Downloaded 132 times


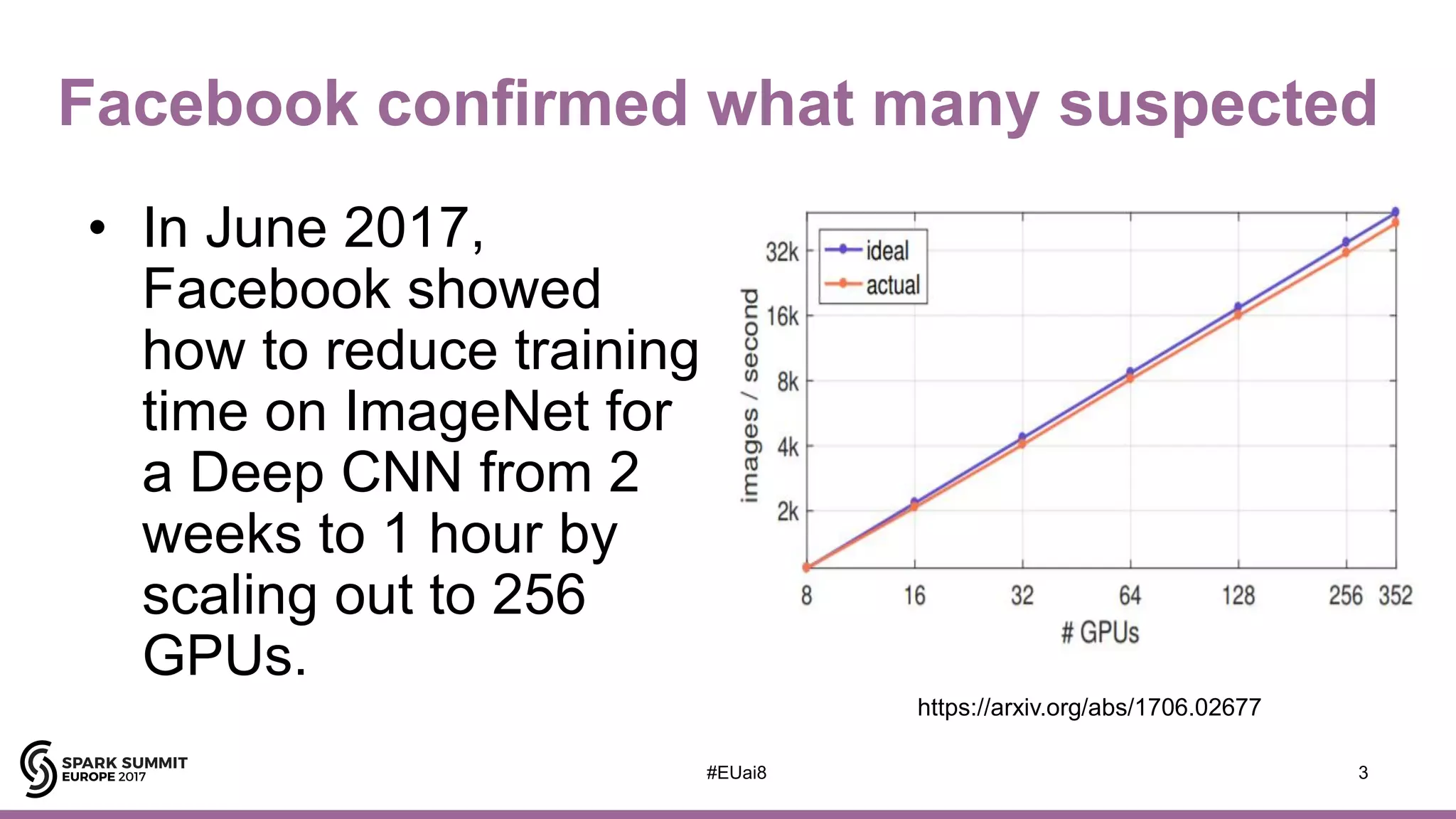
![AI Hierarchy of Needs
5
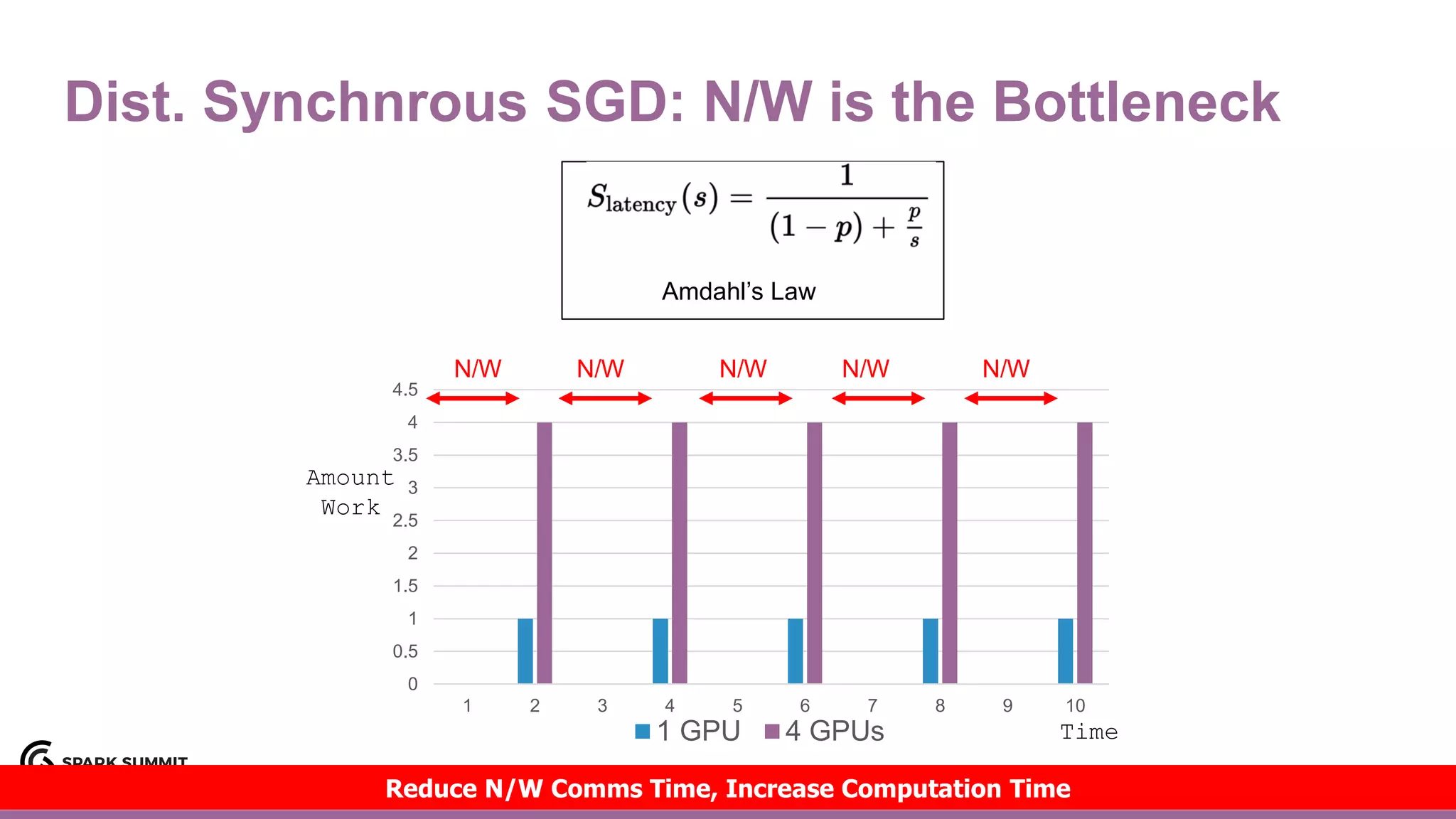
DDL
(Distributed
Deep Learning)
Deep Learning,
RL, Automated ML
A/B Testing, Experimentation, ML
B.I. Analytics, Metrics, Aggregates,
Features, Training/Test Data
Reliable Data Pipelines, ETL, Unstructured and
Structured Data Storage, Real-Time Data Ingestion
[Adapted from https://hackernoon.com/the-ai-hierarchy-of-needs-18f111fcc007?gi=7e13a696e469 ]](https://image.slidesharecdn.com/lb8jimdowling-171102164935/75/Apache-Spark-and-Tensorflow-as-a-Service-with-Jim-Dowling-4-2048.jpg)
![AI Hierarchy of Needs
6
DDL
(Distributed
Deep Learning)
Deep Learning,
RL, Automated ML
A/B Testing, Experimentation, ML
B.I. Analytics, Metrics, Aggregates,
Features, Training/Test Data
Reliable Data Pipelines, ETL, Unstructured and
Structured Data Storage, Real-Time Data Ingestion
