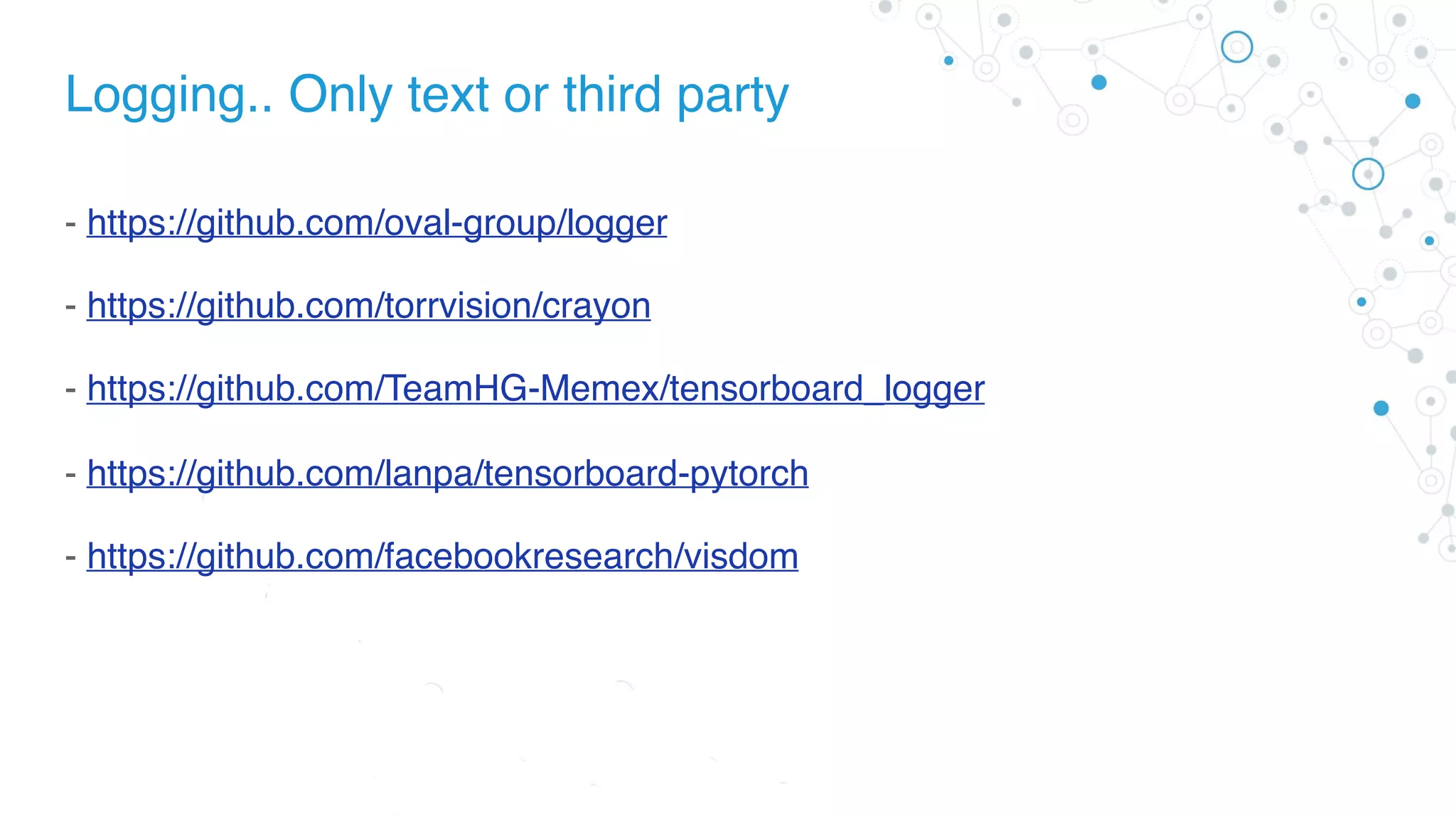
This document discusses the advantages of PyTorch compared to TensorFlow, emphasizing its ease of use, speed, and flexibility for both simple and custom model development. It includes code examples for tensor operations, backward propagation, and model training, highlighting the differences in control flow and variable management between PyTorch and TensorFlow. Additionally, it covers various aspects of model training, including weight initialization, GPU support, and data loading, culminating in a final architecture overview for a training workflow.



