Download as PDF, PPTX














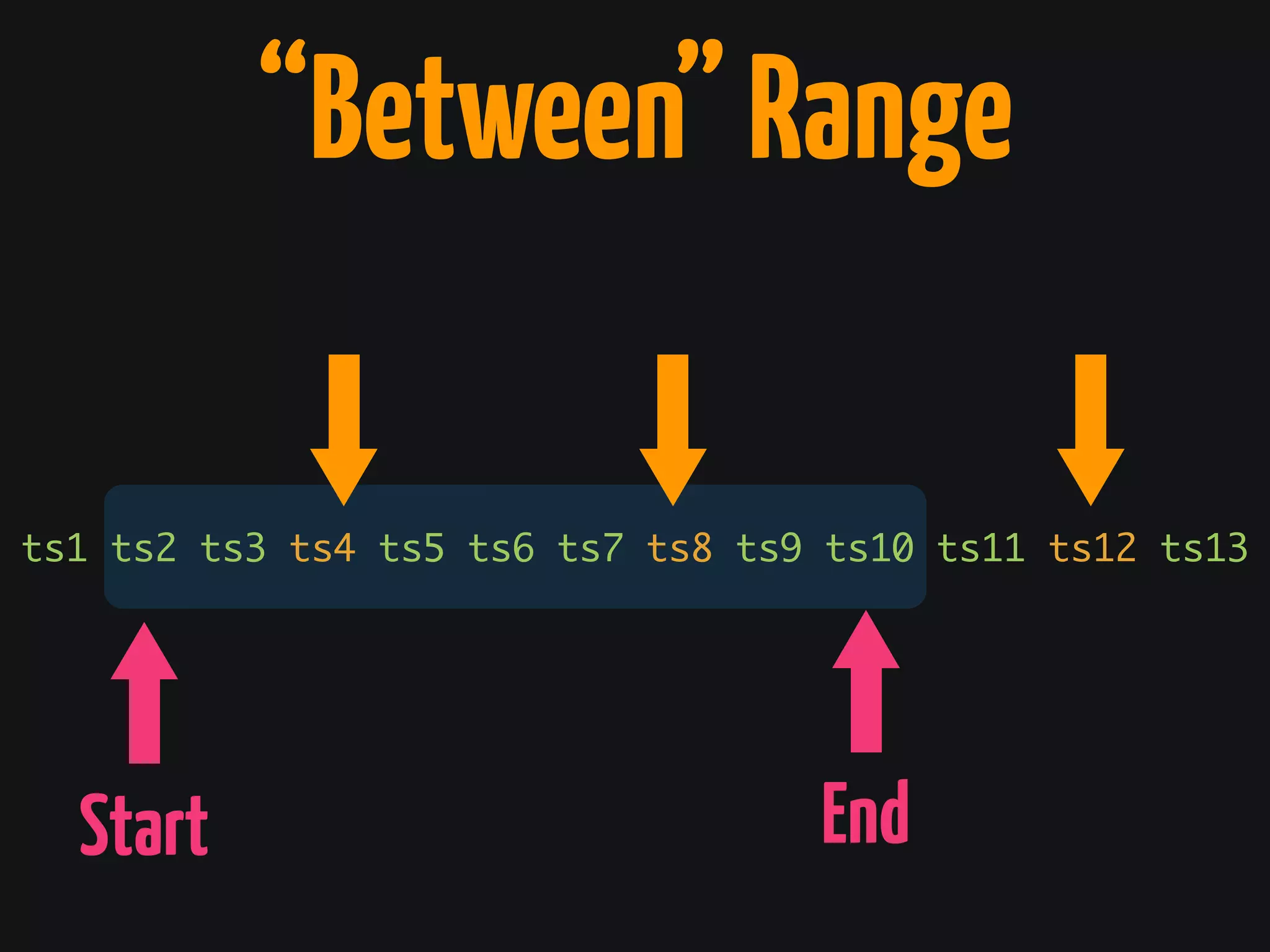

















![[ α1 α1 α1 ...αn ] ρ](https://image.slidesharecdn.com/cassandrasummit2015-dataanalyticswithcassandraandclojure-151002213523-lva1-app6891/75/codecentric-AG-Using-Cassandra-and-Clojure-for-Data-Crunching-backends-44-2048.jpg)





