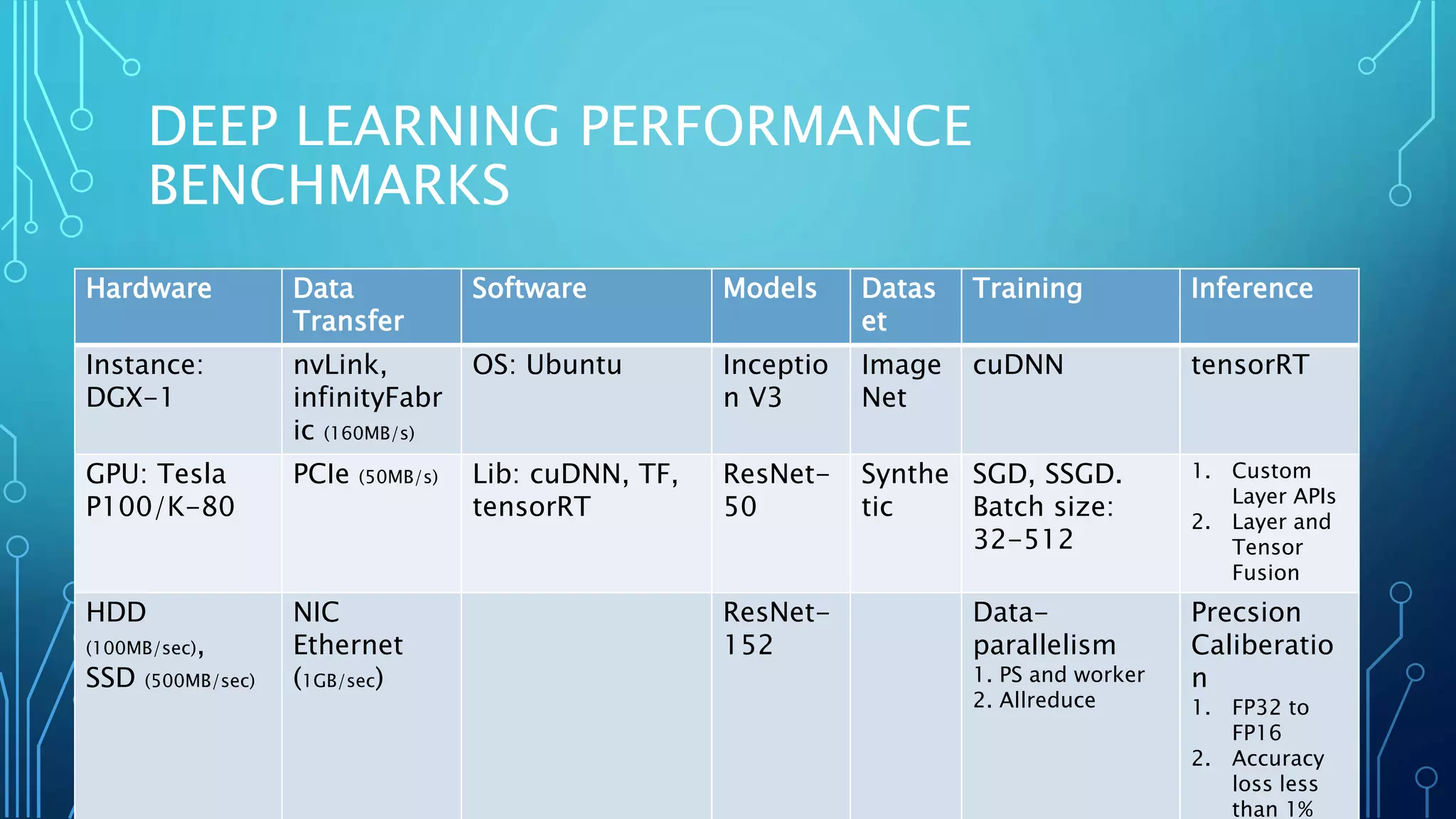
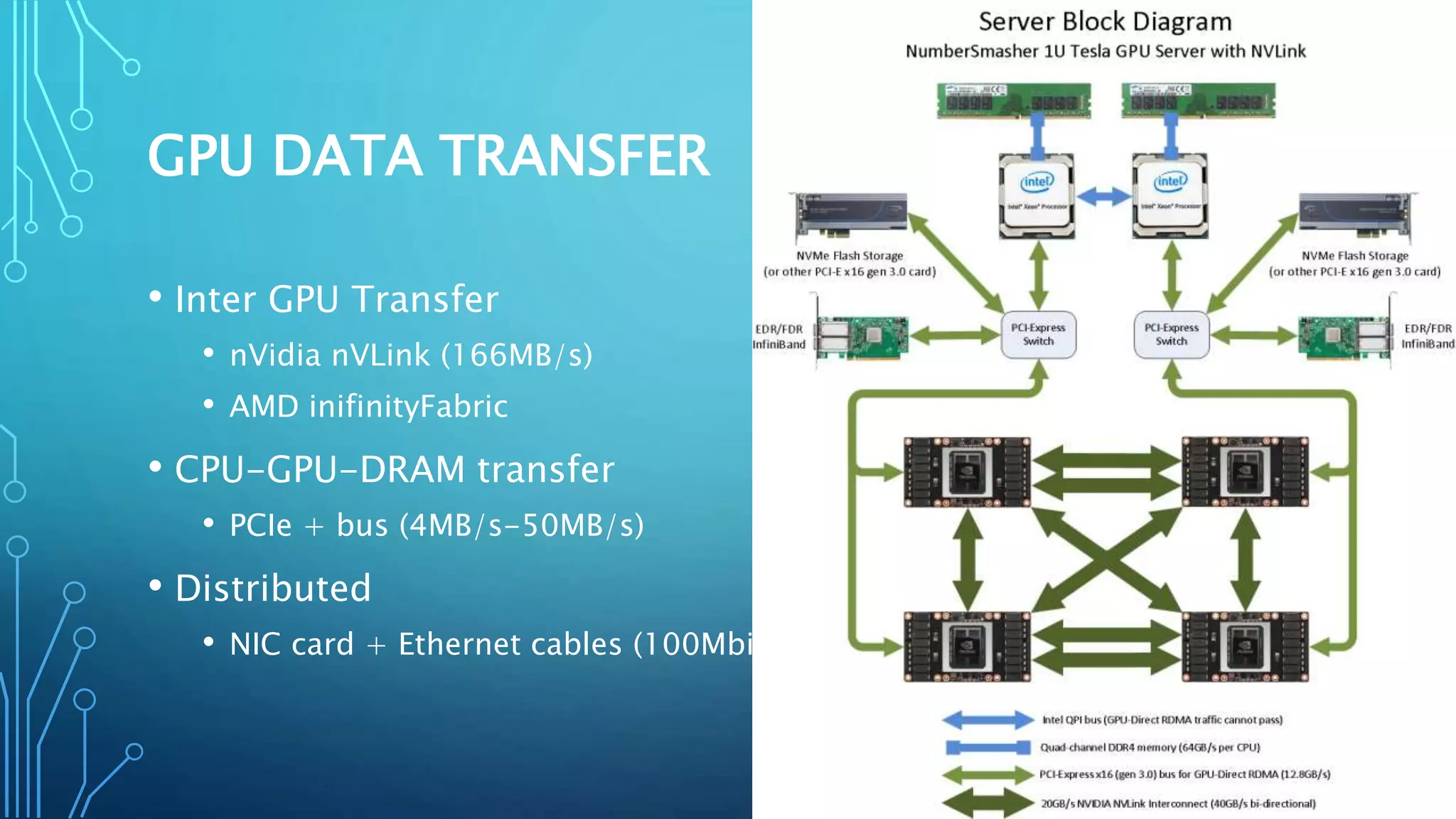
The document discusses the use of GPUs for accelerating machine learning applications, detailing performance benchmarks, hardware considerations, and data transfer techniques. It covers deep learning distribution strategies, optimization methods, and parallelism approaches such as data parallelism and all-reduce. Additionally, it highlights the benefits and challenges of deploying deep learning models using frameworks like cuDNN and TensorRT, focusing on high throughput, low latency, and power efficiency.






















































































![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)









