Downloaded 59 times






























![BATCH NORMALIZATION (2015)
§ Each Mini-Batch May Have Wildly Different Distributions
§ Normalize per Batch (and Layer)
§ Faster Training, Learns Quicker
§ Final Model is More Accurate
§ TensorFlow is already on 2nd Generation Batch Algorithm
§ First-Class Support for Fusing Batch Norm Layers
§ Final mean + variance Are Folded Into Our Graph Later
-- (Almost)Always Use Batch Normalization! --
z = tf.matmul(a_prev, W)
a = tf.nn.relu(z)
a_mean, a_var = tf.nn.moments(a, [0])
scale = tf.Variable(tf.ones([depth/channels]))
beta = tf.Variable(tf.zeros ([depth/channels]))
bn = tf.nn.batch_normalizaton(a, a_mean, a_var,
beta, scale, 0.001)](https://image.slidesharecdn.com/odscwestsfnov2017-171107181917/75/Building-Google-s-ML-Engine-from-Scratch-on-AWS-with-GPUs-Kubernetes-Istio-TensorFlow-and-Spark-ODSC-West-SF-Nov-2017-44-2048.jpg)














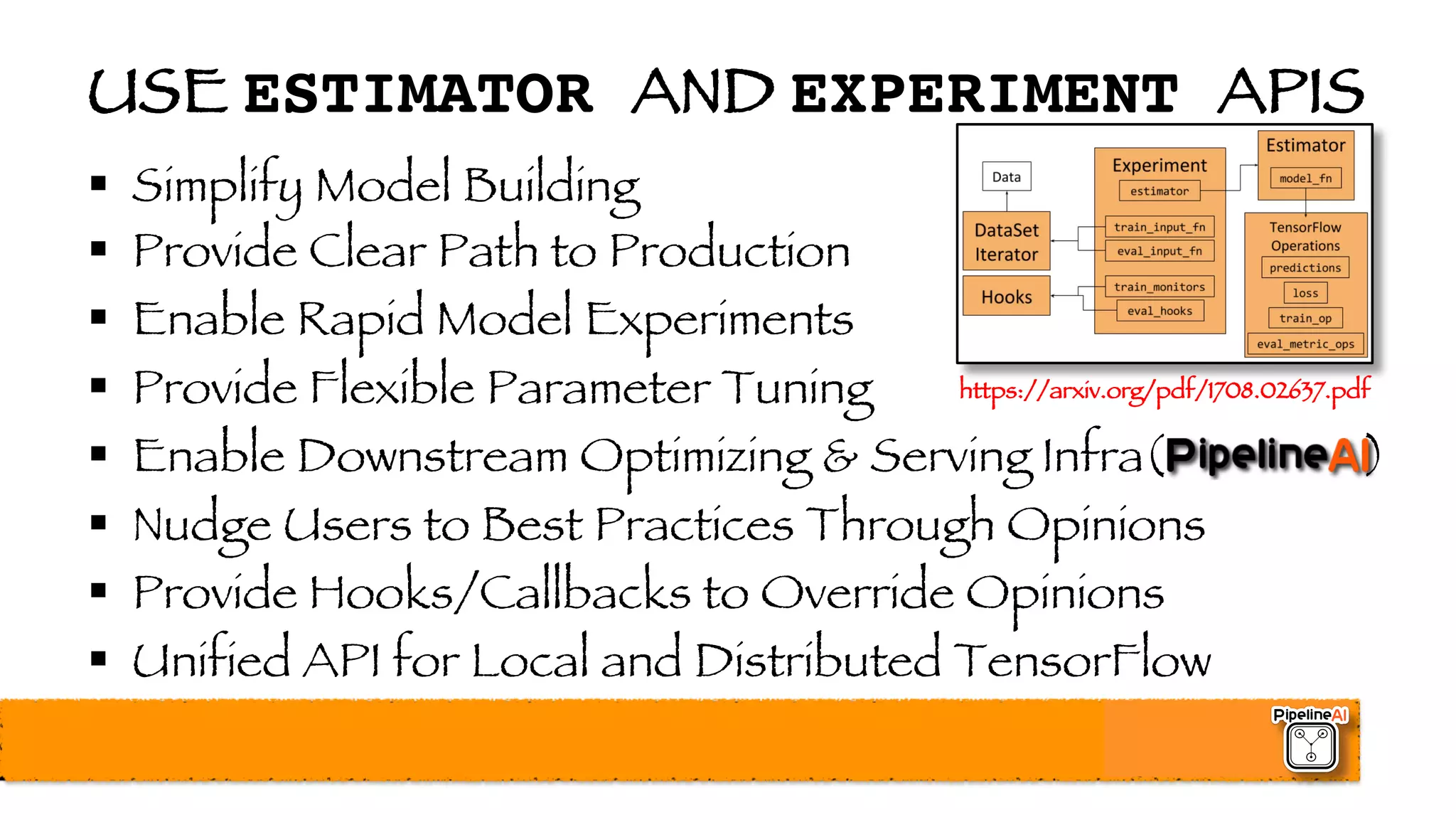





![ESTIMATOR & EXPERIMENT CONFIGS
§ TF_CONFIG
§ Special environment variable for config
§ Defines ClusterSpec in JSON incl. master, workers, PS’s
§ Must set ”{environment”:“cloud”} for distributed mode
§ RunConfig: Defines checkpoint interval, output directory, …
§ HParams: Hyper-parameter tuning parameters and ranges
§ learn_runner creates RunConfig before calling run() & tune()
§ schedule is set based on {”task”:{”type”}}
§ Set to train_and_evaluate for local, single-node training
TF_CONFIG=
'{
"environment": "cloud",
"cluster":
{
"master":["worker0:2222”],
"worker":["worker1:2222"],
"ps": ["ps0:2222"]
},
"task": {"type": "ps",
