Download as PDF, PPTX





![PyTorch + MLflow
M L F L O W A U T O L O G G I N G
• PyTorch auto logging with Lightning training loop
• Model hyper-params like LR, model summary,
optimizer name, min delta, best score
• Early stopping and other callbacks
• Log every N iterations
• User defined metrics like F1 score, test accuracy
import mlflow.pytorch
parser =
LightningMNISTClassifier.add_model_specific_args(parent_parser=parser)
#just add this and your autologging should work!
mlflow.pytorch.autolog()
model = LightningMNISTClassifier(**dict_args)
dm = MNISTDataModule(**dict_args)
dm.prepare_data()
dm.setup(stage="fit")
early_stopping = EarlyStopping(monitor="val_loss", mode="min",
verbose=True)
checkpoint_callback = ModelCheckpoint(
filepath=os.getcwd(), save_top_k=1, verbose=True,
monitor="val_loss", mode="min", prefix="",
)
lr_logger = LearningRateLogger()
trainer = pl.Trainer.from_argparse_args(
args, callbacks=[lr_logger, early_stopping],
checkpoint_callback=checkpoint_callback
)
trainer.fit(model)
trainer.test()](https://image.slidesharecdn.com/reproducibleai-april2021final-210427175333/75/Reproducible-AI-using-MLflow-and-PyTorch-8-2048.jpg)
![PyTorch + MLflow
mlflow.pytorch.save_model(
model,
path=args.model_save_path,
requirements_file="requirements.txt",
extra_files=["class_mapping.json", "bert_base_uncased_vocab.txt"],
)
:param requirements_file: An (optional) string containing the path to requirements file.
If ``None``, no requirements file is added to the model.
:param extra_files: An (optional) list containing the paths to corresponding extra files.
For example, consider the following ``extra_files`` list::
extra_files = ["s3://my-bucket/path/to/my_file1",
"s3://my-bucket/path/to/my_file2"]
In this case, the ``"my_file1 & my_file2"`` extra file is downloaded from S3.
If ``None``, no extra files are added to the model.
S A V E
A R T I F A C T S
• Additional artifacts for
model reproducibility
• For Example: vocabulary files
for NLP models,
requirements.txt and other
extra files for torchserve
deployment](https://image.slidesharecdn.com/reproducibleai-april2021final-210427175333/75/Reproducible-AI-using-MLflow-and-PyTorch-10-2048.jpg)

![PyTorch + MLflow
# deploy model
mlflow deployments create --name mnist_test --target torchserve ——
model-uri mnist.pt -C "MODEL_FILE=mnist_model.py" -C
"HANDLER=mnist_handler.py"
# do prediction
mlflow deployments predict --name mnist_test --target torchserve --
input_path sample.json --output_path output.json
D E P L O Y M E N T P L U G I N
New TorchServe Deployment Plugin
Test models during development cycle, pull
models from MLflow Model repository and run
• CLI
• Run with Local vs remote TorchServe
• Python API
import os
import matplotlib.pyplot as plt
from torchvision import transforms
from mlflow.deployments import get_deploy_client
img = plt.imread(os.path.join(os.getcwd(), "test_data/one.png"))
mnist_transforms = transforms.Compose([
transforms.ToTensor()
])
image = mnist_transforms(img)
plugin = get_deploy_client("torchserve")
config = {
'MODEL_FILE': "mnist_model.py",
'HANDLER_FILE': 'mnist_handler.py'
}
plugin.create_deployment(name="mnist_test", model_uri="mnist_cnn.pt",
config=config)
prediction = plugin.predict("mnist_test", image)](https://image.slidesharecdn.com/reproducibleai-april2021final-210427175333/75/Reproducible-AI-using-MLflow-and-PyTorch-13-2048.jpg)
![NEW FEATURES
Integrations and new samples for:
- Model Interpretability using Captum
- Model Signature
- Hyper Parameter Optimization using Ax/Botorch
- Iterative Pruning Example using Ax/Botorch
#Captum
ig = IntegratedGradients(net)
test_input_tensor.requires_grad_()
attr, _ = ig.attribute(test_input_tensor, target=1,
return_convergence_delta=True)
attr = attr.detach().numpy()
# To understand attributions, average across all inputs, print
and visualize average attribution for each feature.
feature_imp, feature_imp_dict =
visualize_importances(feature_names, np.mean(attr, axis=0))
mlflow.log_metrics(feature_imp_dict)
mlflow.log_text(str(feature_imp), "feature_imp_summary.txt")
fig, (ax1, ax2) = plt.subplots(2, 1)
fig.tight_layout(pad=3)
ax1.hist(attr[:, 1], 100)
ax1.set(title="Distribution of Sibsp Attribution Values")
#Model Signature
from mlflow.models.signature import infer_signature
train = df.drop_column("target_label")
predictions = ... # compute model predictions
signature = infer_signature(train, predictions)](https://image.slidesharecdn.com/reproducibleai-april2021final-210427175333/75/Reproducible-AI-using-MLflow-and-PyTorch-16-2048.jpg)
![NEW FEATURES - HPO WITH AX
with mlflow.start_run(run_name="Parent Run"):
train_evaluate(params=params, max_epochs=max_epochs)
ax_client = AxClient()
ax_client.create_experiment(
parameters=[
{"name": "weight_decay", "type": "range", "bounds": [1e-4, 1e-3]},
{"name": "momentum", "type": "range", "bounds": [0.7, 1.0]},
],
objective_name="test_accuracy",
)
for i in range(total_trials):
with mlflow.start_run(nested=True, run_name="Trial " + str(i)) as child_run:
parameters, trial_index = ax_client.get_next_trial()
test_accuracy = train_evaluate(params=parameters, max_epochs=max_epochs)
# completion of trial
ax_client.complete_trial(trial_index=trial_index,
raw_data=test_accuracy.item())
best_parameters, metrics = ax_client.get_best_parameters()
for param_name, value in best_parameters.items():
mlflow.log_param("optimum_" + param_name, value)](https://image.slidesharecdn.com/reproducibleai-april2021final-210427175333/75/Reproducible-AI-using-MLflow-and-PyTorch-18-2048.jpg)











![PyTorch + MLflow
M L F L O W A U T O L O G G I N G
• PyTorch auto logging with Lightning training loop
• Model hyper-params like LR, model summary,
optimizer name, min delta, best score
• Early stopping and other callbacks
• Log every N iterations
• User defined metrics like F1 score, test accuracy
import mlflow.pytorch
parser =
LightningMNISTClassifier.add_model_specific_args(parent_parser=parser)
#just add this and your autologging should work!
