Downloaded 10 times



















 {
*var = new NGraphVar(dtype_,shape_);
//(*var)->tensor()->set_shape(shape_);
return Status::OK();
};
NGraphVariableOp](https://image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-21-2048.jpg)





![src/ngraph_rewrite_pass.cc
// Pass that rewrites the graph for nGraph operation.
//
// The pass has several phases, each executed in sequence:
//
// 1. Marking [ngraph_mark_for_clustering.cc]
// 2. Cluster Assignment [ngraph_assign_clusters.cc]
// 3. Cluster Deassignment [ngraph_deassign_clusters.cc]
// 4. Cluster Encapsulation [ngraph_encapsulate_clusters.cc]
NGraphEncapsulatePass](https://image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-27-2048.jpg)

![src/ngraph_rewrite_pass.cc
// 1. Marking [ngraph_mark_for_clustering.cc]
// Mark for clustering then, if requested, dump the graphs.
TF_RETURN_IF_ERROR(MarkForClustering(options.graph->get()));
if (DumpMarkedGraphs()) {
DumpGraphs(options, idx, "marked", "Graph Marked for Clustering");
}
NGraphEncapsulatePass](https://image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-29-2048.jpg)
![src/ngraph_rewrite_pass.cc
// 2. Cluster Assignment [ngraph_assign_clusters.cc]
// Assign clusters then, if requested, dump the graphs.
TF_RETURN_IF_ERROR(AssignClusters(options.graph->get()));
if (DumpClusteredGraphs()) {
DumpGraphs(options, idx, "clustered", "Graph with Clusters Assigned");
}
NGraphEncapsulatePass](https://image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-30-2048.jpg)
![src/ngraph_rewrite_pass.cc
// 3. Cluster Deassignment [ngraph_deassign_clusters.cc]
// Deassign trivial clusters then, if requested, dump the graphs.
TF_RETURN_IF_ERROR(DeassignClusters(options.graph->get()));
if (DumpDeclusteredGraphs()) {
DumpGraphs(options, idx, "declustered",
"Graph with Trivial Clusters De-Assigned");
}
NGraphEncapsulatePass](https://image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-31-2048.jpg)
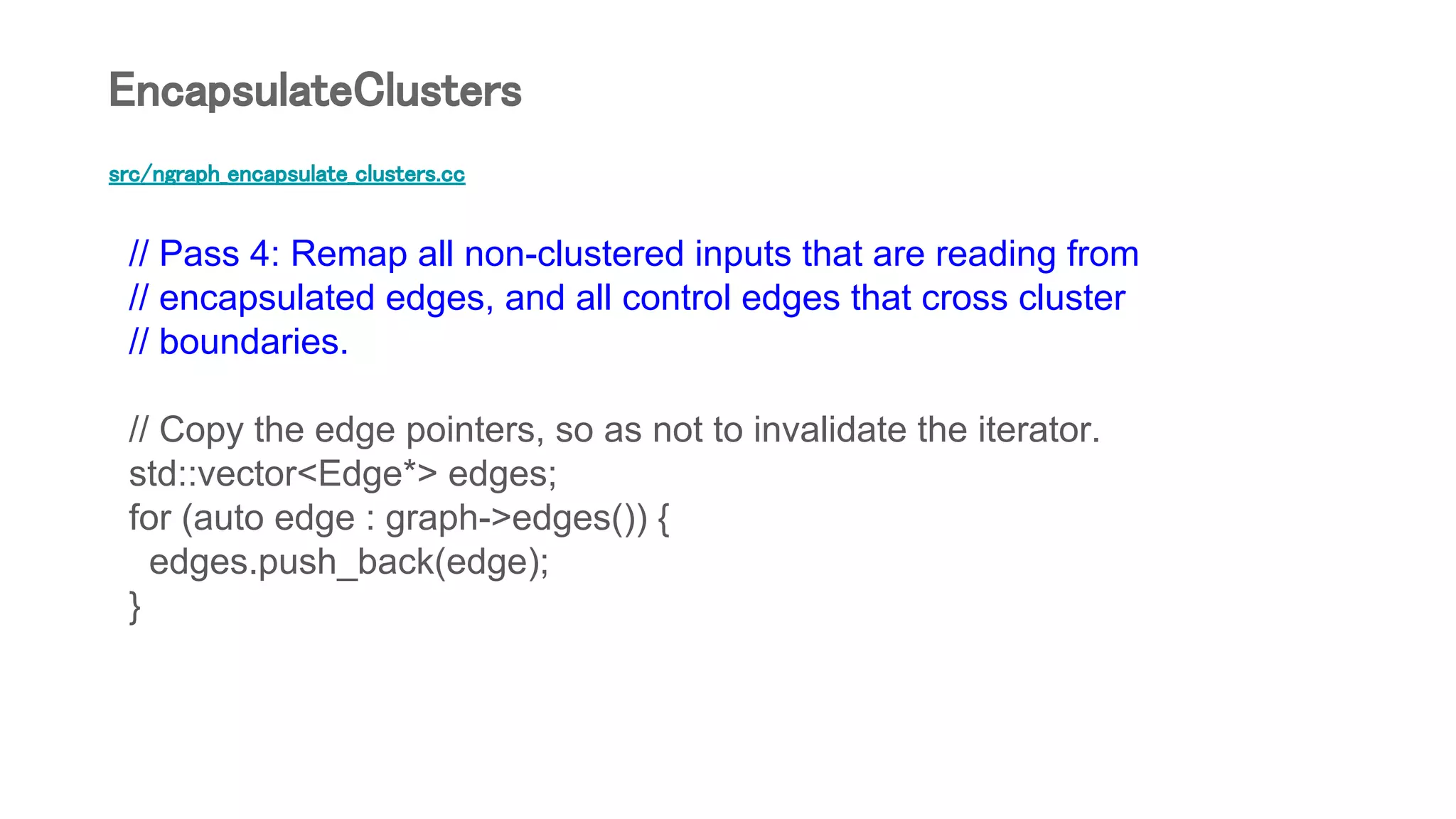
![src/ngraph_rewrite_pass.cc
// 4. Cluster Encapsulation [ngraph_encapsulate_clusters.cc]
// Encapsulate clusters then, if requested, dump the graphs.
TF_RETURN_IF_ERROR(EncapsulateClusters(options.graph->get()));
if (DumpEncapsulatedGraphs()) {
DumpGraphs(options, idx, "encapsulated",
"Graph with Clusters Encapsulated");
}
NGraphEncapsulatePass](https://image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-32-2048.jpg)



