Downloaded 18 times










![def _ExecuteAndCompareClose (self, c, arguments=(), expected=None):
self._ExecuteAndAssertWith (np.testing.assert_allclose, c, arguments,
expected)
def _ExecuteAndAssertWith (self, assert_func, c, arguments, expected):
assert expected is not None
result = self._Execute(c, arguments)
# Numpy's comparison methods are a bit too lenient by treating inputs as
# "array-like", meaning that scalar 4 will be happily compared equal to
# [[4]]. We'd like to be more strict so assert shapes as well.
self.assertEqual(np.asanyarray(result).shape, np.asanyarray(expected).shape)
assert_func(result, expected)
xla_client_test.py](https://image.slidesharecdn.com/tensorflowr1-180804060642/75/TensorFlow-local-Python-XLA-client-13-2048.jpg)


![tf_py_wrap_cc(
name = "pywrap_xla",
srcs = ["xla.i"],
swig_includes = [
"local_computation_builder.i",
],
deps = [
":local_computation_builder",
":numpy_bridge",
"//tensorflow/compiler/xla:literal_util",
"//tensorflow/compiler/xla:shape_util",
"//tensorflow/compiler/xla:xla_data_proto",
"//tensorflow/compiler/xla/service: cpu_plugin",
],
)
BUILD](https://image.slidesharecdn.com/tensorflowr1-180804060642/75/TensorFlow-local-Python-XLA-client-16-2048.jpg)

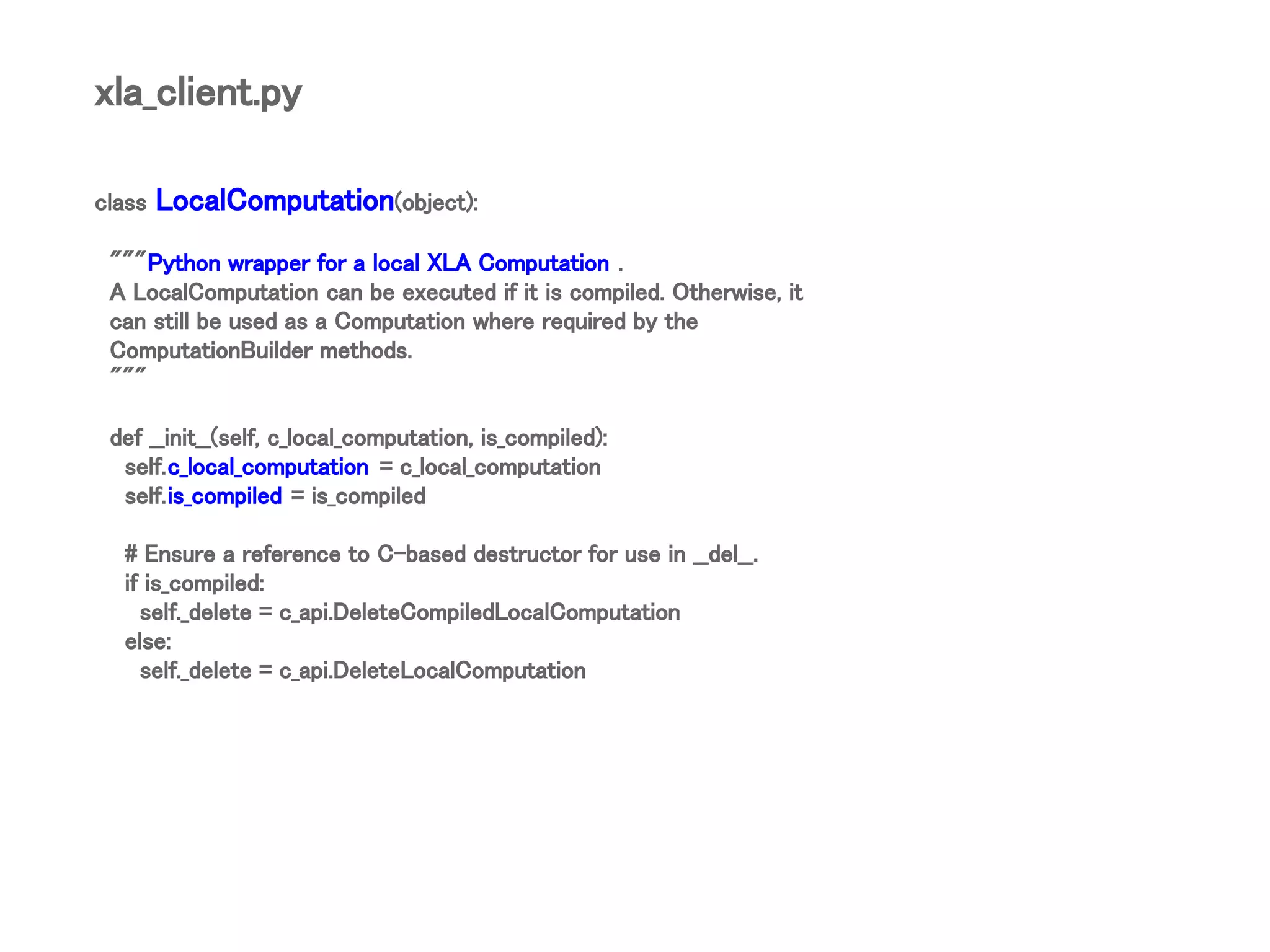
![LocalComputationクラス
def Compile(self, argument_shapes=(), compile_options=None,
layout_fn=None):
if self.is_compiled:
raise ValueError('Attempt to compile a compiled local XLA computation.')
if layout_fn:
argument_shapes = [
shape.map_leaves(layout_fn) for shape in argument_shapes
]
return LocalComputation(
self.c_local_computation.Compile (argument_shapes, compile_options),
is_compiled=True)
xla_client.py](https://image.slidesharecdn.com/tensorflowr1-180804060642/75/TensorFlow-local-Python-XLA-client-19-2048.jpg)
![def Execute(self, arguments=(), layout_fn=None):
"""Execute with Python values as arguments and return value."""
if not self.is_compiled:
raise ValueError('Cannot execute an uncompiled local XLA computation.')
argument_shapes = [Shape.from_numpy(arg) for arg in arguments]
if layout_fn:
argument_shapes = [
shape.map_leaves(layout_fn) for shape in argument_shapes
]
else:
argument_shapes = [None for shape in argument_shapes]
arguments = tuple(map(require_numpy_array_layout, arguments))
return self.c_local_computation.Execute (arguments, argument_shapes)
LocalComputationクラス](https://image.slidesharecdn.com/tensorflowr1-180804060642/75/TensorFlow-local-Python-XLA-client-20-2048.jpg)