mlflow.pytorch.autolog()
model = LightningMNISTClassifier(**dict_args)
dm = MNISTDataModule(**dict_args)
dm.prepare_data()
dm.setup(stage="fit")
early_stopping = EarlyStopping(monitor="val_loss", mode="min",
verbose=True)
checkpoint_callback = ModelCheckpoint(
filepath=os.getcwd(), save_top_k=1, verbose=True,
monitor="val_loss", mode="min", prefix="",
)
lr_logger = LearningRateLogger()
trainer = pl.Trainer.from_argparse_args(
args, callbacks=[lr_logger, early_stopping],
checkpoint_callback=checkpoint_callback
)
trainer.fit(model)
trainer.test()](https://crownmelresort.com/image.slidesharecdn.com/reproducibleai-april2021final-210427175333/75/Reproducible-AI-using-MLflow-and-PyTorch-8-2048.jpg)

![PyTorch + MLflow
mlflow.pytorch.save_model(
model,
path=args.model_save_path,
requirements_file="requirements.txt",
extra_files=["class_mapping.json", "bert_base_uncased_vocab.txt"],
)
:param requirements_file: An (optional) string containing the path to requirements file.
If ``None``, no requirements file is added to the model.
:param extra_files: An (optional) list containing the paths to corresponding extra files.
For example, consider the following ``extra_files`` list::
extra_files = ["s3://my-bucket/path/to/my_file1",
"s3://my-bucket/path/to/my_file2"]
In this case, the ``"my_file1 & my_file2"`` extra file is downloaded from S3.
If ``None``, no extra files are added to the model.
S A V E
A R T I F A C T S
• Additional artifacts for
model reproducibility
• For Example: vocabulary files
for NLP models,
requirements.txt and other
extra files for torchserve
deployment](https://crownmelresort.com/image.slidesharecdn.com/reproducibleai-april2021final-210427175333/75/Reproducible-AI-using-MLflow-and-PyTorch-10-2048.jpg)


![PyTorch + MLflow
# deploy model
mlflow deployments create --name mnist_test --target torchserve ——
model-uri mnist.pt -C "MODEL_FILE=mnist_model.py" -C
"HANDLER=mnist_handler.py"
# do prediction
mlflow deployments predict --name mnist_test --target torchserve --
input_path sample.json --output_path output.json
D E P L O Y M E N T P L U G I N
New TorchServe Deployment Plugin
Test models during development cycle, pull
models from MLflow Model repository and run
• CLI
• Run with Local vs remote TorchServe
• Python API
import os
import matplotlib.pyplot as plt
from torchvision import transforms
from mlflow.deployments import get_deploy_client
img = plt.imread(os.path.join(os.getcwd(), "test_data/one.png"))
mnist_transforms = transforms.Compose([
transforms.ToTensor()
])
image = mnist_transforms(img)
plugin = get_deploy_client("torchserve")
config = {
'MODEL_FILE': "mnist_model.py",
'HANDLER_FILE': 'mnist_handler.py'
}
plugin.create_deployment(name="mnist_test", model_uri="mnist_cnn.pt",
config=config)
prediction = plugin.predict("mnist_test", image)](https://crownmelresort.com/image.slidesharecdn.com/reproducibleai-april2021final-210427175333/75/Reproducible-AI-using-MLflow-and-PyTorch-13-2048.jpg)


![NEW FEATURES
Integrations and new samples for:
- Model Interpretability using Captum
- Model Signature
- Hyper Parameter Optimization using Ax/Botorch
- Iterative Pruning Example using Ax/Botorch
#Captum
ig = IntegratedGradients(net)
test_input_tensor.requires_grad_()
attr, _ = ig.attribute(test_input_tensor, target=1,
return_convergence_delta=True)
attr = attr.detach().numpy()
# To understand attributions, average across all inputs, print
and visualize average attribution for each feature.
