Downloaded 25 times




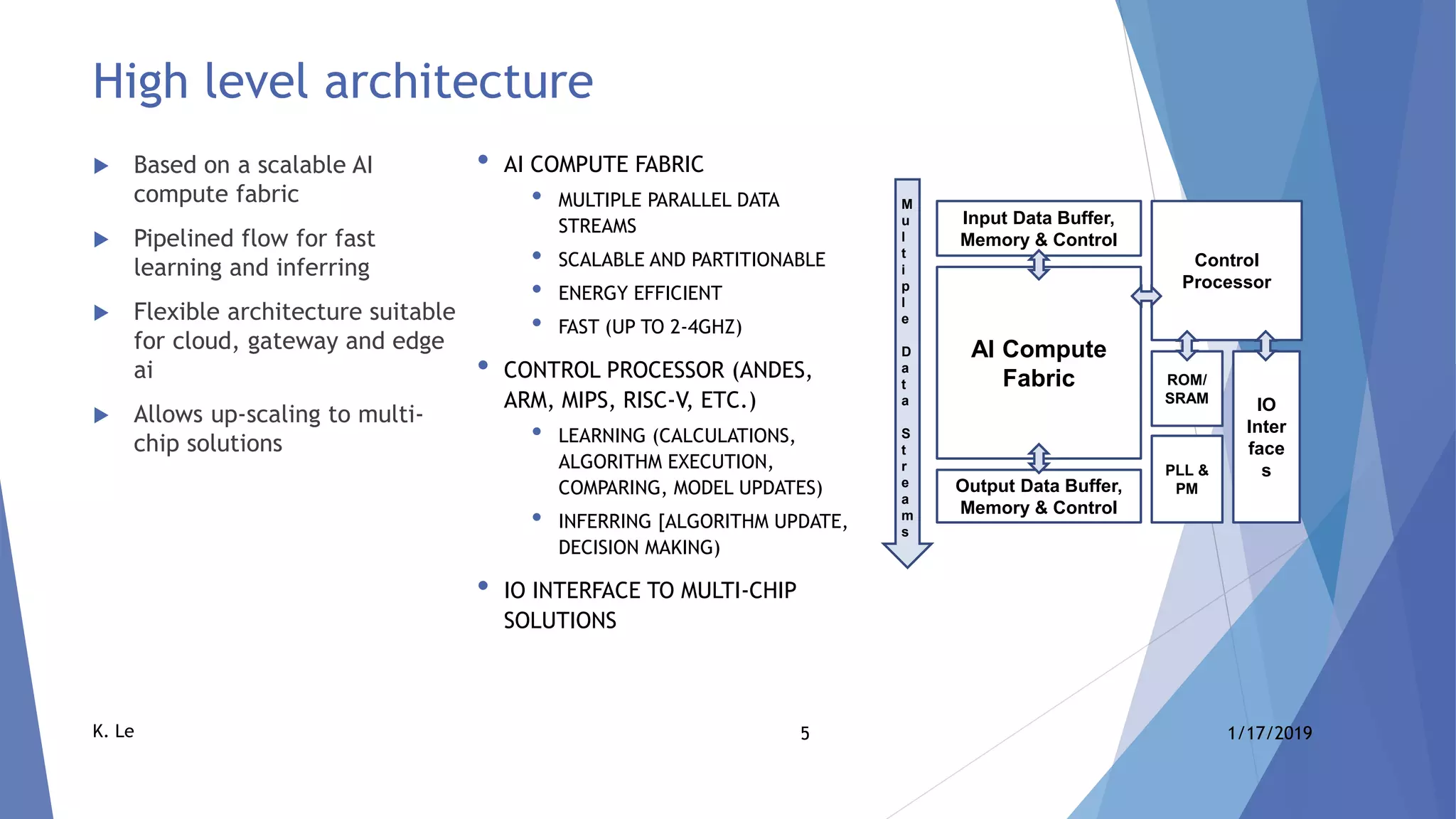
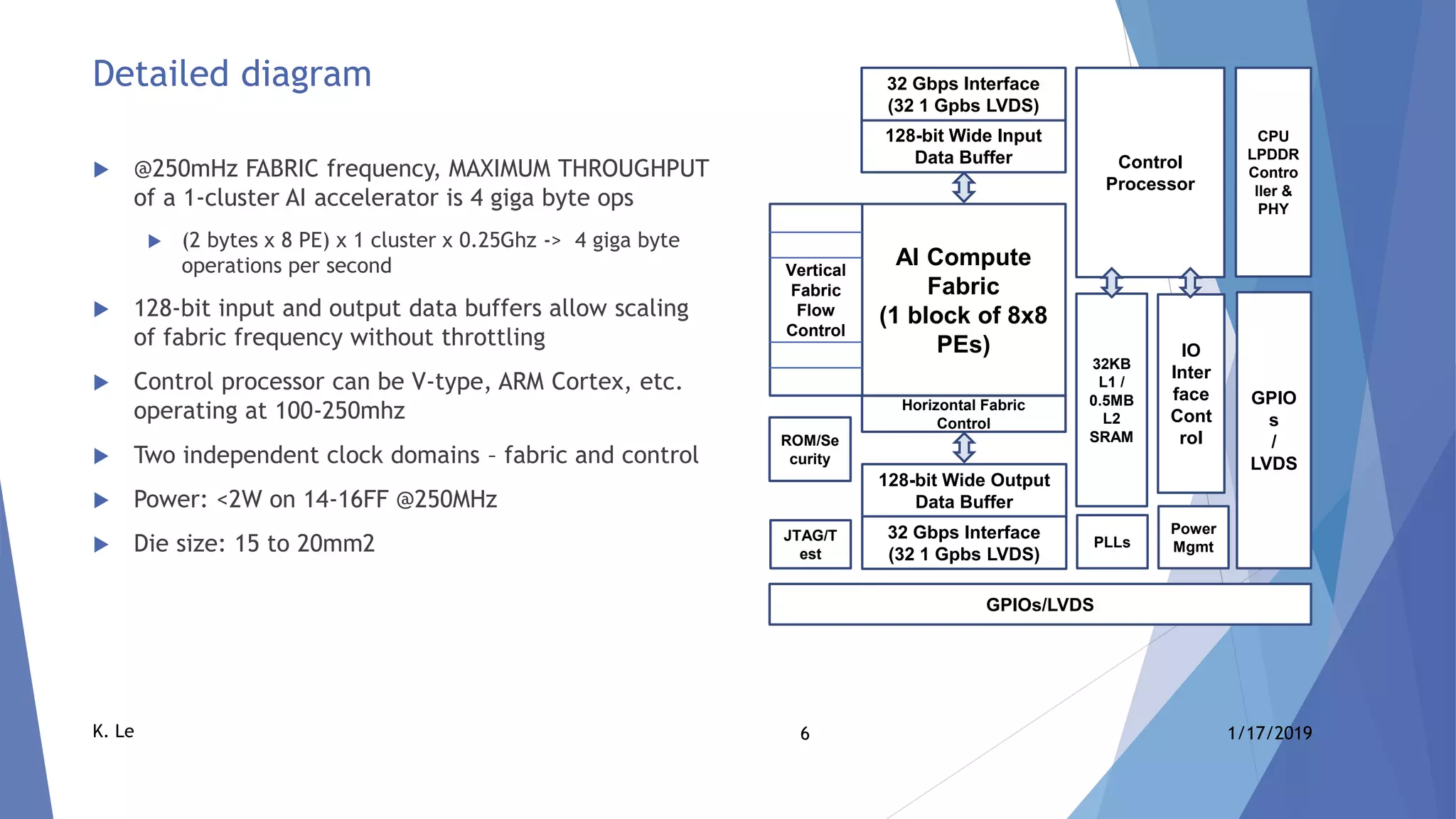
