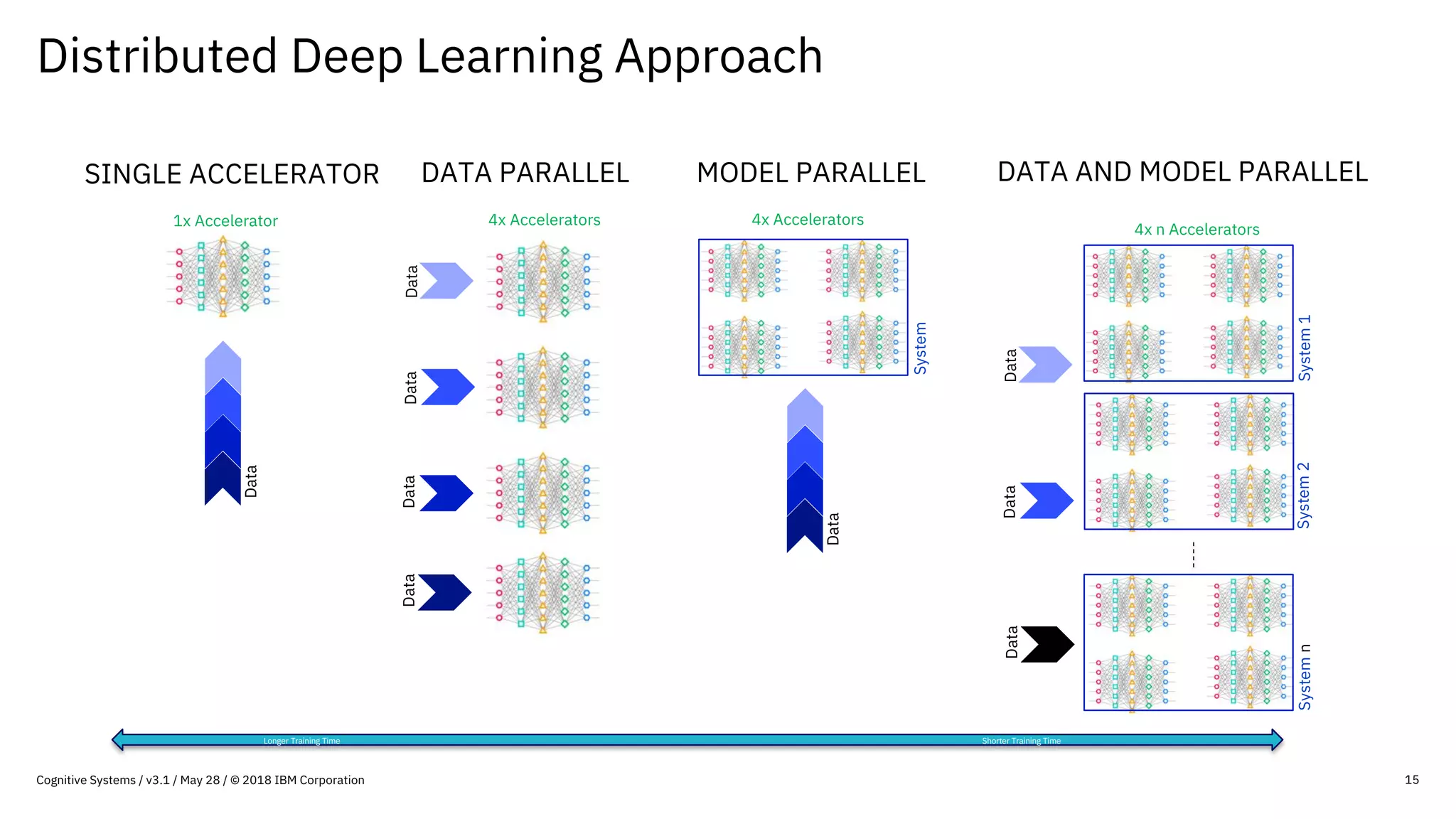
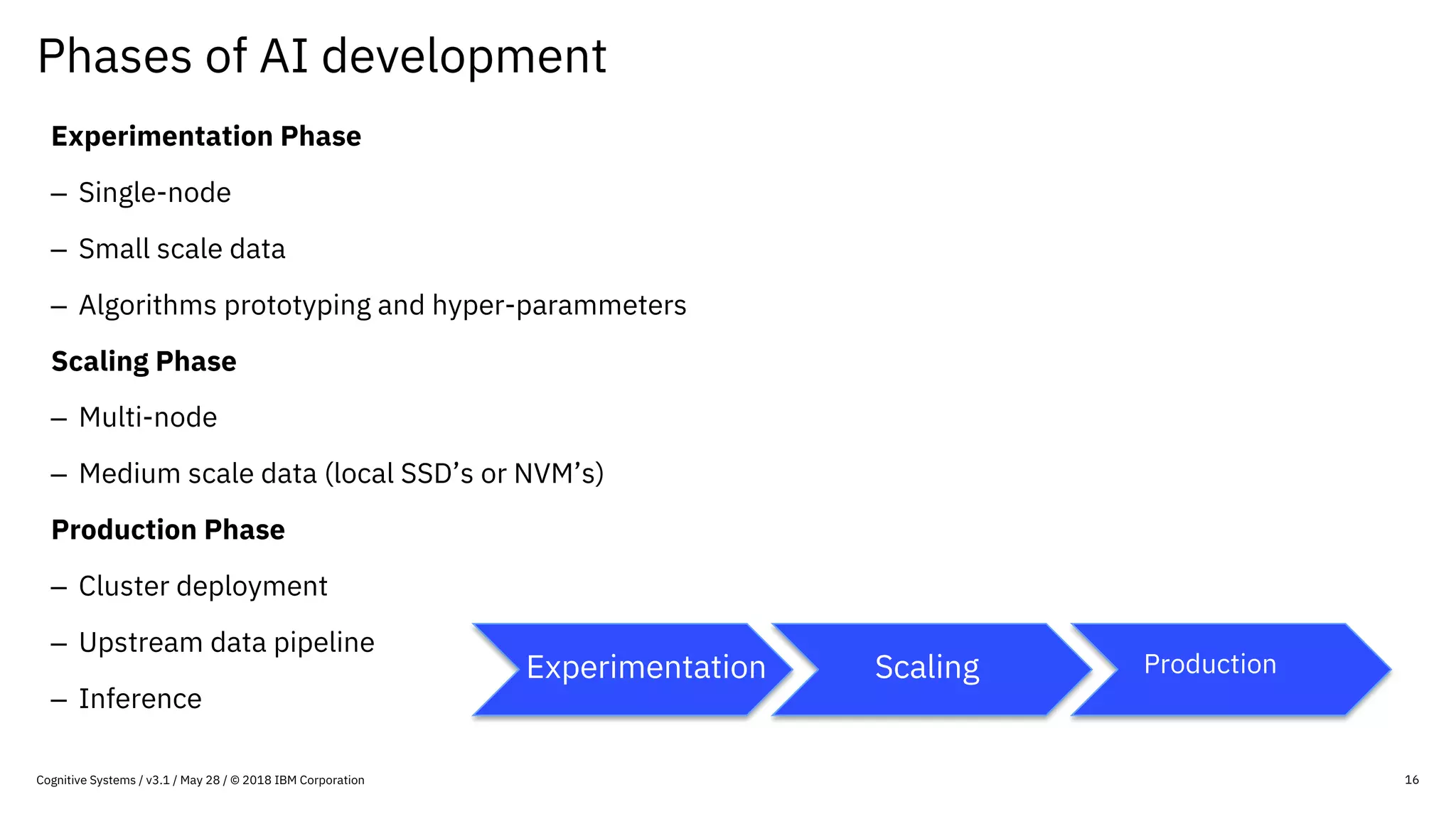
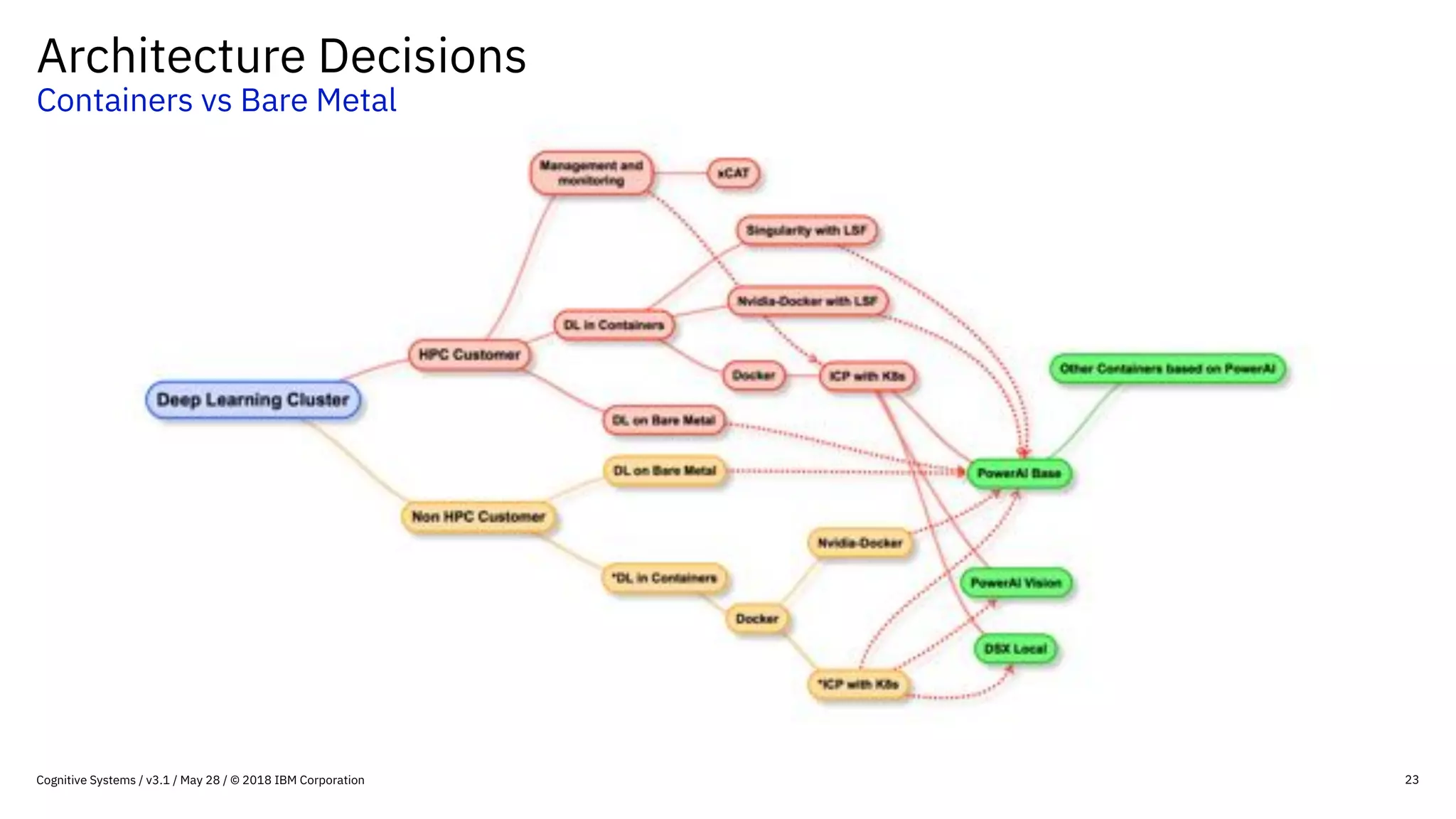
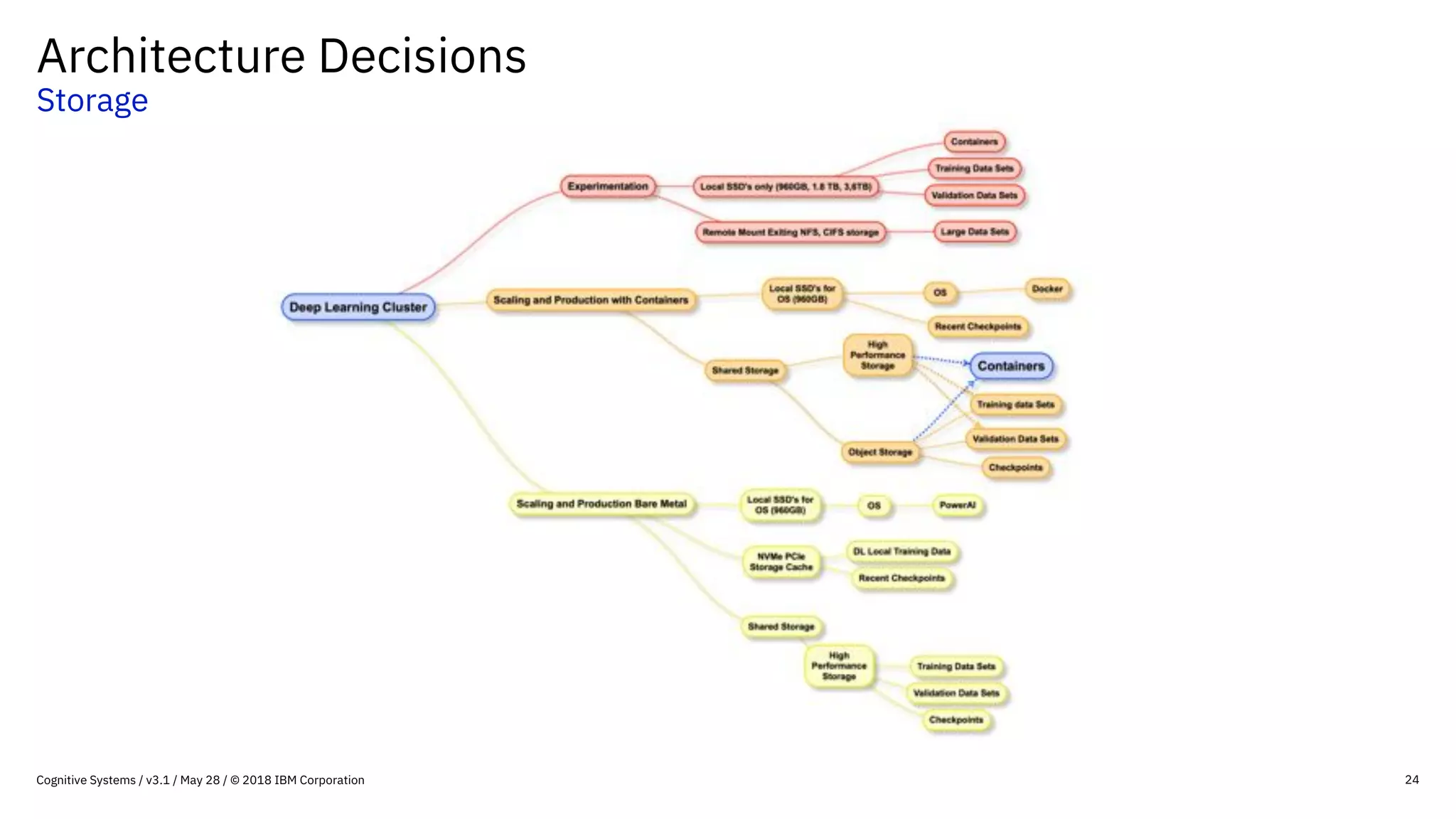
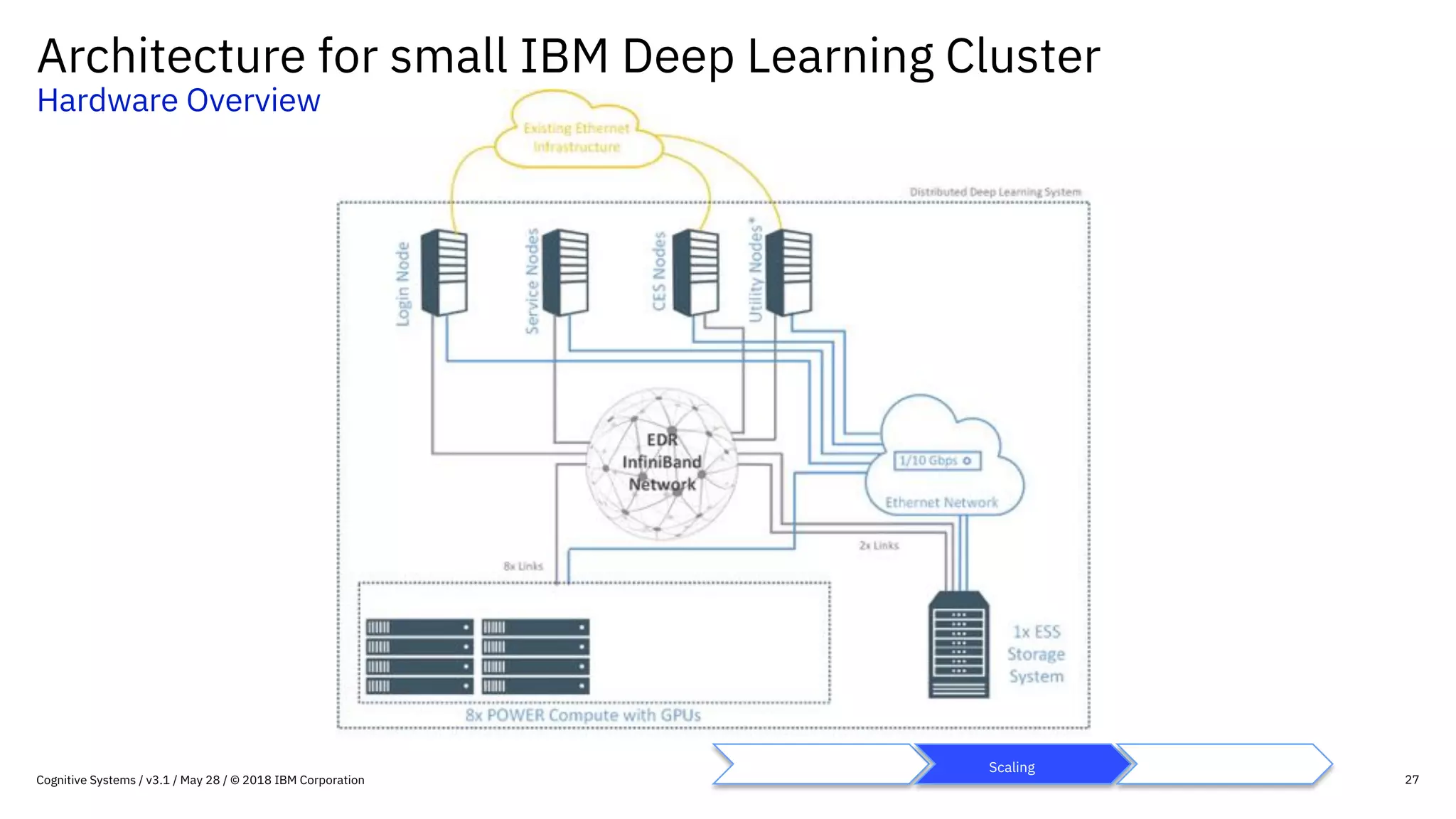
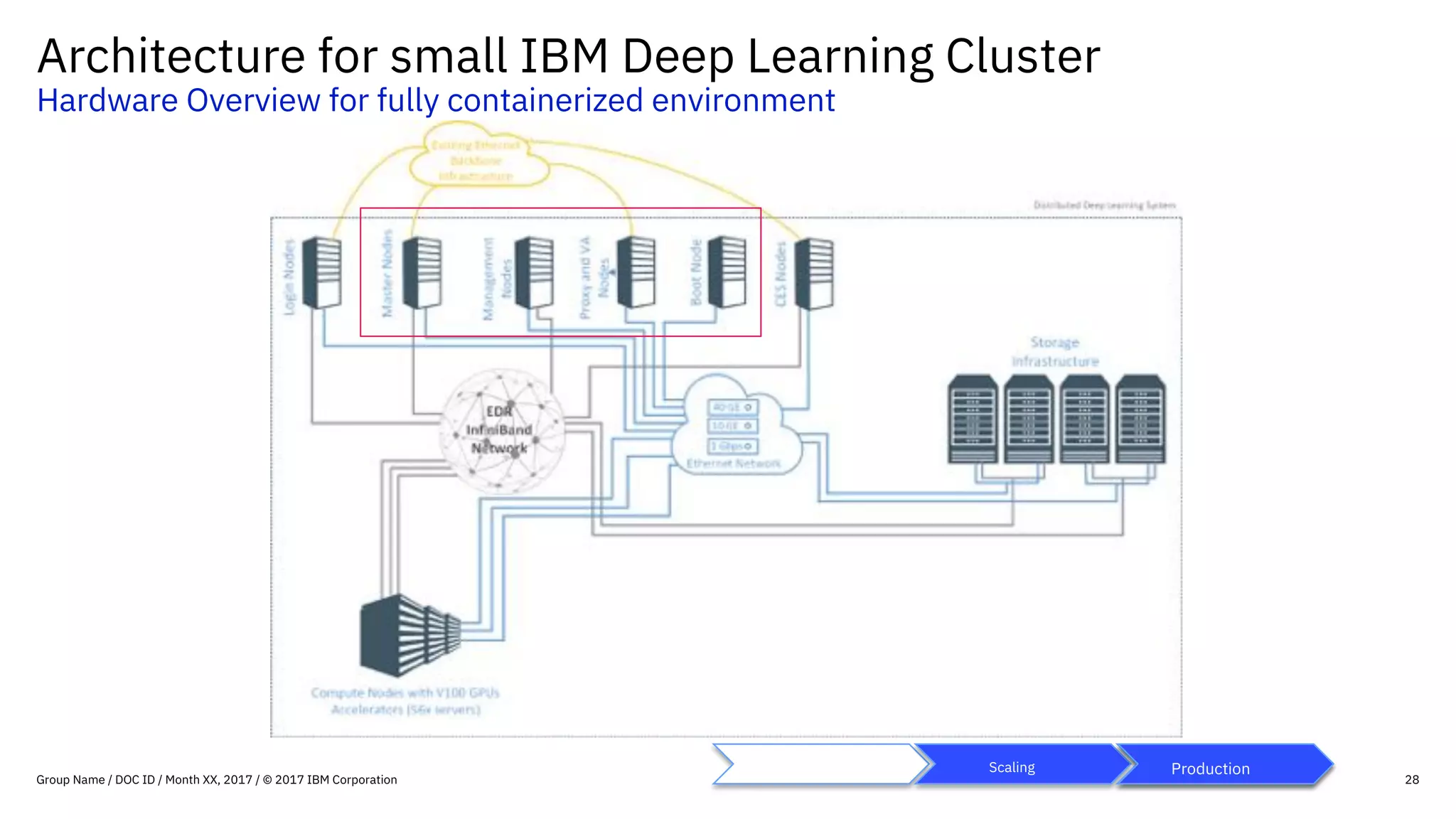
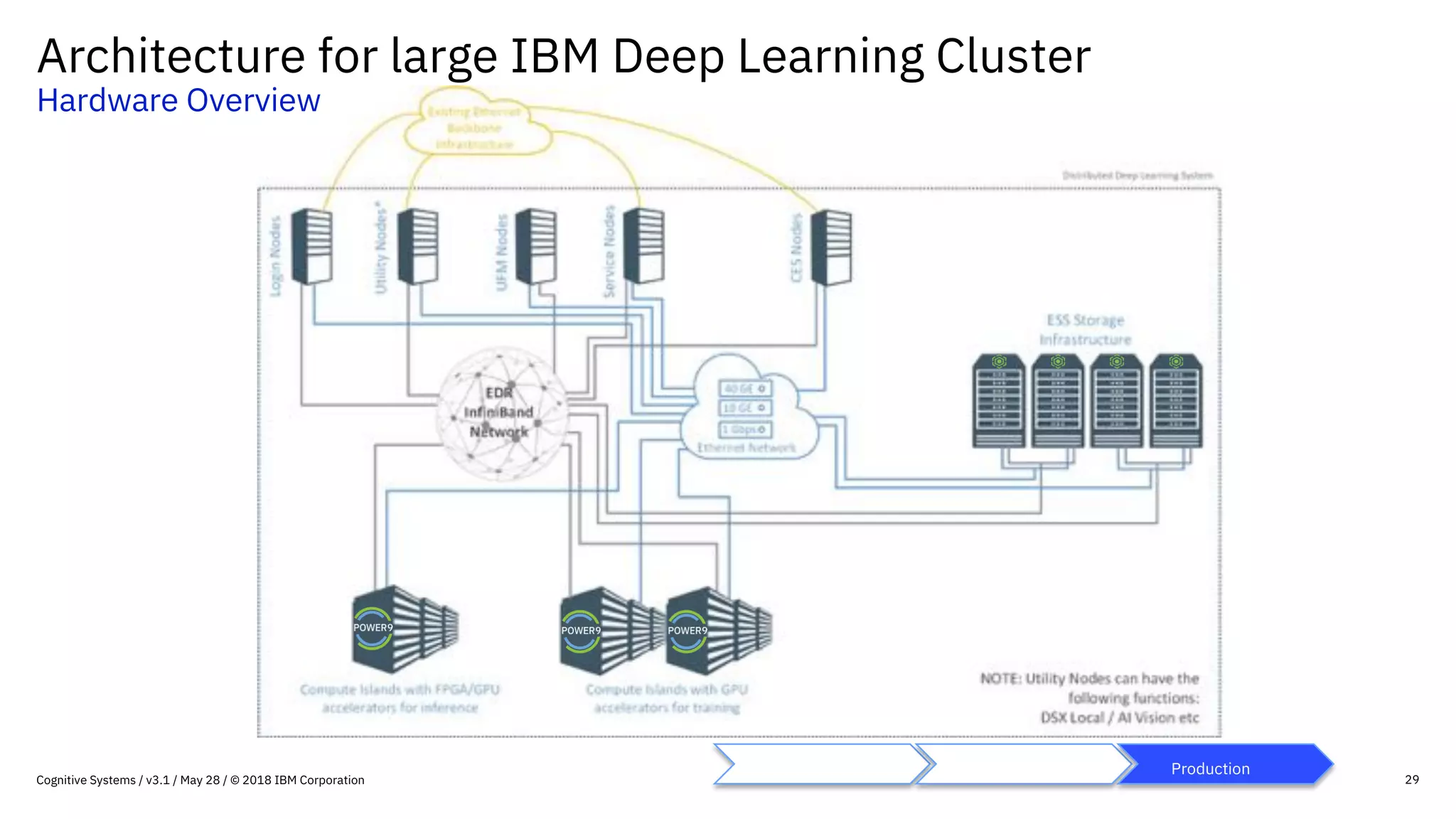
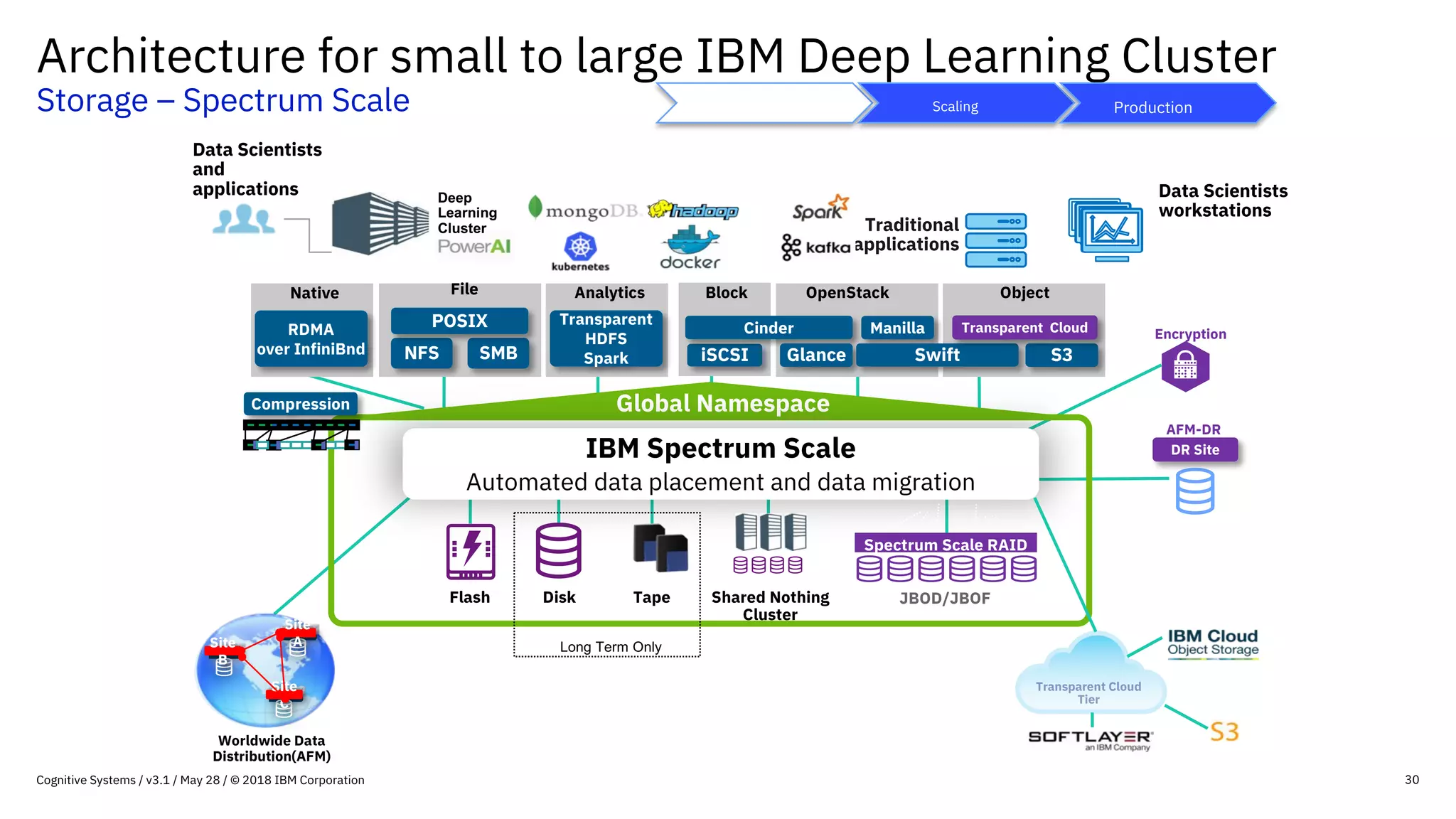
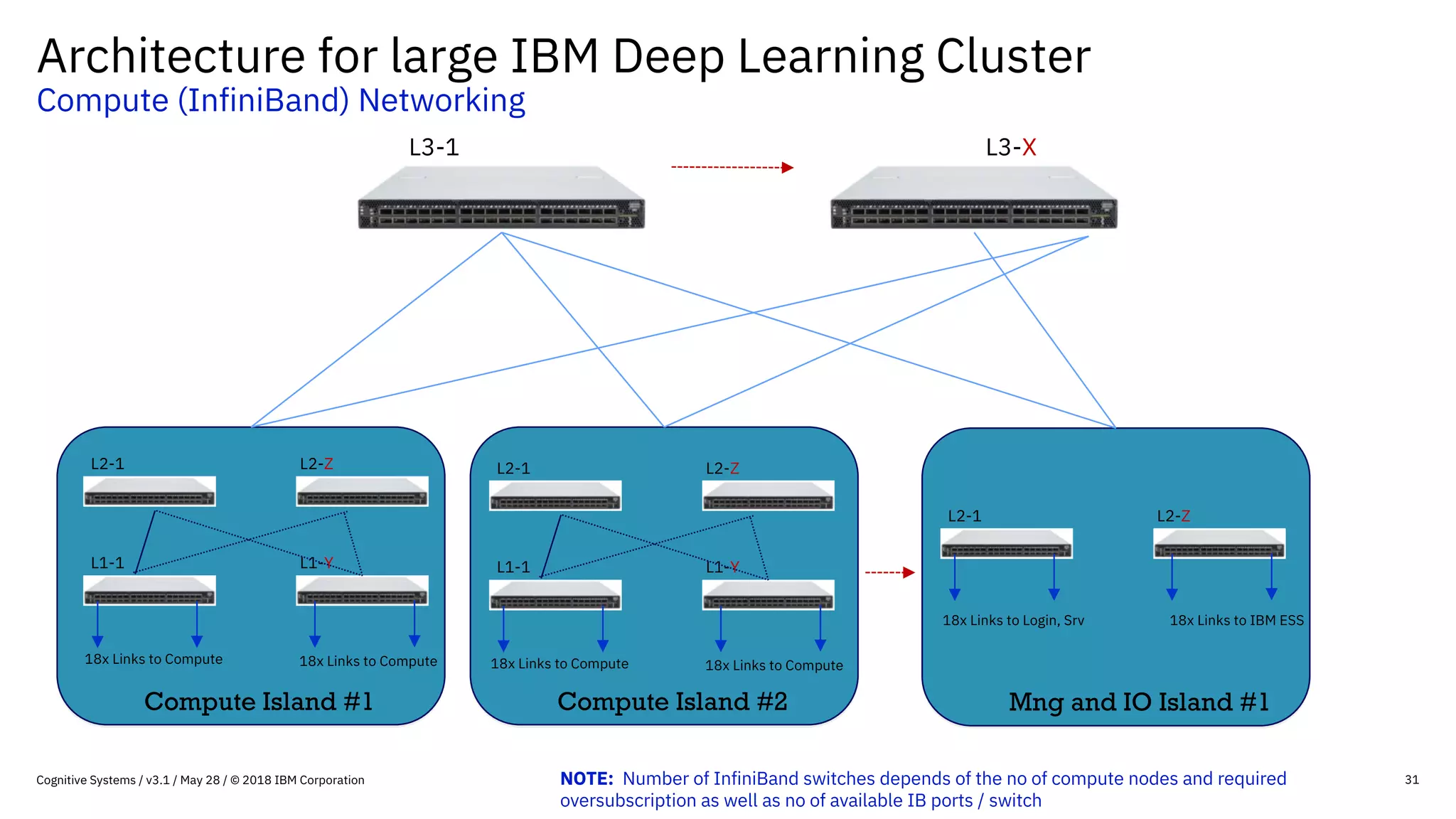
