Download to read offline










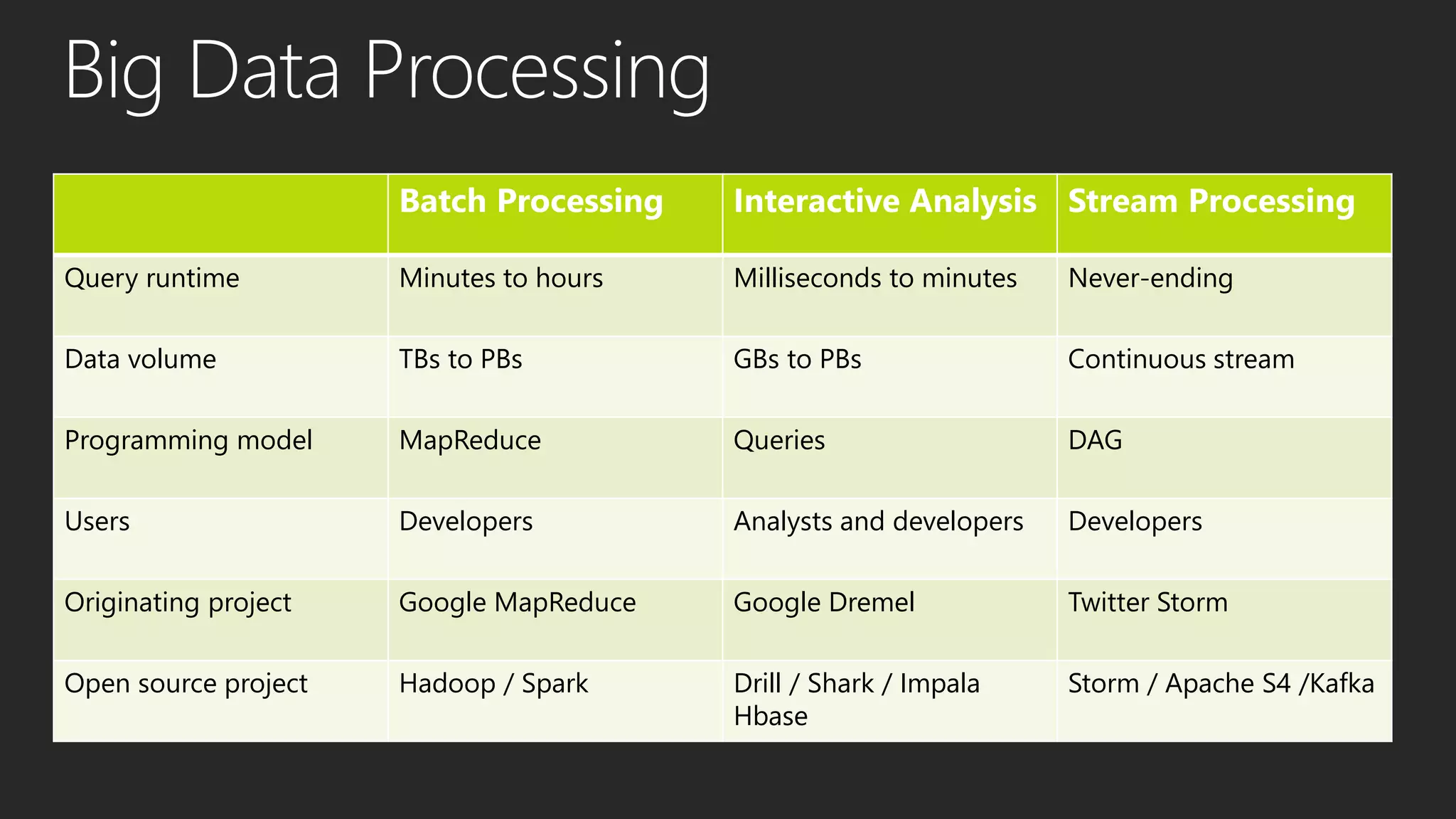





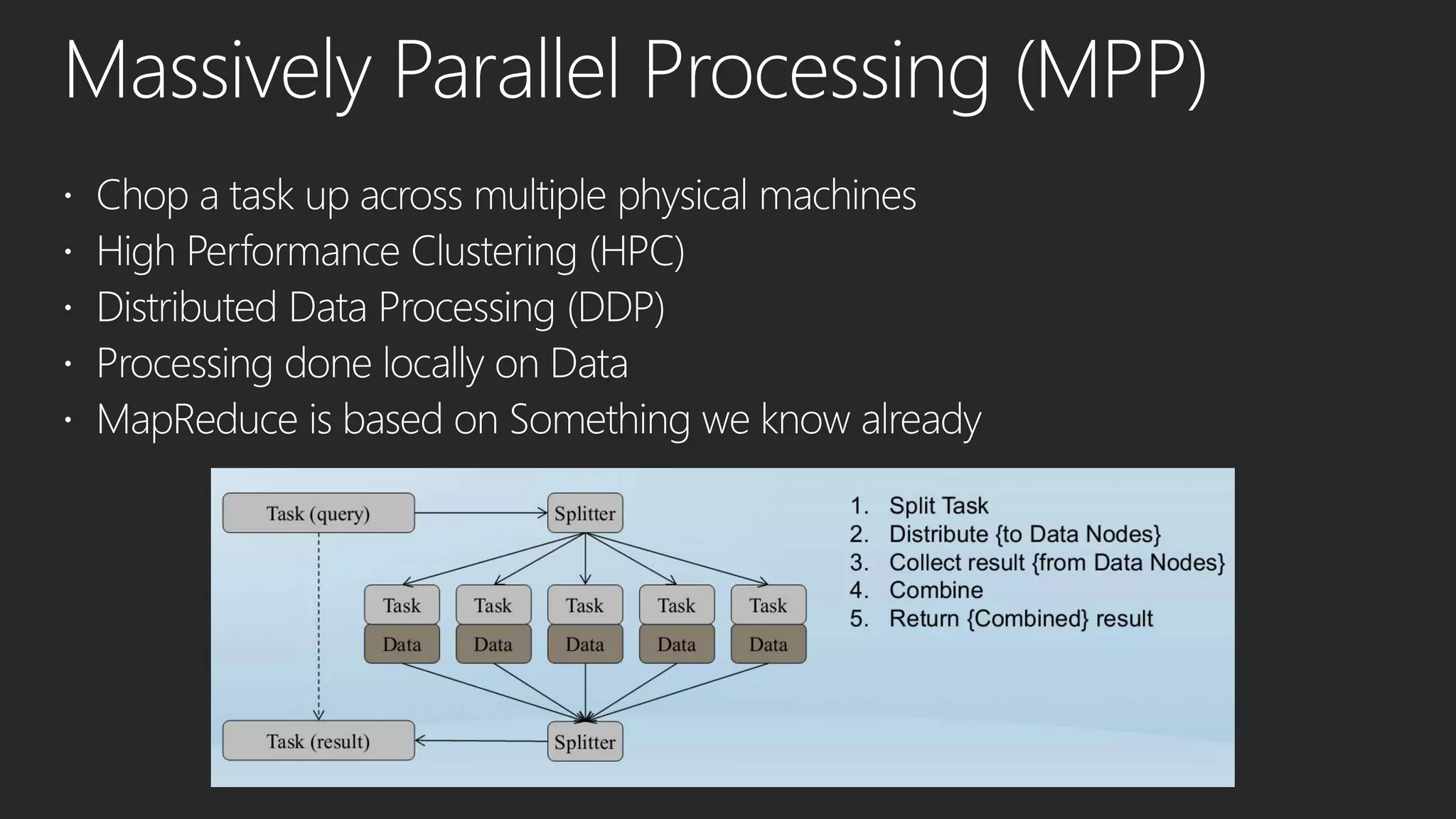


