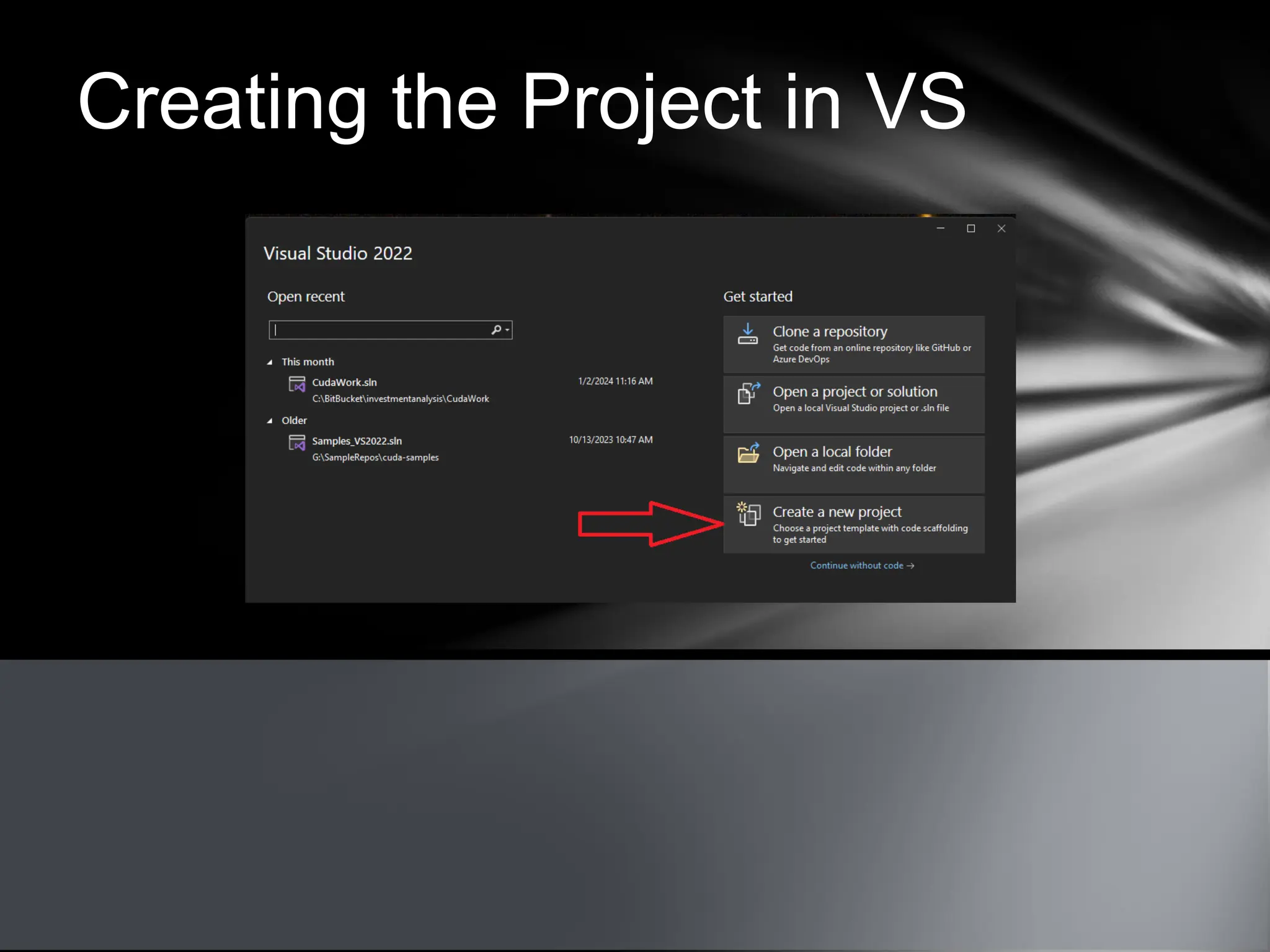
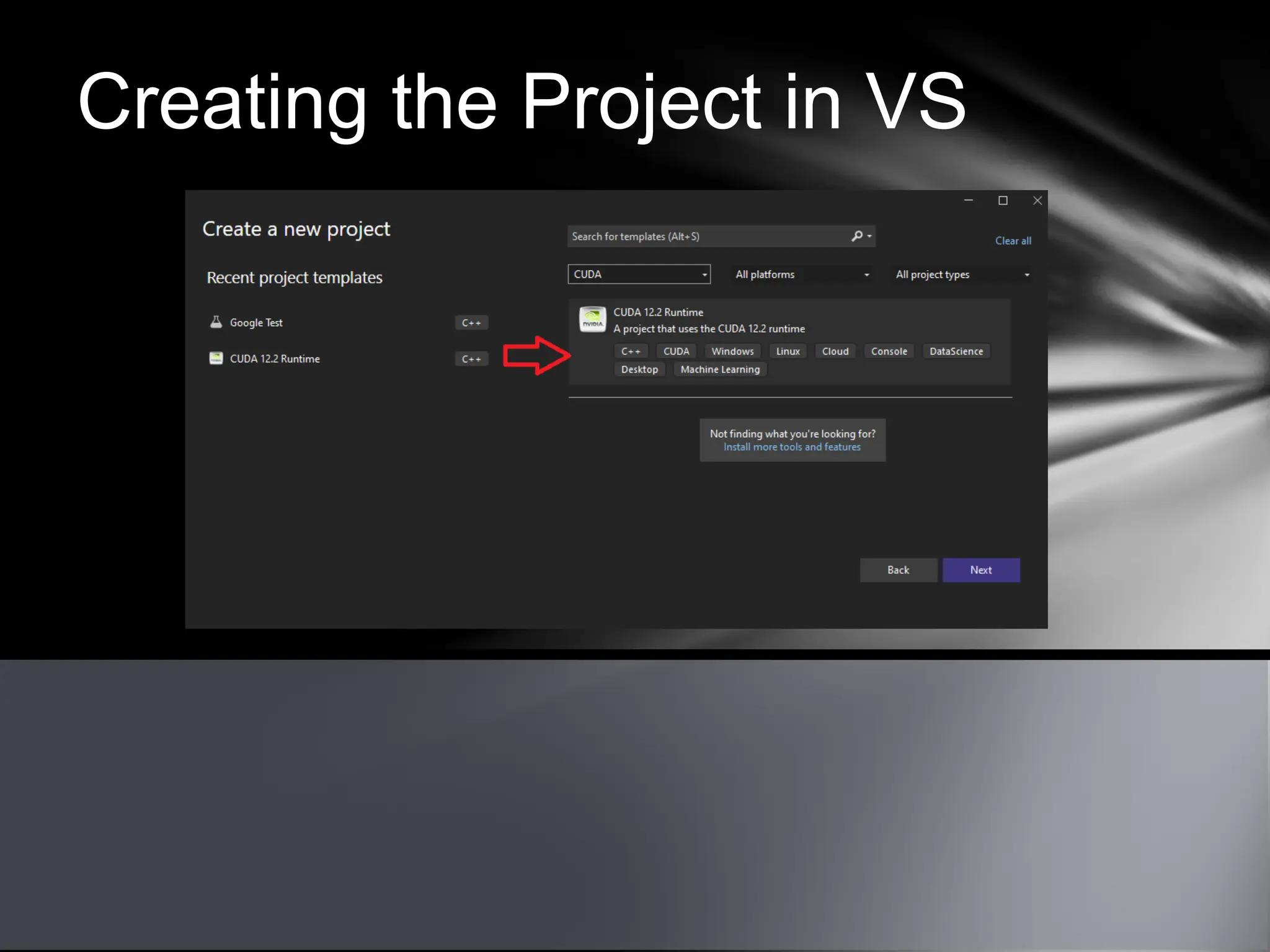
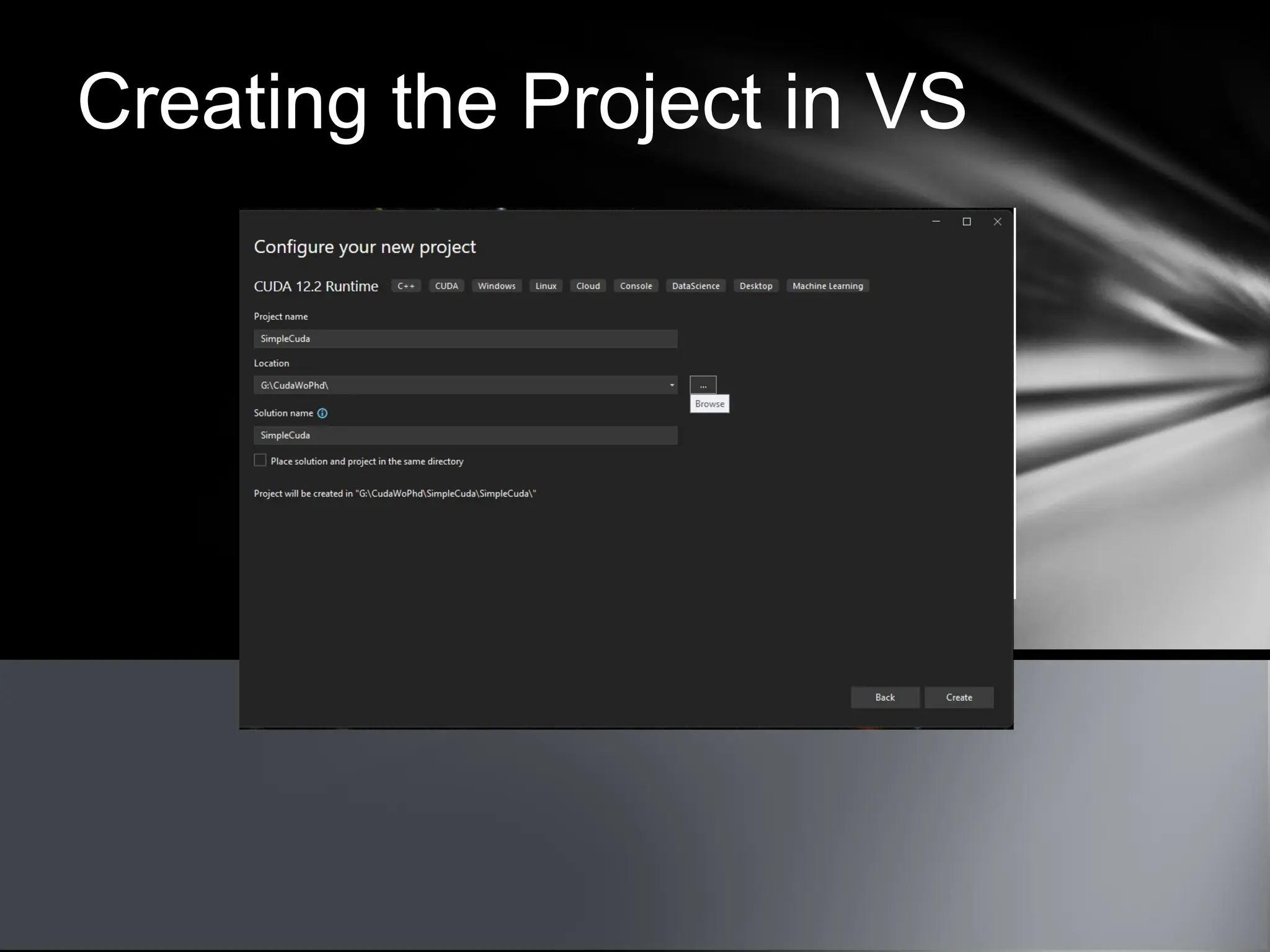
