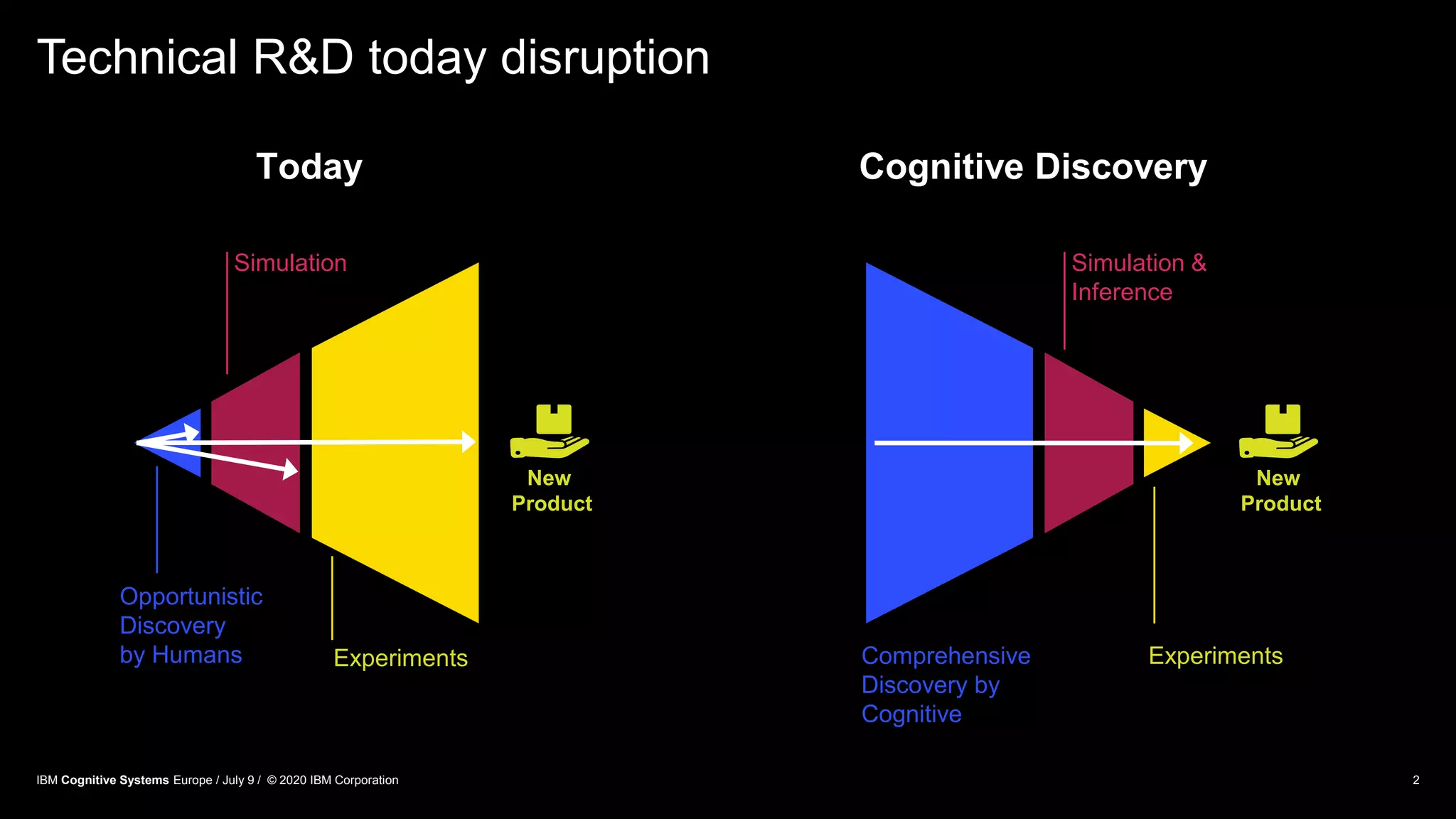
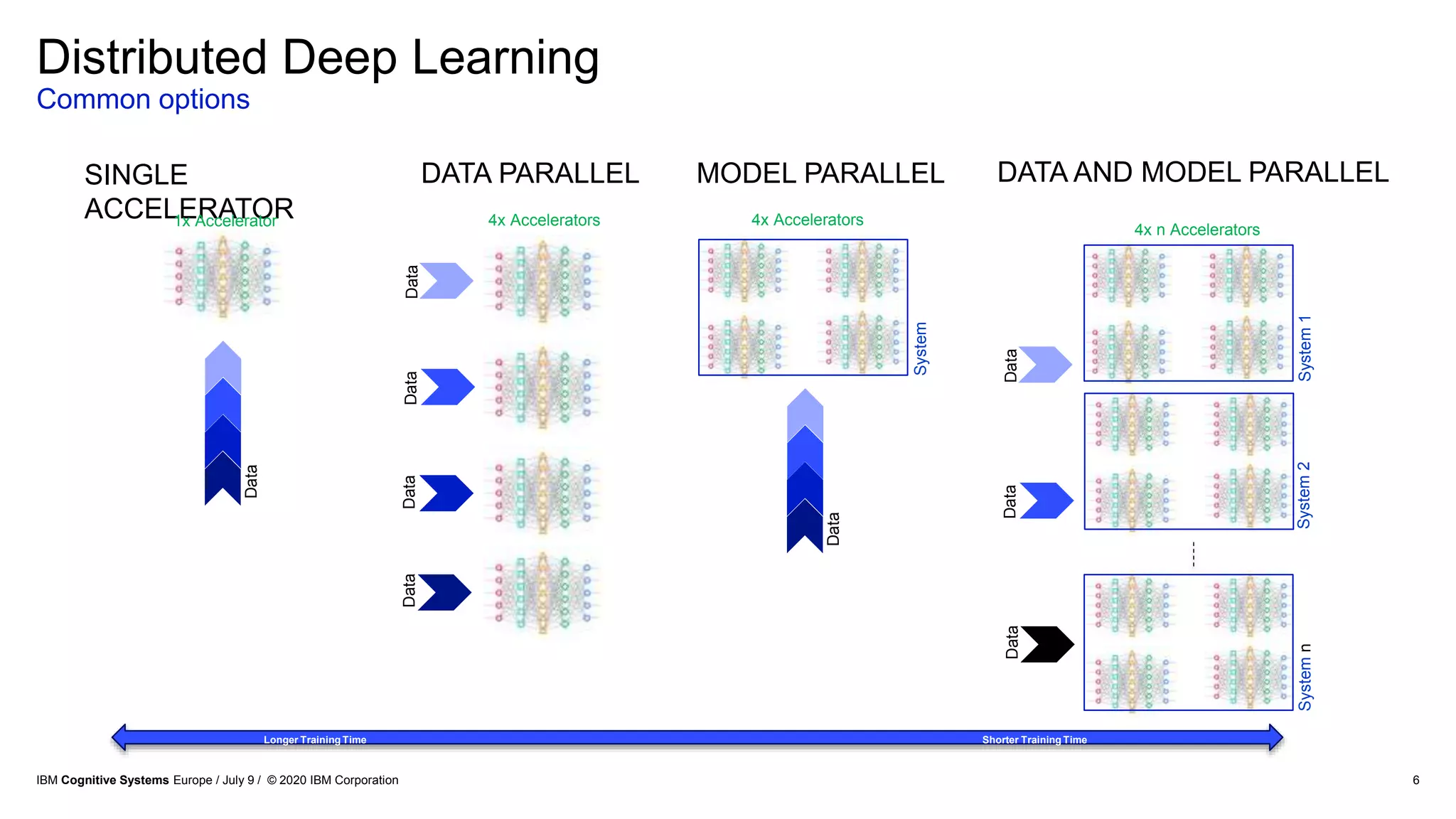
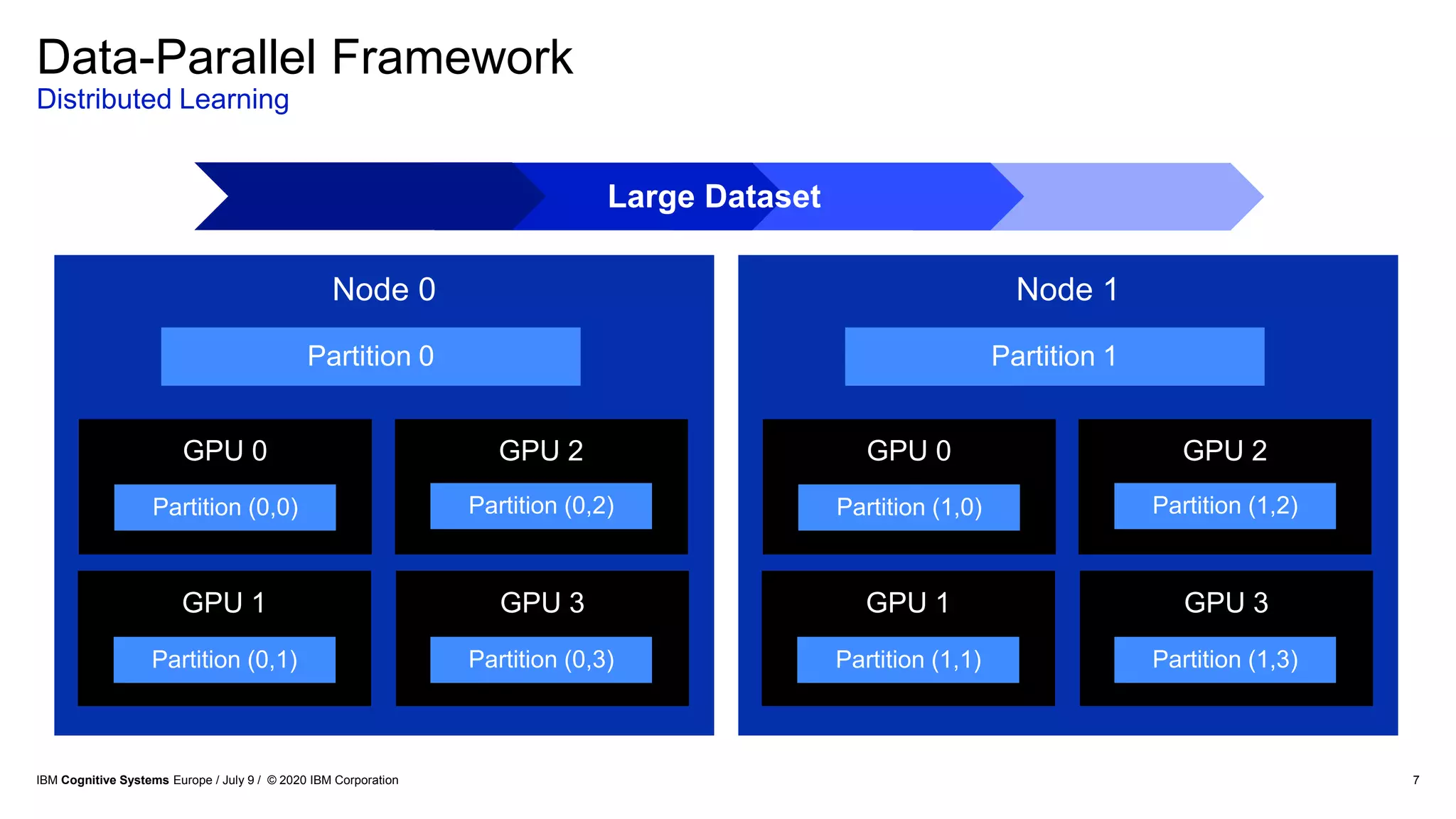
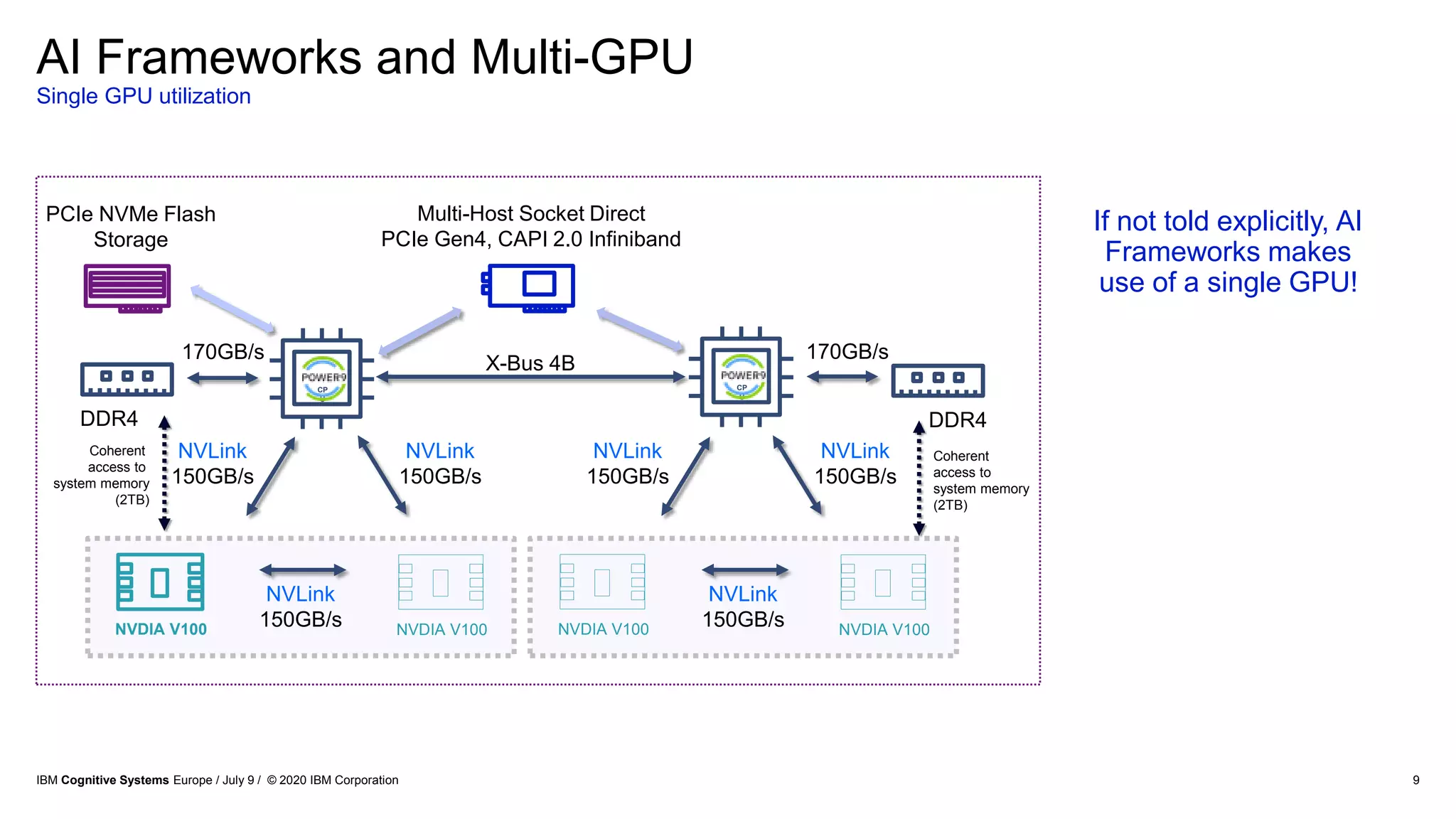