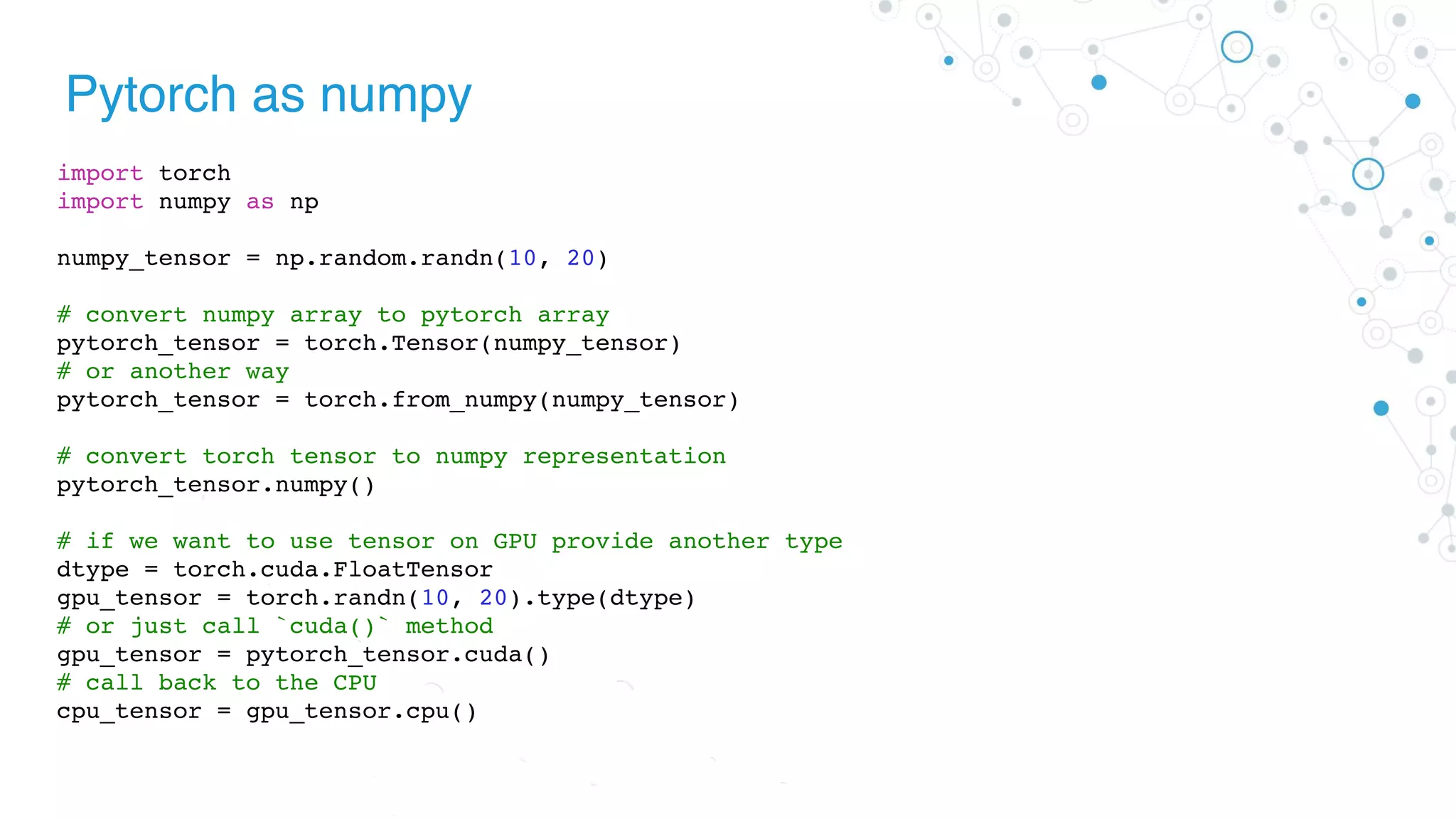
![Pytorch as numpy
import torch
# define pytorch tensors
x = torch.randn(10, 20)
y = torch.ones(20, 5)
# `@` mean matrix multiplication from python3.5, PEP-0465
res = x @ y
# get the shape
res.shape # torch.Size([10, 5])
# in place operations
x.add_(torch.ones(10, 20))
# get the mean and std
x.mean(dim=0)
x.std(dim=1)
# reshaping
x = x.view(3, -1)](https://image.slidesharecdn.com/01-diveintopytorchpdf-180905223551/75/Dive-Into-PyTorch-5-2048.jpg)


![Simple layer with optimizer and loss
import torch
from torch.autograd import Variable
import torch.nn.functional as F
x = Variable(torch.randn(10, 20), requires_grad=False)
y = Variable(torch.randn(10, 3), requires_grad=False)
# define some weights
w1 = Variable(torch.randn(20, 5), requires_grad=True)
w2 = Variable(torch.randn(5, 3), requires_grad=True)
learning_rate = 0.1
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.SGD([w1, w2], lr=learning_rate)
for step in range(5):
pred = F.sigmoid(x @ w1)
pred = F.sigmoid(pred @ w2)
loss = loss_fn(pred, y)
# you still should manually zero all previous gradients
optimizer.zero_grad()
loss.backward()
optimizer.step()](https://image.slidesharecdn.com/01-diveintopytorchpdf-180905223551/75/Dive-Into-PyTorch-9-2048.jpg)
![Tensorflow static graphs
# placeholders should be defined prior graph
x = tf.placeholder(tf.float32, shape=(None, 20))
y = tf.placeholder(tf.float32, shape=(None, 3))
w1 = tf.Variable(tf.random_normal((20, 5)))
w2 = tf.Variable(tf.random_normal((5, 3)))
pred = tf.sigmoid(x @ w1)
pred = tf.sigmoid(pred @ w2)
loss = tf.reduce_sum((y - pred) ** 2)
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1)
minimization = optimizer.minimize(loss)
with tf.Session() as sess:
# Run the graph once to initialize the Variables w1 and w2.
sess.run(tf.global_variables_initializer())
x_value = np.random.randn(10, 20)
y_value = np.random.randn(10, 3)
for step in range(5):
loss_value, _ = sess.run([loss, minimization],
