This document presents an overview of deep learning fundamentals, GPU technology, and best practices for configuration and optimization in model training. It covers GPU acceleration, the importance of multi-GPU setups, and CUDA usage for efficient deep learning applications. Additionally, it provides insights into model parallelism, data parallelism, and practical tools for implementing distributed deep learning, along with tips for optimizing performance.
7
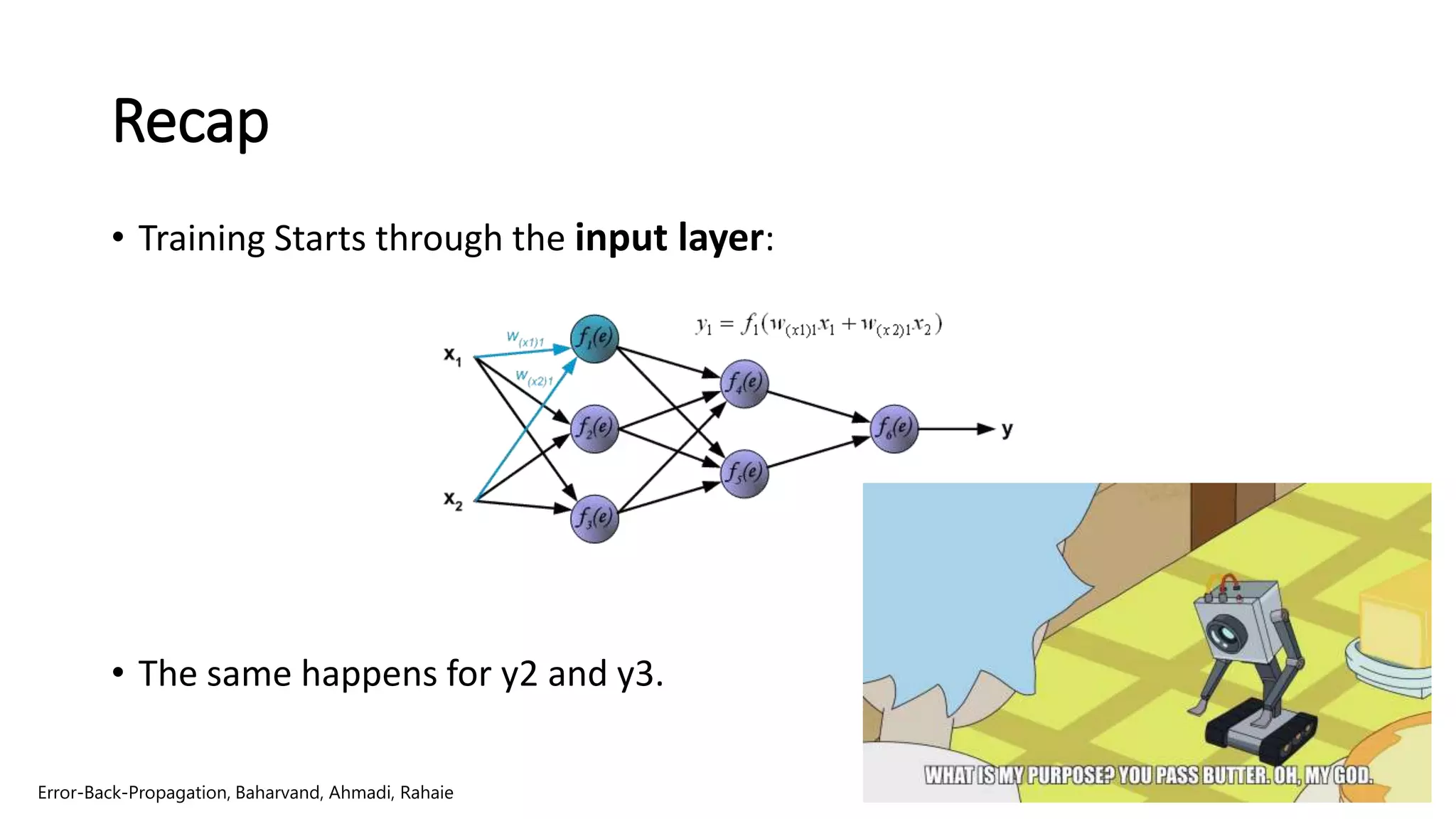
Intuition by Illustration
•Propagation of signals through the hidden layer:
• The same happens for y5.
Error-Back-Propagation, Baharvand, Ahmadi, Rahaie
8.
8
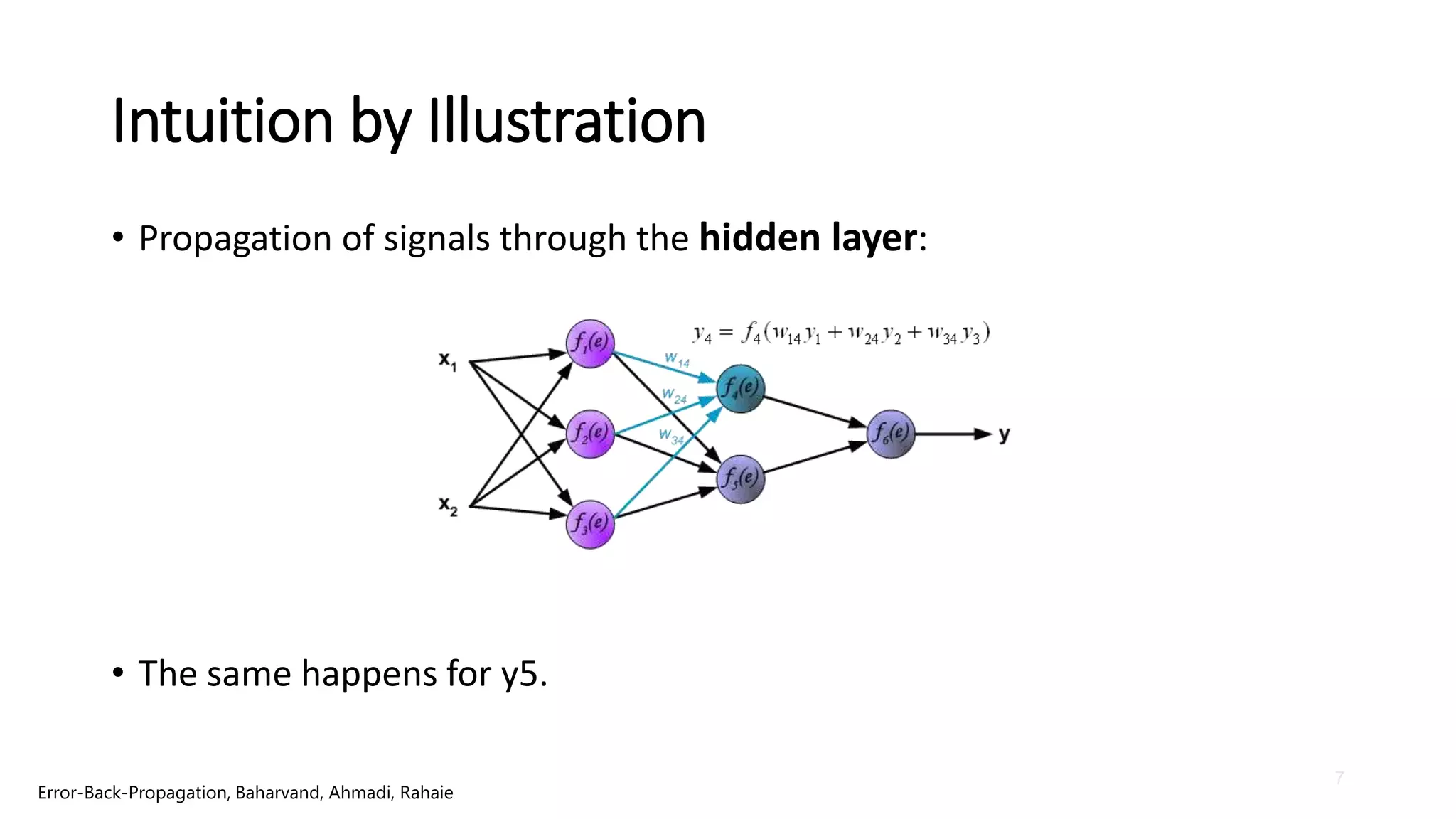
Intuition by Illustration
•Propagation of signals through the output layer:
Error-Back-Propagation, Baharvand, Ahmadi, Rahaie
10
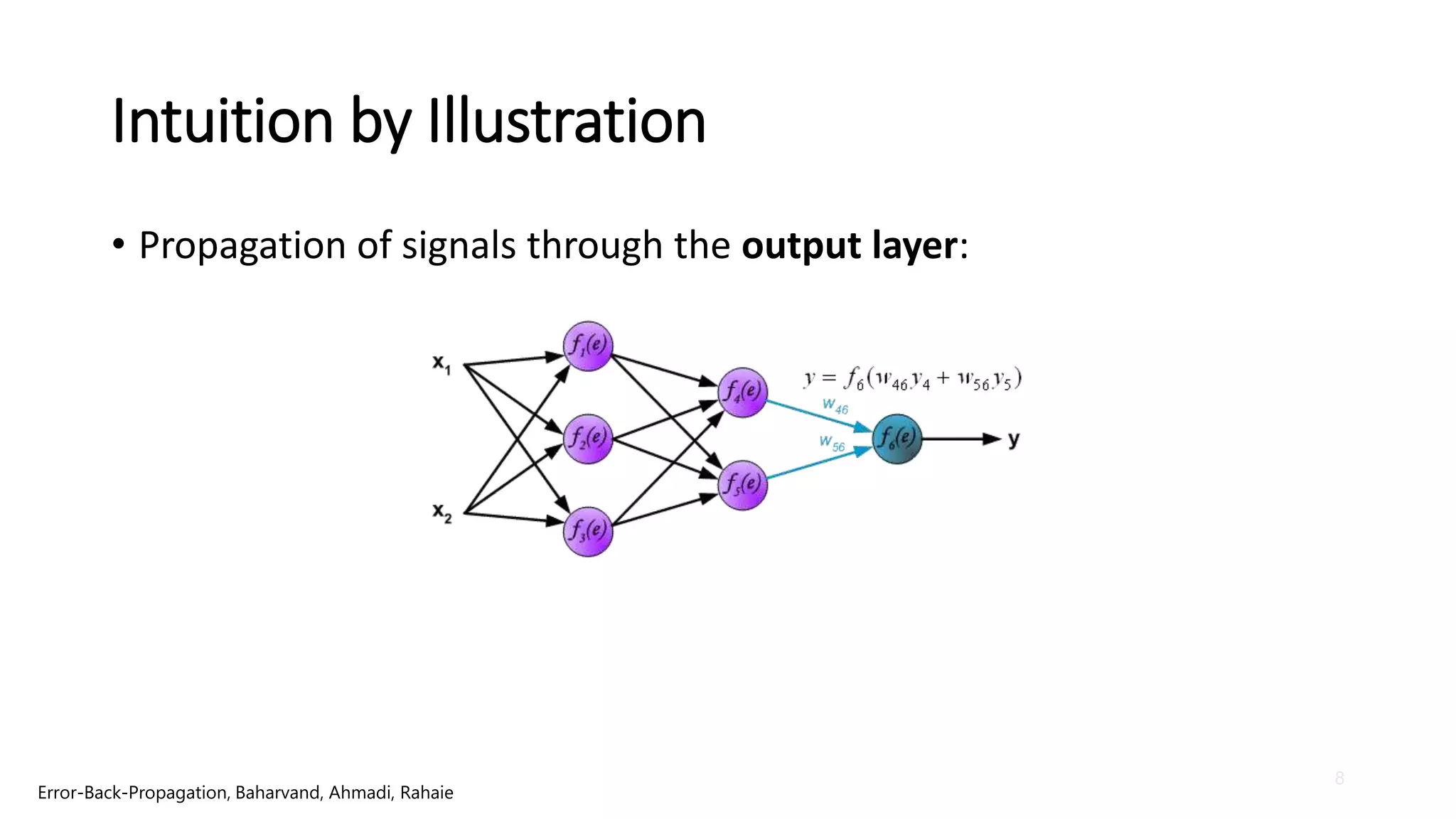
Intuition by Illustration
•propagate error
signal back to all
neurons.
Error-Back-Propagation, Baharvand, Ahmadi, Rahaie
11.
