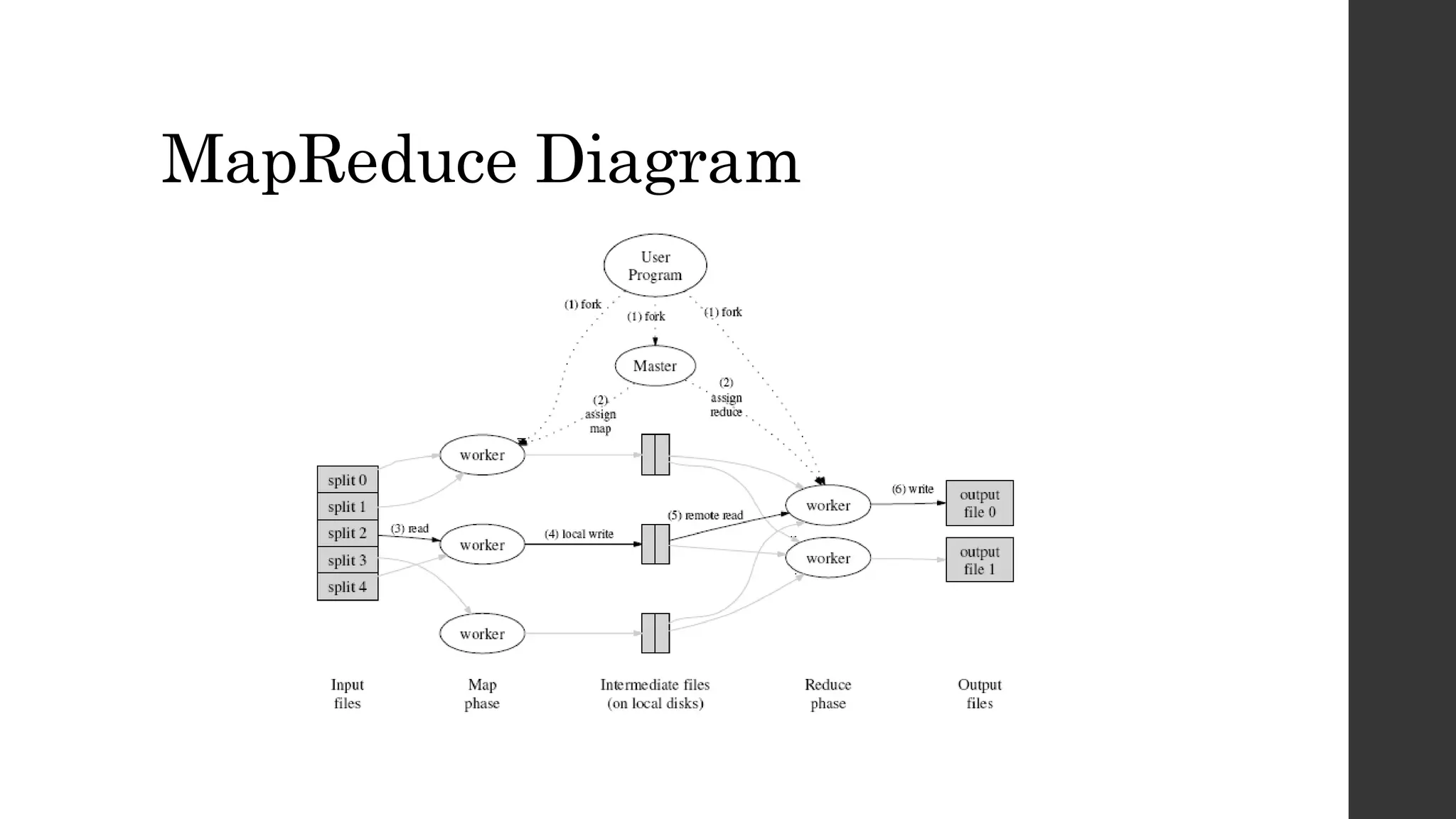
This document proposes CSMR, a scalable algorithm for text clustering that uses cosine similarity and MapReduce. CSMR performs pairwise text similarity by representing text documents as vectors in a vector space model and measuring similarity in parallel using MapReduce. It is a 4-phase algorithm that includes word counting, text vectorization using term frequencies, applying TF-IDF to document vectors, and measuring cosine similarity. The algorithm is designed to cluster large text corpora in a scalable manner on distributed systems like Hadoop. Future work includes implementing and testing CSMR on real data and publishing results.








