Downloaded 24 times




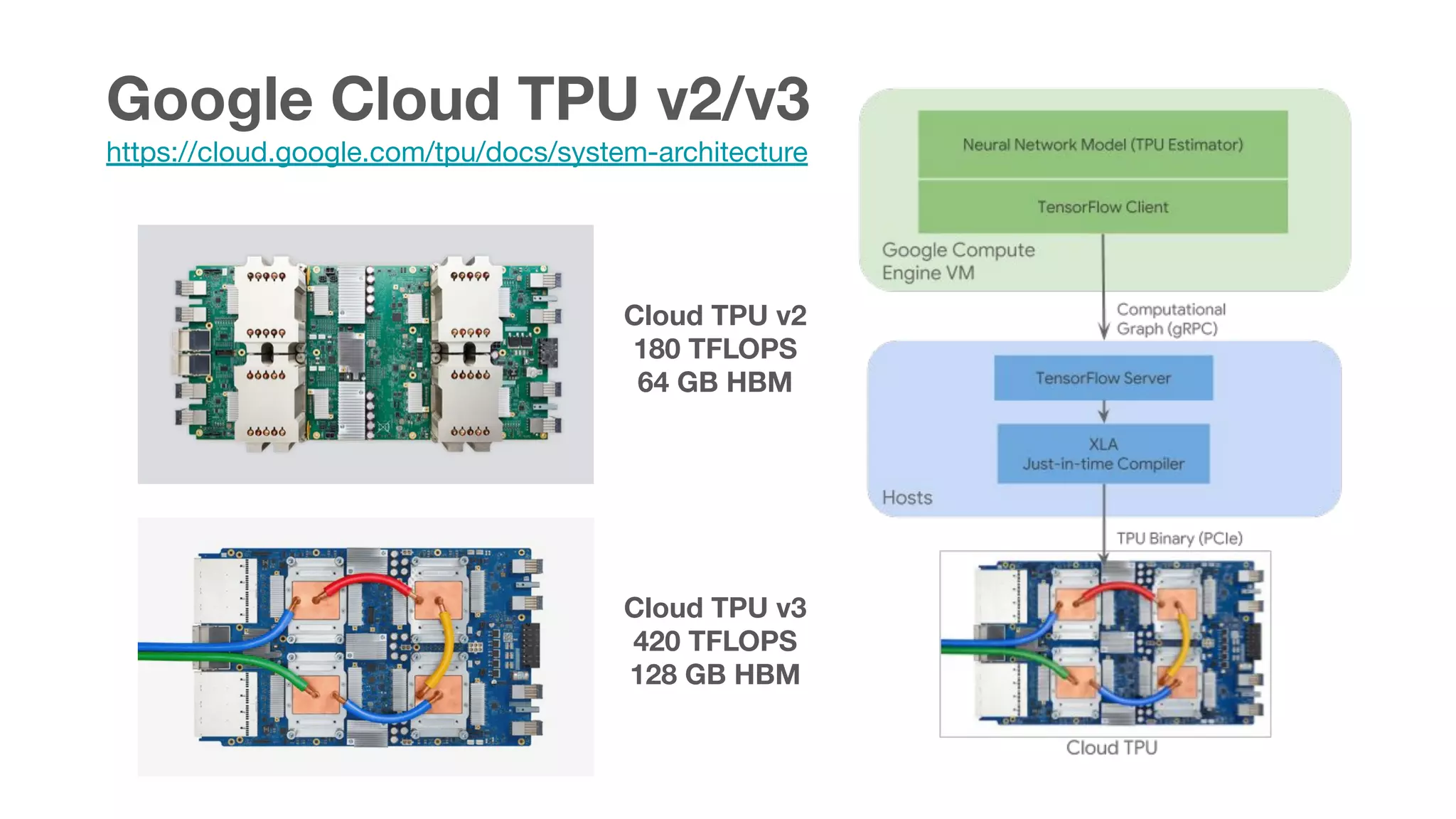
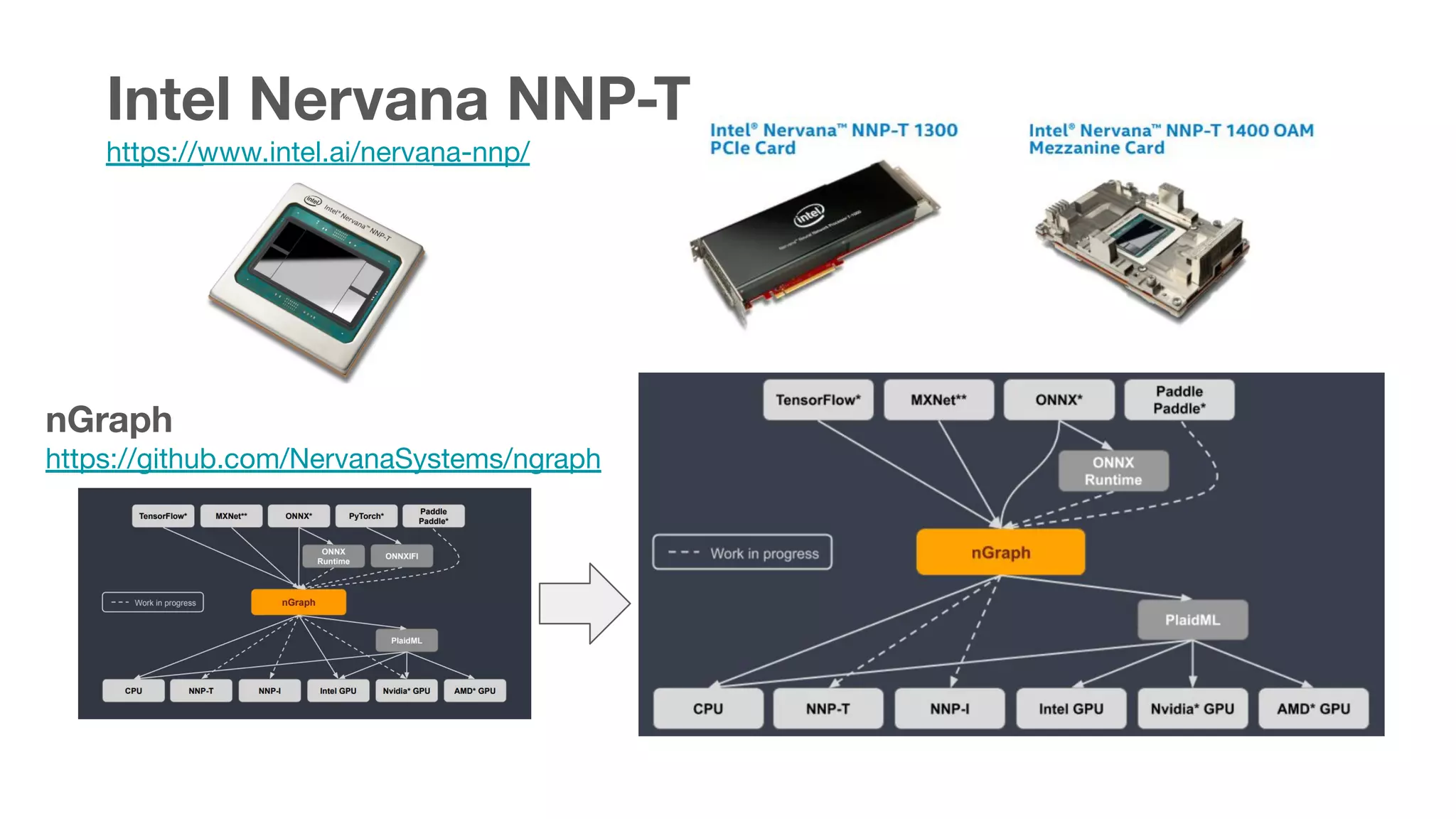