11
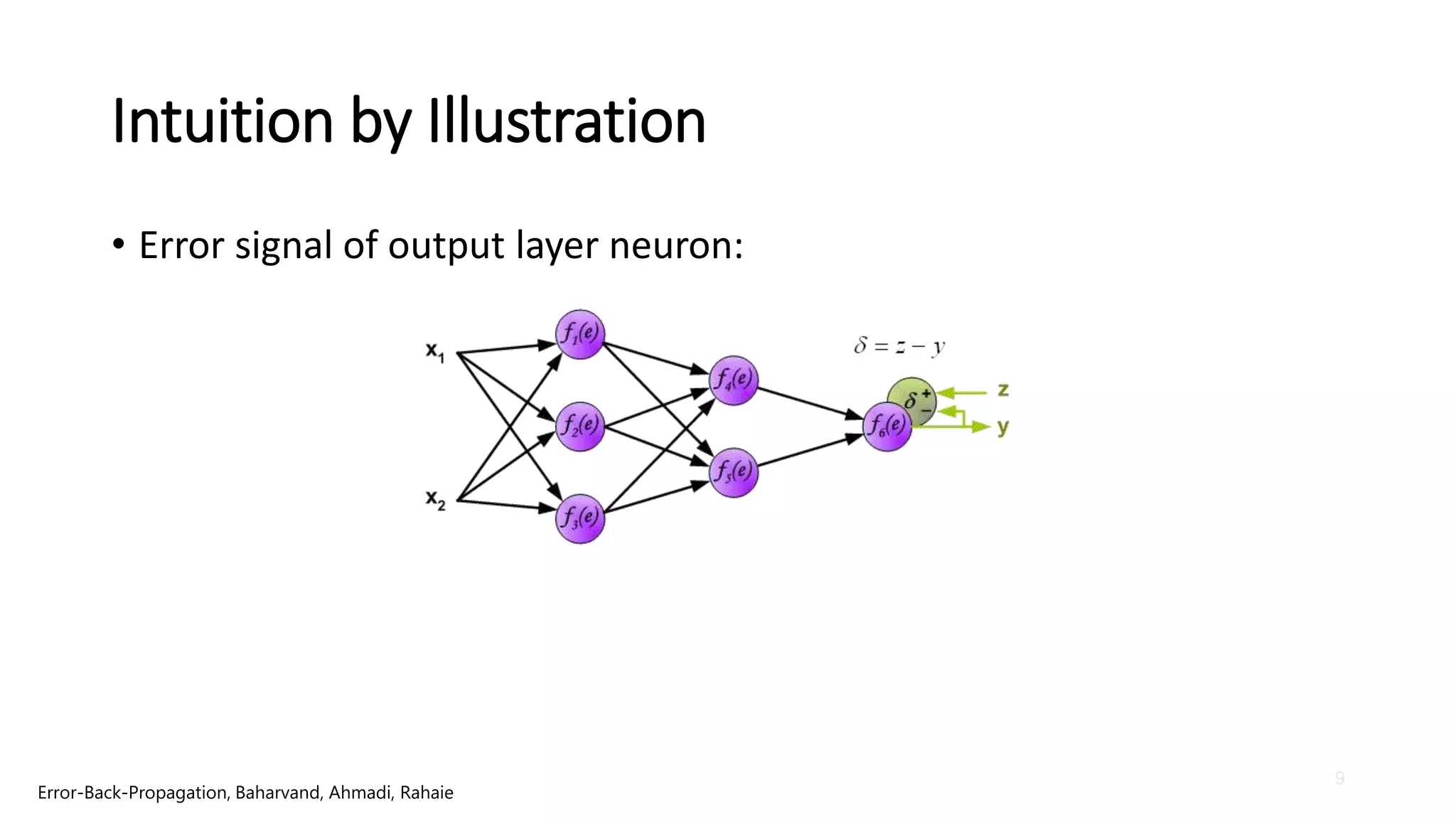
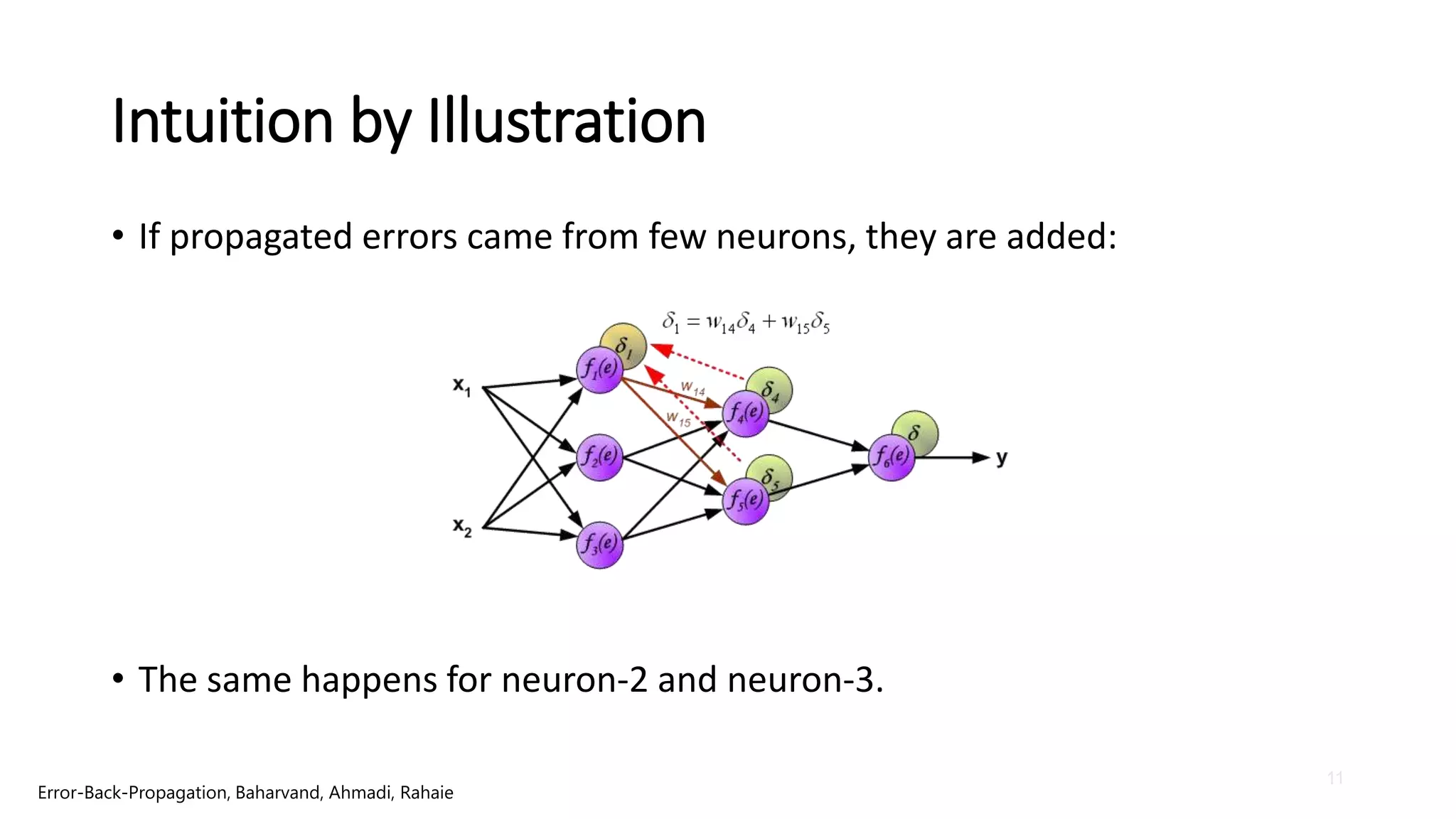
Intuition by Illustration
•If propagated errors came from few neurons, they are added:
• The same happens for neuron-2 and neuron-3.
Error-Back-Propagation, Baharvand, Ahmadi, Rahaie
12.
12
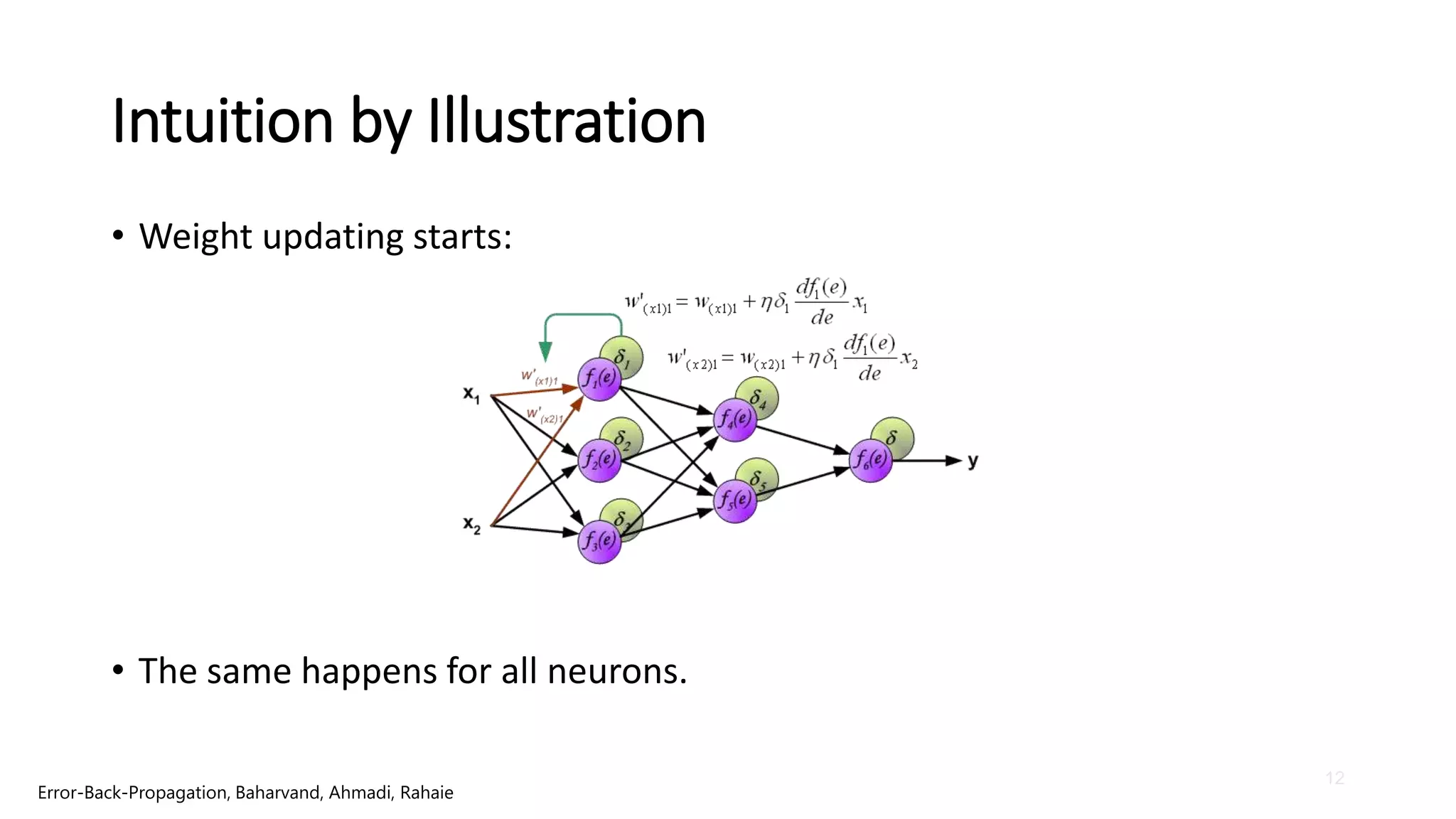
Intuition by Illustration
•Weight updating starts:
• The same happens for all neurons.
Error-Back-Propagation, Baharvand, Ahmadi, Rahaie
This image islicensed under CC-BY 2.0
Spot the CPU!
(central processing unit)
http://cs231n.stanford.edu/
19.
Spot the GPUs!
(graphicsprocessing unit)
This image is in the public domain
http://cs231n.stanford.edu/
20.
CPU / GPUCommunication
Model
is here
Data is here
http://cs231n.stanford.edu/
21.
CPU / GPUCommunication
Model
is here
Data is here
If you aren’t careful, training can
bottleneck on reading data and
transferring to GPU!
Solutions:
- Read all data into RAM
- Use SSD instead of HDD
- Use multiple CPU threads
to prefetch data
http://cs231n.stanford.edu/
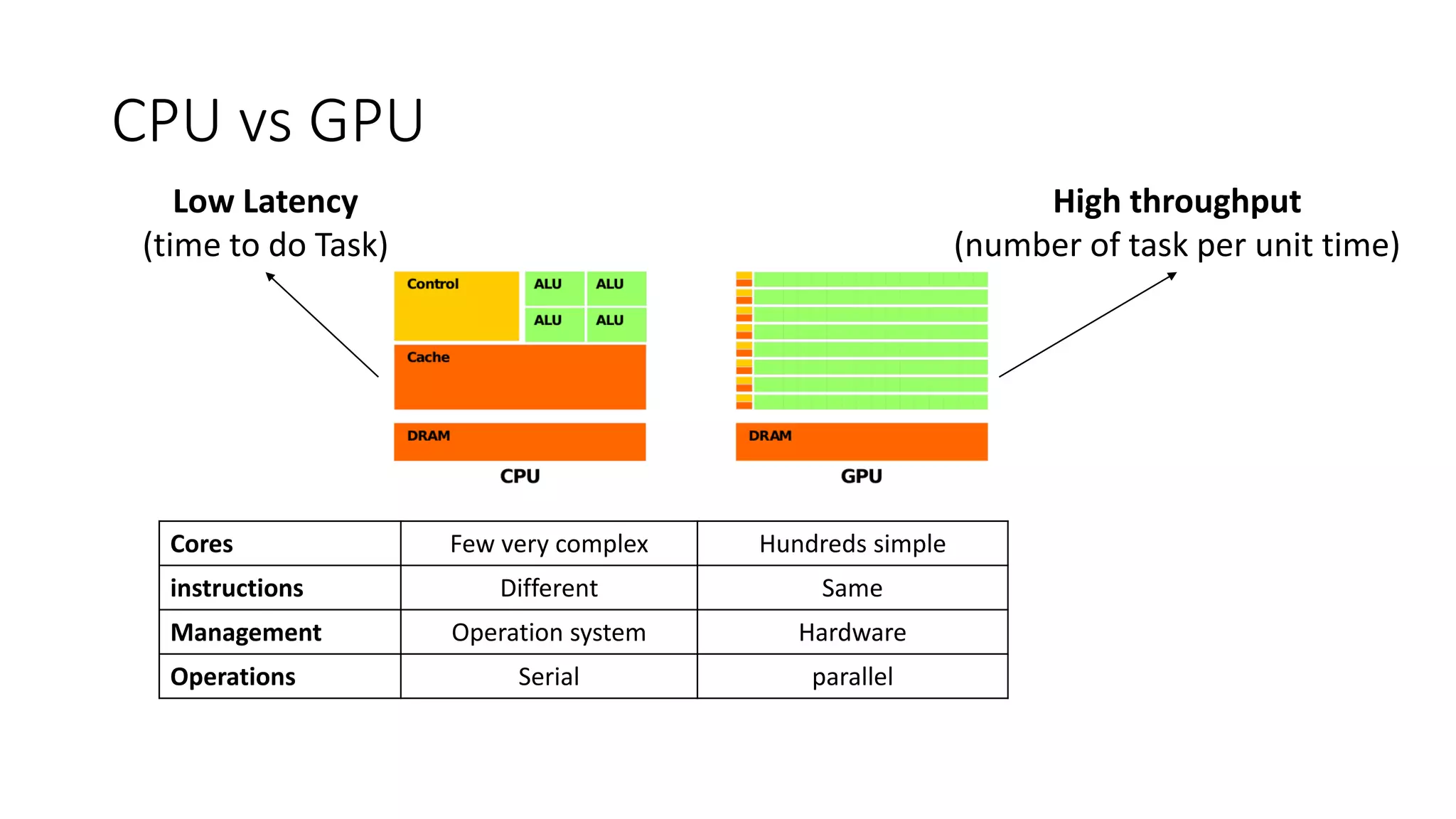
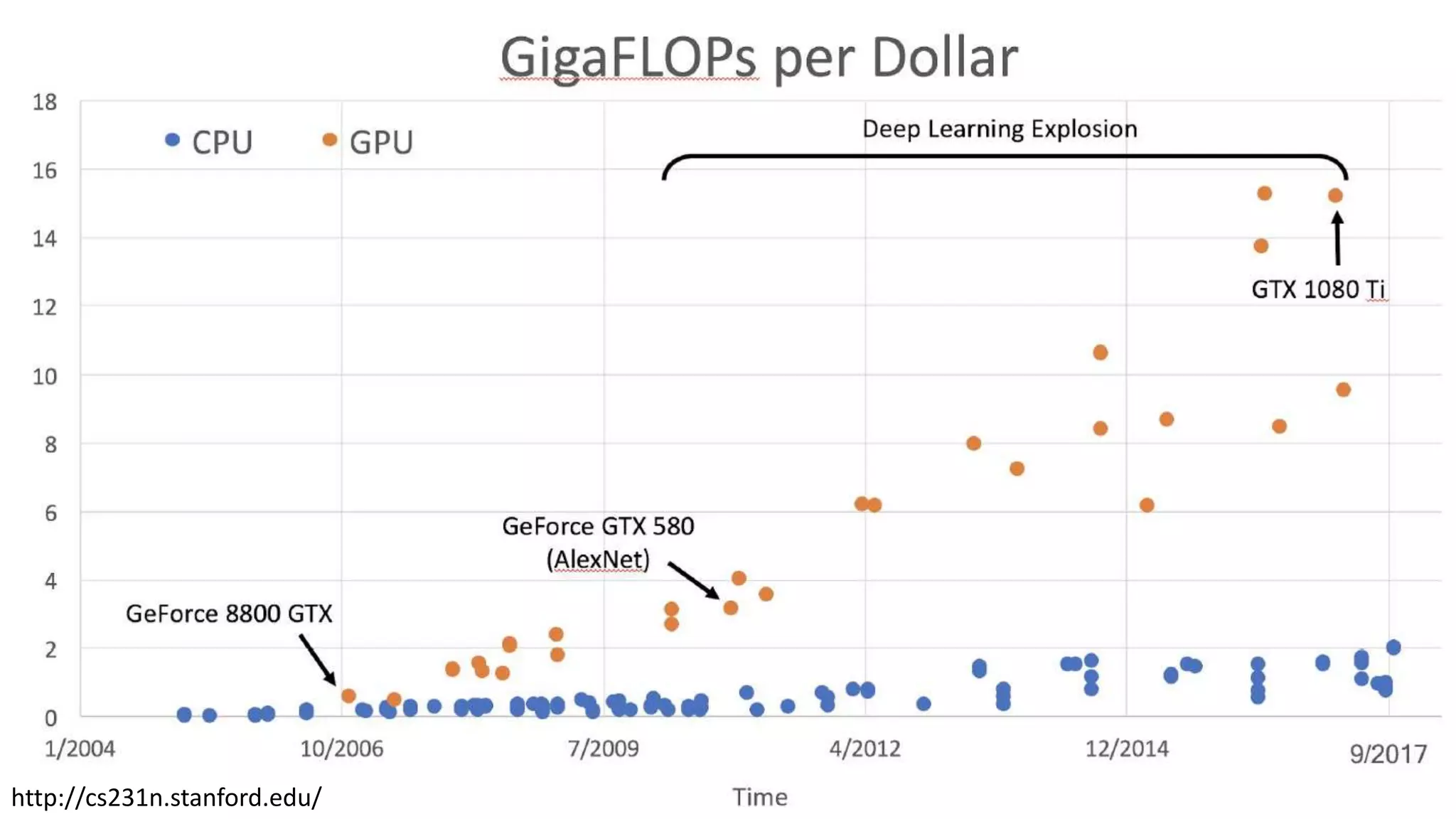
CPU vs GPU
CoresFew very complex Hundreds simple
instructions Different Same
Management Operation system Hardware
Operations Serial parallel
24.