feed_dict={x: x_value, y: y_value})](https://image.slidesharecdn.com/01-diveintopytorchpdf-180905223551/75/Dive-Into-PyTorch-10-2048.jpg)
![Tensorflow control flow
first_counter = tf.constant(0)
second_counter = tf.constant(10)
some_value = tf.Variable(15)
# condition should handle all args:
def cond(first_counter, second_counter):
return first_counter < second_counter
def body(first_counter, second_counter, some_value):
first_counter = tf.add(first_counter, 2)
second_counter = tf.add(second_counter, 1)
some_value = tf.add(some_value, second_counter)
return first_counter, second_counter, some_value
c1, c2, val = tf.while_loop(
cond, body, [first_counter, second_counter, some_value])
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
counter_1_res, counter_2_res = sess.run([c1, c2])](https://image.slidesharecdn.com/01-diveintopytorchpdf-180905223551/75/Dive-Into-PyTorch-11-2048.jpg)
![Pytorch control flow
import torch
first_counter = torch.Tensor([0])
second_counter = torch.Tensor([10])
some_value = torch.Tensor(15)
while (first_counter < second_counter)[0]:
first_counter += 2
second_counter += 1
some_value += second_counter](https://image.slidesharecdn.com/01-diveintopytorchpdf-180905223551/75/Dive-Into-PyTorch-12-2048.jpg)

![Sequential models definition
from collections import OrderedDict
import torch.nn as nn
# Example of using Sequential
model = nn.Sequential(
nn.Conv2d(1, 20, 5),
nn.ReLU(),
nn.Conv2d(20, 64, 5),
nn.ReLU()
)
# Example of using Sequential with OrderedDict
model = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1, 20, 5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20, 64, 5)),
('relu2', nn.ReLU())
]))
output = model(some_input)](https://image.slidesharecdn.com/01-diveintopytorchpdf-180905223551/75/Dive-Into-PyTorch-14-2048.jpg)


![Self defined layers(old style)
class MyFunction(torch.autograd.Function):
def forward(self, input):
self.save_for_backward(input)
output = torch.sign(input)
return output
