















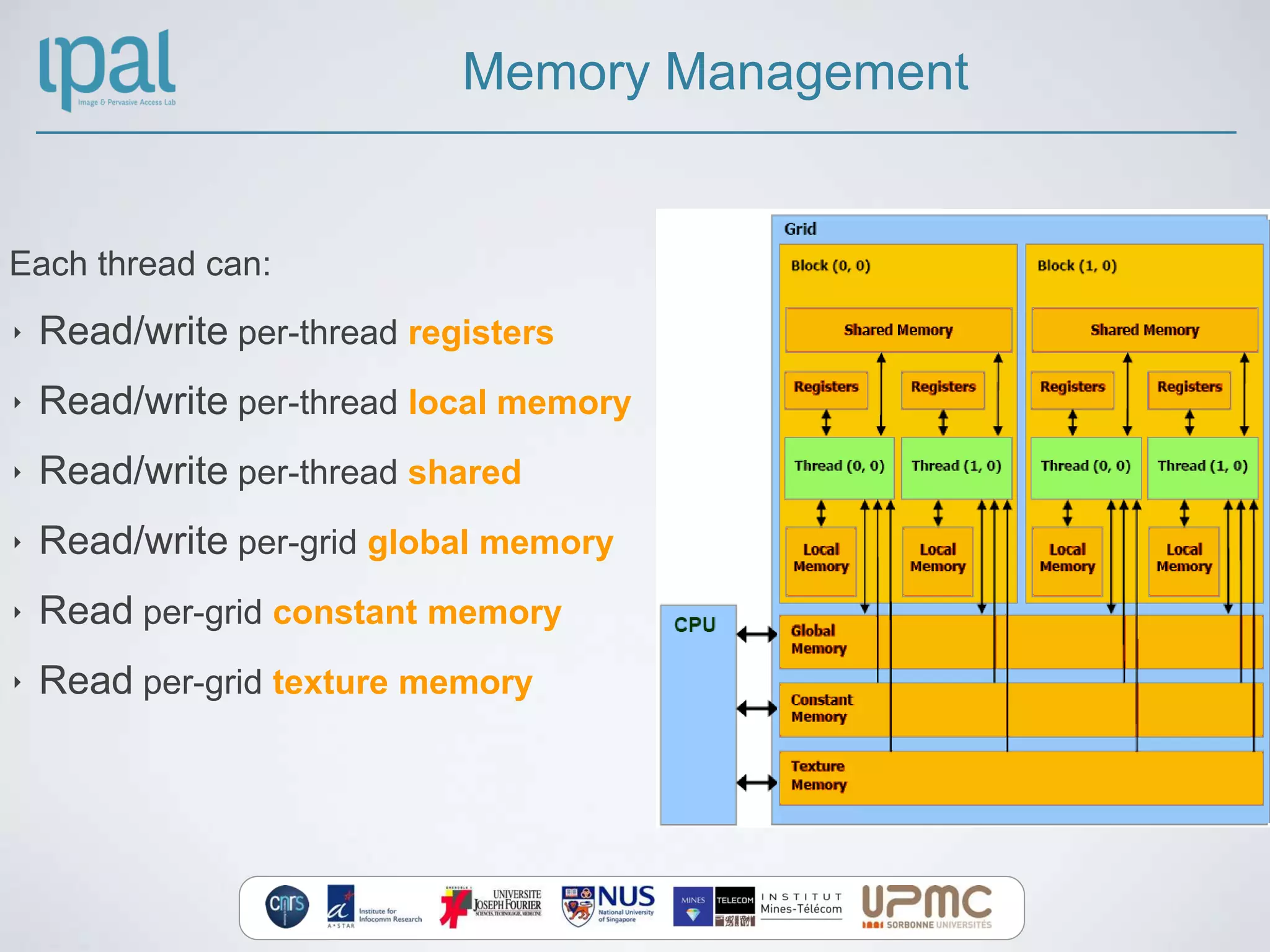





![Shared Memory
‣ [16-64] KB of memory per block
‣ Extremely fast on-chip memory,
user managed
‣ Declare using __shared__,
allocated per block
‣ Data is not visible to threads in
other blocks
‣ !!!Bank Conflict!!!
‣ When to use? When threads will
access many times the global
memory](https://image.slidesharecdn.com/cudapresentation-130514205547-phpapp02/75/C-for-Cuda-Small-Introduction-to-GPU-computing-24-2048.jpg)