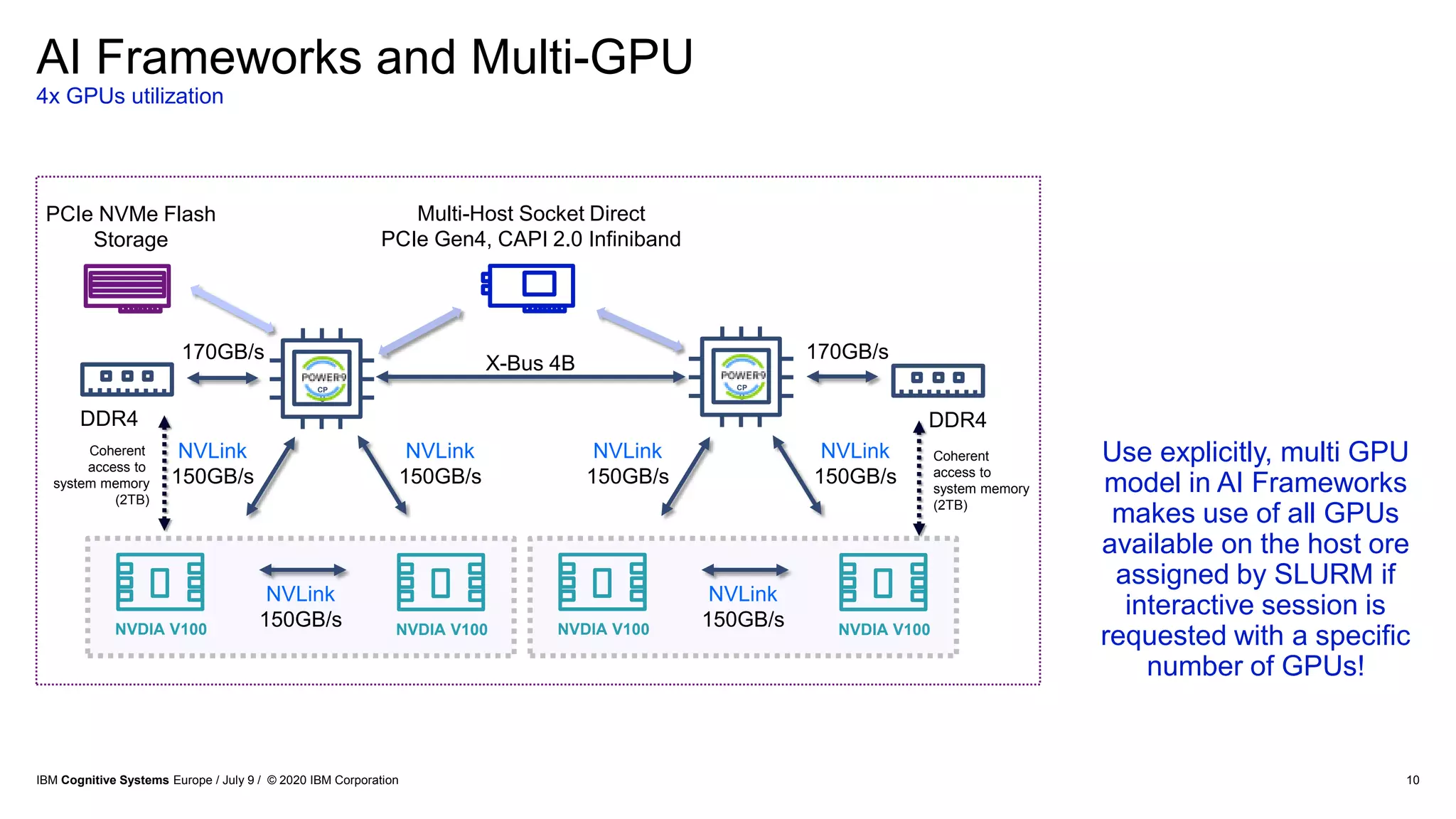
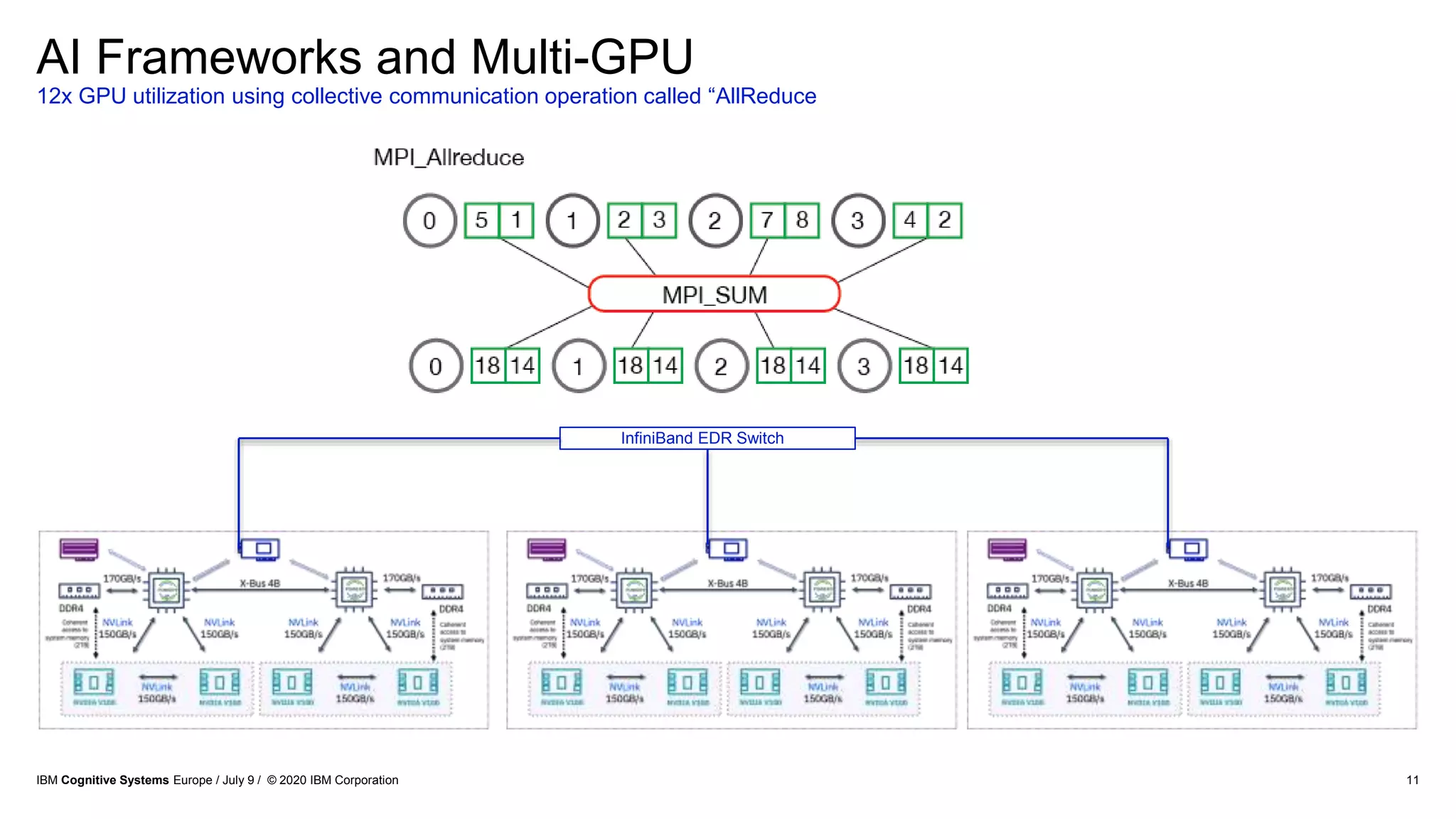
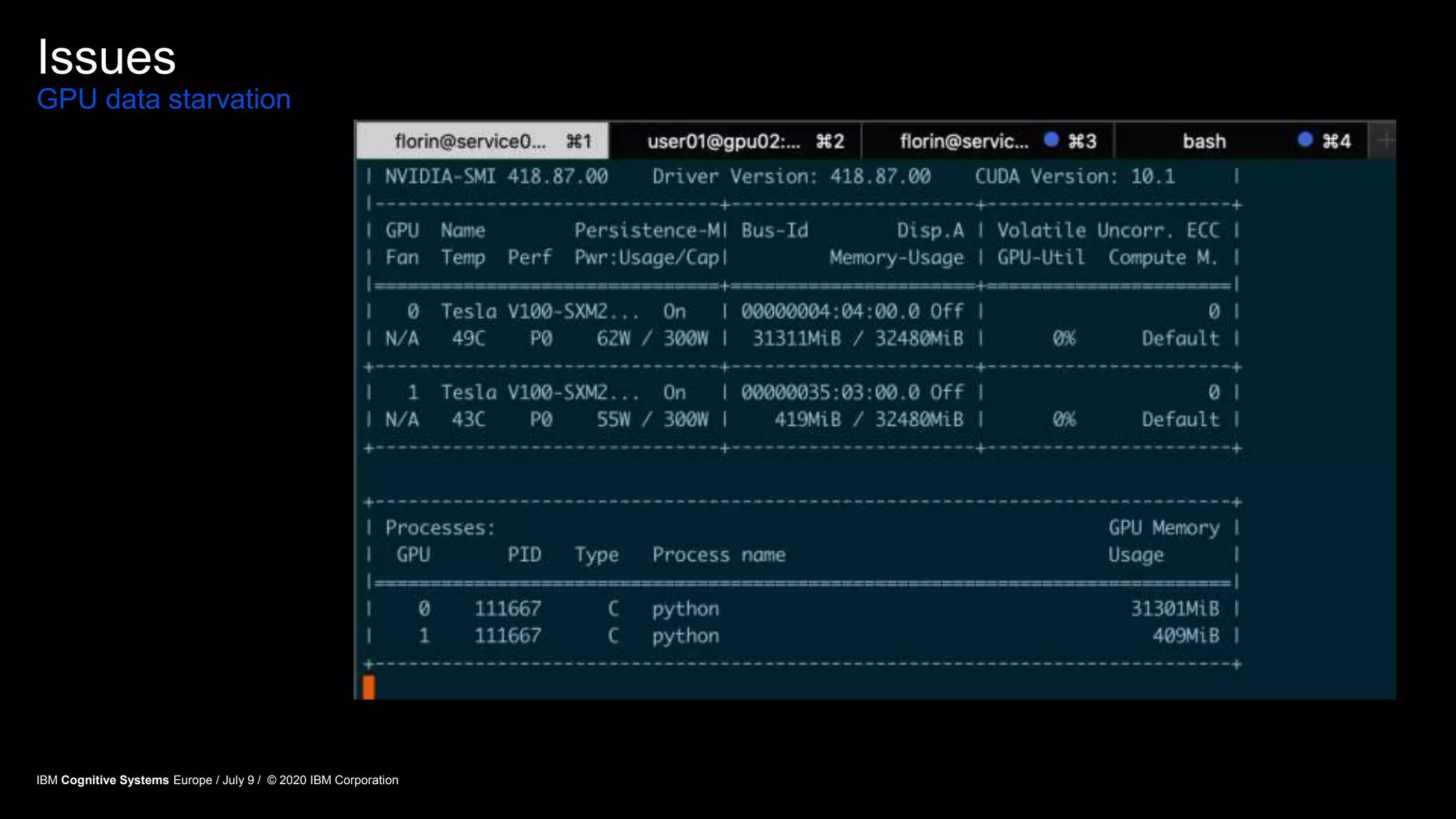
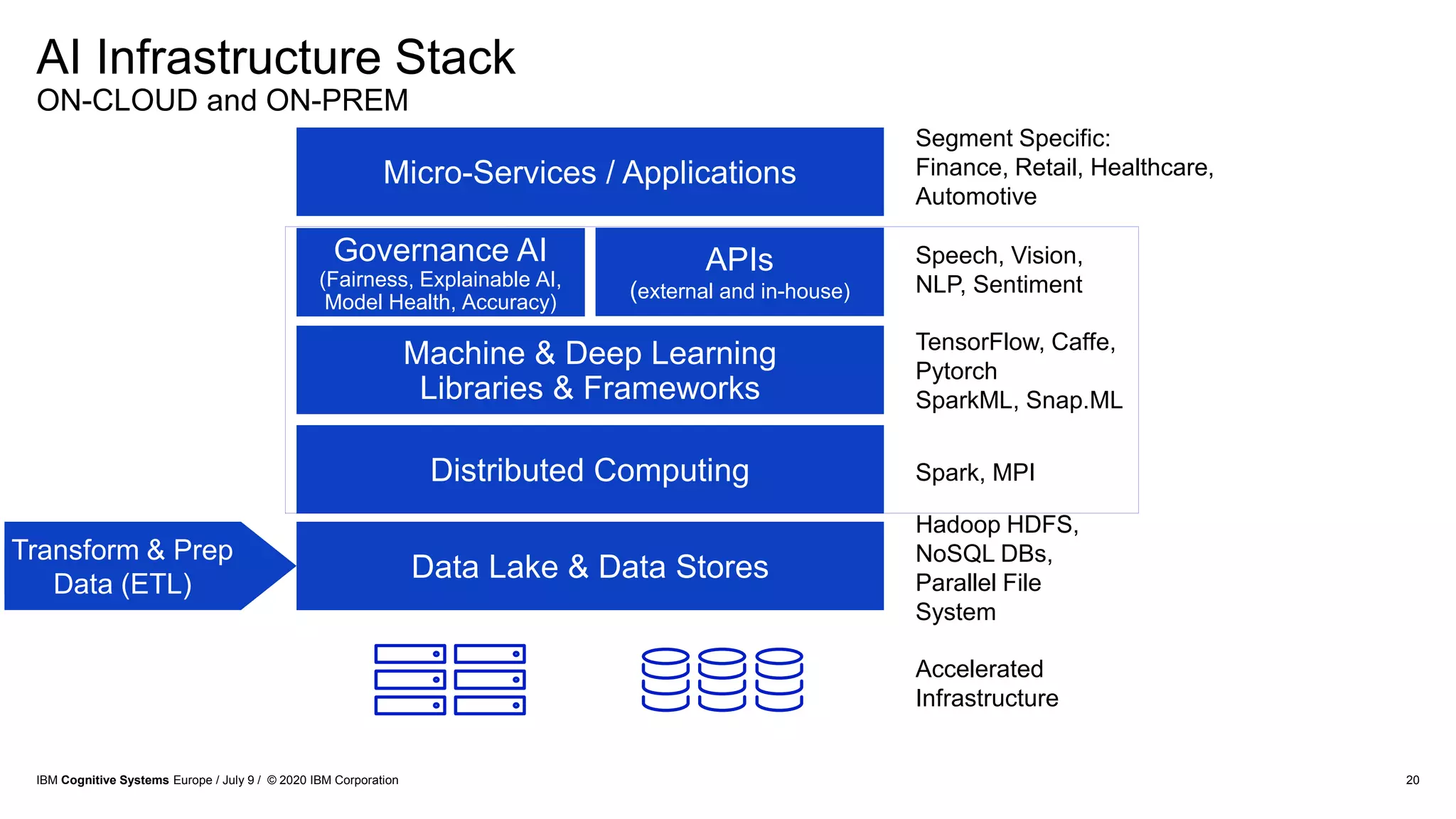
