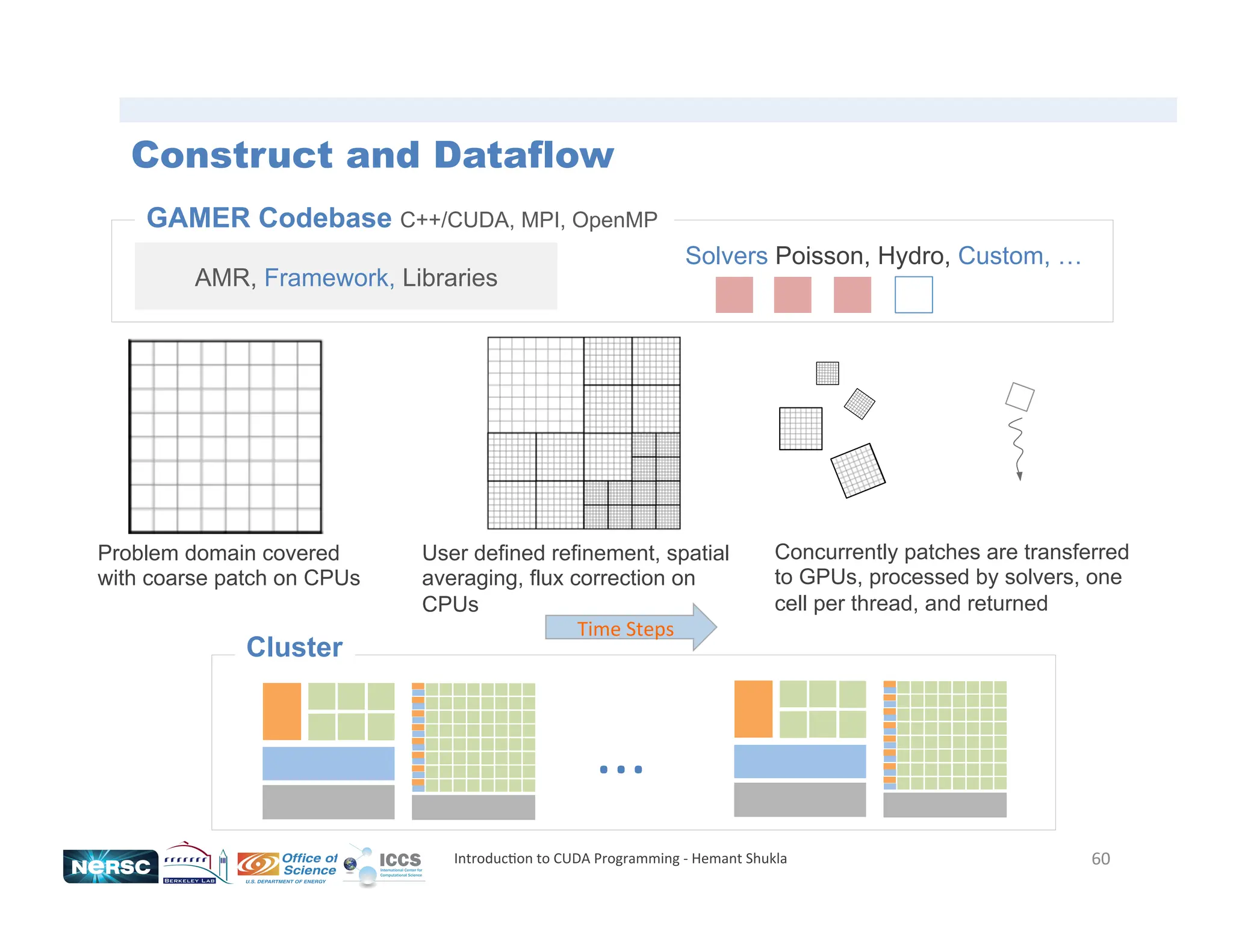
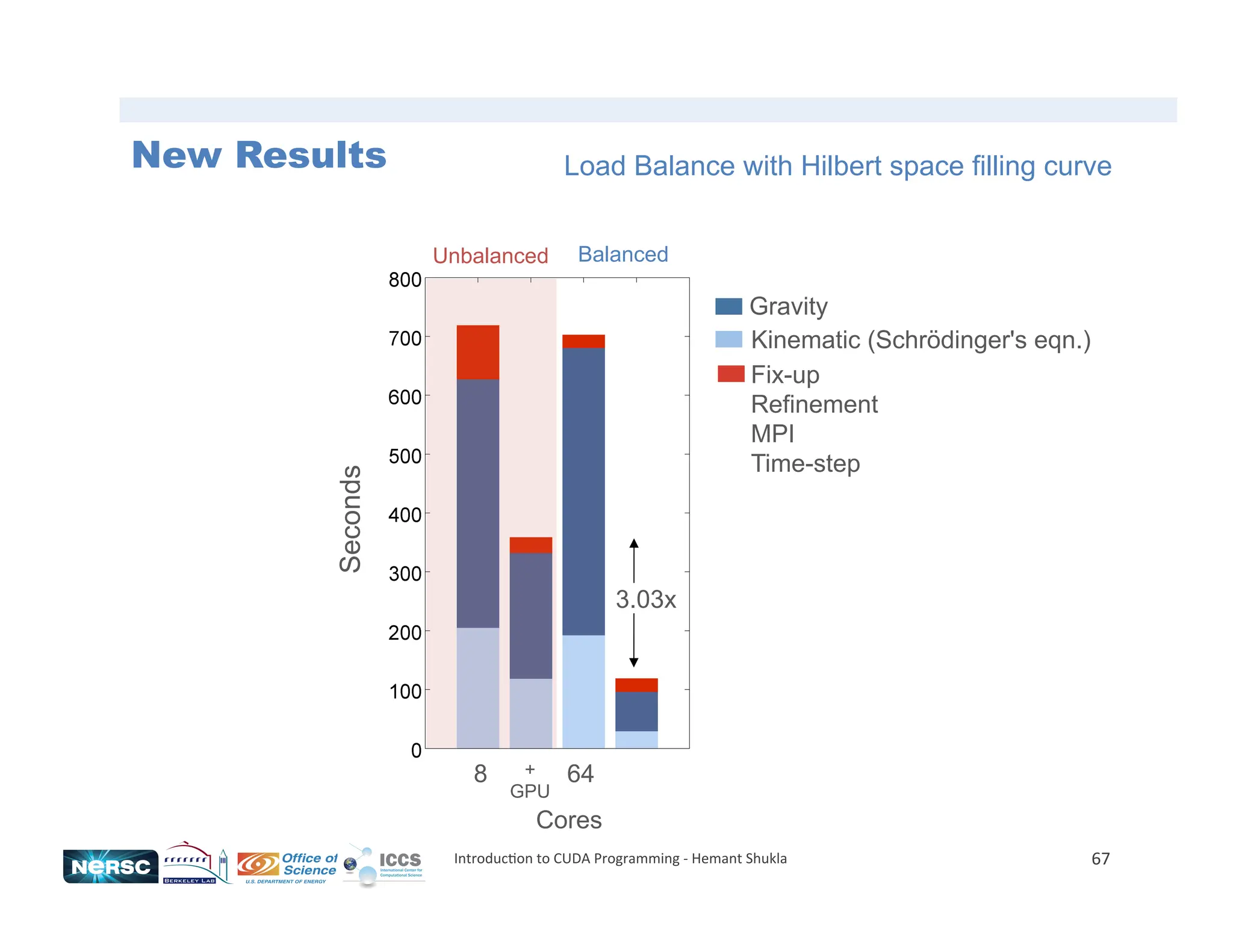
![61
Solvers
Hydrodynamics PDE Solver
3D Euler equations solved in 5 separate schemes
Second-order relaxing Total Variation Diminishing
Weighted average flux
MUSCL-Hancock (MHM)
MUSCL-Hancock (VL)
Corner transport upwind (CTU)
Flux conservation is done using Riemann Solver
(4 types - exact solver, HLLE, HLLC, and Roe)
€
∂ρ
∂t
+
∂(ρv j )
∂x j
= 0
∂(ρvi )
∂t
+
∂(ρviv j +Pδij )
∂x j
= −ρ
∂φ
∂xi
∂e
∂t
+
∂[(e + P)v j ]
∂x j
= −ρv j
∂φ
∂x j
Poisson-Gravity Solver
€
∇2
φ(
x) = 4πGρ(
x)
Laplacian operator is replaced by seven-point