[Adapted from https://hackernoon.com/the-ai-hierarchy-of-needs-18f111fcc007?gi=7e13a696e469 ]
Analytics
Prediction](https://image.slidesharecdn.com/lb8jimdowling-171102164935/75/Apache-Spark-and-Tensorflow-as-a-Service-with-Jim-Dowling-5-2048.jpg)
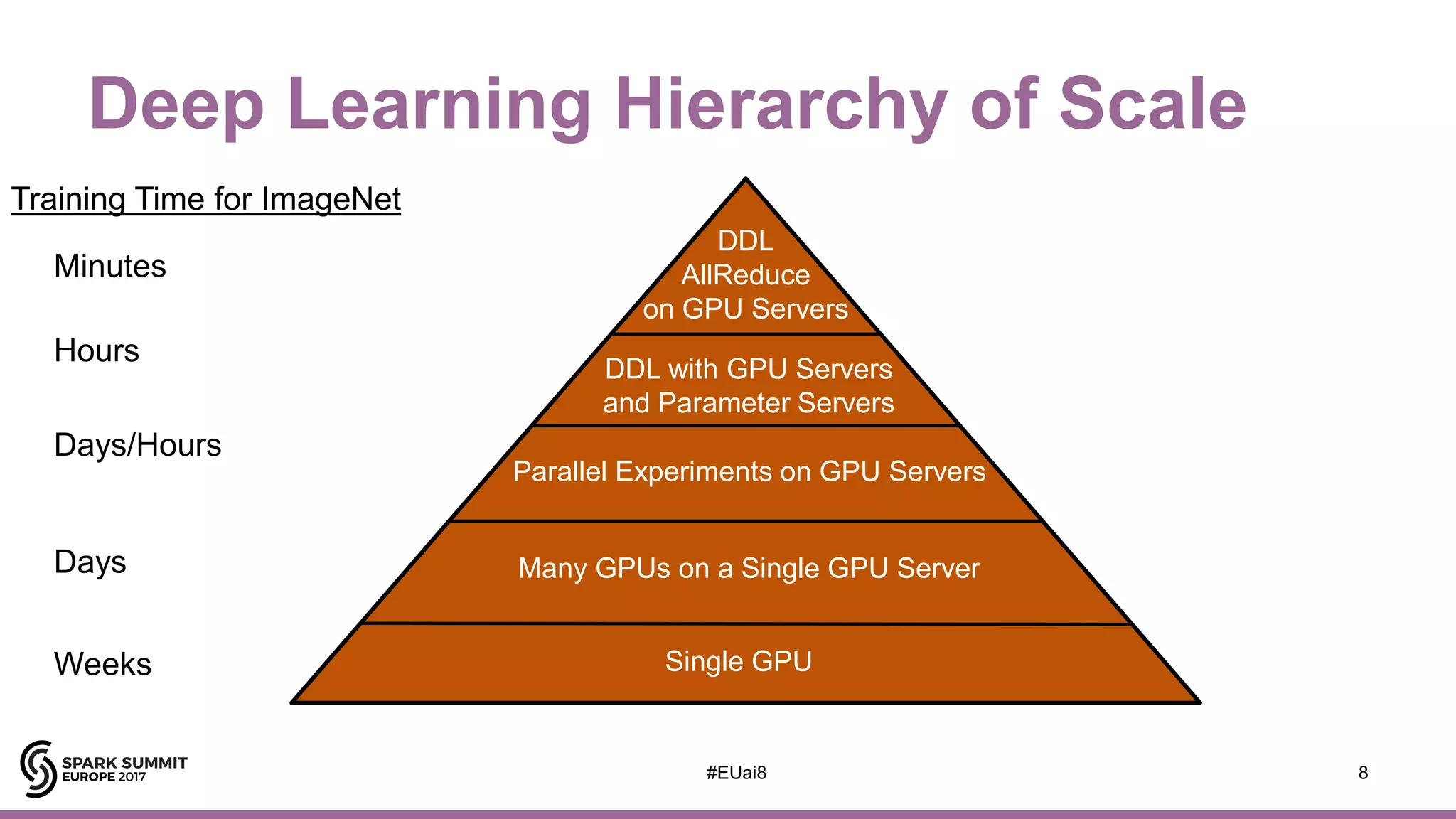
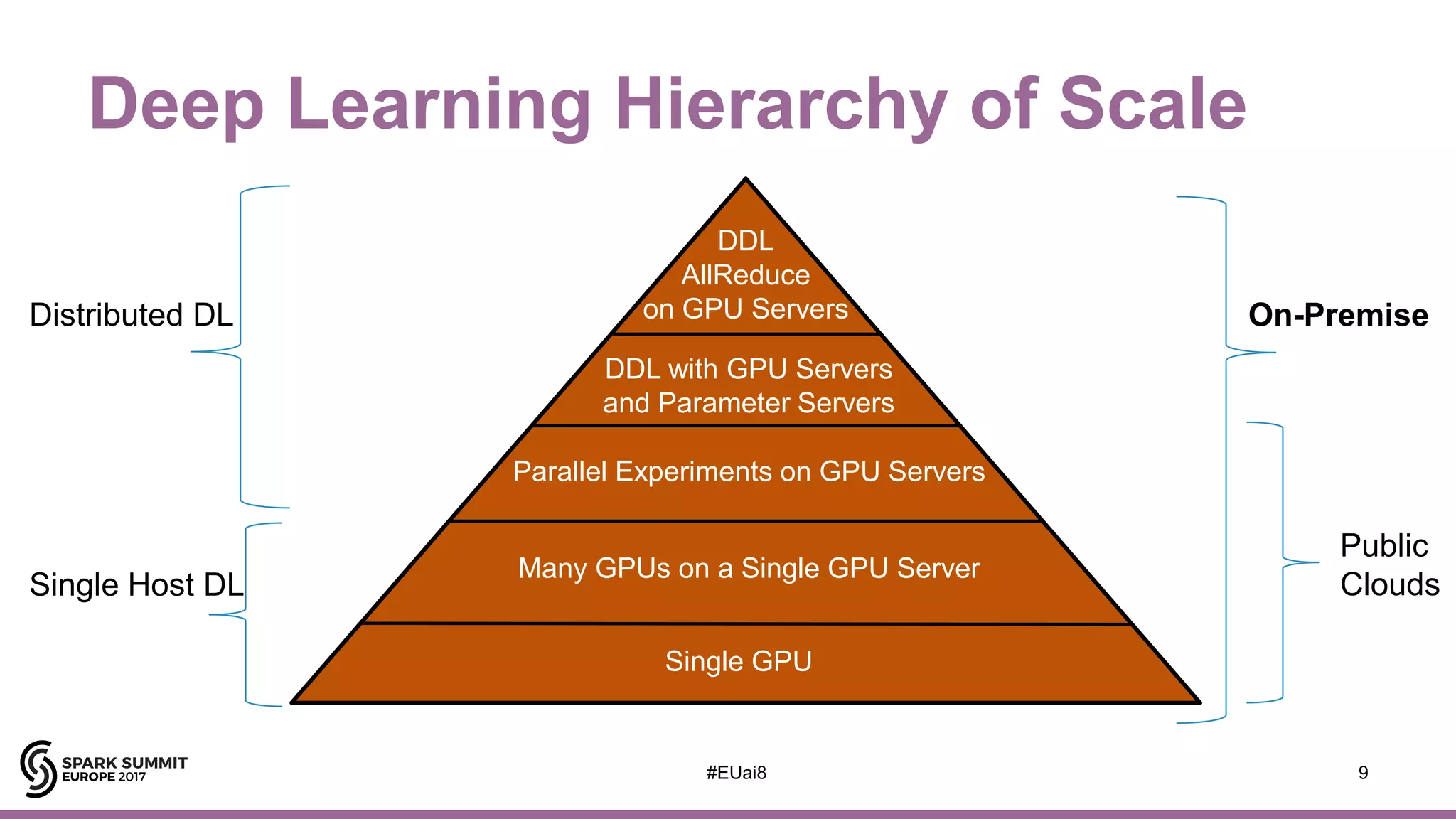
![AI Hierarchy of Needs
7
DDL
(Distributed
Deep Learning)
Deep Learning,
RL, Automated ML
A/B Testing, Experimentation, ML
B.I. Analytics, Metrics, Aggregates,
Features, Training/Test Data
Reliable Data Pipelines, ETL, Unstructured and
Structured Data Storage, Real-Time Data Ingestion
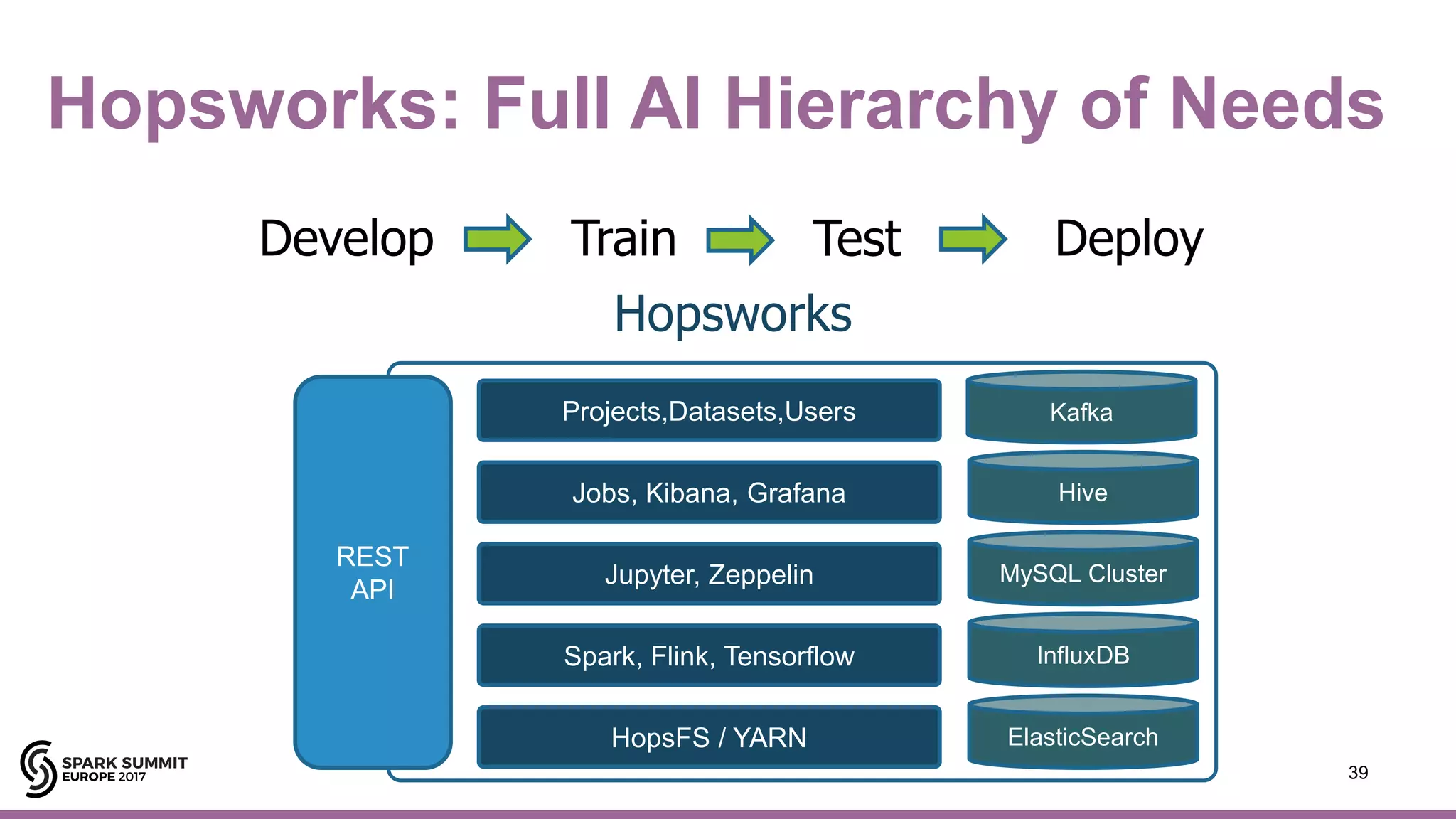
Hops
[Adapted from https://hackernoon.com/the-ai-hierarchy-of-needs-18f111fcc007?gi=7e13a696e469 ]](https://image.slidesharecdn.com/lb8jimdowling-171102164935/75/Apache-Spark-and-Tensorflow-as-a-Service-with-Jim-Dowling-6-2048.jpg)

![12#EUai8
SingleRoot
Complex Server
with 10 GPUs
[Images from: https://www.microway.com/product/octoputer-4u-10-gpu-server-single-root-complex/ ]](https://image.slidesharecdn.com/lb8jimdowling-171102164935/75/Apache-Spark-and-Tensorflow-as-a-Service-with-Jim-Dowling-11-2048.jpg)



![Hops TfLauncher – TF in Spark
def model_fn(learning_rate, dropout):
import tensorflow as tf
from hops import tensorboard, hdfs, devices
…..
from hops import tflauncher
args_dict = {'learning_rate': [0.001], 'dropout': [0.5]}
tflauncher.launch(spark, model_fn, args_dict)
20
Launch TF jobs as Mappers in Spark
“Pure” TensorFlow code
in the Executor](https://image.slidesharecdn.com/lb8jimdowling-171102164935/75/Apache-Spark-and-Tensorflow-as-a-Service-with-Jim-Dowling-19-2048.jpg)
![Hops TfLauncher – Parallel Experiments
21#EUai8
def model_fn(learning_rate, dropout):
…..