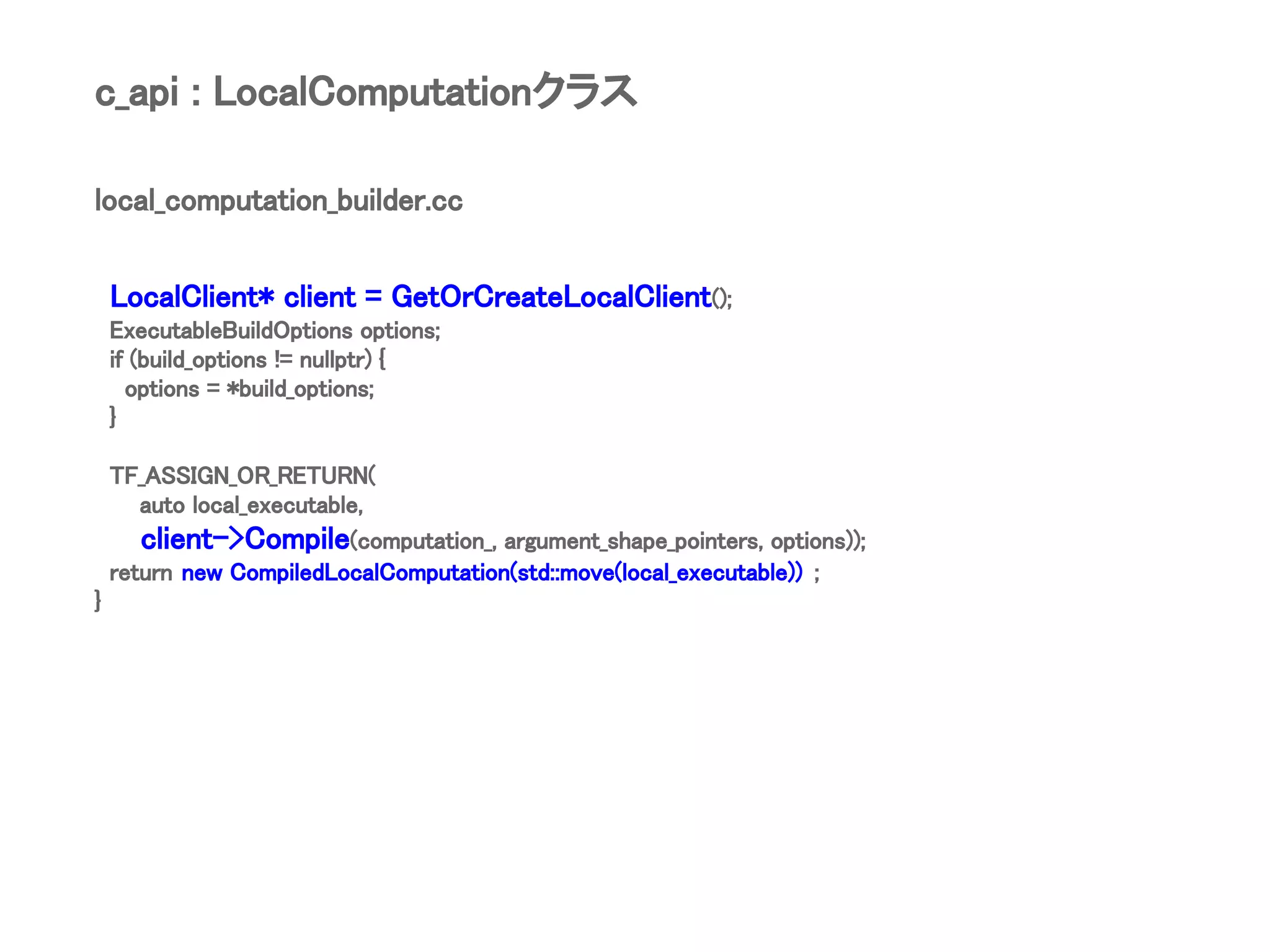


![local_computation_builder.cc
StatusOr<std::unique_ptr<Literal>> CompiledLocalComputation:: Execute(
const std::vector<Literal>& arguments,
const std::vector<tensorflow::gtl::optional<Shape>>& shapes_with_layout) {
// 途中略
StatusOr<std::unique_ptr<ScopedShapedBuffer>> result_buffer_status =
executable_->Run(argument_buffers, options);
if (!result_buffer_status.ok()) {
results[replica] = result_buffer_status.status();
return;
}
// 途中略
}
c_api : CompiledLocalComputationクラス](https://image.slidesharecdn.com/tensorflowr1-180804060642/75/TensorFlow-local-Python-XLA-client-27-2048.jpg)



![def testInfeedS32Values(self):
to_infeed = NumpyArrayS32([1, 2, 3, 4])
c = self._NewComputation()
c.Infeed(xla_client.Shape.from_numpy(to_infeed[0]))
compiled_c = c.Build().CompileWithExampleArguments()
for item in to_infeed:
xla_client.transfer_to_infeed (item)
for item in to_infeed:
result = compiled_c.Execute()
self.assertEqual(result, item)
Infeed : xla_client_test.py](https://image.slidesharecdn.com/tensorflowr1-180804060642/75/TensorFlow-local-Python-XLA-client-32-2048.jpg)

![def testInfeedThenOutfeedS32(self):
to_round_trip = NumpyArrayS32([1, 2, 3, 4])
c = self._NewComputation()
x = c.Infeed(xla_client.Shape.from_numpy(to_round_trip[0]))