def backward(self, grad_output):
input, = self.saved_tensors
grad_output[input.ge(1)] = 0
grad_output[input.le(-1)] = 0
return grad_output
# usage
x = torch.randn(10, 20)
y = MyFunction()(x)
# and if we want to use inside nn.Module
class MyFunctionModule(torch.nn.Module):
def forward(self, x):
return MyFunction()(x)](https://image.slidesharecdn.com/01-diveintopytorchpdf-180905223551/75/Dive-Into-PyTorch-18-2048.jpg)
![Self defined layers(new style)
class MyFunction(torch.autograd.Function):
@staticmethod
def forward(ctx, input):
ctx.save_for_backward(input)
output = torch.sign(input)
return output
@staticmethod
def backward(ctx, grad_output):
# saved tensors - tuple of tensors, so we need get first
input, = ctx.saved_variables
grad_output[input.ge(1)] = 0
grad_output[input.le(-1)] = 0
return grad_output
x = torch.randn(10, 20)
y = MyFunction.apply(x)
my_func = MyFunction.apply
y = my_func(x)
class MyFunctionModule(torch.nn.Module):
def forward(self, x):
return MyFunction.apply(x)](https://image.slidesharecdn.com/01-diveintopytorchpdf-180905223551/75/Dive-Into-PyTorch-19-2048.jpg)


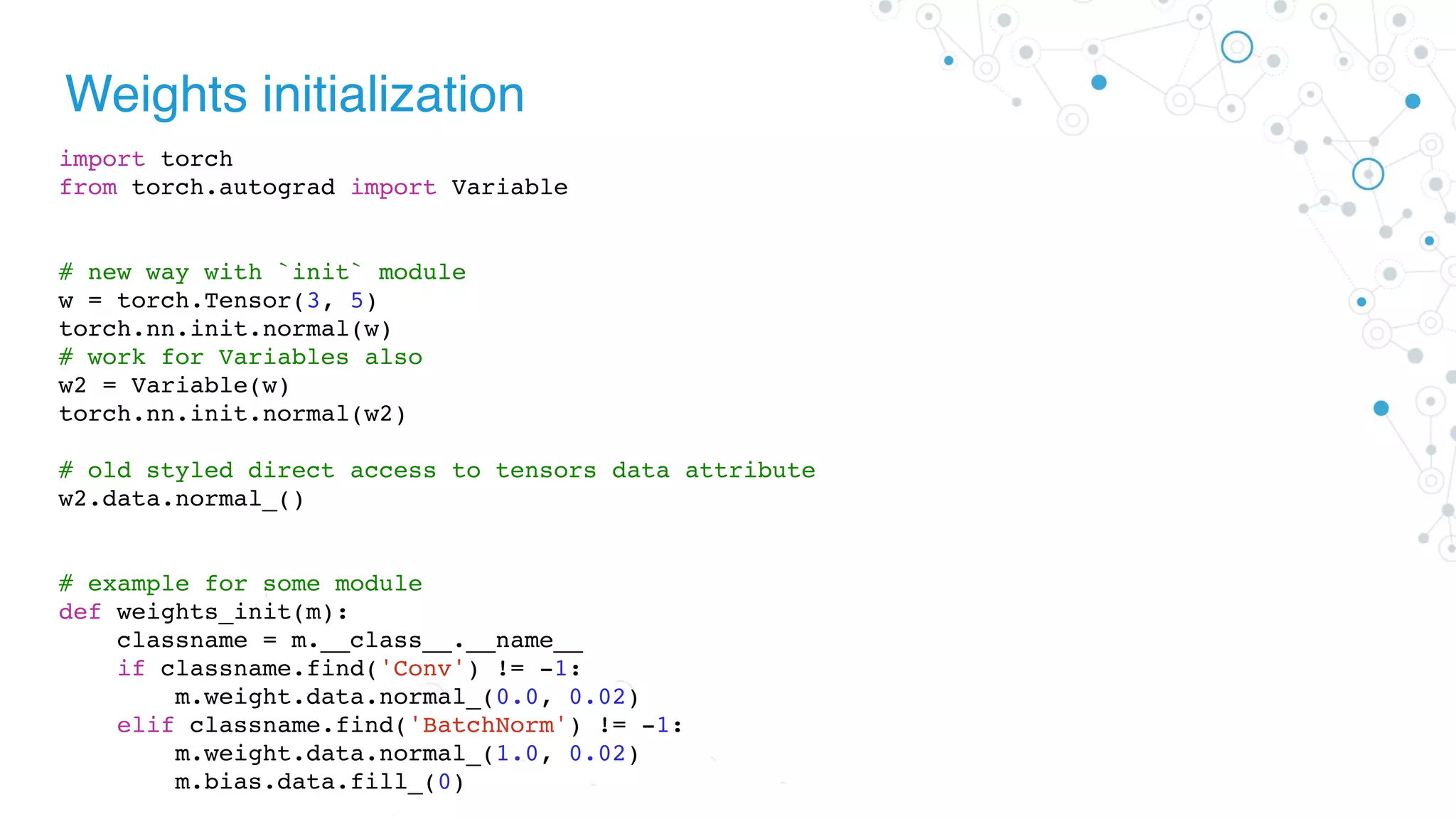
![Weights initialization
import math
from torch import nn
# for loop approach with direct access
class MyModel(nn.Module):
def __init__(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
m.bias.data.zero_()](https://image.slidesharecdn.com/01-diveintopytorchpdf-180905223551/75/Dive-Into-PyTorch-24-2048.jpg)





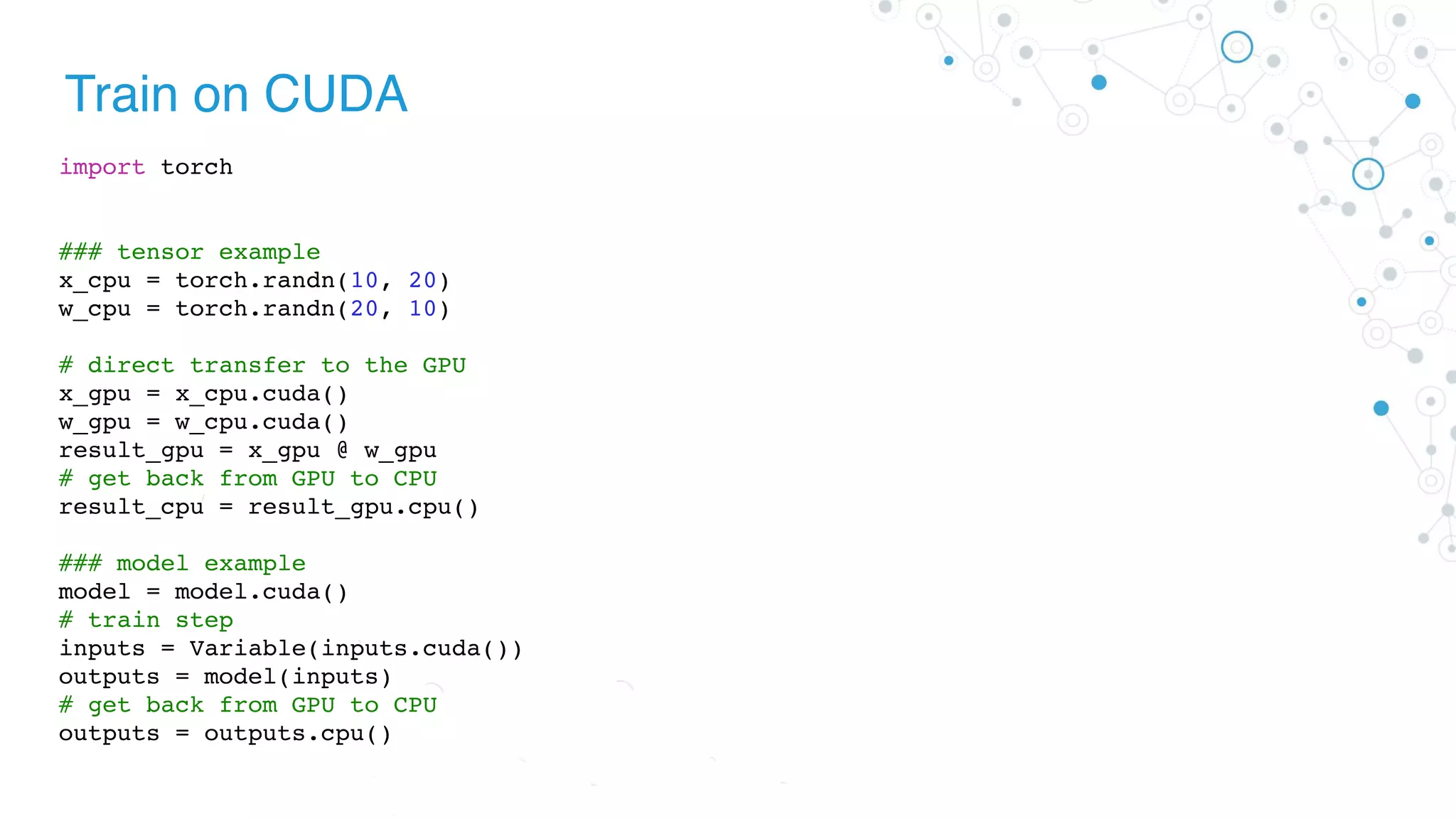
![Pytorch data loader(definition)
import torchvision as tv
class ImagesDataset(torch.utils.data.Dataset):
def __init__(self, df, transform=None,
loader=tv.datasets.folder.default_loader):
self.df = df
self.transform = transform
self.loader = loader
def __getitem__(self, index):
row = self.df.iloc[index]
target = row['class_']
path = row['path']
img = self.loader(path)
if self.transform is not None:
img = self.transform(img)
return img, target
def __len__(self):
n, _ = self.df.shape
