Download to read offline






![Results
Dimensions (A,B,C)
CPU
time (s)
GPU
time (s)
Speedup
[400,800] , [400, 400], [400 , 800] 0.17 0.00109 155
[800,1600] , [800, 800], [800 , 1600] 2.10 0.00846 258
[1200,2400] , [1200, 1200], [2400 , 2400] 6.65 0.02860 232
[1600,2400] , [1600, 1600], [2400 , 2400] 15.18 0.06739 225
[2000,4000] , [4000, 4000], [4000 , 4000] 29.44 0.13178 223
[2400,4800] , [2400, 4800], [4800 , 4800] 50.21 0.22703 221
11](https://image.slidesharecdn.com/04-introductiontoaccelerators-240108063623-96c62fe2/75/Introduction-to-Accelerators-11-2048.jpg)







![Example
#include "stdio.h"
#define N 10
__global__ void add(int *a, int *b, int *c)
{
int tID = blockIdx.x;
if (tID < N)
{
c[tID] = a[tID] + b[tID];
}
}
int main()
{
int a[N], b[N], c[N];
int *dev_a, *dev_b, *dev_c;
cudaMalloc((void **) &dev_a, N*sizeof(int));
cudaMalloc((void **) &dev_b, N*sizeof(int));
cudaMalloc((void **) &dev_c, N*sizeof(int));
for (int i = 0; i < N; i++)