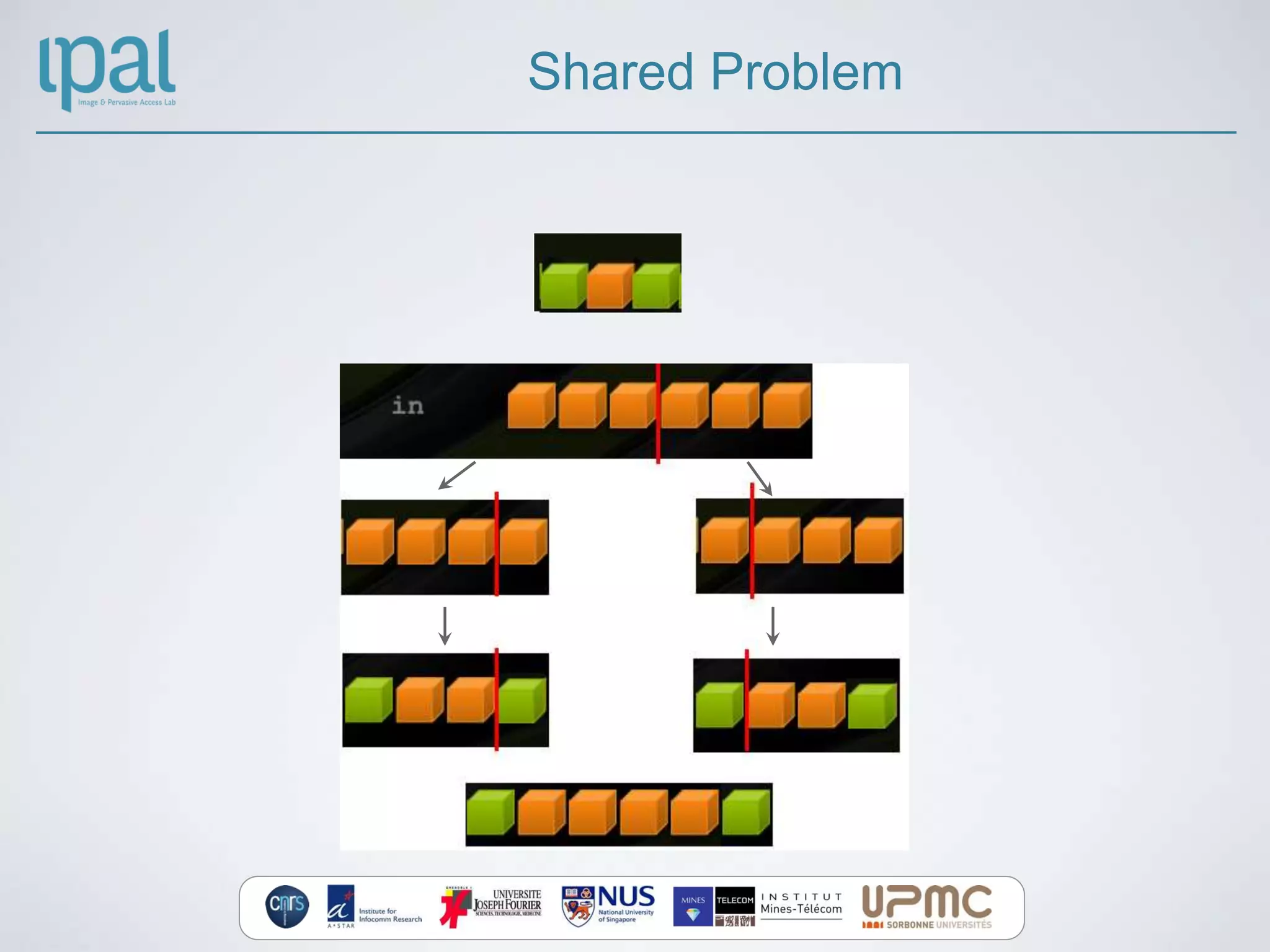
![Shared Memory - Example
__global__ void stencil_1d(int *in, int *out)
{
__shared__ int temp[BLOCK_SIZE];
int lindex = threadIdx.x ;
// Read input elements into shared memory
temp[lindex] = in[lindex];
if (lindex > RADIUS && lindex < BLOCK_SIZE-RADIUS);
{
for (...) //Loop for calculating the sum
out[lindex] = res;
}
}
??
__syncthreads()](https://image.slidesharecdn.com/cudapresentation-130514205547-phpapp02/75/C-for-Cuda-Small-Introduction-to-GPU-computing-26-2048.jpg)




























![Shared Memory
‣ [16-64] KB of memory per block
‣ Extremely fast on-chip memory,
user managed
‣ Declare using __shared__,
allocated per block
‣ Data is not visible to threads in
other blocks
‣ !!!Bank Conflict!!!
‣ When to use? When threads will
access many times the global
memory](https://crownmelresort.com/image.slidesharecdn.com/cudapresentation-130514205547-phpapp02/75/C-for-Cuda-Small-Introduction-to-GPU-computing-24-2048.jpg)