CPU vs GPU
CoresFew very complex Hundreds simple
instructions Different Same
Management Operation system Hardware
Operations Serial parallel
High throughput
(number of task per unit time)
Low Latency
(time to do Task)
25.
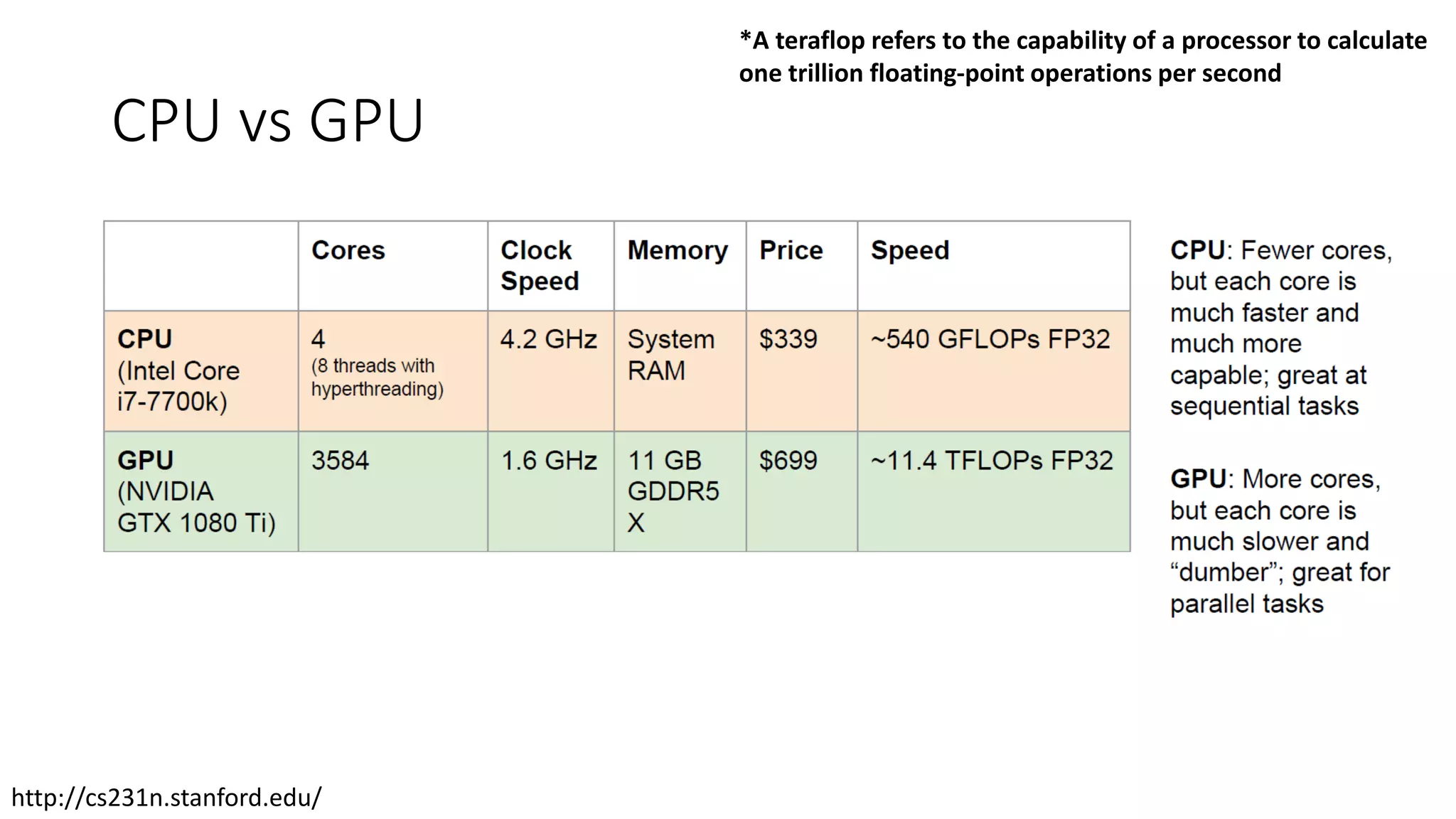
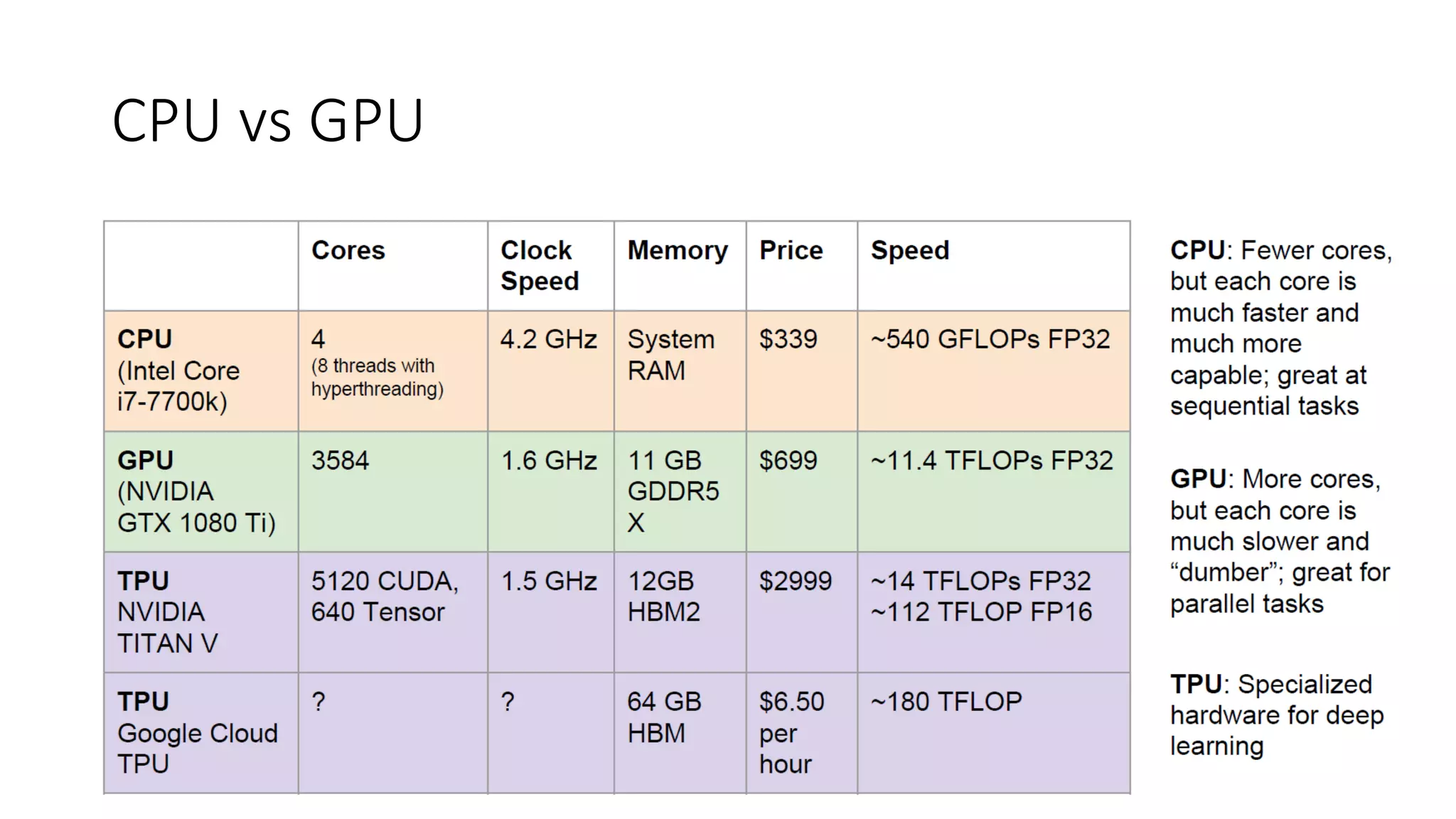
CPU vs GPU
*Ateraflop refers to the capability of a processor to calculate
one trillion floating-point operations per second
http://cs231n.stanford.edu/
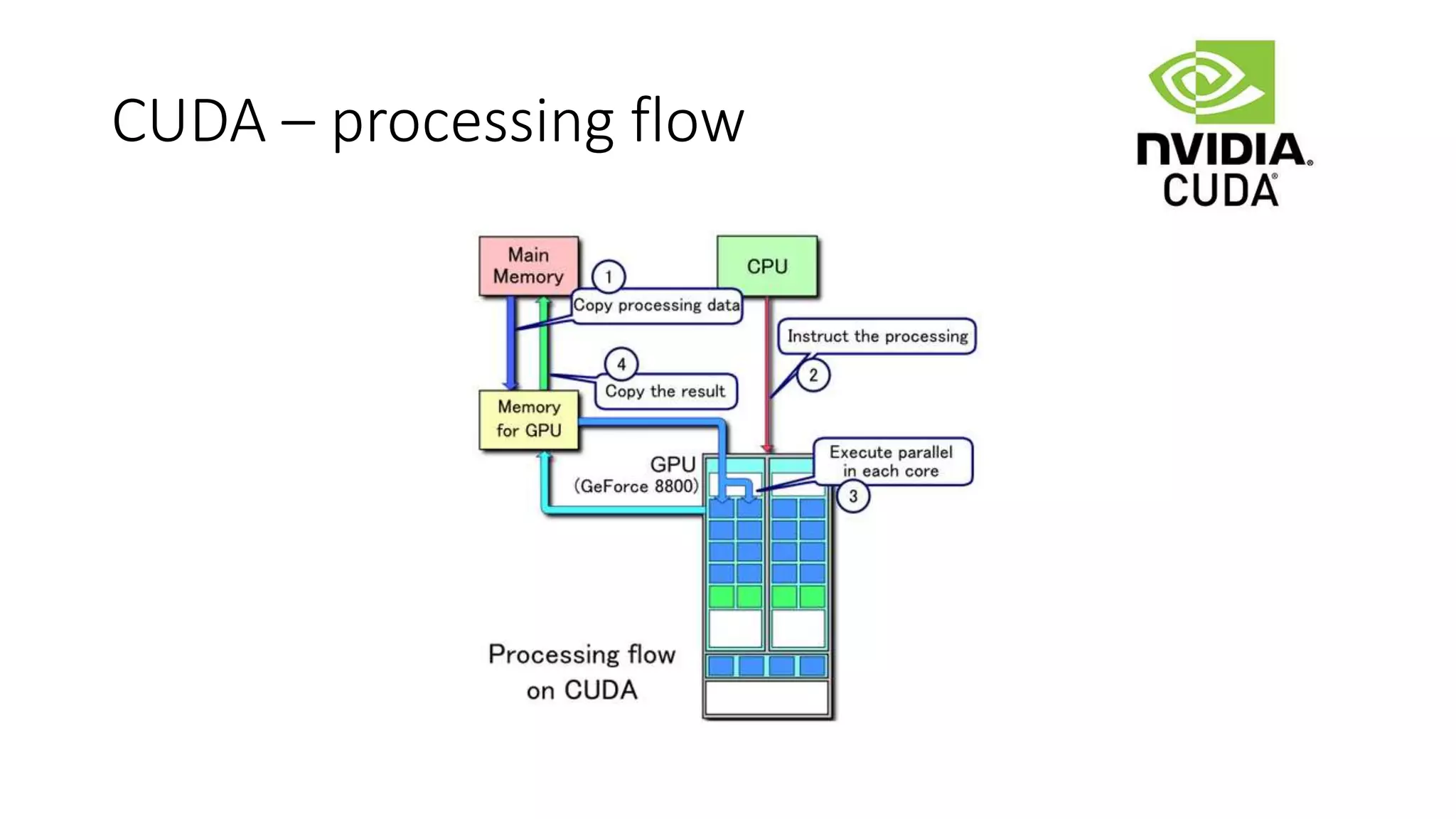
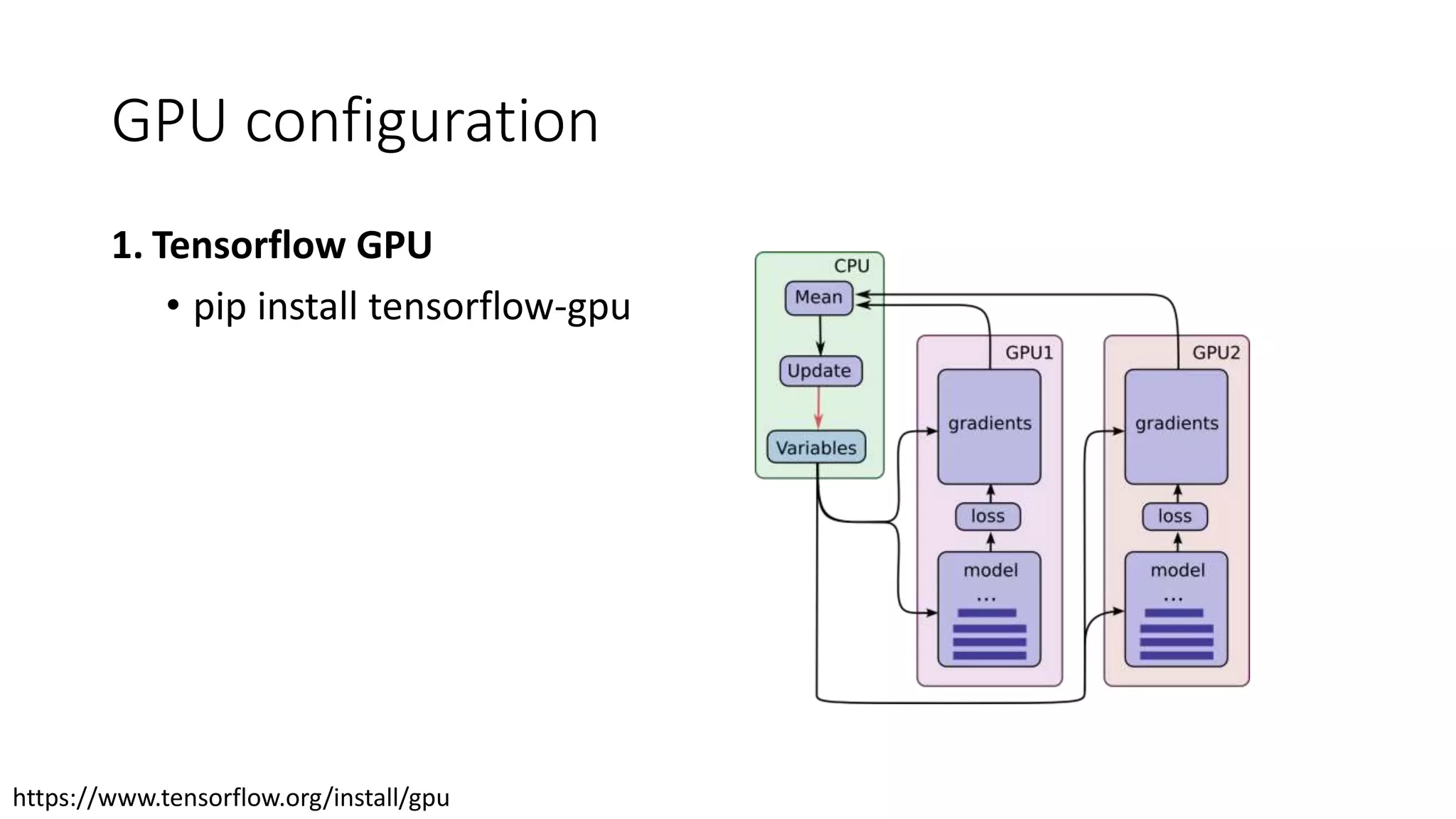
CUDA
• CUDA isa parallel computing platform and application programming
interface (API) model created by Nvidia
• software layer that gives direct access to the GPU
CUDA Deep NeuralNetwork
• a GPU-accelerated library for deep neural networks.
