Download as PDF, PPTX














![Language Modeling
Objectives - MLM
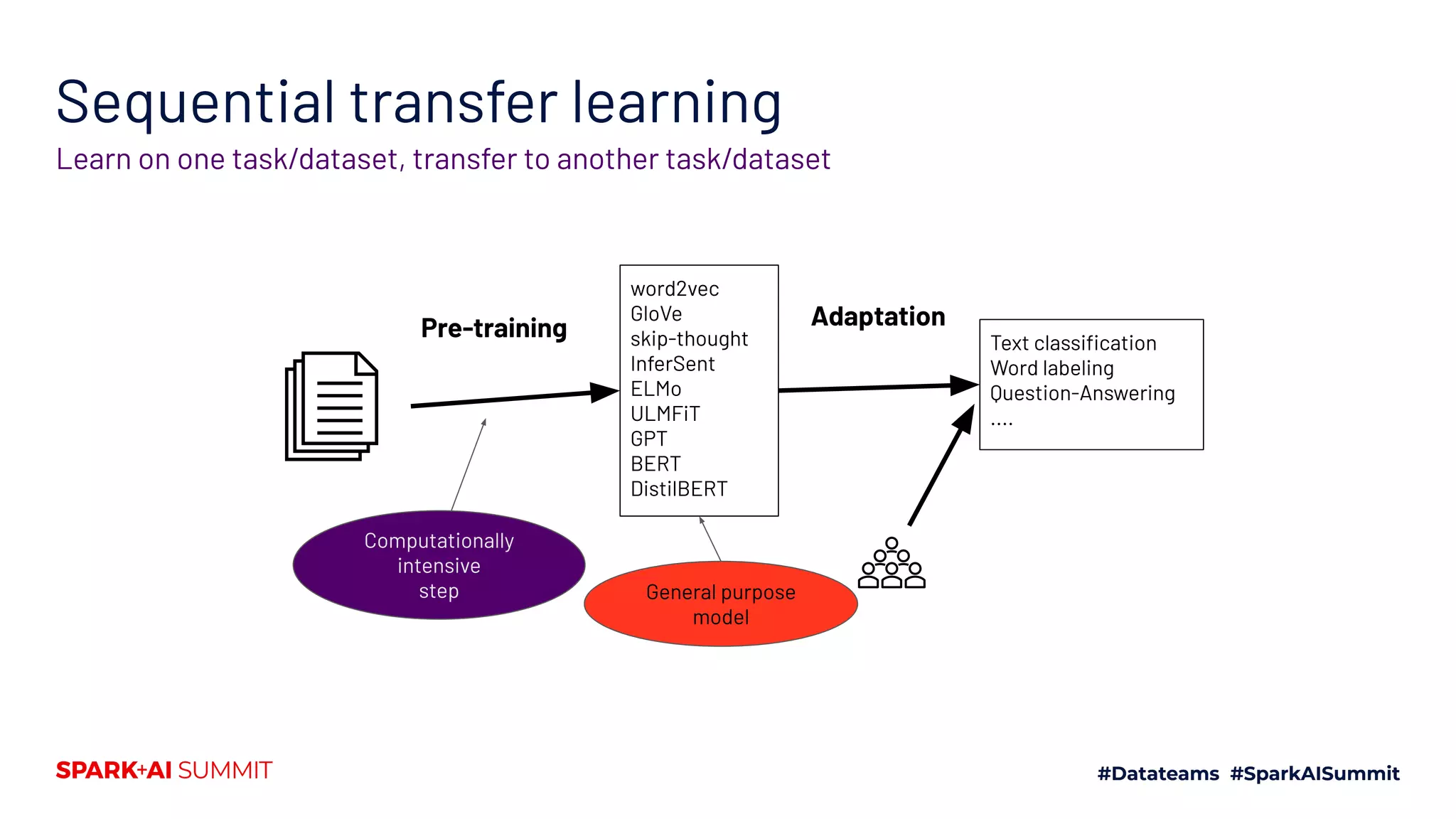
['The', 'pipeline', 'for', 'State', '-', 'of', '-', 'the', '-', 'Art', 'Natural', 'Language', 'Process', '##ing']
The pipeline for State-of-the-Art Natural Language Processing