from hops import tflauncher
args_dict = {'learning_rate': [0.001, 0.005, 0.01],
'dropout': [0.5, 0.6, 0.7]}
tflauncher.launch(spark, model_fn, args_dict)
Launches 3 Executors with 3 different Hyperparameter
settings. Each Executor can have 1-N GPUs.](https://image.slidesharecdn.com/lb8jimdowling-171102164935/75/Apache-Spark-and-Tensorflow-as-a-Service-with-Jim-Dowling-20-2048.jpg)
![New TensorFlow APIs
tf.data.Dataset tf.estimator.Estimator tf.data.Iterator
22#EUai8
def model_fn(features, labels, mode, params):
…
dataset = tf.data.TFRecordDataset([“/v/f1.tfrecord", “/v/f2.tfrecord"])
dataset = dataset.map(...)
dataset = dataset.shuffle(buffer_size=10000)
dataset = dataset.batch(32)
iterator = Iterator.from_dataset(dataset)
….
nn = tf.estimator.Estimator(model_fn=model_fn, params=dict_hyp_params)
Prefer over RDDs-to-feed_dict](https://image.slidesharecdn.com/lb8jimdowling-171102164935/75/Apache-Spark-and-Tensorflow-as-a-Service-with-Jim-Dowling-21-2048.jpg)
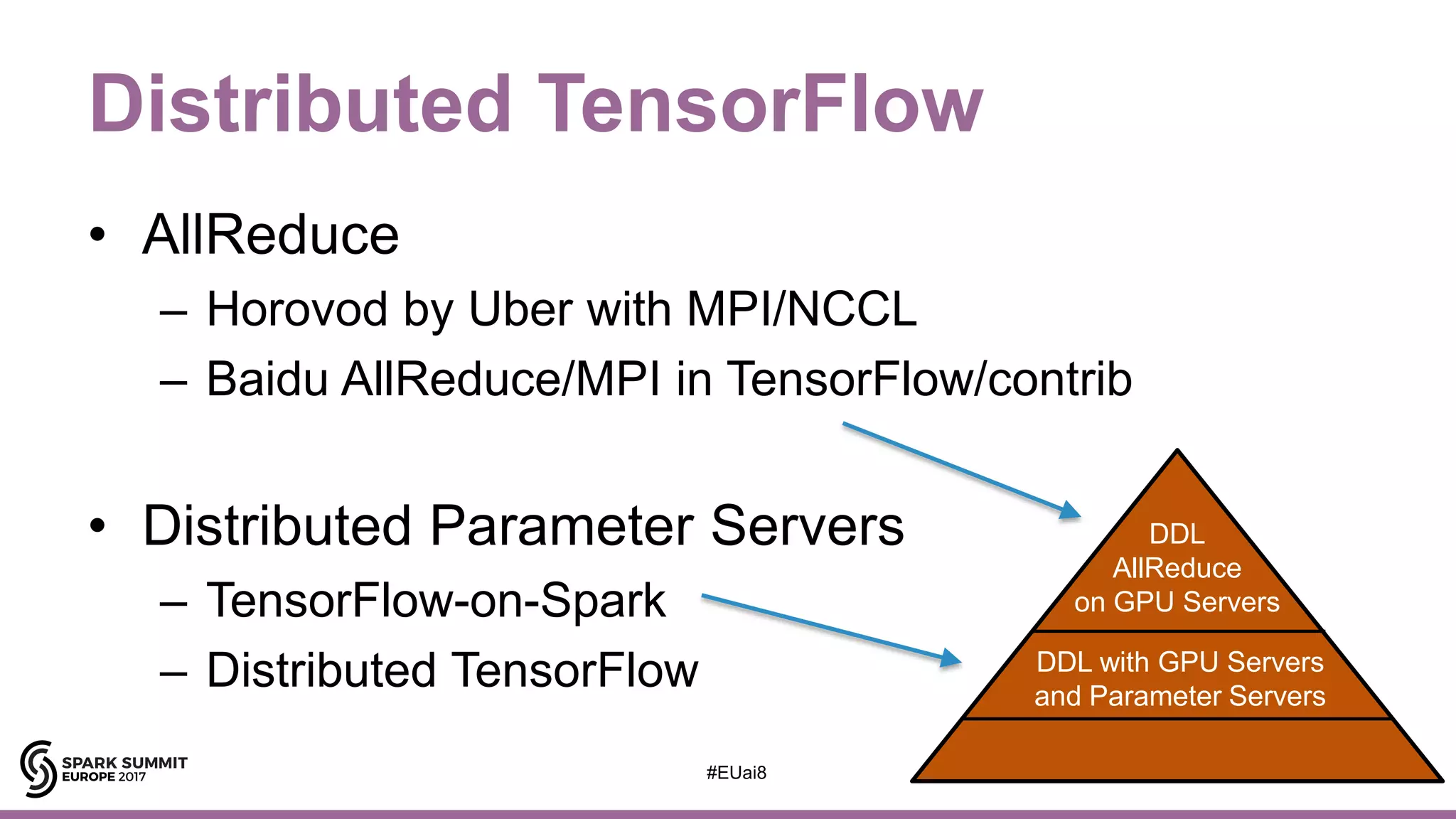
![Tensorflow-on-Spark (Yahoo!)