"index": "0"}
}'](https://image.slidesharecdn.com/odscwestsfnov2017-171107181917/75/Building-Google-s-ML-Engine-from-Scratch-on-AWS-with-GPUs-Kubernetes-Istio-TensorFlow-and-Spark-ODSC-West-SF-Nov-2017-73-2048.jpg)







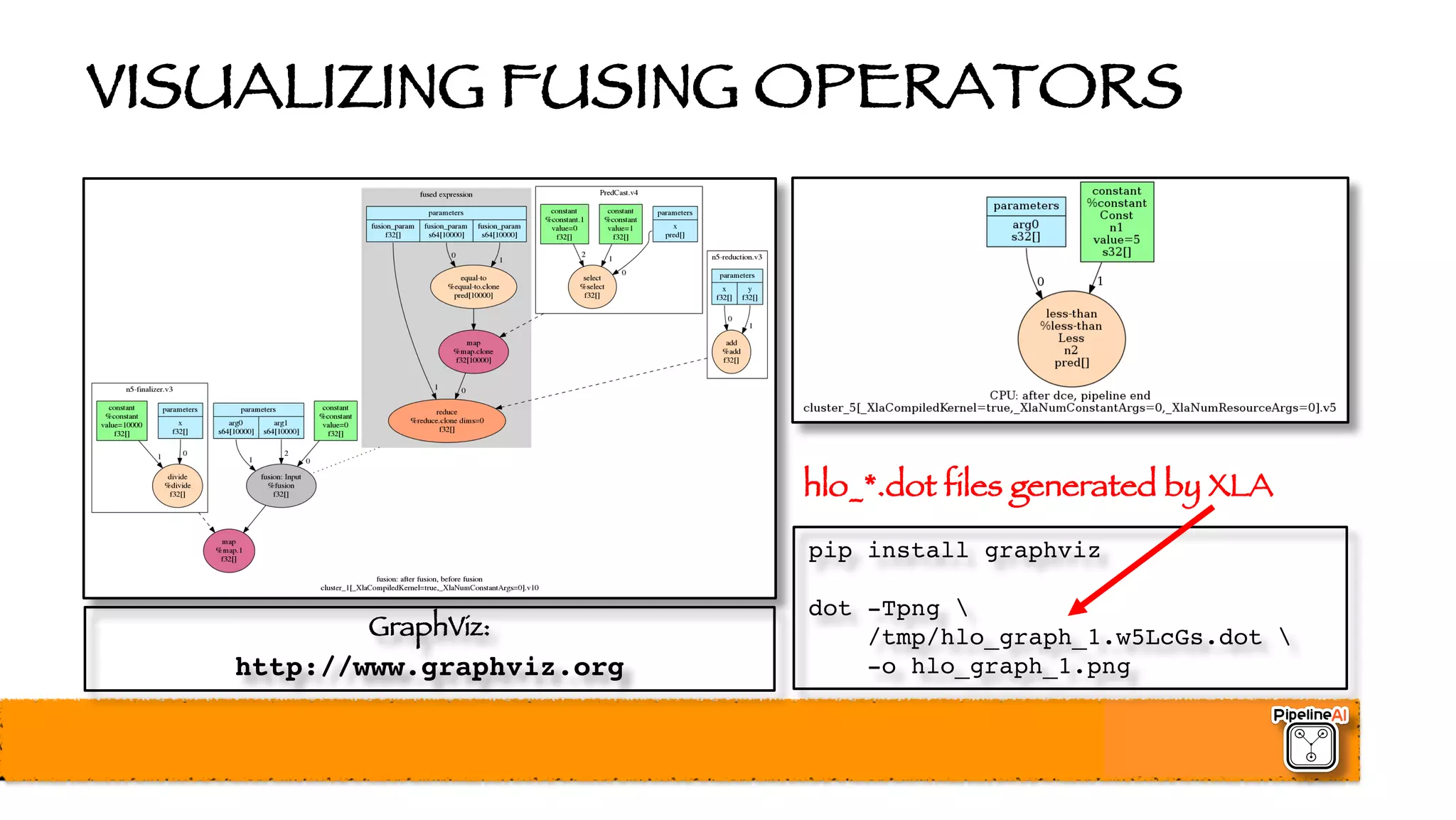








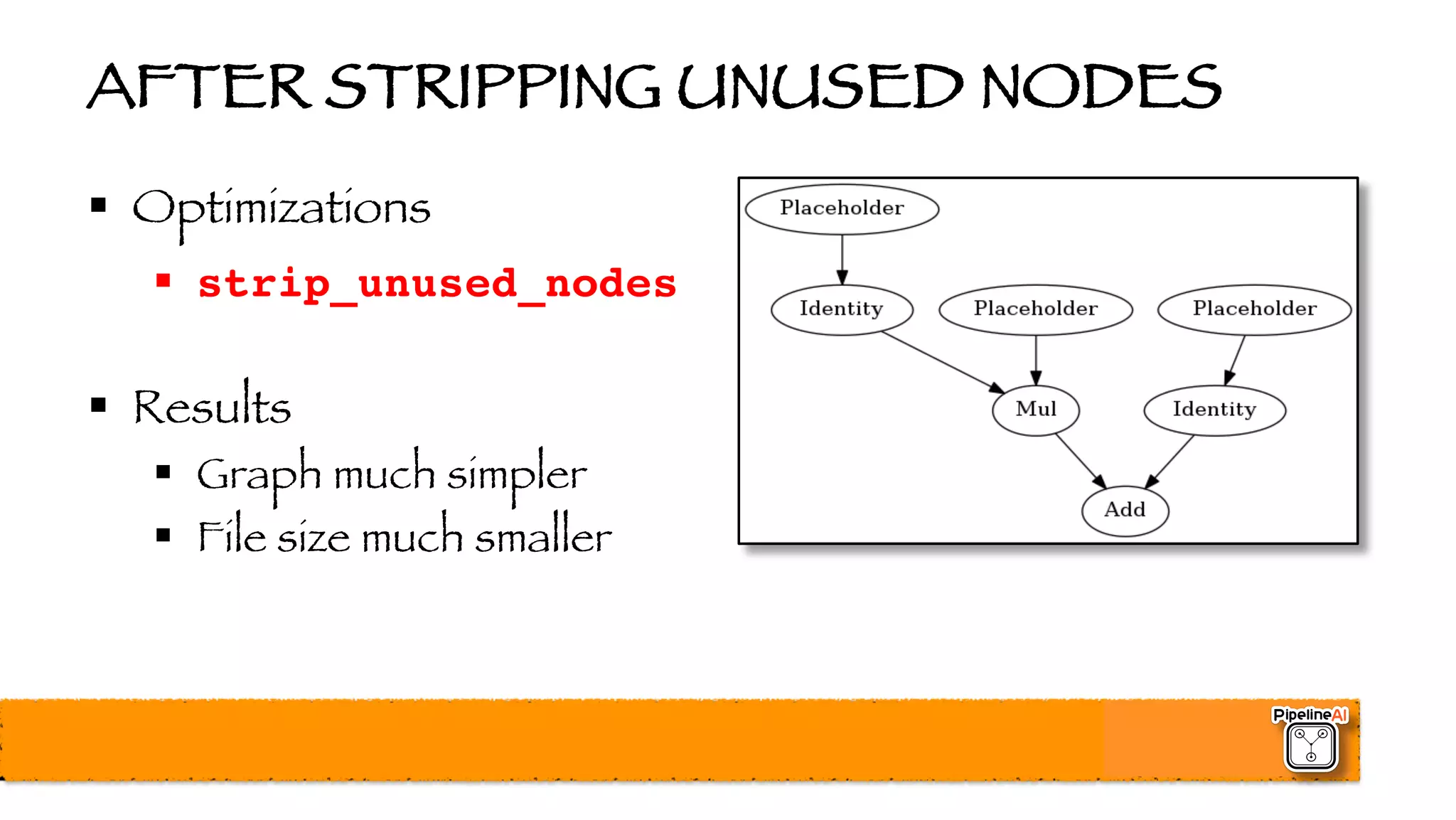
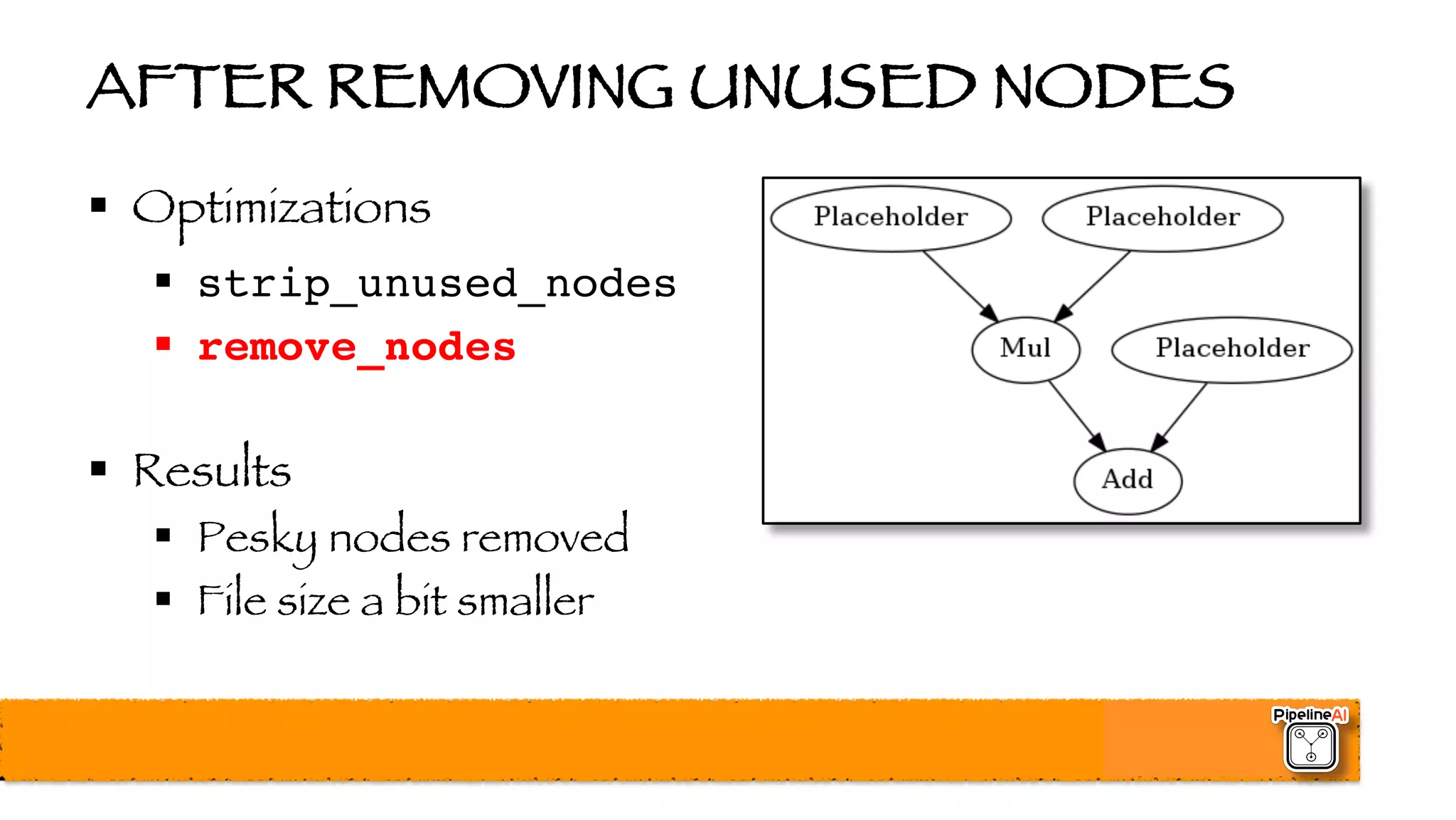
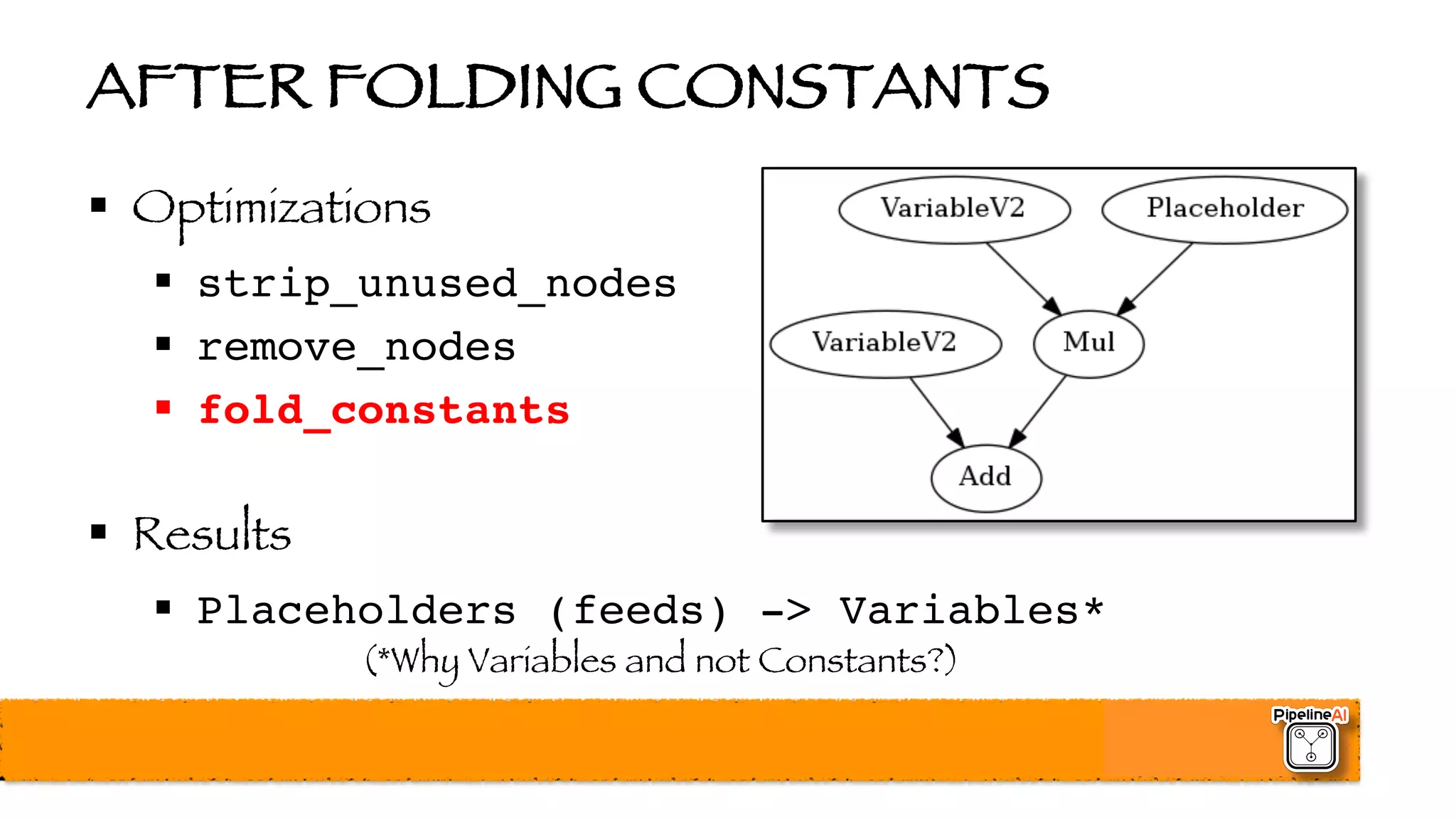



























































![BATCH NORMALIZATION (2015)
§ Each Mini-Batch May Have Wildly Different Distributions
§ Normalize per Batch (and Layer)
§ Faster Training, Learns Quicker
§ Final Model is More Accurate
§ TensorFlow is already on 2nd Generation Batch Algorithm
§ First-Class Support for Fusing Batch Norm Layers
§ Final mean + variance Are Folded Into Our Graph Later