![src/ngraph_encapsulate_clusters.cc
// Pass 1: Populate the cluster-index-to-device name map for each existing
// cluster.
if (it != device_name_map.end()) {
if (it->second != node->requested_device()) {
std::stringstream ss_err;
// ここでエラーメッセージを生成
return errors::Internal(ss_err.str());
}
} else {
device_name_map[cluster_idx] = node->requested_device();
}
}
EncapsulateClusters](https://image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-36-2048.jpg)



![src/ngraph_encapsulate_clusters.cc
if (src_clustered &&
output_remap_map.find(std::make_tuple(src->id(), edge->src_output())) ==
output_remap_map.end()) {
output_remap_map[std::make_tuple(src->id(), edge->src_output())] =
std::make_tuple(src_cluster_idx,
cluster_output_dt_map[src_cluster_idx].size());
std::stringstream ss;
ss << "ngraph_output_" << cluster_output_dt_map[src_cluster_idx].size();
string output_name = ss.str();
EncapsulateClusters](https://image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-40-2048.jpg)

![src/ngraph_encapsulate_clusters.cc
SetAttrValue(dt, &((*(new_output_node_def->mutable_attr()))["T"]));
SetAttrValue(retval_index_count[src_cluster_idx],
&((*(new_output_node_def->mutable_attr()))["index"]));
retval_index_count[src_cluster_idx]++;
cluster_output_dt_map[src_cluster_idx].push_back(dt);
}
EncapsulateClusters](https://image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-42-2048.jpg)
![src/ngraph_encapsulate_clusters.cc
if (dst_clustered &&
input_remap_map.find(
std::make_tuple(dst_cluster_idx, src->id(), edge->src_output())) ==
input_remap_map.end()) {
input_remap_map[std::make_tuple(dst_cluster_idx, src->id(),
edge->src_output())] =
cluster_input_map[dst_cluster_idx].size();
std::stringstream ss;
ss << "ngraph_input_" << cluster_input_map[dst_cluster_idx].size();
std::string new_input_name = ss.str();
EncapsulateClusters](https://image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-43-2048.jpg)
![src/ngraph_encapsulate_clusters.cc
input_rename_map[std::make_tuple(dst_cluster_idx, src->name(),
edge->src_output())] = new_input_name;
auto new_input_node_def =
NGraphClusterManager::GetClusterGraph(dst_cluster_idx)->add_node();
new_input_node_def->set_name(new_input_name);
new_input_node_def->set_op("_Arg");
SetAttrValue(dt, &((*(new_input_node_def->mutable_attr()))["T"]));
SetAttrValue(arg_index_count[dst_cluster_idx],
&((*(new_input_node_def->mutable_attr()))["index"]));
EncapsulateClusters](https://image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-44-2048.jpg)
![src/ngraph_encapsulate_clusters.cc
arg_index_count[dst_cluster_idx]++;
cluster_input_map[dst_cluster_idx].push_back(
std::make_tuple(src->id(), edge->src_output(), dt));
}
}
EncapsulateClusters](https://image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-45-2048.jpg)

![src/ngraph_encapsulate_clusters.cc
for (auto& tup : cluster_input_map[cluster_idx]) {
int src_node_id;
int src_output_idx;
DataType dt;
std::tie(src_node_id, src_output_idx, dt) = tup;
input_types.push_back(dt);
inputs.push_back(
NodeBuilder::NodeOut(graph->FindNodeId(src_node_id), src_output_idx));
}
EncapsulateClusters](https://image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-47-2048.jpg)
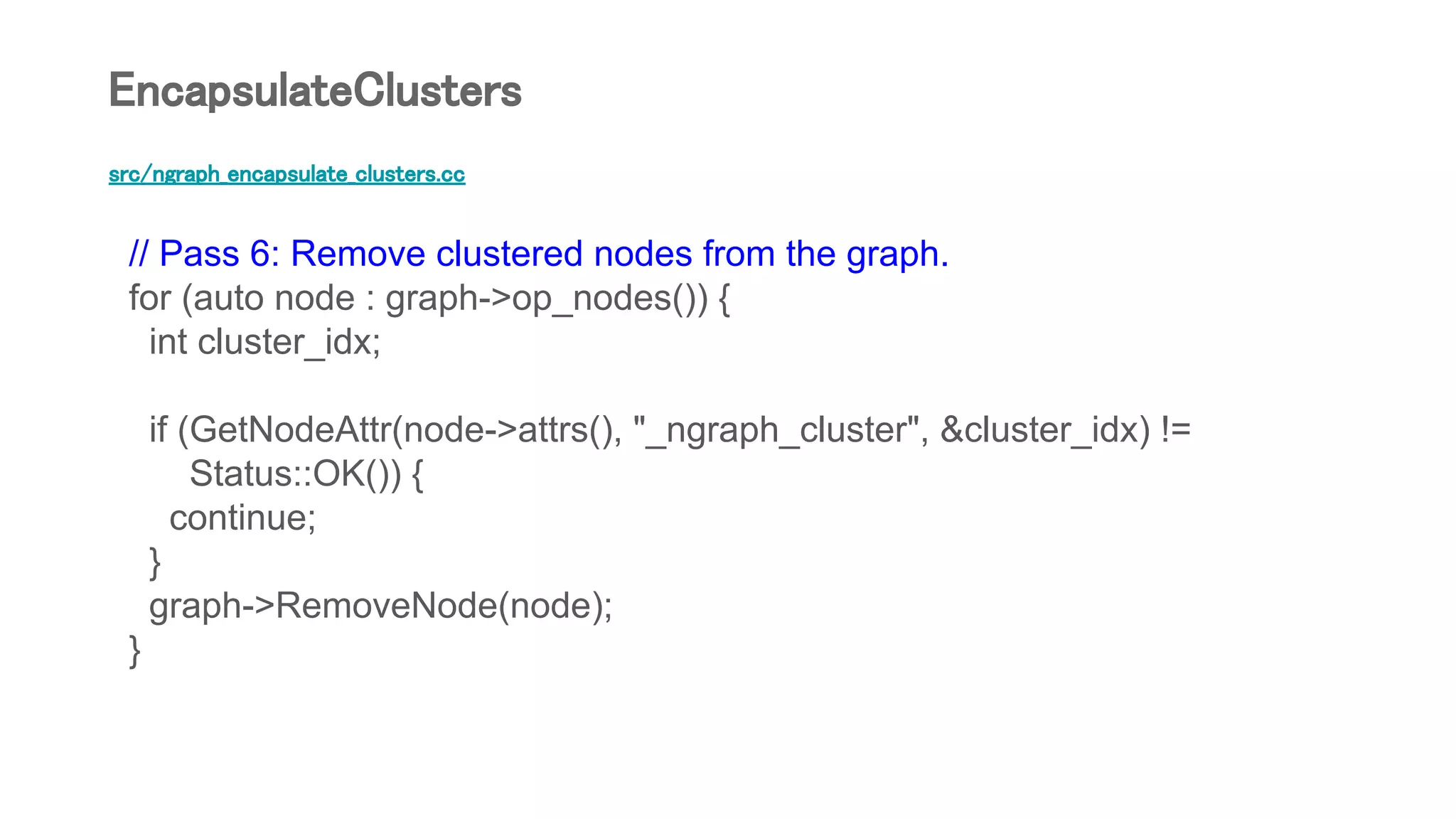
![src/ngraph_encapsulate_clusters.cc
Node* n;
Status status = NodeBuilder(ss.str(), "NGraphEncapsulate")
.Attr("ngraph_cluster", cluster_idx)
.Attr("Targuments", input_types)
.Attr("Tresults", cluster_output_dt_map[cluster_idx])
.Device(device_name_map[cluster_idx])
.Input(inputs)
.Finalize(graph, &n);
TF_RETURN_IF_ERROR(status);
n->set_assigned_device_name(device_name_map[cluster_idx]);
cluster_node_map[cluster_idx] = n;
}
EncapsulateClusters](https://image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-48-2048.jpg)