• Rewrite TensorFlow apps to Distributed TensorFlow
• Two modes:
1. feed_dict: RDD.mapPartitions()
2. TFReader + queue_runner: direct HDFS access from Tensorflow
26[Image from https://www.slideshare.net/Hadoop_Summit/tensorflowonspark-scalable-tensorflow-learning-on-spark-clusters]](https://image.slidesharecdn.com/lb8jimdowling-171102164935/75/Apache-Spark-and-Tensorflow-as-a-Service-with-Jim-Dowling-25-2048.jpg)
![TFonSpark with Spark Streaming
27#EUai8
[Image from https://www.slideshare.net/Hadoop_Summit/tensorflowonspark-scalable-tensorflow-learning-on-spark-clusters]](https://image.slidesharecdn.com/lb8jimdowling-171102164935/75/Apache-Spark-and-Tensorflow-as-a-Service-with-Jim-Dowling-26-2048.jpg)
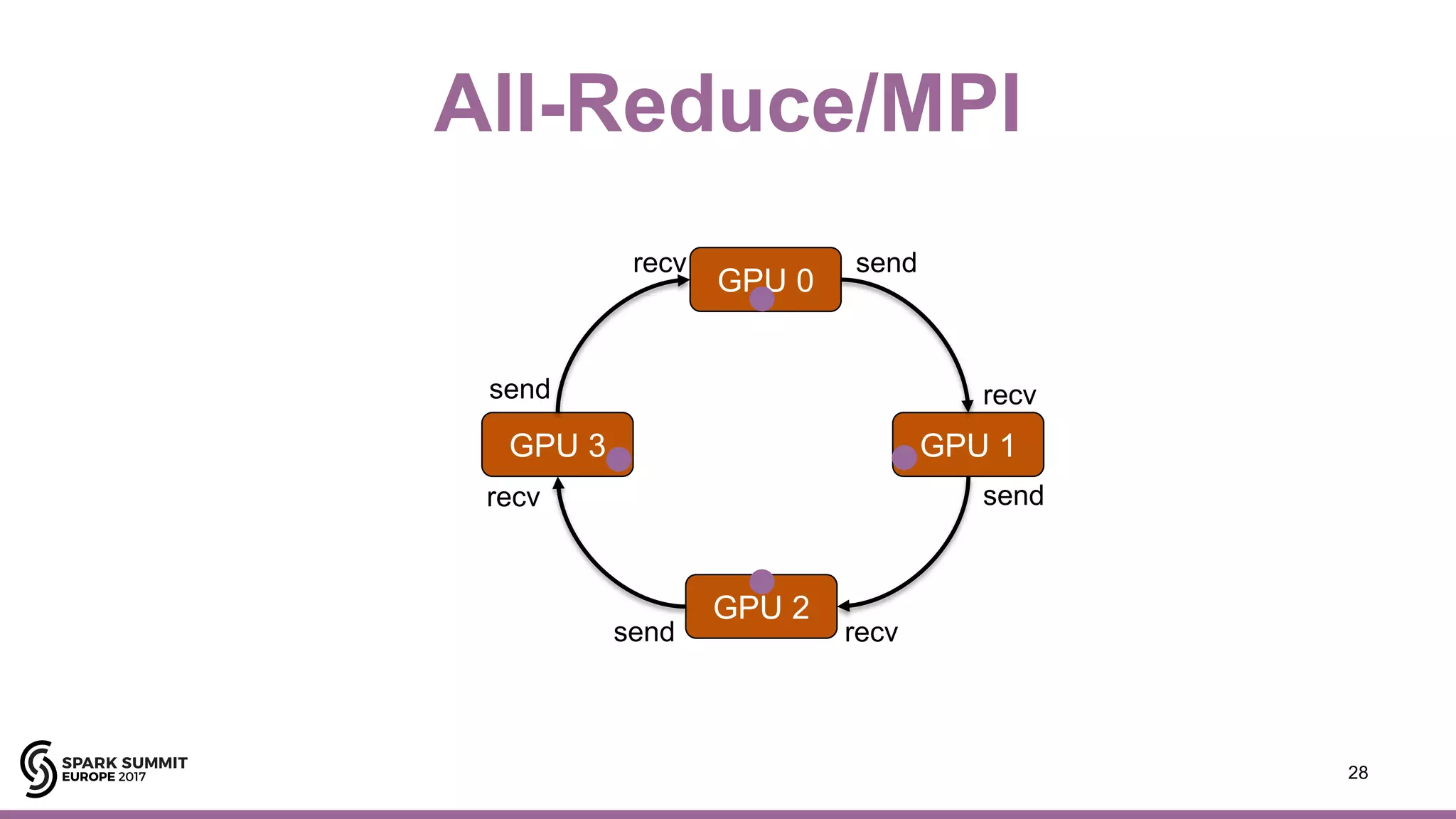
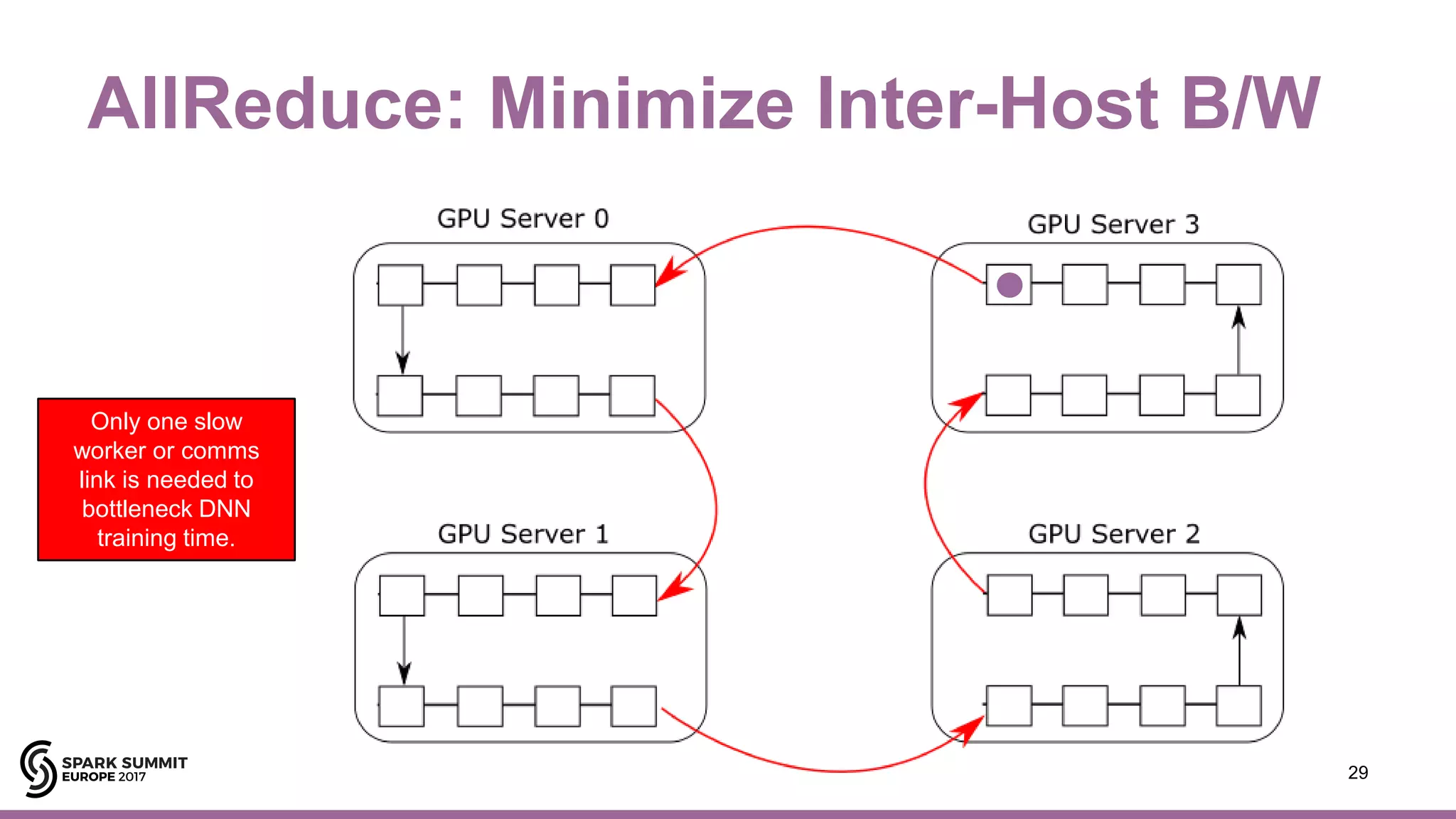
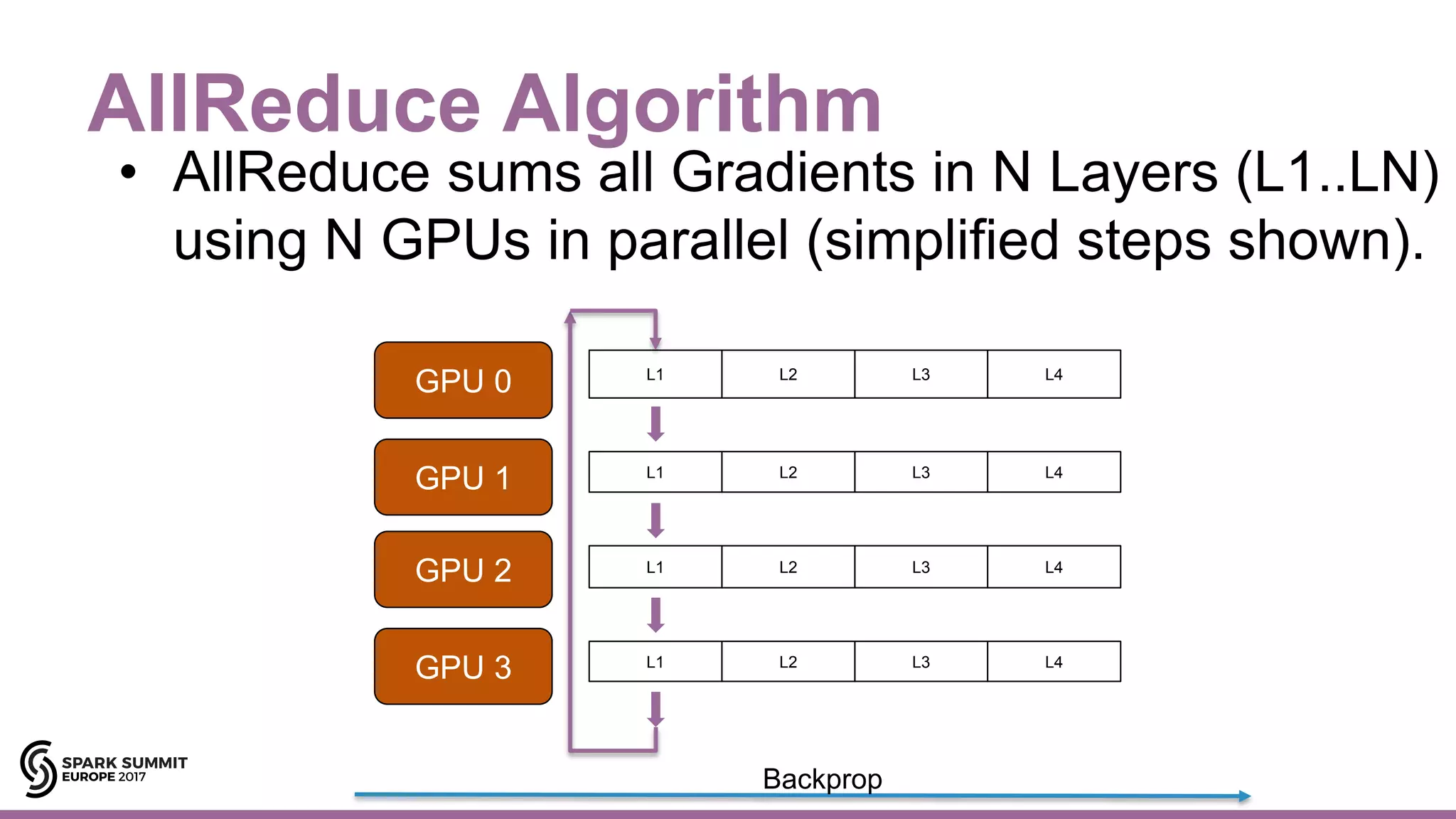

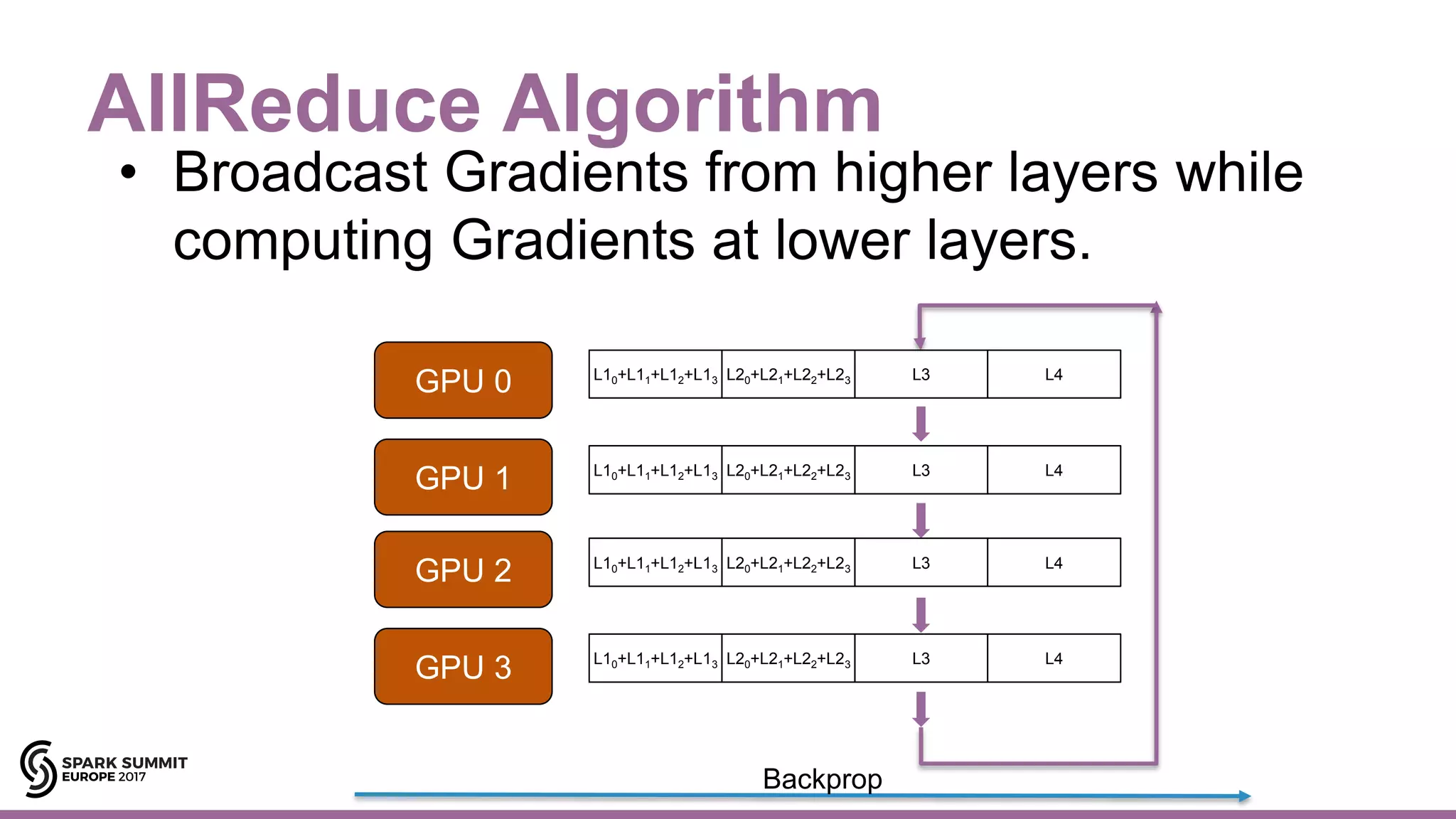
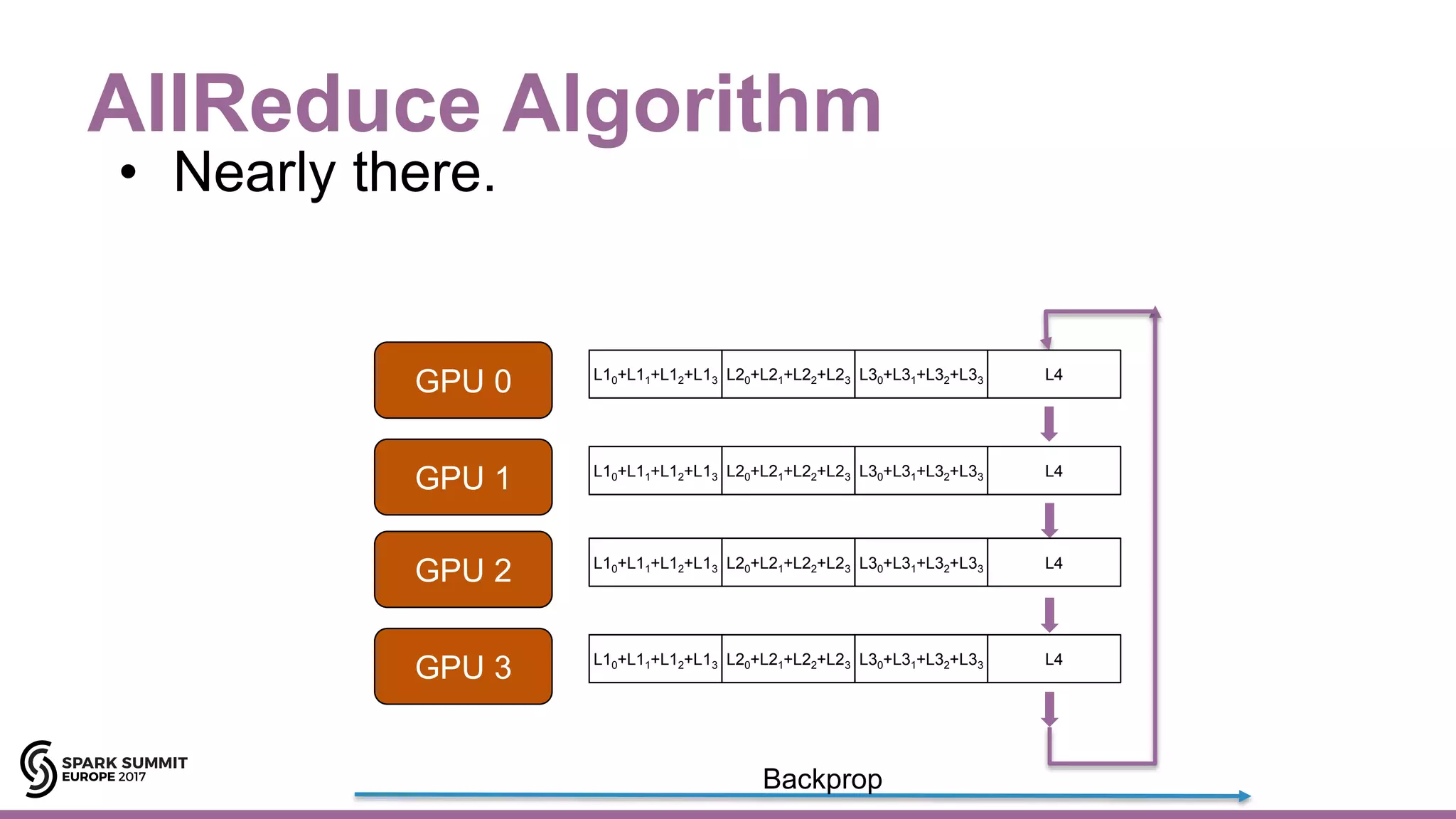

![Hops AllReduce/Horovod/TensorFlow
35#EUai8
import horovod.tensorflow as hvd
def conv_model(feature, target, mode)
…..
def main(_):
hvd.init()
opt = hvd.DistributedOptimizer(opt)
if hvd.local_rank()==0:
hooks = [hvd.BroadcastGlobalVariablesHook(0), ..]
…..
else:
hooks = [hvd.BroadcastGlobalVariablesHook(0), ..]
…..
from hops import allreduce
allreduce.launch(spark, 'hdfs:///Projects/…/all_reduce.ipynb')
