This document summarizes an algorithm to detect algorithm names in computer science research papers. It involves converting PDFs to text, performing named entity recognition to extract noun phrases, filtering entities to remove author names and locations, and using a word2vec model trained on computer science papers to classify extracted tokens as true algorithm names or noisy data by comparing their similarity to known positives and negatives. The top similar words are used to label each token as a true or false positive for an algorithm name.
![Algorithm Name Detection
in Computer Science Research Papers
Information Retrieval & Extraction Course
IIIT HYDERABAD
Submitted To: Prof. Vasudev Verma
Submission By: Team 41
Allaparthi Sriteja [201302139]
Deeksha Singh Thakur [201505627]
Sneh gupta [201302201]](https://image.slidesharecdn.com/ire1-160415133440/75/Algorithm-Name-Detection-Extraction-1-2048.jpg)

![Converting pdf to text
Input : A research paper in the pdf format.
Output : Need to convert that pdf to text format.
Processing : Using PDFMiner
pdf2txt.py -O myoutput -o myoutput/myfile.text -t text myfile.pdf
Usage:
pdf2txt.py [options] filename.pdf
Options: -o output file name
-t output format (text/html/xml/tag[for Tagged PDFs])
-O dirname (triggers extraction of images from PDF into directory)](https://image.slidesharecdn.com/ire1-160415133440/75/Algorithm-Name-Detection-Extraction-3-2048.jpg)
![Named Entity Recognition
Input : Research paper in the text format.
Output : Noun phrases (NNPS and NNs)
Processing :
Sentence tokenization
Merging the divided words at the end of the line [ex: div - n ision]
Removing the part before the Abstract and after the Reference.
Find the citation sentences and extract them
Do pos_tagging for those sentences.
Now extract the NNPS and NN. combine the NNPS occurring adjacent to each other in a sentence.](https://image.slidesharecdn.com/ire1-160415133440/75/Algorithm-Name-Detection-Extraction-4-2048.jpg)




![WORD2VEC MODEL :
The word2vec model under consideration contains -
word2vec word vectors
trained on ~4.3lac computer science papers, 3.7B tokens
A 300 dimensional vector representation of all 1 word algorithm names
Used as model[‘word’] = {[300 dimension vector], dtype: float}](https://image.slidesharecdn.com/ire1-160415133440/75/Algorithm-Name-Detection-Extraction-9-2048.jpg)
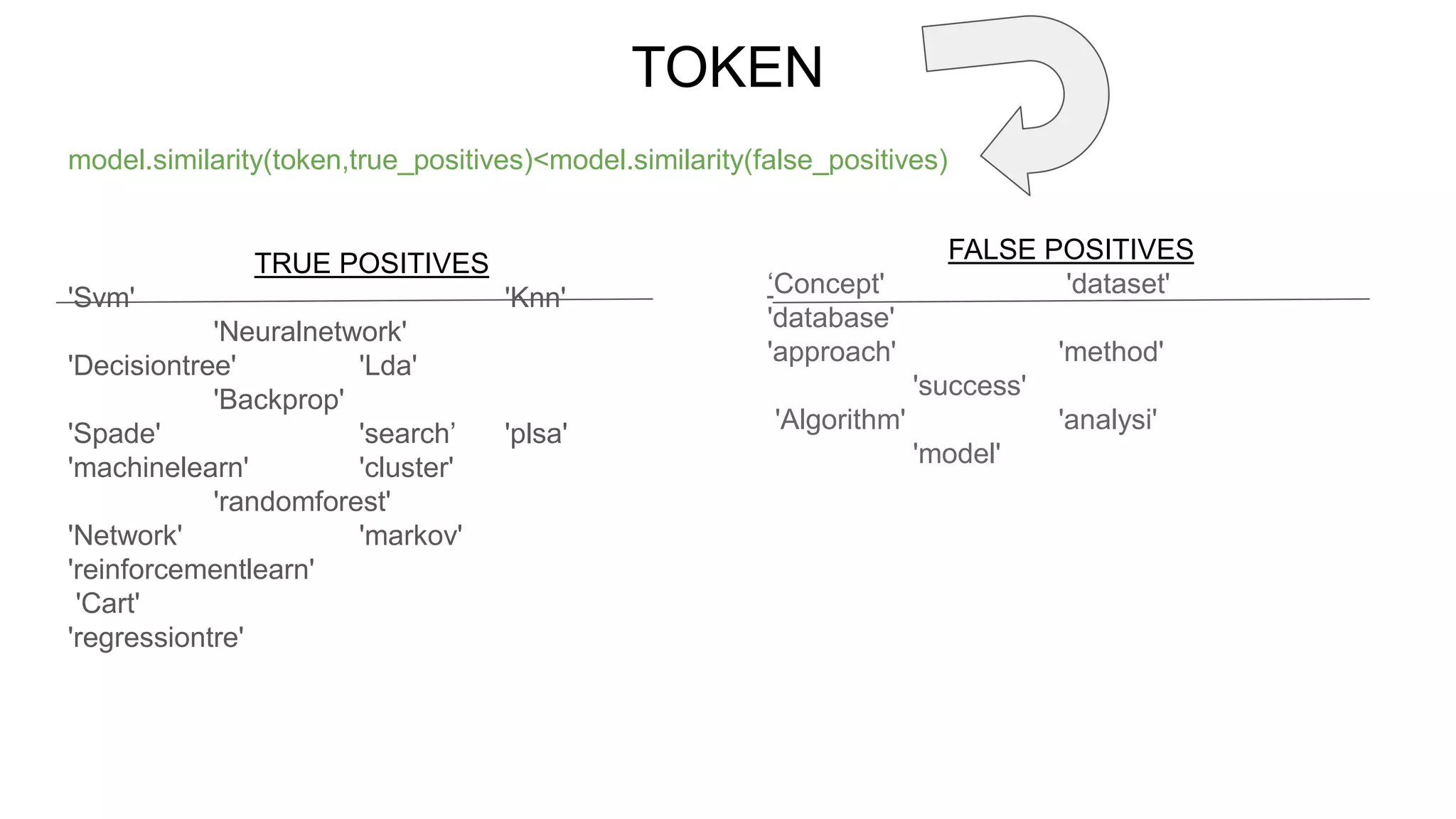
![Classifying the tokens :
Form a list,(manually by going through some papers) -
true positives[containing name of actual computer science algorithms]
false positives [most common noise components in each paper].
Compare each named entity extracted from paper with these lists of TPs and FPs
and find the similarity between them. If the similarity between a word and another
word in TP is greater than a threshold value (0.4 considered in our case), classify
it as the TP, otherwise FP.](https://image.slidesharecdn.com/ire1-160415133440/75/Algorithm-Name-Detection-Extraction-10-2048.jpg)
![Algorithm Name Detection
in Computer Science Research Papers
Information Retrieval & Extraction Course
IIIT HYDERABAD
Submitted To: Prof. Vasudev Verma
Submission By: Team 41
Allaparthi Sriteja [201302139]
Deeksha Singh Thakur [201505627]
Sneh gupta [201302201]](https://crownmelresort.com/image.slidesharecdn.com/ire1-160415133440/75/Algorithm-Name-Detection-Extraction-1-2048.jpg)

