Downloaded 58 times











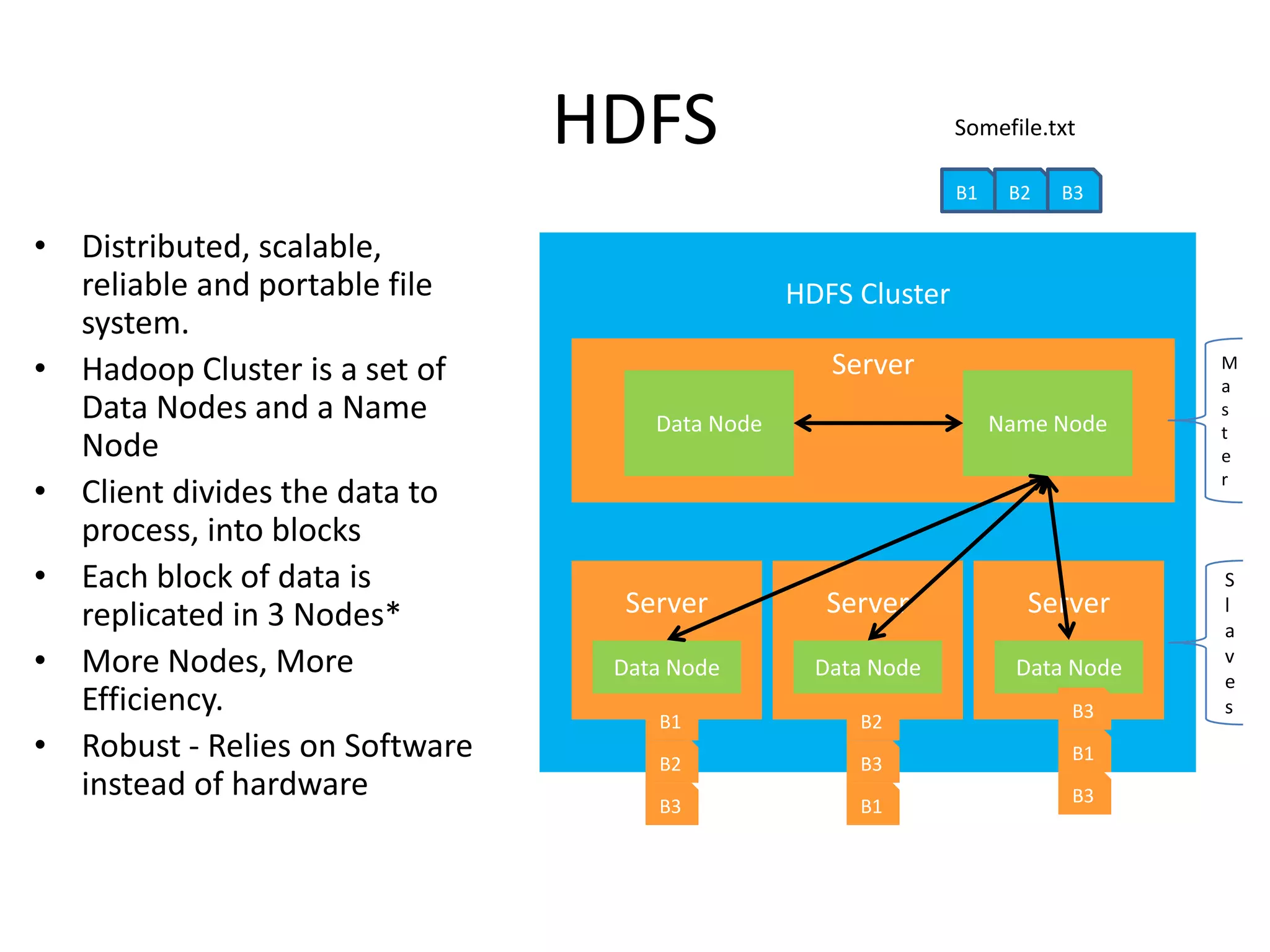
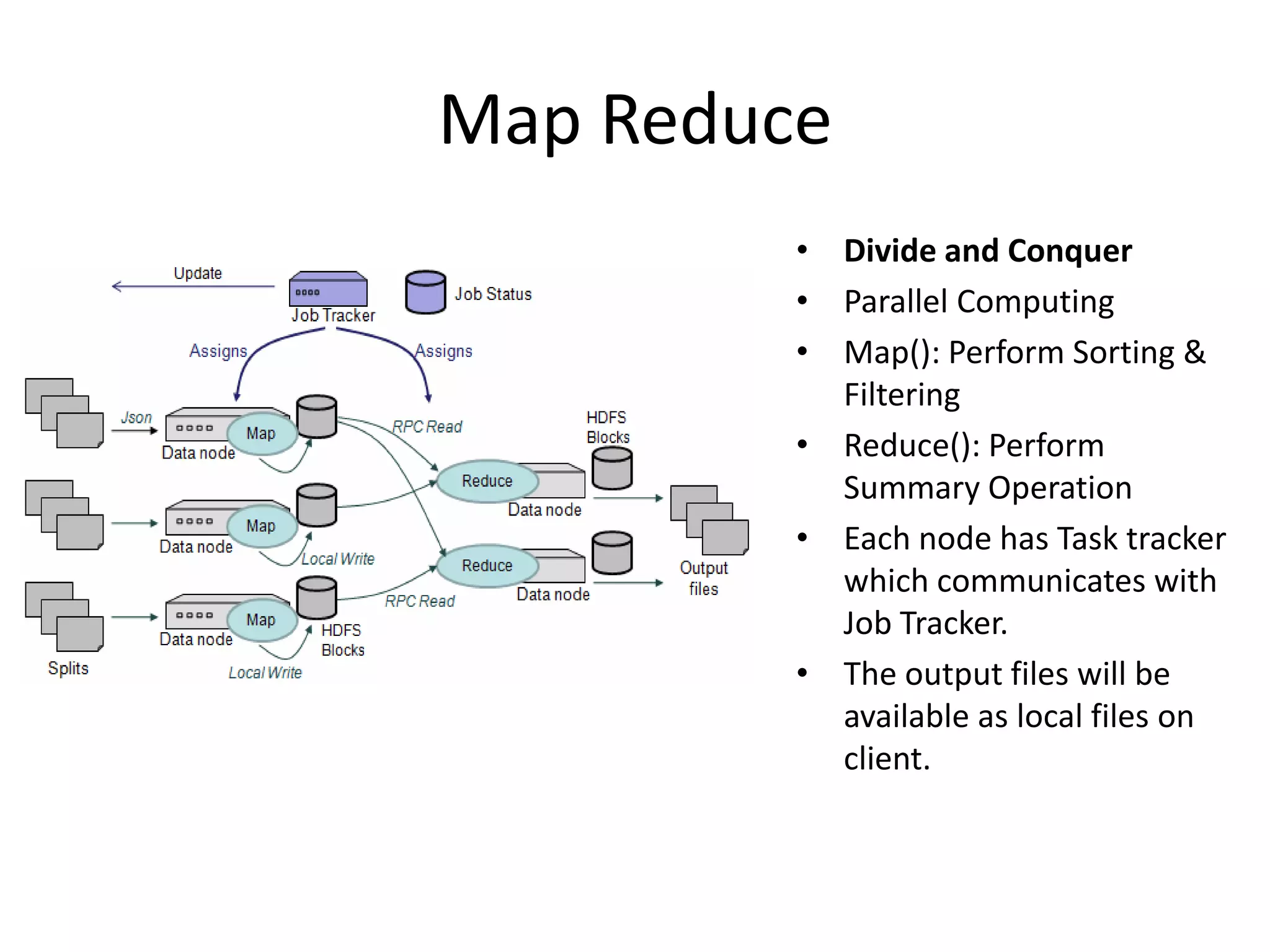
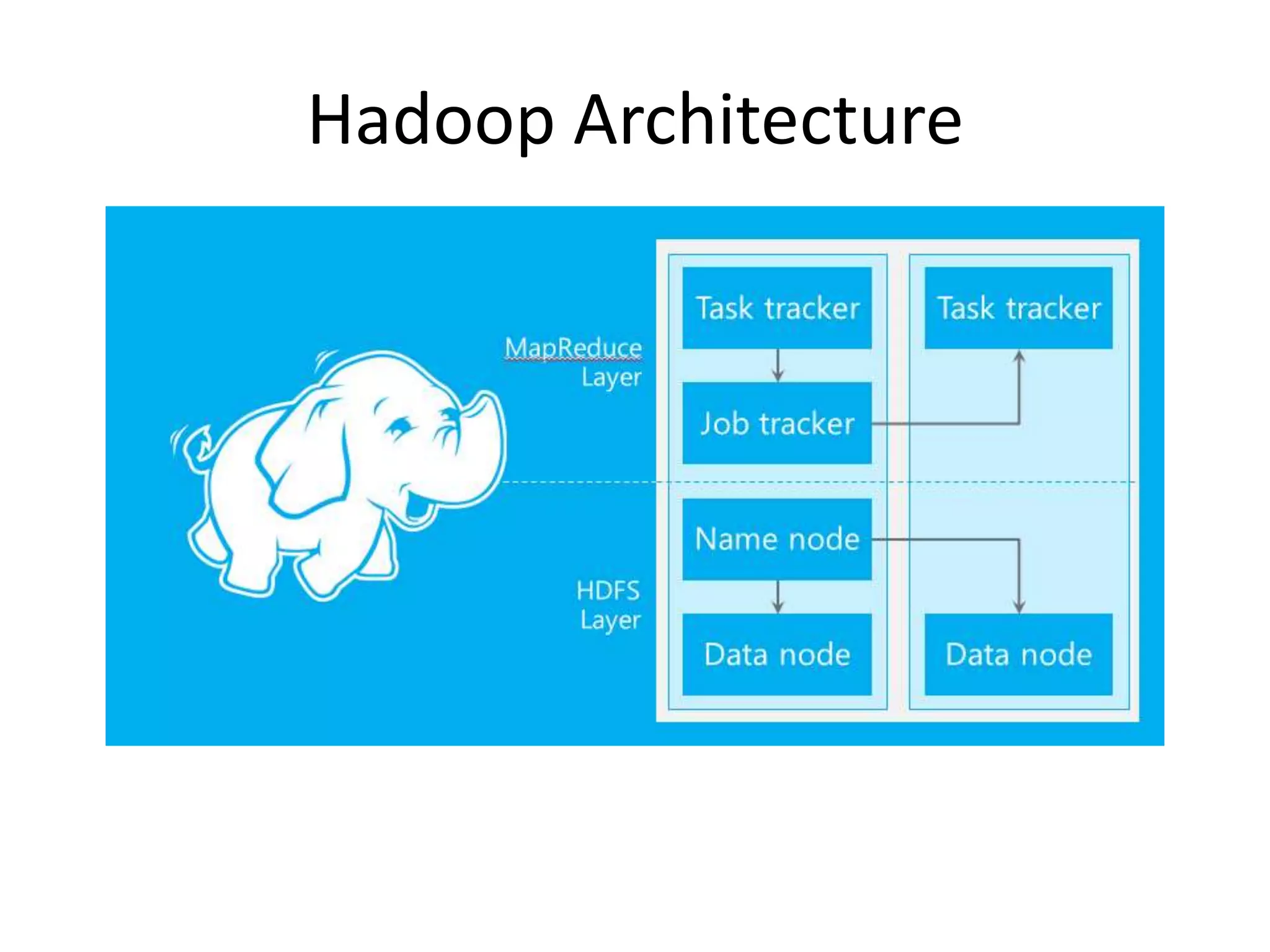