feature_imp, feature_imp_dict =
visualize_importances(feature_names, np.mean(attr, axis=0))
mlflow.log_metrics(feature_imp_dict)
mlflow.log_text(str(feature_imp), "feature_imp_summary.txt")
fig, (ax1, ax2) = plt.subplots(2, 1)
fig.tight_layout(pad=3)
ax1.hist(attr[:, 1], 100)
ax1.set(title="Distribution of Sibsp Attribution Values")
#Model Signature
from mlflow.models.signature import infer_signature
train = df.drop_column("target_label")
predictions = ... # compute model predictions
signature = infer_signature(train, predictions)](https://crownmelresort.com/image.slidesharecdn.com/reproducibleai-april2021final-210427175333/75/Reproducible-AI-using-MLflow-and-PyTorch-16-2048.jpg)

![NEW FEATURES - HPO WITH AX
with mlflow.start_run(run_name="Parent Run"):
train_evaluate(params=params, max_epochs=max_epochs)
ax_client = AxClient()
ax_client.create_experiment(
parameters=[
{"name": "weight_decay", "type": "range", "bounds": [1e-4, 1e-3]},
{"name": "momentum", "type": "range", "bounds": [0.7, 1.0]},
],
objective_name="test_accuracy",
)
for i in range(total_trials):
with mlflow.start_run(nested=True, run_name="Trial " + str(i)) as child_run:
parameters, trial_index = ax_client.get_next_trial()
test_accuracy = train_evaluate(params=parameters, max_epochs=max_epochs)
# completion of trial
ax_client.complete_trial(trial_index=trial_index,
raw_data=test_accuracy.item())
best_parameters, metrics = ax_client.get_best_parameters()
for param_name, value in best_parameters.items():
mlflow.log_param("optimum_" + param_name, value)](https://crownmelresort.com/image.slidesharecdn.com/reproducibleai-april2021final-210427175333/75/Reproducible-AI-using-MLflow-and-PyTorch-18-2048.jpg)






The document discusses the integration of PyTorch and MLflow for reproducible AI workflows, emphasizing their roles in experiment tracking, model deployment, and management of machine learning models. It presents the features of MLflow, such as model registration, autologging, and deployment with TorchServe, along with examples and best practices for setting up experiments. The content also highlights the importance of model interpretability and provides resources for further learning and implementation.