![src/ngraph_encapsulate_clusters.cc
if (edge->IsControlEdge()) {
if (src_clustered && dst_clustered) {
graph->RemoveControlEdge(edge);
graph->AddControlEdge(cluster_node_map[src_cluster_idx],
cluster_node_map[dst_cluster_idx]);
} else if (src_clustered) {
Node* dst = edge->dst();
graph->RemoveControlEdge(edge);
graph->AddControlEdge(cluster_node_map[src_cluster_idx], dst);
EncapsulateClusters](https://image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-51-2048.jpg)
![src/ngraph_encapsulate_clusters.cc
} else if (dst_clustered) {
Node* src = edge->src();
graph->RemoveControlEdge(edge);
graph->AddControlEdge(src, cluster_node_map[dst_cluster_idx]);
}
} else {
// This is handled at a later stage (TODO(amprocte): explain)
if (dst_clustered) {
continue;
}
EncapsulateClusters](https://image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-52-2048.jpg)
![src/ngraph_encapsulate_clusters.cc
auto it = output_remap_map.find(
std::make_tuple(edge->src()->id(), edge->src_output()));
if (it == output_remap_map.end()) {
continue;
}
int cluster_idx, cluster_output;
std::tie(cluster_idx, cluster_output) = it->second;
graph->UpdateEdge(cluster_node_map[cluster_idx], cluster_output,
edge->dst(), edge->dst_input());
}
}
EncapsulateClusters](https://image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-53-2048.jpg)


![src/ngraph_encapsulate_clusters.cc
original_def.clear_input();
original_def.mutable_input()->Reserve(inputs.size());
for (size_t i = 0; i < inputs.size(); ++i) {
const Edge* edge = inputs[i];
if (edge == nullptr) {
if (i < node->requested_inputs().size()) {
original_def.add_input(node->requested_inputs()[i]);
} else {
original_def.add_input("");
EncapsulateClusters](https://image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-56-2048.jpg)









