Downloaded 33 times






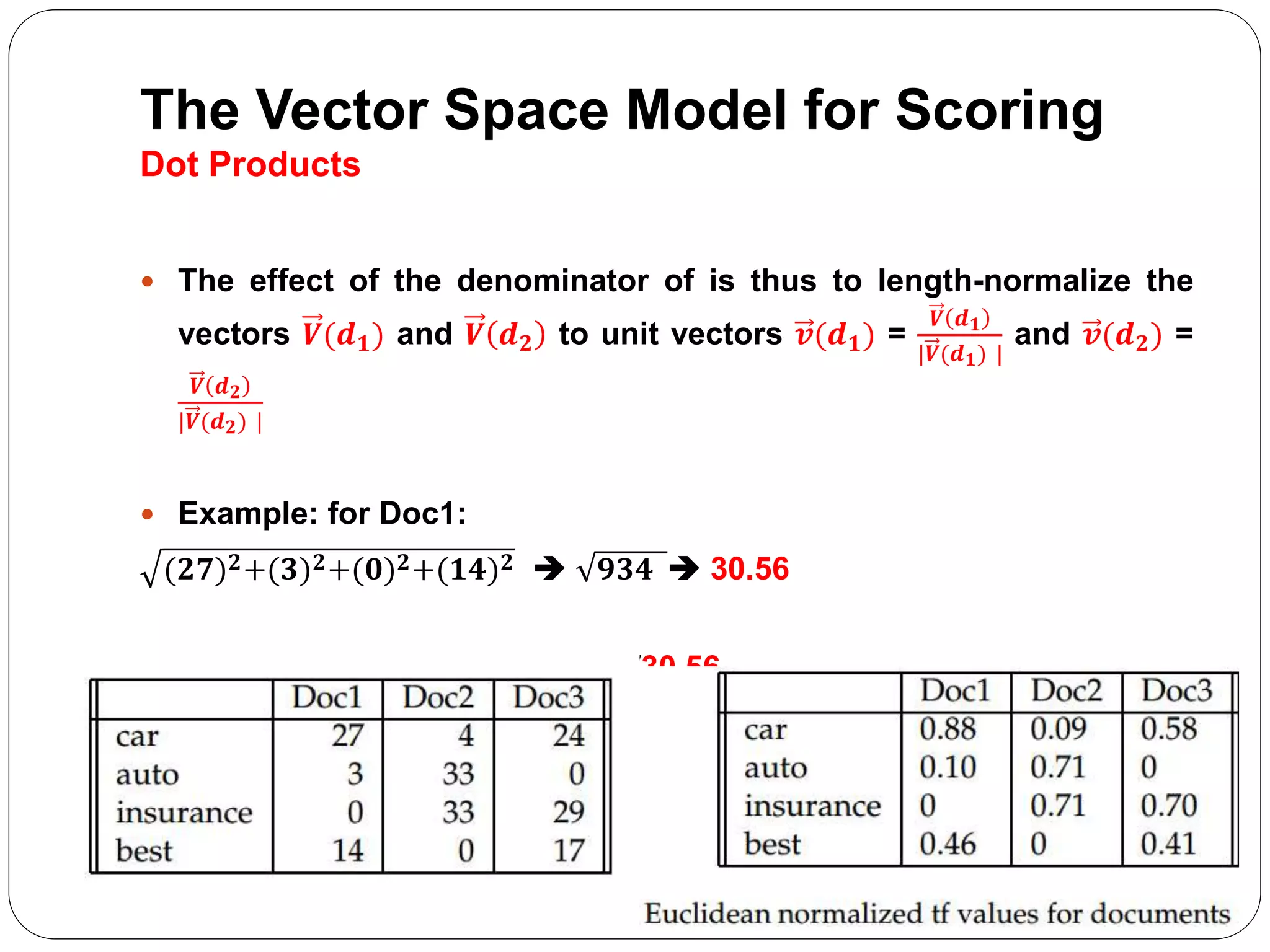
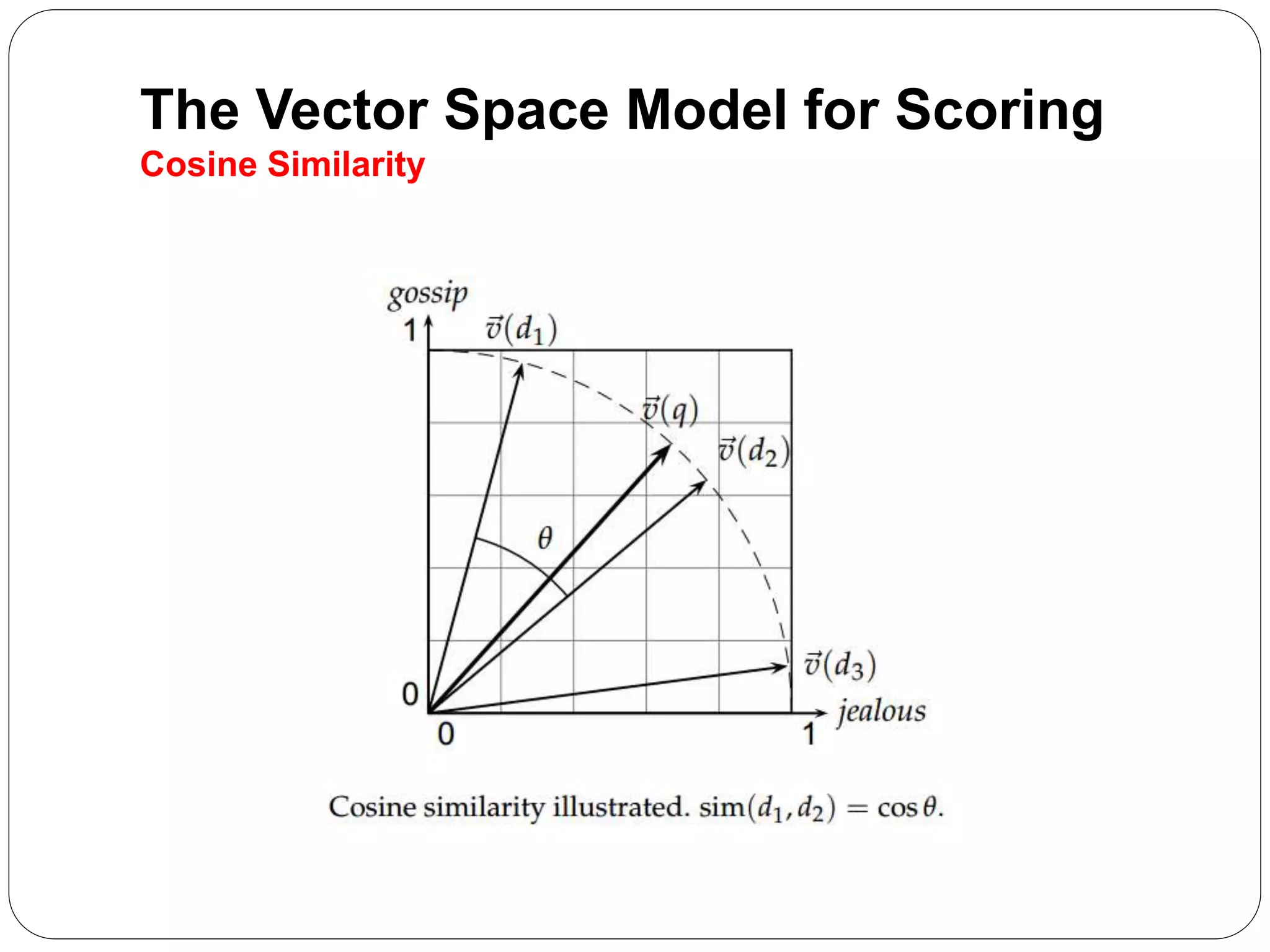
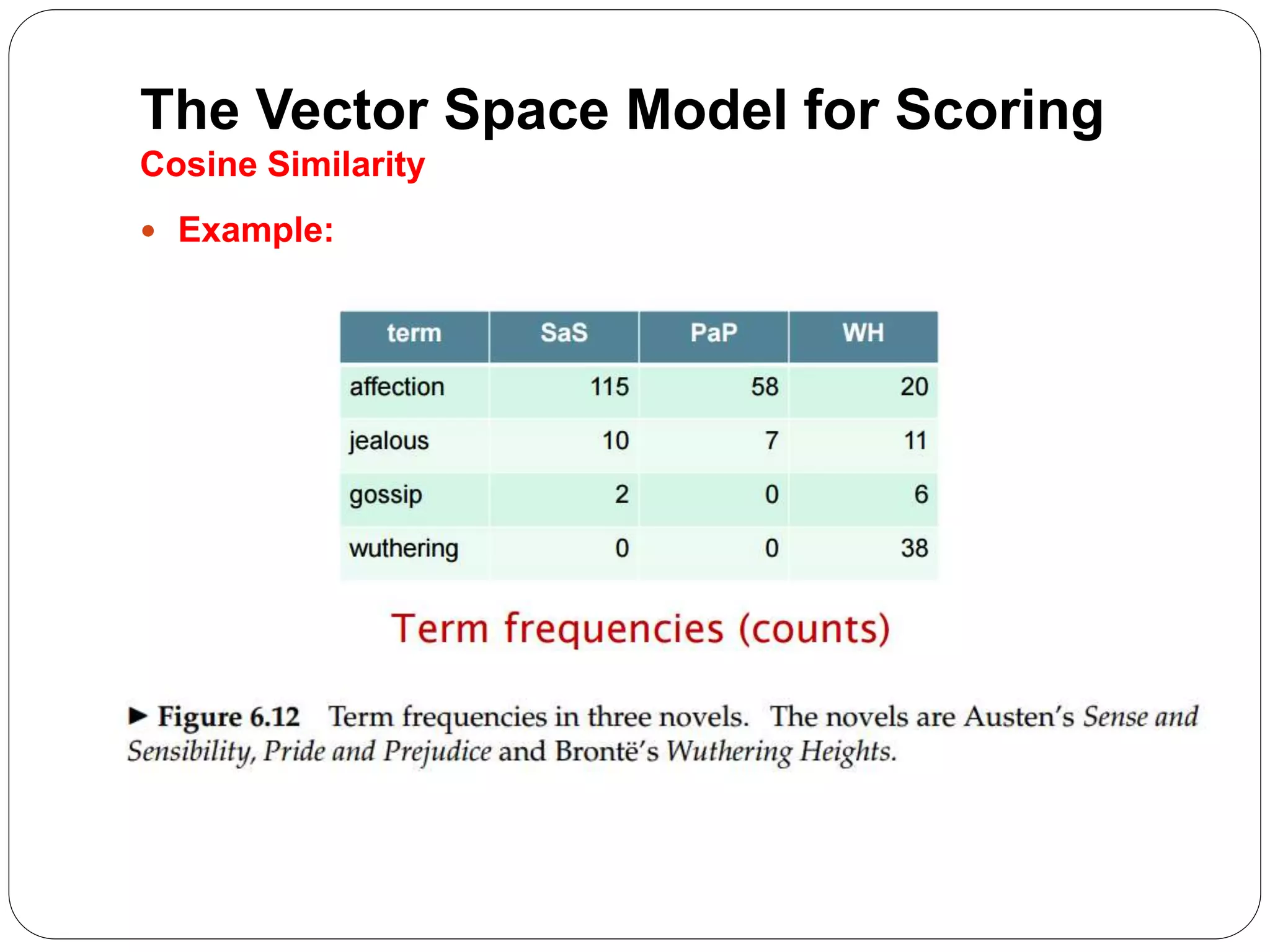