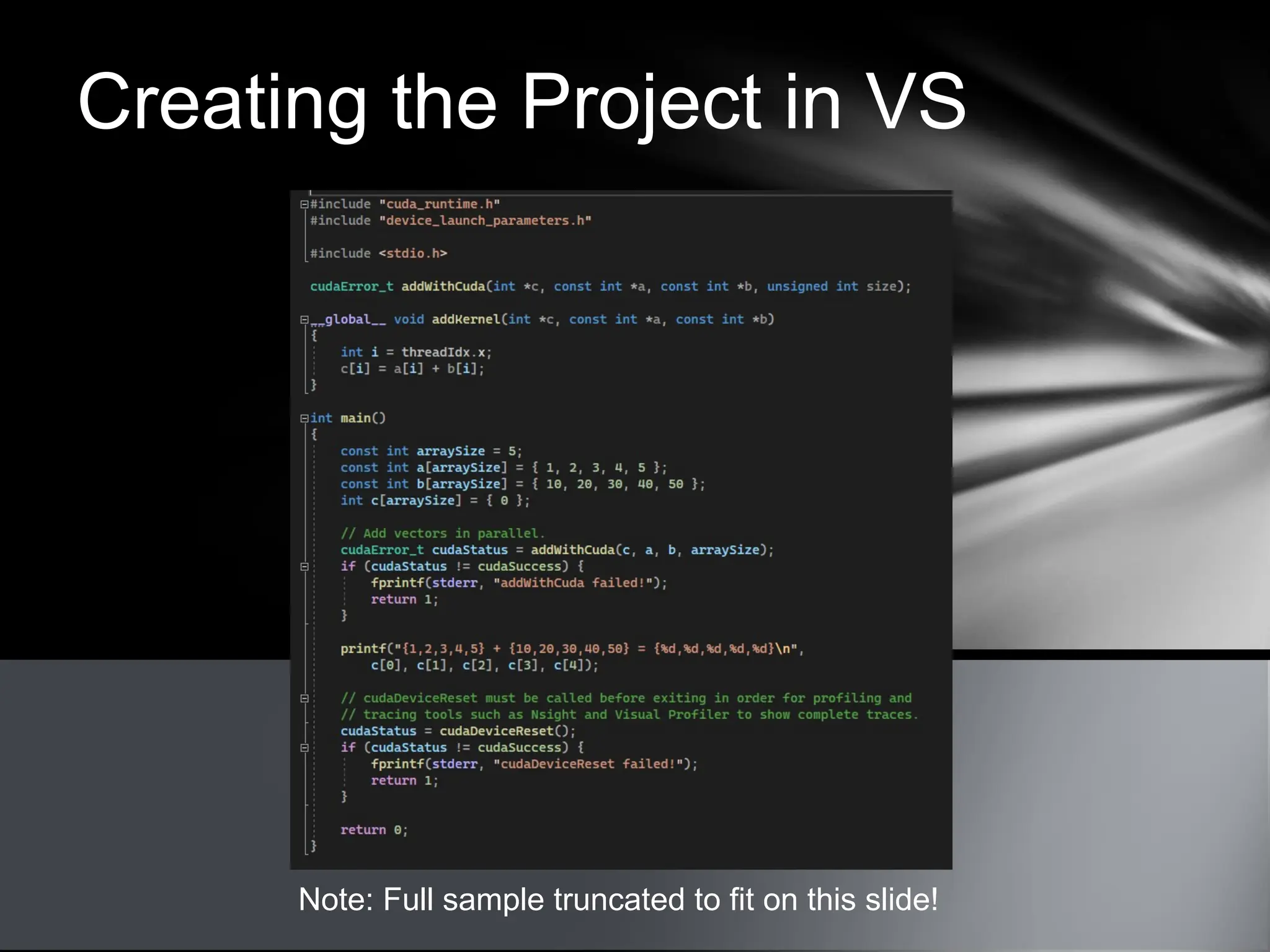
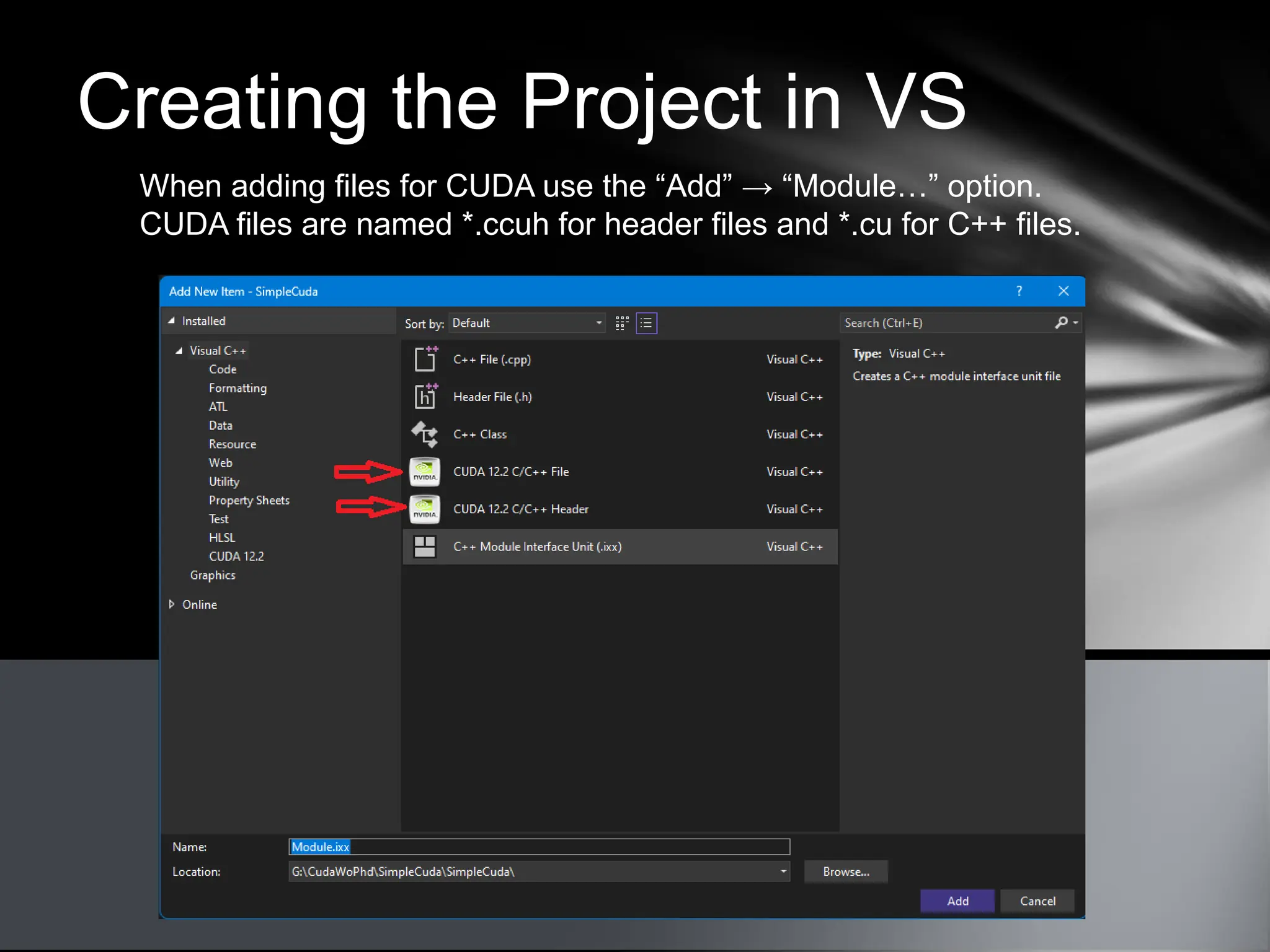
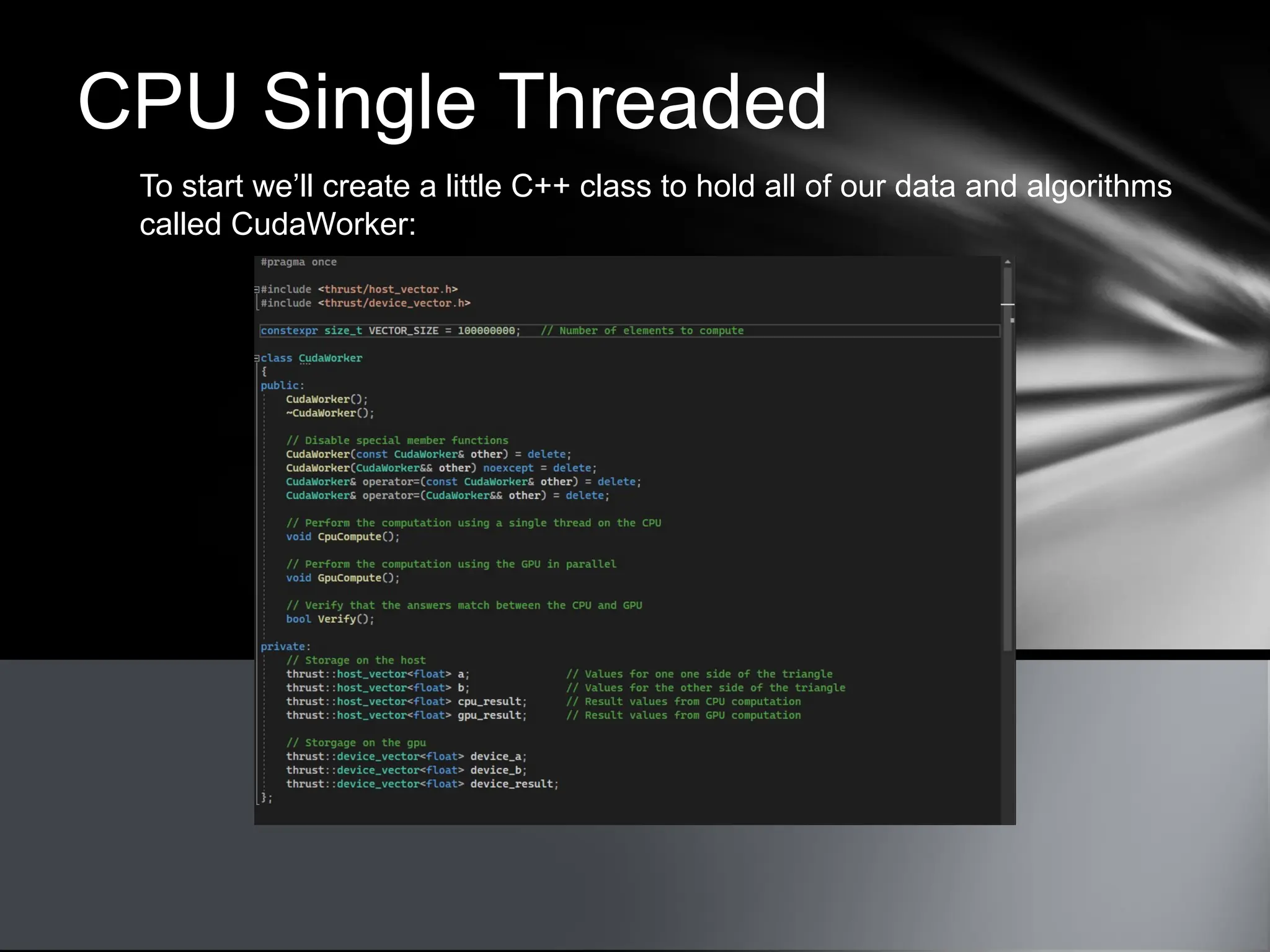