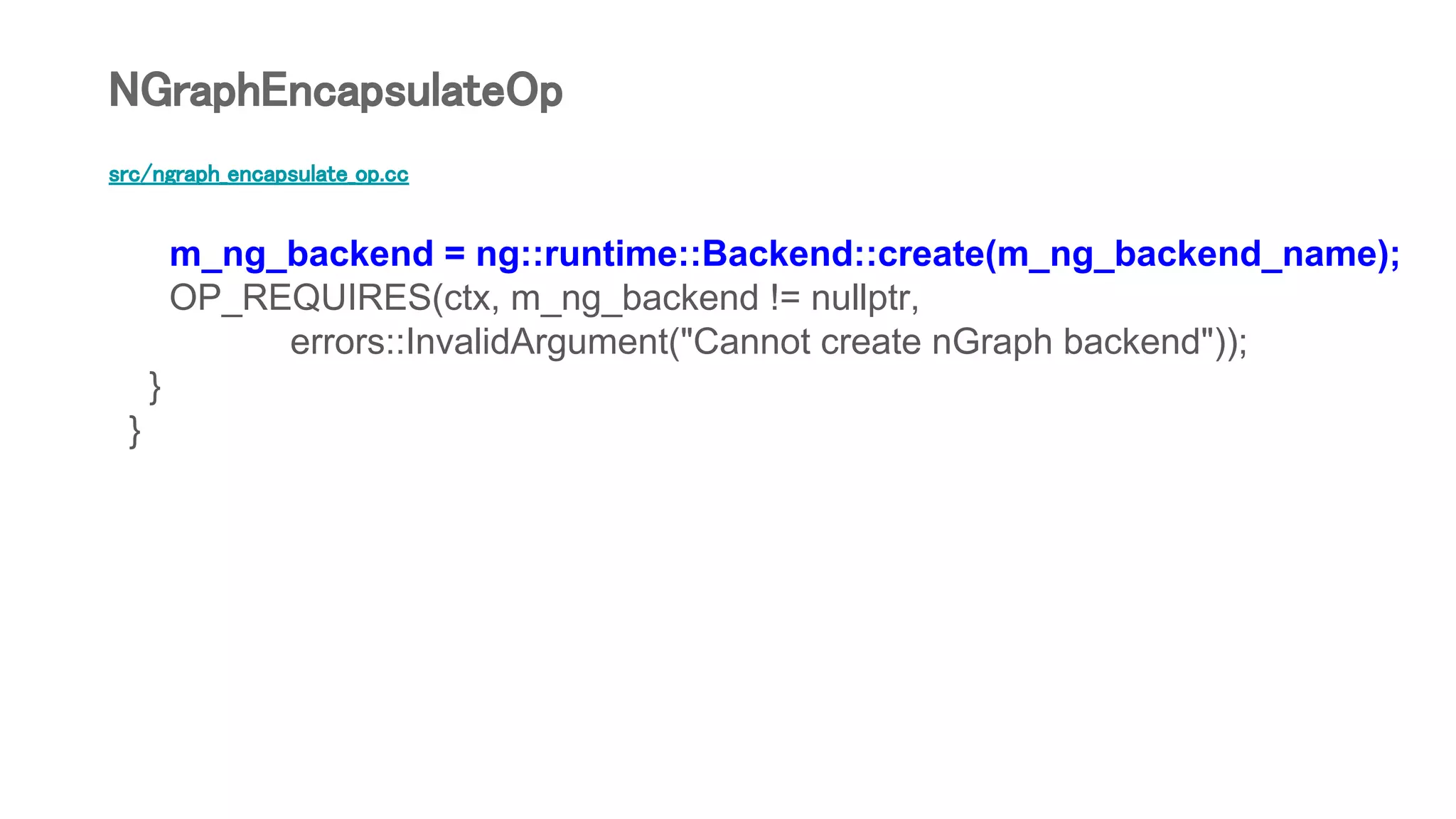


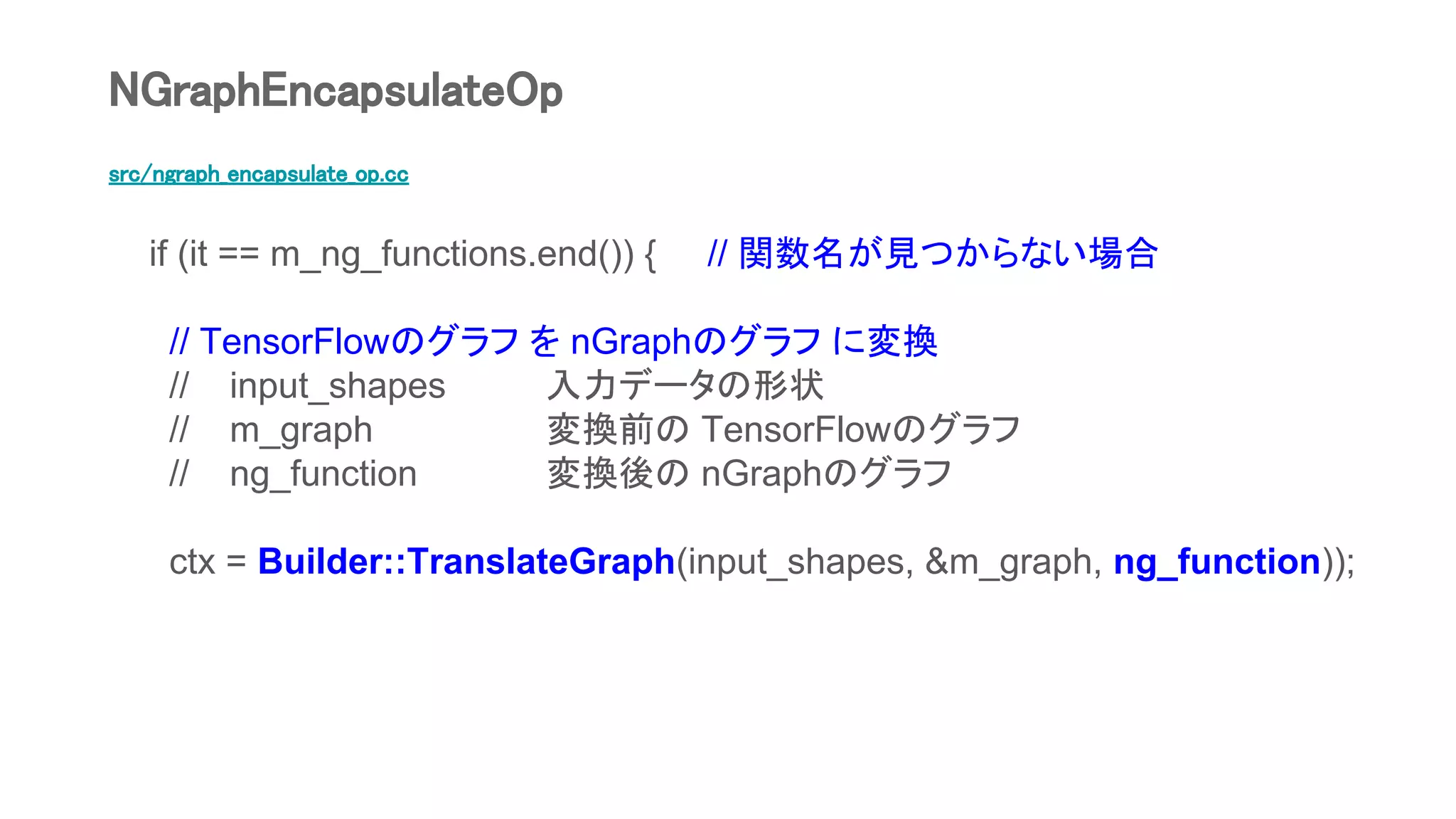

![src/ngraph_encapsulate_op.cc
m_ng_functions[signature] = ng_function; // 関数を登録
} else {
ng_function = it->second; // 登録済みの関数
}
NGraphEncapsulateOp](https://image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-72-2048.jpg)
 {
*tracker = new NGraphFreshnessTracker();
return Status::OK();
};
OP_REQUIRES_OK(
ctx,
ctx->resource_manager()->LookupOrCreate<NGraphFreshnessTracker>(
ctx->resource_manager()->default_container(),
"ngraph_freshness_tracker", &m_freshness_tracker, creator));
}
NGraphEncapsulateOp](https://image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-73-2048.jpg)
![src/ngraph_encapsulate_op.cc
vector<shared_ptr<ng::runtime::TensorView>> ng_inputs;
std::vector<std::pair<void*, std::shared_ptr<ng::runtime::TensorView>>>&
input_caches = m_ng_function_input_cache_map[ng_function];
input_caches.resize(input_shapes.size());
// 入力を nGraph用に変換
for (int i = 0; i < input_shapes.size(); i++) {
ng::Shape ng_shape(input_shapes[i].dims());
for (int j = 0; j < input_shapes[i].dims(); ++j) {
ng_shape[j] = input_shapes[i].dim_size(j);
}
NGraphEncapsulateOp](https://image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-74-2048.jpg)
![src/ngraph_encapsulate_op.cc
ng::element::Type ng_element_type;
ctx = TFDataTypeToNGraphElementType(ctx->input(i).dtype(),
&ng_element_type));
void* last_src_ptr = input_caches[i].first;
std::shared_ptr<ng::runtime::TensorView> last_tv = input_caches[i].second;
// 入力データを DMA
void* current_src_ptr = (void*)DMAHelper::base(&ctx->input(i));
std::shared_ptr<ng::runtime::TensorView> current_tv;
NGraphEncapsulateOp](https://image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-75-2048.jpg)

![src/ngraph_encapsulate_op.cc
} else {
if (last_tv != nullptr) {
current_tv = last_tv;
} else {
current_tv = m_ng_backend->create_tensor(ng_element_type, ng_shape);
}
current_tv->write(current_src_ptr, 0, current_tv->get_element_count() *
ng_element_type.size());
} // if (m_ng_backend_name == "CPU")
input_caches[i] = std::make_pair(current_src_ptr, current_tv);
ng_inputs.push_back(current_tv);
}
NGraphEncapsulateOp](https://image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-77-2048.jpg)
![src/ngraph_encapsulate_op.cc
// 出力
vector<shared_ptr<ng::runtime::TensorView>> ng_outputs;
std::vector<std::pair<void*, std::shared_ptr<ng::runtime::TensorView>>>&
output_caches = m_ng_function_output_cache_map[ng_function];
output_caches.resize(ng_function->get_output_size());
for (auto i = 0; i < ng_function->get_output_size(); i++) {
auto ng_shape = ng_function->get_output_shape(i);
auto ng_element_type = ng_function->get_output_element_type(i);
NGraphEncapsulateOp](https://image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-78-2048.jpg)

![src/ngraph_encapsulate_op.cc
OP_REQUIRES(
ctx, ng_element_type == expected_elem_type,