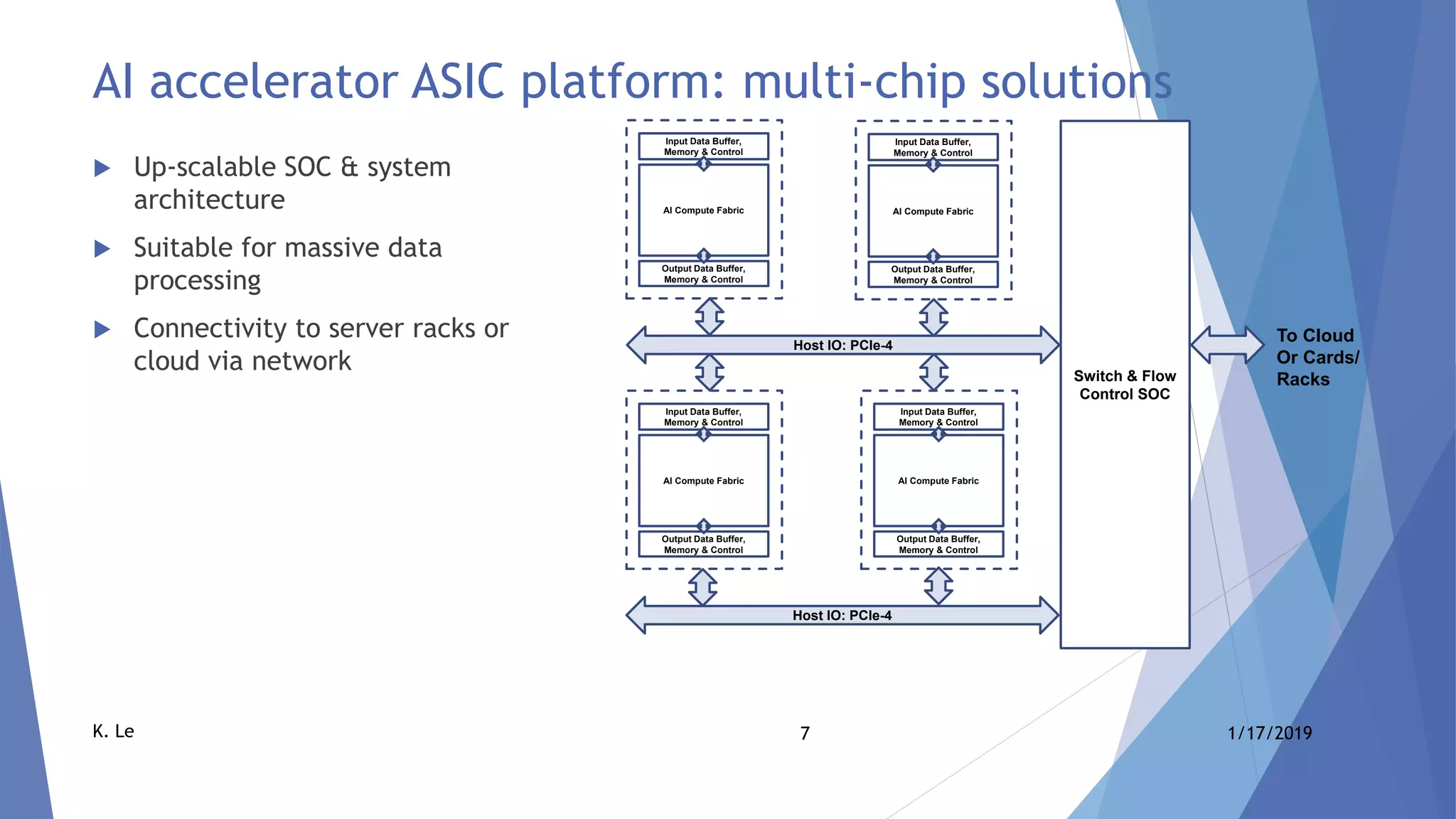

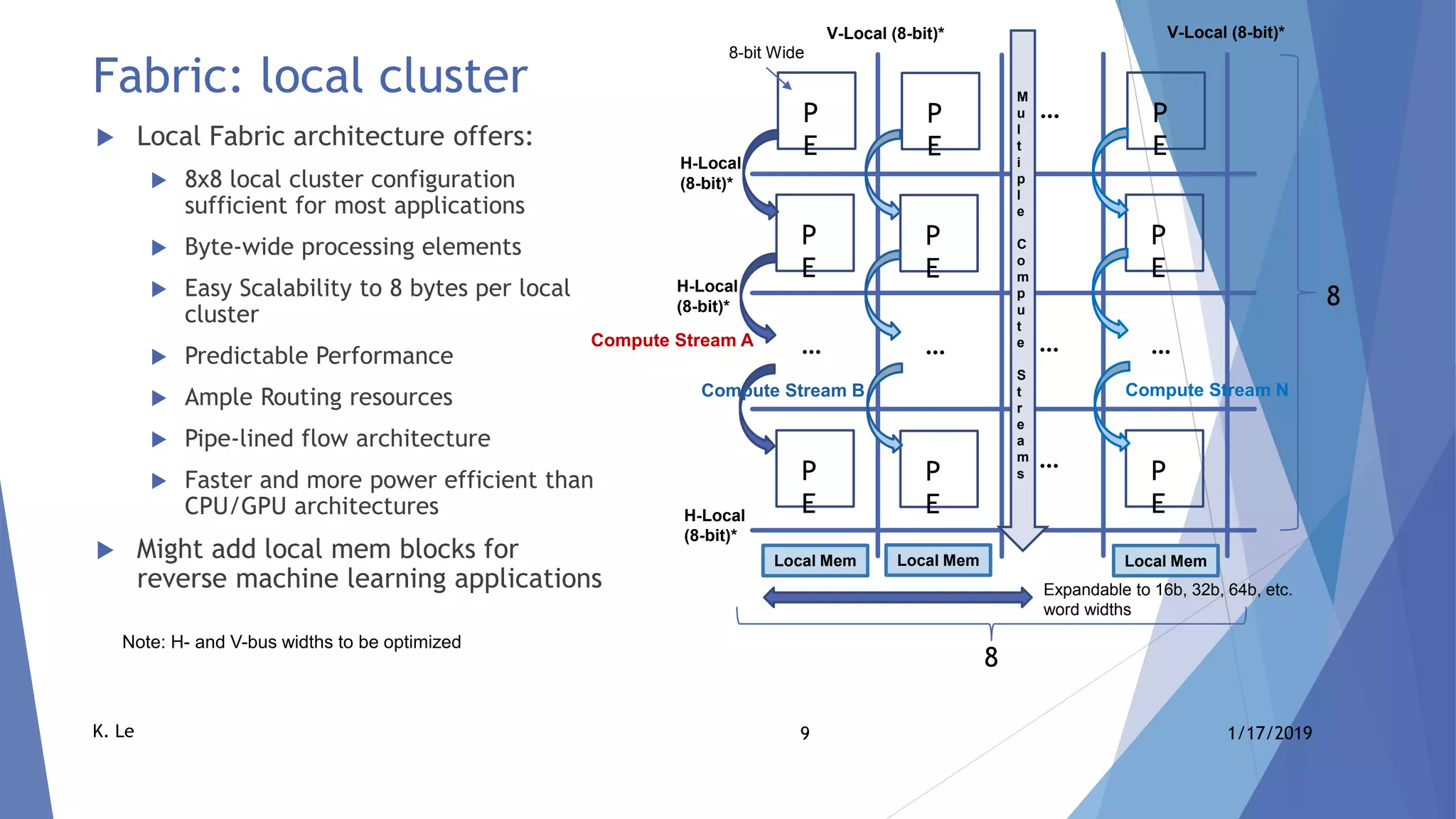
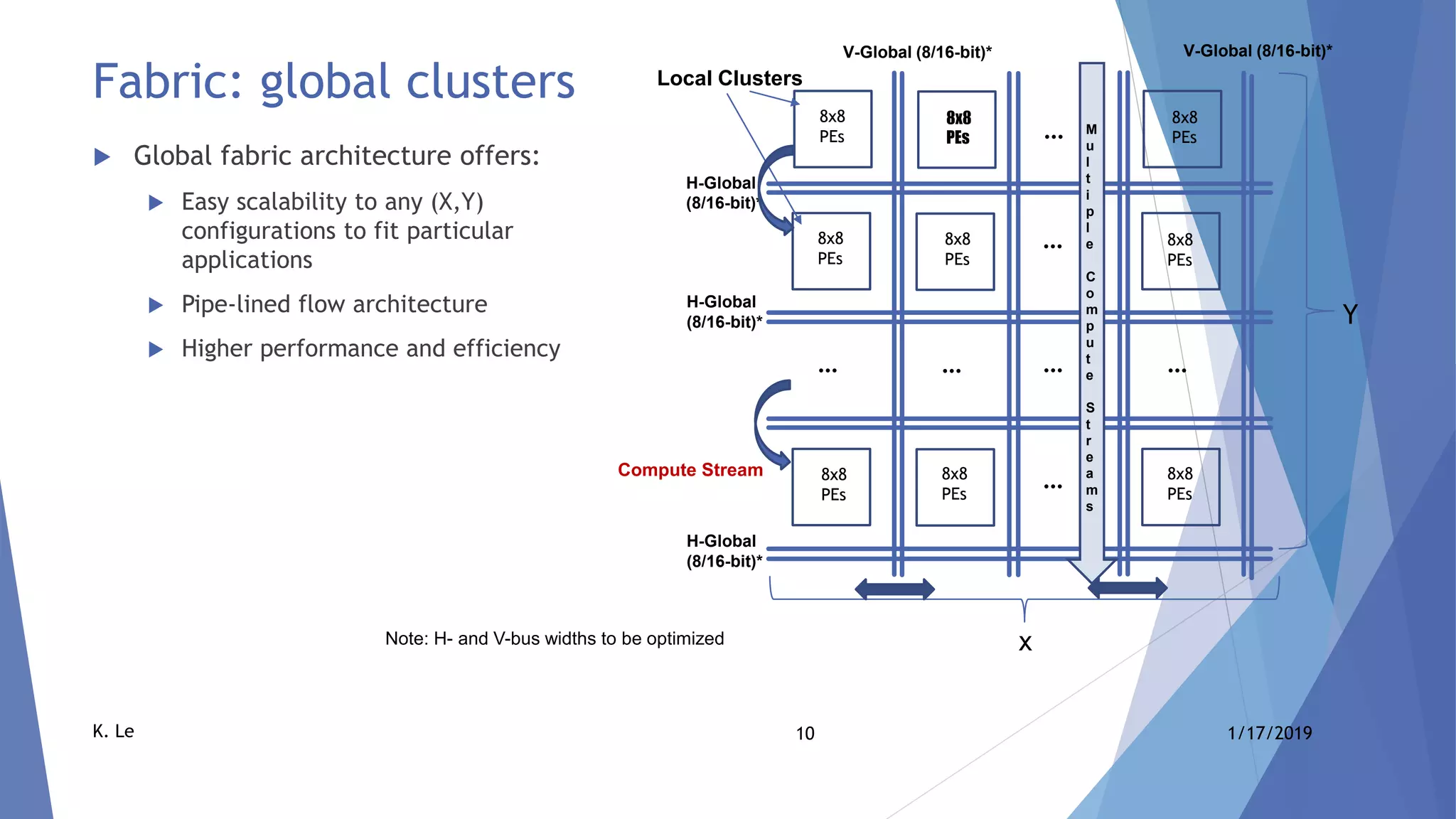