Introduction to the presentation by Geeta Chauhan on Reproducible AI using PyTorch and MLflow.
Discusses the challenges of reproducibility in ML, such as tracking experiments, model drift, and optimizing metrics.
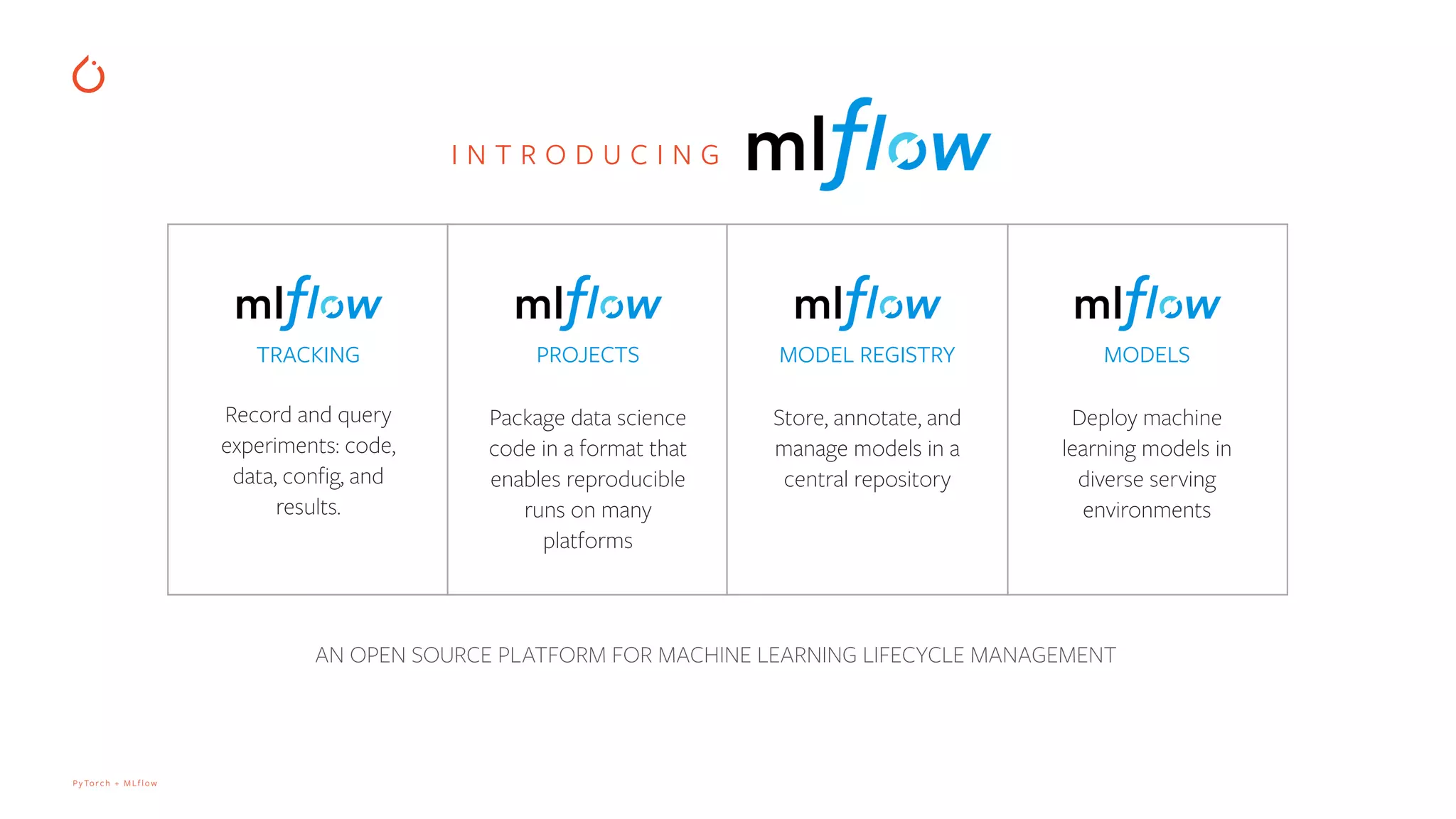
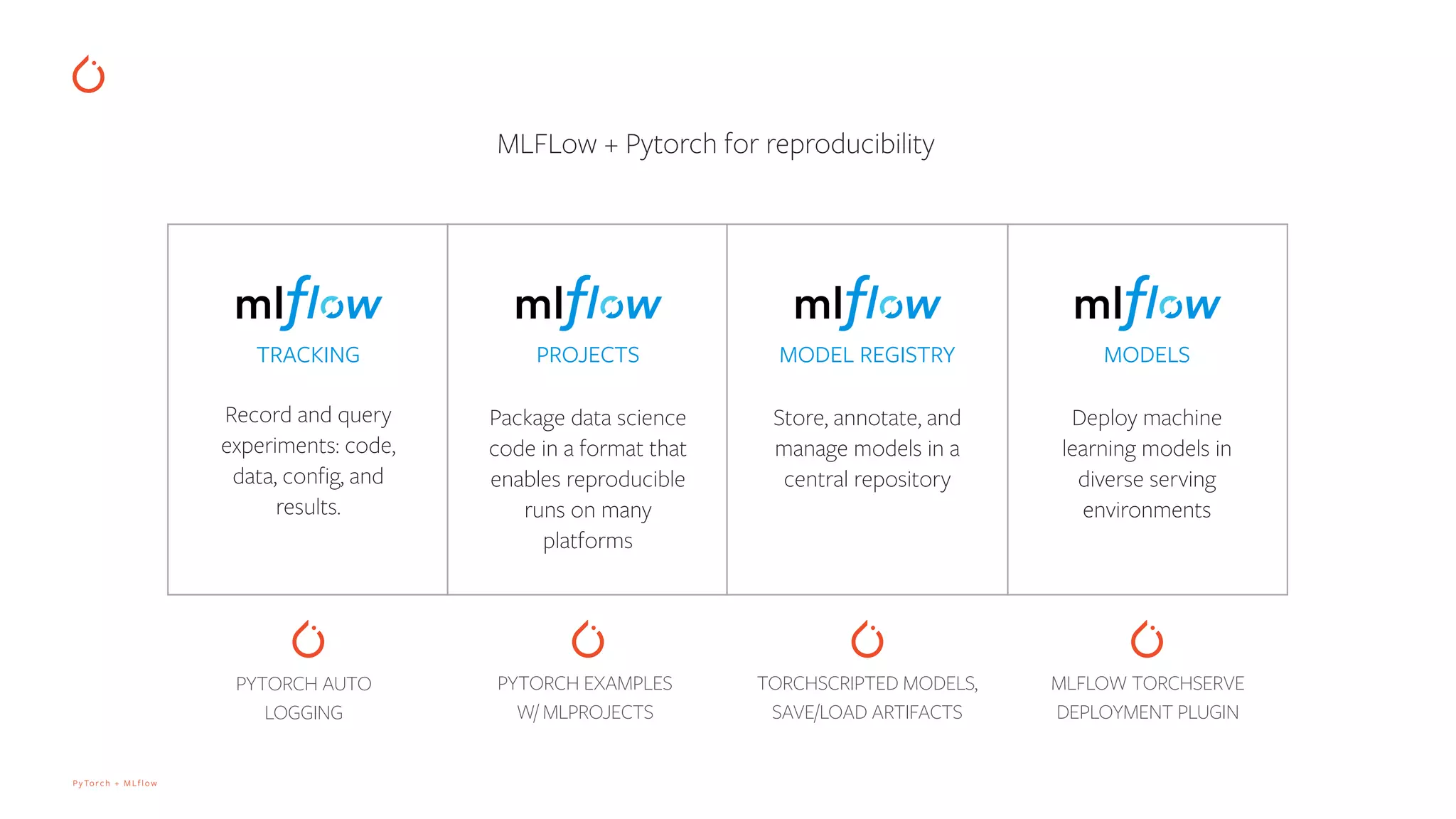
Introduction of MLflow as an open-source platform for managing the ML lifecycle, including experiment tracking, model registry, and reproducibility.
Features of PyTorch's autologging including logging model hyper-parameters and user-defined metrics during training.
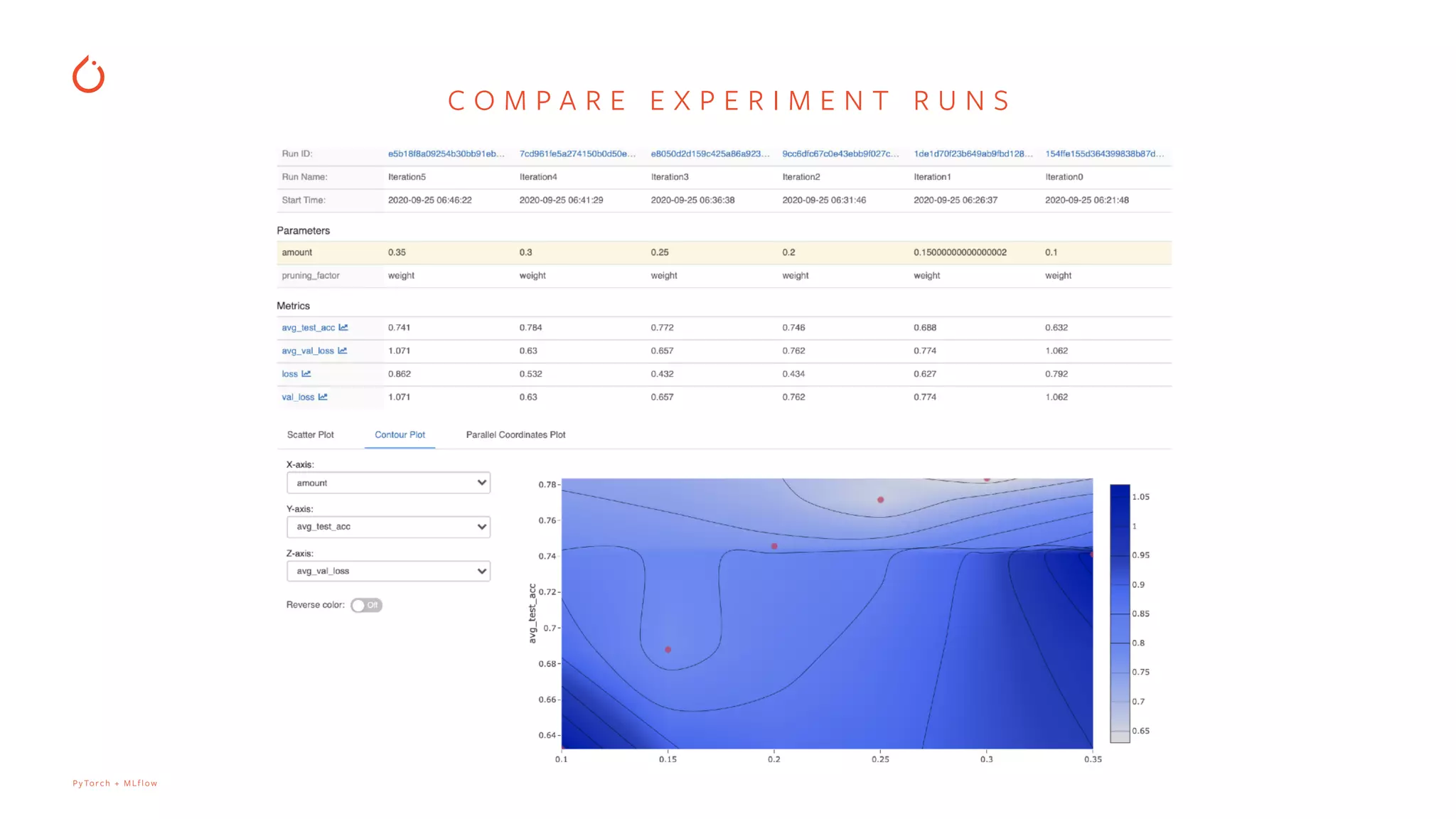
How to compare experiment runs and save artifacts such as model files and additional files for reproducibility.
Logging TorchScript models for optimized and serialized model inference in production environments.
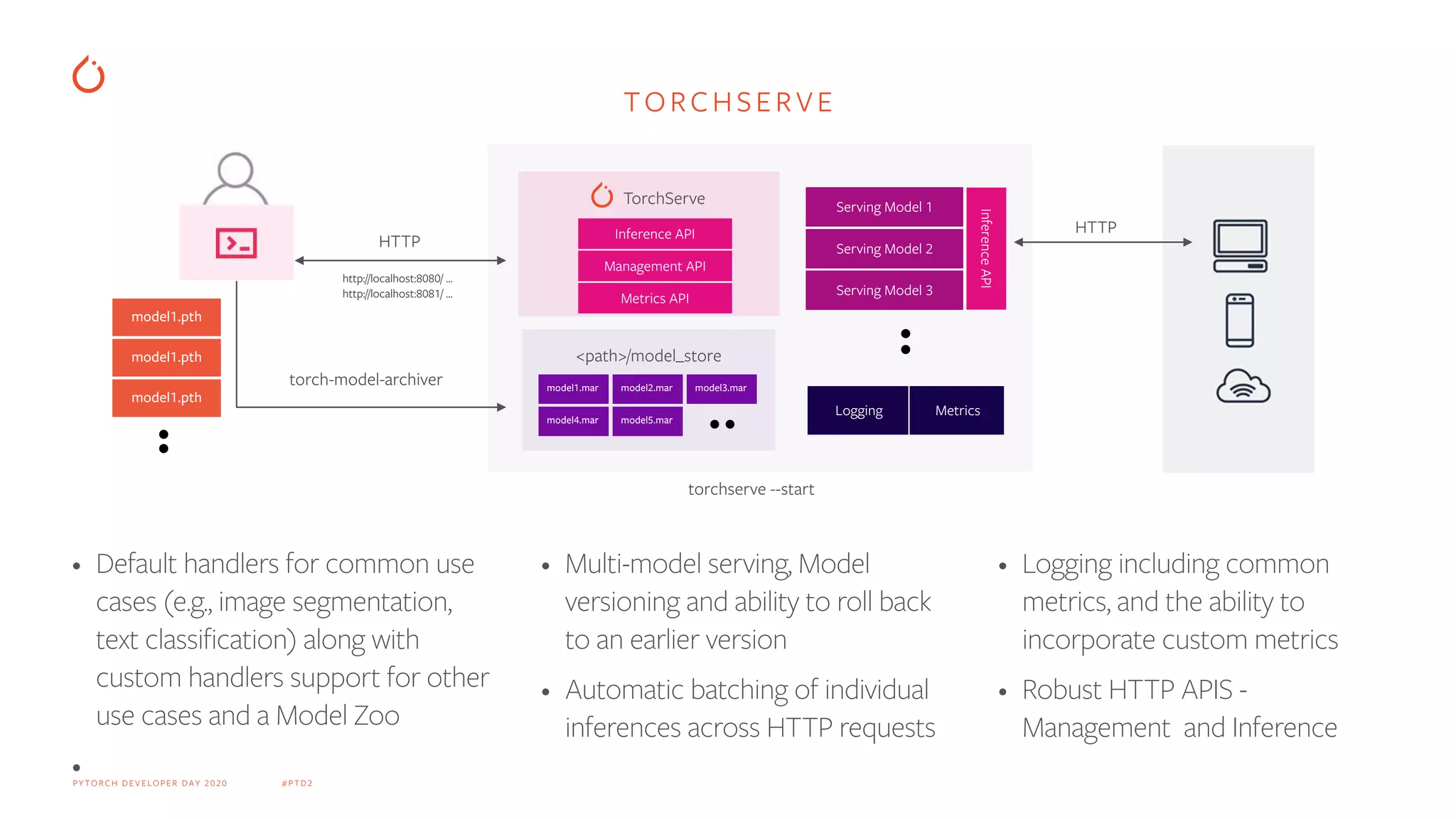
Deployment of models using TorchServe, including logging, versioning, and management via MLflow.