errors::Internal("Element type inferred by nGraph does not match "
"the element type expected by TensorFlow"));
void* last_dst_ptr = output_caches[i].first;
std::shared_ptr<ng::runtime::TensorView> last_tv =
output_caches[i].second;
NGraphEncapsulateOp](https://image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-80-2048.jpg)

![src/ngraph_encapsulate_op.cc
if (last_tv != nullptr) {
current_tv = last_tv;
} else {
current_tv = m_ng_backend->create_tensor(ng_element_type, ng_shape);
}
}
current_tv->set_stale(true);
output_caches[i] = std::make_pair(current_dst_ptr, current_tv);
ng_outputs.push_back(current_tv);
}
NGraphEncapsulateOp](https://image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-82-2048.jpg)

![src/ngraph_encapsulate_op.cc
// 出力をコピー
if (m_ng_backend_name != "CPU") {
for (size_t i = 0; i < output_caches.size(); ++i) {
void* dst_ptr;
std::shared_ptr<ng::runtime::TensorView> dst_tv;
std::tie(dst_ptr, dst_tv) = output_caches[i];
auto ng_element_type = dst_tv->get_tensor().get_element_type();
dst_tv->read(dst_ptr, 0,
dst_tv->get_element_count() * ng_element_type.size());
}
}
NGraphEncapsulateOp](https://image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-84-2048.jpg)







![src/ngraph_builder.cc
// TensorFlow のデータタイプを nGraphのエレメントタイプに変換
ng::element::Type ng_et;
TFDataTypeToNGraphElementType(dtype, &ng_et);
// TensorFlow のテンソルシェイプを nGraphのシェイプに変換
ng::Shape ng_shape;
TFTensorShapeToNGraphShape(inputs[index], &ng_shape);
auto ng_param = make_shared<ng::op::Parameter>(ng_et, ng_shape);
// nGraph の Opに
SaveNgOp(ng_op_map, parm->name(), ng_param);
ng_parameter_list[index] = ng_param;
}
Builder::TranslateGraph](https://image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-92-2048.jpg)


![src/ngraph_builder.cc
shared_ptr<ng::Node> result;
GetInputNode(ng_op_map, n, 0, &result);
ng_result_list[index] = result;
}
// nGraphの関数を生成 : nGraph Libraryを利用する
ng_function = make_shared<ng::Function>(ng_result_list, ng_parameter_list);
return Status::OK();
}
Builder::TranslateGraph](https://image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-95-2048.jpg)



























 {
*var = new NGraphVar(dtype_,shape_);
//(*var)->tensor()->set_shape(shape_);
return Status::OK();
};
NGraphVariableOp](https://crownmelresort.com/image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-21-2048.jpg)





![src/ngraph_rewrite_pass.cc
// Pass that rewrites the graph for nGraph operation.
//
// The pass has several phases, each executed in sequence:
//
// 1. Marking [ngraph_mark_for_clustering.cc]
// 2. Cluster Assignment [ngraph_assign_clusters.cc]
// 3. Cluster Deassignment [ngraph_deassign_clusters.cc]
// 4. Cluster Encapsulation [ngraph_encapsulate_clusters.cc]
NGraphEncapsulatePass](https://crownmelresort.com/image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-27-2048.jpg)