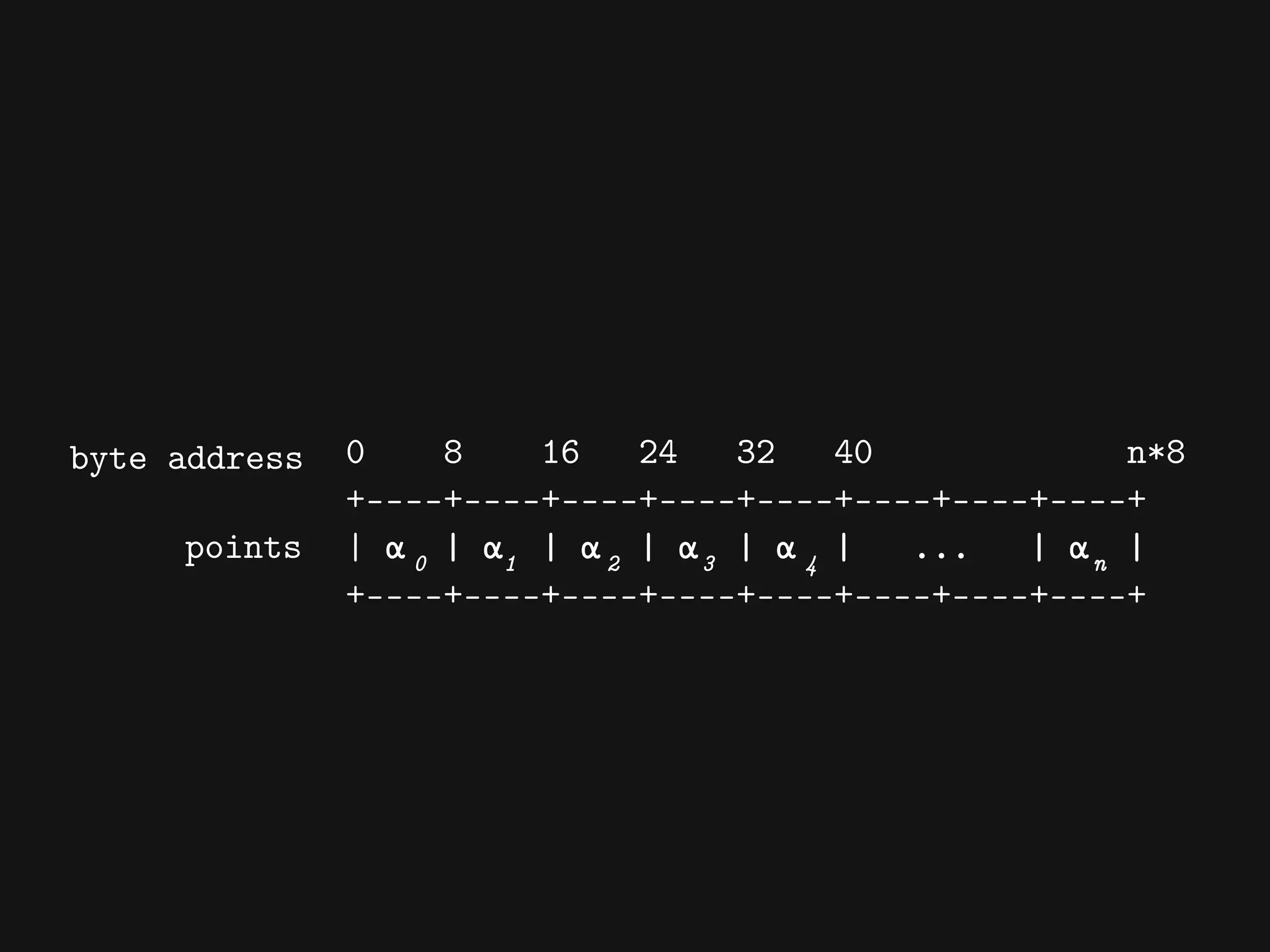

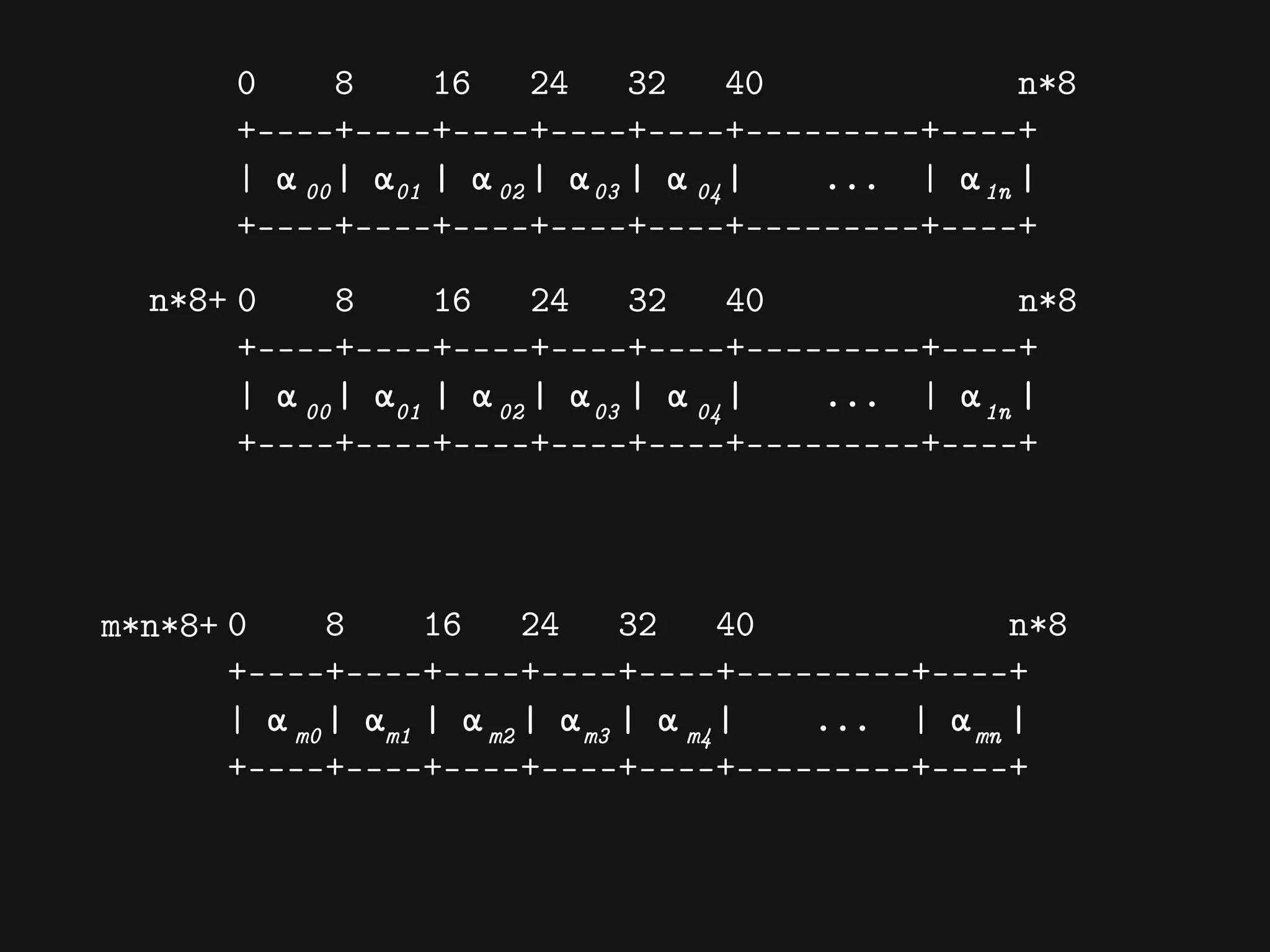


![[[Mean(x1), Var(x1)]
[Mean(x2), Var(x3)]
...
[Mean(xn), Var(xn)]]](https://image.slidesharecdn.com/cassandrasummit2015-dataanalyticswithcassandraandclojure-151002213523-lva1-app6891/75/codecentric