['The', ‘pipeline’ 'for', 'State', '-', 'of', '-', 'the', '-', 'Art', [MASK], 'Language', 'Process', '##ing']
Tokenization
Masking
['The', ‘pipeline’, 'for', 'State', '-', 'of', '-', 'the', '-', 'Art', [MASK], 'Language', 'Process', '##ing']
‘Natural’
‘Artificial’
‘Machine’
‘Processing’
‘Speech’
Prediction](https://image.slidesharecdn.com/661lysandredebutanthonymoi-200629032103/75/Building-a-Pipeline-for-State-of-the-Art-Natural-Language-Processing-Using-Hugging-Face-Tools-22-2048.jpg)
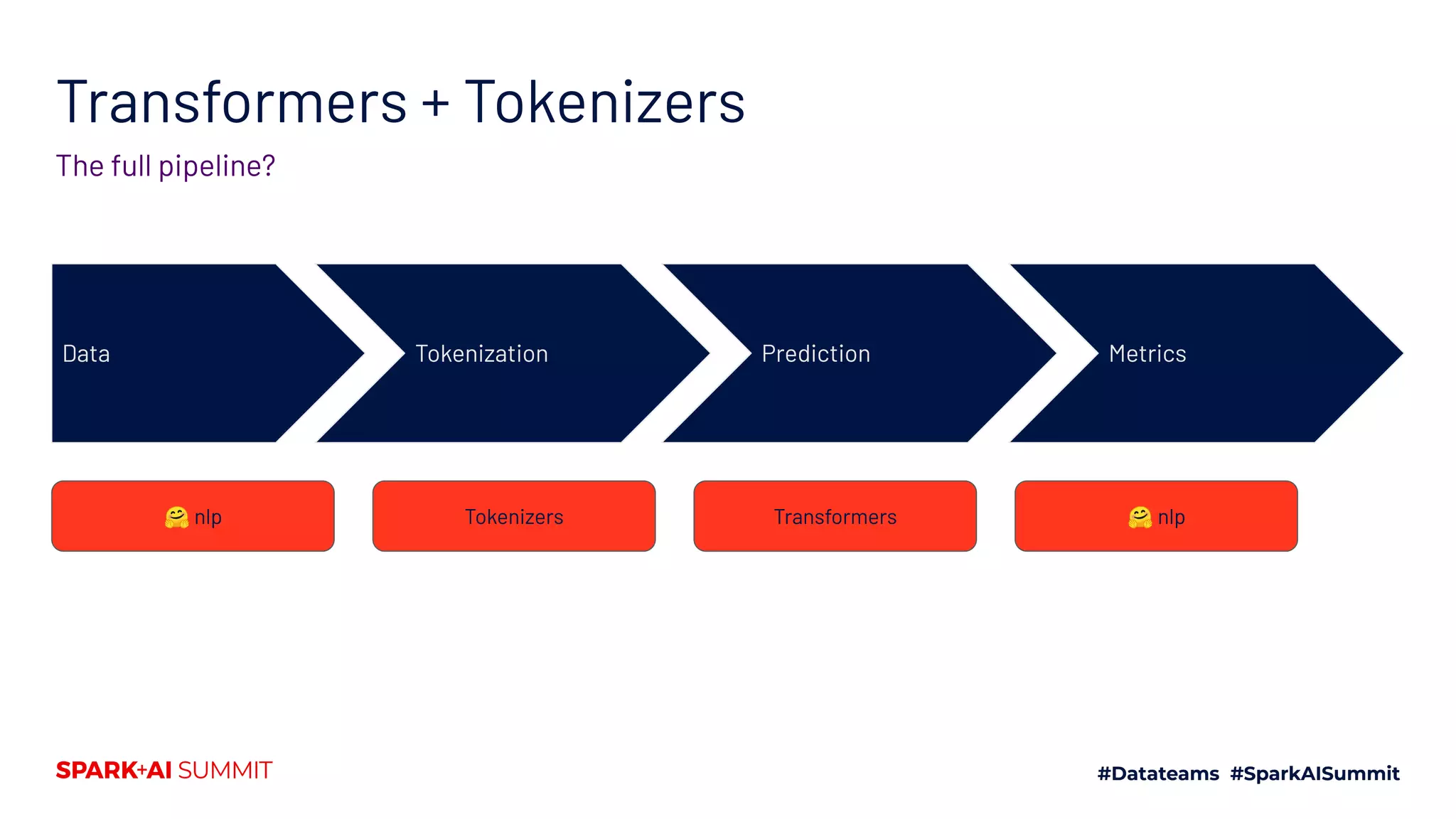
![Language Modeling
Objectives - CLM