• Provides highly tuned implementations for standard routines such as
forward and backward convolution, pooling, normalization, and
activation layers.
36.
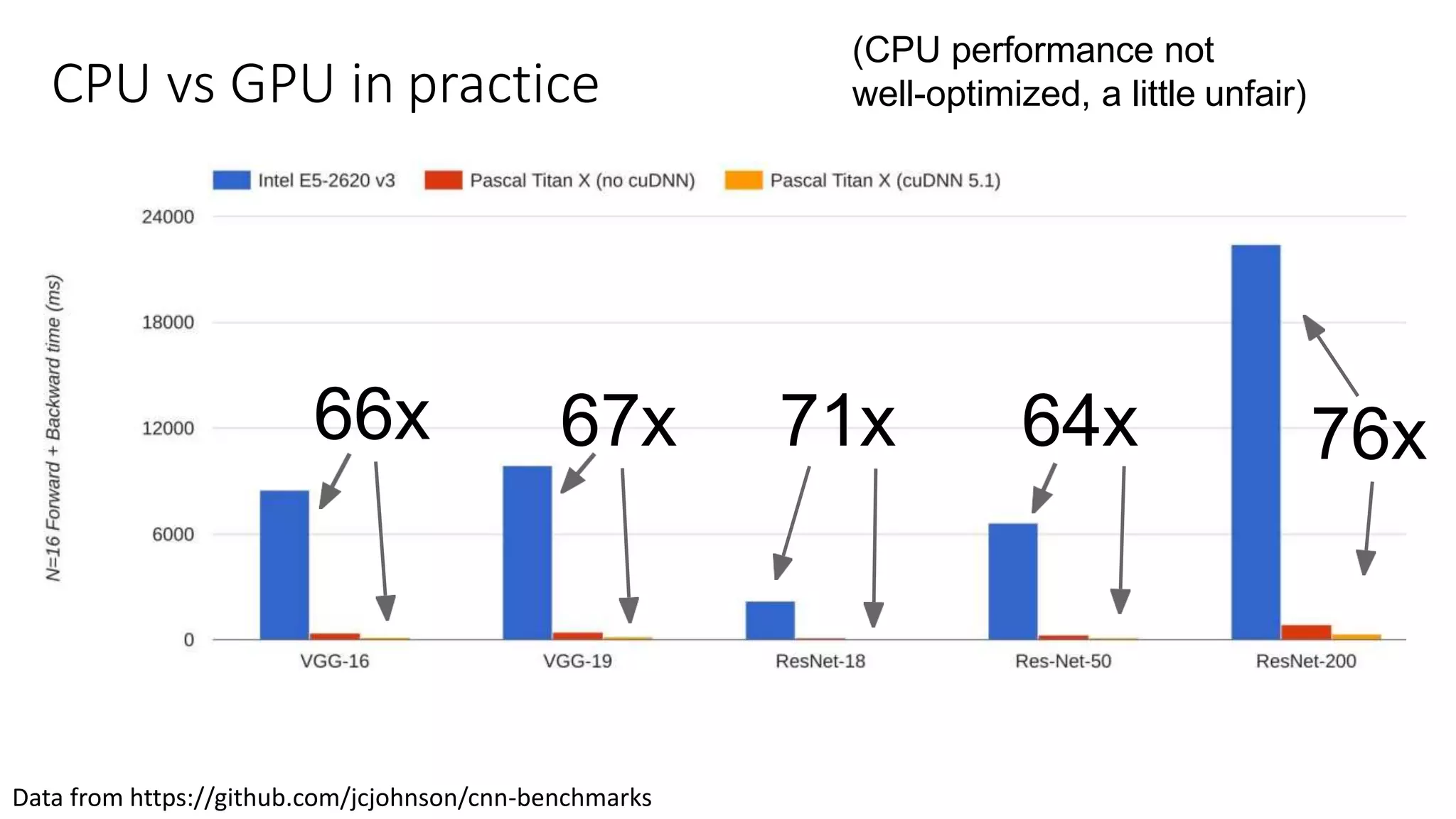
CPU vs GPUin practice
(CPU performance not
well-optimized, a little unfair)
66x 67x 71x 64x 76x
Data from https://github.com/jcjohnson/cnn-benchmarks
37.
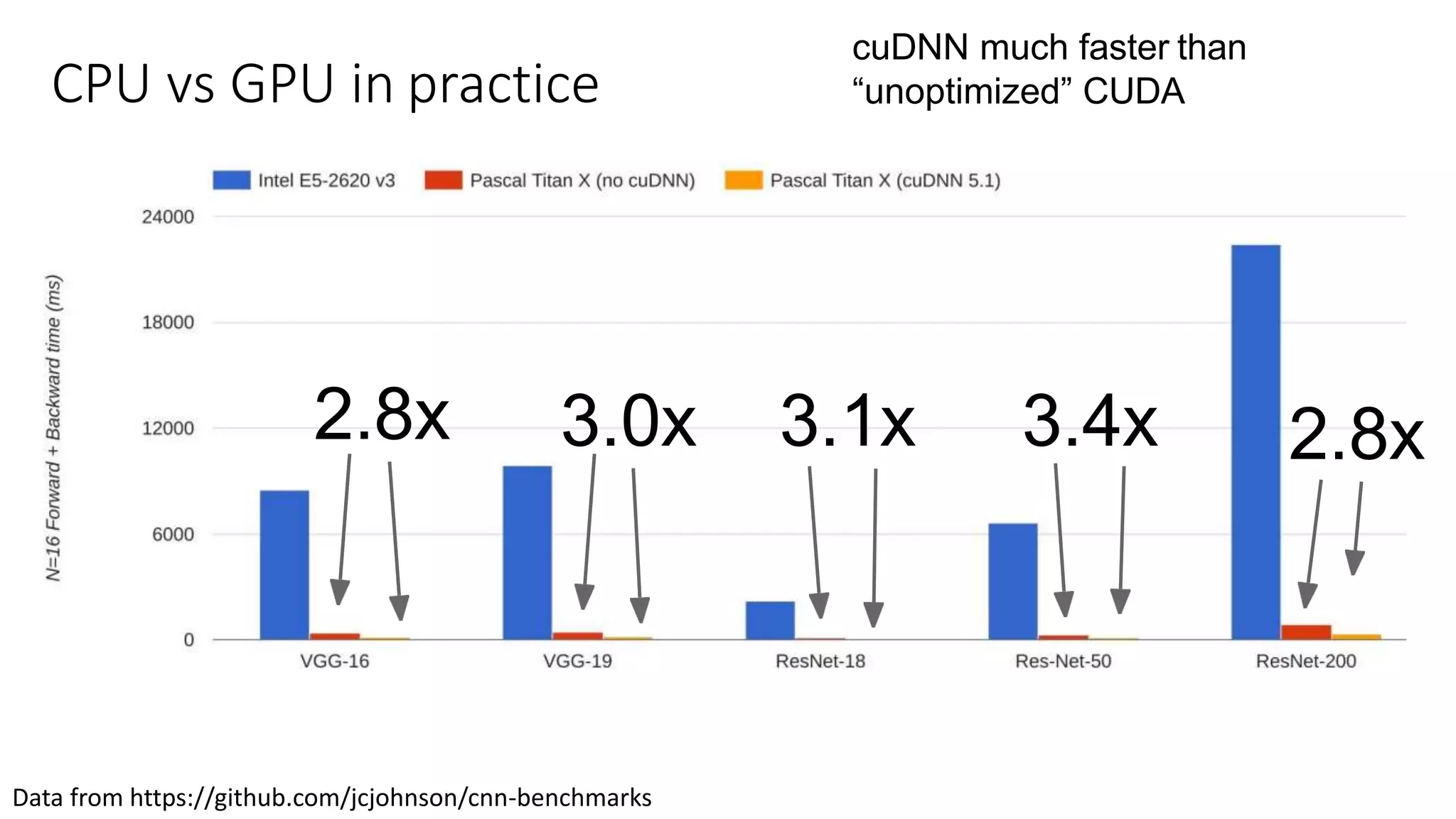
CPU vs GPUin practice
cuDNN much faster than
“unoptimized” CUDA
2.8x 3.0x 3.1x 3.4x 2.8x
Data from https://github.com/jcjohnson/cnn-benchmarks
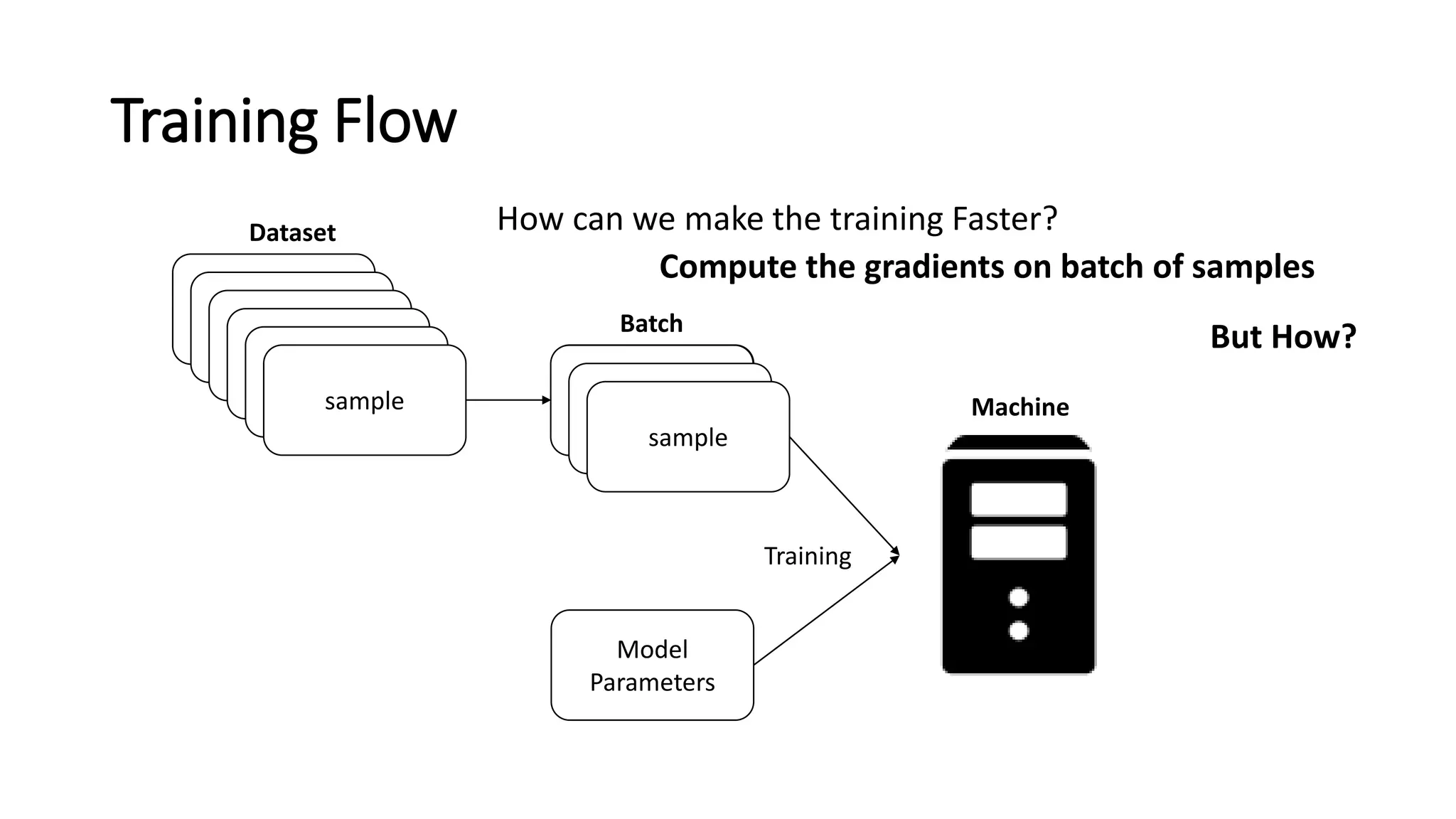
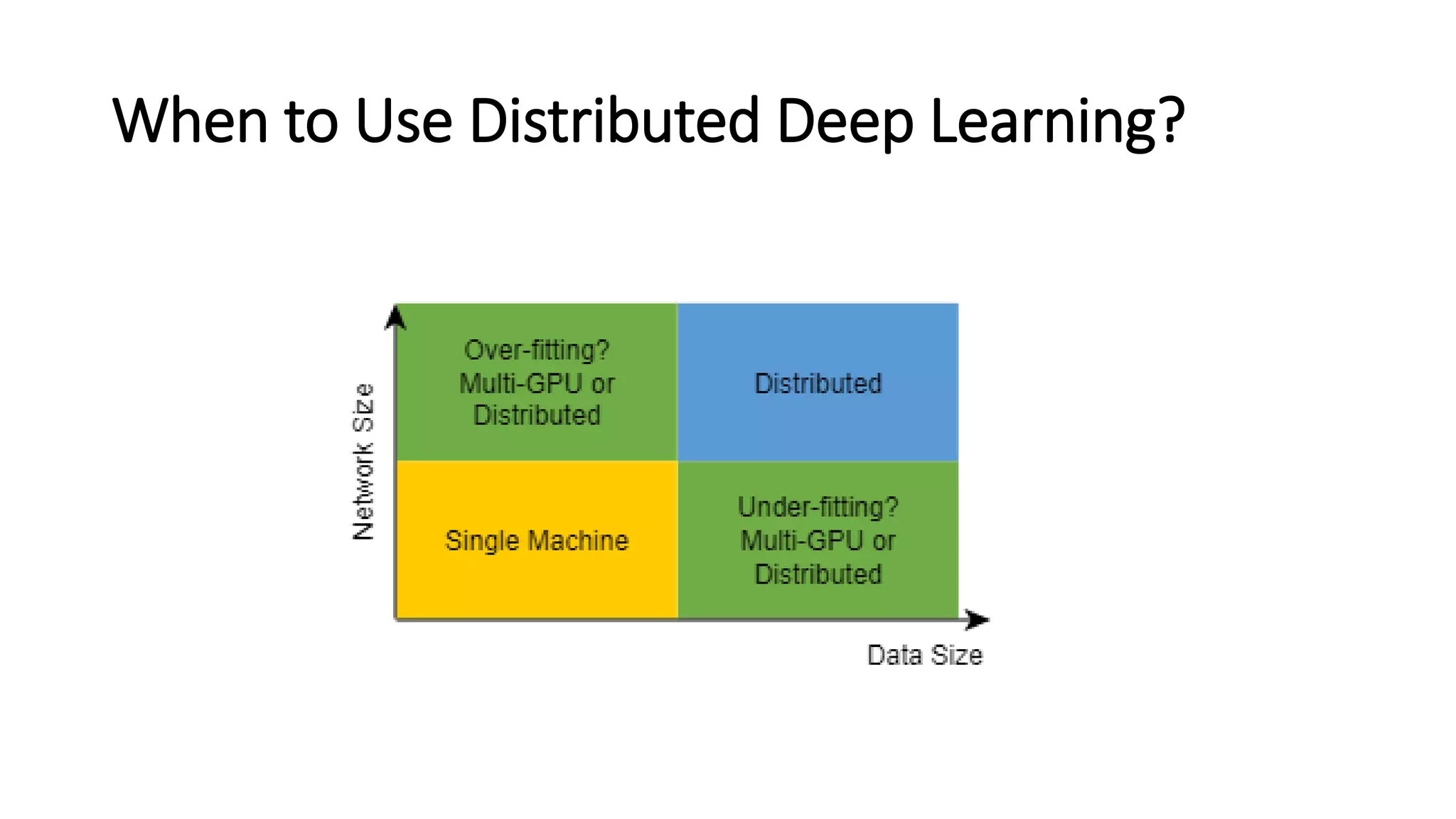
TheNeed for DistributedTraining
•Largerand Deeper models arebeingproposed; AlexNetto ResNetto NMT
– DNNsrequire a lot of memory
– Larger models cannotfita GPU’s memory
• Single GPU training became abottleneck
• As mentionedearlier,communityhas alreadymoved to multi-GPUtraining
• Multi-GPU in one node is good but thereis alimitto Scale-up(8 GPUs)
• Multi-node (Distributed or Parallel) Training isnecessary!!