“Pure” TensorFlow code](https://image.slidesharecdn.com/lb8jimdowling-171102164935/75/Apache-Spark-and-Tensorflow-as-a-Service-with-Jim-Dowling-34-2048.jpg)








![AI Hierarchy of Needs
5
DDL
(Distributed
Deep Learning)
Deep Learning,
RL, Automated ML
A/B Testing, Experimentation, ML
B.I. Analytics, Metrics, Aggregates,
Features, Training/Test Data
Reliable Data Pipelines, ETL, Unstructured and
Structured Data Storage, Real-Time Data Ingestion
[Adapted from https://hackernoon.com/the-ai-hierarchy-of-needs-18f111fcc007?gi=7e13a696e469 ]](https://crownmelresort.com/image.slidesharecdn.com/lb8jimdowling-171102164935/75/Apache-Spark-and-Tensorflow-as-a-Service-with-Jim-Dowling-4-2048.jpg)
![AI Hierarchy of Needs
6
DDL
(Distributed
Deep Learning)
Deep Learning,
RL, Automated ML
A/B Testing, Experimentation, ML
B.I. Analytics, Metrics, Aggregates,
Features, Training/Test Data
Reliable Data Pipelines, ETL, Unstructured and
Structured Data Storage, Real-Time Data Ingestion
[Adapted from https://hackernoon.com/the-ai-hierarchy-of-needs-18f111fcc007?gi=7e13a696e469 ]
Analytics
Prediction](https://crownmelresort.com/image.slidesharecdn.com/lb8jimdowling-171102164935/75/Apache-Spark-and-Tensorflow-as-a-Service-with-Jim-Dowling-5-2048.jpg)
![AI Hierarchy of Needs
7
DDL
(Distributed
Deep Learning)
Deep Learning,
RL, Automated ML