finite difference operator
For root level patches Green’s functions is used
using FFTW
For refined levels SOR is used
Recently implemented
Multigrid Poisson Solver
Hilbert space-filling curve (load balancing)
Currently implementing
Fast Poisson Solver with Dirichlet’s boundary
conditions
€
∇2
Introduc+on
to
CUDA
Programming
-‐
Hemant
Shukla](https://image.slidesharecdn.com/introductiontocudaprogramming-250126180859-2334ee97/75/Introduction-to-CUDA-programming-in-C-language-61-2048.jpg)

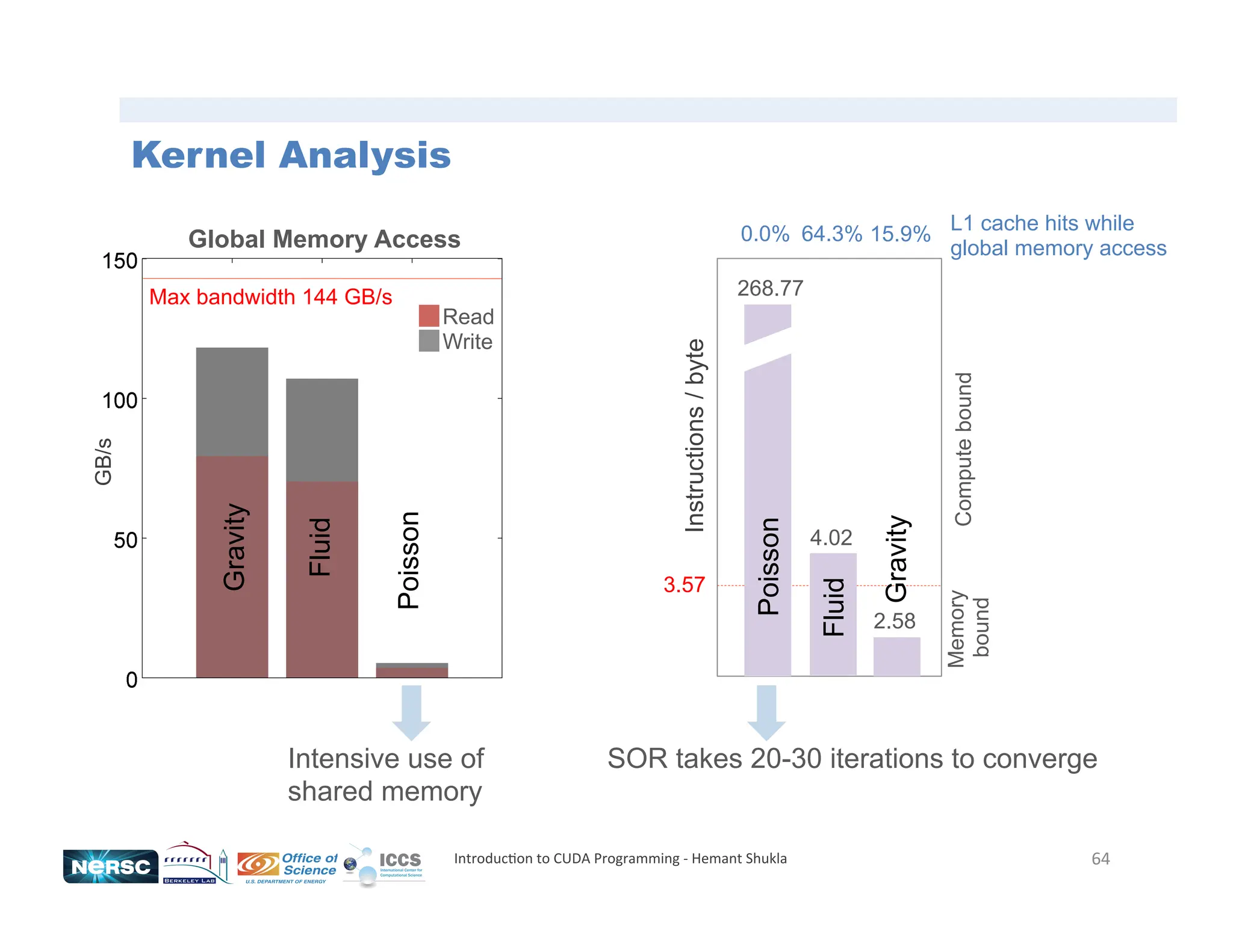
![63
Introduc+on
to
CUDA
Programming
-‐
Hemant
Shukla
Multi-Science
Cosmological Large-scale Structure
Bosonic Dark Matter
Gravitational Lensing Potential
€
∇2
φ(
x) = 4πGa[ρ(
x) − ρb (
x)]
Effec+ve
resolu+on
81923
€
i
∂ψ
∂t
= −
2
2a2
m
∇2
ψ + mVψ
Gravitational potential
Schrodinger-Poisson equation
u =
x − ∇φ(
x)
∇2
φ(
x) = ∑(
x)/∑cr
Lens equation and mass relationship
Structure
due
to
dark
maTer
model
in
early
universe](https://image.slidesharecdn.com/introductiontocudaprogramming-250126180859-2334ee97/75/Introduction-to-CUDA-programming-in-C-language-63-2048.jpg)
















![Memory Allocations / Copies
17
Introduc+on
to
CUDA
Programming
-‐
Hemant
Shukla
int main ()
{
...