-AG-Using-Cassandra-and-Clojure-for-Data-Crunching-backends-56-2048.jpg)








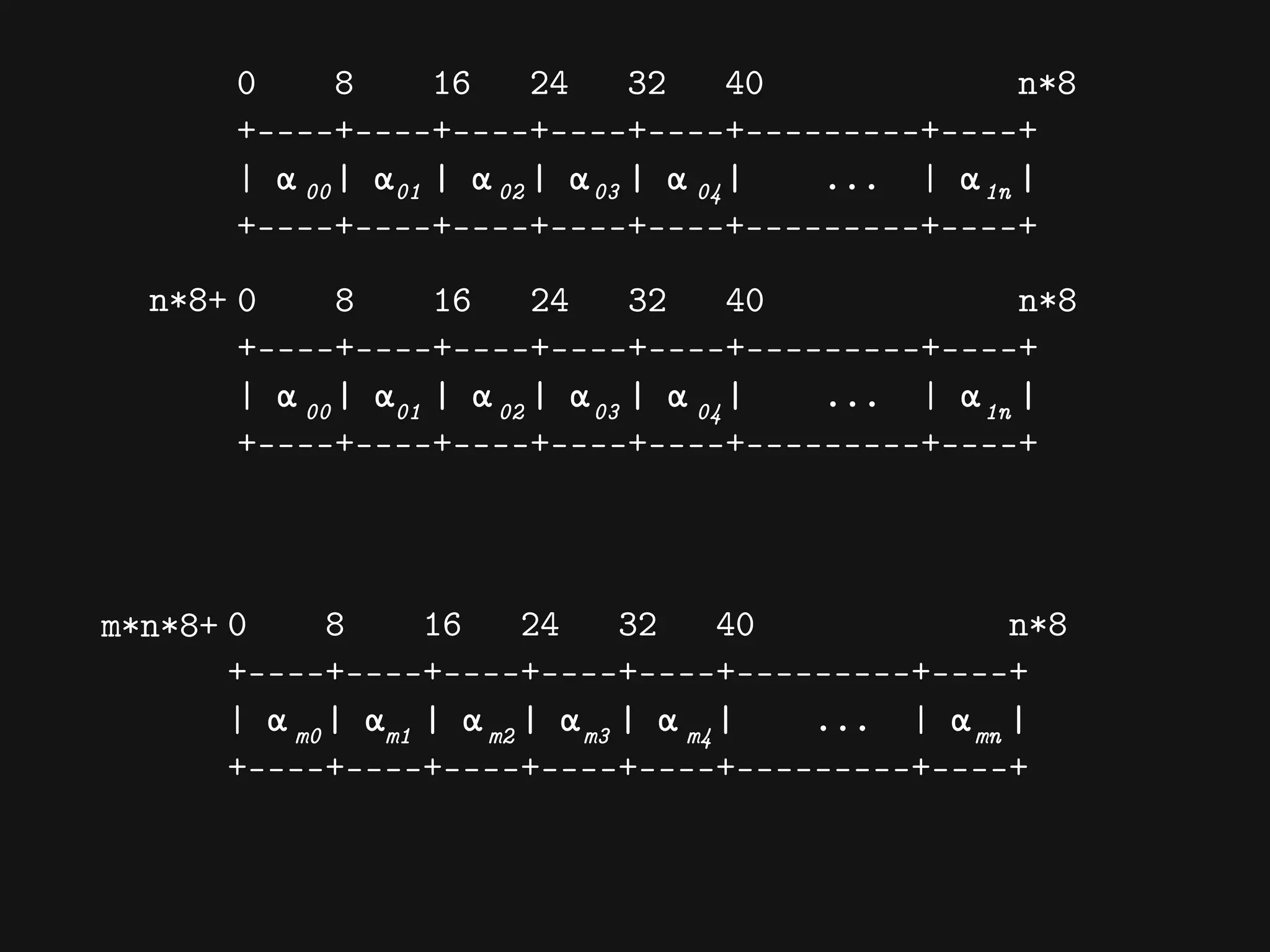















































![[ α1 α1 α1 ...αn ] ρ](https://crownmelresort.com/image.slidesharecdn.com/cassandrasummit2015-dataanalyticswithcassandraandclojure-151