Downloaded 203 times











![16
Auto Setting the Number of Reducers
Map
Task 1
Partition 0
Partition 1
Partition 2
Partition 3
Partition 4
Map
Task 2
Partition 0
Partition 1
Partition 2
Partition 3
Partition 4
Reduce
Task 1
Partition 0
(70MB)
Reduce
Task 2
Partition 1
(30MB)
Partition 2
(20 MB)
Partition 3
(10 MB)
Reduce
Task 3
Parition 4
(50 MB)
• 5 initial reducer partitions with size
[70 MB, 30 MB, 20 MB, 10 MB, 50 MB]
• Set target size per reducer = 64 MB. At runtime, we use 3 actual reducers.
• Also support setting target row count per reducer.](https://image.slidesharecdn.com/a4carsonwang-171031193242/75/An-Adaptive-Execution-Engine-for-Apache-Spark-with-Carson-Wang-and-Yucai-Yu-16-2048.jpg)























![16
Auto Setting the Number of Reducers
Map
Task 1
Partition 0
Partition 1
Partition 2
Partition 3
Partition 4
Map
Task 2
Partition 0
Partition 1
Partition 2
Partition 3
Partition 4
Reduce
Task 1
Partition 0
(70MB)
Reduce
Task 2
Partition 1
(30MB)
Partition 2
(20 MB)
Partition 3
(10 MB)
Reduce
Task 3
Parition 4
(50 MB)
• 5 initial reducer partitions with size
[70 MB, 30 MB, 20 MB, 10 MB, 50 MB]
• Set target size per reducer = 64 MB. At runtime, we use 3 actual reducers.
• Also support setting target row count per reducer.](https://crownmelresort.com/image.slidesharecdn.com/a4carsonwang-171031193242/75