40.
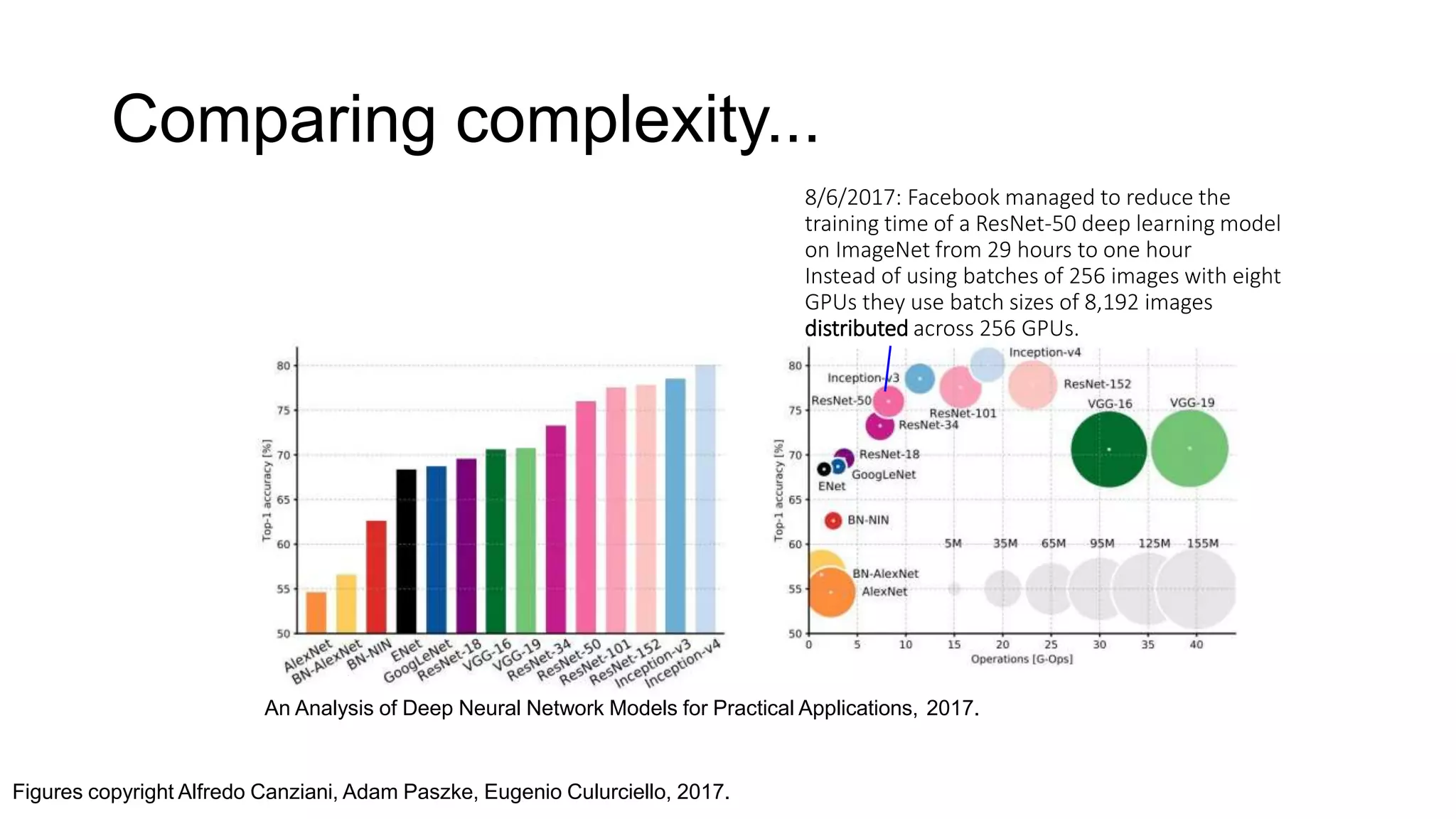
Comparing complexity...
An Analysisof Deep Neural Network Models for Practical Applications, 2017.
8/6/2017: Facebook managed to reduce the
training time of a ResNet-50 deep learning model
on ImageNet from 29 hours to one hour
Instead of using batches of 256 images with eight
GPUs they use batch sizes of 8,192 images
distributed across 256 GPUs.
Figures copyright Alfredo Canziani, Adam Paszke, Eugenio Culurciello, 2017.
41.
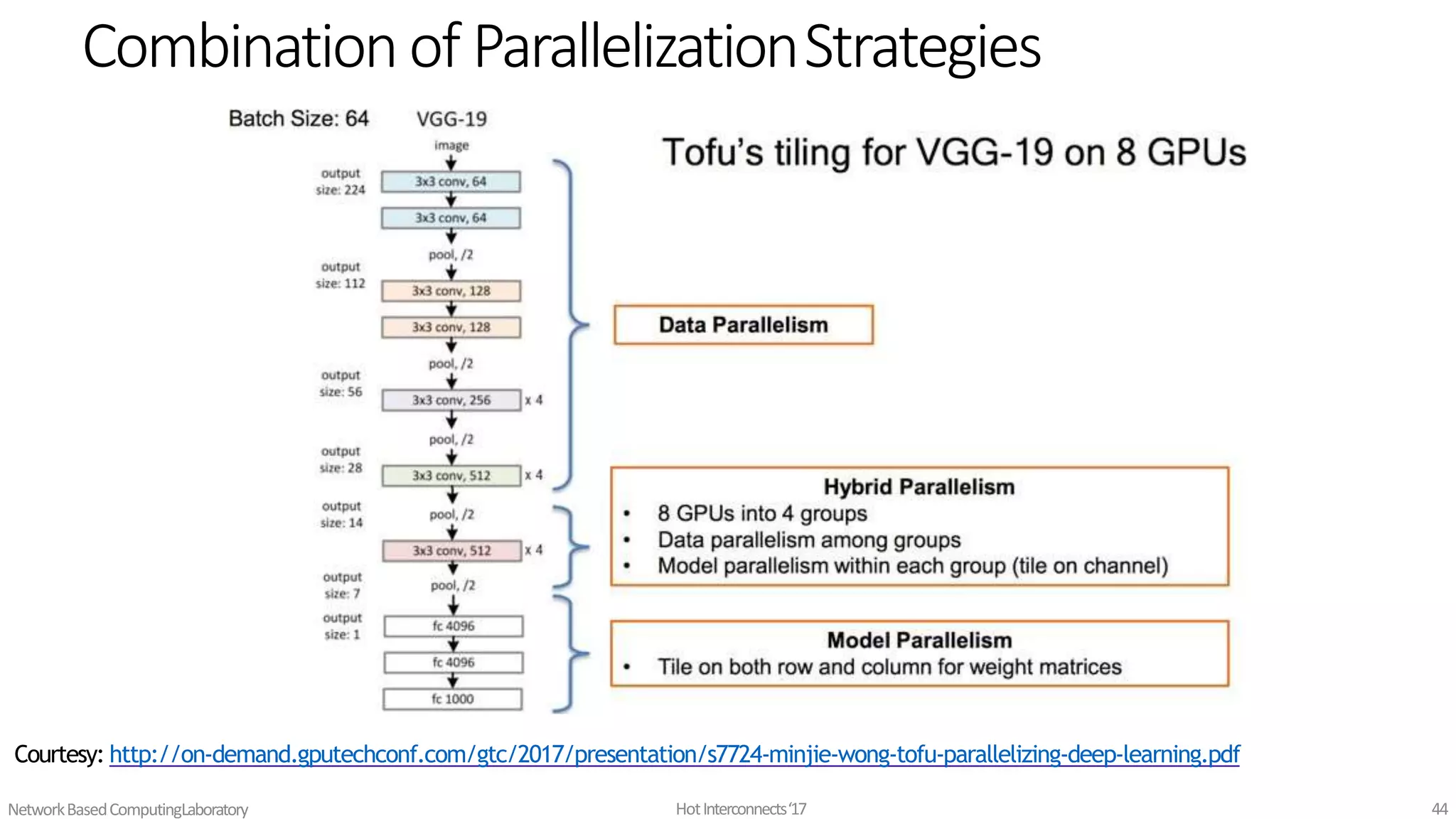
Parallelism Types
model parallelism
differentmachines in the
distributed system are responsible
for the computations in different
parts of a single network.
for example, each layer in the
neural network may be assigned
to a different machine.
42.
Parallelism Types
model parallelism
differentmachines in the
distributed system are responsible
for the computations in different
parts of a single network.
for example, each layer in the
neural network may be assigned
to a different machine.
data parallelism
different machines have a
complete copy of the model; each
machine simply gets a different
portion of the data, and results
from each are somehow
combined
Data Parallelism
• Dataparallel approaches to distributed training keep a copy of the
entire model on each worker machine, processing different subsets of
the training data set on each.
46.
Data Parallelism
• Dataparallel approaches to distributed training keep a copy of the
entire model on each worker machine, processing different subsets of
the training data set on each.
• Data parallel training approaches all require some method of
combining results and synchronizing the model parameters between
each worker
• Approaches:
• Parameter averaging vs. update (gradient)-based approaches
• Synchronous vs. asynchronous methods
• Centralized vs. distributed synchronization
47.