![Shared Memory - Example
__global__ void stencil_1d(int *in, int *out)
{
__shared__ int temp[BLOCK_SIZE];
int lindex = threadIdx.x ;
// Read input elements into shared memory
temp[lindex] = in[lindex];
if (lindex > RADIUS && lindex < BLOCK_SIZE-RADIUS);
{
for (...) //Loop for calculating the sum
out[lindex] = res;
}
}
??
__syncthreads()](https://crownmelresort.com/image.slidesharecdn.com/cudapresentation-130514205547-phpapp02/75/C-for-Cuda-Small-Introduction-to-GPU-computing-26-2048.jpg)








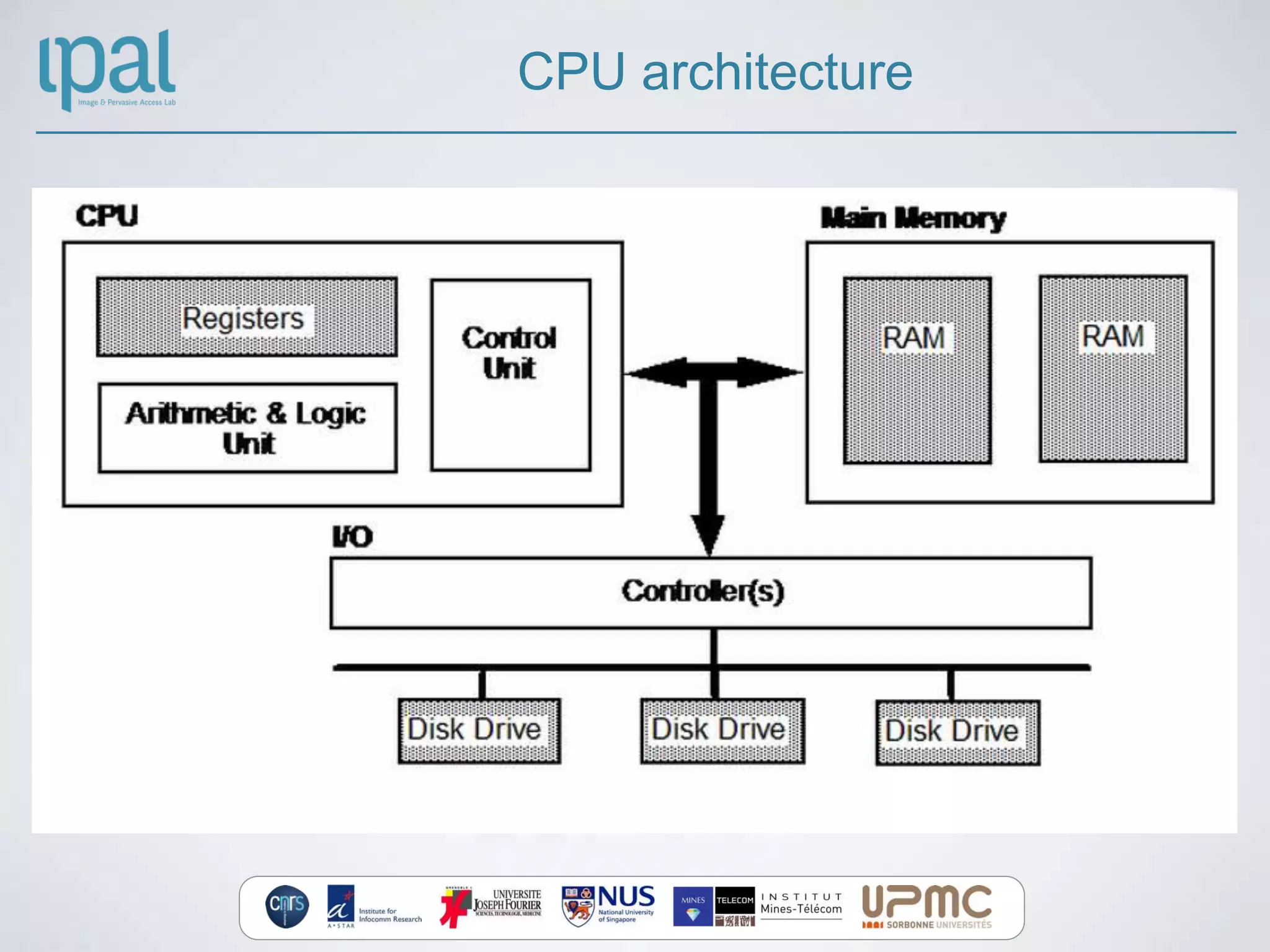
The document provides an introduction to GPU computing using CUDA, outlining the differences between CPUs and GPUs in terms of architecture, latency, and throughput. It discusses the software abstraction involving grids, blocks, and threads, as well as memory organization including global, constant, shared, and texture memory. The conclusion emphasizes the importance of understanding GPU design for effective parallel computing and resource management.

























































































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)




