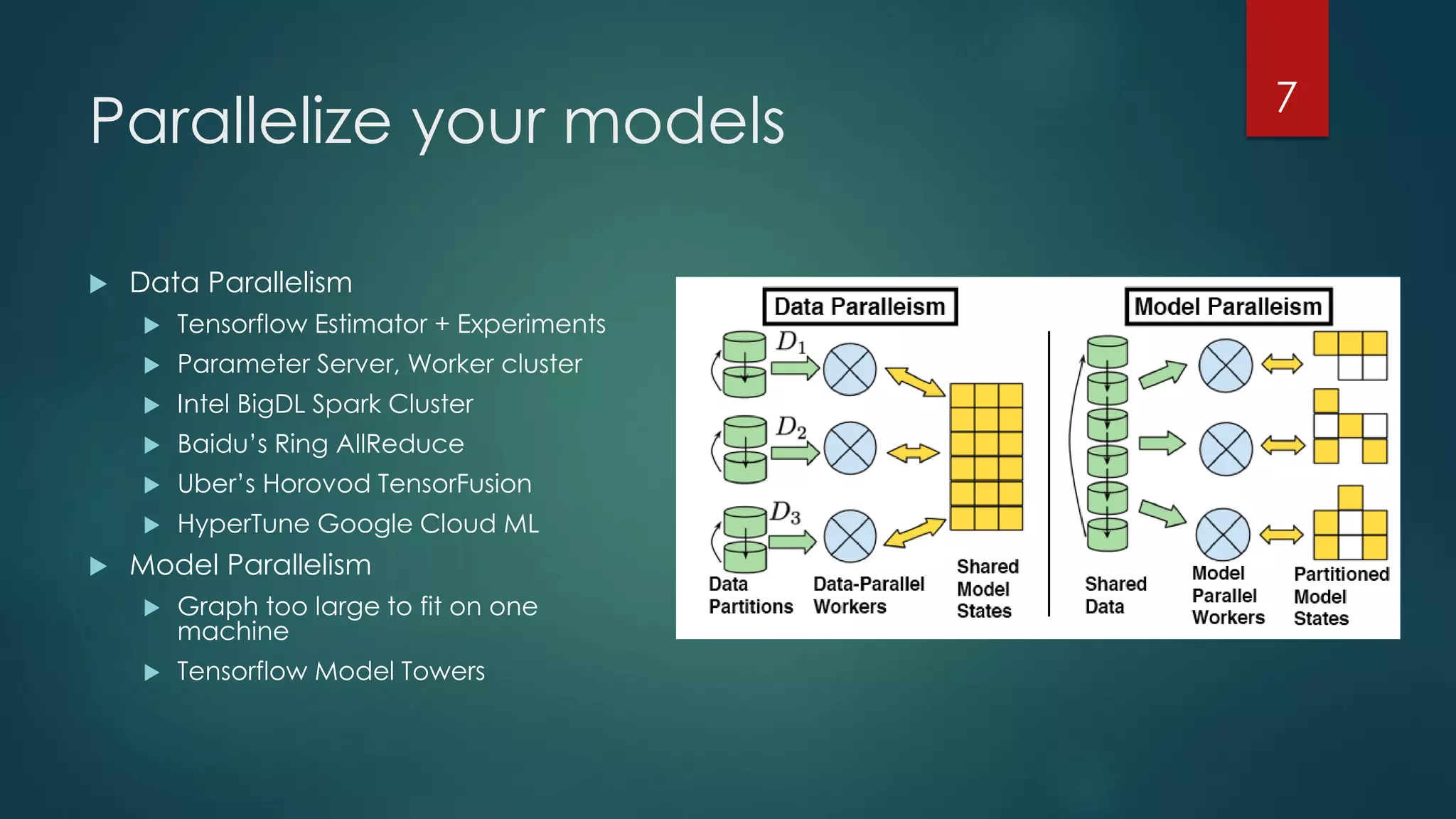
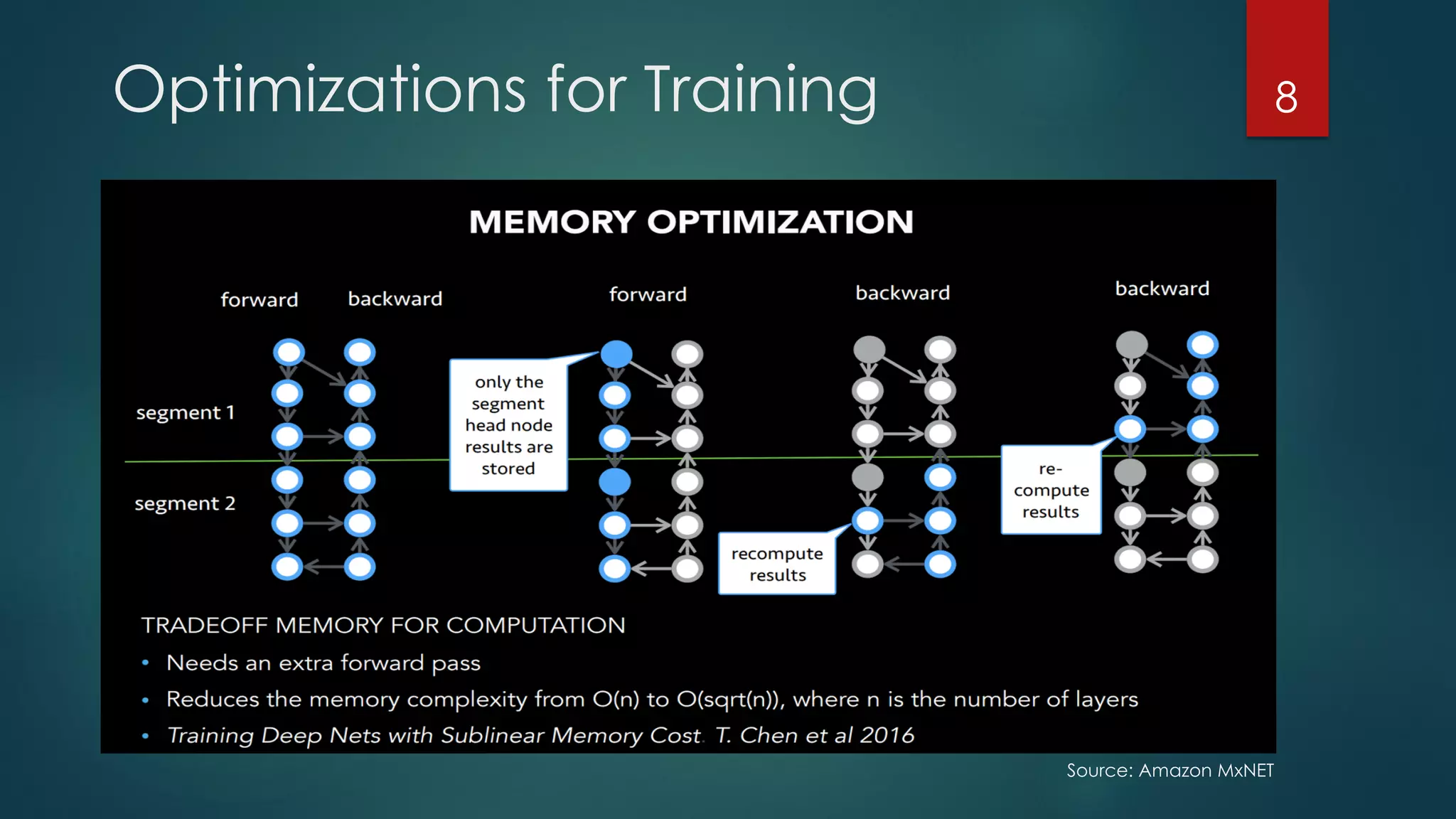
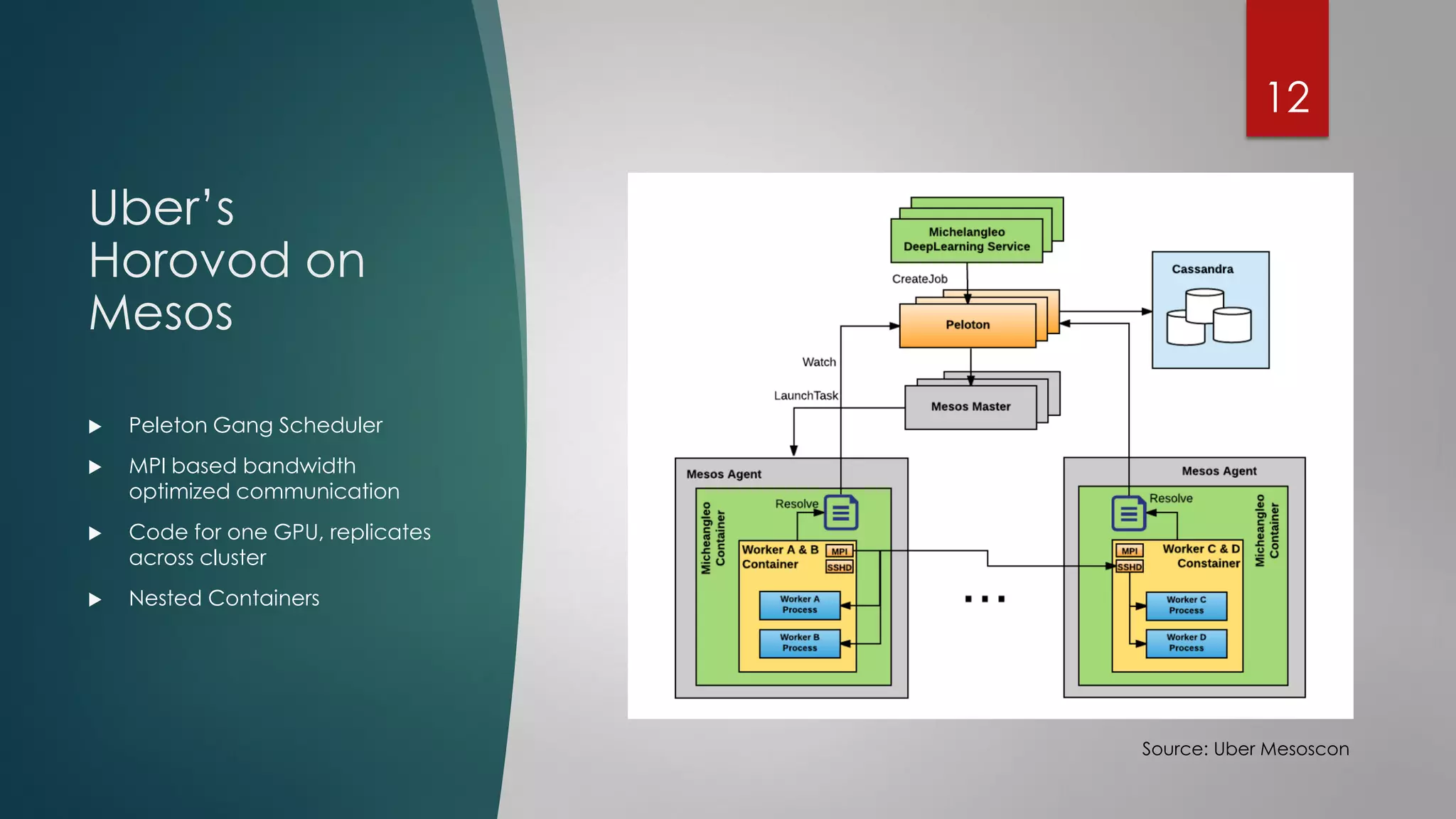