return n](https://image.slidesharecdn.com/01-diveintopytorchpdf-180905223551/75/Dive-Into-PyTorch-33-2048.jpg)
![Pytorch data loader(usage)
import torchvision as tv
data_transforms = tv.transforms.Compose([
tv.transforms.RandomCrop((64, 64), padding=4),
tv.transforms.RandomHorizontalFlip(),
tv.transforms.ToTensor(),
])
train_df = pd.read_csv('path/to/some.csv')
train_dataset = ImagesDataset(
df=train_df,
transform=data_transforms
)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=10, shuffle=True,
num_workers=16)
# fetch the batch, same as `__getitem__` method
# NOTE: images dimensions in another order than tensorflow
for img, target in train_loader:
pass](https://image.slidesharecdn.com/01-diveintopytorchpdf-180905223551/75/Dive-Into-PyTorch-34-2048.jpg)








![Pytorch as numpy
import torch
# define pytorch tensors
x = torch.randn(10, 20)
y = torch.ones(20, 5)
# `@` mean matrix multiplication from python3.5, PEP-0465
res = x @ y
# get the shape
res.shape # torch.Size([10, 5])
# in place operations
x.add_(torch.ones(10, 20))
# get the mean and std
x.mean(dim=0)
x.std(dim=1)
# reshaping
x = x.view(3, -1)](https://crownmelresort.com/image.slidesharecdn.com/01-diveintopytorchpdf-180905223551/75/Dive-Into-PyTorch-5-2048.jpg)



![Simple layer with optimizer and loss
import torch
from torch.autograd import Variable
import torch.nn.functional as F
x = Variable(torch.randn(10, 20), requires_grad=False)
y = Variable(torch.randn(10, 3), requires_grad=False)
# define some weights
w1 = Variable(torch.randn(20, 5), requires_grad=True)
w2 = Variable(torch.randn(5, 3), requires_grad=True)
learning_rate = 0.1
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.SGD([w1, w2], lr=learning_rate)
for step in range(5):
pred = F.sigmoid(x @ w1)
pred = F.sigmoid(pred @ w2)
loss = loss_fn(pred, y)
# you still should manually zero all previous gradients
optimizer.zero_grad()
loss.backward()