/An-Adaptive-Execution-Engine-for-Apache-Spark-with-Carson-Wang-and-Yucai-Yu-16-2048.jpg)














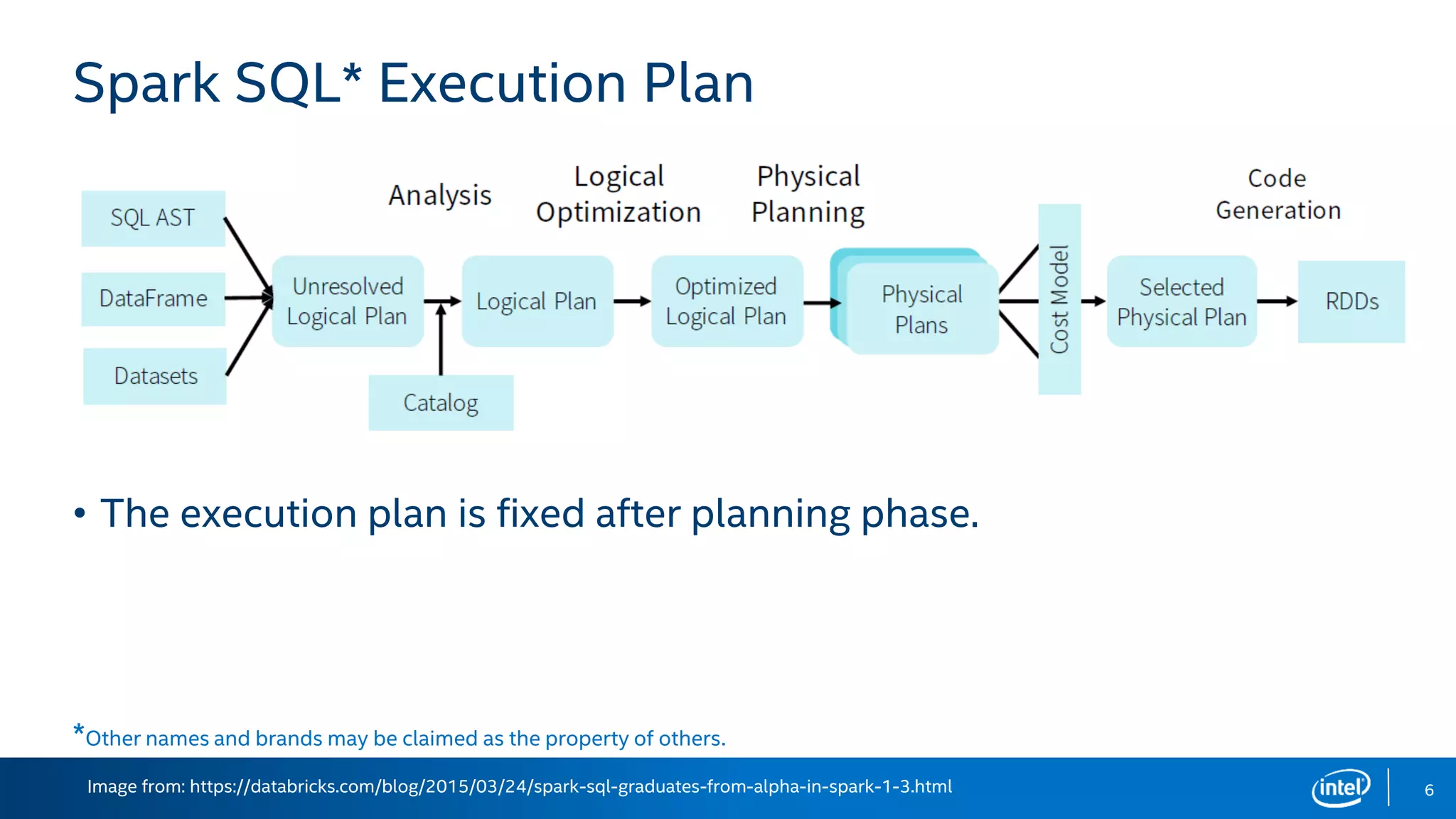
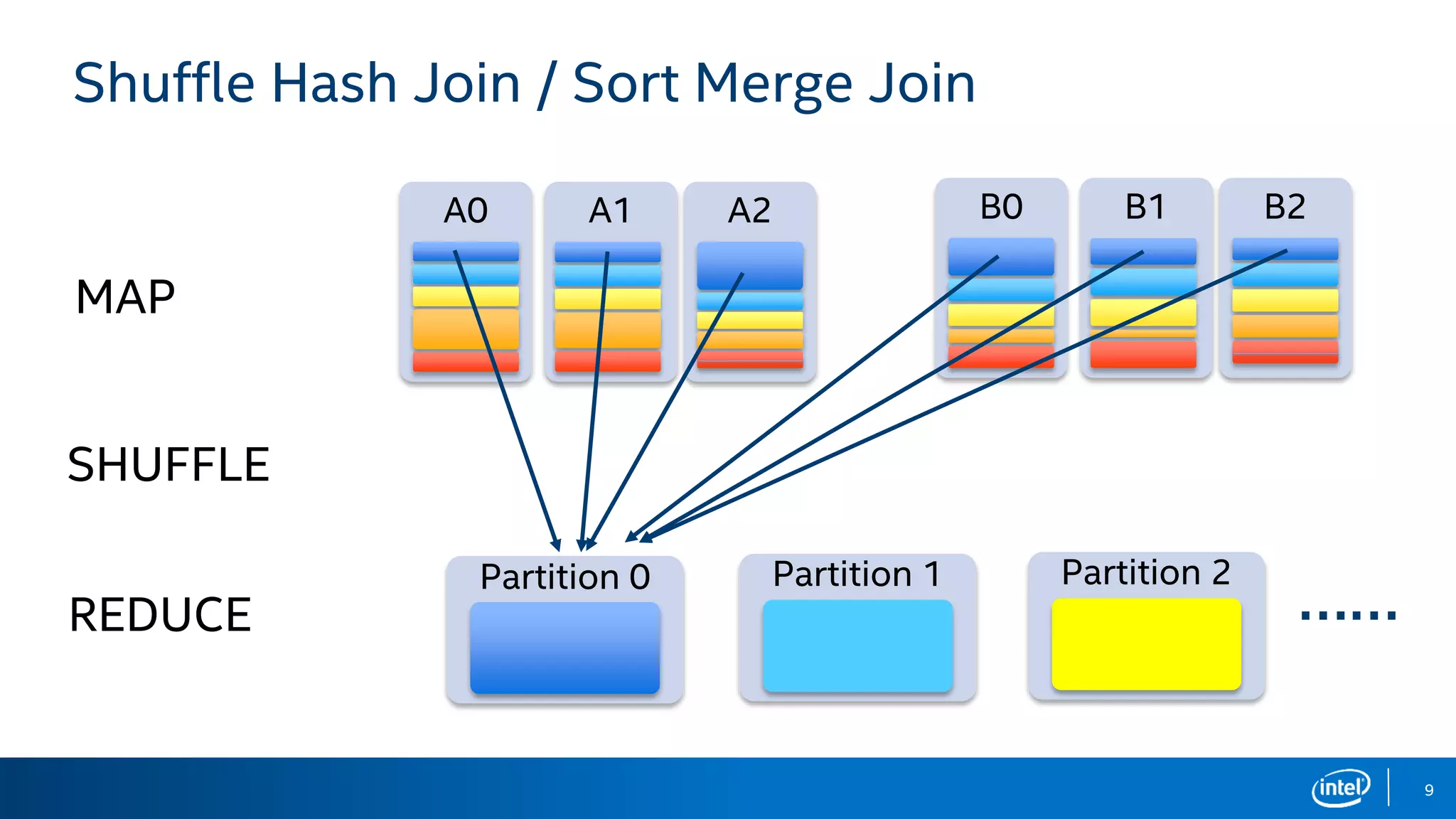
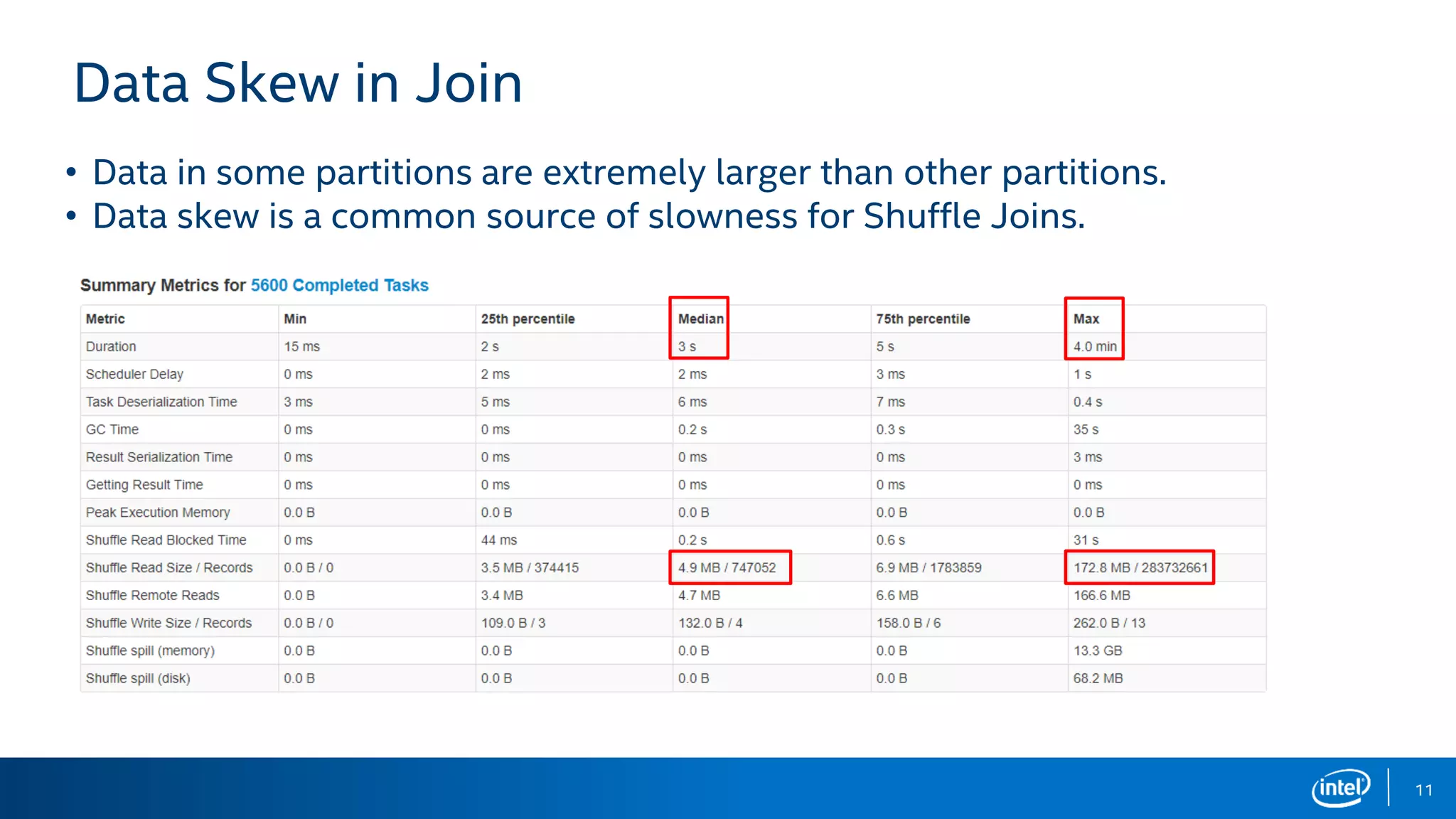
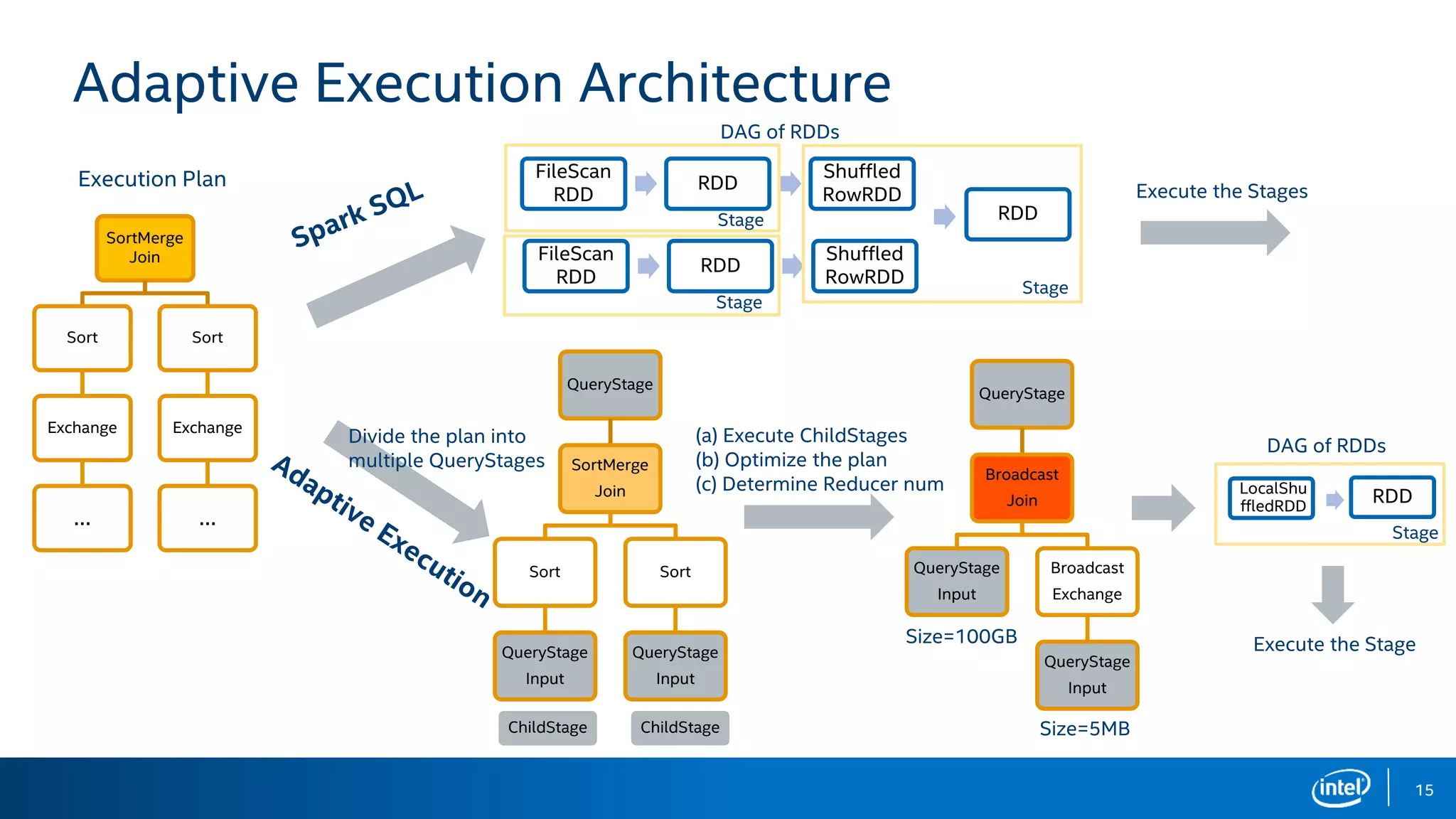
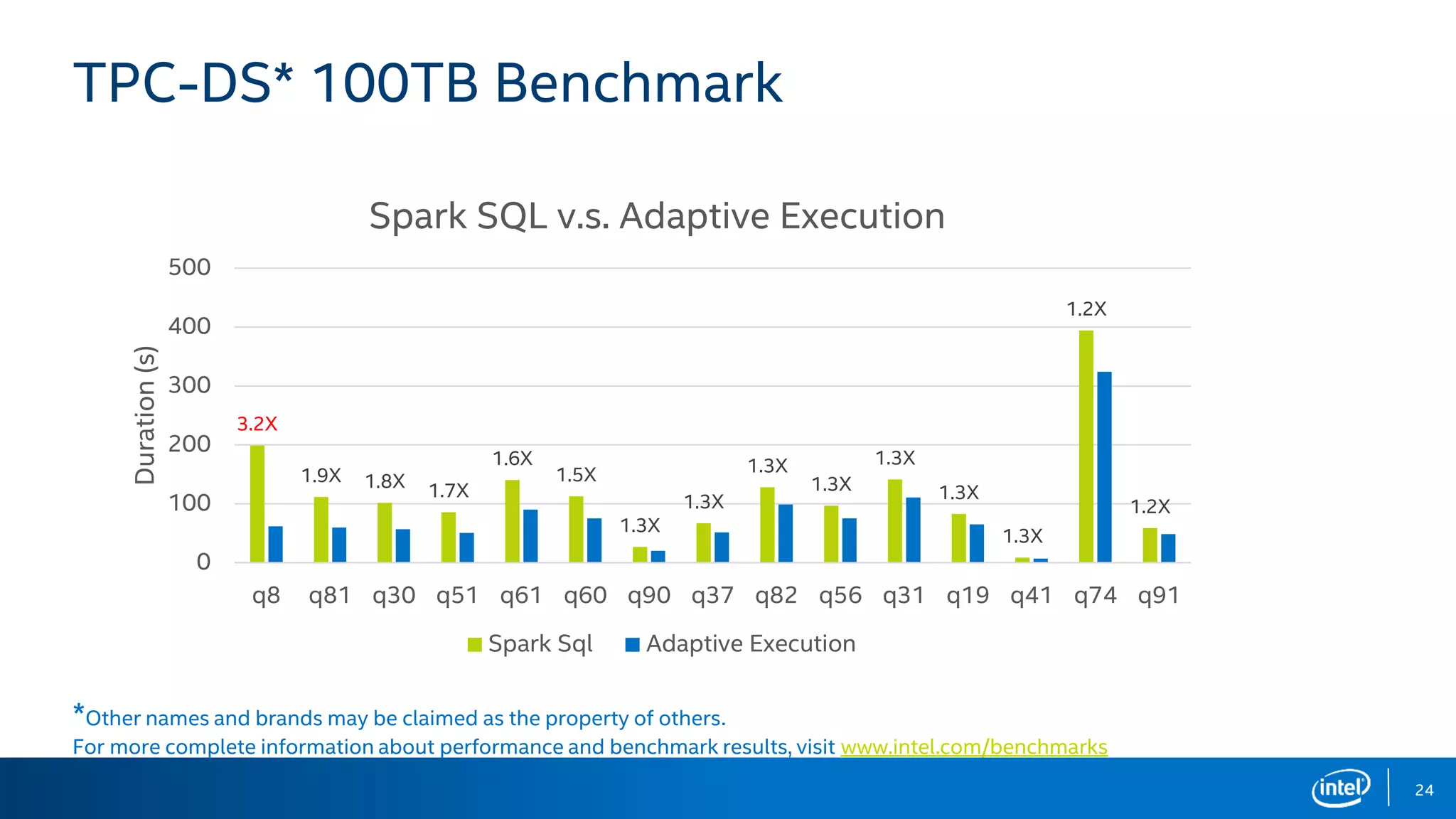
The document discusses the challenges and solutions related to adaptive execution in Apache Spark SQL, particularly focusing on optimizing shuffle partition numbers and join strategies to enhance performance. It introduces a new adaptive execution engine designed to dynamically adjust execution plans and tackle issues like data skew during query execution. Benchmark results demonstrate significant performance improvements with the new engine compared to traditional Spark SQL execution.






























































