![Converting pdf to text
Input : A research paper in the pdf format.
Output : Need to convert that pdf to text format.
Processing : Using PDFMiner
pdf2txt.py -O myoutput -o myoutput/myfile.text -t text myfile.pdf
Usage:
pdf2txt.py [options] filename.pdf
Options: -o output file name
-t output format (text/html/xml/tag[for Tagged PDFs])
-O dirname (triggers extraction of images from PDF into directory)](https://crownmelresort.com/image.slidesharecdn.com/ire1-160415133440/75/Algorithm-Name-Detection-Extraction-3-2048.jpg)
![Named Entity Recognition
Input : Research paper in the text format.
Output : Noun phrases (NNPS and NNs)
Processing :
Sentence tokenization
Merging the divided words at the end of the line [ex: div - n ision]
Removing the part before the Abstract and after the Reference.
Find the citation sentences and extract them
Do pos_tagging for those sentences.
Now extract the NNPS and NN. combine the NNPS occurring adjacent to each other in a sentence.](https://crownmelresort.com/image.slidesharecdn.com/ire1-160415133440/75/Algorithm-Name-Detection-Extraction-4-2048.jpg)




![WORD2VEC MODEL :
The word2vec model under consideration contains -
word2vec word vectors
trained on ~4.3lac computer science papers, 3.7B tokens
A 300 dimensional vector representation of all 1 word algorithm names
Used as model[‘word’] = {[300 dimension vector], dtype: float}](https://crownmelresort.com/image.slidesharecdn.com/ire1-160415133440/75/Algorithm-Name-Detection-Extraction-9-2048.jpg)
![Classifying the tokens :
Form a list,(manually by going through some papers) -
true positives[containing name of actual computer science algorithms]
false positives [most common noise components in each paper].
Compare each named entity extracted from paper with these lists of TPs and FPs
and find the similarity between them. If the similarity between a word and another
word in TP is greater than a threshold value (0.4 considered in our case), classify
it as the TP, otherwise FP.](https://crownmelresort.com/image.slidesharecdn.com/ire1-160415133440/75/Algorithm-Name-Detection-Extraction-10-2048.jpg)












































![[EN] Capture Indexing & Auto-Classification | DLM Forum Industry Whitepaper 0...](https://cdn.slidesharecdn.com/ss_thumbnails/dlmforumindustrywhitepaper01captureindexingauto-classificationser20020618-150824091618-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)











