A/B Testing, Experimentation, ML
B.I. Analytics, Metrics, Aggregates,
Features, Training/Test Data
Reliable Data Pipelines, ETL, Unstructured and
Structured Data Storage, Real-Time Data Ingestion
Hops
[Adapted from https://hackernoon.com/the-ai-hierarchy-of-needs-18f111fcc007?gi=7e13a696e469 ]](https://crownmelresort.com/image.slidesharecdn.com/lb8jimdowling-171102164935/75/Apache-Spark-and-Tensorflow-as-a-Service-with-Jim-Dowling-6-2048.jpg)




![12#EUai8
SingleRoot
Complex Server
with 10 GPUs
[Images from: https://www.microway.com/product/octoputer-4u-10-gpu-server-single-root-complex/ ]](https://crownmelresort.com/image.slidesharecdn.com/lb8jimdowling-171102164935/75/Apache-Spark-and-Tensorflow-as-a-Service-with-Jim-Dowling-11-2048.jpg)







![Hops TfLauncher – TF in Spark
def model_fn(learning_rate, dropout):
import tensorflow as tf
from hops import tensorboard, hdfs, devices
…..
from hops import tflauncher
args_dict = {'learning_rate': [0.001], 'dropout': [0.5]}
tflauncher.launch(spark, model_fn, args_dict)
20
Launch TF jobs as Mappers in Spark
“Pure” TensorFlow code
in the Executor](https://crownmelresort.com/image.slidesharecdn.com/lb8jimdowling-171102164935/75/Apache-Spark-and-Tensorflow-as-a-Service-with-Jim-Dowling-19-2048.jpg)
![Hops TfLauncher – Parallel Experiments
21#EUai8
def model_fn(learning_rate, dropout):
…..