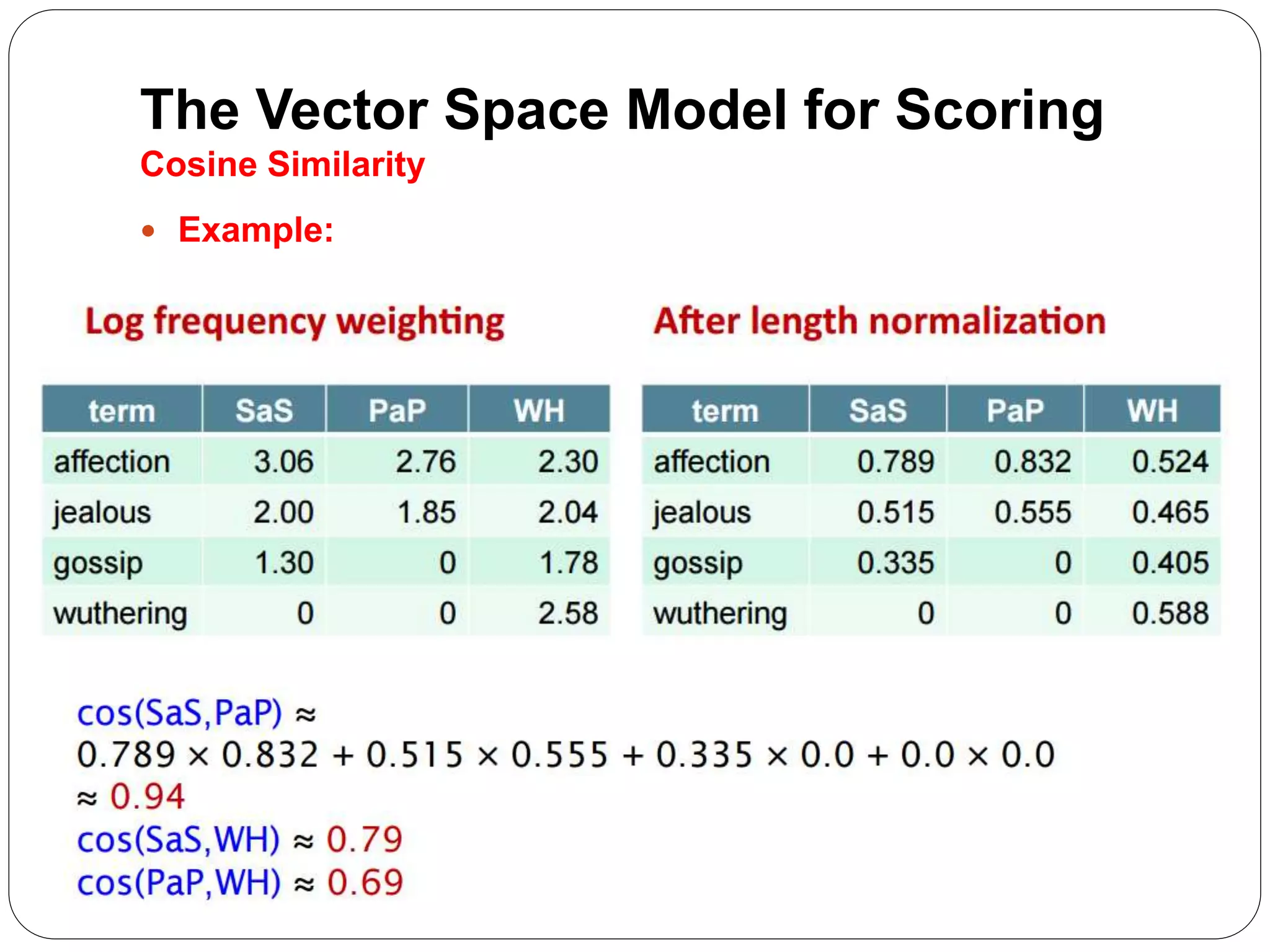


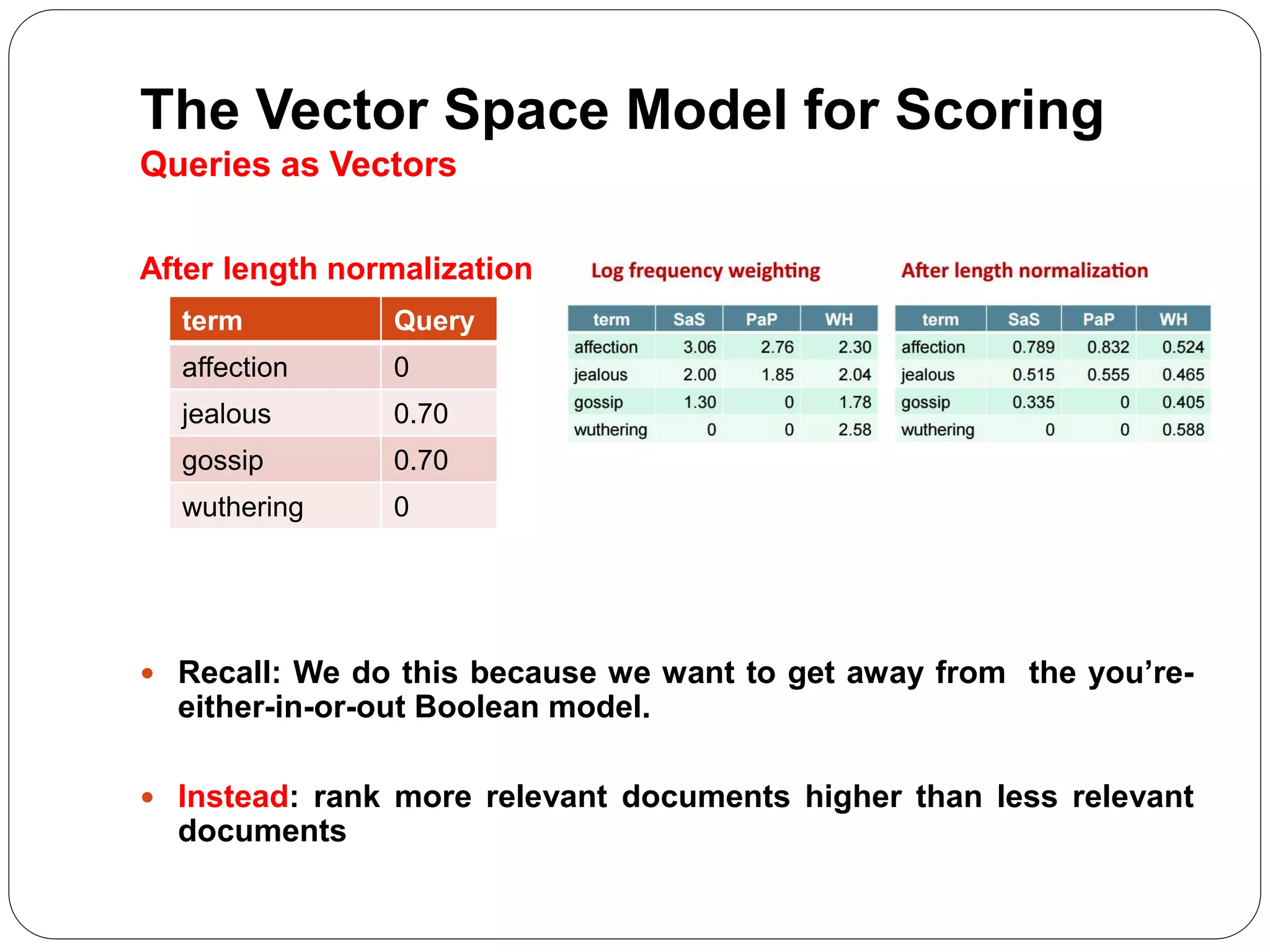

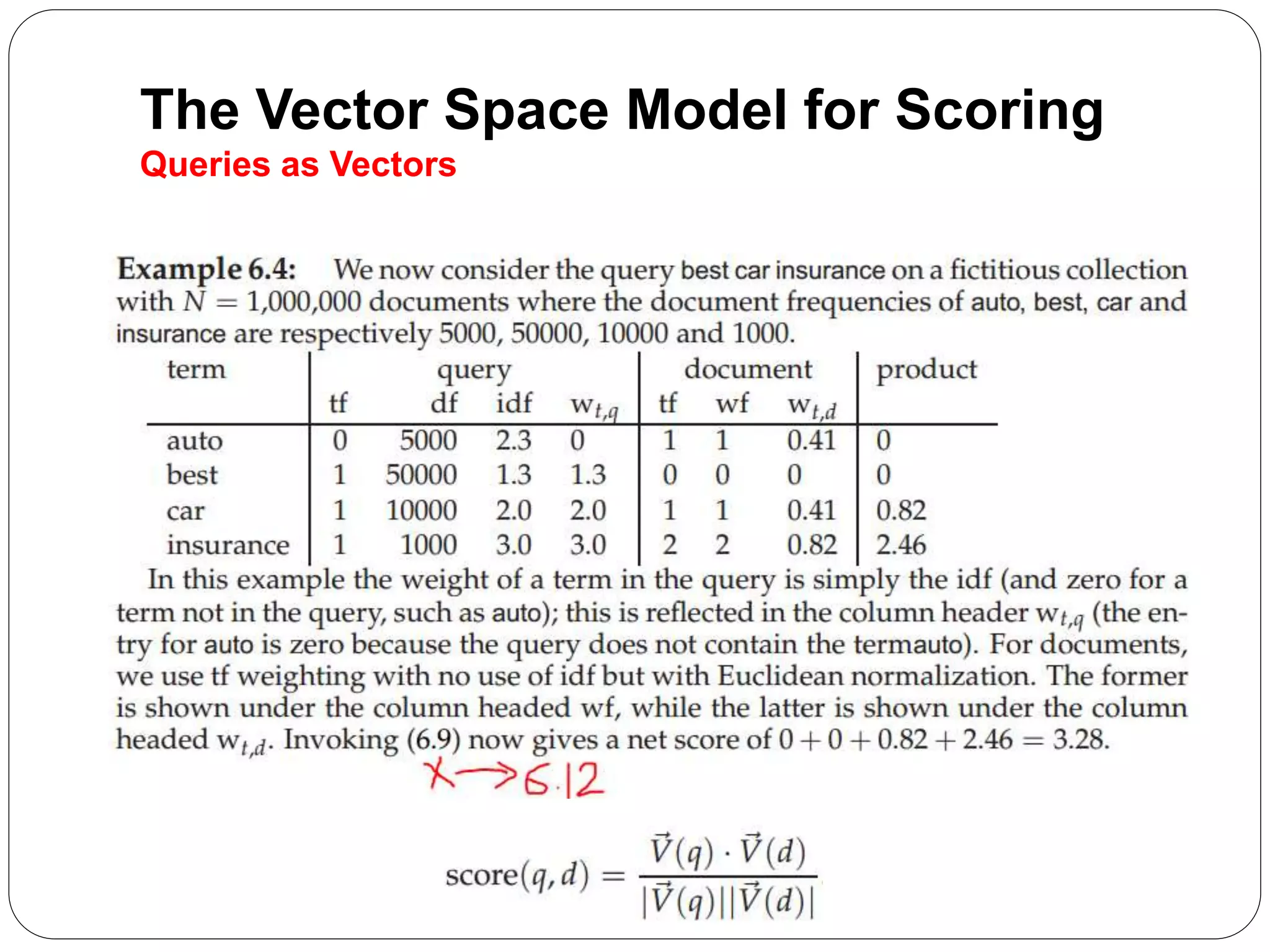
























The document summarizes the vector space model for scoring and ranking documents in response to a query in an information retrieval system. It explains that in this model, documents and queries are represented as vectors in a common vector space. The similarity between a document and query vector is measured by calculating the cosine similarity of the two vectors, which scores and ranks documents based on the terms they share with the query. It also describes how the vector space model allows retrieving the top K documents by relevance rather than using a Boolean retrieval model.









































































