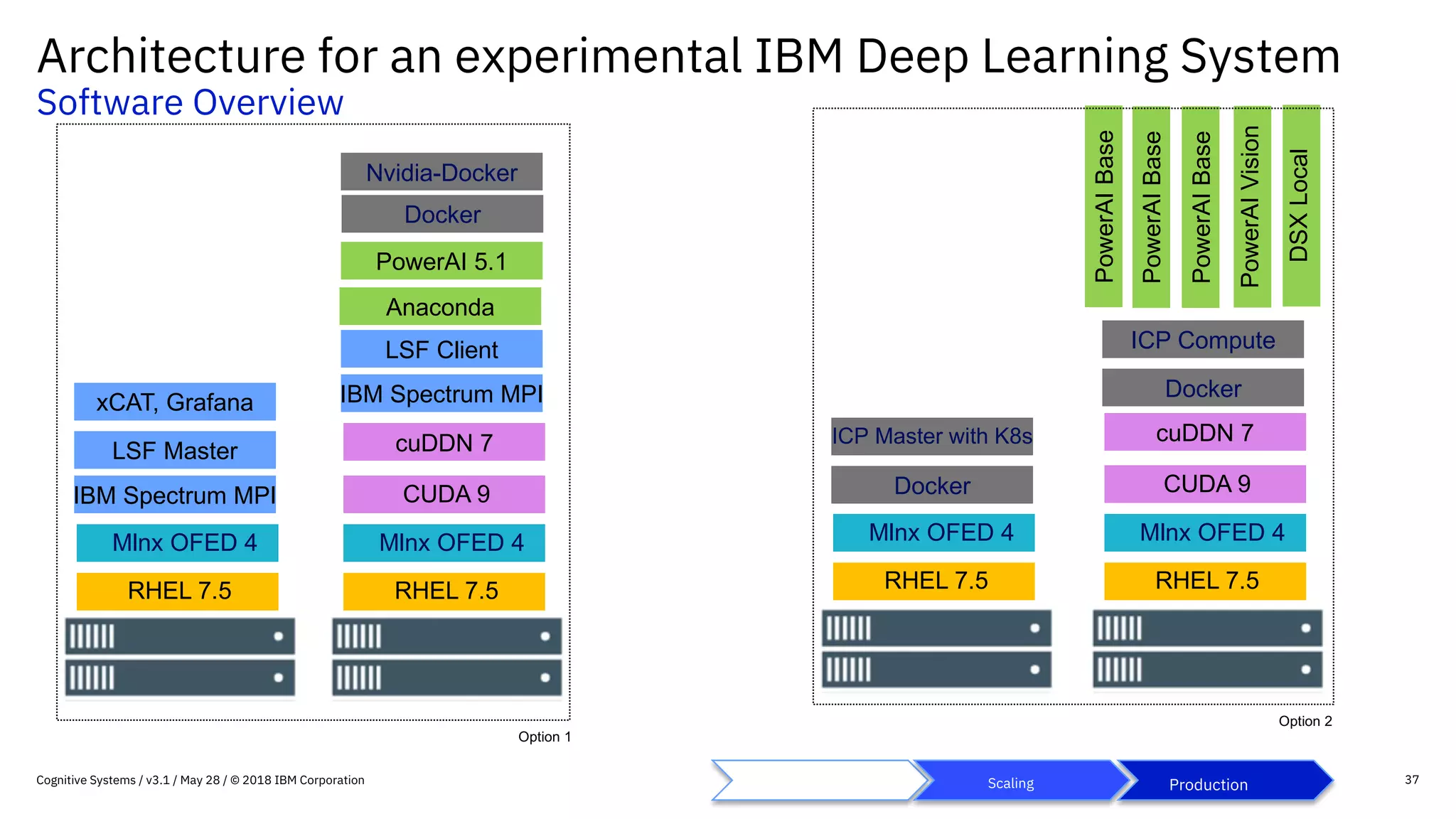
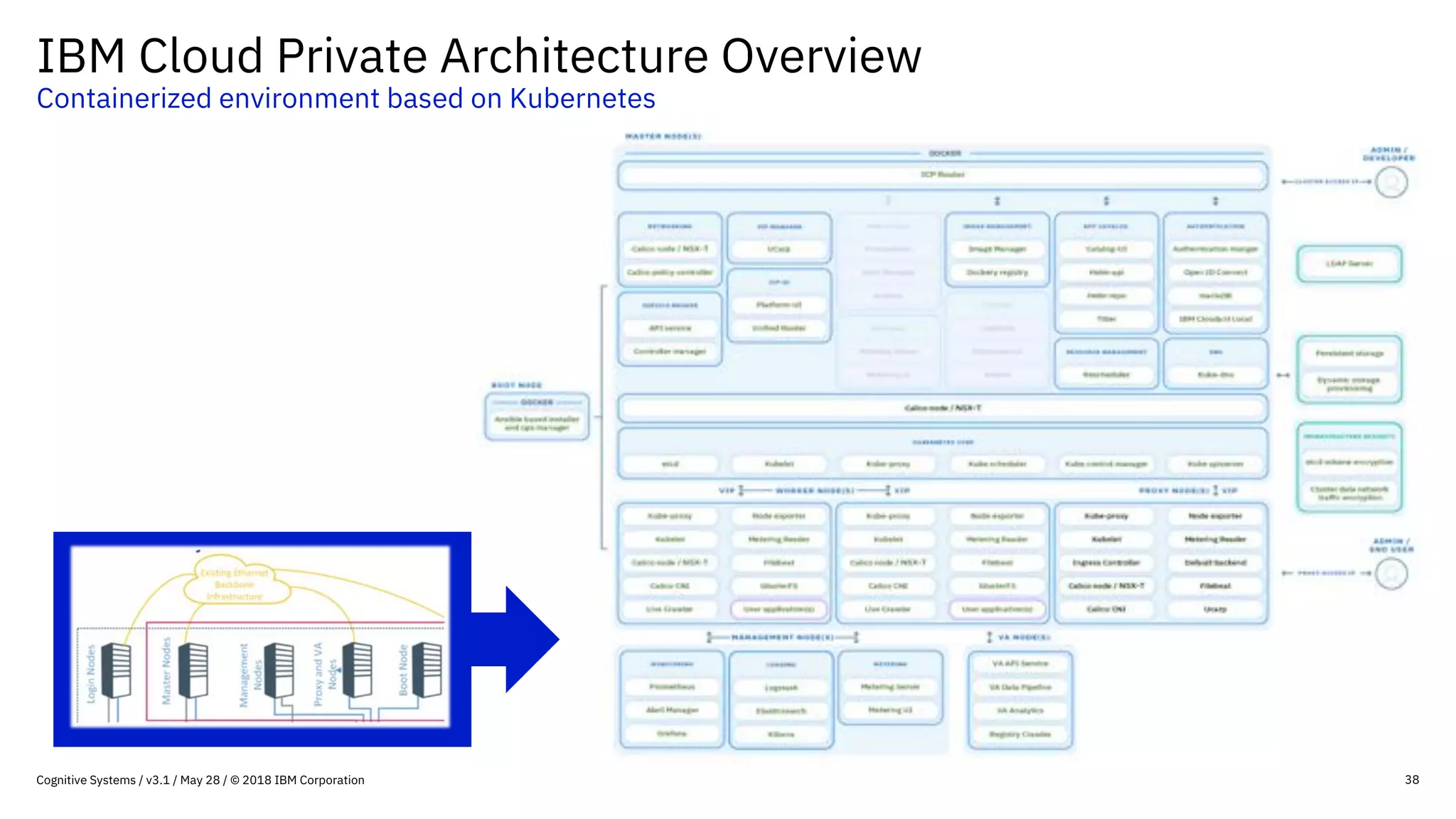
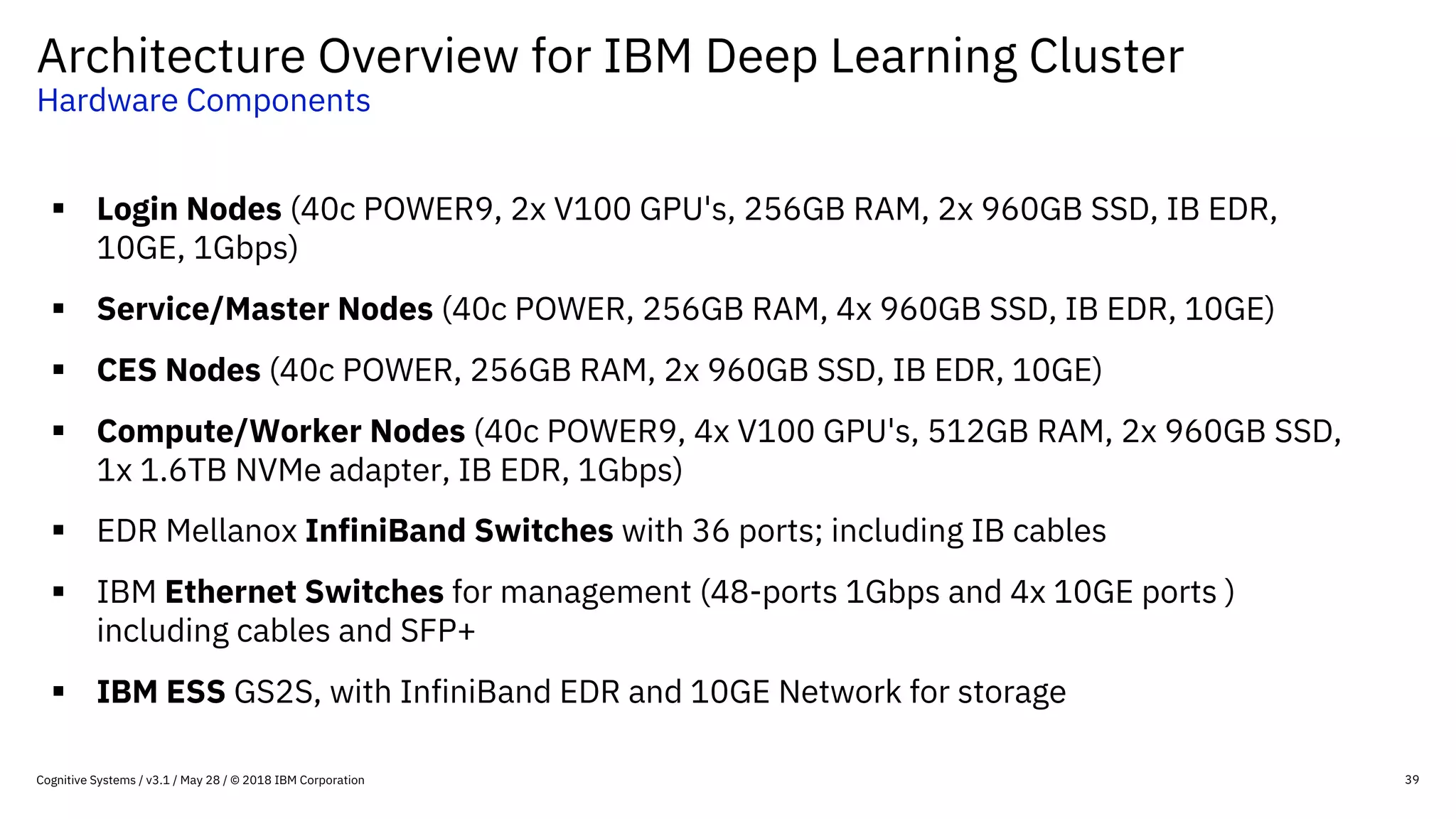
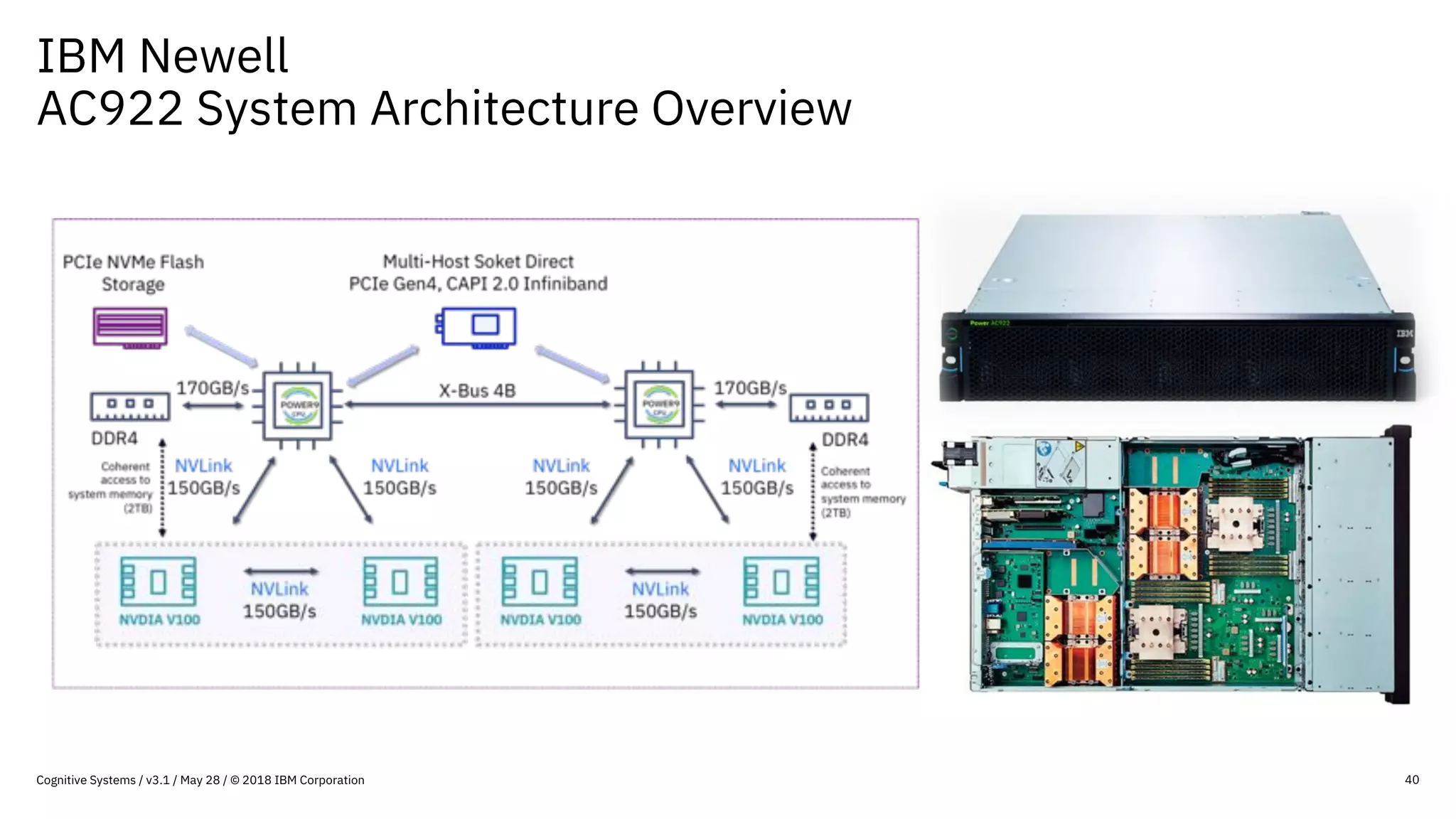
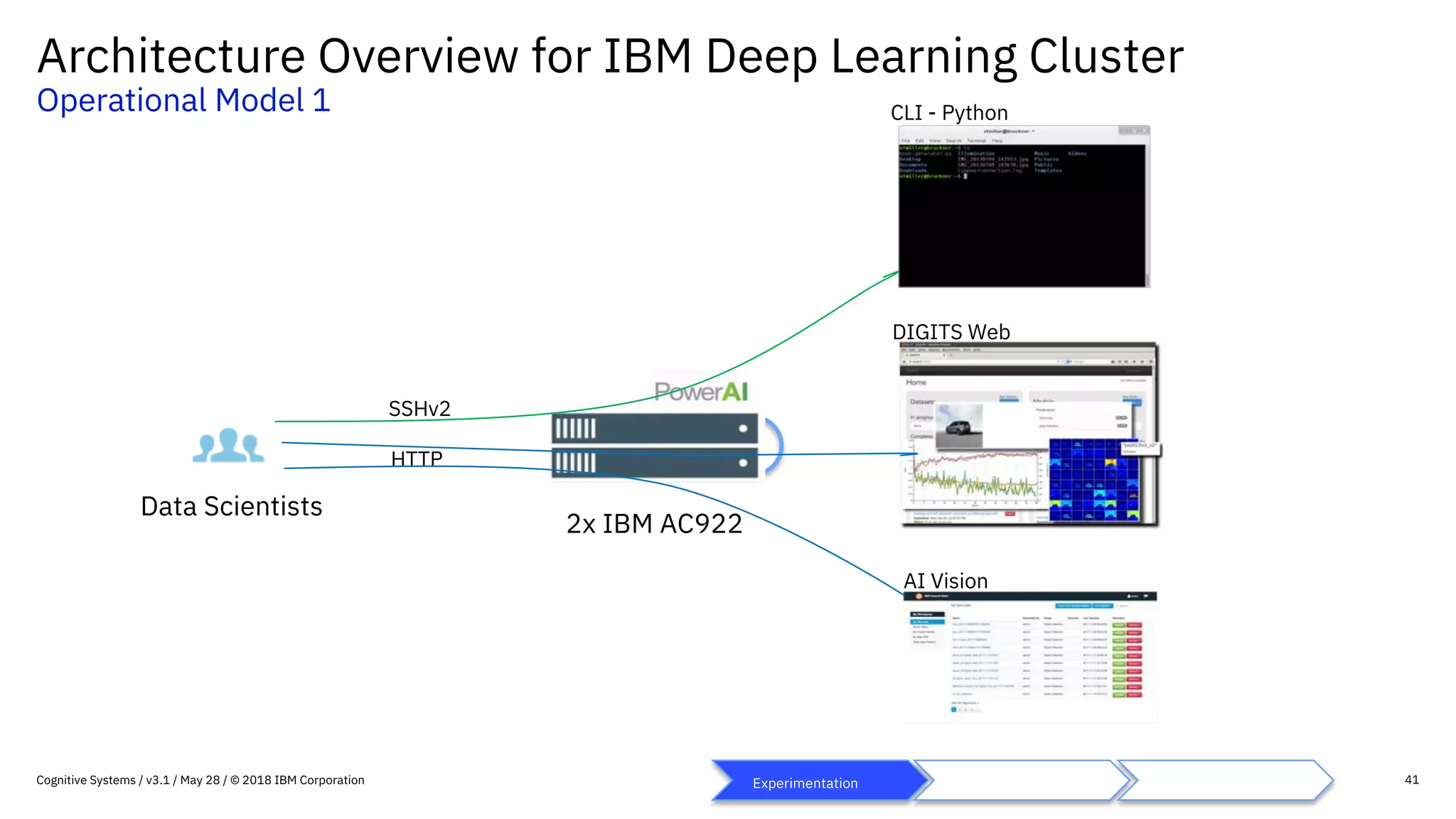
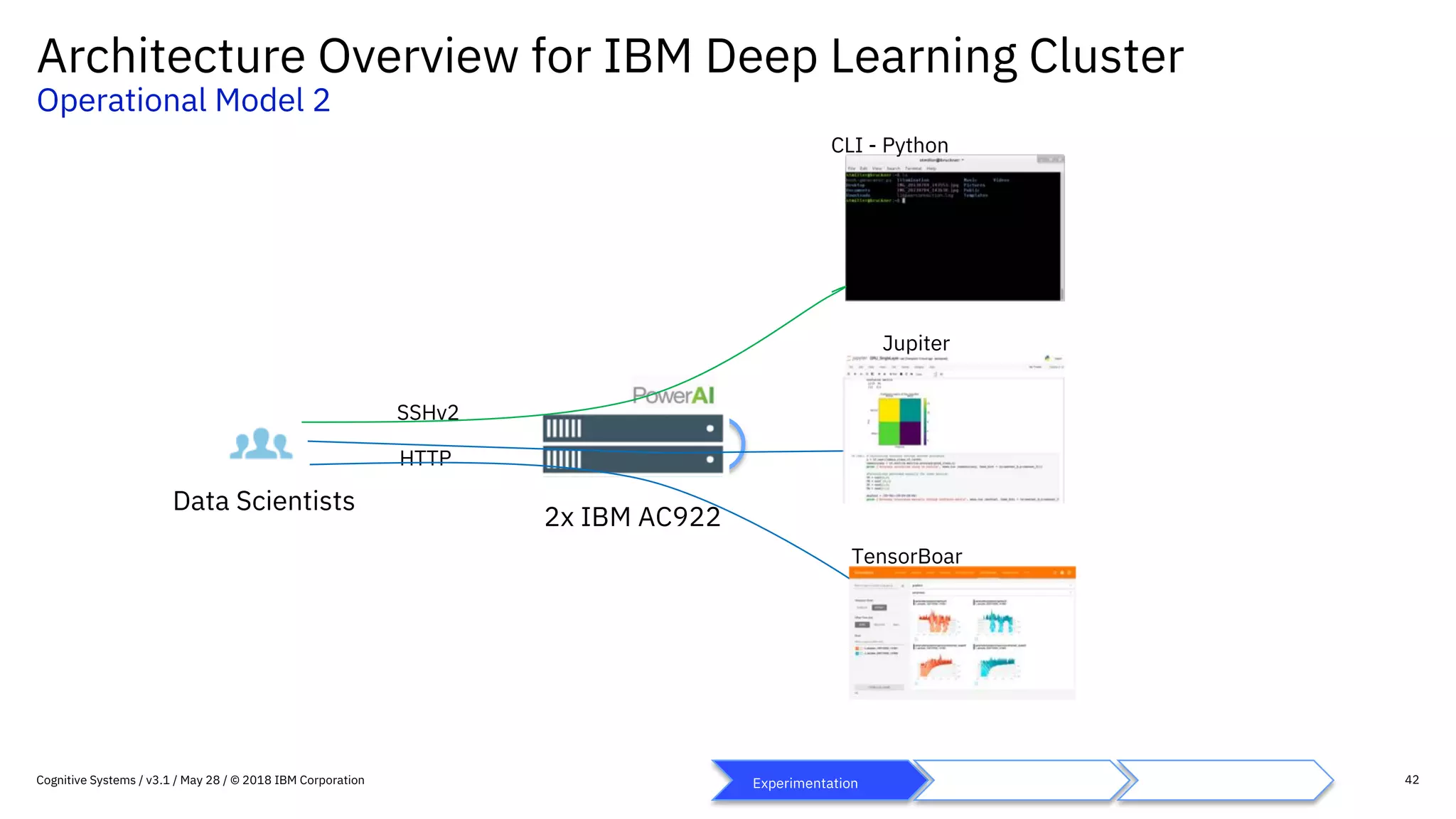
This document provides an overview of IBM's reference architecture for deep learning clusters. It discusses