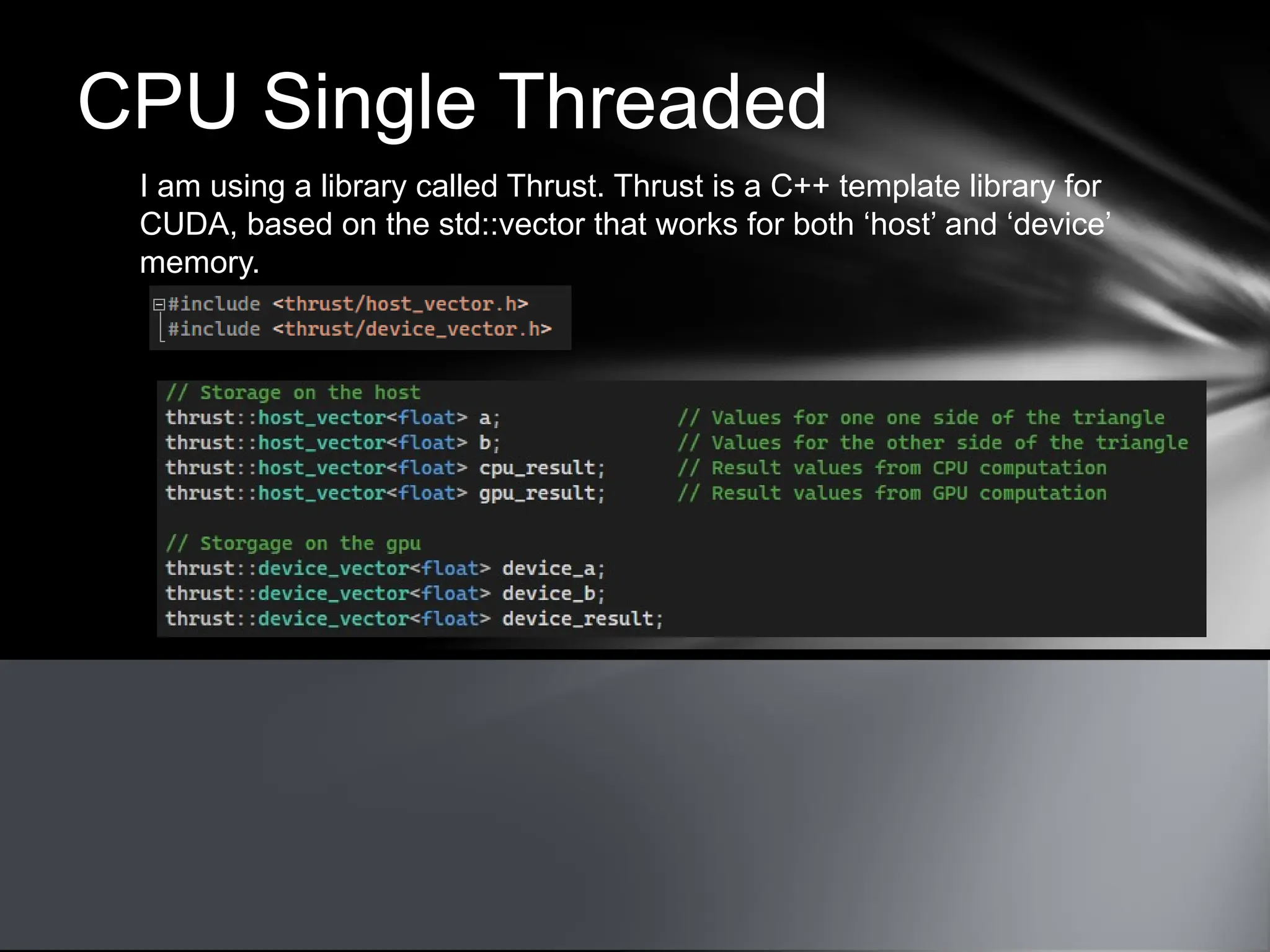
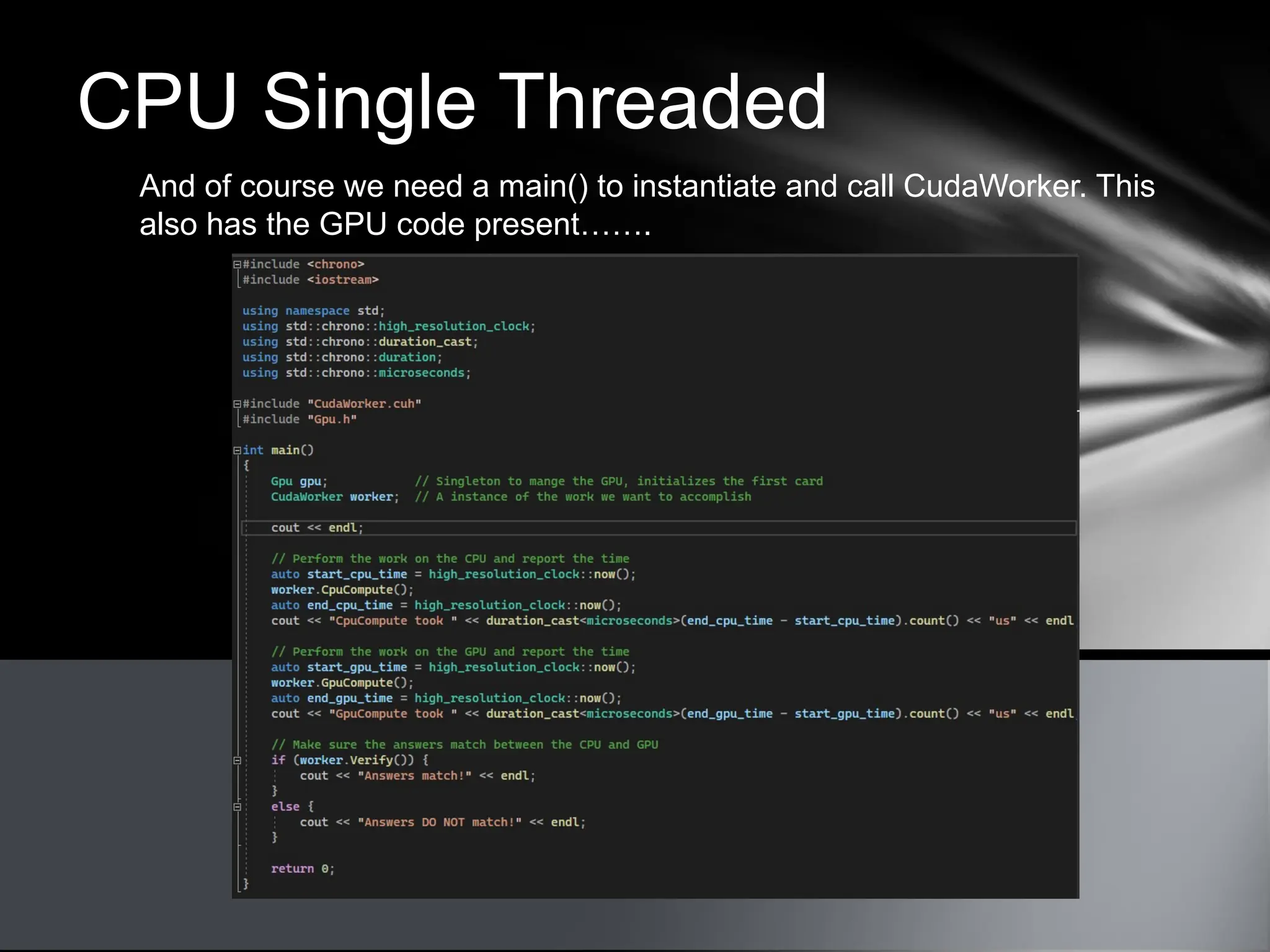
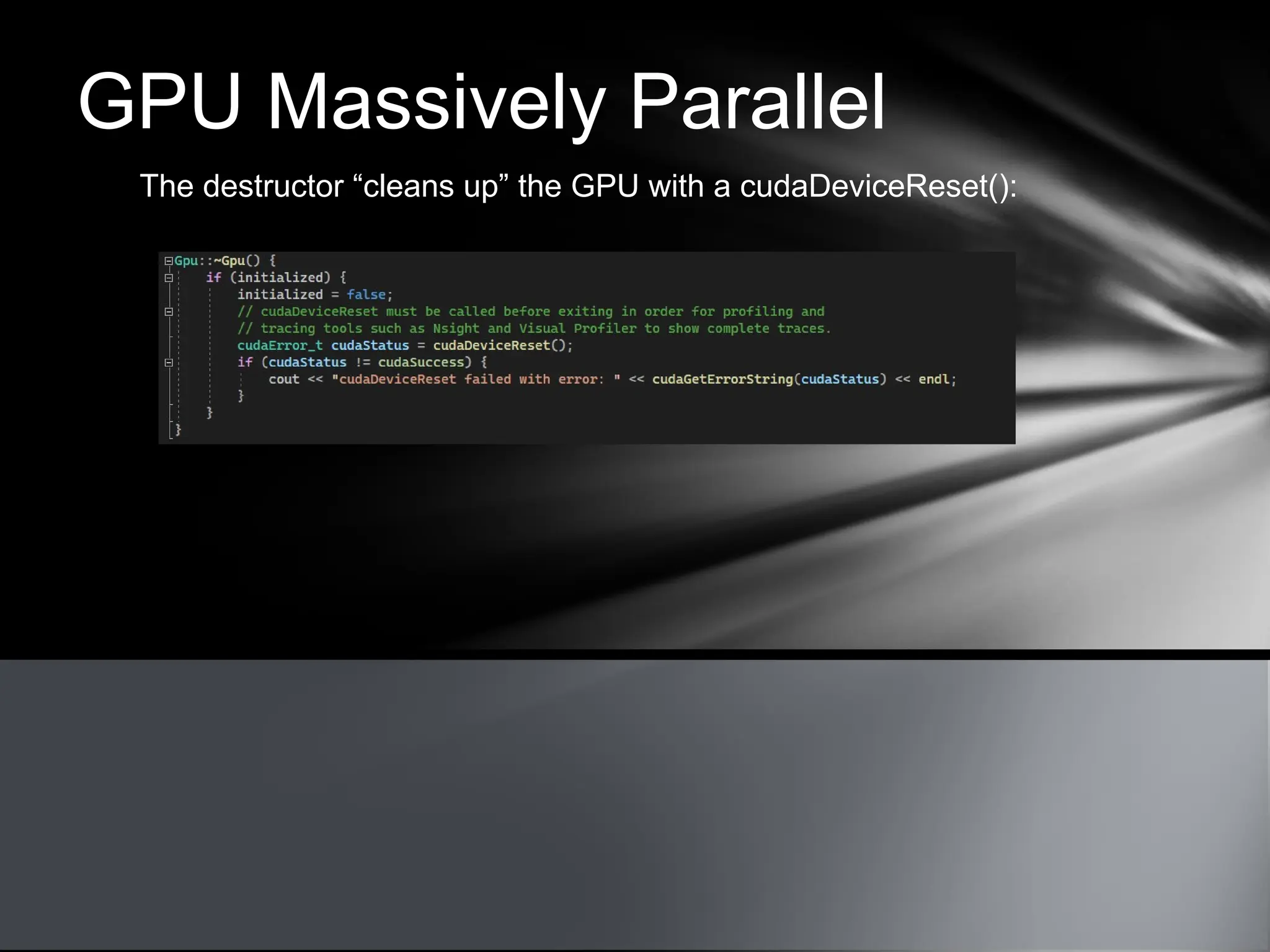