optimizer.step()](https://crownmelresort.com/image.slidesharecdn.com/01-diveintopytorchpdf-180905223551/75/Dive-Into-PyTorch-9-2048.jpg)
![Tensorflow static graphs
# placeholders should be defined prior graph
x = tf.placeholder(tf.float32, shape=(None, 20))
y = tf.placeholder(tf.float32, shape=(None, 3))
w1 = tf.Variable(tf.random_normal((20, 5)))
w2 = tf.Variable(tf.random_normal((5, 3)))
pred = tf.sigmoid(x @ w1)
pred = tf.sigmoid(pred @ w2)
loss = tf.reduce_sum((y - pred) ** 2)
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1)
minimization = optimizer.minimize(loss)
with tf.Session() as sess:
# Run the graph once to initialize the Variables w1 and w2.
sess.run(tf.global_variables_initializer())
x_value = np.random.randn(10, 20)
y_value = np.random.randn(10, 3)
for step in range(5):
loss_value, _ = sess.run([loss, minimization],
feed_dict={x: x_value, y: y_value})](https://crownmelresort.com/image.slidesharecdn.com/01-diveintopytorchpdf-180905223551/75/Dive-Into-PyTorch-10-2048.jpg)
![Tensorflow control flow
first_counter = tf.constant(0)
second_counter = tf.constant(10)
some_value = tf.Variable(15)
# condition should handle all args:
def cond(first_counter, second_counter):
return first_counter < second_counter
def body(first_counter, second_counter, some_value):
first_counter = tf.add(first_counter, 2)
second_counter = tf.add(second_counter, 1)
some_value = tf.add(some_value, second_counter)
return first_counter, second_counter, some_value
c1, c2, val = tf.while_loop(
cond, body, [first_counter, second_counter, some_value])
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
counter_1_res, counter_2_res = sess.run([c1, c2])](https://crownmelresort.com/image.slidesharecdn.com/01-diveintopytorchpdf-180905223551/75/Dive-Into-PyTorch-11-2048.jpg)
![Pytorch control flow
import torch
first_counter = torch.Tensor([0])
second_counter = torch.Tensor([10])
some_value = torch.Tensor(15)
while (first_counter < second_counter)[0]:
first_counter += 2
second_counter += 1