c.Outfeed(x)
compiled_c = c.Build().CompileWithExampleArguments()
for want in to_round_trip:
execution = threading.Thread(target=compiled_c.Execute)
execution.start()
xla_client.transfer_to_infeed(want)
got = xla_client.transfer_from_outfeed (
xla_client.Shape.from_numpy(to_round_trip[0]))
execution.join()
self.assertEqual(want, got)
Outfeed : xla_client_test.py](https://image.slidesharecdn.com/tensorflowr1-180804060642/75/TensorFlow-local-Python-XLA-client-34-2048.jpg)
















![def _ExecuteAndCompareClose (self, c, arguments=(), expected=None):
self._ExecuteAndAssertWith (np.testing.assert_allclose, c, arguments,
expected)
def _ExecuteAndAssertWith (self, assert_func, c, arguments, expected):
assert expected is not None
result = self._Execute(c, arguments)
# Numpy's comparison methods are a bit too lenient by treating inputs as
# "array-like", meaning that scalar 4 will be happily compared equal to
# [[4]]. We'd like to be more strict so assert shapes as well.
self.assertEqual(np.asanyarray(result).shape, np.asanyarray(expected).shape)
assert_func(result, expected)
xla_client_test.py](https://crownmelresort.com/image.slidesharecdn.com/tensorflowr1-180804060642/75/TensorFlow-local-Python-XLA-client-13-2048.jpg)