['The', 'pipeline', 'for', 'State', '-', 'of', '-', 'the', '-', 'Art', 'Natural', 'Language', 'Process', '##ing']
The pipeline for State-of-the-Art Natural Language Processing
Tokenization
Prediction
['Process', '##ing', '(', 'NL', '##P', ')', 'software', 'which', 'will', 'allow', 'a', 'user', 'to', 'develop']](https://image.slidesharecdn.com/661lysandredebutanthonymoi-200629032103/75/Building-a-Pipeline-for-State-of-the-Art-Natural-Language-Processing-Using-Hugging-Face-Tools-23-2048.jpg)










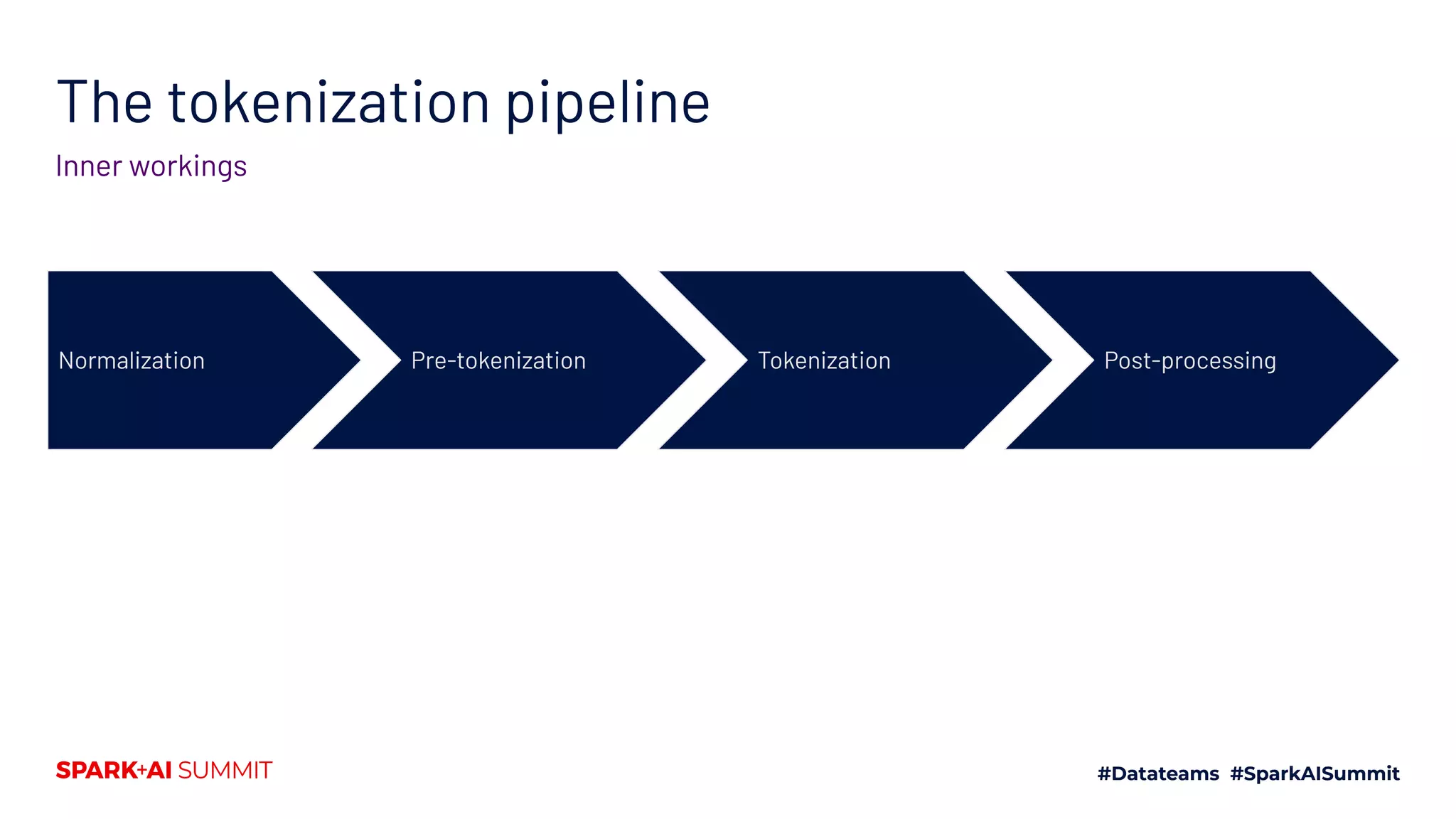
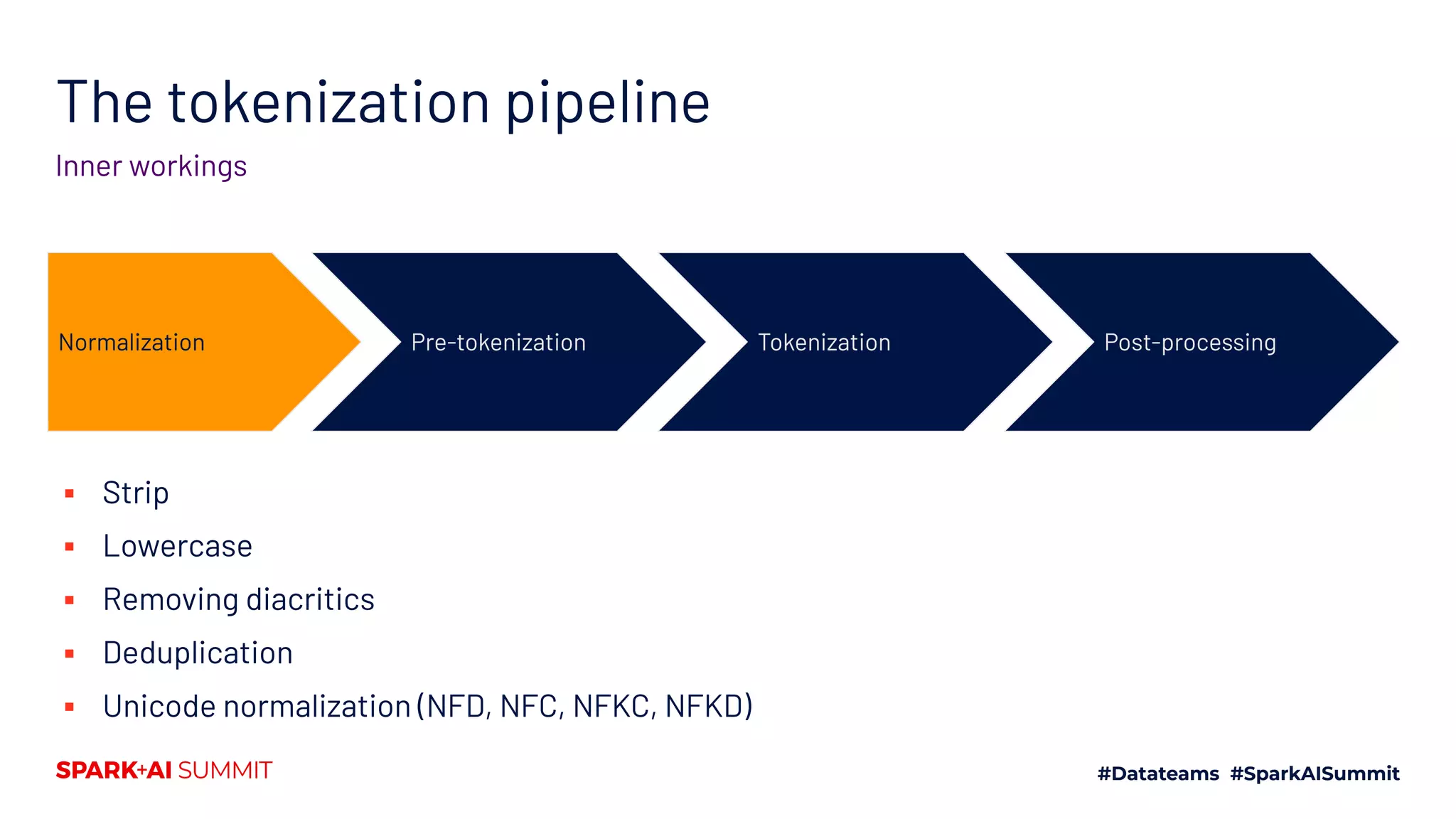