a[i] = i, b[i] = 1;
cudaMemcpy(dev_a, a, N*sizeof(int),
cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, N*sizeof(int),
cudaMemcpyHostToDevice);
add<<<N,1>>>(dev_a, dev_b, dev_c);
cudaMemcpy(c, dev_c, N*sizeof(int),
cudaMemcpyDeviceToHost);
for (int i = 0; i < N; i++)
printf("%d + %d = %dn", a[i], b[i], c[i]);
return 0;
}
27](https://image.slidesharecdn.com/04-introductiontoaccelerators-240108063623-96c62fe2/75/Introduction-to-Accelerators-27-2048.jpg)












![Results
Dimensions (A,B,C)
CPU
time (s)
GPU
time (s)
Speedup
[400,800] , [400, 400], [400 , 800] 0.17 0.00109 155
[800,1600] , [800, 800], [800 , 1600] 2.10 0.00846 258
[1200,2400] , [1200, 1200], [2400 , 2400] 6.65 0.02860 232
[1600,2400] , [1600, 1600], [2400 , 2400] 15.18 0.06739 225
[2000,4000] , [4000, 4000], [4000 , 4000] 29.44 0.13178 223
[2400,4800] , [2400, 4800], [4800 , 4800] 50.21 0.22703 221
11](https://crownmelresort.com/image.slidesharecdn.com/04-introductiontoaccelerators-240108063623-96c62fe2/75/Introduction-to-Accelerators-11-2048.jpg)















![Example
#include "stdio.h"
#define N 10
__global__ void add(int *a, int *b, int *c)
{
int tID = blockIdx.x;
if (tID < N)
{
c[tID] = a[tID] + b[tID];
}
}
int main()
{
int a[N], b[N], c[N];
int *dev_a, *dev_b, *dev_c;
cudaMalloc((void **) &dev_a, N*sizeof(int));
cudaMalloc((void **) &dev_b, N*sizeof(int));
cudaMalloc((void **) &dev_c, N*sizeof(int));
for (int i = 0; i < N; i++)