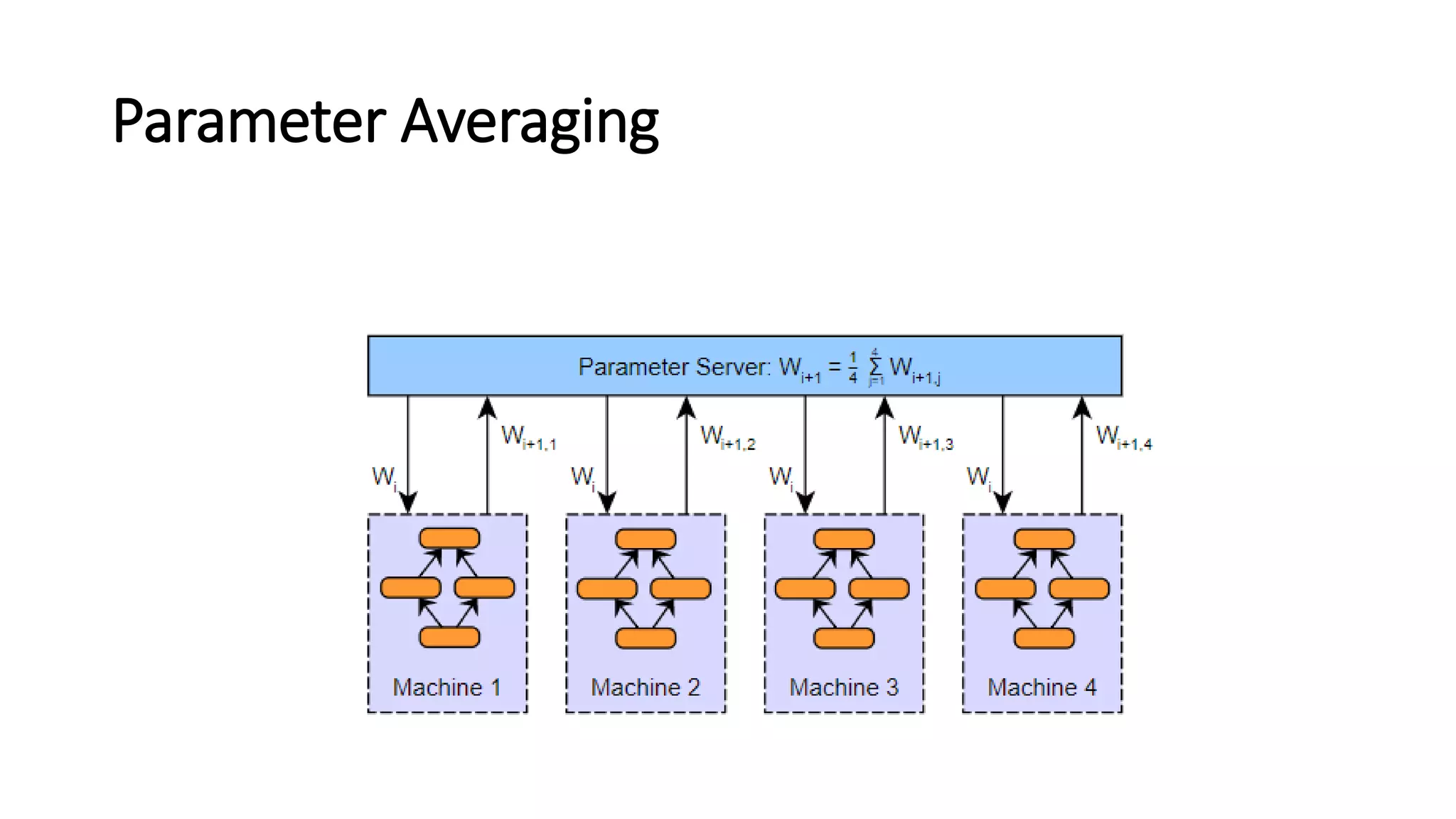
Parameter Averaging
• Parameteraveraging is the conceptually simplest approach to data
parallelism. With parameter averaging, training proceeds as follows:
1. Initialize the network parameters randomly based on the model
configuration
2. Distribute a copy of the current parameters to each worker
3. Train each worker on a subset of the data
4. Set the global parameters to the average the parameters from each
worker
5. While there is more data to process, go to step 2
Multi GPU -Data Parallelism on Keras!
https://keras.io/utils/#multi_gpu_model
50.
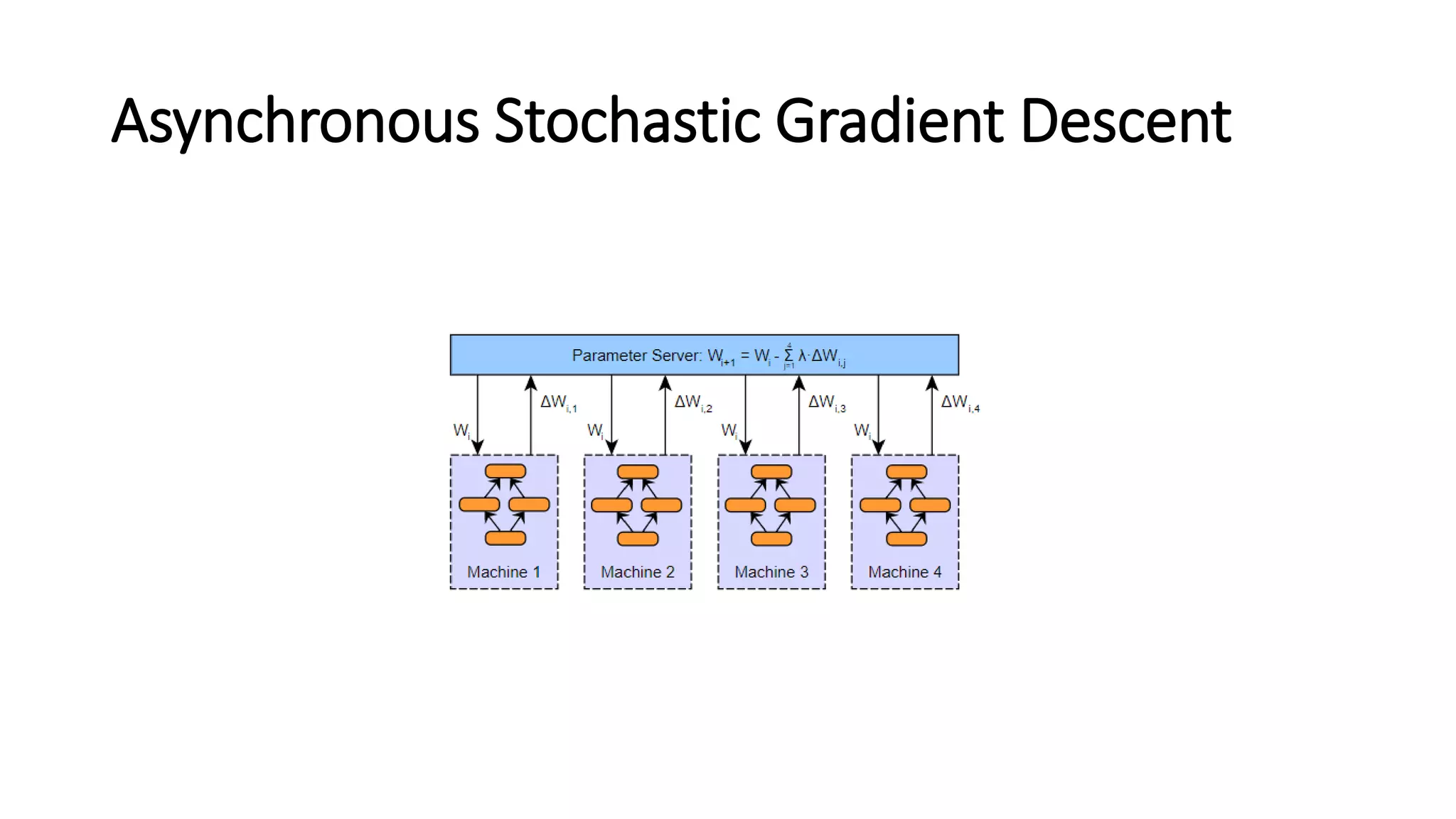
Asynchronous Stochastic GradientDescent
• An ‘update based’ data parallelism.
• The primary difference between the two is that instead of transferring
parameters from the workers to the parameter server, we will
transfer the updates (i.e., gradients post learning rate and
momentum, etc.) instead.
NVIDIA System ManagementInterface
• The NVIDIA System Management Interface (nvidia-smi) is a command
line utility, based on top of the NVIDIA Management Library (NVML),
intended to aid in the management and monitoring of NVIDIA GPU
devices.
• This utility allows administrators to query GPU device state and with
the appropriate privileges, permits administrators to modify GPU
device state. It is targeted at the TeslaTM, GRIDTM, QuadroTM and Titan
X product, though limited support is also available on other NVIDIA
GPUs.
https://developer.nvidia.com/nvidia-system-management-interface
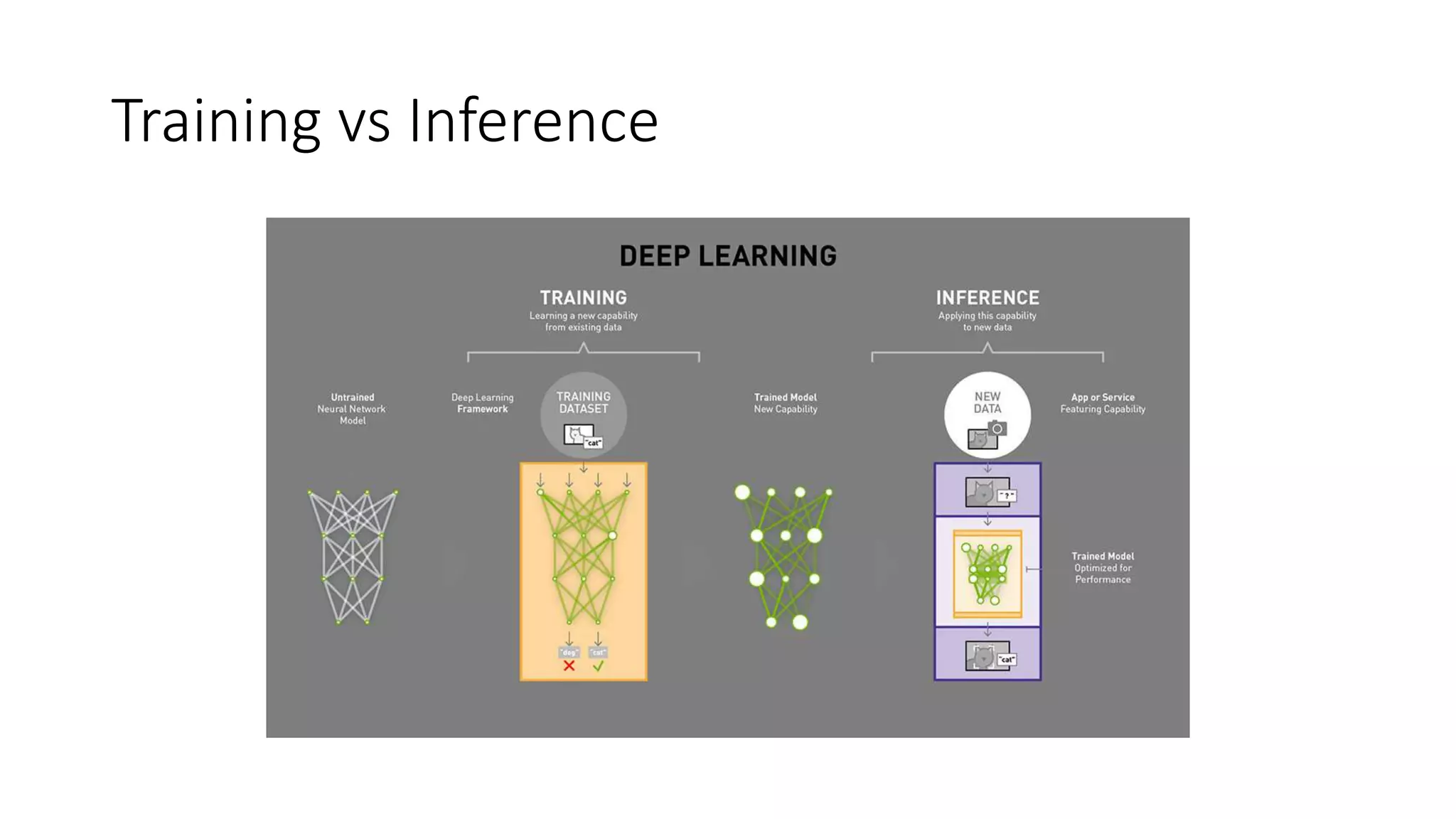
Inference - Spark
1.Install tensorflow & Keras on each node
2. Train a model on GPU
3. Save model as H5 file
4. Define batch size based on executor memory size & network size
5. Load the saved model on each node in the cluster
6. Run Code
1. Base on RDD
2. Use map partition to call executors code:
1. Load model
2. Predict_on_batch
73.
Inference – SparkCode
import pandas as pd
from keras.models import load_model, Sequential
from pyspark.sql.types import Row
def keras_spark_predict(model_path, weights_path, partition):
# load model
model = Sequential.from_config(model_path.value)
model.set_weights(weights_path.value)