![src/ngraph_rewrite_pass.cc
// 1. Marking [ngraph_mark_for_clustering.cc]
// Mark for clustering then, if requested, dump the graphs.
TF_RETURN_IF_ERROR(MarkForClustering(options.graph->get()));
if (DumpMarkedGraphs()) {
DumpGraphs(options, idx, "marked", "Graph Marked for Clustering");
}
NGraphEncapsulatePass](https://crownmelresort.com/image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-29-2048.jpg)
![src/ngraph_rewrite_pass.cc
// 2. Cluster Assignment [ngraph_assign_clusters.cc]
// Assign clusters then, if requested, dump the graphs.
TF_RETURN_IF_ERROR(AssignClusters(options.graph->get()));
if (DumpClusteredGraphs()) {
DumpGraphs(options, idx, "clustered", "Graph with Clusters Assigned");
}
NGraphEncapsulatePass](https://crownmelresort.com/image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-30-2048.jpg)
![src/ngraph_rewrite_pass.cc
// 3. Cluster Deassignment [ngraph_deassign_clusters.cc]
// Deassign trivial clusters then, if requested, dump the graphs.
TF_RETURN_IF_ERROR(DeassignClusters(options.graph->get()));
if (DumpDeclusteredGraphs()) {
DumpGraphs(options, idx, "declustered",
"Graph with Trivial Clusters De-Assigned");
}
NGraphEncapsulatePass](https://crownmelresort.com/image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-31-2048.jpg)
![src/ngraph_rewrite_pass.cc
// 4. Cluster Encapsulation [ngraph_encapsulate_clusters.cc]
// Encapsulate clusters then, if requested, dump the graphs.
TF_RETURN_IF_ERROR(EncapsulateClusters(options.graph->get()));
if (DumpEncapsulatedGraphs()) {
DumpGraphs(options, idx, "encapsulated",
"Graph with Clusters Encapsulated");
}
NGraphEncapsulatePass](https://crownmelresort.com/image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-32-2048.jpg)



![src/ngraph_encapsulate_clusters.cc
// Pass 1: Populate the cluster-index-to-device name map for each existing
// cluster.
if (it != device_name_map.end()) {
if (it->second != node->requested_device()) {
std::stringstream ss_err;
// ここでエラーメッセージを生成
return errors::Internal(ss_err.str());
}
} else {
device_name_map[cluster_idx] = node->requested_device();
}
}
EncapsulateClusters](https://crownmelresort.com/image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-36-2048.jpg)



![src/ngraph_encapsulate_clusters.cc
if (src_clustered &&
output_remap_map.find(std::make_tuple(src->id(), edge->src_output())) ==
output_remap_map.end()) {
output_remap_map[std::make_tuple(src->id(), edge->src_output())] =
std::make_tuple(src_cluster_idx,
cluster_output_dt_map[src_cluster_idx].size());
std::stringstream ss;
ss << "ngraph_output_" << cluster_output_dt_map[src_cluster_idx].size();
string output_name = ss.str();
EncapsulateClusters](https://crownmelresort.com/image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-40-2048.jpg)

![src/ngraph_encapsulate_clusters.cc
SetAttrValue(dt, &((*(new_output_node_def->mutable_attr()))["T"]));
SetAttrValue(retval_index_count[src_cluster_idx],
&((*(new_output_node_def->mutable_attr()))["index"]));
retval_index_count[src_cluster_idx]++;
cluster_output_dt_map[src_cluster_idx].push_back(dt);
}
EncapsulateClusters](https://crownmelresort.com/image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-42-2048.jpg)
![src/ngraph_encapsulate_clusters.cc
if (dst_clustered &&
input_remap_map.find(
std::make_tuple(dst_cluster_idx, src->id(), edge->src_output())) ==
input_remap_map.end()) {
input_remap_map[std::make_tuple(dst_cluster_idx, src->id(),
edge->src_output())] =
cluster_input_map[dst_cluster_idx].size();
std::stringstream ss;
ss << "ngraph_input_" << cluster_input_map[dst_cluster_idx].size();
std::string new_input_name = ss.str();
EncapsulateClusters](https://crownmelresort.com/image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-43-2048.jpg)
![src/ngraph_encapsulate_clusters.cc
input_rename_map[std::make_tuple(dst_cluster_idx, src->name(),
edge->src_output())] = new_input_name;
auto new_input_node_def =
NGraphClusterManager::GetClusterGraph(dst_cluster_idx)->add_node();
new_input_node_def->set_name(new_input_name);
new_input_node_def->set_op("_Arg");
SetAttrValue(dt, &((*(new_input_node_def->mutable_attr()))["T"]));
SetAttrValue(arg_index_count[dst_cluster_idx],
&((*(new_input_node_def->mutable_attr()))["index"]));
EncapsulateClusters](https://crownmelresort.com/image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-44-2048.jpg)
![src/ngraph_encapsulate_clusters.cc
arg_index_count[dst_cluster_idx]++;
cluster_input_map[dst_cluster_idx].push_back(
std::make_tuple(src->id(), edge->src_output(), dt));
}
}
EncapsulateClusters](https://crownmelresort.com/image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-45-2048.jpg)

![src/ngraph_encapsulate_clusters.cc
for (auto& tup : cluster_input_map[cluster_idx]) {
int src_node_id;
int src_output_idx;
DataType dt;
std::tie(src_node_id, src_output_idx, dt) = tup;
input_types.push_back(dt);
inputs.push_back(
NodeBuilder::NodeOut(graph->FindNodeId(src_node_id), src_output_idx));
}
EncapsulateClusters](https://crownmelresort.com/image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-47-2048.jpg)
![src/ngraph_encapsulate_clusters.cc
Node* n;
Status status = NodeBuilder(ss.str(), "NGraphEncapsulate")
.Attr("ngraph_cluster", cluster_idx)
.Attr("Targuments", input_types)
.Attr("Tresults", cluster_output_dt_map[cluster_idx])
.Device(device_name_map[cluster_idx])
.Input(inputs)
.Finalize(graph, &n);
TF_RETURN_IF_ERROR(status);
n->set_assigned_device_name(device_name_map[cluster_idx]);
cluster_node_map[cluster_idx] = n;
}
EncapsulateClusters](https://crownmelresort.com/image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-48-2048.jpg)