002213523-lva1-app6891/75/codecentric-AG-Using-Cassandra-and-Clojure-for-Data-Crunching-backends-44-2048.jpg)











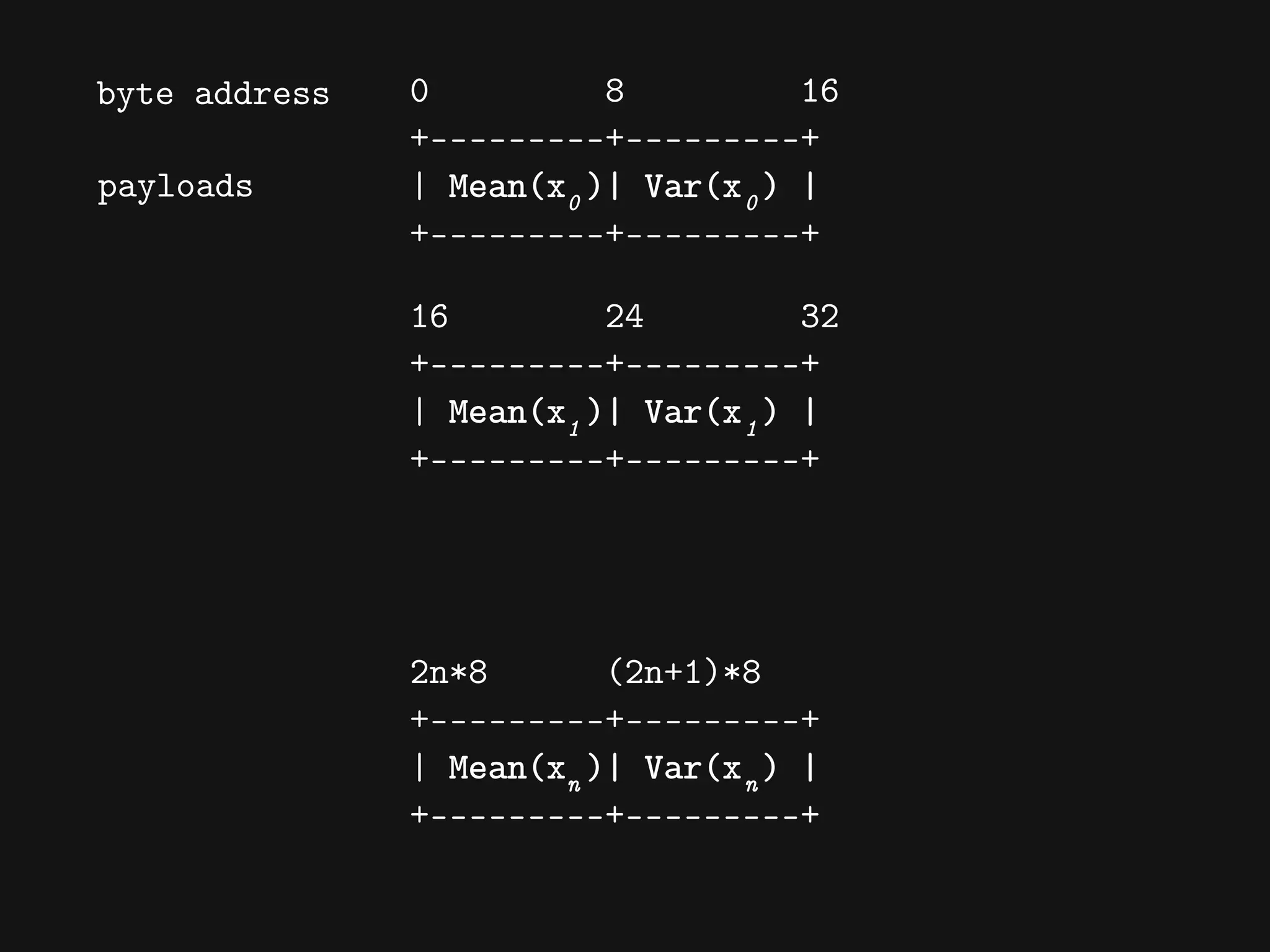
![[[Mean(x1), Var(x1)]
[Mean(x2), Var(x3)]
...
[Mean(xn), Var(xn)]]](https://crownmelresort.com/image.slidesharecdn.com/cassandrasummit2015-dataanalyticswithcassandraandclojure-151002213523-lva1-app6891/75/codecentric-AG-Using-Cassandra-and-Clojure-for-Data-Crunching-backends-56-2048.jpg)















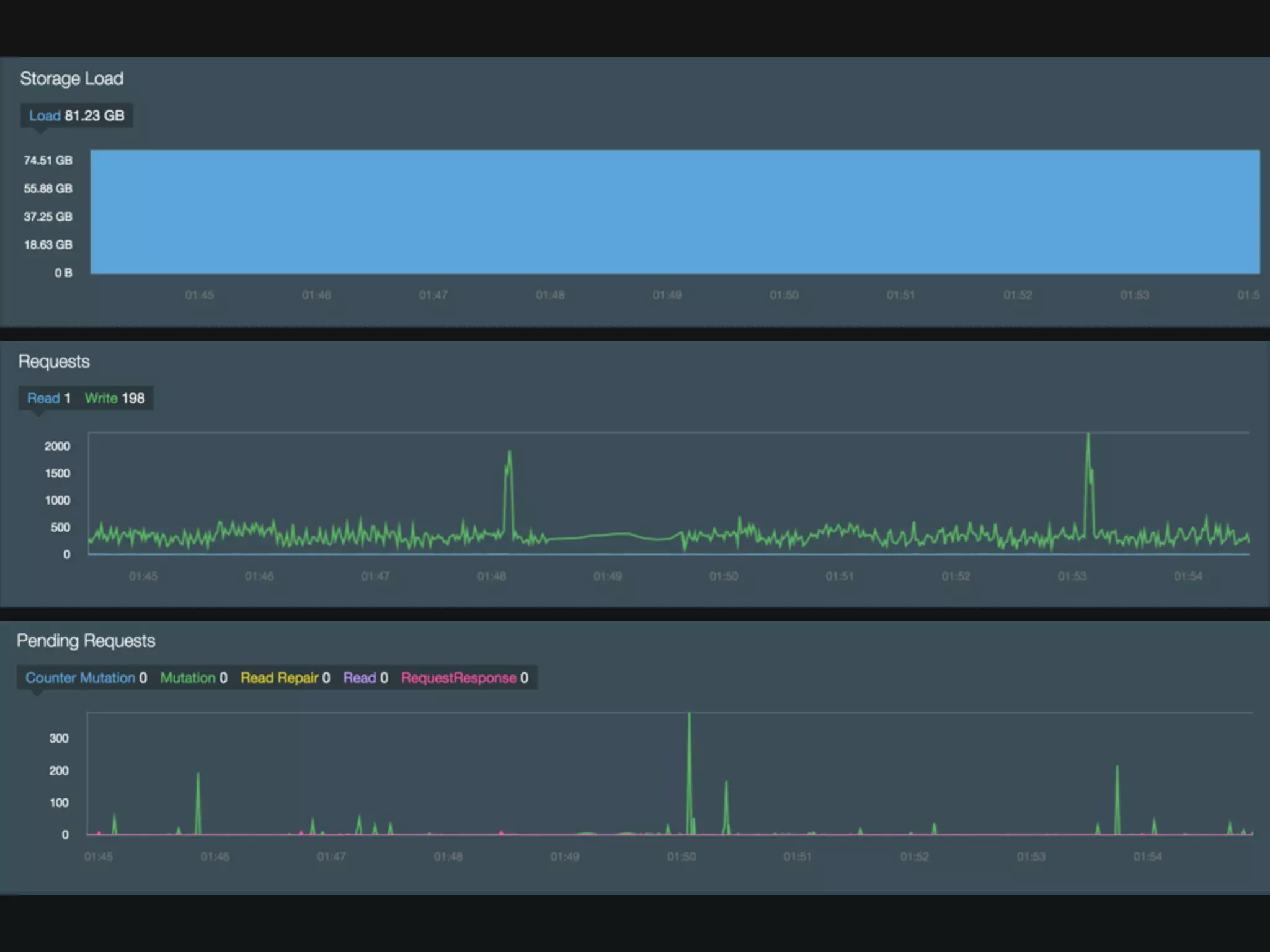
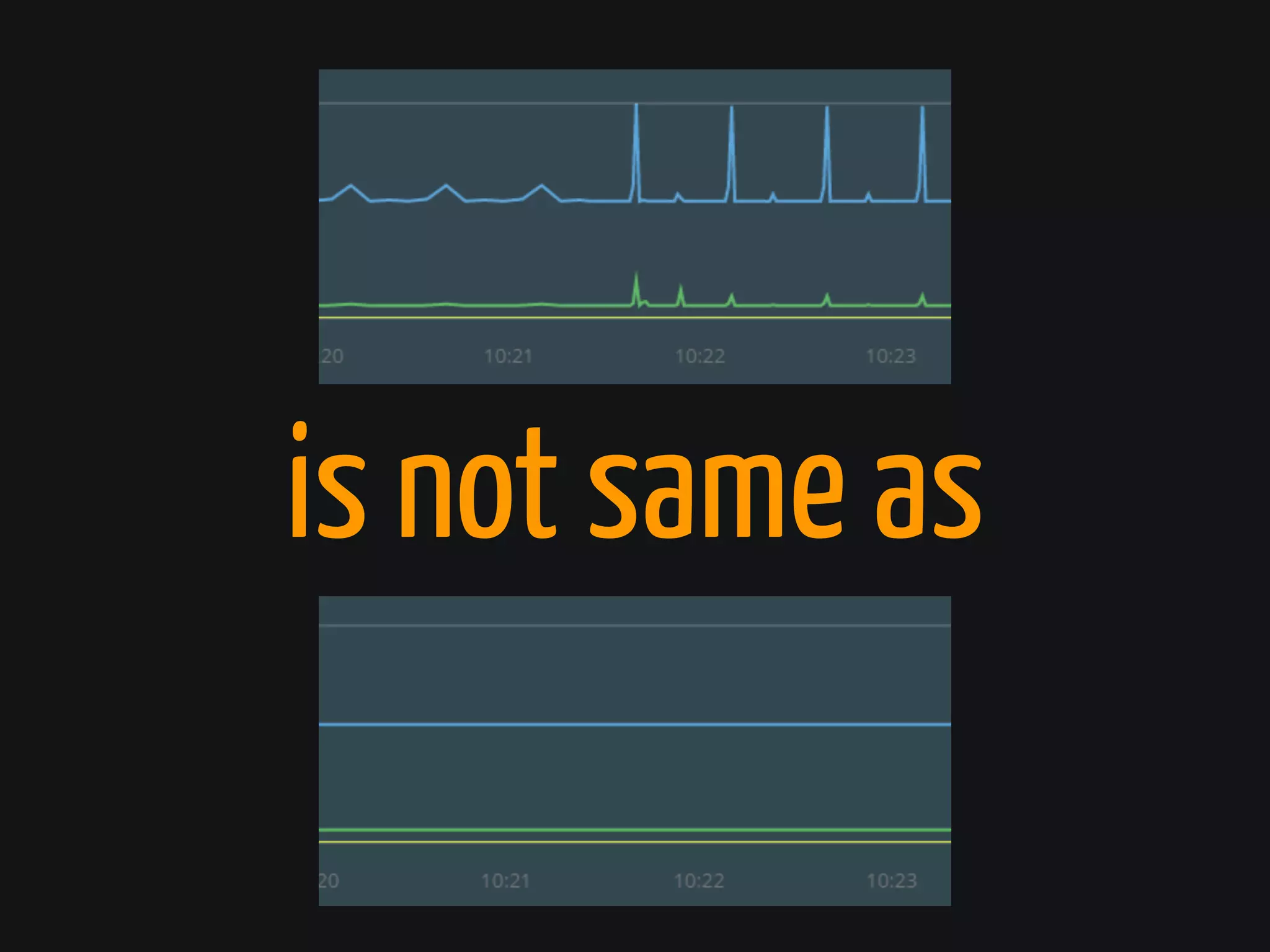
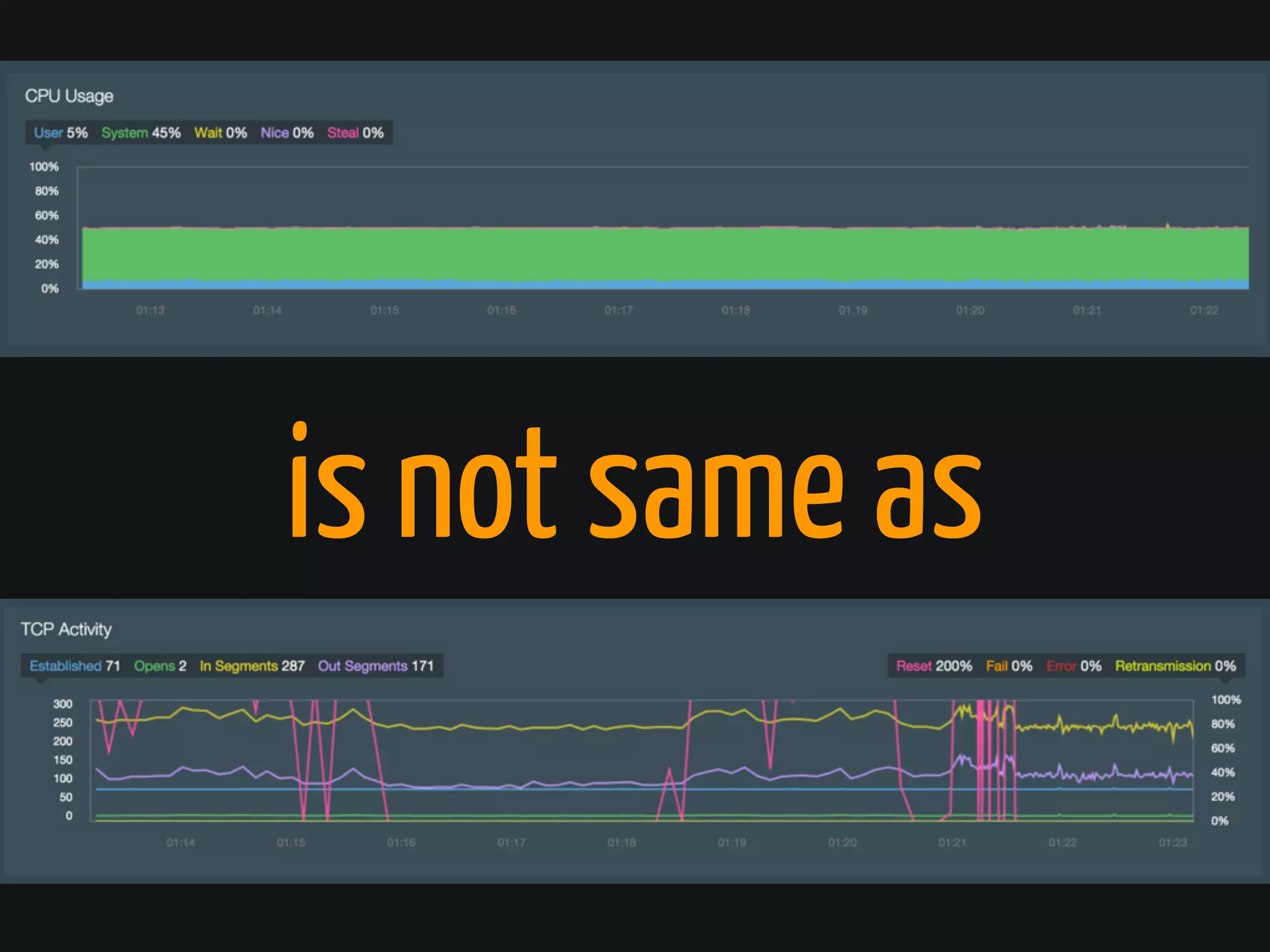