the hardware and software components, including POWER-based servers with NVIDIA GPUs connected by Mellanox InfiniBand switches. It describes the storage architecture using IBM Spectrum Scale for a shared filesystem. The software stack is based on Red Hat Enterprise Linux, CUDA, Nvidia-Docker, IBM PowerAI, and container orchestration with either Kubernetes or IBM Spectrum LSF. Operational models and workflows are shown to support experimentation, scaling, and production phases of deep learning.
















![LSF Docker Support
44
Starting with LSF 10.1.0.3 we provide support for nVidia’s distribution of Docker which allows
LSF’s CPU, cgroup and GPU allocation functionality to work correctly.
Begin Application
NAME = nvdia-docker
CONTAINER = nvidia-docker [ image(nvidia/cuda) options(--rm --net=host --ipc=host --sig-
proxy=false) starter(lsfadmin)]
End Application
$bsub -app nvdia-docker –gpu “num=1” ./ibm-powerai
Cognitive Systems / v3.1 / May 28 / © 2018 IBM Corporation](https://image.slidesharecdn.com/orais18-distributeddeeplearningreferencearchitecturev3-180530102335/75/Distributed-deep-learning-reference-architecture-v3-2l-43-2048.jpg)














































![LSF Docker Support
44
Starting with LSF 10.1.0.3 we provide support for nVidia’s distribution of Docker which allows
LSF’s CPU, cgroup and GPU allocation functionality to work correctly.
Begin Application
NAME = nvdia-docker
CONTAINER = nvidia-docker [ image(nvidia/cuda) options(--rm --net=host --ipc=host --sig-
proxy=false) starter(lsfadmin)]
End Application
$bsub -app nvdia-docker –gpu “num=1” ./ibm-powerai
Cognitive Systems / v3.1 / May 28 / © 2018 IBM Corporation](https://crownmelresort.com/image.slidesharecdn.com/orais18-distributeddeeplearningreferencearchitecturev3-180530102335/75/Distributed-deep-learning-reference-architecture-v3-2l-43-2048.jpg)





































![[DSC Europe 24] Thomas Kitzler - Building the Future – Unpacking the Essentia...](https://cdn.slidesharecdn.com/ss_thumbnails/thomaskitzler-241220214738-670777be-thumbnail.jpg?width=640&height=640&fit=bounds)





















