some_value += second_counter](https://crownmelresort.com/image.slidesharecdn.com/01-diveintopytorchpdf-180905223551/75/Dive-Into-PyTorch-12-2048.jpg)

![Sequential models definition
from collections import OrderedDict
import torch.nn as nn
# Example of using Sequential
model = nn.Sequential(
nn.Conv2d(1, 20, 5),
nn.ReLU(),
nn.Conv2d(20, 64, 5),
nn.ReLU()
)
# Example of using Sequential with OrderedDict
model = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1, 20, 5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20, 64, 5)),
('relu2', nn.ReLU())
]))
output = model(some_input)](https://crownmelresort.com/image.slidesharecdn.com/01-diveintopytorchpdf-180905223551/75/Dive-Into-PyTorch-14-2048.jpg)



![Self defined layers(old style)
class MyFunction(torch.autograd.Function):
def forward(self, input):
self.save_for_backward(input)
output = torch.sign(input)
return output
def backward(self, grad_output):
input, = self.saved_tensors
grad_output[input.ge(1)] = 0
grad_output[input.le(-1)] = 0
return grad_output
# usage
x = torch.randn(10, 20)
y = MyFunction()(x)
# and if we want to use inside nn.Module
class MyFunctionModule(torch.nn.Module):
def forward(self, x):
return MyFunction()(x)](https://crownmelresort.com/image.slidesharecdn.com/01-diveintopytorchpdf-180905223551/75/Dive-Into-PyTorch-18-2048.jpg)
![Self defined layers(new style)
class MyFunction(torch.autograd.Function):
@staticmethod
def forward(ctx, input):
ctx.save_for_backward(input)
output = torch.sign(input)
return output
@staticmethod
def backward(ctx, grad_output):
# saved tensors - tuple of tensors, so we need get first
input, = ctx.saved_variables
grad_output[input.ge(1)] = 0
grad_output[input.le(-1)] = 0
return grad_output
x = torch.randn(10, 20)
y = MyFunction.apply(x)
my_func = MyFunction.apply
y = my_func(x)
class MyFunctionModule(torch.nn.Module):
def forward(self, x):
return MyFunction.apply(x)](https://crownmelresort.com/image.slidesharecdn.com/01-diveintopytorchpdf-180905223551/75/Dive-Into-PyTorch-19-2048.jpg)