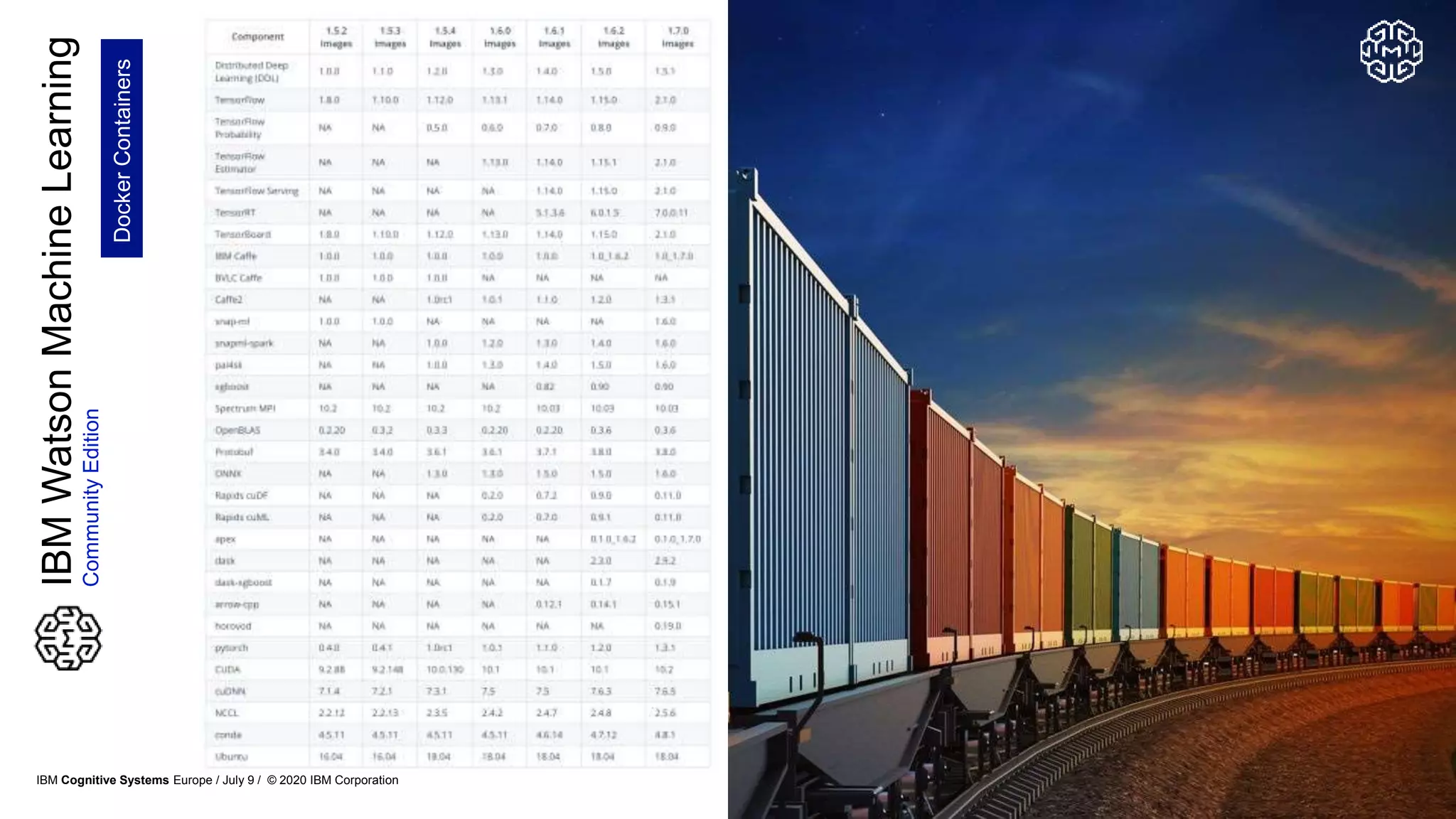
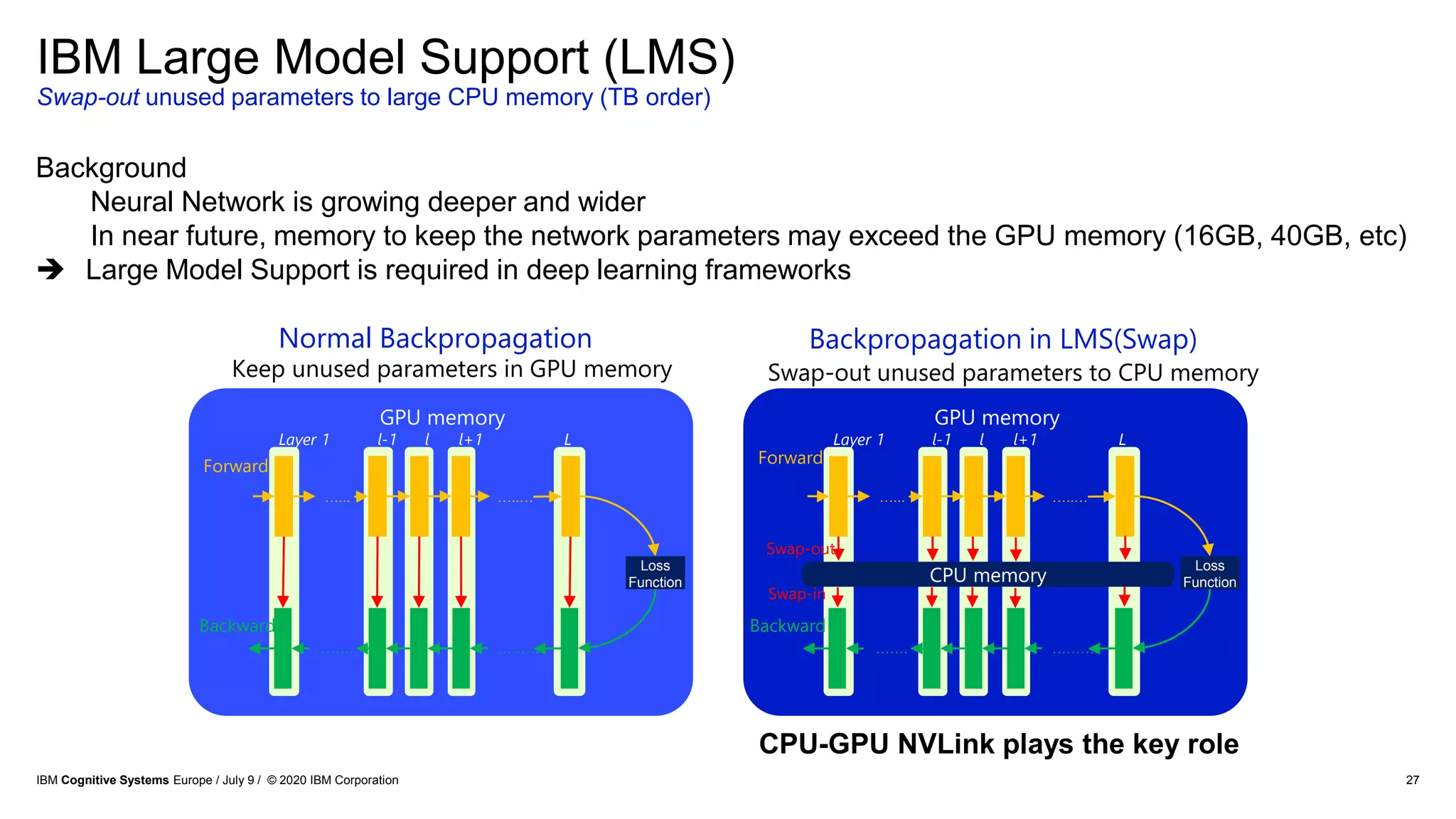
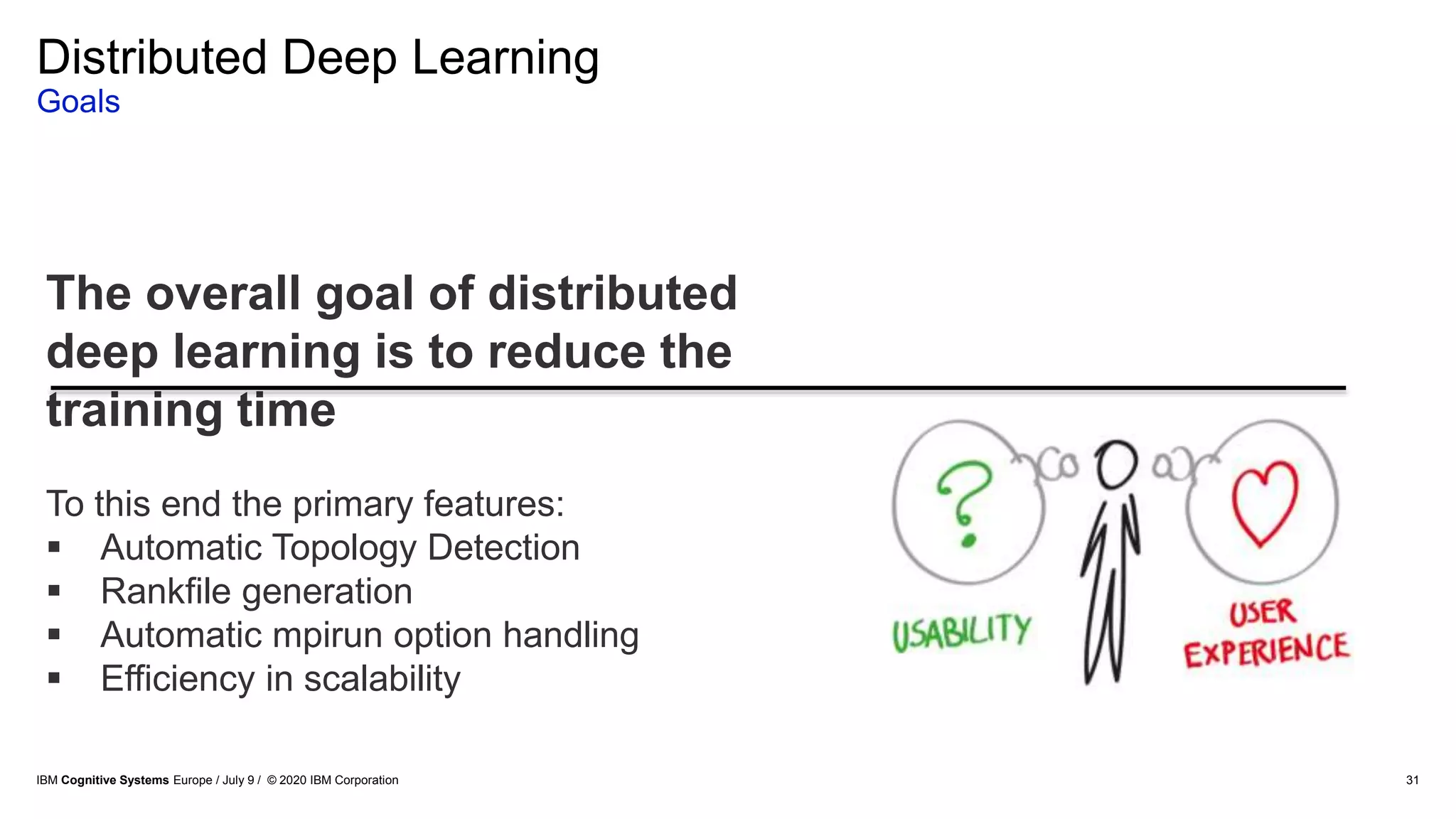
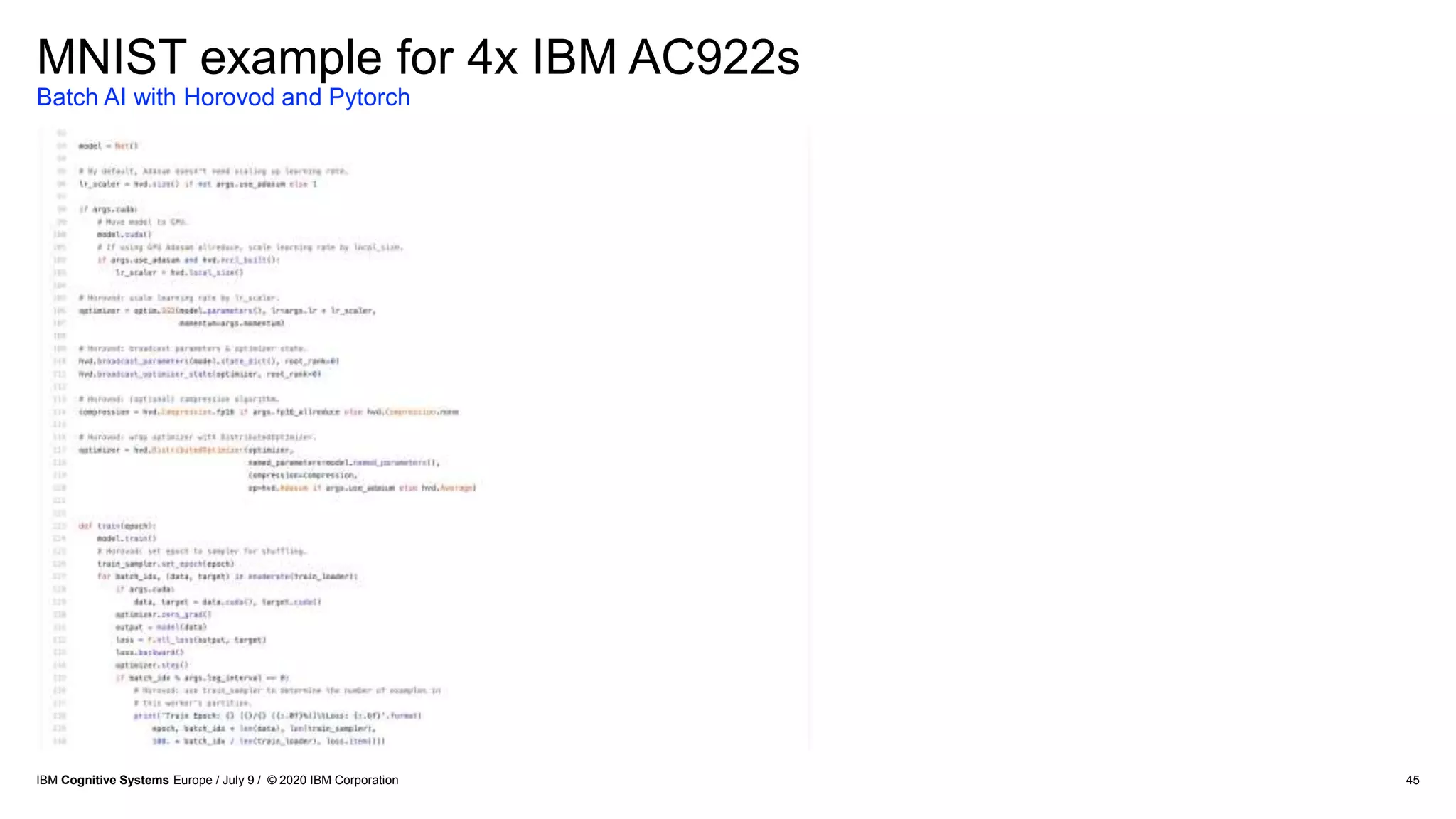