![src/ngraph_encapsulate_clusters.cc
if (edge->IsControlEdge()) {
if (src_clustered && dst_clustered) {
graph->RemoveControlEdge(edge);
graph->AddControlEdge(cluster_node_map[src_cluster_idx],
cluster_node_map[dst_cluster_idx]);
} else if (src_clustered) {
Node* dst = edge->dst();
graph->RemoveControlEdge(edge);
graph->AddControlEdge(cluster_node_map[src_cluster_idx], dst);
EncapsulateClusters](https://crownmelresort.com/image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-51-2048.jpg)
![src/ngraph_encapsulate_clusters.cc
} else if (dst_clustered) {
Node* src = edge->src();
graph->RemoveControlEdge(edge);
graph->AddControlEdge(src, cluster_node_map[dst_cluster_idx]);
}
} else {
// This is handled at a later stage (TODO(amprocte): explain)
if (dst_clustered) {
continue;
}
EncapsulateClusters](https://crownmelresort.com/image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-52-2048.jpg)
![src/ngraph_encapsulate_clusters.cc
auto it = output_remap_map.find(
std::make_tuple(edge->src()->id(), edge->src_output()));
if (it == output_remap_map.end()) {
continue;
}
int cluster_idx, cluster_output;
std::tie(cluster_idx, cluster_output) = it->second;
graph->UpdateEdge(cluster_node_map[cluster_idx], cluster_output,
edge->dst(), edge->dst_input());
}
}
EncapsulateClusters](https://crownmelresort.com/image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-53-2048.jpg)


![src/ngraph_encapsulate_clusters.cc
original_def.clear_input();
original_def.mutable_input()->Reserve(inputs.size());
for (size_t i = 0; i < inputs.size(); ++i) {
const Edge* edge = inputs[i];
if (edge == nullptr) {
if (i < node->requested_inputs().size()) {
original_def.add_input(node->requested_inputs()[i]);
} else {
original_def.add_input("");
EncapsulateClusters](https://crownmelresort.com/image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-56-2048.jpg)















![src/ngraph_encapsulate_op.cc
m_ng_functions[signature] = ng_function; // 関数を登録
} else {
ng_function = it->second; // 登録済みの関数
}
NGraphEncapsulateOp](https://crownmelresort.com/image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-72-2048.jpg)
 {
*tracker = new NGraphFreshnessTracker();
return Status::OK();
};
OP_REQUIRES_OK(
ctx,
ctx->resource_manager()->LookupOrCreate<NGraphFreshnessTracker>(
ctx->resource_manager()->default_container(),
"ngraph_freshness_tracker", &m_freshness_tracker, creator));
}
NGraphEncapsulateOp](https://crownmelresort.com/image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-73-2048.jpg)
![src/ngraph_encapsulate_op.cc
vector<shared_ptr<ng::runtime::TensorView>> ng_inputs;
std::vector<std::pair<void*, std::shared_ptr<ng::runtime::TensorView>>>&
input_caches = m_ng_function_input_cache_map[ng_function];
input_caches.resize(input_shapes.size());
// 入力を nGraph用に変換
for (int i = 0; i < input_shapes.size(); i++) {
ng::Shape ng_shape(input_shapes[i].dims());
for (int j = 0; j < input_shapes[i].dims(); ++j) {
ng_shape[j] = input_shapes[i].dim_size(j);
}
NGraphEncapsulateOp](https://crownmelresort.com/image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-74-2048.jpg)
![src/ngraph_encapsulate_op.cc
ng::element::Type ng_element_type;
ctx = TFDataTypeToNGraphElementType(ctx->input(i).dtype(),
&ng_element_type));
void* last_src_ptr = input_caches[i].first;
std::shared_ptr<ng::runtime::TensorView> last_tv = input_caches[i].second;
// 入力データを DMA
void* current_src_ptr = (void*)DMAHelper::base(&ctx->input(i));
std::shared_ptr<ng::runtime::TensorView> current_tv;
NGraphEncapsulateOp](https://crownmelresort.com/image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-75-2048.jpg)

![src/ngraph_encapsulate_op.cc
} else {
if (last_tv != nullptr) {
current_tv = last_tv;
} else {
current_tv = m_ng_backend->create_tensor(ng_element_type, ng_shape);
}
current_tv->write(current_src_ptr, 0, current_tv->get_element_count() *
ng_element_type.size());
} // if (m_ng_backend_name == "CPU")
input_caches[i] = std::make_pair(current_src_ptr, current_tv);
ng_inputs.push_back(current_tv);
}
NGraphEncapsulateOp](https://crownmelresort.com/image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-77-2048.jpg)
![src/ngraph_encapsulate_op.cc
// 出力
vector<shared_ptr<ng::runtime::TensorView>> ng_outputs;
std::vector<std::pair<void*, std::shared_ptr<ng::runtime::TensorView>>>&
output_caches = m_ng_function_output_cache_map[ng_function];
output_caches.resize(ng_function->get_output_size());
for (auto i = 0; i < ng_function->get_output_size(); i++) {
auto ng_shape = ng_function->get_output_shape(i);
auto ng_element_type = ng_function->get_output_element_type(i);
NGraphEncapsulateOp](https://crownmelresort.com/image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-78-2048.jpg)

![src/ngraph_encapsulate_op.cc
OP_REQUIRES(
ctx, ng_element_type == expected_elem_type,
errors::Internal("Element type inferred by nGraph does not match "
"the element type expected by TensorFlow"));
void* last_dst_ptr = output_caches[i].first;
std::shared_ptr<ng::runtime::TensorView> last_tv =
output_caches[i].second;
NGraphEncapsulateOp](https://crownmelresort.com/image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-80-2048.jpg)

![src/ngraph_encapsulate_op.cc
if (last_tv != nullptr) {
current_tv = last_tv;
} else {
current_tv = m_ng_backend->create_tensor(ng_element_type, ng_shape);
}
}
current_tv->set_stale(true);
output_caches[i] = std::make_pair(current_dst_ptr, current_tv);
ng_outputs.push_back(current_tv);
}
NGraphEncapsulateOp](https://crownmelresort.com/image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-82-2048.jpg)