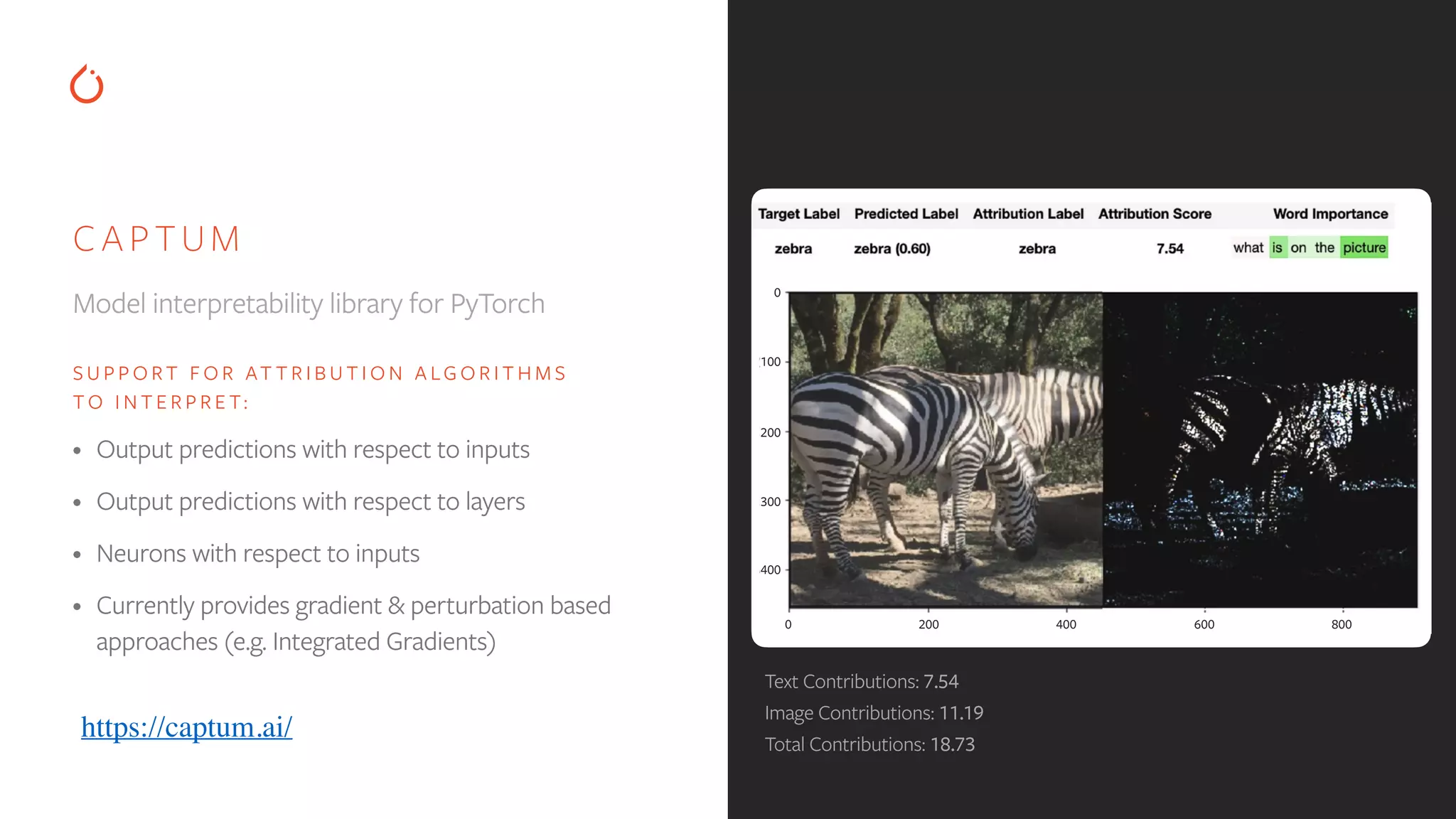
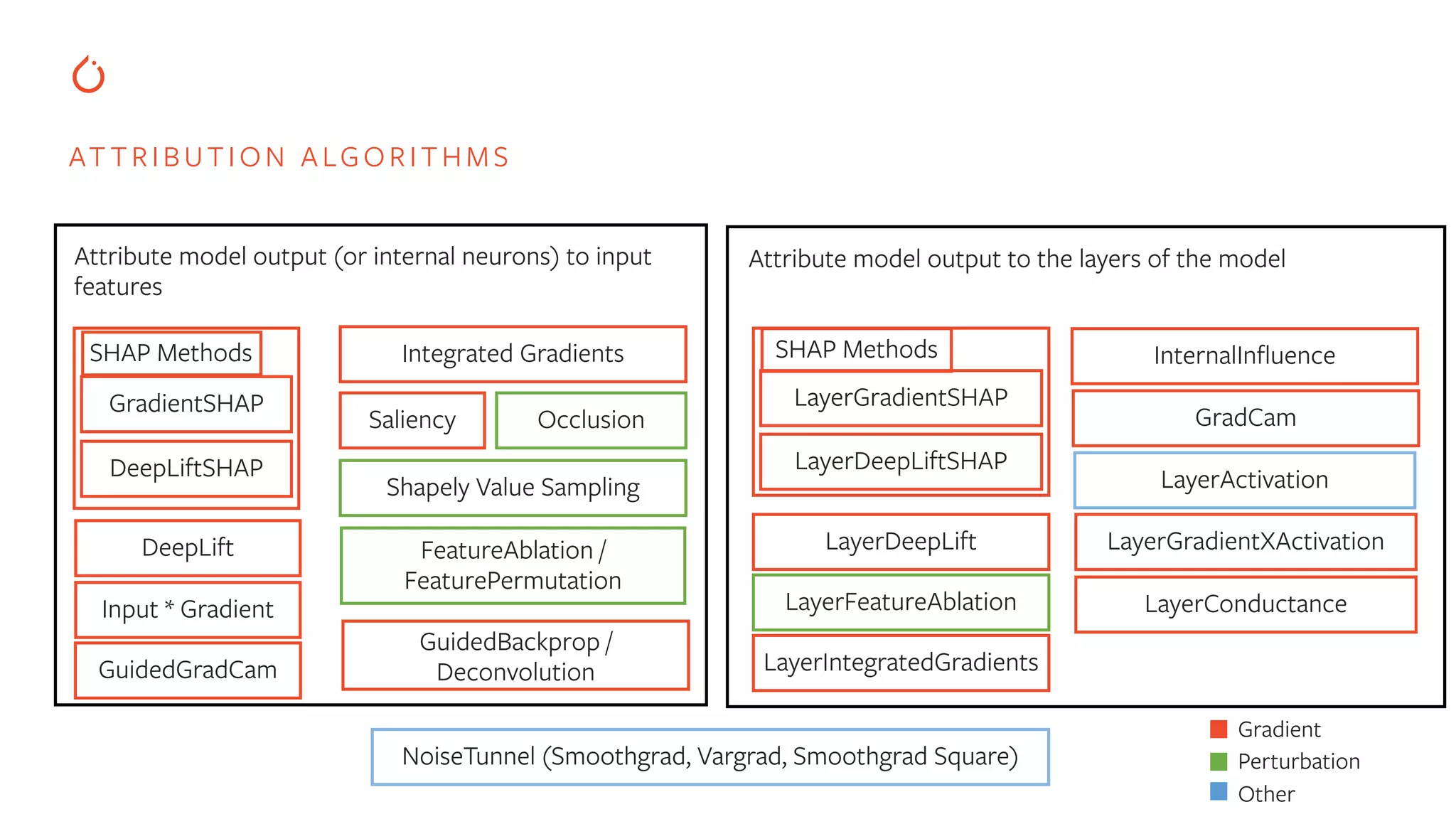
Support for Captum to interpret model predictions using various attribution algorithms for insights.