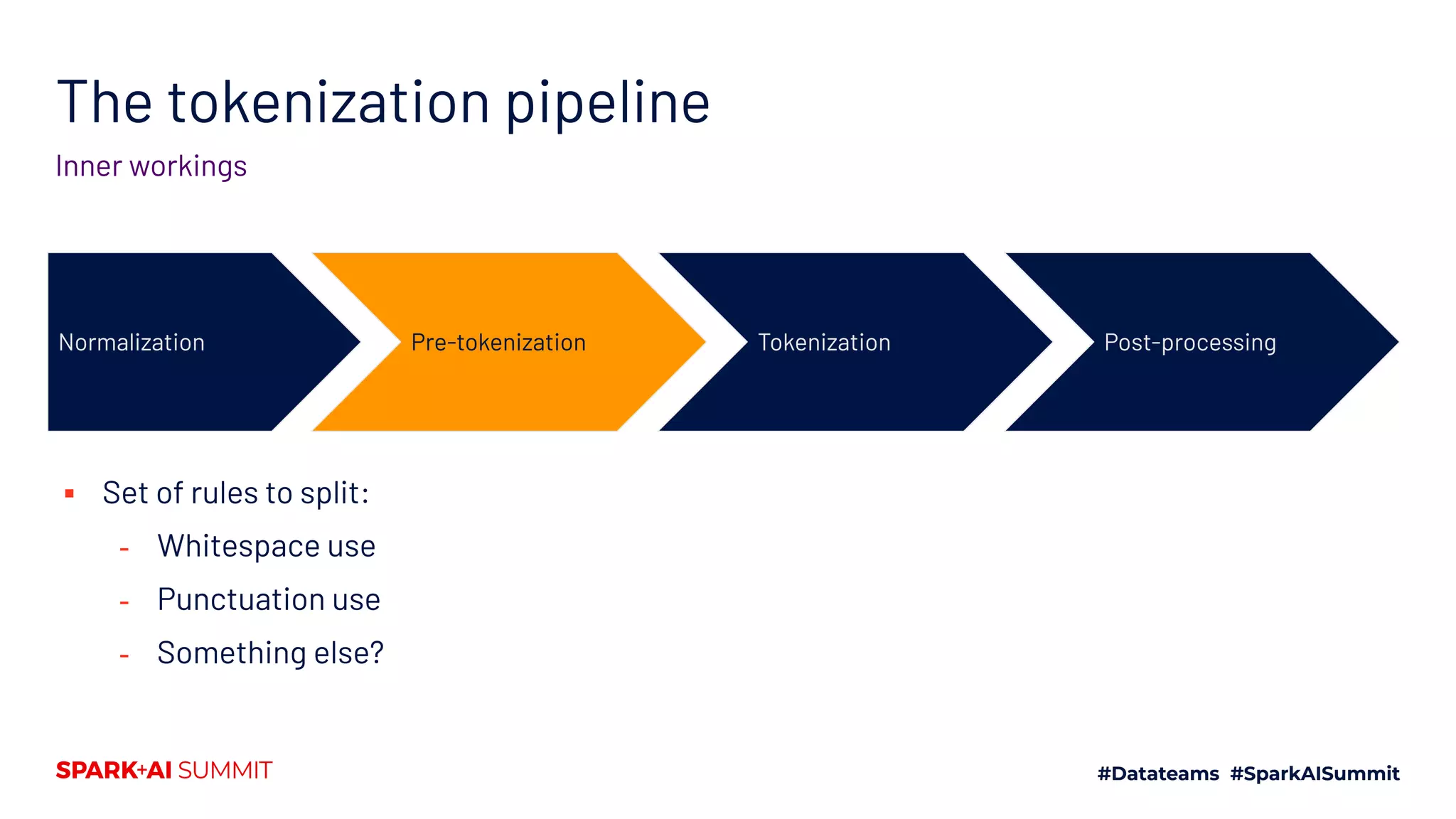
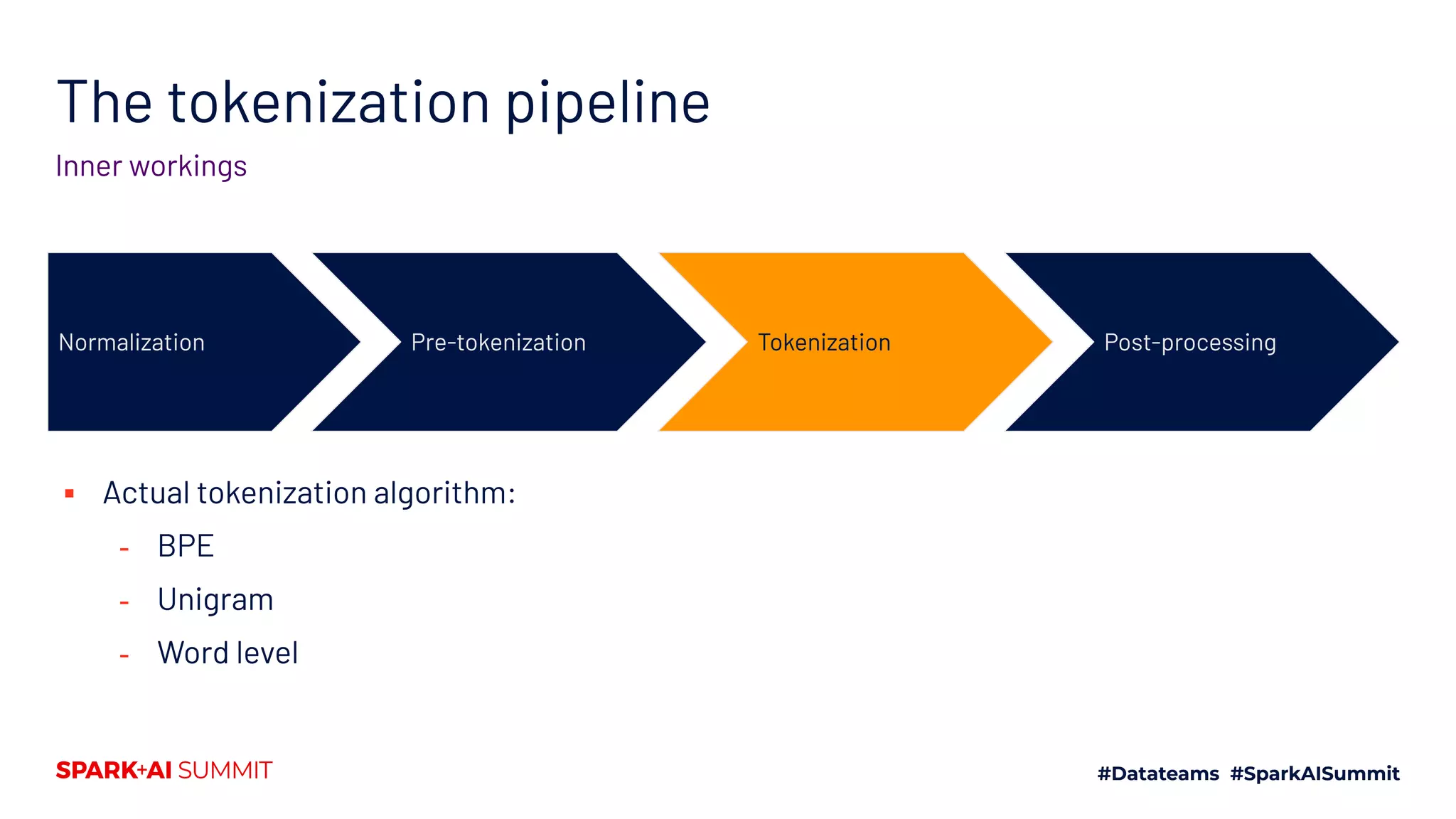
![The tokenization pipeline
Inner workings
Normalization Pre-tokenization Tokenization Post-processing
▪ Add special tokens: for example [CLS], [SEP] with BERT
▪ Truncate to match the maximum length of the model