float host_signal[N]; host_result[N];
float *device_signal, *device_result;
//allocate memory on the device (GPU)
cudaMalloc ((void**) &device_signal, N * sizeof(float));
cudaMalloc ((void**) &device_result, N * sizeof(float));
... Get data for the host_signal array
// copy host_signal array to the device
cudaMemcpy (device_signal, host_signal , N * sizeof(float),
cudaMemcpyHostToDevice);
someKernel <<<< >>> (...);
//copy the result back from device to the host
cudaMemcpy (host_result, device_result, N * sizeof(float),
cudaMemcpyDeviceToHost);
//display the results
...
cudaFree (device_signal); cudaFree (device_result) ;
}
Host and device have separate physical memory
Cannot
dereference
host
pointers
on
device
and
vice
versa](https://crownmelresort.com/image.slidesharecdn.com/introductiontocudaprogramming-250126180859-2334ee97/75/Introduction-to-CUDA-programming-in-C-language-17-2048.jpg)





![Example
23
Introduc+on
to
CUDA
Programming
-‐
Hemant
Shukla
c = aibi
i
∑
a
b
×
+
c
Multiplications are done in parallel
Summation is sequential
double c = 0.0;
for (int i = 0; i < SIZE; i++)
c += a[i] * b[i];
Serial representation
Simple parallelization strategy](https://crownmelresort.com/image.slidesharecdn.com/introductiontocudaprogramming-250126180859-2334ee97/75/Introduction-to-CUDA-programming-in-C-language-23-2048.jpg)
![Example
24
Introduc+on
to
CUDA
Programming
-‐
Hemant
Shukla
__global__ void innerProduct (int *a, int *b, int *c)
{
int product[SIZE];
int i = threadIdx.x;
if (i < SIZE)
product[i] = a[i] * b[i];
}
__global__ void innerProduct (...)
{
...
}
int main ()
{
...
innerProduct<<<grid, block>>> (...);
...
}
CUDA Kernel
Called in the host code](https://crownmelresort.com/image.slidesharecdn.com/introductiontocudaprogramming-250126180859-2334ee97/75/Introduction-to-CUDA-programming-in-C-language-24-2048.jpg)
![Example
25
Introduc+on
to
CUDA
Programming
-‐
Hemant
Shukla
__global__ void innerProduct (int *a, int *b, int *c)
{
int product[SIZE];
int i = threadIdx.x;
if (i < SIZE)
product[i] = a[i] * b[i];
}
Qualifier __global__ encapsulates
device specific code that runs on the
device and is called by the host
Other qualifiers are,
__device__, __host__,
host__and__device
threadIdx is a built in iterator for
threads. It has 3 dimensions x, y and
z.