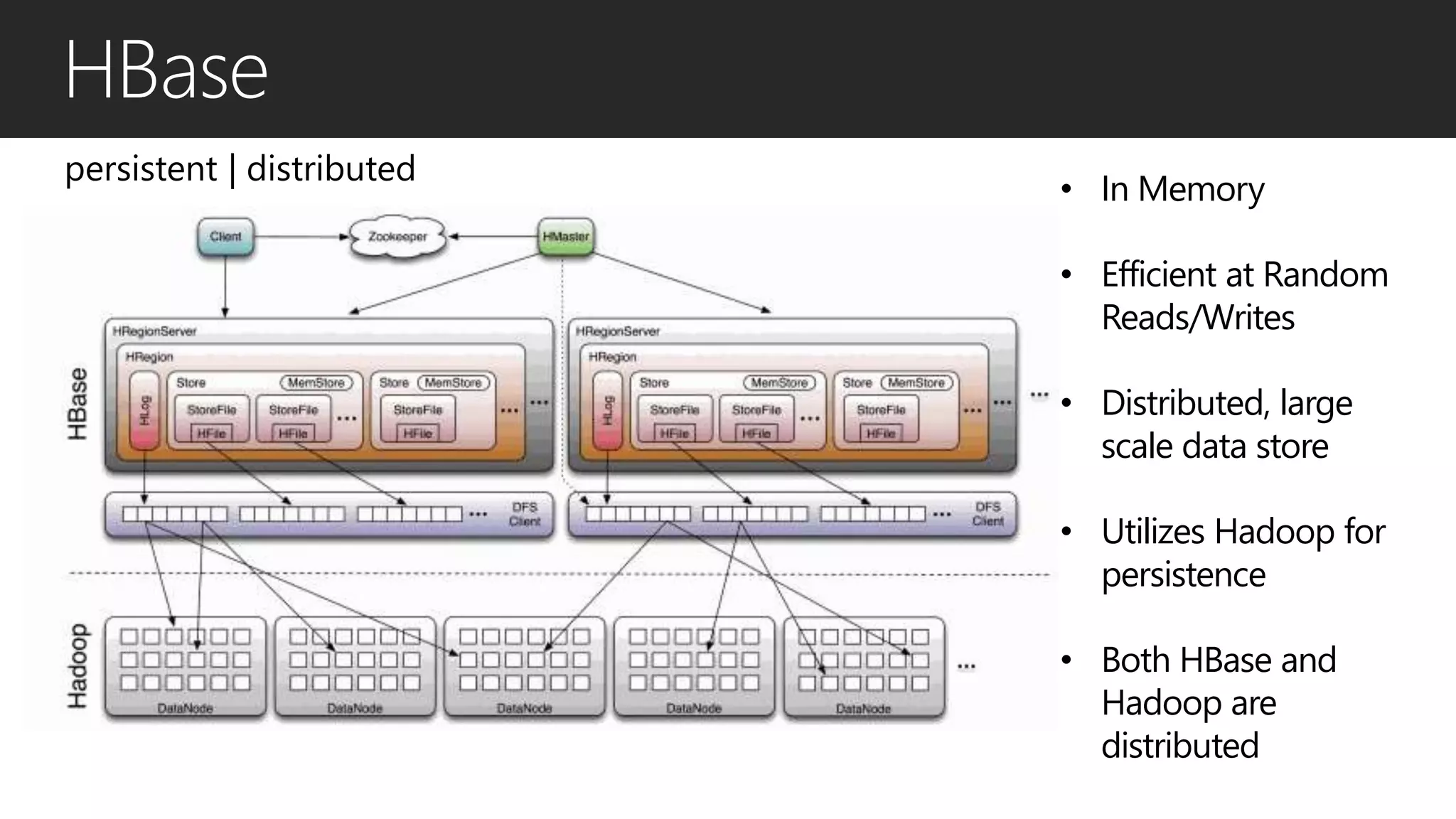









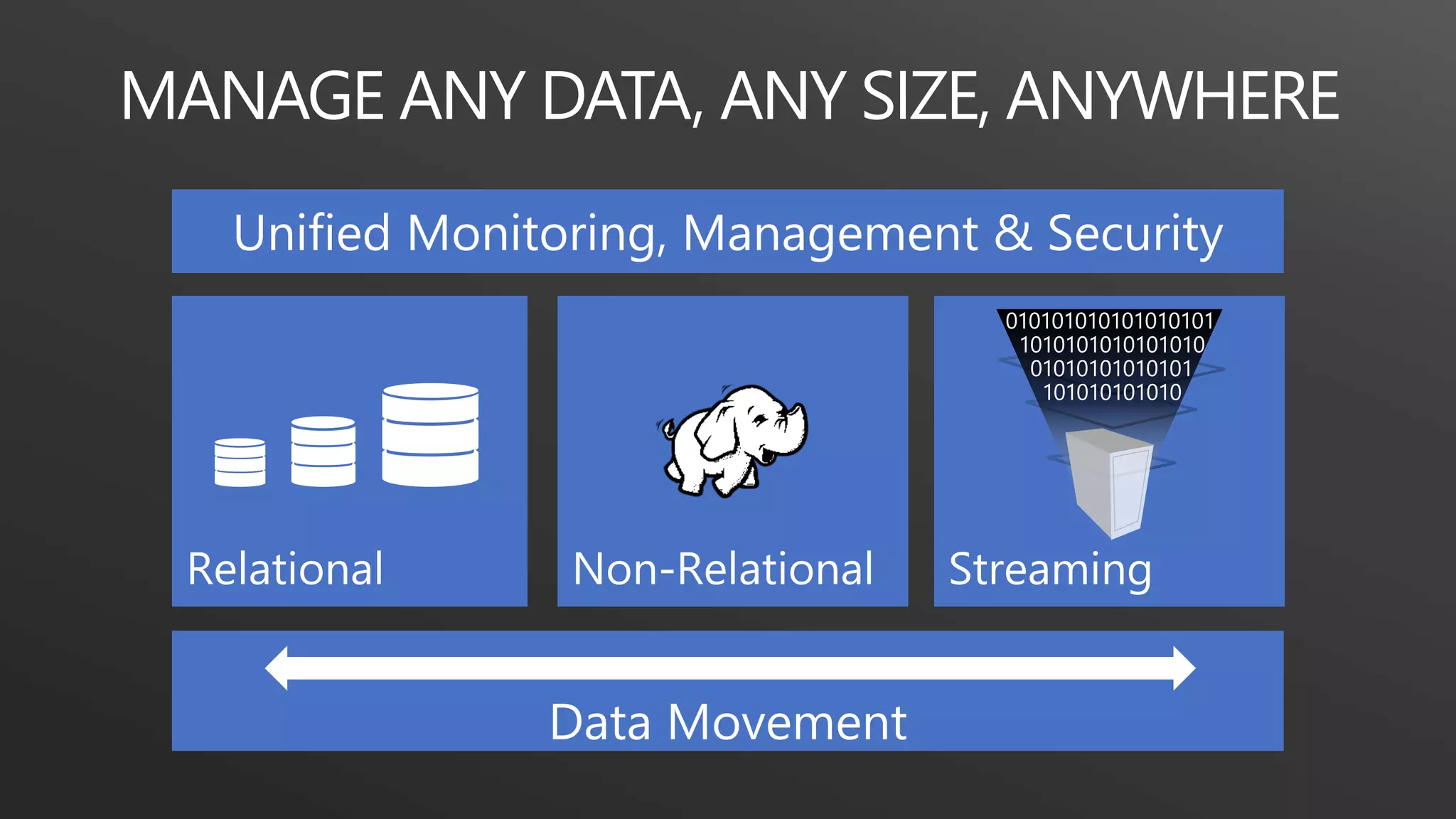

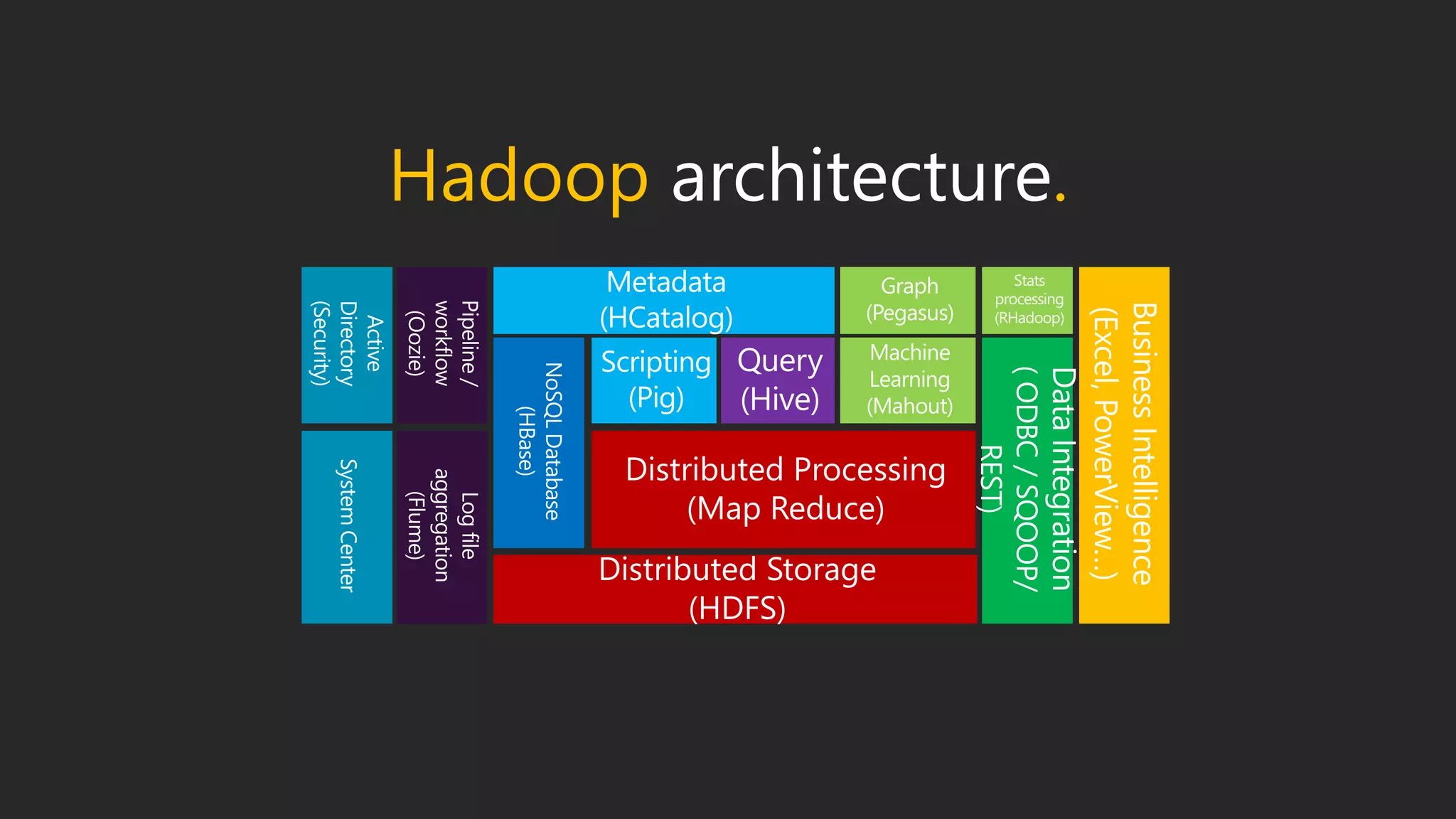