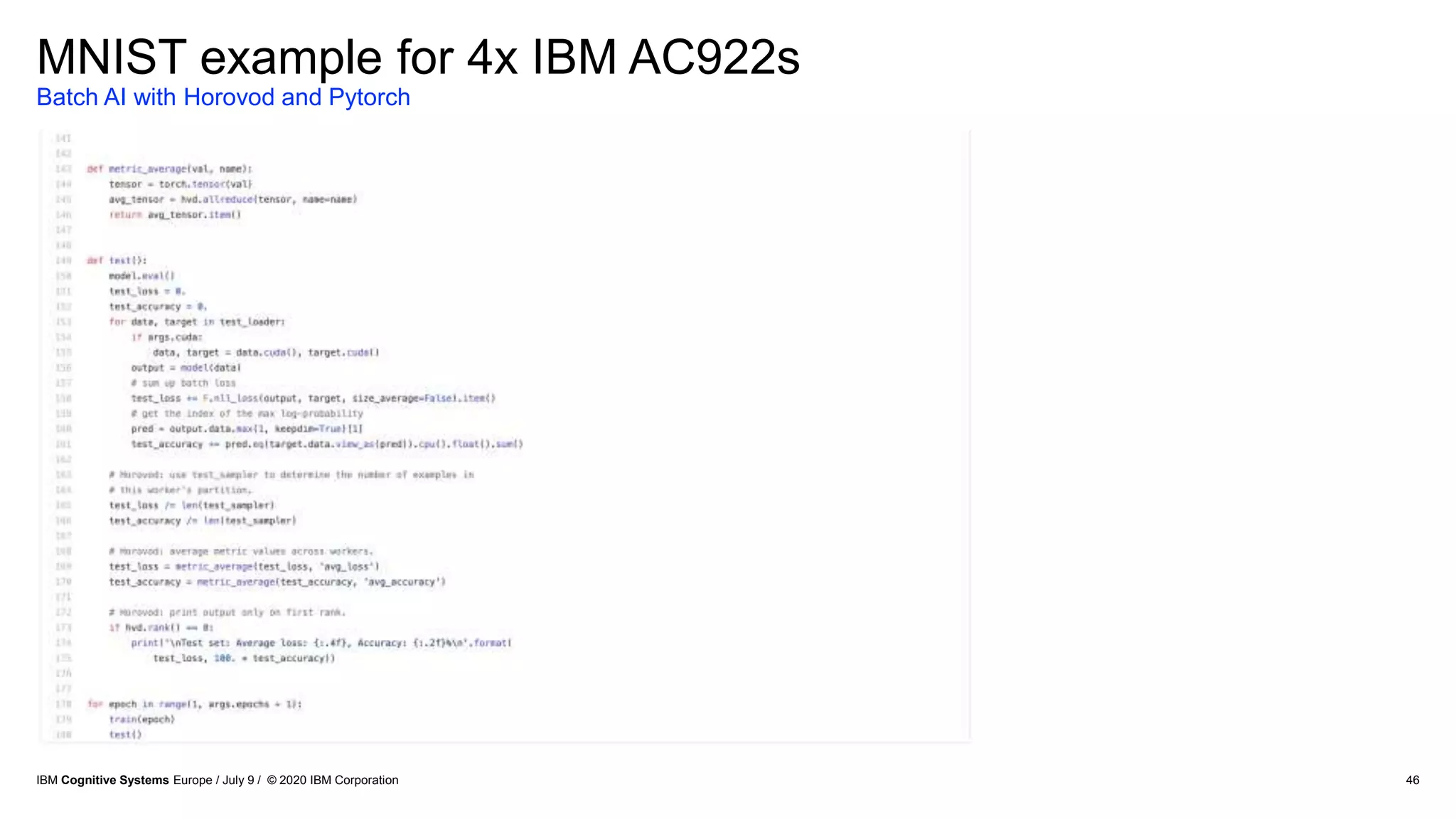
The document discusses advancements in distributed deep learning and cognitive systems, highlighting the challenges posed by increasing dataset sizes and the need for more sophisticated models. It details frameworks, infrastructure, and concepts like multi-GPU utilization and large model support that aim to enhance performance in AI training. It also introduces tools such as IBM DDL and Horovod for optimizing communication in distributed training scenarios.




