![Weights initialization
import math
from torch import nn
# for loop approach with direct access
class MyModel(nn.Module):
def __init__(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
m.bias.data.zero_()](https://crownmelresort.com/image.slidesharecdn.com/01-diveintopytorchpdf-180905223551/75/Dive-Into-PyTorch-24-2048.jpg)








![Pytorch data loader(definition)
import torchvision as tv
class ImagesDataset(torch.utils.data.Dataset):
def __init__(self, df, transform=None,
loader=tv.datasets.folder.default_loader):
self.df = df
self.transform = transform
self.loader = loader
def __getitem__(self, index):
row = self.df.iloc[index]
target = row['class_']
path = row['path']
img = self.loader(path)
if self.transform is not None:
img = self.transform(img)
return img, target
def __len__(self):
n, _ = self.df.shape
return n](https://crownmelresort.com/image.slidesharecdn.com/01-diveintopytorchpdf-180905223551/75/Dive-Into-PyTorch-33-2048.jpg)
![Pytorch data loader(usage)
import torchvision as tv
data_transforms = tv.transforms.Compose([
tv.transforms.RandomCrop((64, 64), padding=4),
tv.transforms.RandomHorizontalFlip(),
tv.transforms.ToTensor(),
])
train_df = pd.read_csv('path/to/some.csv')
train_dataset = ImagesDataset(
df=train_df,
transform=data_transforms
)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=10, shuffle=True,
num_workers=16)
# fetch the batch, same as `__getitem__` method
# NOTE: images dimensions in another order than tensorflow
for img, target in train_loader:
pass](https://crownmelresort.com/image.slidesharecdn.com/01-diveintopytorchpdf-180905223551/75/Dive-Into-PyTorch-34-2048.jpg)














































![[Update] PyTorch Tutorial for NTU Machine Learing Course 2017](https://cdn.slidesharecdn.com/ss_thumbnails/pytorchtutorial-2017-1103-171103060015-thumbnail.jpg?width=640&height=640&fit=bounds)


















![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)