![Phase 1: Word Counting
Algorithm 1: Word Count
1: class Mapper
2: method Map( document )
3: for each term ∈ document
4: write ( ( term , docId ) , 1 )
5:
6: class Reducer
7: method Reduce( ( term , docId ) , ones[ 1 , 1 , … , n ] )
8: sum = 0
9: for each one ∈ ones do
10: sum = sum +1
11: return ( ( term , docId ) , o )
12:
13: /* { o ∈ N : the number of occurrences } */](https://image.slidesharecdn.com/csmr-141107170606-conversion-gate02/75/CSMR-A-Scalable-Algorithm-for-Text-Clustering-with-Cosine-Similarity-and-MapReduce-10-2048.jpg)


![Phase 4: Cosine Similarity
Algorithm 4: Cosine Similarity
1: class Mapper
2: method Map( docs )
3: n = docs.length
4:
5: for i = 0 to docs.length
6: for j = i+1 to docs.length
7: write ( ( docs[i].id, docs[j].id ),( docs[i].tfidf, docs[j].tfidf ) )
8:
9: class Reducer
10: method Reduce( ( docId_A, docId_B ),( docA.tfidf, docB.tfidf ) )
11: A = docA.tfidf
12: B = docB.tfidf
13: cosine = sum( A×B )/ (sqrt( sum(A2) )× sqrt( sum(B2) ))
14: return ( (docId_A, docId_B), cosine )](https://image.slidesharecdn.com/csmr-141107170606-conversion-gate02/75/CSMR-A-Scalable-Algorithm-for-Text-Clustering-with-Cosine-Similarity-and-MapReduce-13-2048.jpg)
![Phase 4: Diagram
Map
Doc1,Doc2
[Doc1 TF-IDF], [Doc2 TF-IDF]
Doc1,Doc3
[Doc1 TF-IDF], [Doc3 TF-IDF]
Doc1,Doc4
Input [Doc1 TF-IDF], [Doc4 TF-IDF]
Output
Doc4,Doc10
[Doc4 TF-IDF], [Doc10 TF-IDF]
DocM,DocN
[DocM TF-IDF], [DocN TF-IDF]
Reduce
Doc1,Doc3
Cosine(Doc1, Doc3)
Doc1,Doc4
Cosine(Doc1 ,Doc4)
Doc4,Doc10
Cosine(Doc4, Doc10)
DocM,DocN
Cosine(DocM, DocN)
Doc1,Doc2
Cosine(Doc1, Doc2)](https://image.slidesharecdn.com/csmr-141107170606-conversion-gate02/75/CSMR-A-Scalable-Algorithm-for-Text-Clustering-with-Cosine-Similarity-and-MapReduce-14-2048.jpg)










![Phase 1: Word Counting
Algorithm 1: Word Count
1: class Mapper
2: method Map( document )
3: for each term ∈ document
4: write ( ( term , docId ) , 1 )
5:
6: class Reducer
7: method Reduce( ( term , docId ) , ones[ 1 , 1 , … , n ] )
8: sum = 0
9: for each one ∈ ones do
10: sum = sum +1
11: return ( ( term , docId ) , o )
12:
13: /* { o ∈ N : the number of occurrences } */](https://crownmelresort.com/image.slidesharecdn.com/csmr-141107170606-conversion-gate02/75/CSMR-A-Scalable-Algorithm-for-Text-Clustering-with-Cosine-Similarity-and-MapReduce-10-2048.jpg)


![Phase 4: Cosine Similarity
Algorithm 4: Cosine Similarity
1: class Mapper
2: method Map( docs )
3: n = docs.length
4:
5: for i = 0 to docs.length
6: for j = i+1 to docs.length
7: write ( ( docs[i].id, docs[j].id ),( docs[i].tfidf, docs[j].tfidf ) )
8:
9: class Reducer
10: method Reduce( ( docId_A, docId_B ),( docA.tfidf, docB.tfidf ) )
11: A = docA.tfidf
12: B = docB.tfidf
13: cosine = sum( A×B )/ (sqrt( sum(A2) )× sqrt( sum(B2) ))
14: return ( (docId_A, docId_B), cosine )](https://crownmelresort.com/image.slidesharecdn.com/csmr-141107170606-conversion-gate02/75/CSMR-A-Scalable-Algorithm-for-Text-Clustering-with-Cosine-Similarity-and-MapReduce-13-2048.jpg)
![Phase 4: Diagram
Map
Doc1,Doc2
[Doc1 TF-IDF], [Doc2 TF-IDF]
Doc1,Doc3
[Doc1 TF-IDF], [Doc3 TF-IDF]
Doc1,Doc4
Input [Doc1 TF-IDF], [Doc4 TF-IDF]
Output
Doc4,Doc10
[Doc4 TF-IDF], [Doc10 TF-IDF]
DocM,DocN
[DocM TF-IDF], [DocN TF-IDF]
Reduce
Doc1,Doc3
Cosine(Doc1, Doc3)
Doc1,Doc4
Cosine(Doc1 ,Doc4)
Doc4,Doc10
Cosine(Doc4, Doc10)
DocM,DocN
Cosine(DocM, DocN)
Doc1,Doc2
Cosine(Doc1, Doc2)](https://crownmelresort.com/image.slidesharecdn.com/csmr-141107170606-conversion-gate02/75/CSMR-A-Scalable-Algorithm-for-Text-Clustering-with-Cosine-Similarity-and-MapReduce-14-2048.jpg)























































