![33
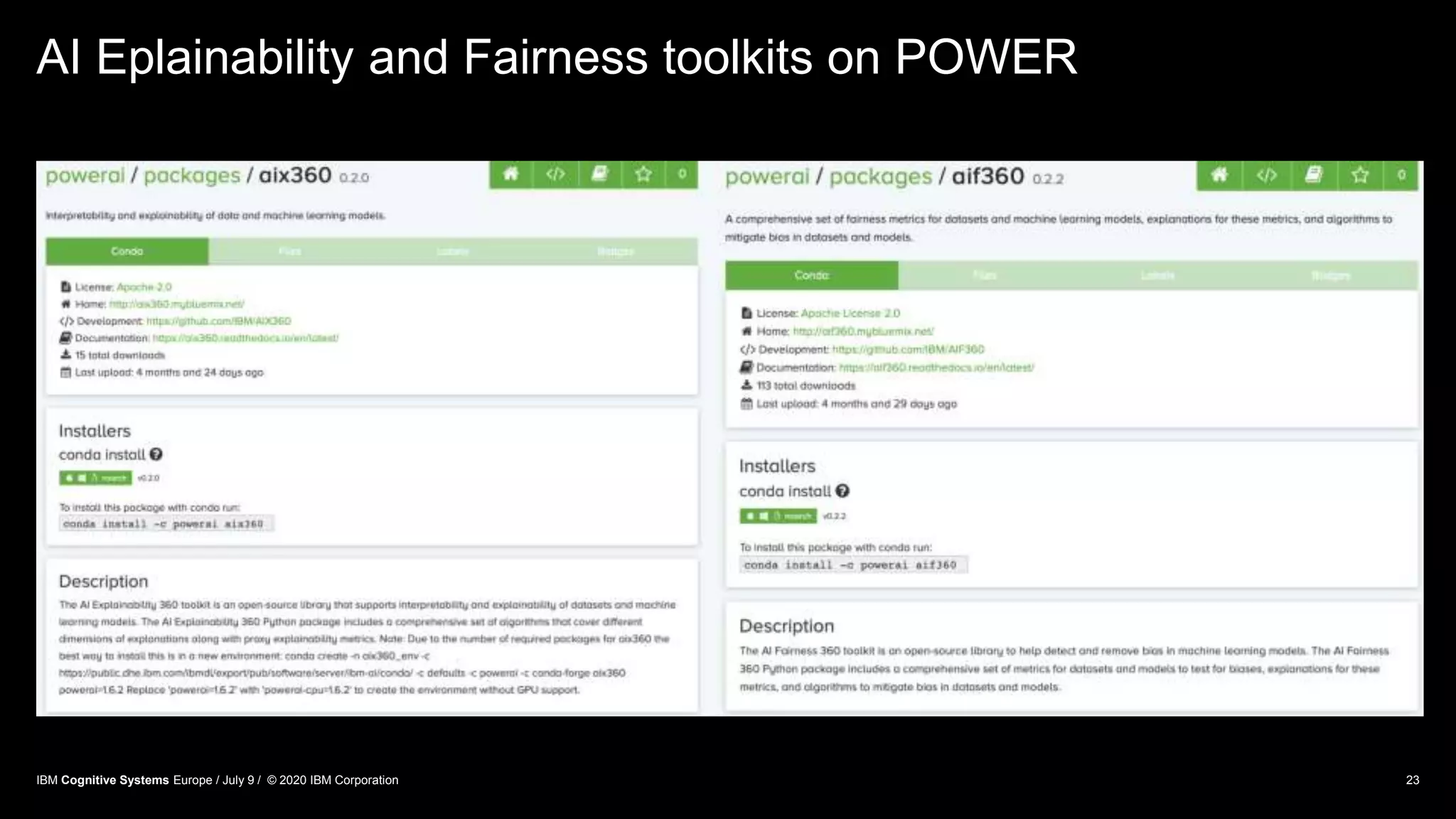
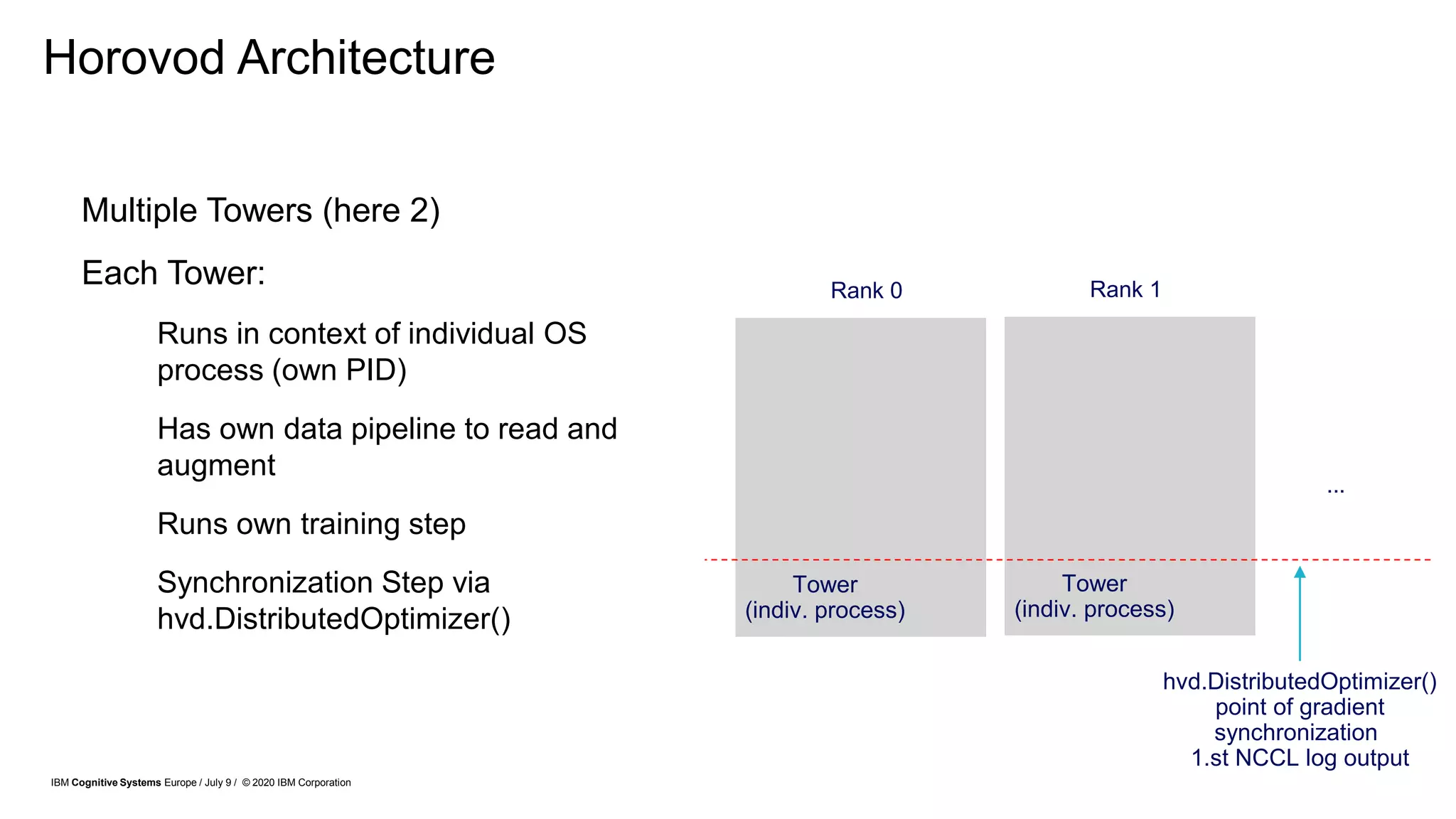
Tools and Libraries
The following tools are libraries, which provide the communication functions necessary to perform distributed
training. Primarily allReduce and broadcast functions.
IBM Spectrum MPI: Classic tool for distributed computing. Still commonly used for distributed deep
learning.