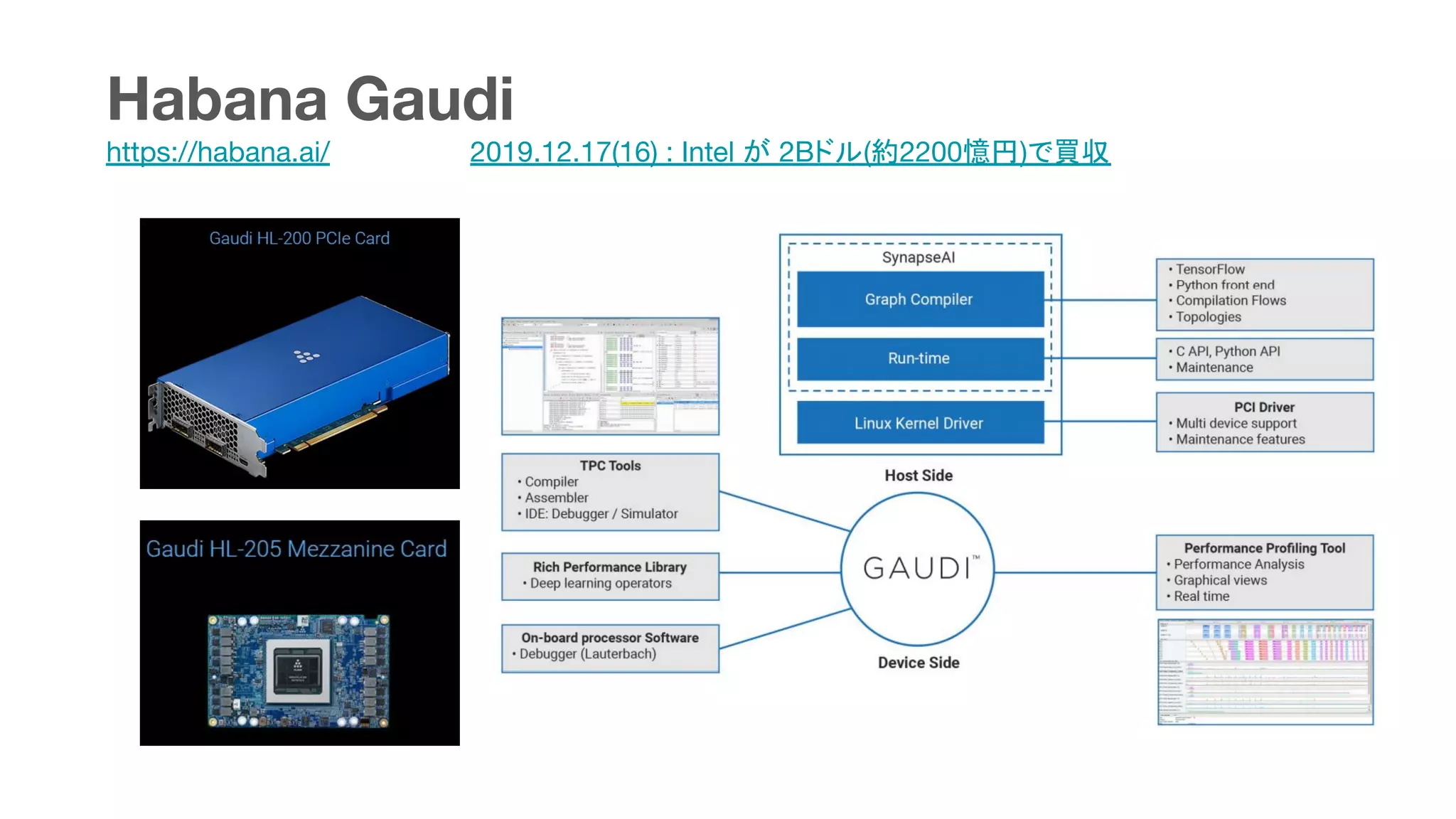
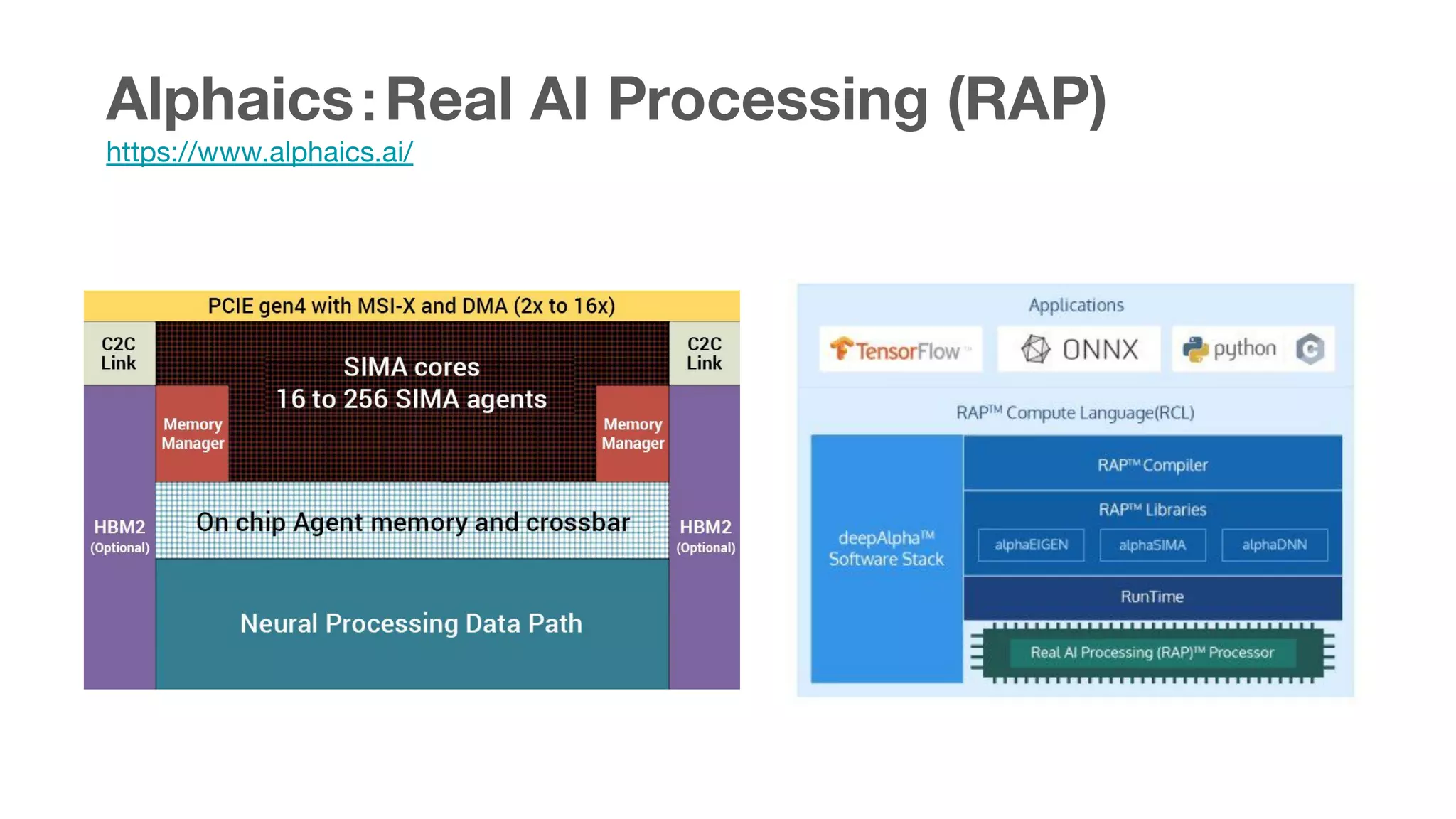
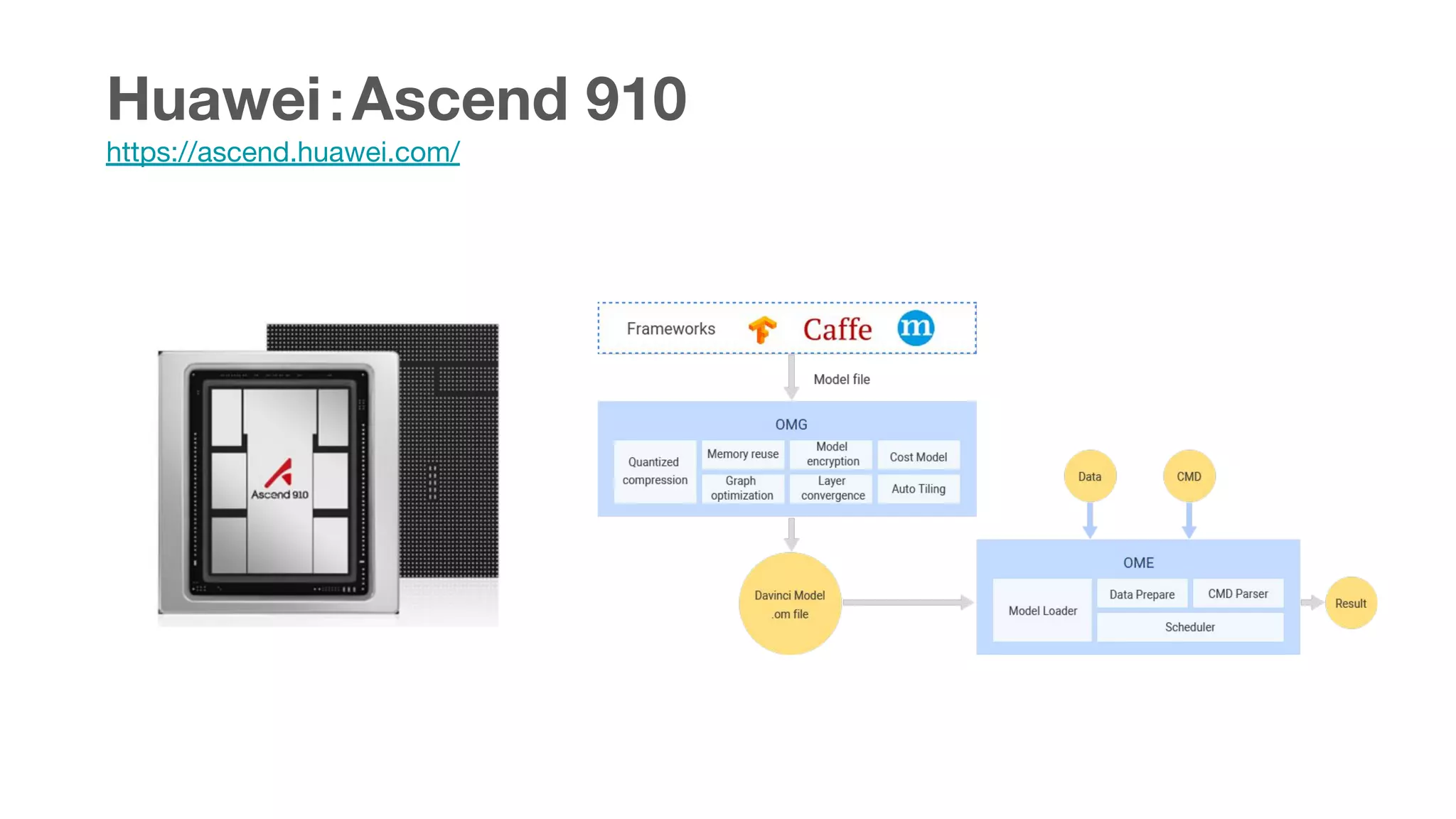