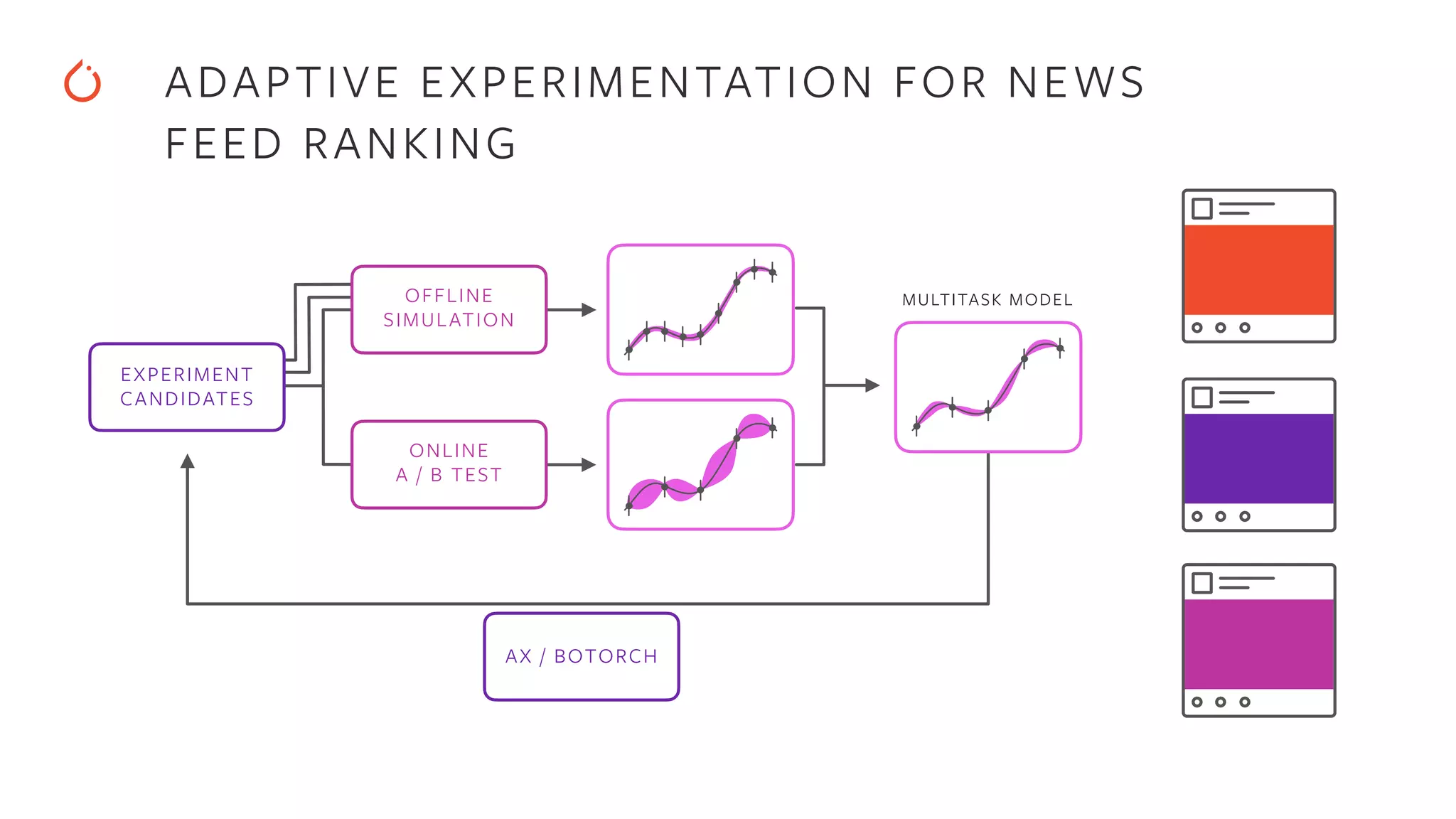
Overview of new features such as hyper-parameter optimization and adaptive experimentation capabilities.