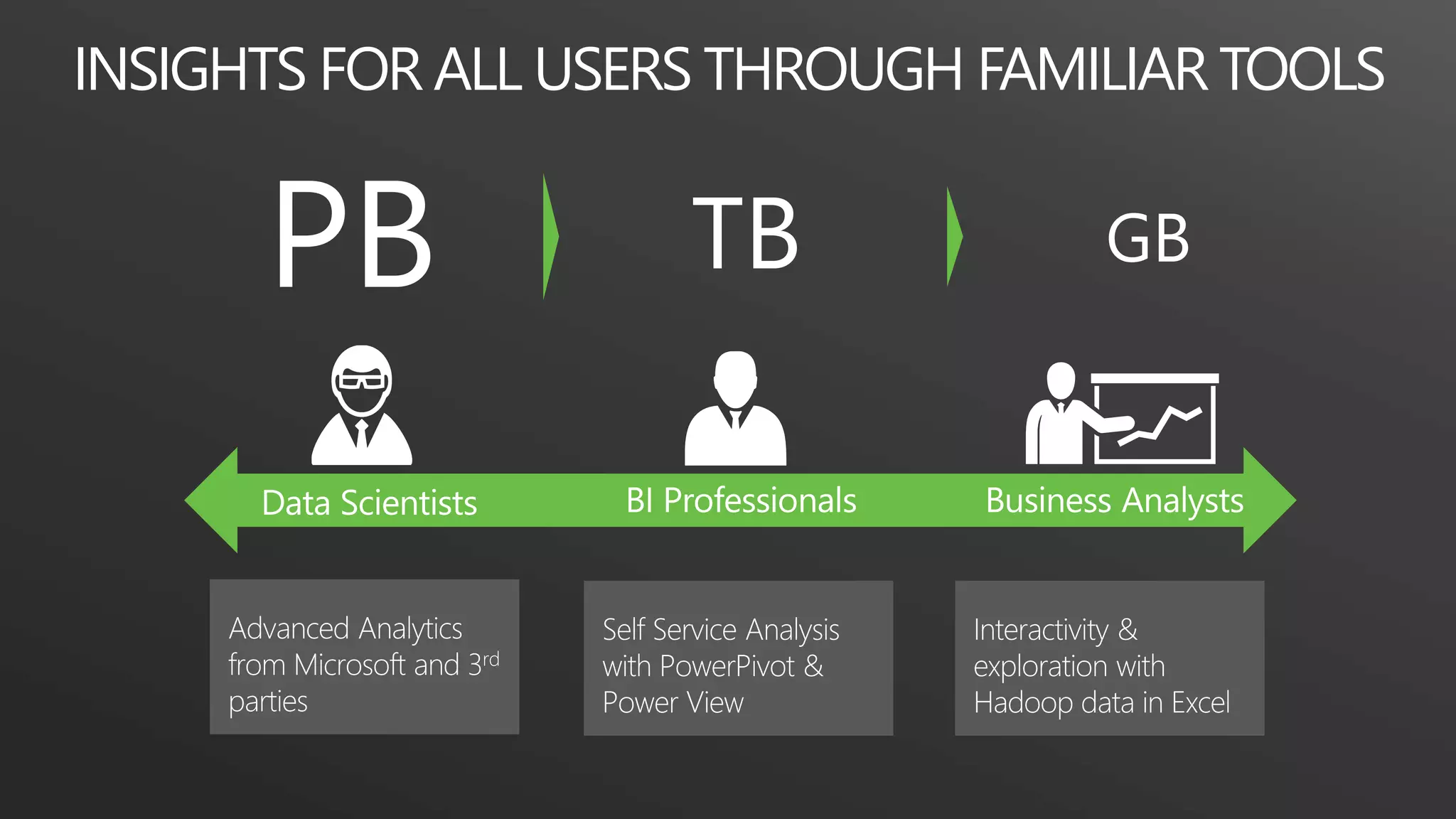

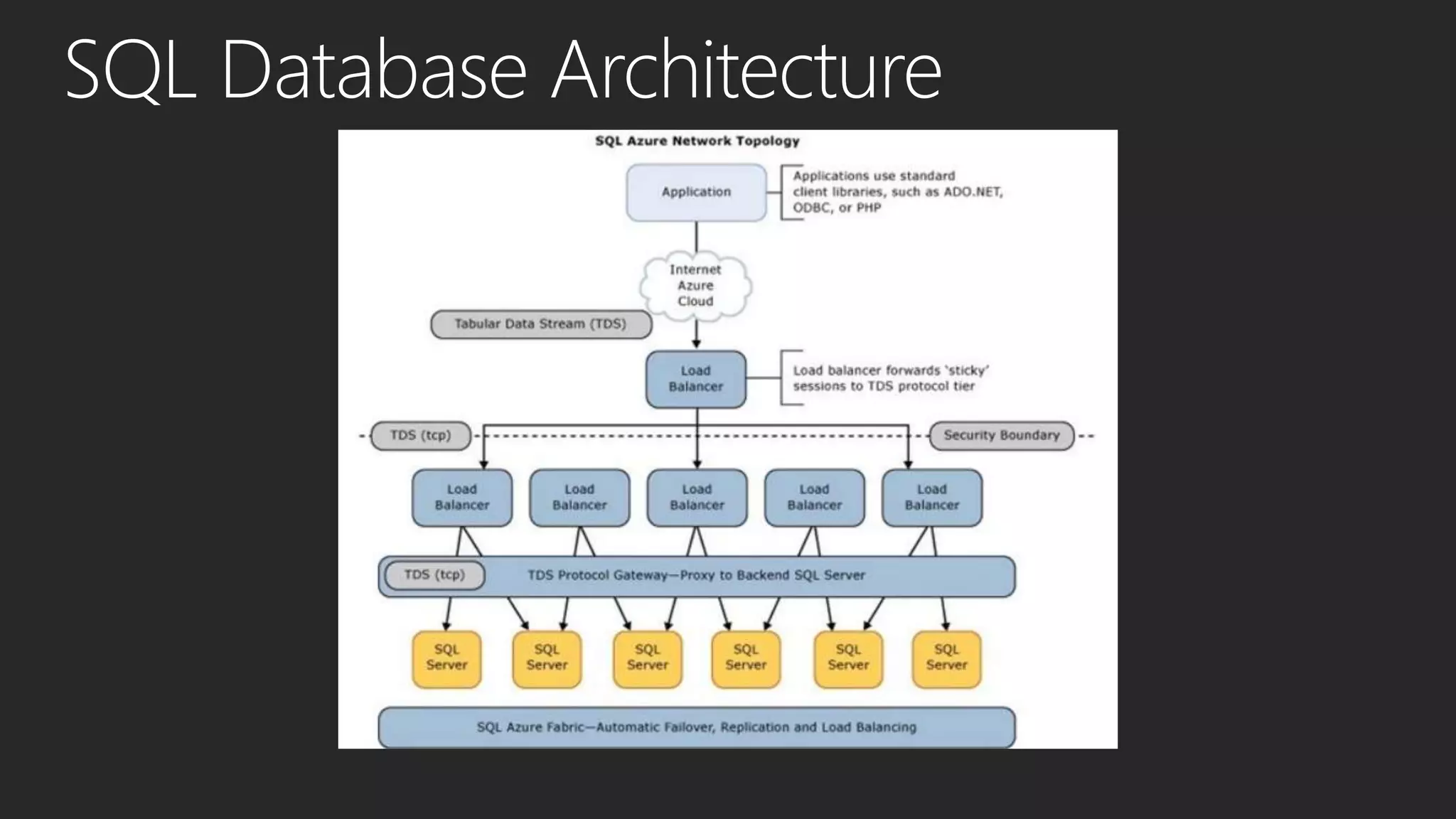
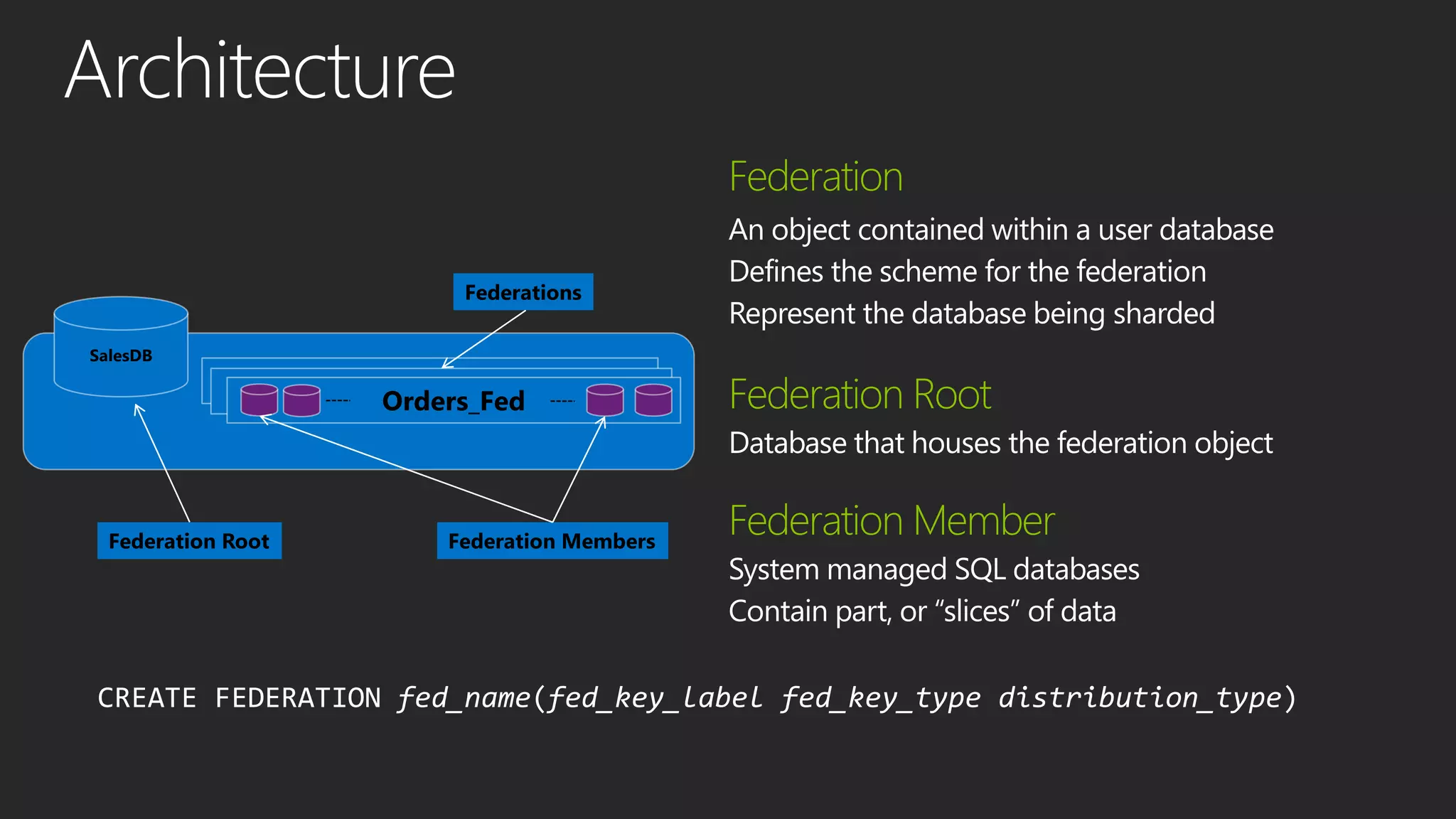