from hops import tflauncher
args_dict = {'learning_rate': [0.001, 0.005, 0.01],
'dropout': [0.5, 0.6, 0.7]}
tflauncher.launch(spark, model_fn, args_dict)
Launches 3 Executors with 3 different Hyperparameter
settings. Each Executor can have 1-N GPUs.](https://crownmelresort.com/image.slidesharecdn.com/lb8jimdowling-171102164935/75/Apache-Spark-and-Tensorflow-as-a-Service-with-Jim-Dowling-20-2048.jpg)
![New TensorFlow APIs
tf.data.Dataset tf.estimator.Estimator tf.data.Iterator
22#EUai8
def model_fn(features, labels, mode, params):
…
dataset = tf.data.TFRecordDataset([“/v/f1.tfrecord", “/v/f2.tfrecord"])
dataset = dataset.map(...)
dataset = dataset.shuffle(buffer_size=10000)
dataset = dataset.batch(32)
iterator = Iterator.from_dataset(dataset)
….
nn = tf.estimator.Estimator(model_fn=model_fn, params=dict_hyp_params)
Prefer over RDDs-to-feed_dict](https://crownmelresort.com/image.slidesharecdn.com/lb8jimdowling-171102164935/75/Apache-Spark-and-Tensorflow-as-a-Service-with-Jim-Dowling-21-2048.jpg)



![Tensorflow-on-Spark (Yahoo!)
• Rewrite TensorFlow apps to Distributed TensorFlow
• Two modes:
1. feed_dict: RDD.mapPartitions()
2. TFReader + queue_runner: direct HDFS access from Tensorflow
26[Image from https://www.slideshare.net/Hadoop_Summit/tensorflowonspark-scalable-tensorflow-learning-on-spark-clusters]](https://crownmelresort.com/image.slidesharecdn.com/lb8jimdowling-171102164935/75/Apache-Spark-and-Tensorflow-as-a-Service-with-Jim-Dowling-25-2048.jpg)
![TFonSpark with Spark Streaming
27#EUai8
[Image from https://www.slideshare.net/Hadoop_Summit/tensorflowonspark-scalable-tensorflow-learning-on-spark-clusters]](https://crownmelresort.com/image.slidesharecdn.com/lb8jimdowling-171102164935/75/Apache-Spark-and-Tensorflow-as-a-Service-with-Jim-Dowling-26-2048.jpg)







![Hops AllReduce/Horovod/TensorFlow
35#EUai8
import horovod.tensorflow as hvd
def conv_model(feature, target, mode)
…..
def main(_):
hvd.init()
opt = hvd.DistributedOptimizer(opt)
if hvd.local_rank()==0:
hooks = [hvd.BroadcastGlobalVariablesHook(0), ..]
…..
else:
hooks = [hvd.BroadcastGlobalVariablesHook(0), ..]
…..
from hops import allreduce
allreduce.launch(spark, 'hdfs:///Projects/…/all_reduce.ipynb')
“Pure” TensorFlow code](https://crownmelresort.com/image.slidesharecdn.com/lb8jimdowling-171102164935/75/Apache-Spark-and-Tensorflow-as-a-Service-with-Jim-Dowling-34-2048.jpg)











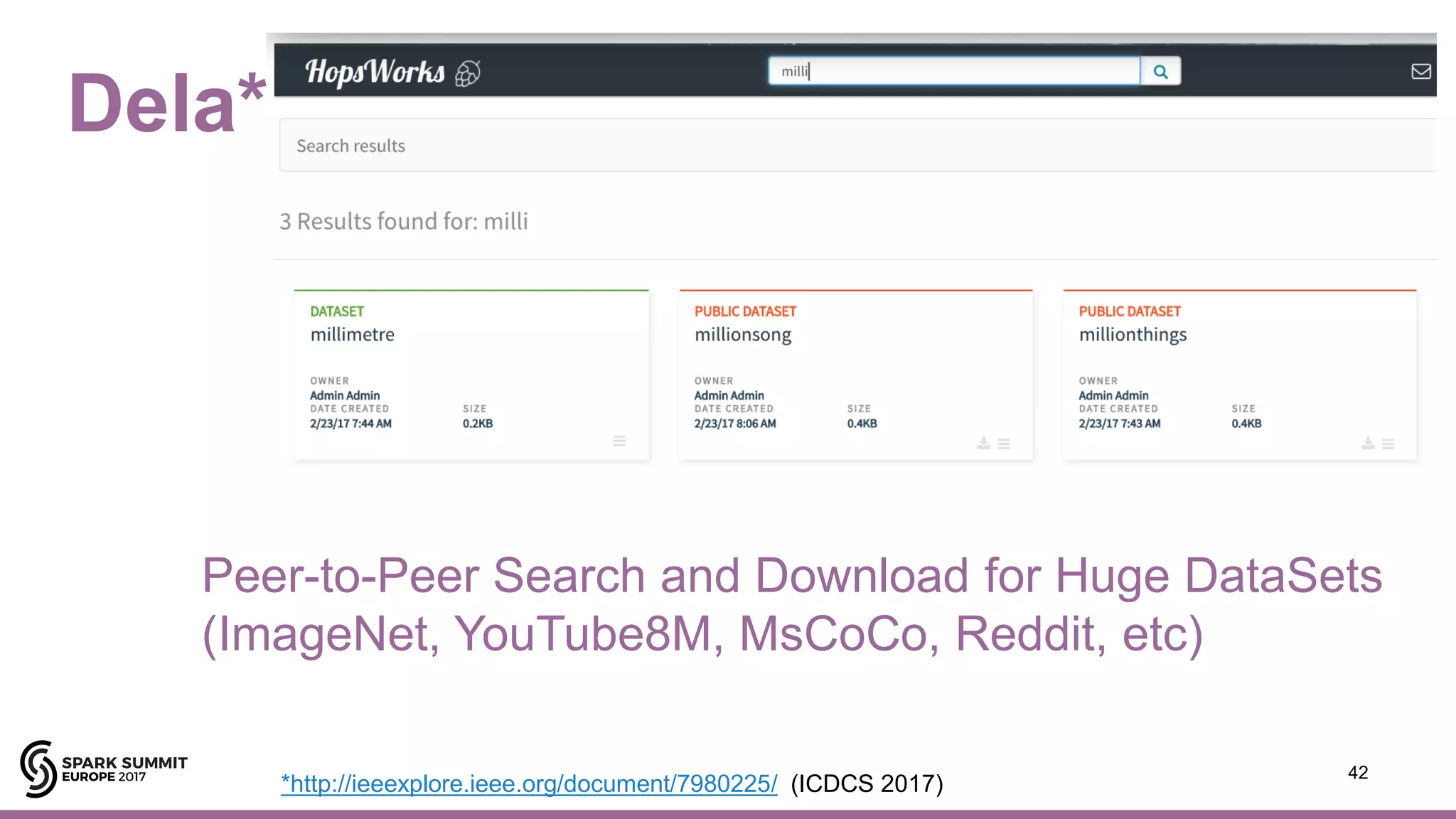
The document discusses advancements in deep learning, particularly the integration of TensorFlow and Spark for distributed training, highlighting the need for robust data pipelines and hardware configurations. It outlines various models and frameworks, such as Horovod and TensorFlow on Spark, to enhance efficiency in training using multiple GPUs and optimization techniques. Additionally, it presents the AI hierarchy of needs and the role of Hopsworks in supporting machine learning workflows.




















































































![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)