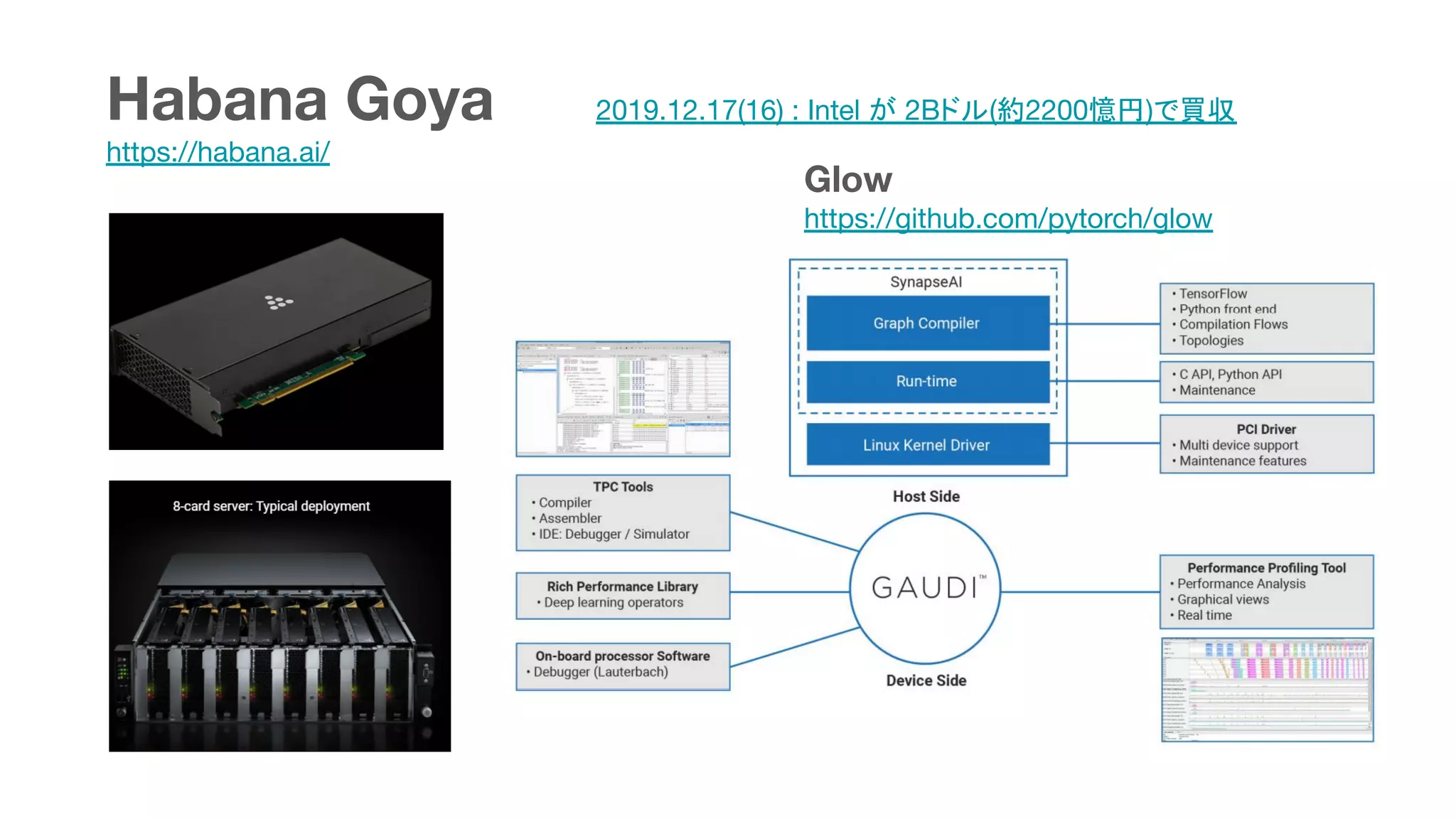



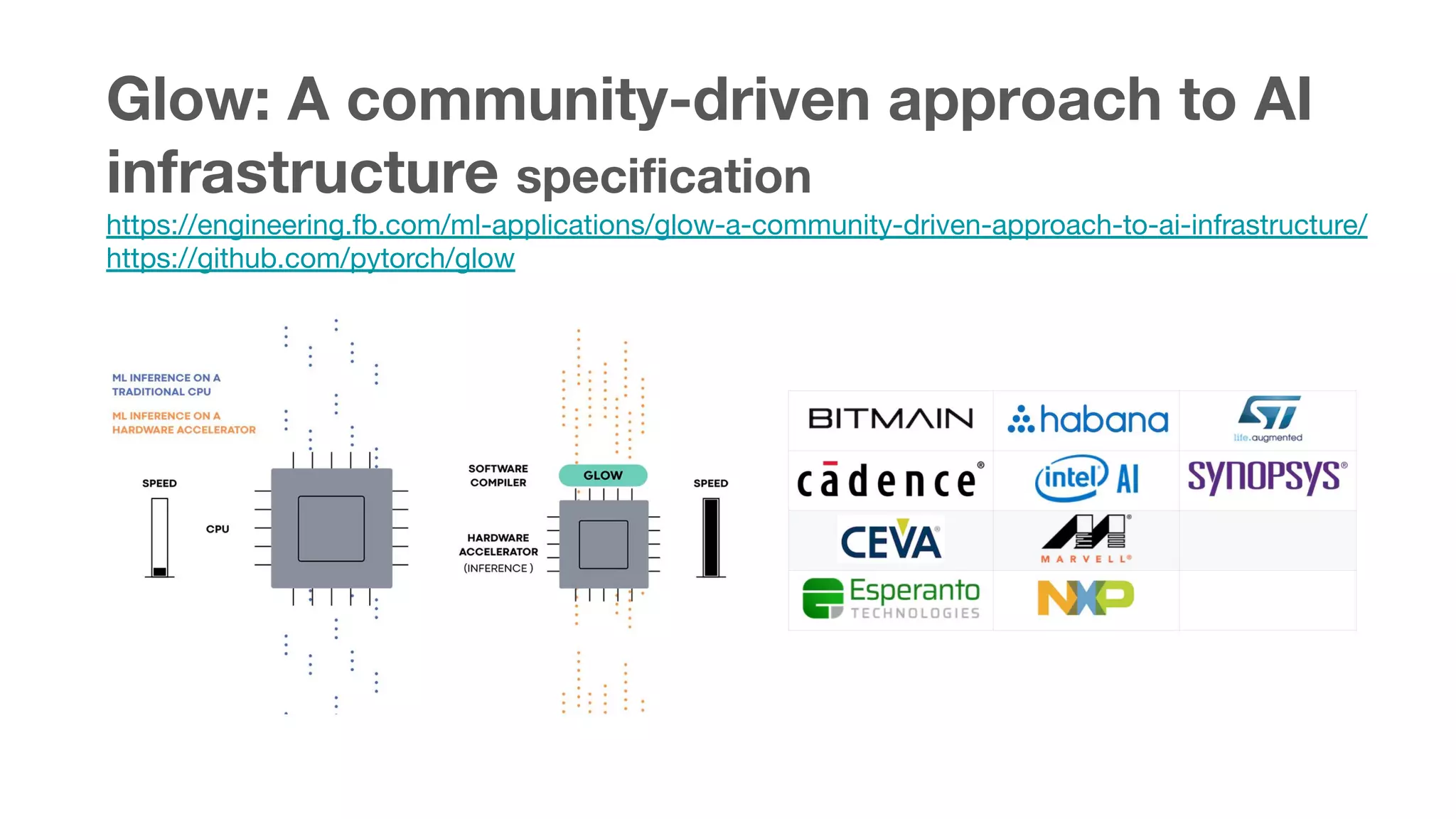