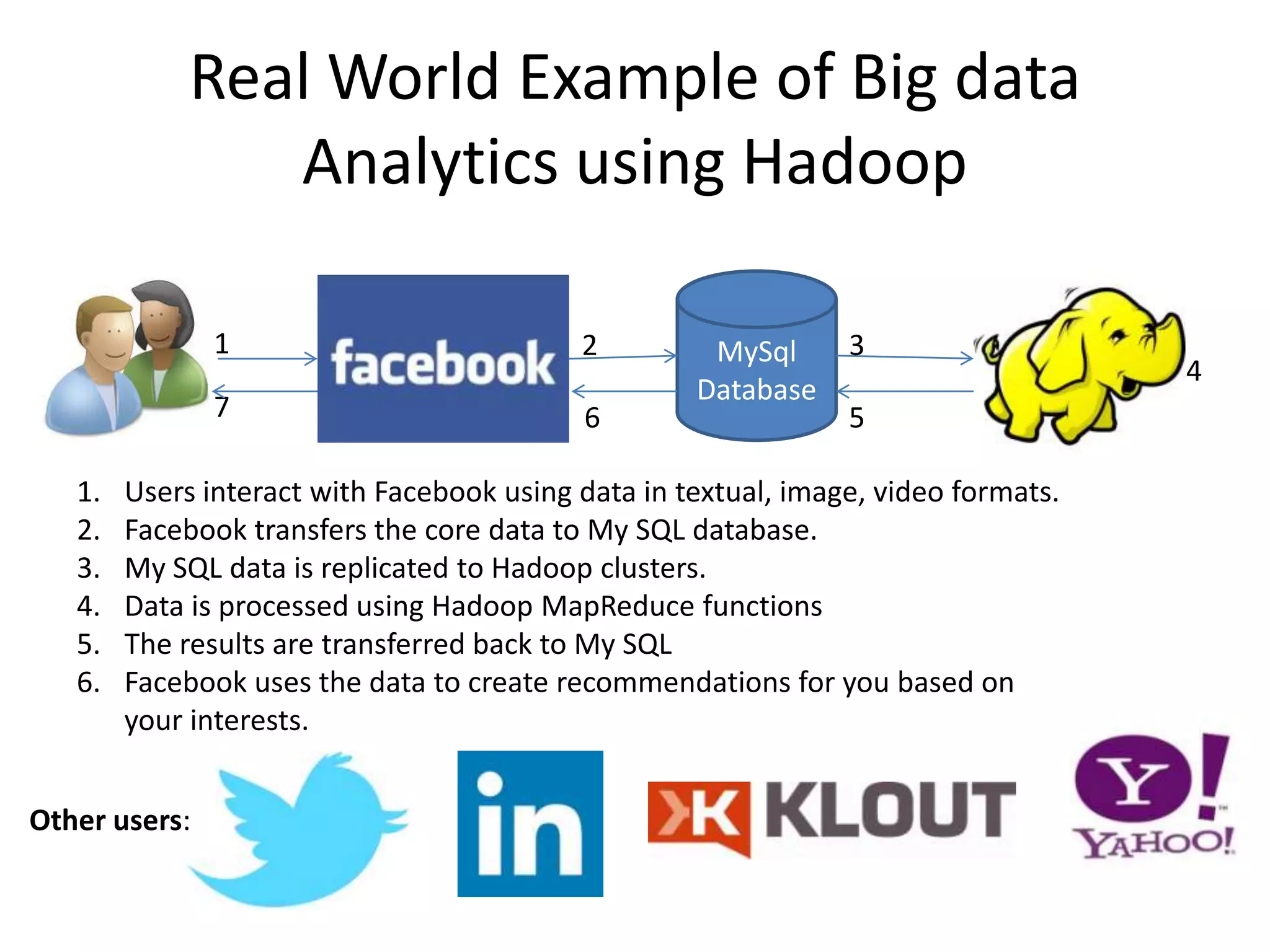

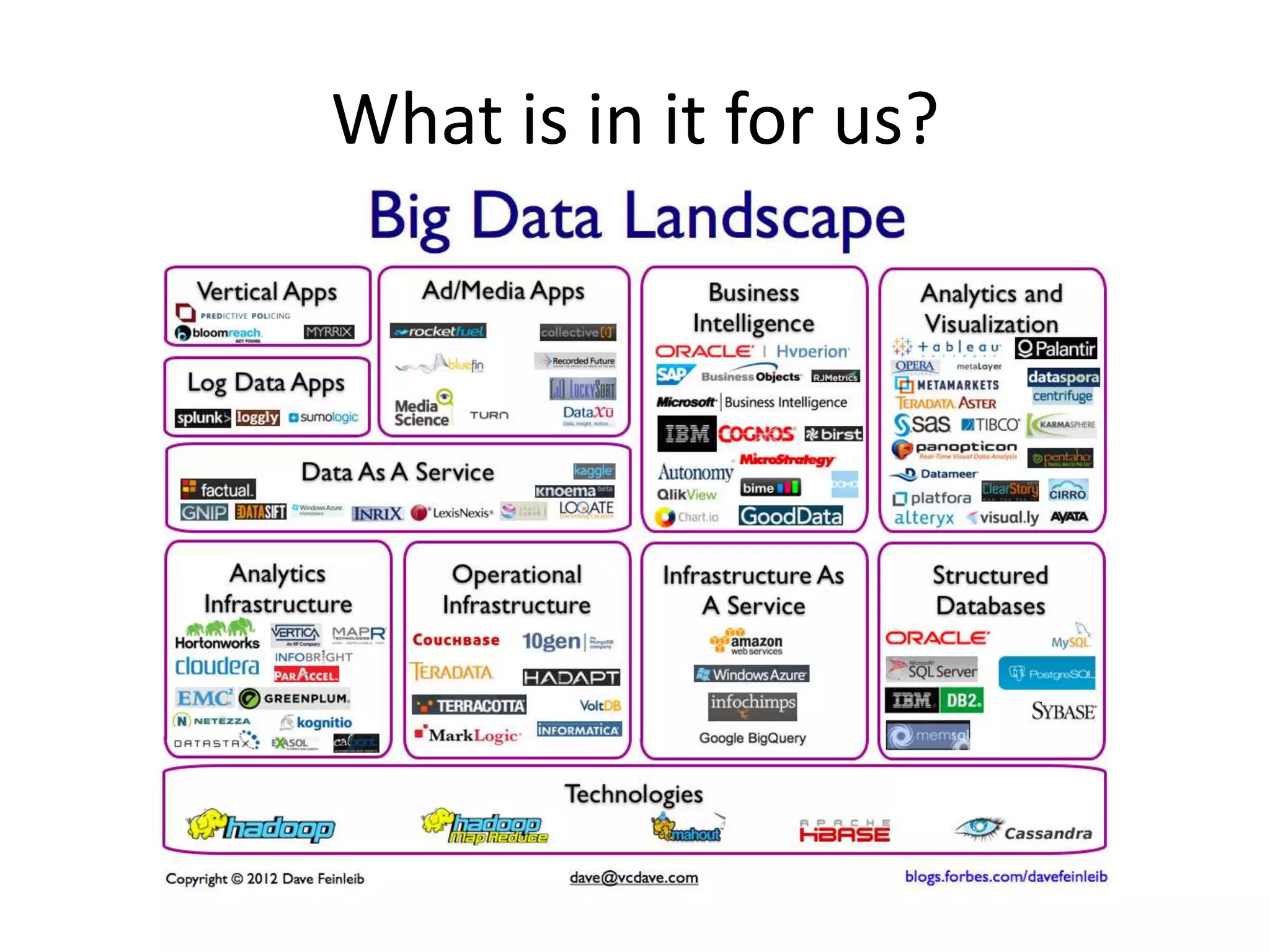























The document discusses big data and Hadoop, explaining that big data consists of large and complex datasets that exceed the processing capacity of conventional database systems. It highlights Hadoop as a flexible solution for storing and analyzing big data, detailing its key components such as HDFS, MapReduce, and YARN, along with various secondary components. Real-world use cases, particularly in social media analytics, are provided to illustrate how enterprises can utilize big data to enhance decision-making and identify trends.










































