# Create a list containing features.
featurs_list = map(lambda x: [x[:]], partition)
featurs_df = pd.DataFrame(featurs_list)
# predict with keras model
predictions = model.predict_on_batch(featurs_df)
predictions_return = map(lambda prediction: Row(prediction=prediction[0].item()), predictions)
return iter(predictions_return)
rdd = rdd.mapPartitions(lambda partition: keras_spark_predict(model_path, weights_path, partition))
https://github.com/liorsidi/GPU_deep_demo
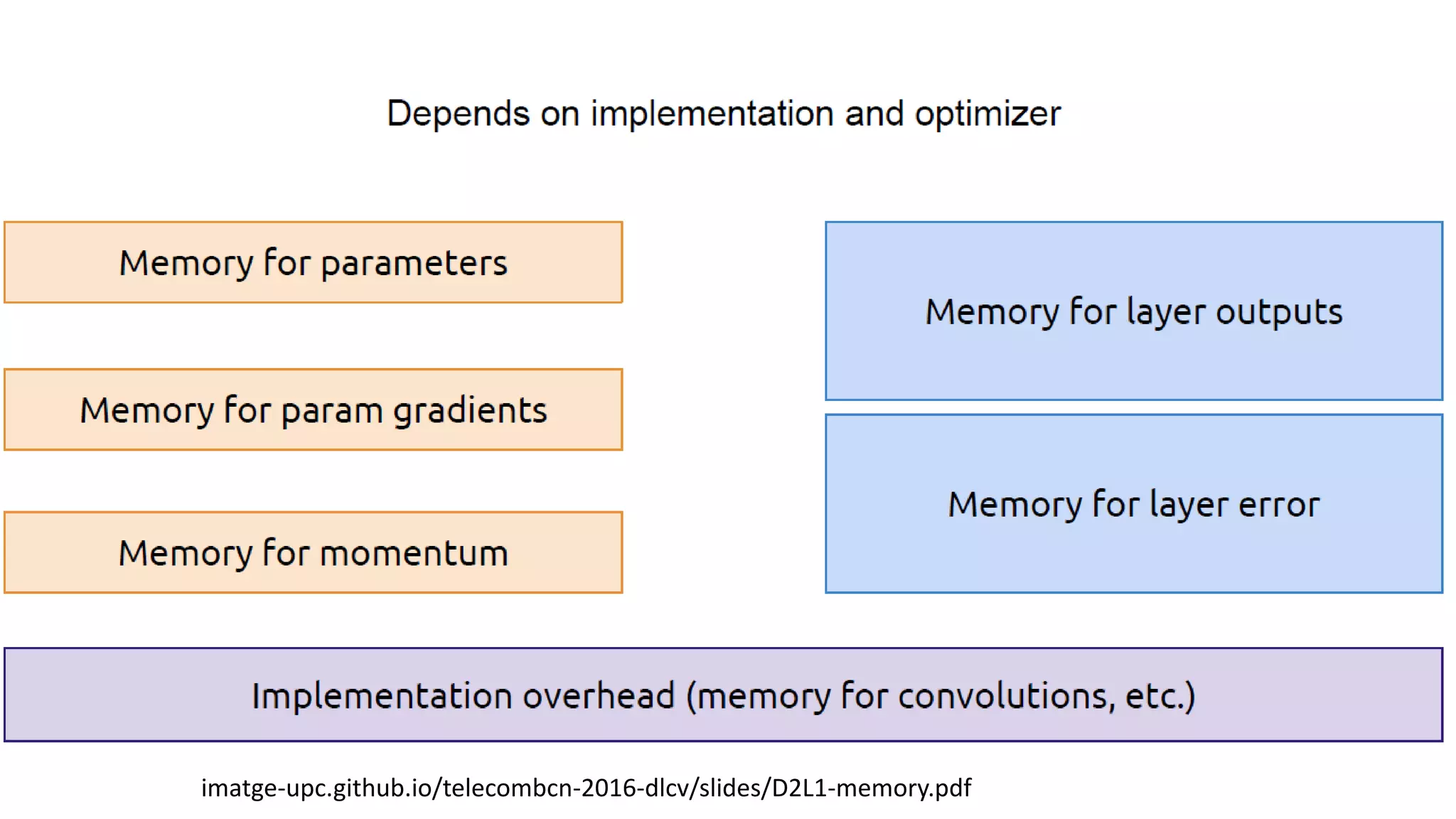
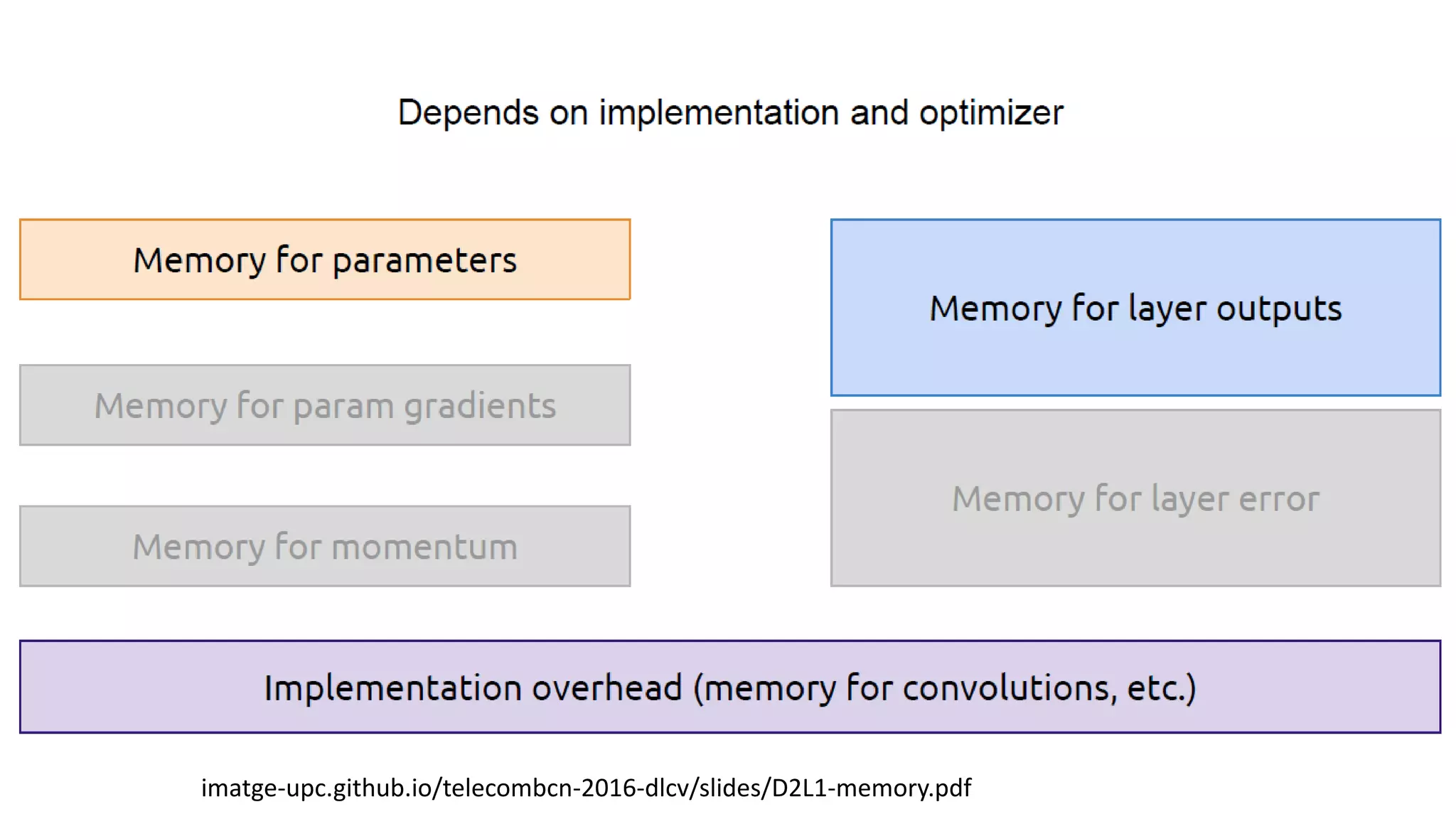
Back to theDemo
#https://stackoverflow.com/questions/43137288/how-to-determine-needed-memory-of-keras-model
def get_model_memory_usage(batch_size, model):
import numpy as np
from keras import backend as K
shapes_mem_count = 0
for l in model.layers:
single_layer_mem = 1
for s in l.output_shape:
if s is None:
continue
single_layer_mem *= s
shapes_mem_count += single_layer_mem
trainable_count = np.sum([K.count_params(p) for p in set(model.trainable_weights)])
non_trainable_count = np.sum([K.count_params(p) for p in set(model.non_trainable_weights)])
number_size = 4.0
if K.floatx() == 'float16':
number_size = 2.0
if K.floatx() == 'float64':
number_size = 8.0
total_memory = number_size*(batch_size*shapes_mem_count + trainable_count + non_trainable_count)
gbytes = np.round(total_memory / (1024.0 ** 3), 3)
return gbytes
https://github.com/liorsidi/GPU_deep_demo
83.
To summarize
• GPUare Awesome
• Mind the batch size
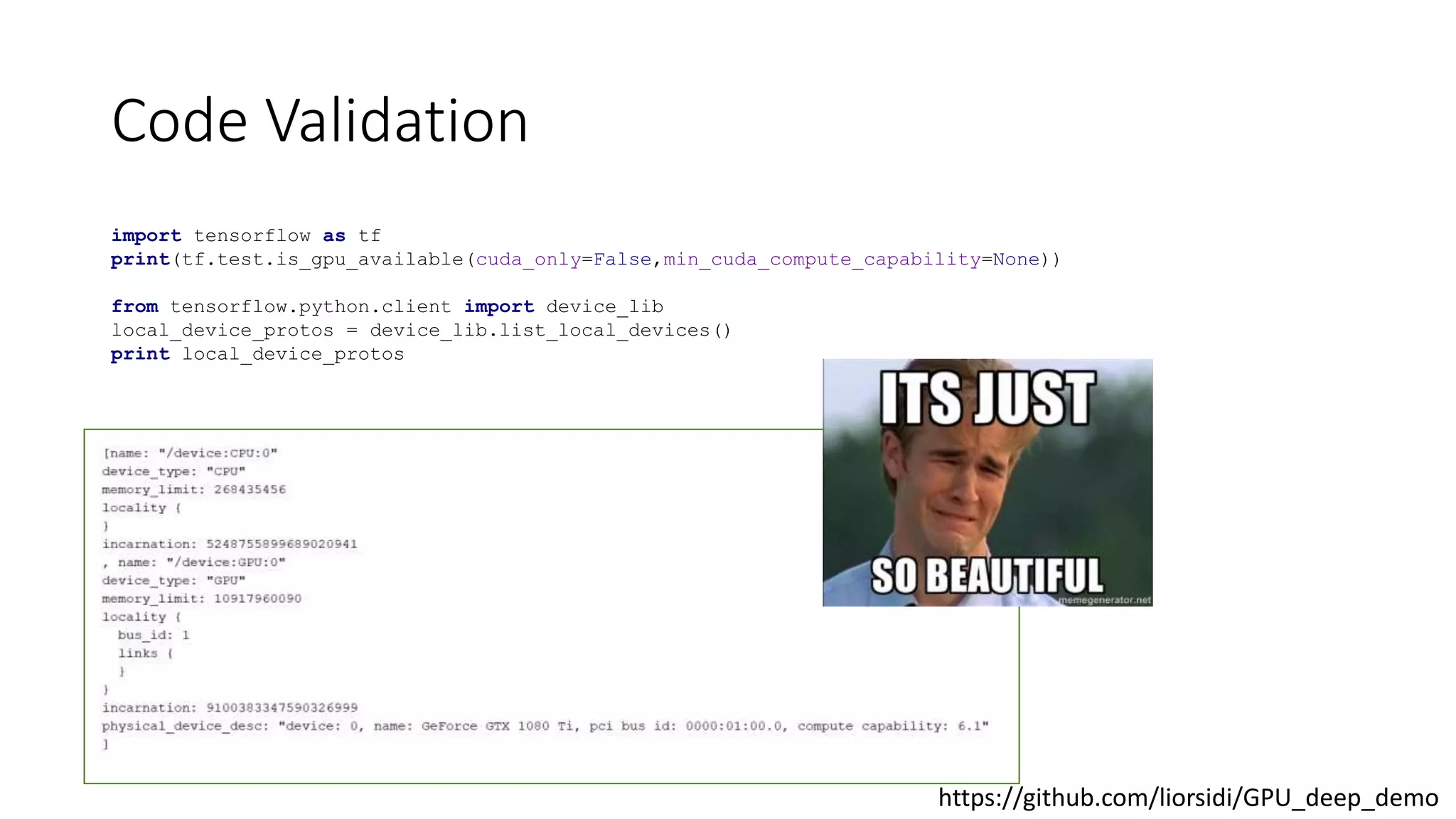
• Monitor your GPU (validate for every tf software update)
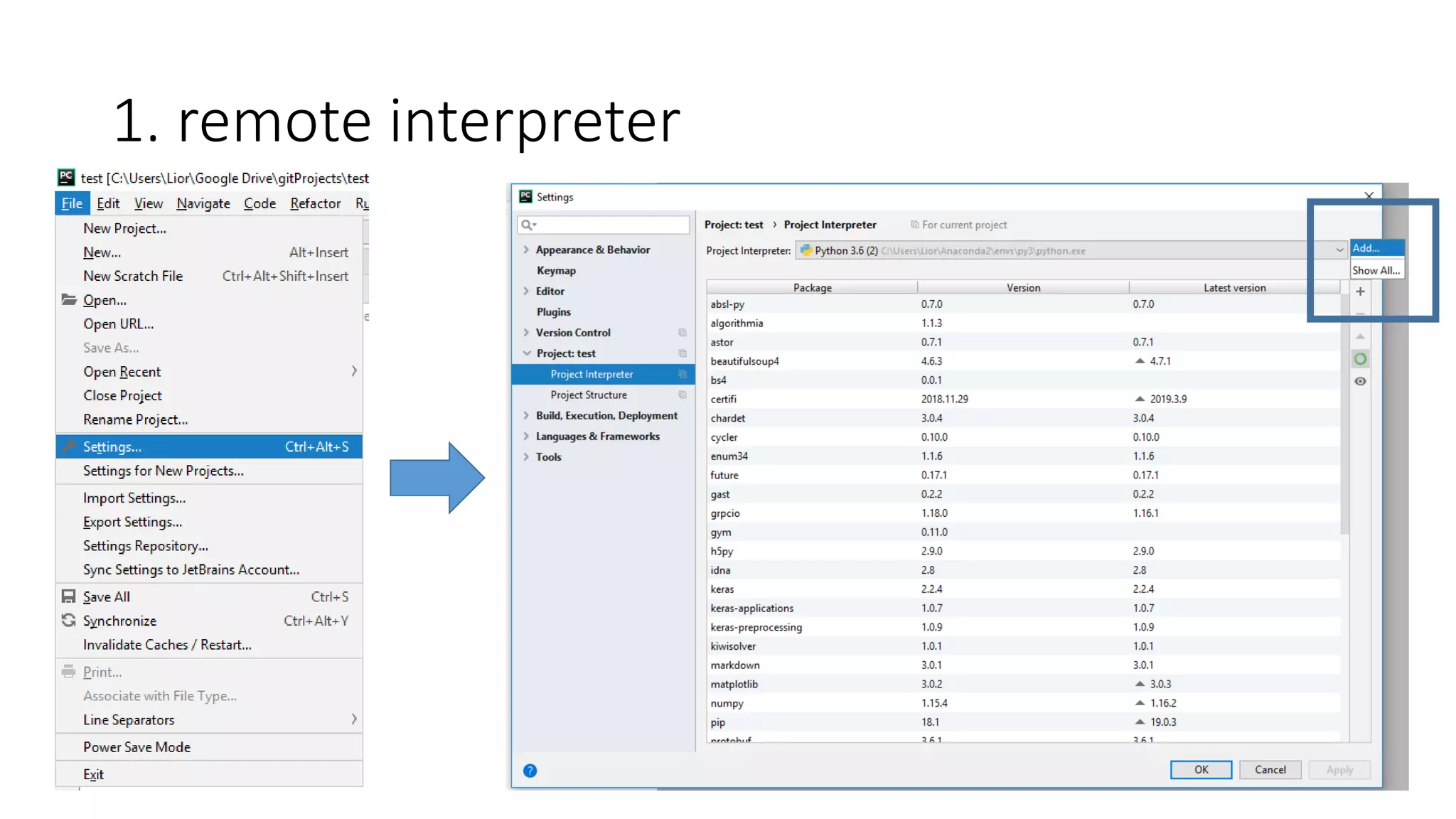
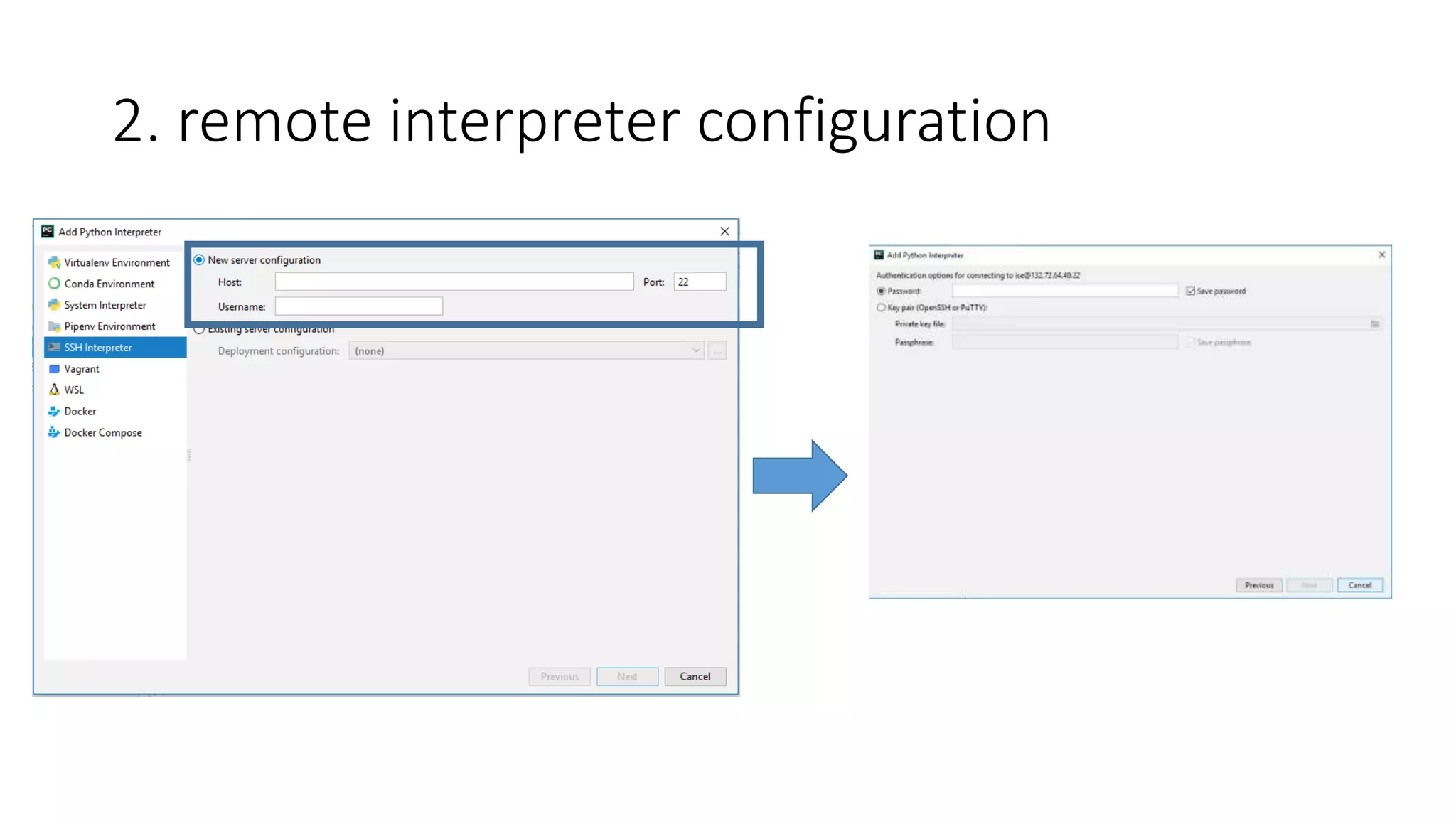
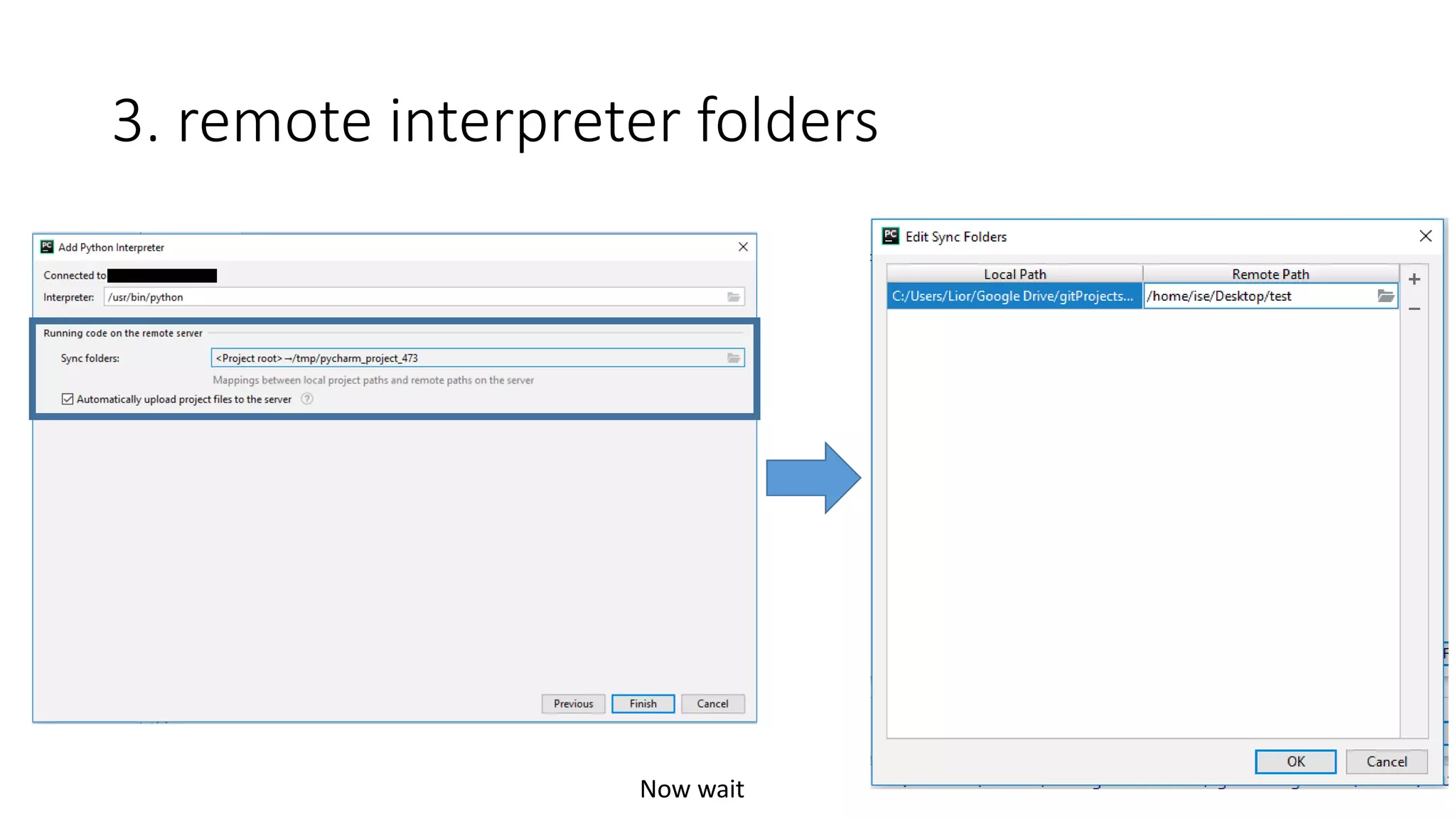
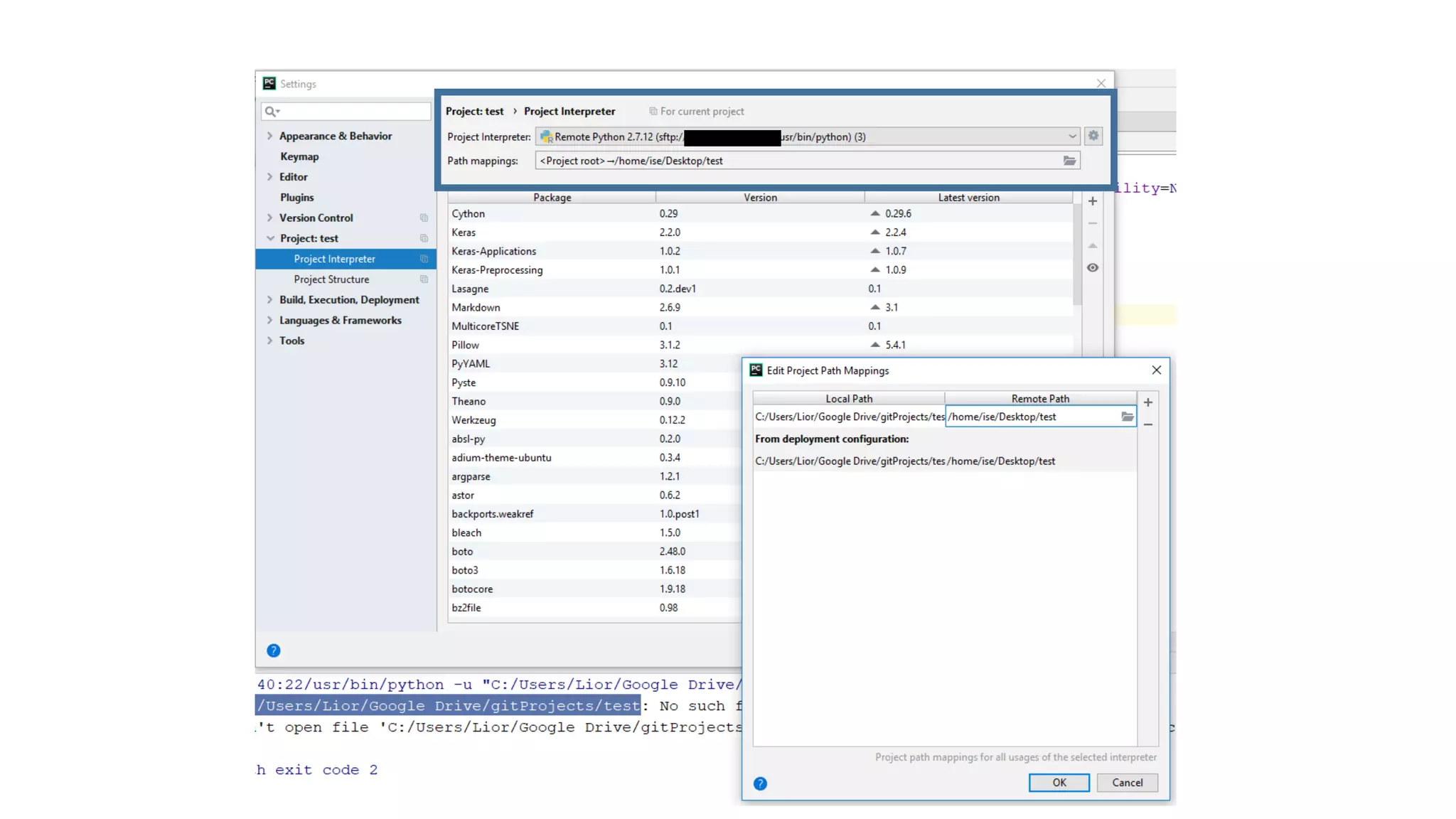
• Work with Pycharm – remote interpreter
• Separate between training and inference
• Consider using free cloud tier
• Fast.ai
Tips for winningdata hackathons
• Separate roles:
• Domain expert – explore the data, define features, read papers, metrics
• Data engineer – preprocess data, extract feature, evaluation pipeline
• Data scientist – algorithm development, evaluation, hyper tuning
• Evaluation – avoid overfitting - someone is trying to trick you
• Be consistent with your plan and feature exploration
• Limited data
• Augmentation
• Extreme regularizations
• Creativity
• Think out of the box
• Use state of the art tools
• Save time and rest











































![Inference – Spark Code
import pandas as pd
from keras.models import load_model, Sequential
from pyspark.sql.types import Row
def keras_spark_predict(model_path, weights_path, partition):
# load model
model = Sequential.from_config(model_path.value)
model.set_weights(weights_path.value)
# Create a list containing features.
featurs_list = map(lambda x: [x[:]], partition)
featurs_df = pd.DataFrame(featurs_list)
# predict with keras model
predictions = model.predict_on_batch(featurs_df)
predictions_return = map(lambda prediction: Row(prediction=prediction[0].item()), predictions)
return iter(predictions_return)
rdd = rdd.mapPartitions(lambda partition: keras_spark_predict(model_path, weights_path, partition))