![tf_py_wrap_cc(
name = "pywrap_xla",
srcs = ["xla.i"],
swig_includes = [
"local_computation_builder.i",
],
deps = [
":local_computation_builder",
":numpy_bridge",
"//tensorflow/compiler/xla:literal_util",
"//tensorflow/compiler/xla:shape_util",
"//tensorflow/compiler/xla:xla_data_proto",
"//tensorflow/compiler/xla/service: cpu_plugin",
],
)
BUILD](https://crownmelresort.com/image.slidesharecdn.com/tensorflowr1-180804060642/75/TensorFlow-local-Python-XLA-client-16-2048.jpg)


![LocalComputationクラス
def Compile(self, argument_shapes=(), compile_options=None,
layout_fn=None):
if self.is_compiled:
raise ValueError('Attempt to compile a compiled local XLA computation.')
if layout_fn:
argument_shapes = [
shape.map_leaves(layout_fn) for shape in argument_shapes
]
return LocalComputation(
self.c_local_computation.Compile (argument_shapes, compile_options),
is_compiled=True)
xla_client.py](https://crownmelresort.com/image.slidesharecdn.com/tensorflowr1-180804060642/75/TensorFlow-local-Python-XLA-client-19-2048.jpg)
![def Execute(self, arguments=(), layout_fn=None):
"""Execute with Python values as arguments and return value."""
if not self.is_compiled:
raise ValueError('Cannot execute an uncompiled local XLA computation.')
argument_shapes = [Shape.from_numpy(arg) for arg in arguments]
if layout_fn:
argument_shapes = [
shape.map_leaves(layout_fn) for shape in argument_shapes
]
else:
argument_shapes = [None for shape in argument_shapes]
arguments = tuple(map(require_numpy_array_layout, arguments))
return self.c_local_computation.Execute (arguments, argument_shapes)
LocalComputationクラス](https://crownmelresort.com/image.slidesharecdn.com/tensorflowr1-180804060642/75/TensorFlow-local-Python-XLA-client-20-2048.jpg)






![local_computation_builder.cc
StatusOr<std::unique_ptr<Literal>> CompiledLocalComputation:: Execute(
const std::vector<Literal>& arguments,
const std::vector<tensorflow::gtl::optional<Shape>>& shapes_with_layout) {
// 途中略
StatusOr<std::unique_ptr<ScopedShapedBuffer>> result_buffer_status =
executable_->Run(argument_buffers, options);
if (!result_buffer_status.ok()) {
results[replica] = result_buffer_status.status();
return;
}
// 途中略
}
c_api : CompiledLocalComputationクラス](https://crownmelresort.com/image.slidesharecdn.com/tensorflowr1-180804060642/75/TensorFlow-local-Python-XLA-client-27-2048.jpg)




![def testInfeedS32Values(self):
to_infeed = NumpyArrayS32([1, 2, 3, 4])
c = self._NewComputation()
c.Infeed(xla_client.Shape.from_numpy(to_infeed[0]))
compiled_c = c.Build().CompileWithExampleArguments()
for item in to_infeed:
xla_client.transfer_to_infeed (item)
for item in to_infeed:
result = compiled_c.Execute()
self.assertEqual(result, item)
Infeed : xla_client_test.py](https://crownmelresort.com/image.slidesharecdn.com/tensorflowr1-180804060642/75/TensorFlow-local-Python-XLA-client-32-2048.jpg)

![def testInfeedThenOutfeedS32(self):
to_round_trip = NumpyArrayS32([1, 2, 3, 4])
c = self._NewComputation()
x = c.Infeed(xla_client.Shape.from_numpy(to_round_trip[0]))
c.Outfeed(x)
compiled_c = c.Build().CompileWithExampleArguments()
for want in to_round_trip:
execution = threading.Thread(target=compiled_c.Execute)
execution.start()
xla_client.transfer_to_infeed(want)
got = xla_client.transfer_from_outfeed (
xla_client.Shape.from_numpy(to_round_trip[0]))
execution.join()
self.assertEqual(want, got)
Outfeed : xla_client_test.py](https://crownmelresort.com/image.slidesharecdn.com/tensorflowr1-180804060642/75/TensorFlow-local-Python-XLA-client-34-2048.jpg)









The document discusses the implementation and functionality of the TensorFlow XLA (Accelerated Linear Algebra) local Python client, detailing its internal structure, compilation process, and various testing components for executing computations. It outlines how computations are built, optimized, and executed using both high-level and low-level optimization techniques, emphasizing the coupling between Python interfaces and the underlying C++ code. Additionally, it includes references to tests conducted to validate the performance and correctness of the local client within the TensorFlow framework.


























