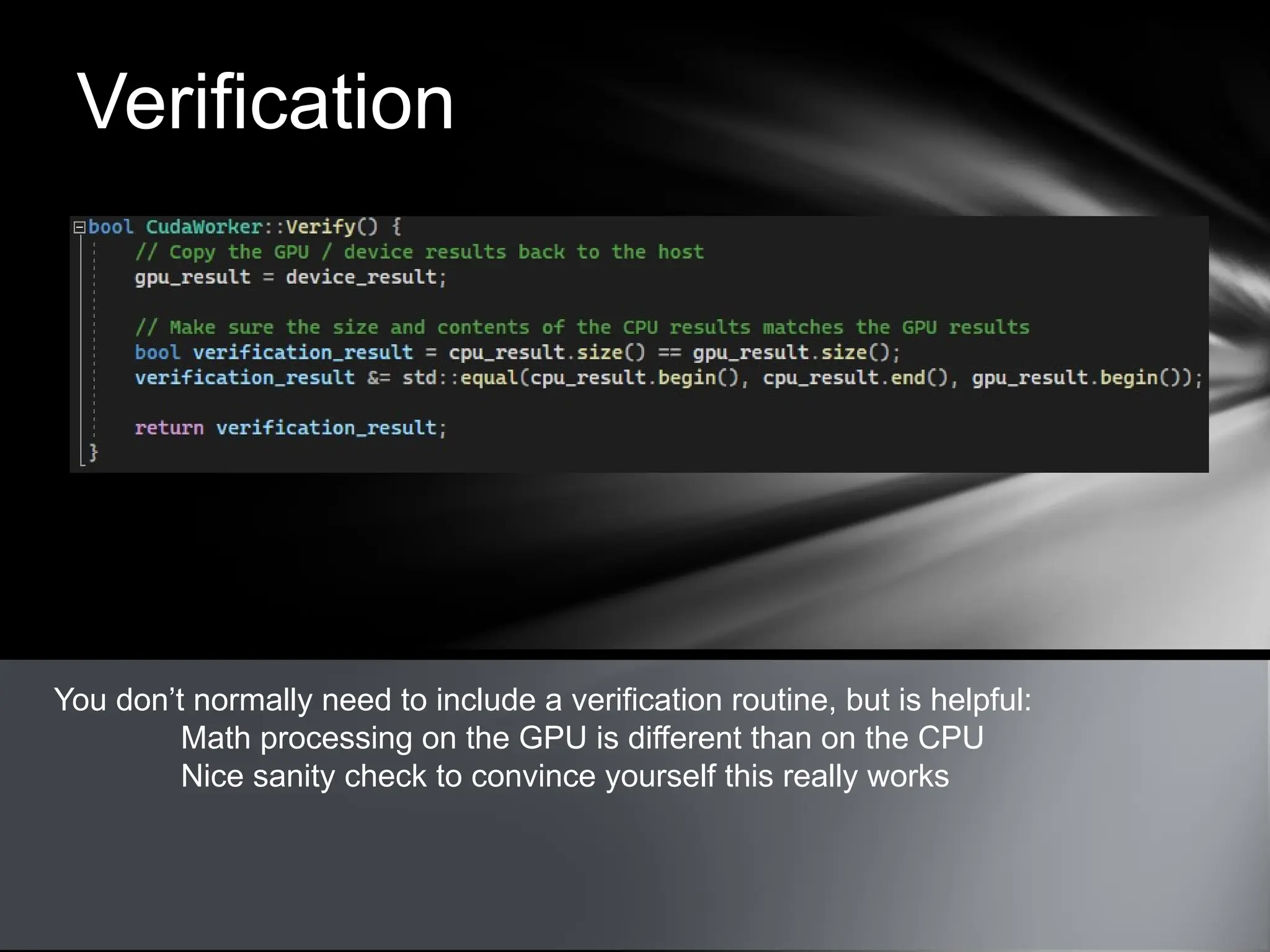
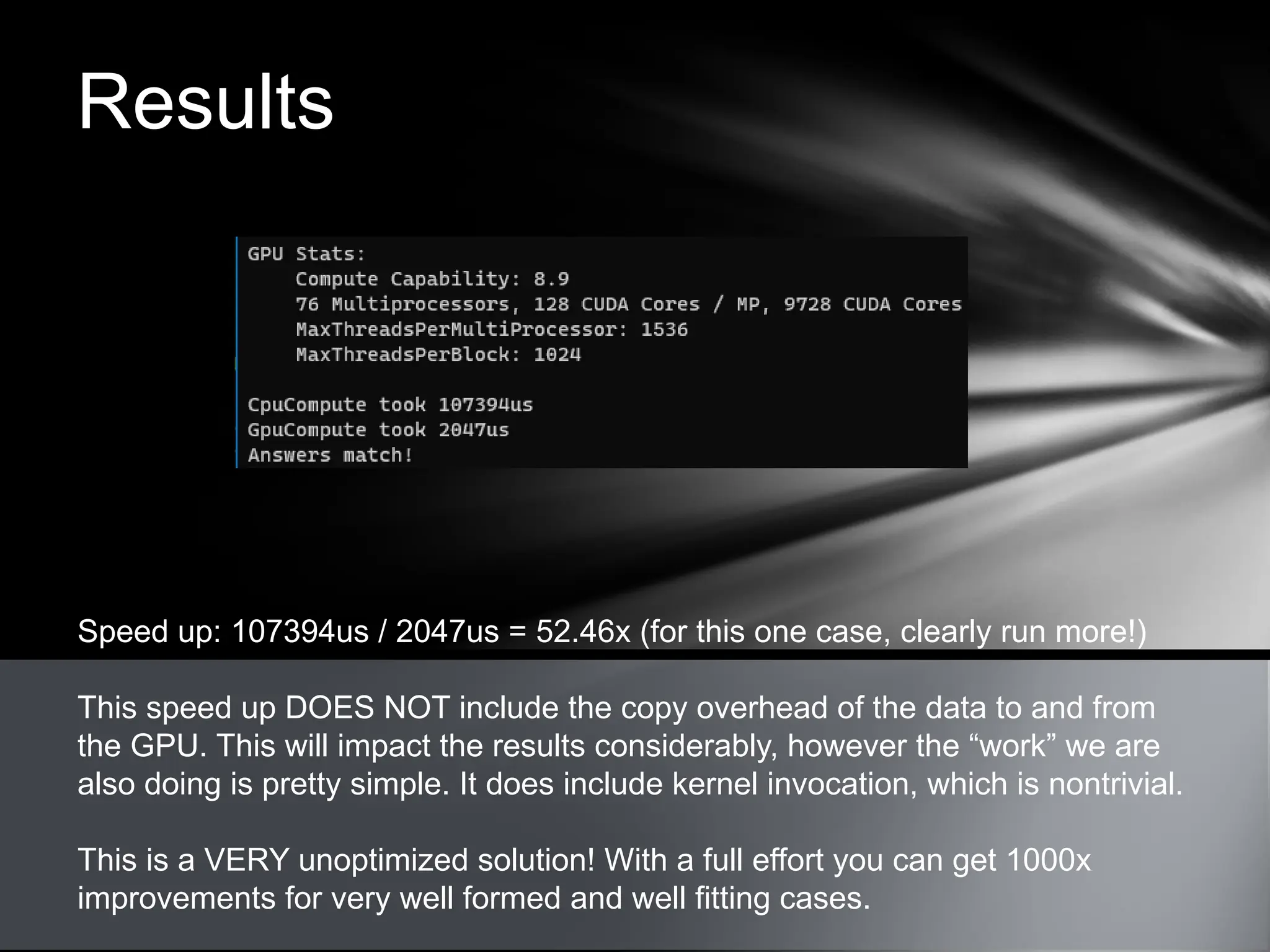
This document provides an overview of CUDA, NVIDIA's framework for developing applications on GPU hardware, emphasizing the benefits of using GPU for massively parallel processing. It outlines the architecture of GPUs compared to CPUs, explains the setup required for CUDA, and presents a simple example of computing the hypotenuse of triangles using both CPU and GPU implementations. The document also touches on kernel execution, debugging techniques, and additional resources for further learning in CUDA development.