Each thread with a unique threadIdx.x
runs the kernel code in parallel.](https://crownmelresort.com/image.slidesharecdn.com/introductiontocudaprogramming-250126180859-2334ee97/75/Introduction-to-CUDA-programming-in-C-language-25-2048.jpg)
![Example
26
Introduc+on
to
CUDA
Programming
-‐
Hemant
Shukla
__global__ void innerProduct (int *a, int *b, int *c)
{
int product[SIZE];
int i = threadIdx.x;
if (i < SIZE)
product[i] = a[i] * b[i];
int sum = 0;
for (int k = 0; k < N; k++)
sum += product[k];
*c = sum;
}
Now we can sum the all the products to get
the scalar c
Unfortunately this won’t work for following reasons,
- product[i] is local to each thread
- Threads are not visible to each other](https://crownmelresort.com/image.slidesharecdn.com/introductiontocudaprogramming-250126180859-2334ee97/75/Introduction-to-CUDA-programming-in-C-language-26-2048.jpg)
![Example
27
Introduc+on
to
CUDA
Programming
-‐
Hemant
Shukla
__global__ void innerProduct (int *a, int *b, int *c)
{
__shared__ int product[SIZE];
int i = threadIdx.x;
if (i < SIZE)
product[i] = a[i] * b[i];
__syncthreads();
if (threadIdx.x == 0)
{
int sum = 0;
for (int k = 0; k < SIZE; k++)
sum += product[k];
*c = sum;
}
}
First we make the product[i] visible to all the
threads by copying it to shared memory
Next we make sure that all the threads are
synchronized. In other words each thread has
finished its workload before we move ahead. We do
this by calling __syncthreads()
Finally we assign summation to one thread
(extremely inefficient reduction)
Aside: cudaThreadSynchronize() is used
on the host side to synchronize host and device](https://crownmelresort.com/image.slidesharecdn.com/introductiontocudaprogramming-250126180859-2334ee97/75/Introduction-to-CUDA-programming-in-C-language-27-2048.jpg)
![Example
28
Introduc+on
to
CUDA
Programming
-‐
Hemant
Shukla
__global__ void innerProduct (int *a, int *b, int *c)
{
__shared__ int product[SIZE];
int i = threadIdx.x;
if (i < SIZE)
product[i] = a[i] * b[i];
__syncthreads();
// Efficient reduction call
*c = someEfficientLibrary_reduce (product);
}](https://crownmelresort.com/image.slidesharecdn.com/introductiontocudaprogramming-250126180859-2334ee97/75/Introduction-to-CUDA-programming-in-C-language-28-2048.jpg)

![Memory Bandwidth
30
Introduc+on
to
CUDA
Programming
-‐
Hemant
Shukla
Memory bandwidth – rate at which the data is transferred – is a valuable
metric to gauge the performance of an application
Memory bandwidth (GB/s) = Memory clock rate (Hz) × interface width (bytes) / 109
Theoretical Bandwidth
Bandwidth (GB/s) = [(bytes read + bytes written) / 109 ] / execution time
Real Bandwidth (Effective Bandwidth)
May also use profilers to estimate bandwidth and bottlenecks
If real bandwidth is much lower than the theoretical then code may need review
Optimize on Real Bandwidth](https://crownmelresort.com/image.slidesharecdn.com/introductiontocudaprogramming-250126180859-2334ee97/75/Introduction-to-CUDA-programming-in-C-language-30-2048.jpg)

![Example revisited
32
Introduc+on
to
CUDA
Programming
-‐
Hemant
Shukla
__global__ void innerProduct (int *a, int *b, int *c)
{
__shared__ int product[SIZE];
int i = threadIdx.x;
if (i < SIZE)
product[i] = a[i] * b[i];
__syncthreads();
if (threadIdx.x == 0)
{
int sum = 0;
for (int k = 0; k < SIZE; k++)
sum += product[k];
*c = sum;
}
}
Contrast this with inner product example where for
every 2 memory (data ai and bi) accesses only two
operations (multiplication and add) are performed.
That is ratio of 1 as opposed to 28 that is required for
peak throughput.
Room for algorithm improvement!
Aside: Not all performance will be peak performance](https://crownmelresort.com/image.slidesharecdn.com/introductiontocudaprogramming-250126180859-2334ee97/75/Introduction-to-CUDA-programming-in-C-language-32-2048.jpg)














![Matrix Multiplication...