a[i] = i, b[i] = 1;
cudaMemcpy(dev_a, a, N*sizeof(int),
cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, N*sizeof(int),
cudaMemcpyHostToDevice);
add<<<N,1>>>(dev_a, dev_b, dev_c);
cudaMemcpy(c, dev_c, N*sizeof(int),
cudaMemcpyDeviceToHost);
for (int i = 0; i < N; i++)
printf("%d + %d = %dn", a[i], b[i], c[i]);
return 0;
}
27](https://crownmelresort.com/image.slidesharecdn.com/04-introductiontoaccelerators-240108063623-96c62fe2/75/Introduction-to-Accelerators-27-2048.jpg)





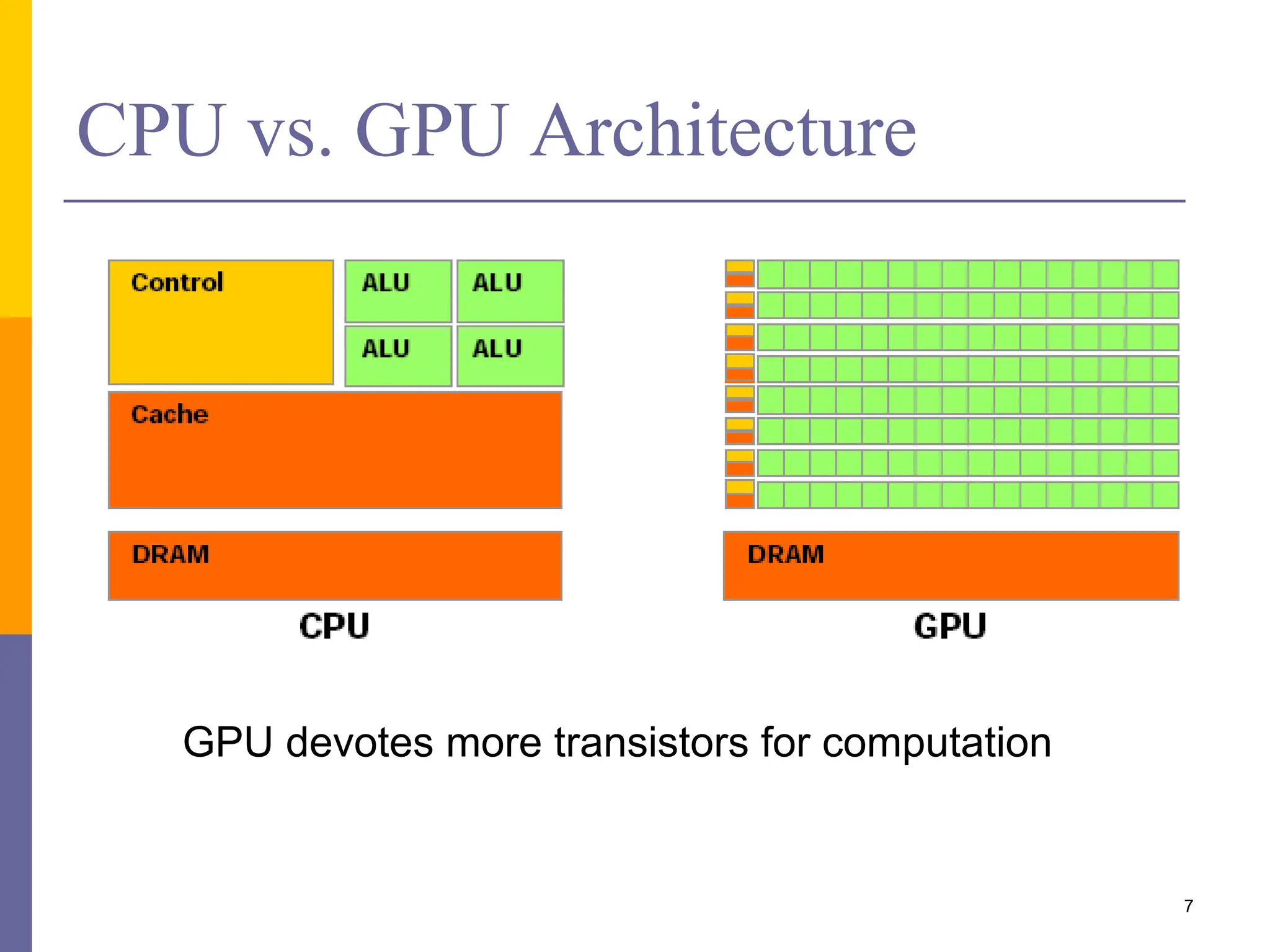
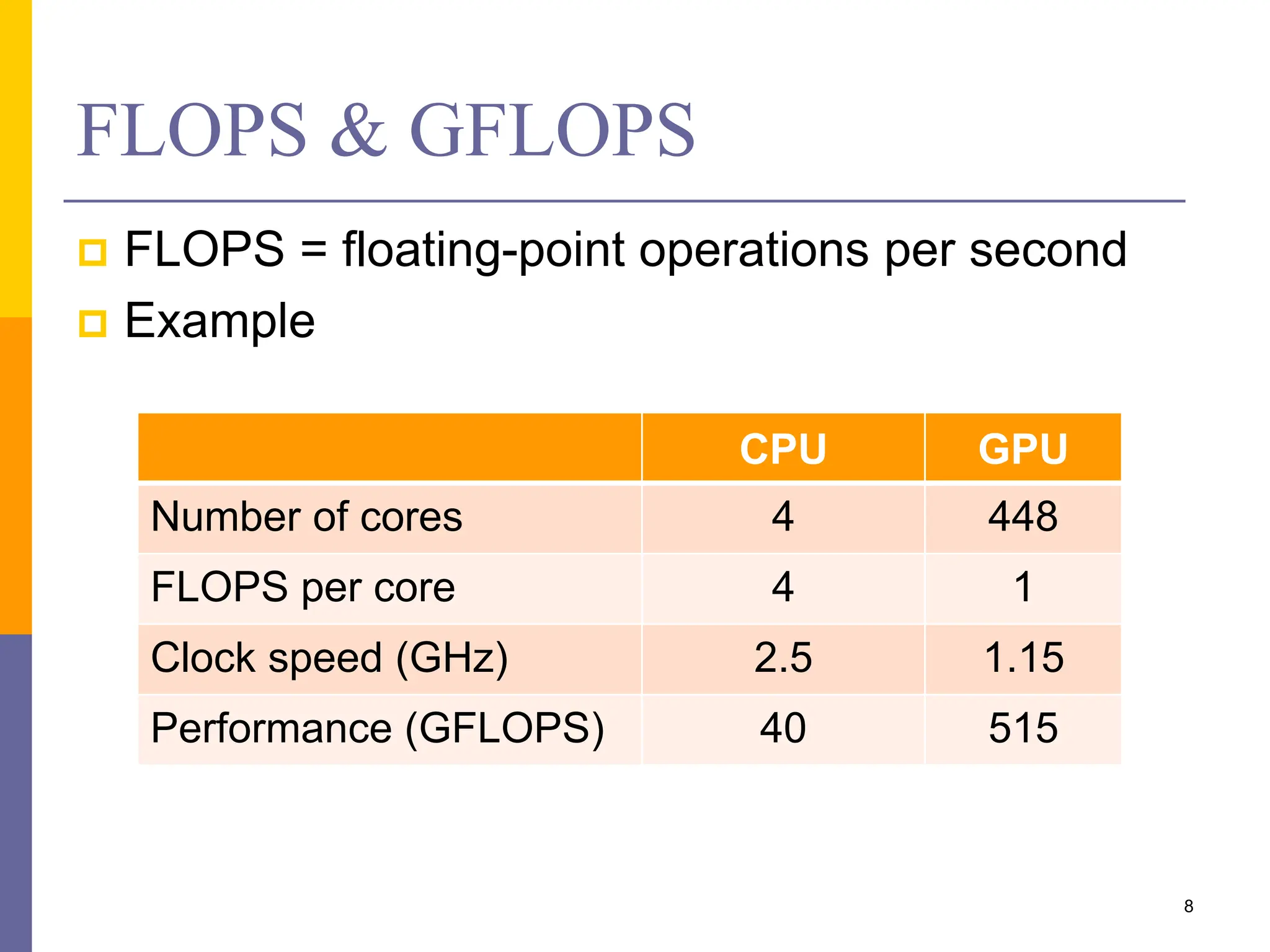
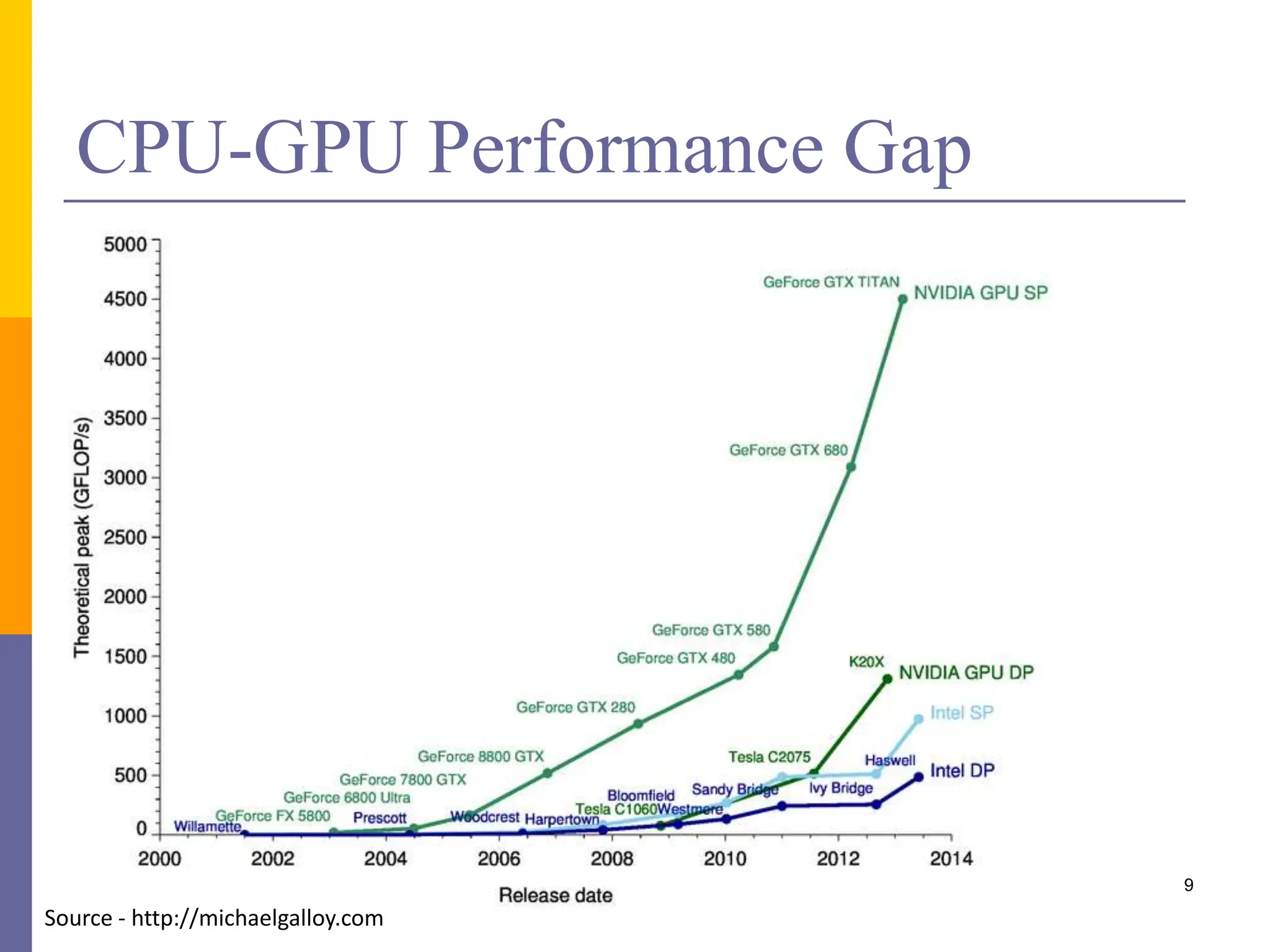
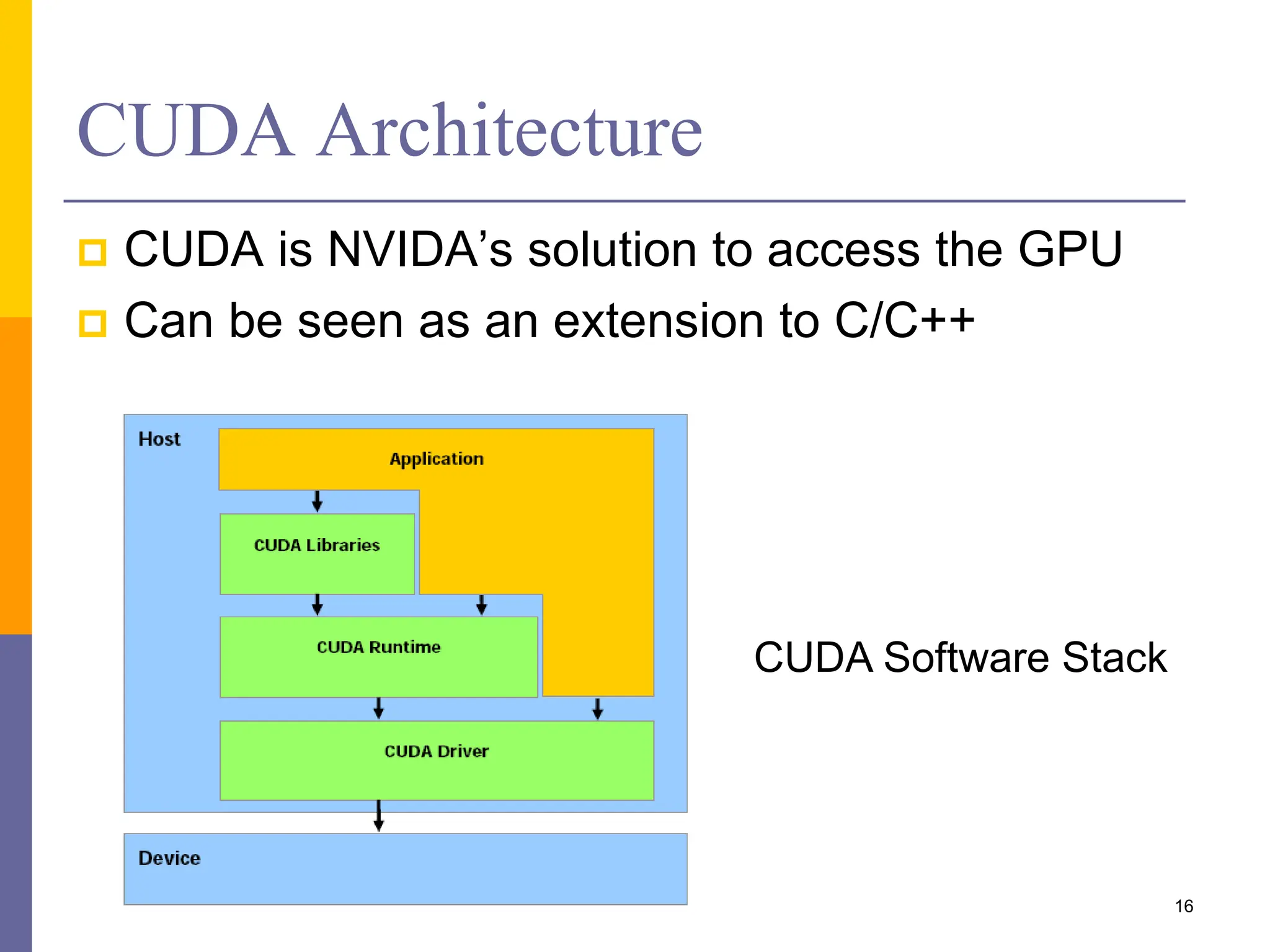
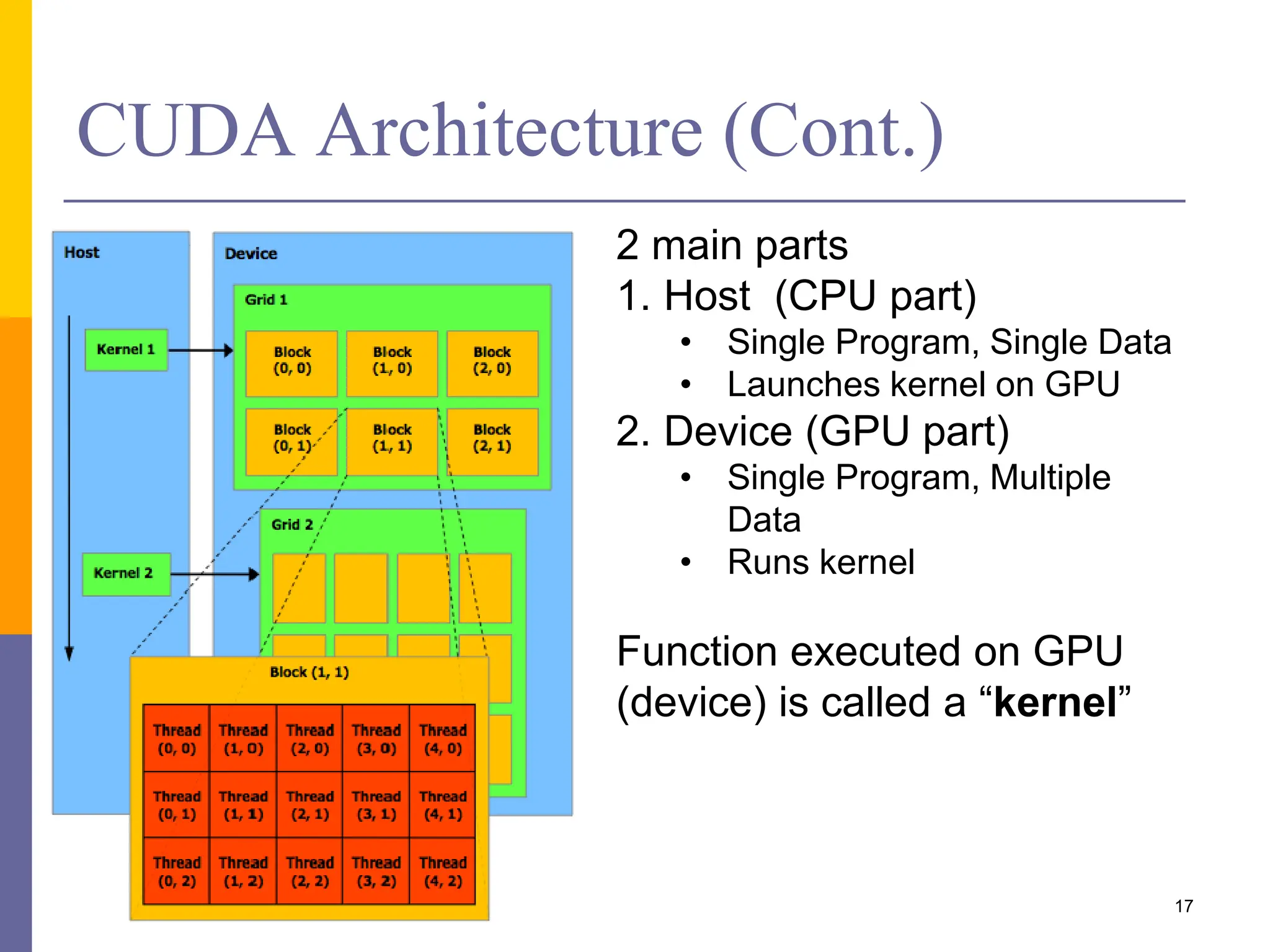
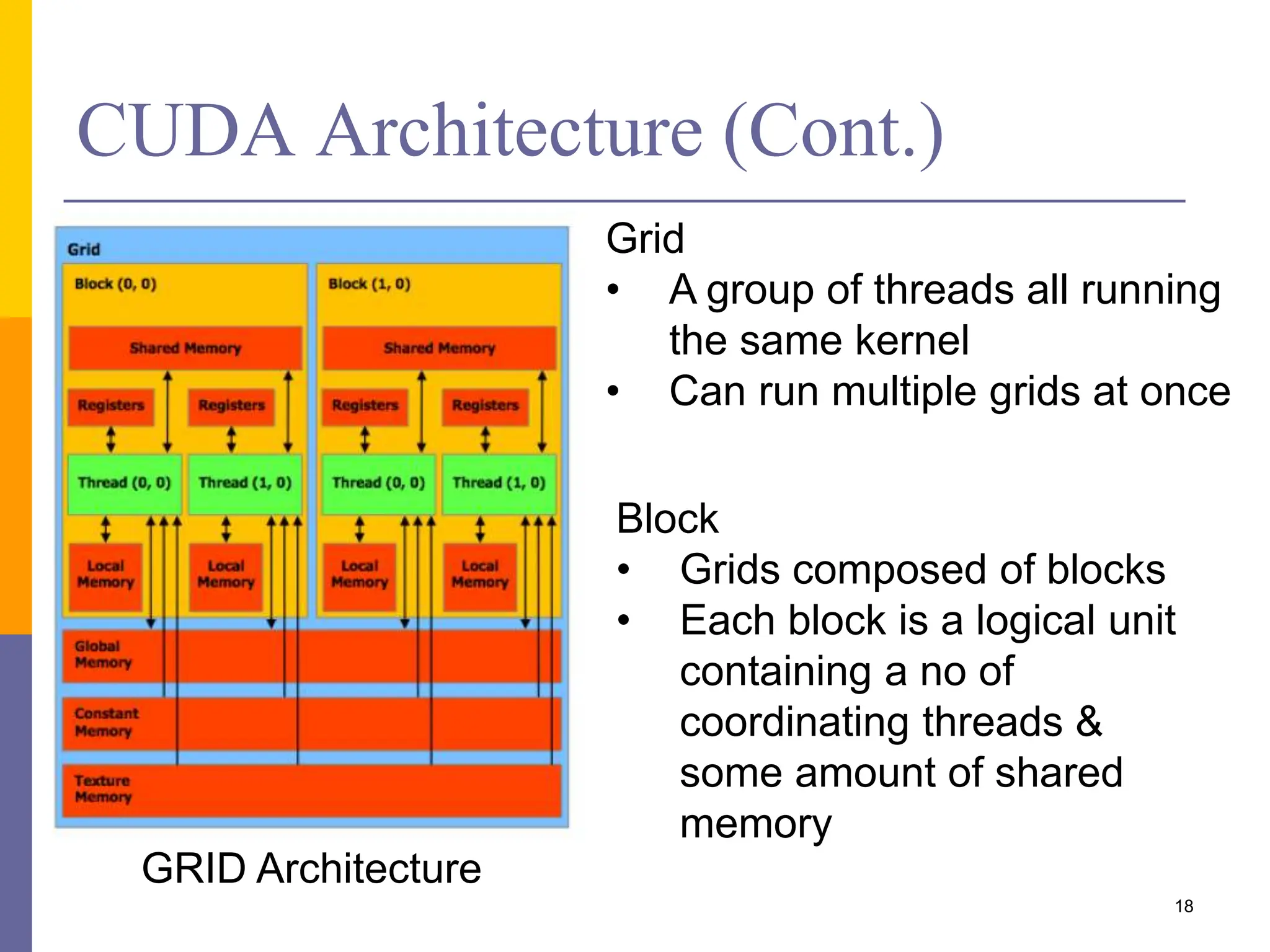
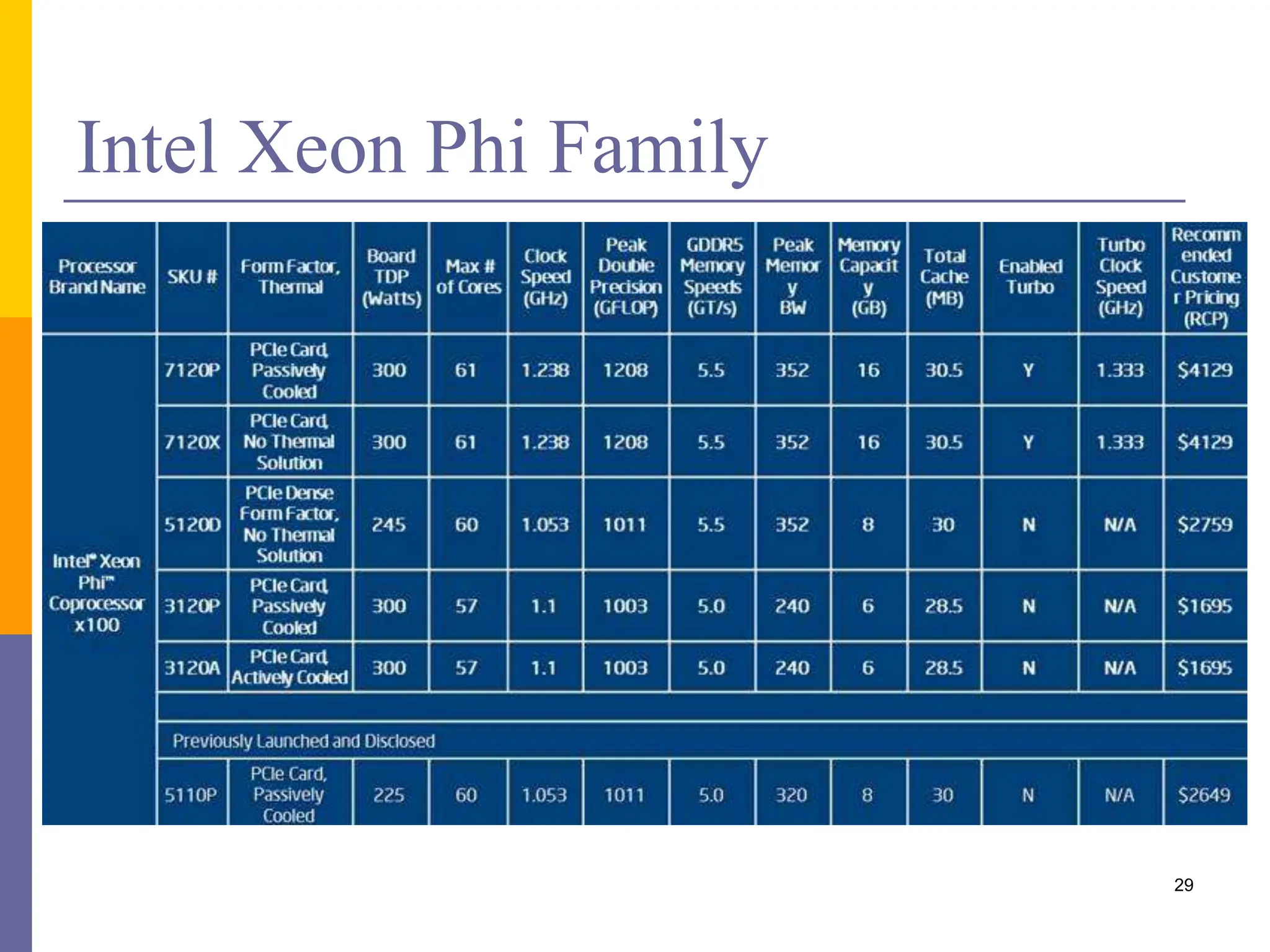
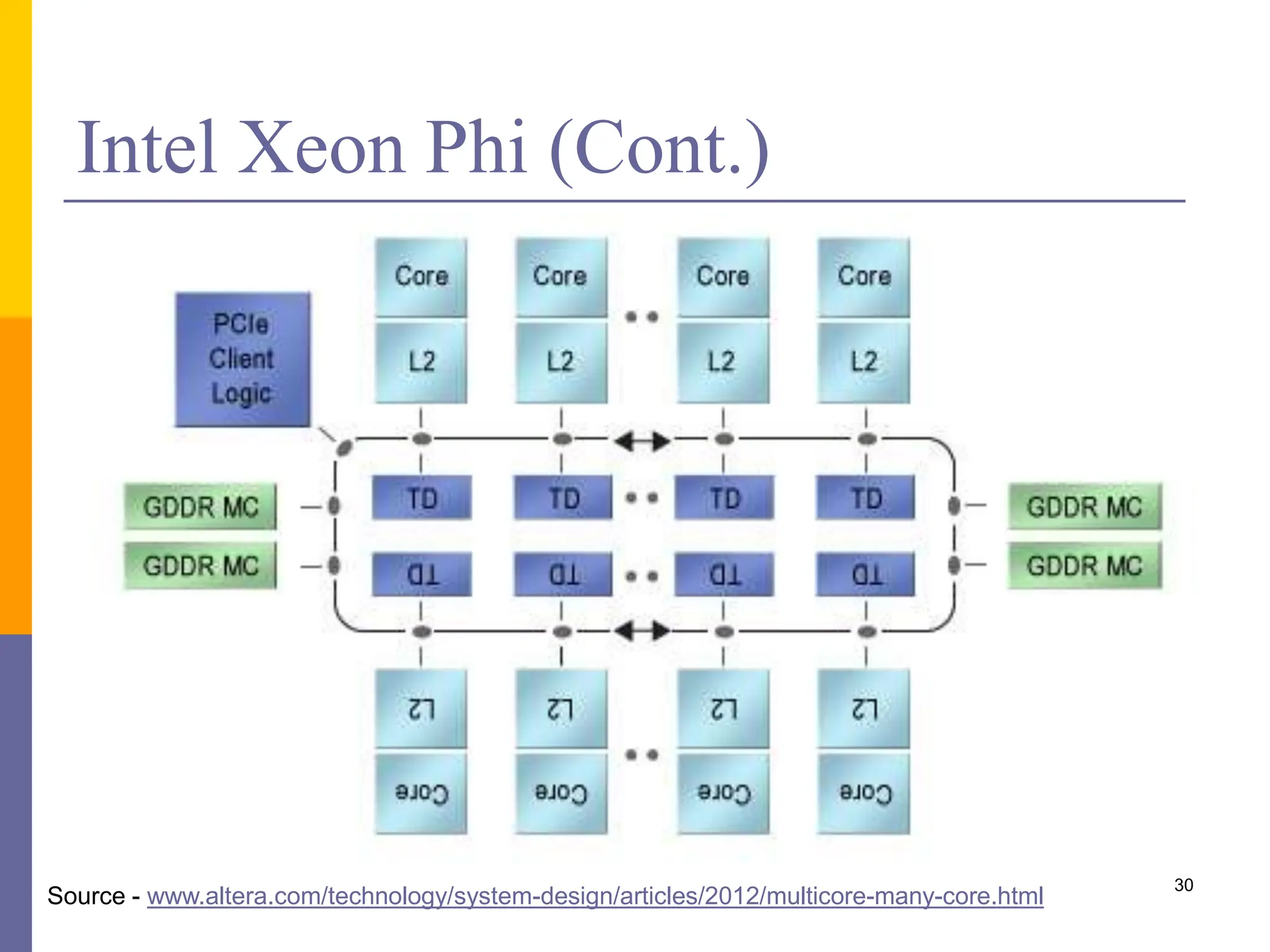
This document provides an introduction to accelerators such as GPUs and Intel Xeon Phi. It discusses the architecture and programming of GPUs using CUDA. GPUs are massively parallel many-core processors designed for graphics processing but now used for general purpose computing. They provide much higher floating point performance than CPUs. The document outlines GPU memory architecture and programming using CUDA. It also provides an overview of Intel Xeon Phi which contains over 50 simple CPU cores for highly parallel workloads.


































