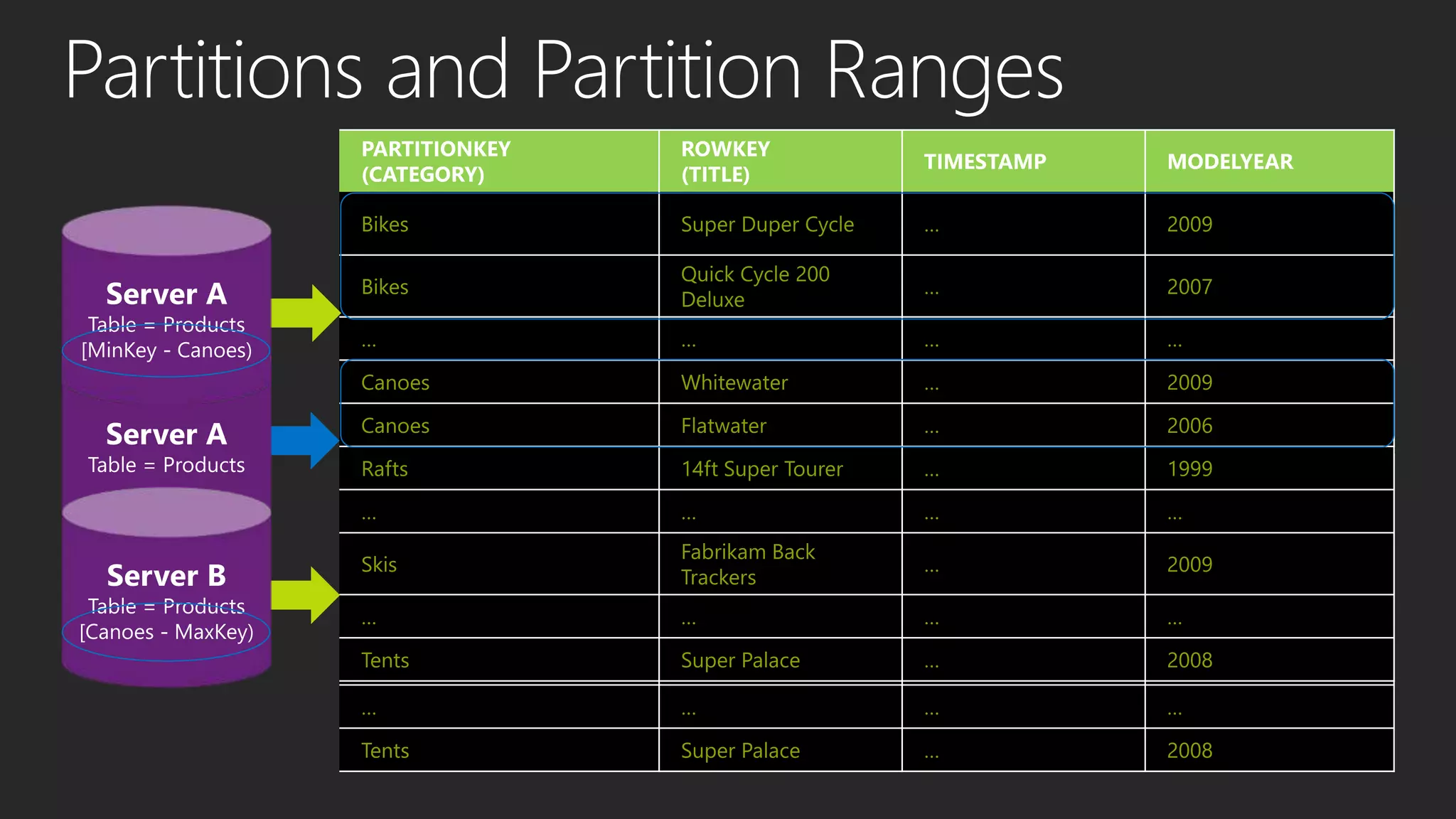

























































This document discusses different data processing models and their characteristics for structured and unstructured data at varying scales. It compares batch processing, interactive analysis, and stream processing in terms of query runtime, data volume handled, programming models, typical users, and examples of originating projects and open source implementations. It then provides examples of how organizations can gain competitive advantage by analyzing different types of data using these approaches.


































