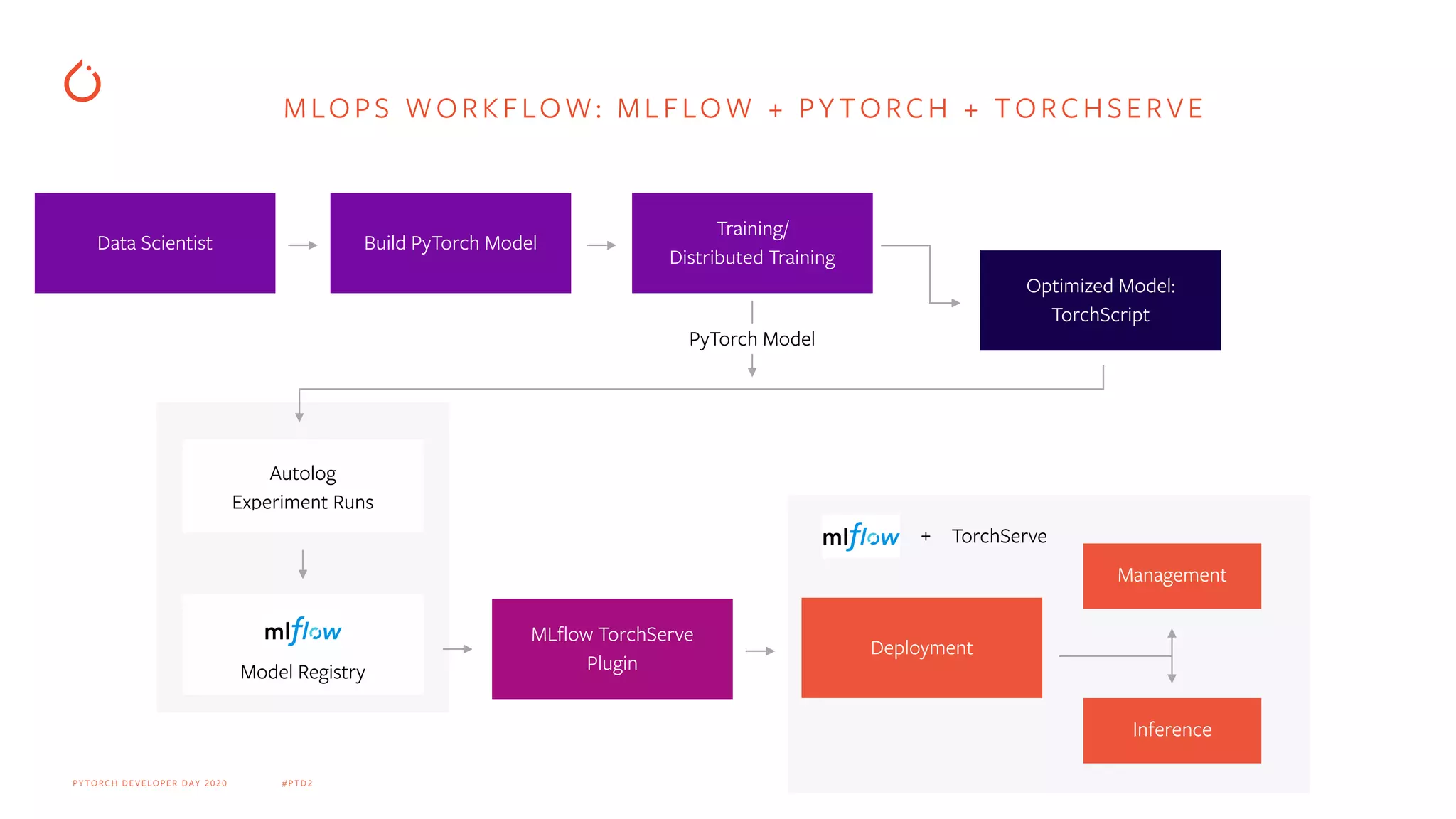
Diagrammatic workflow of MLOps integrating MLflow, PyTorch, and TorchServe along the deployment pipeline.
Plans for future enhancements including Captum insights and better integrations within MLflow.
Links to resources for reproducibility and MLflow with PyTorch, including contact information for the presenter.

![[Cloud OnAir] BigQuery の仕組みからベストプラクティスまでのご紹介 2018年9月6日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/dddddd-180906091548-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス](https://cdn.slidesharecdn.com/ss_thumbnails/amazonauroratips-170307140000-thumbnail.jpg?width=640&height=640&fit=bounds)

































