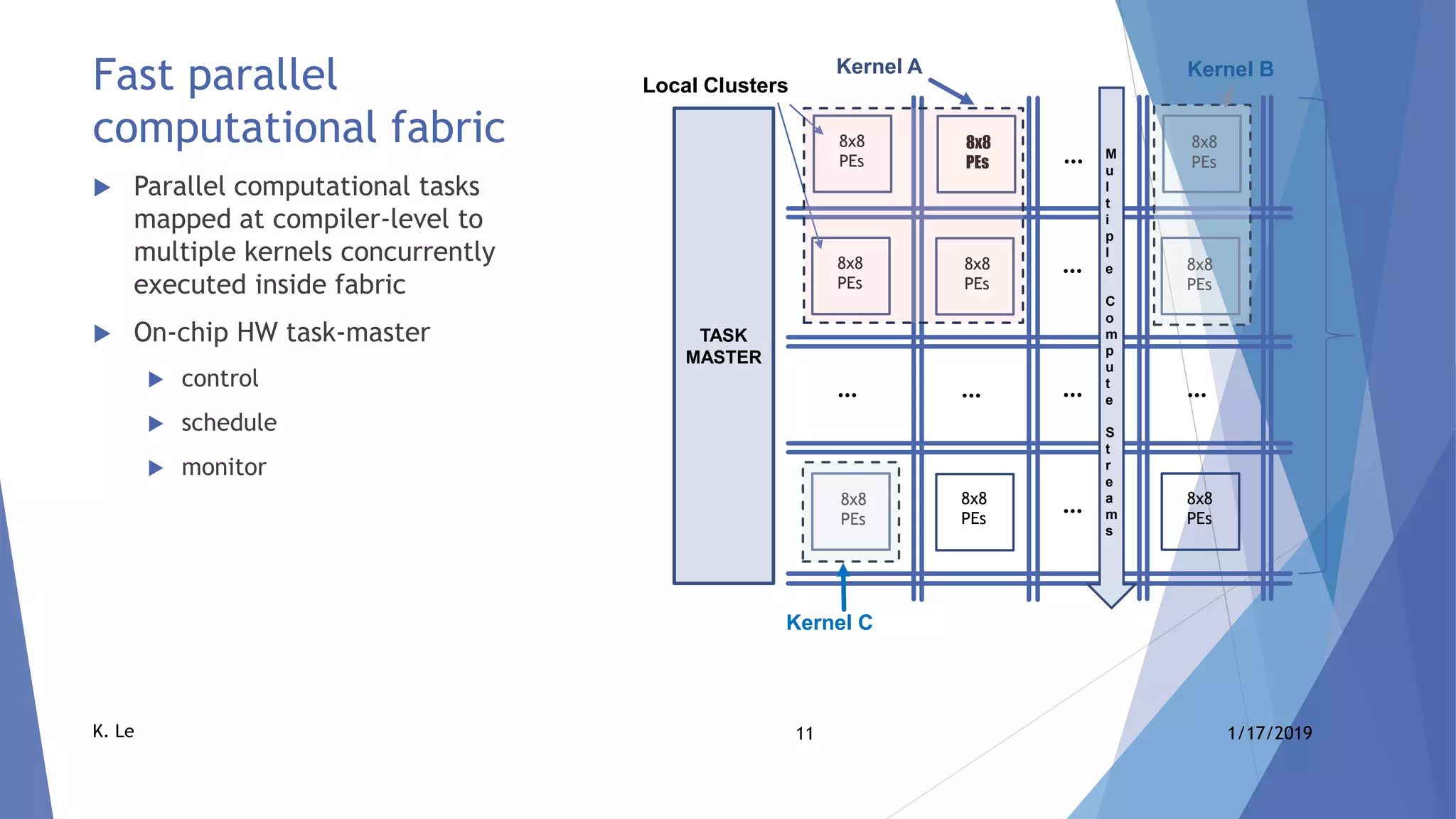



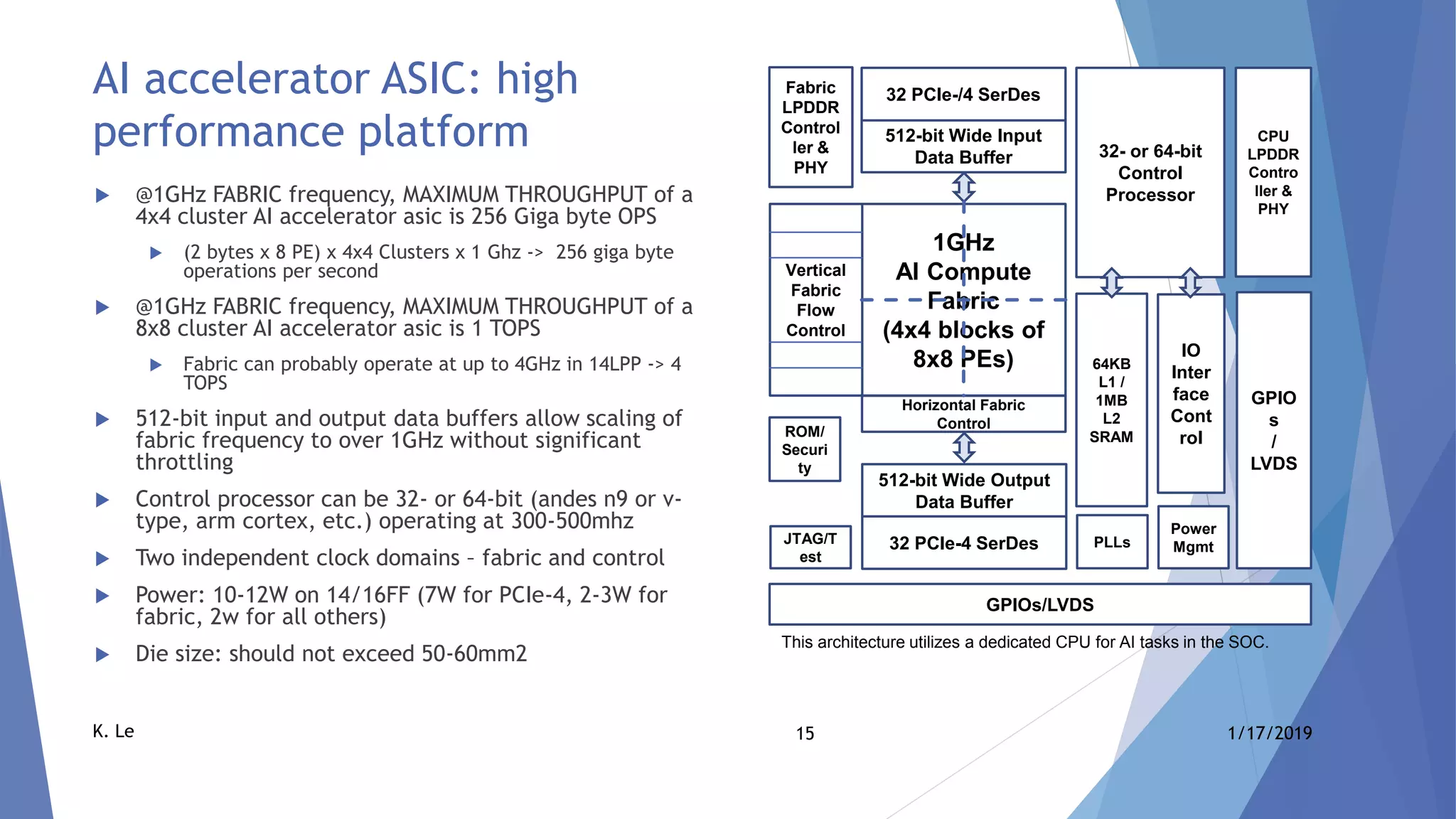
















The document proposes a scalable AI accelerator ASIC platform for edge AI processing. It describes a high-level architecture based on a scalable AI compute fabric that allows for fast learning and inference. The architecture is flexible and can scale from single-chip solutions to multi-chip solutions connected via high-speed interfaces. It also provides details on the AI compute fabric, processing elements, and how the platform could enable high-performance edge AI processing.



























