![src/ngraph_encapsulate_op.cc
// 出力をコピー
if (m_ng_backend_name != "CPU") {
for (size_t i = 0; i < output_caches.size(); ++i) {
void* dst_ptr;
std::shared_ptr<ng::runtime::TensorView> dst_tv;
std::tie(dst_ptr, dst_tv) = output_caches[i];
auto ng_element_type = dst_tv->get_tensor().get_element_type();
dst_tv->read(dst_ptr, 0,
dst_tv->get_element_count() * ng_element_type.size());
}
}
NGraphEncapsulateOp](https://crownmelresort.com/image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-84-2048.jpg)







![src/ngraph_builder.cc
// TensorFlow のデータタイプを nGraphのエレメントタイプに変換
ng::element::Type ng_et;
TFDataTypeToNGraphElementType(dtype, &ng_et);
// TensorFlow のテンソルシェイプを nGraphのシェイプに変換
ng::Shape ng_shape;
TFTensorShapeToNGraphShape(inputs[index], &ng_shape);
auto ng_param = make_shared<ng::op::Parameter>(ng_et, ng_shape);
// nGraph の Opに
SaveNgOp(ng_op_map, parm->name(), ng_param);
ng_parameter_list[index] = ng_param;
}
Builder::TranslateGraph](https://crownmelresort.com/image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-92-2048.jpg)


![src/ngraph_builder.cc
shared_ptr<ng::Node> result;
GetInputNode(ng_op_map, n, 0, &result);
ng_result_list[index] = result;
}
// nGraphの関数を生成 : nGraph Libraryを利用する
ng_function = make_shared<ng::Function>(ng_result_list, ng_parameter_list);
return Status::OK();
}
Builder::TranslateGraph](https://crownmelresort.com/image.slidesharecdn.com/bridgetensorflowtorunonintelngraphbackendsv05-180825013103/75/Bridge-TensorFlow-to-run-on-Intel-nGraph-backends-v0-5-95-2048.jpg)









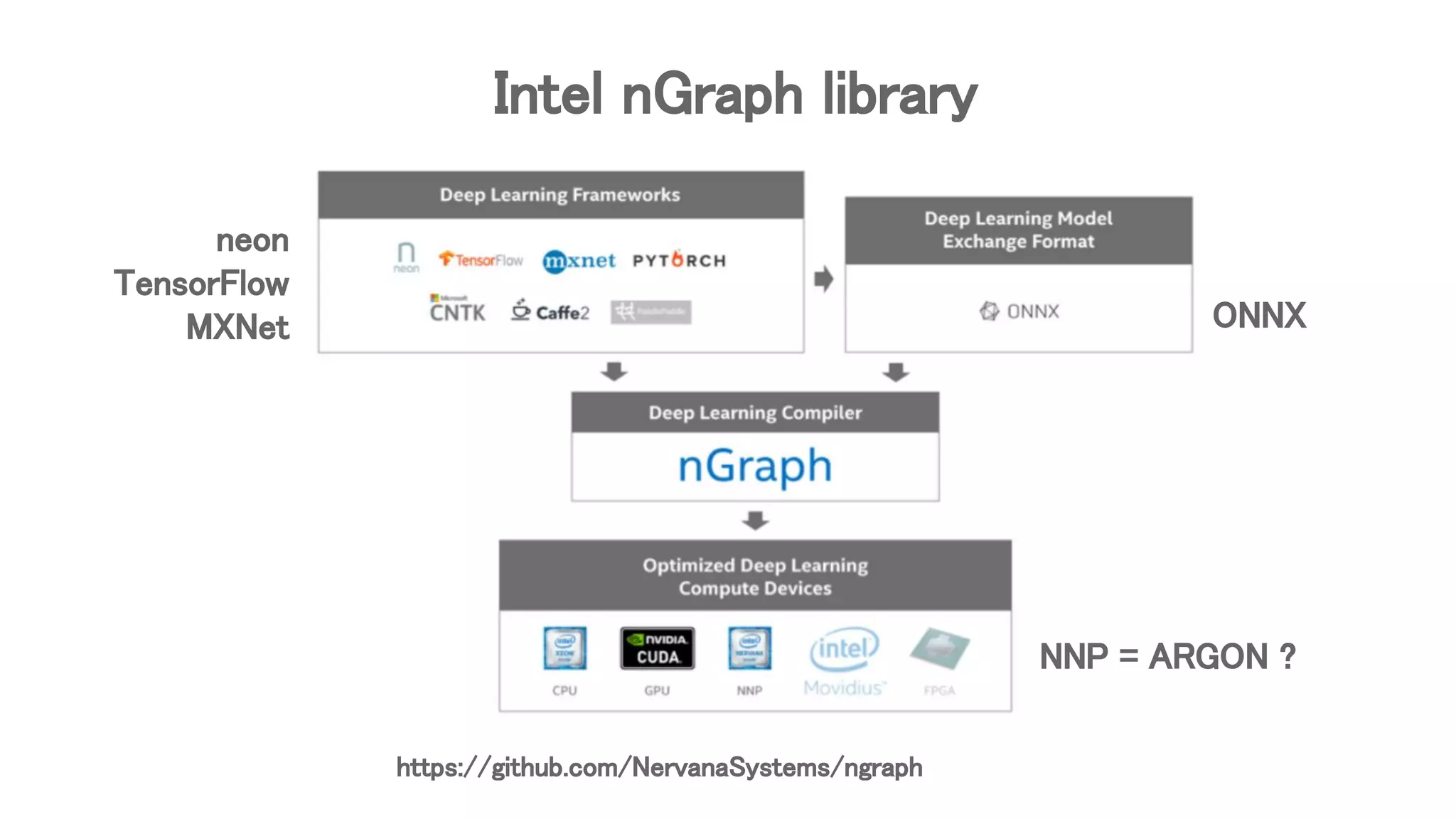
The document describes how the nGraph TensorFlow bridge works by rewriting TensorFlow graphs to run on Intel nGraph backends. It discusses how optimization passes are used to modify the graph in several phases: 1) Capturing TensorFlow variables as nGraph variables, 2) Marking/assigning/deassigning nodes to clusters, 3) Encapsulating clusters into nGraphEncapsulateOp nodes to run subgraphs on nGraph. Key classes and files involved are described like NGraphVariableCapturePass, NGraphEncapsulatePass, and how they implement the different rewriting phases to prepare the graph for nGraph execution.













































