NVIDIA NCCL: Nvidia’s gpu-to-gpu communication library. Since NCCL2, between-node communication
is supported.
IBM DDL: Provides a topology-aware all-Reduce. Capable of optimally dividing communication across
hierarchies of fabrics. Utilizes different communication protocols at different hierarchies. When WMLCE is
installed all related frameworks are comming with IBM DDL support, you don’t have to compile additional
software packages, only to modify your training scripts to make use of the need distributed deep learning
APIs.Integrations into deep learning frameworks to enable distributed training is using common communication
libraries such as:
TensorFlow Distribution Strategies. Native Tensorflow distribution methods.
IBM DDL. Provides integrations into common frameworks, including a Tensorflow operator that integrates
IBM DDL with Tensorflow and similar for Pytorch.
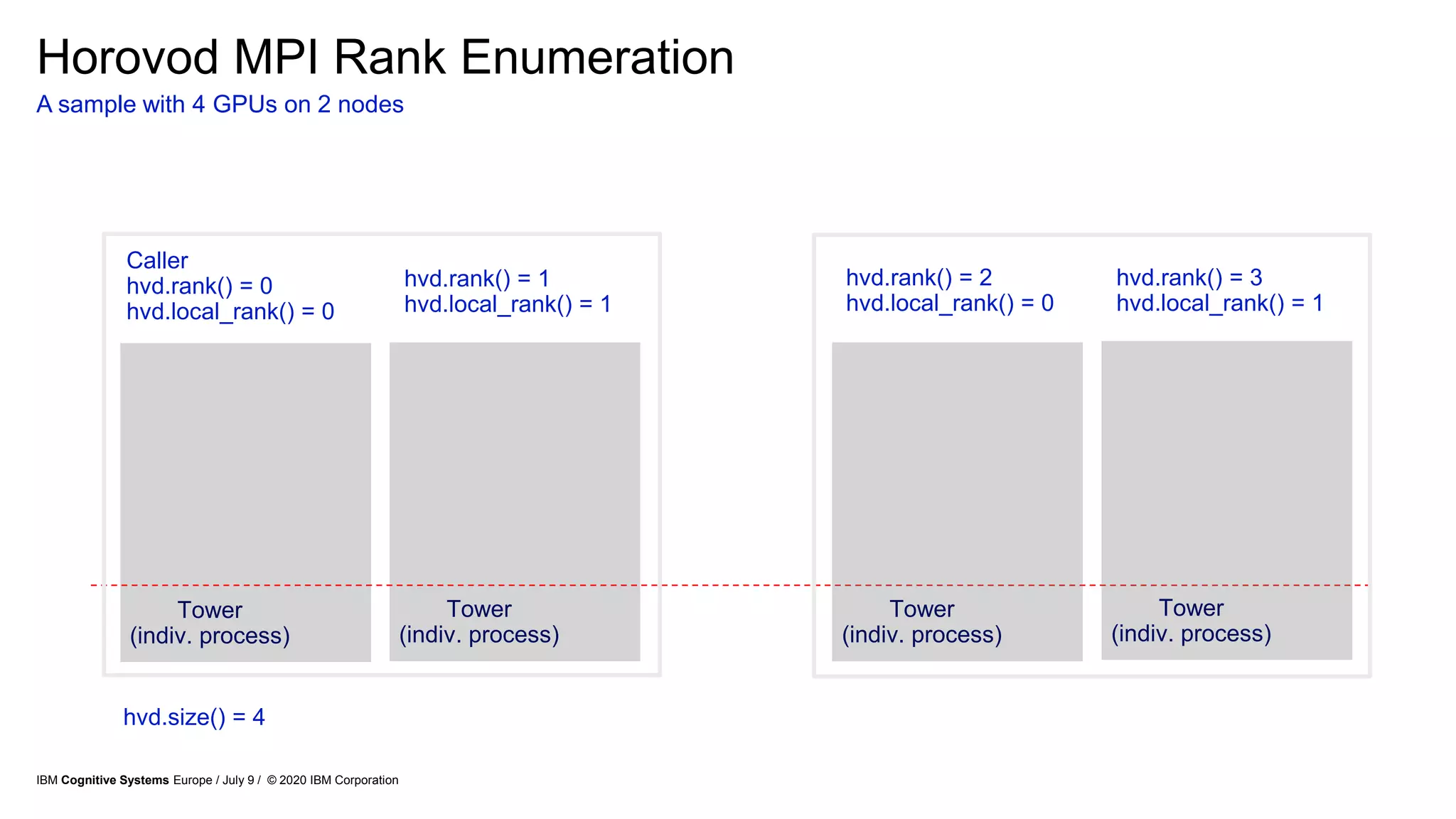
Horovod [Sergeev et al. 2018]. Provides integration libraries into common frameworks which enable
distributed training with common communication libraries, including. IBM DDL or NCCL can be used as
backend for Horovod implementation.
IBM Cognitive Systems Europe / July 9 / © 2020 IBM Corporation](https://image.slidesharecdn.com/aiatscalev1-200716012036/75/IBM-AI-at-Scale-33-2048.jpg)

![Horovod with DDL
Running
35
$ ddlrun -H host1,host2,host3,host4 -mpiarg "-x HOROVOD_FUSION_THRESHOLD=16777216" python
hpms/tf_cnn_benchmarks/tf_cnn_benchmarks.py --model resnet50 --batch_size 64 --
variable_update=horovod
I 20:42:52.209 12173 12173 DDL:29 ] [MPI:0 ] ==== IBM Corp. DDL 1.1.0 + (MPI 3.1) ====
...
----------------------------------------------------------------
total images/sec: 5682.34
----------------------------------------------------------------
IBM Cognitive Systems Europe / July 9 / © 2020 IBM Corporation](https://image.slidesharecdn.com/aiatscalev1-200716012036/75/IBM-AI-at-Scale-35-2048.jpg)







































![33
Tools and Libraries
The following tools are libraries, which provide the communication functions necessary to perform distributed
training. Primarily allReduce and broadcast functions.
IBM Spectrum MPI: Classic tool for distributed computing. Still commonly used for distributed deep
learning.
NVIDIA NCCL: Nvidia’s gpu-to-gpu communication library. Since NCCL2, between-node communication
is supported.
IBM DDL: Provides a topology-aware all-Reduce. Capable of optimally dividing communication across
hierarchies of fabrics. Utilizes different communication protocols at different hierarchies. When WMLCE is
installed all related frameworks are comming with IBM DDL support, you don’t have to compile additional
software packages, only to modify your training scripts to make use of the need distributed deep learning
APIs.Integrations into deep learning frameworks to enable distributed training is using common communication
libraries such as:
TensorFlow Distribution Strategies. Native Tensorflow distribution methods.
IBM DDL. Provides integrations into common frameworks, including a Tensorflow operator that integrates
IBM DDL with Tensorflow and similar for Pytorch.
Horovod [Sergeev et al. 2018]. Provides integration libraries into common frameworks which enable
distributed training with common communication libraries, including. IBM DDL or NCCL can be used as
backend for Horovod implementation.
IBM Cognitive Systems Europe / July 9 / © 2020 IBM Corporation](https://crownmelresort.com/image.slidesharecdn.com/aiatscalev1-200716012036/75/IBM-AI-at-Scale-33-2048.jpg)

![Horovod with DDL
Running
35
$ ddlrun -H host1,host2,host3,host4 -mpiarg "-x HOROVOD_FUSION_THRESHOLD=16777216" python
hpms/tf_cnn_benchmarks/tf_cnn_benchmarks.py --model resnet50 --batch_size 64 --
variable_update=horovod
I 20:42:52.209 12173 12173 DDL:29 ] [MPI:0 ] ==== IBM Corp. DDL 1.1.0 + (MPI 3.1) ====
...
----------------------------------------------------------------
total images/sec: 5682.34
----------------------------------------------------------------
IBM Cognitive Systems Europe / July 9 / © 2020 IBM Corporation](https://crownmelresort.com/image.slidesharecdn.com/aiatscalev1-200716012036/75/IBM-AI-at-Scale-35-2048.jpg)


































































































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)