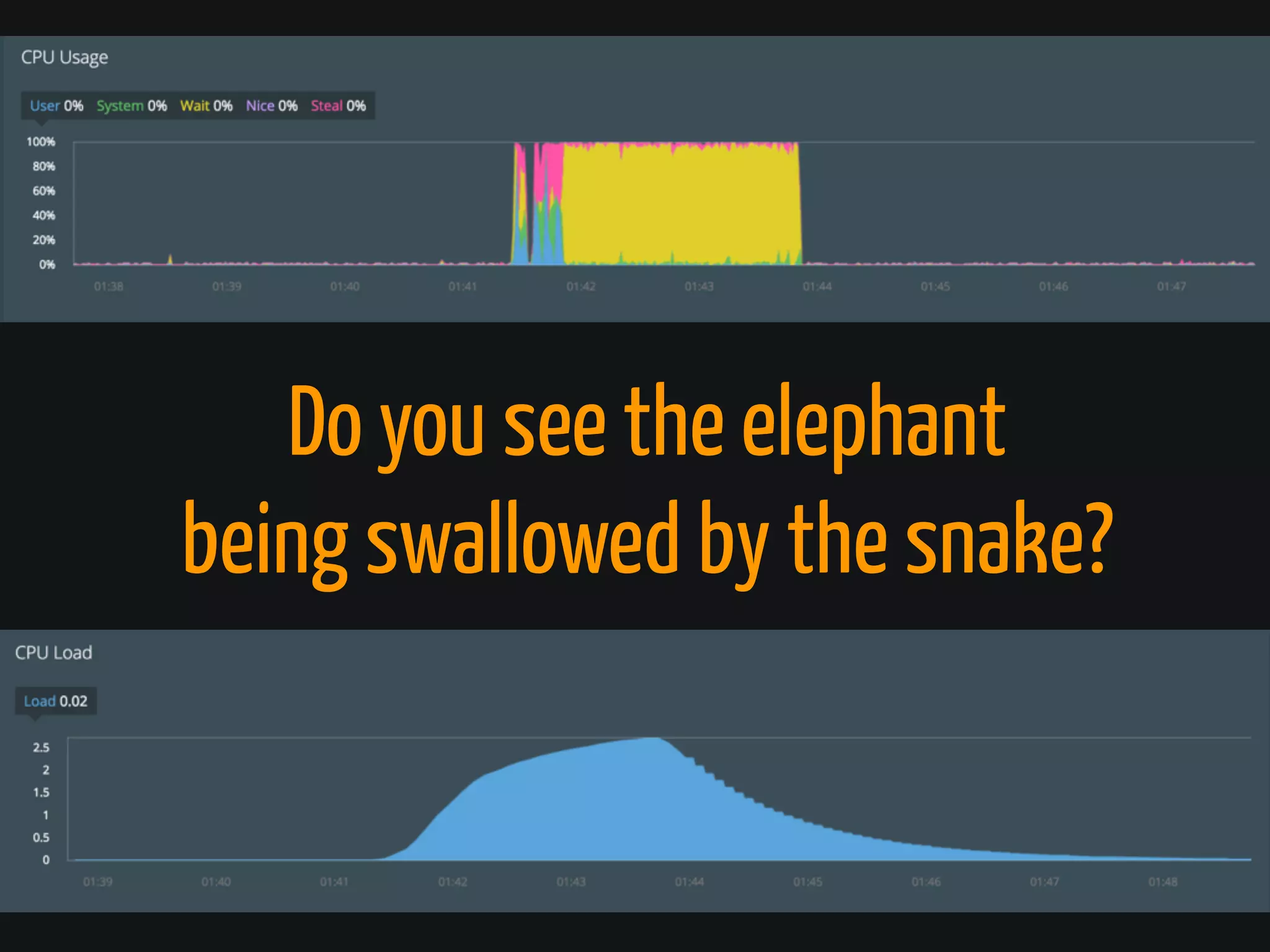
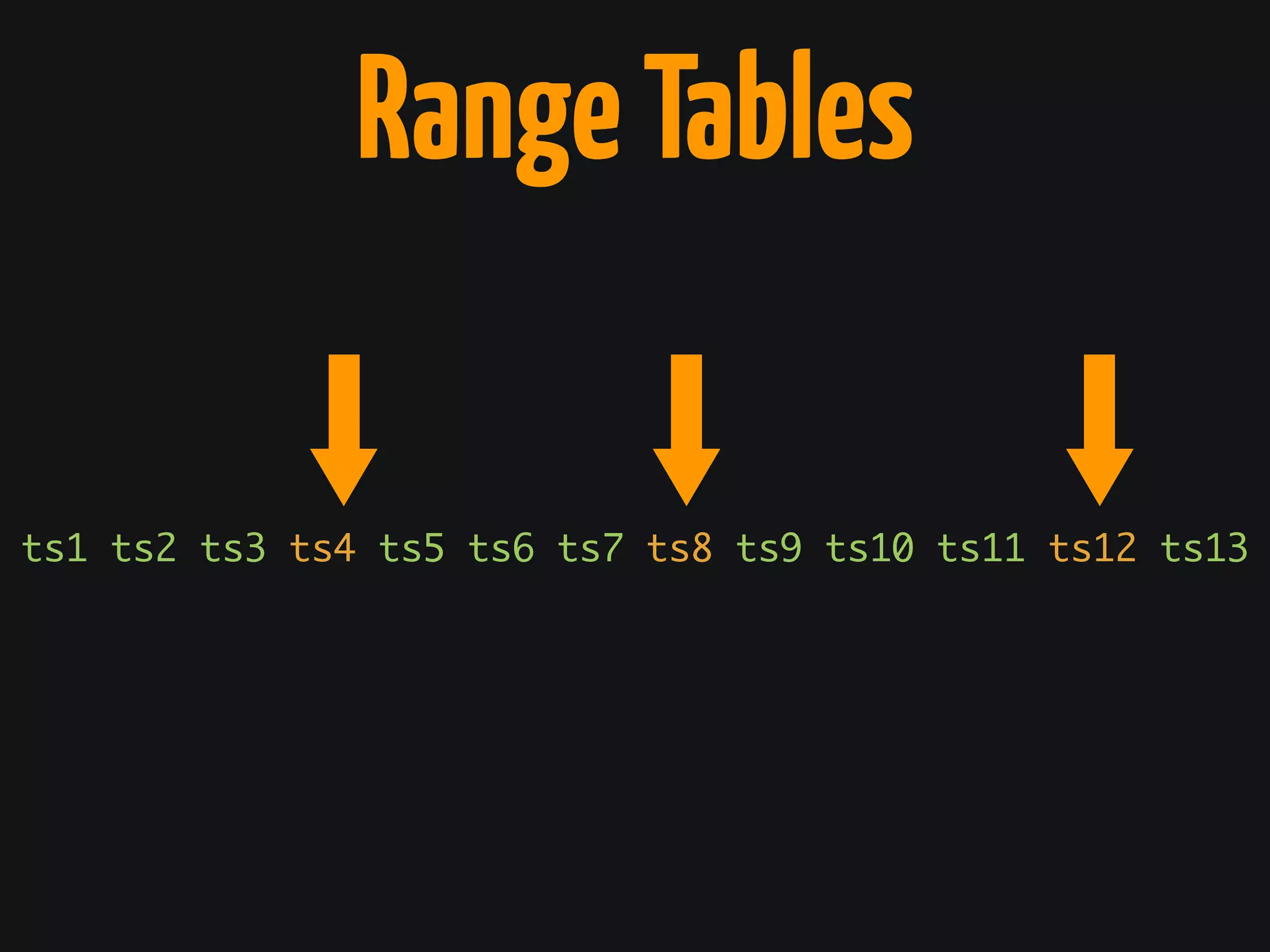
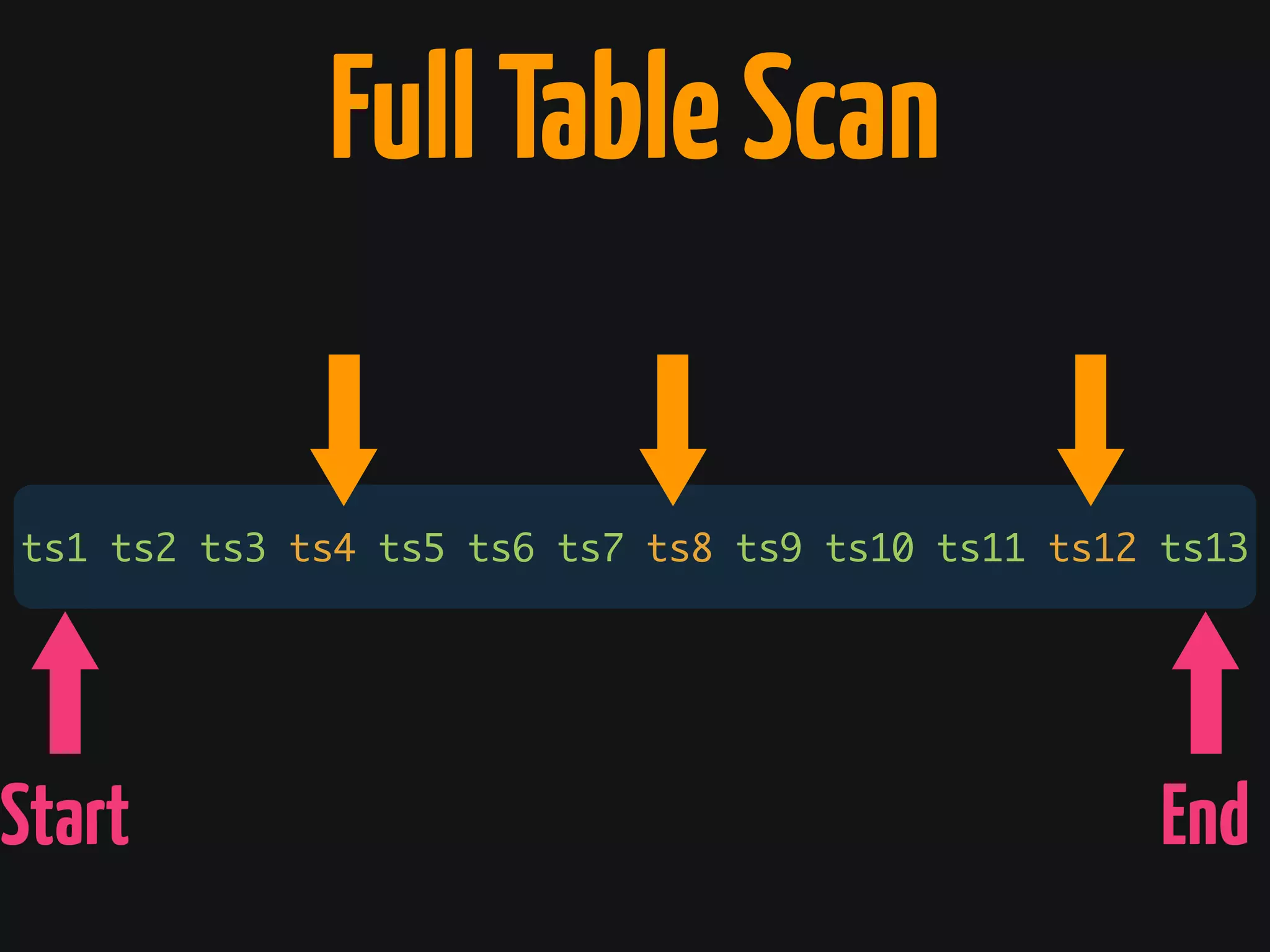
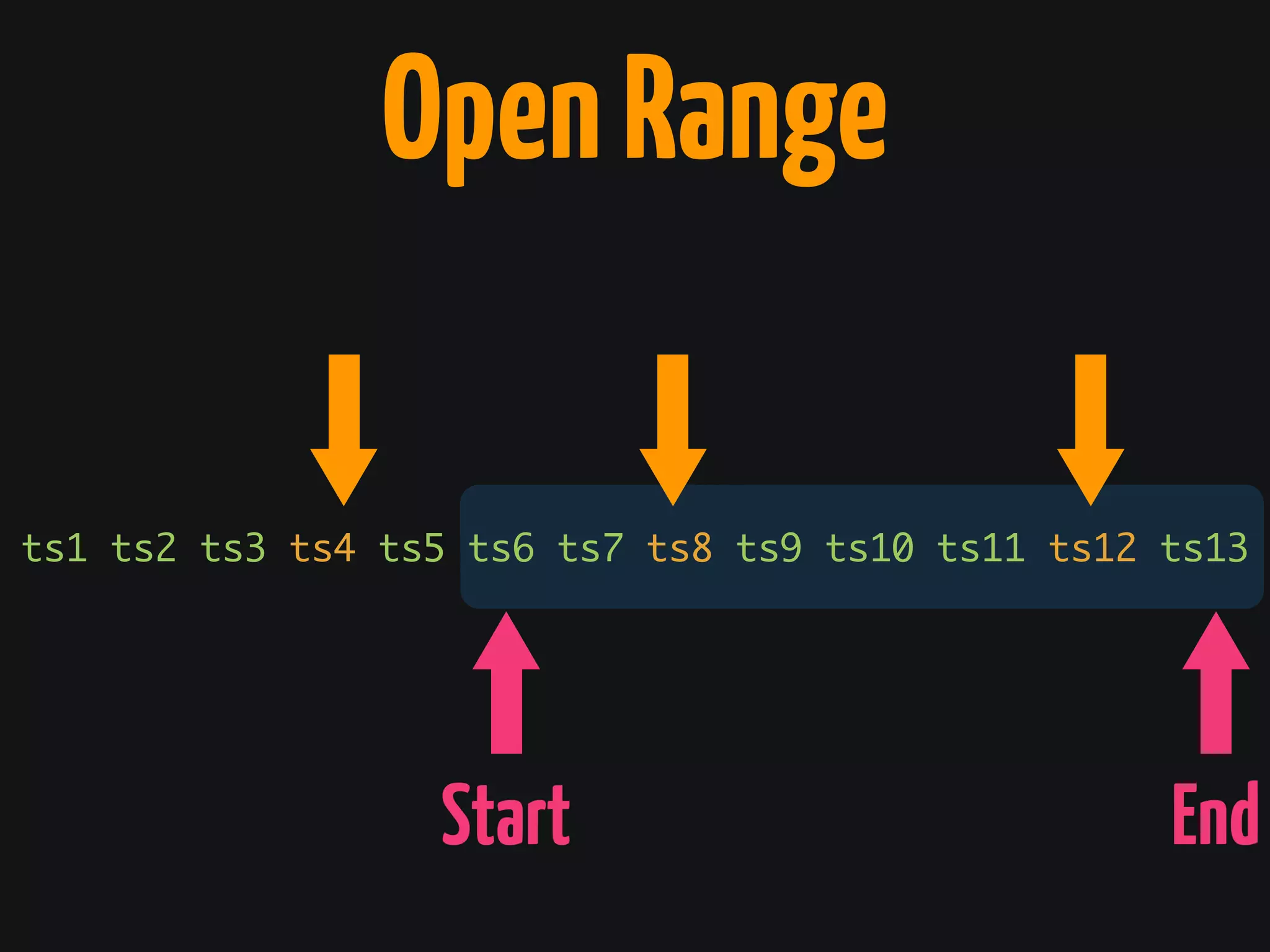
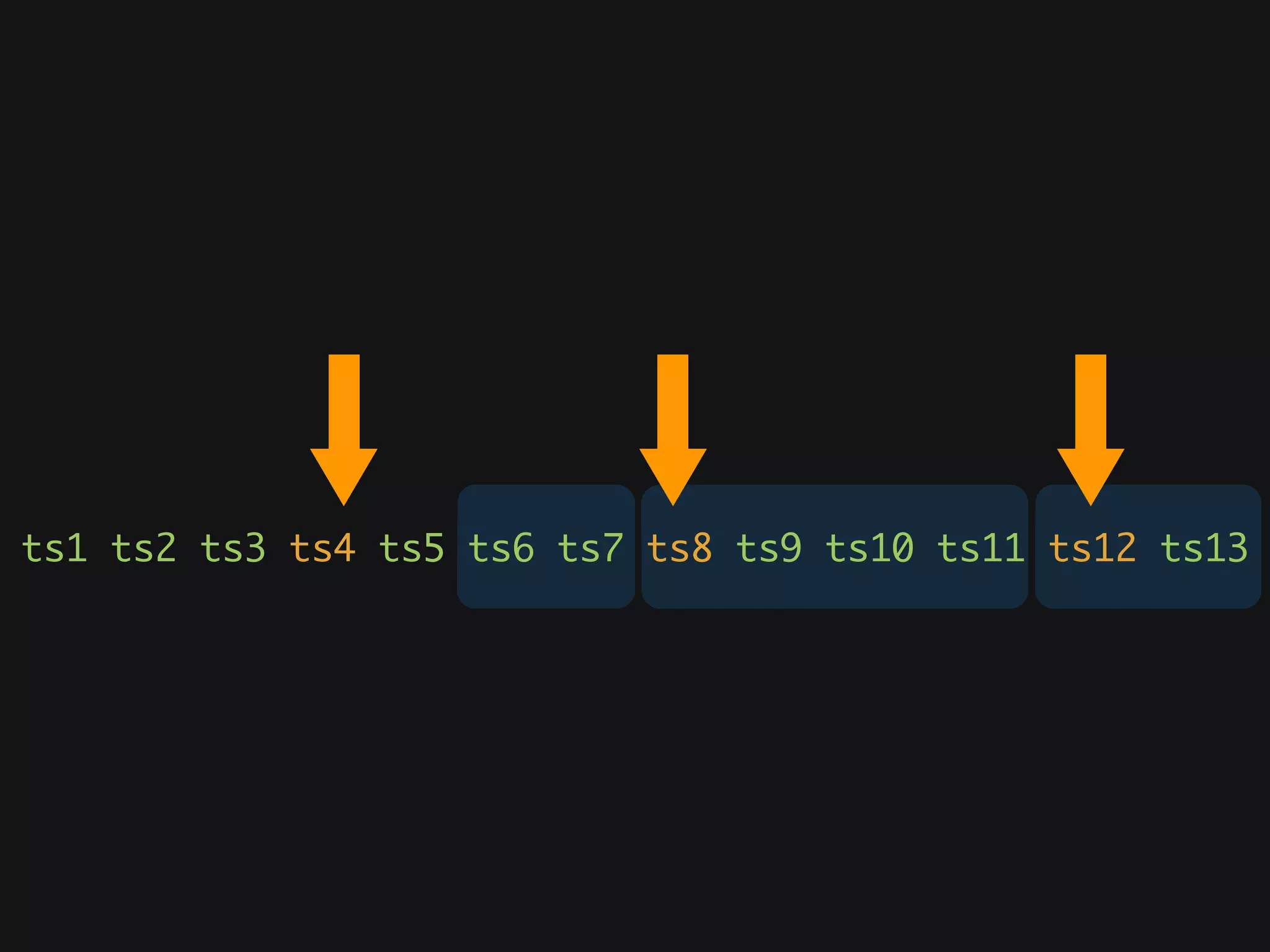
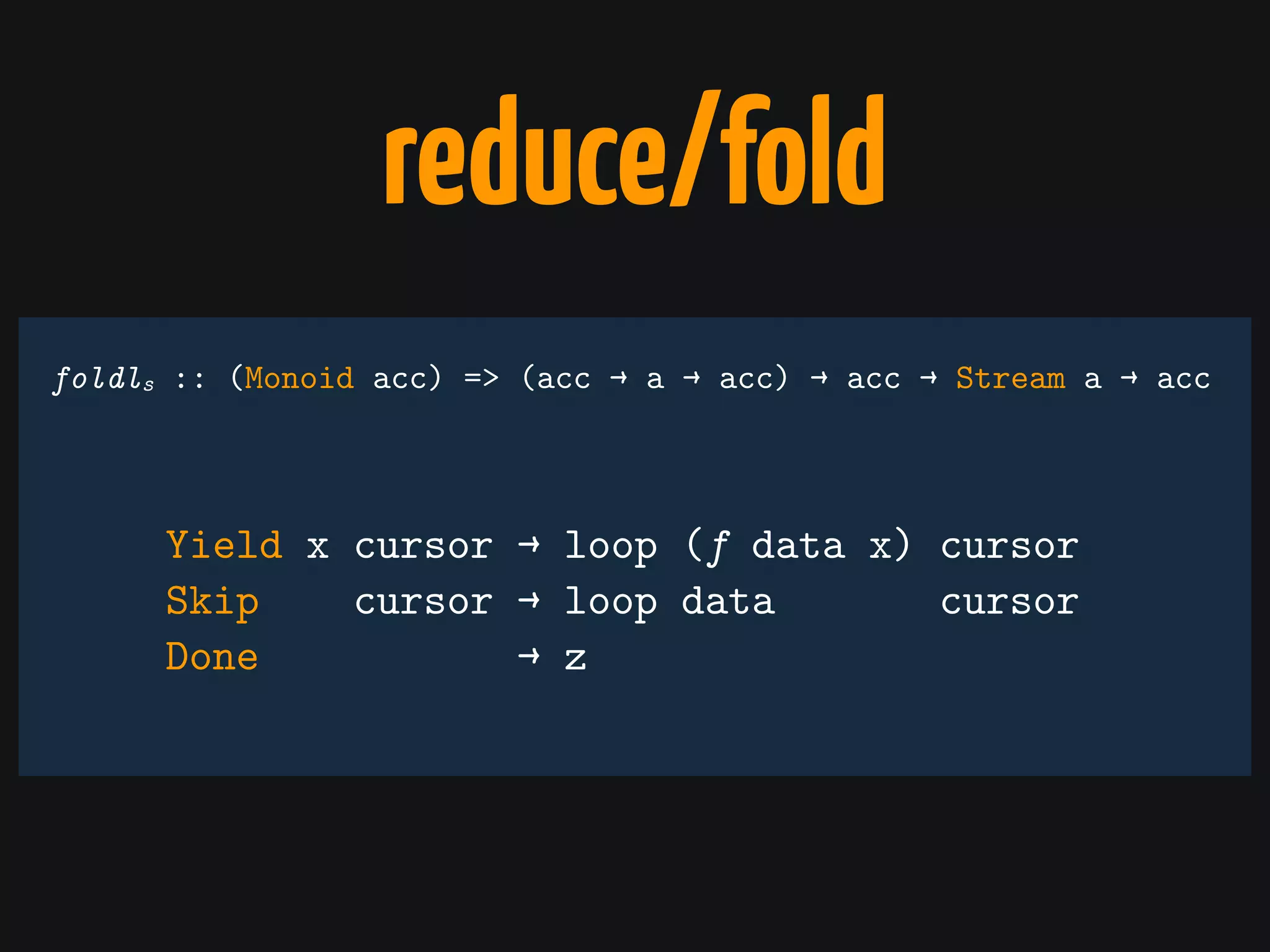
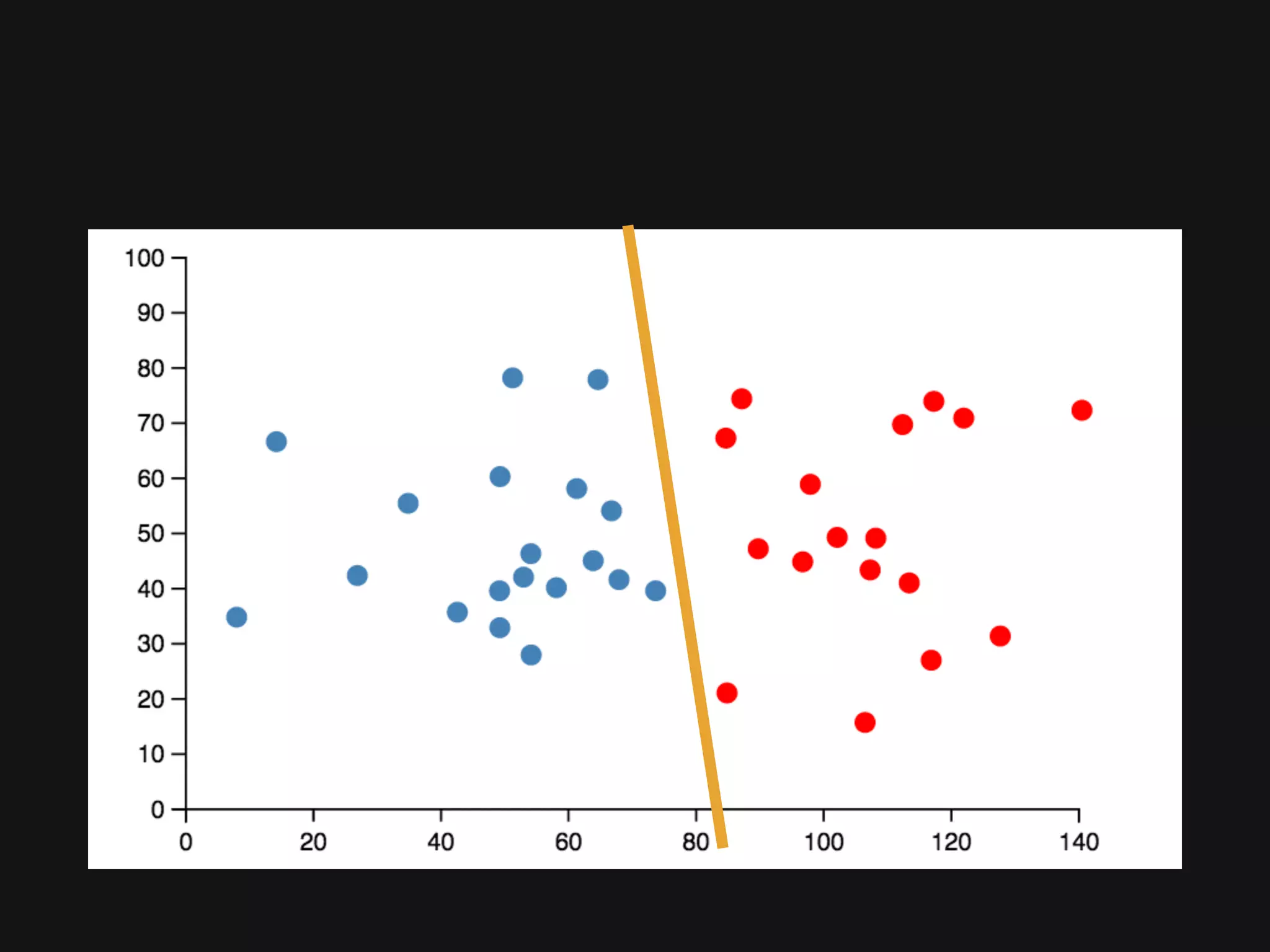
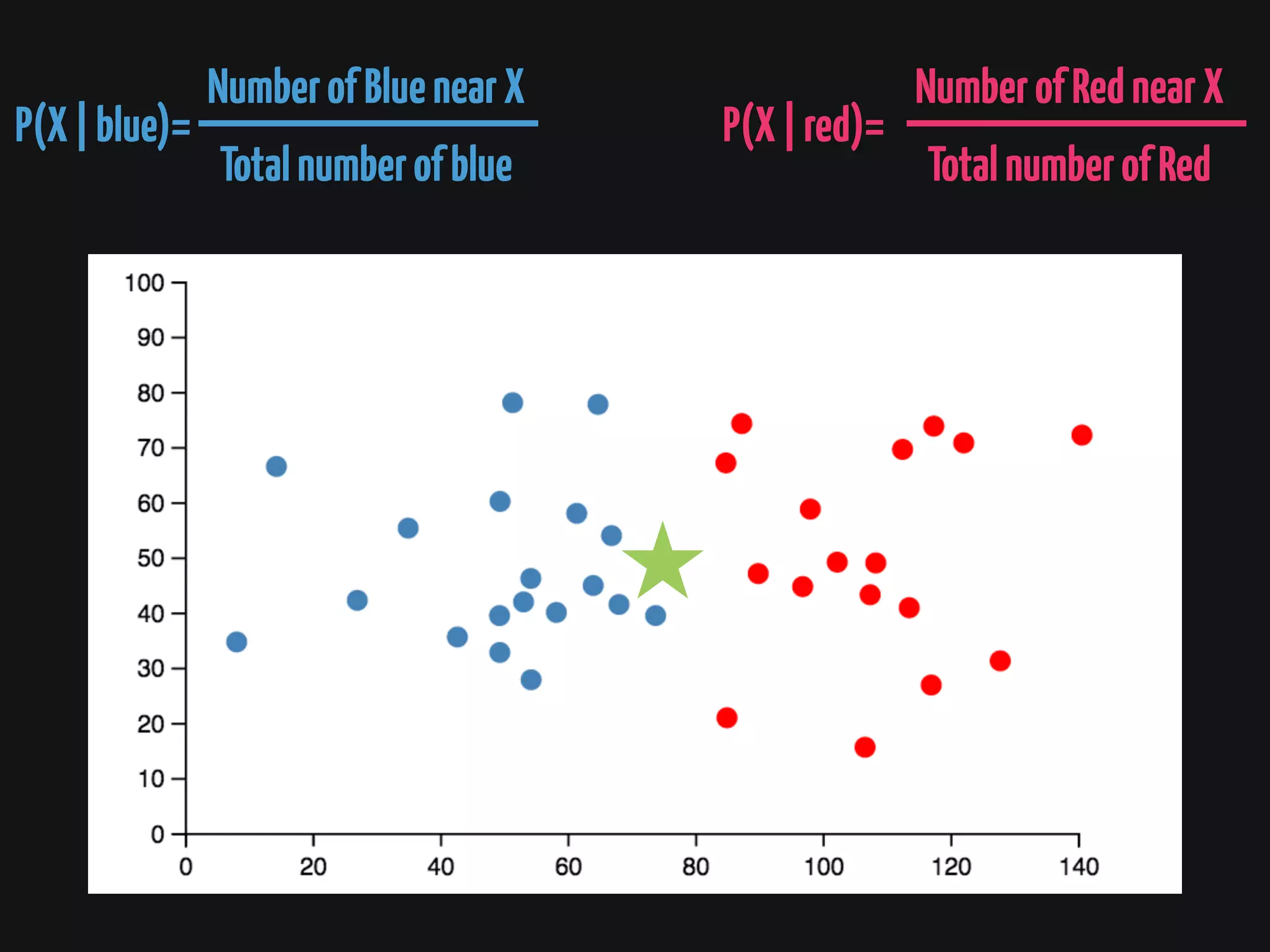
The document discusses Cassandra monitoring, emphasizing the distinction between semantics and anomaly detection. It covers various techniques, including ad-hoc queries, data modeling for machine learning, and the use of data structures like Bloom filters and count-min sketches for efficient data handling. Additionally, it addresses performance optimizations and the lightweight design of data representation compatible with parallel processing.





















































































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)