-- (Almost)Always Use Batch Normalization! --
z = tf.matmul(a_prev, W)
a = tf.nn.relu(z)
a_mean, a_var = tf.nn.moments(a, [0])
scale = tf.Variable(tf.ones([depth/channels]))
beta = tf.Variable(tf.zeros ([depth/channels]))
bn = tf.nn.batch_normalizaton(a, a_mean, a_var,
beta, scale, 0.001)](https://crownmelresort.com/image.slidesharecdn.com/odscwestsfnov2017-171107181917/75/Building-Google-s-ML-Engine-from-Scratch-on-AWS-with-GPUs-Kubernetes-Istio-TensorFlow-and-Spark-ODSC-West-SF-Nov-2017-44-2048.jpg)




























![ESTIMATOR & EXPERIMENT CONFIGS
§ TF_CONFIG
§ Special environment variable for config
§ Defines ClusterSpec in JSON incl. master, workers, PS’s
§ Must set ”{environment”:“cloud”} for distributed mode
§ RunConfig: Defines checkpoint interval, output directory, …
§ HParams: Hyper-parameter tuning parameters and ranges
§ learn_runner creates RunConfig before calling run() & tune()
§ schedule is set based on {”task”:{”type”}}
§ Set to train_and_evaluate for local, single-node training
TF_CONFIG=
'{
"environment": "cloud",
"cluster":
{
"master":["worker0:2222”],
"worker":["worker1:2222"],
"ps": ["ps0:2222"]
},
"task": {"type": "ps",
"index": "0"}
}'](https://crownmelresort.com/image.slidesharecdn.com/odscwestsfnov2017-171107181917/75/Building-Google-s-ML-Engine-from-Scratch-on-AWS-with-GPUs-Kubernetes-Istio-TensorFlow-and-Spark-ODSC-West-SF-Nov-2017-73-2048.jpg)















































The document covers a presentation on optimizing TensorFlow model training and serving for production, focusing on GPU utilization at the ODSC Conference in San Francisco. It details the PipelineAI framework, which allows for efficient deployment, tuning, and experimentation with TensorFlow models, emphasizing the importance of real-time predictions over batch training. The agenda includes a breakdown of content and hands-on exercises, showcasing tools and techniques for effective model management in production environments.








































![[DSC 2016] 系列活動:李泳泉 / 星火燎原 - Spark 機器學習初探](https://cdn.slidesharecdn.com/ss_thumbnails/sparkmllib-161026052038-thumbnail.jpg?width=640&height=640&fit=bounds)



![[系列活動] 資料探勘速遊](https://cdn.slidesharecdn.com/ss_thumbnails/0114ycchendmquicktour-170110050658-thumbnail.jpg?width=640&height=640&fit=bounds)
























