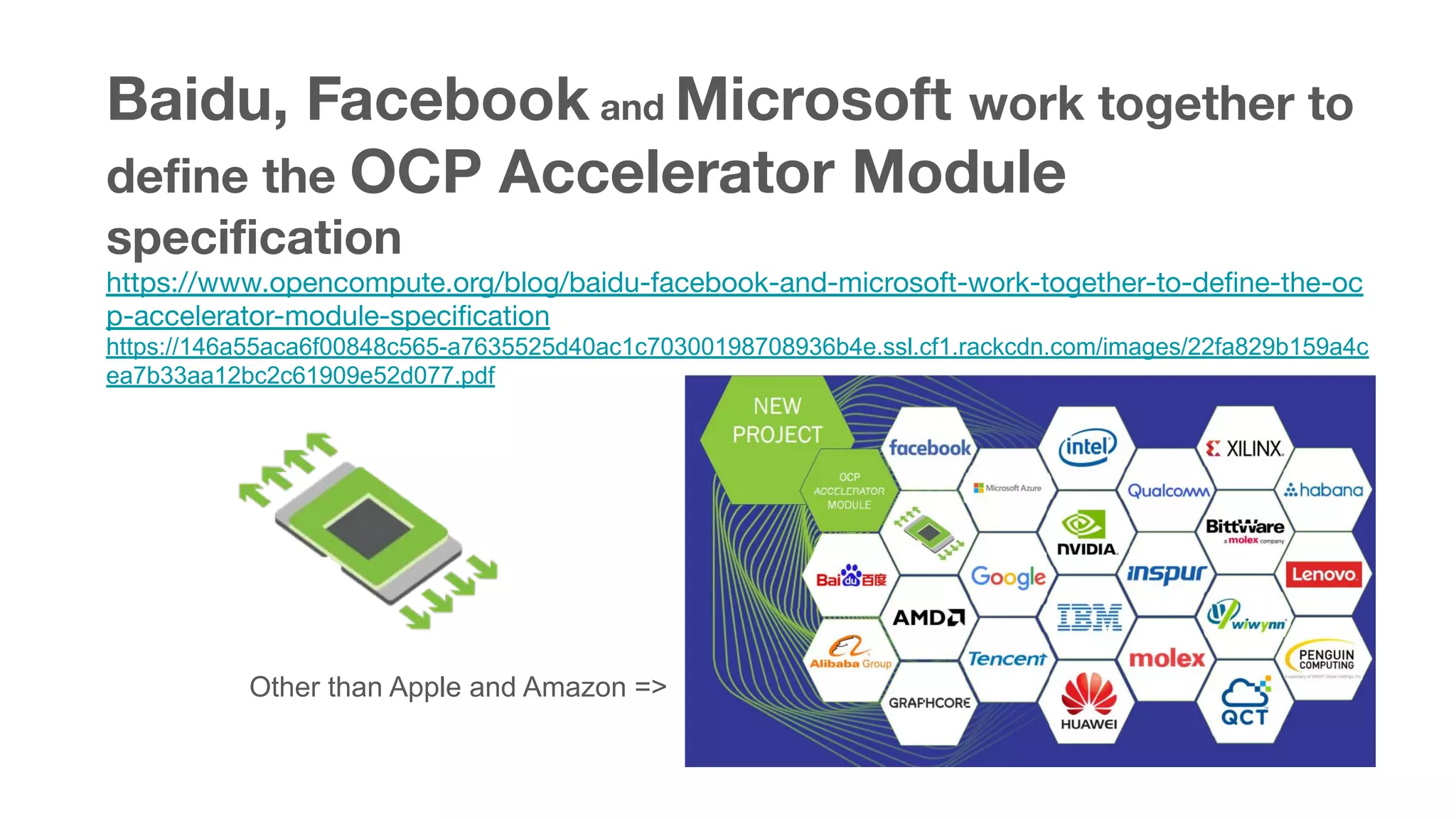




























This document summarizes various chips for deep learning training and inference in the cloud from companies such as Google, Intel, Habana Labs, Alibaba, and Graphcore. It provides information on the specs and capabilities of each chip, such as the memory type and TFLOPS, and links to product pages and documentation. It also discusses collaborations between companies on projects like Glow, ONNX, and OCP accelerator modules.














































