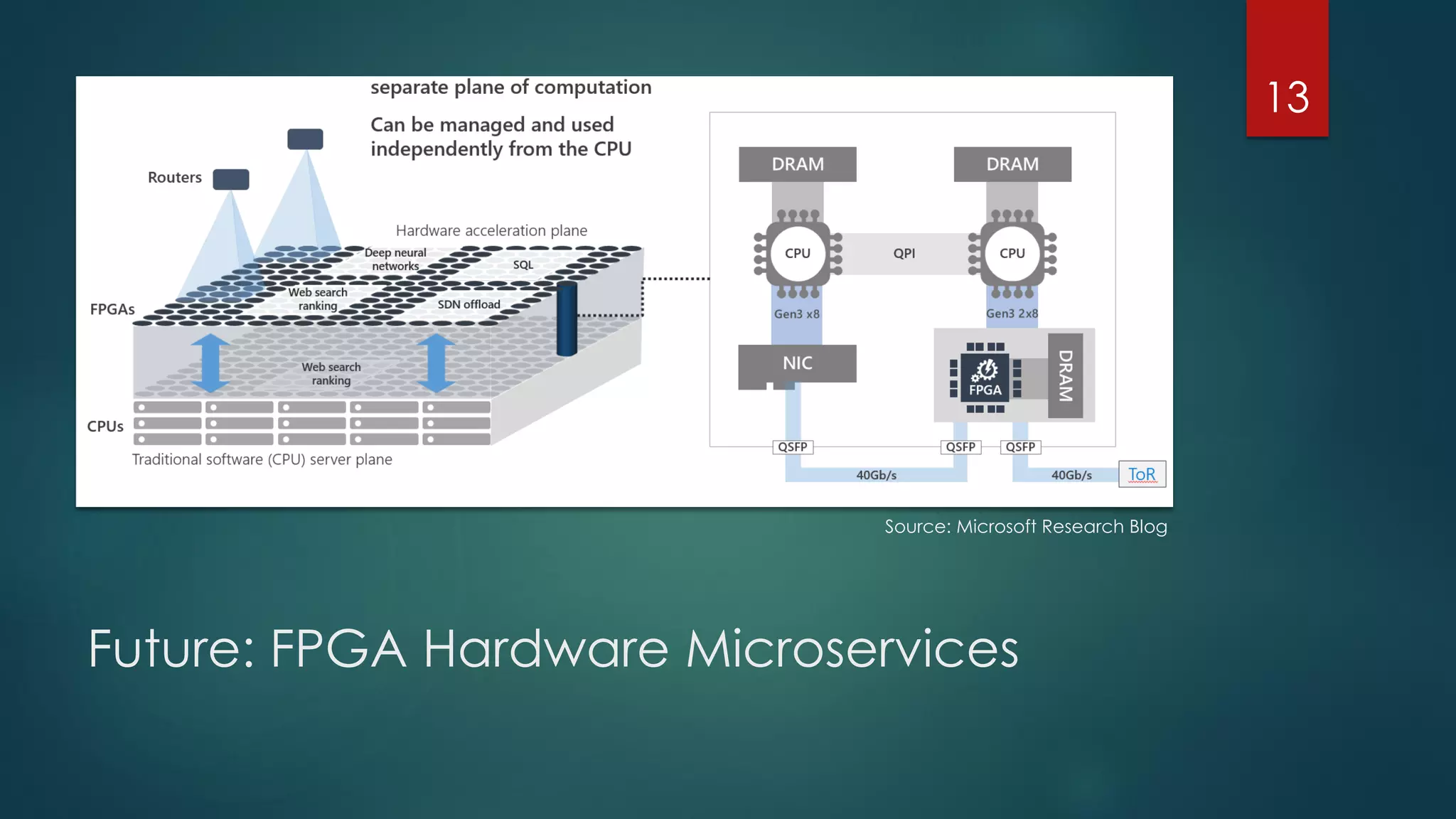
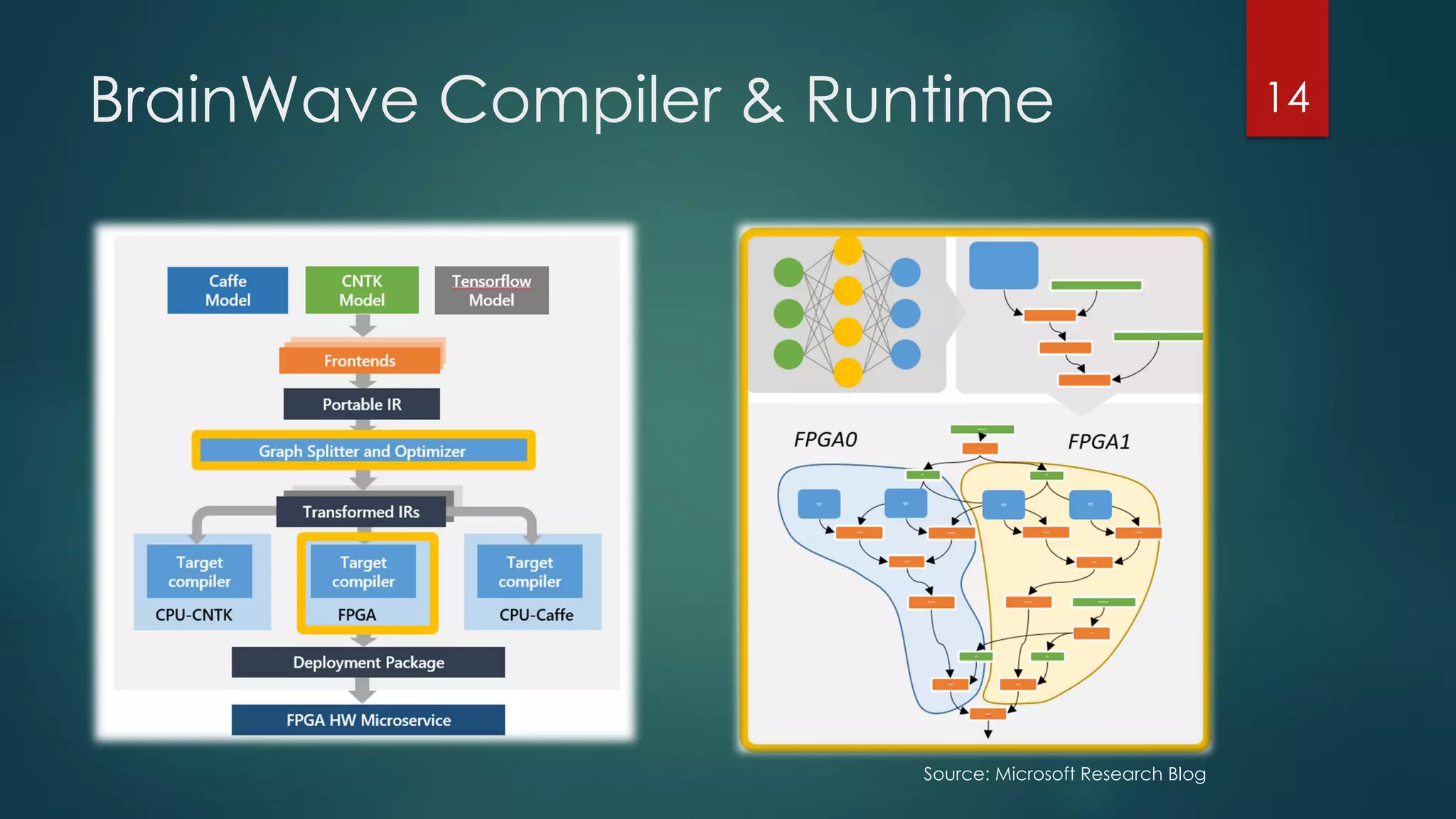
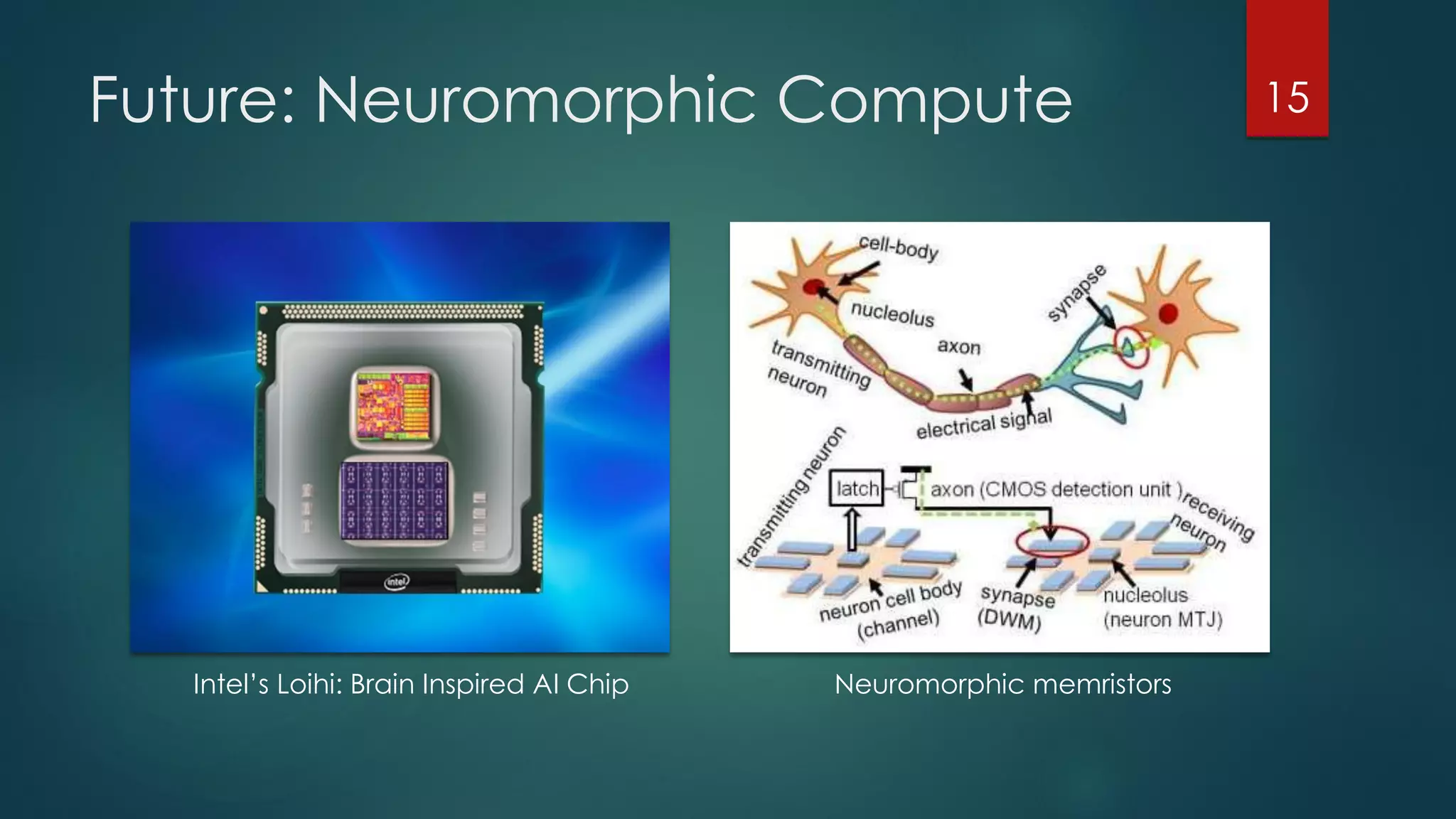
The document discusses advancements and challenges in distributed deep learning, focusing on optimizations for large-scale applications, hardware efficiency, and model parallelism. It highlights various specialized computing architectures, tools, and techniques for optimizing CPU and TensorFlow performance, as well as strategies for training and inference optimizations. The content also looks toward future computing paradigms including neuromorphic and quantum computing.