47
Introduc+on
to
CUDA
Programming
-‐
Hemant
Shukla
__global__ void matrixMultiplication (float* A, float* B, float* C, int WIDTH)
{
int i = blockIdx.y * WIDTH + threadIdx.y;
int j = blockIdx.x * WIDTH + threadIdx.x;
// each thread computes one element of product matrix C
for (k 0 : k)
sum += A[i][k] * B[k][j];
C[i][j] = sum;
}
GPU Version (Memory locations)
Constant memory
Shared memory
Global memory (read)
Global memory (write)](https://crownmelresort.com/image.slidesharecdn.com/introductiontocudaprogramming-250126180859-2334ee97/75/Introduction-to-CUDA-programming-in-C-language-47-2048.jpg)




![Matrix Multiplication...
52
Introduc+on
to
CUDA
Programming
-‐
Hemant
Shukla
__global__ void matrixMultiplication(float* A, float* B, float* C, int WIDTH,
int TILE_WIDTH)
{
__shared__float A_S[TILE_WIDTH][TILE_WIDTH];
__shared__float B_S[TILE_WIDTH][TILE_WIDTH];
int bx = blockIdx.x; int by = blockIdx.y;
int tx = threadIdx.x; int ty = threadIdx.y;
// row and column of the C element to calculate
int Row = by * TILE_WIDTH + ty;
int Col = bx * TILE_WIDTH + tx;
float sum = 0;
// Loop over the A and B tiles required to compute the C element
for (int m = 0; m < Width/TILE_WIDTH; ++m) {
// Collectively Load A and B tiles from the global memory into shared memory
A_S[tx][ty] = A[(m*TILE_WIDTH + tx)*Width+Row];
B_S[tx][ty] = B[Col*Width+(m*TILE_WIDTH + ty)];
__syncthreads();
for (int k = 0; k < TILE_WIDTH; ++k)
sum += A_S[tx][k] * B_C[k][ty];
__synchthreads();
}
C [Row*Width+Col] = sum;
}](https://crownmelresort.com/image.slidesharecdn.com/introductiontocudaprogramming-250126180859-2334ee97/75/Introduction-to-CUDA-programming-in-C-language-52-2048.jpg)








![61
Solvers
Hydrodynamics PDE Solver
3D Euler equations solved in 5 separate schemes
Second-order relaxing Total Variation Diminishing
Weighted average flux
MUSCL-Hancock (MHM)
MUSCL-Hancock (VL)
Corner transport upwind (CTU)
Flux conservation is done using Riemann Solver
(4 types - exact solver, HLLE, HLLC, and Roe)
€
∂ρ
∂t
+
∂(ρv j )
∂x j
= 0
∂(ρvi )
∂t
+
∂(ρviv j +Pδij )
∂x j
= −ρ
∂φ
∂xi
∂e
∂t
+
∂[(e + P)v j ]
∂x j
= −ρv j
∂φ
∂x j
Poisson-Gravity Solver
€
∇2
φ(
x) = 4πGρ(
x)
Laplacian operator is replaced by seven-point
finite difference operator
For root level patches Green’s functions is used
using FFTW
For refined levels SOR is used
Recently implemented
Multigrid Poisson Solver
Hilbert space-filling curve (load balancing)
Currently implementing
Fast Poisson Solver with Dirichlet’s boundary
conditions
€
∇2
Introduc+on
to
CUDA
Programming
-‐
Hemant
Shukla](https://crownmelresort.com/image.slidesharecdn.com/introductiontocudaprogramming-250126180859-2334ee97/75/Introduction-to-CUDA-programming-in-C-language-61-2048.jpg)

![63
Introduc+on
to
CUDA
Programming
-‐
Hemant
Shukla
Multi-Science
Cosmological Large-scale Structure
Bosonic Dark Matter
Gravitational Lensing Potential
€
∇2
φ(
x) = 4πGa[ρ(
x) − ρb (
x)]
Effec+ve
resolu+on
81923
€
i
∂ψ
∂t
= −
2
2a2
m
∇2
ψ + mVψ
Gravitational potential
Schrodinger-Poisson equation
u =
x − ∇φ(
x)
∇2
φ(
x) = ∑(
x)/∑cr
Lens equation and mass relationship
Structure
due
to
dark
maTer
model
in
early
universe](https://crownmelresort.com/image.slidesharecdn.com/introductiontocudaprogramming-250126180859-2334ee97/75/Introduction-to-CUDA-programming-in-C-language-63-2048.jpg)
































