https://github.com/liorsidi/GPU_deep_demo](https://image.slidesharecdn.com/gpudeep-190518140310/75/GPU-and-Deep-learning-best-practices-73-2048.jpg)






![Back to the Demo
#https://stackoverflow.com/questions/43137288/how-to-determine-needed-memory-of-keras-model
def get_model_memory_usage(batch_size, model):
import numpy as np
from keras import backend as K
shapes_mem_count = 0
for l in model.layers:
single_layer_mem = 1
for s in l.output_shape:
if s is None:
continue
single_layer_mem *= s
shapes_mem_count += single_layer_mem
trainable_count = np.sum([K.count_params(p) for p in set(model.trainable_weights)])
non_trainable_count = np.sum([K.count_params(p) for p in set(model.non_trainable_weights)])
number_size = 4.0
if K.floatx() == 'float16':
number_size = 2.0
if K.floatx() == 'float64':
number_size = 8.0
total_memory = number_size*(batch_size*shapes_mem_count + trainable_count + non_trainable_count)
gbytes = np.round(total_memory / (1024.0 ** 3), 3)
return gbytes
https://github.com/liorsidi/GPU_deep_demo](https://image.slidesharecdn.com/gpudeep-190518140310/75/GPU-and-Deep-learning-best-practices-82-2048.jpg)











































































![Inference – Spark Code
import pandas as pd
from keras.models import load_model, Sequential
from pyspark.sql.types import Row
def keras_spark_predict(model_path, weights_path, partition):
# load model
model = Sequential.from_config(model_path.value)
model.set_weights(weights_path.value)
# Create a list containing features.
featurs_list = map(lambda x: [x[:]], partition)
featurs_df = pd.DataFrame(featurs_list)
# predict with keras model
predictions = model.predict_on_batch(featurs_df)
predictions_return = map(lambda prediction: Row(prediction=prediction[0].item()), predictions)
return iter(predictions_return)
rdd = rdd.mapPartitions(lambda partition: keras_spark_predict(model_path, weights_path, partition))
https://github.com/liorsidi/GPU_deep_demo](https://crownmelresort.com/image.slidesharecdn.com/gpudeep-190518140310/75/GPU-and-Deep-learning-best-practices-73-2048.jpg)








![Back to the Demo
#https://stackoverflow.com/questions/43137288/how-to-determine-needed-memory-of-keras-model
def get_model_memory_usage(batch_size, model):
import numpy as np
from keras import backend as K
shapes_mem_count = 0
for l in model.layers:
single_layer_mem = 1
for s in l.output_shape:
if s is None:
continue
single_layer_mem *= s
shapes_mem_count += single_layer_mem
trainable_count = np.sum([K.count_params(p) for p in set(model.trainable_weights)])
non_trainable_count = np.sum([K.count_params(p) for p in set(model.non_trainable_weights)])
number_size = 4.0
if K.floatx() == 'float16':
number_size = 2.0
if K.floatx() == 'float64':
number_size = 8.0
total_memory = number_size*(batch_size*shapes_mem_count + trainable_count + non_trainable_count)
gbytes = np.round(total_memory / (1024.0 ** 3), 3)
return gbytes
https://github.com/liorsidi/GPU_deep_demo](https://crownmelresort.com/image.slidesharecdn.com/gpudeep-190518140310/75/GPU-and-Deep-learning-best-practices-82-2048.jpg)






































