▪ Pad all sequence in a batch to the same length
▪ ...](https://image.slidesharecdn.com/661lysandredebutanthonymoi-200629032103/75/Building-a-Pipeline-for-State-of-the-Art-Natural-Language-Processing-Using-Hugging-Face-Tools-38-2048.jpg)








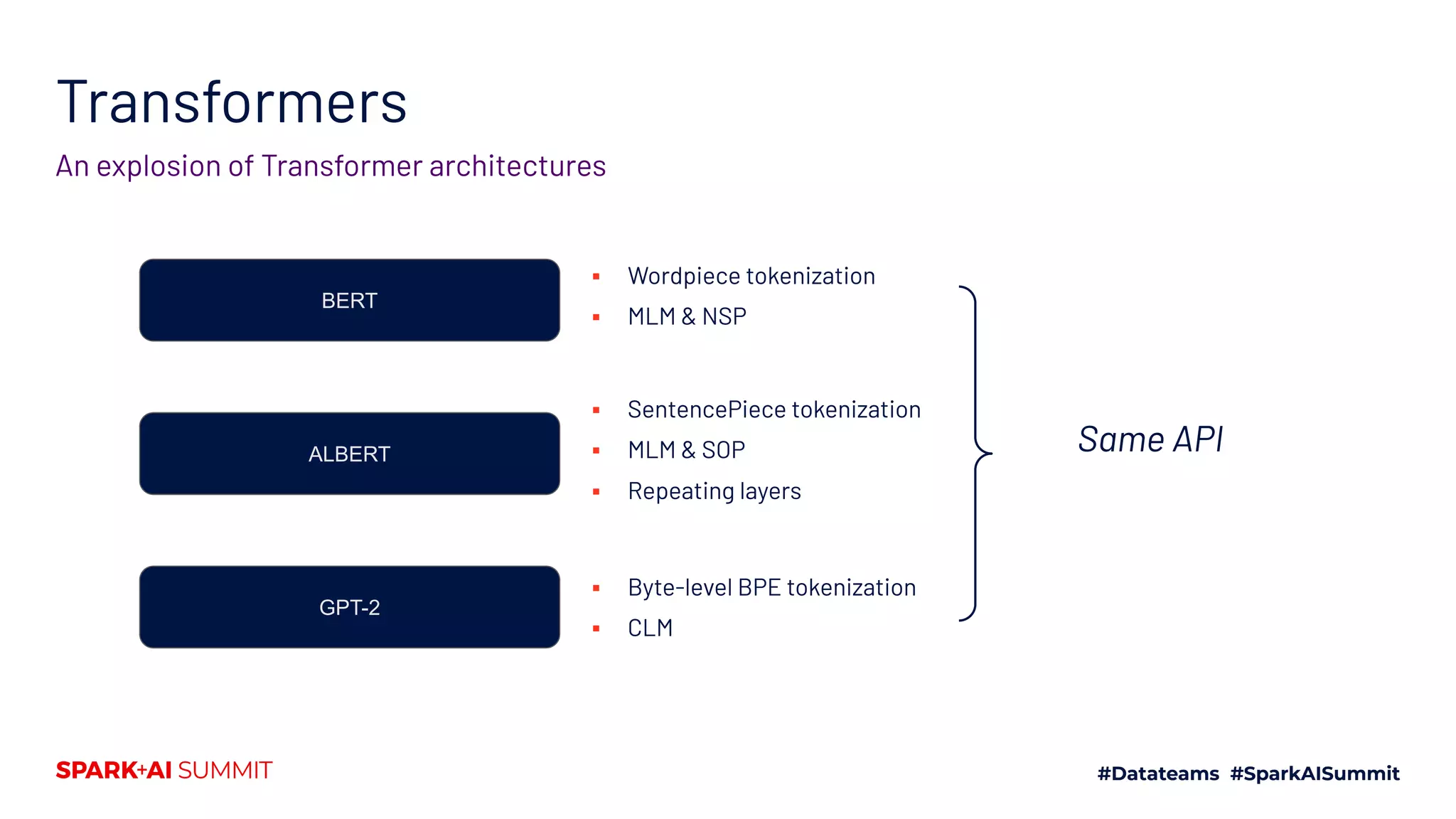

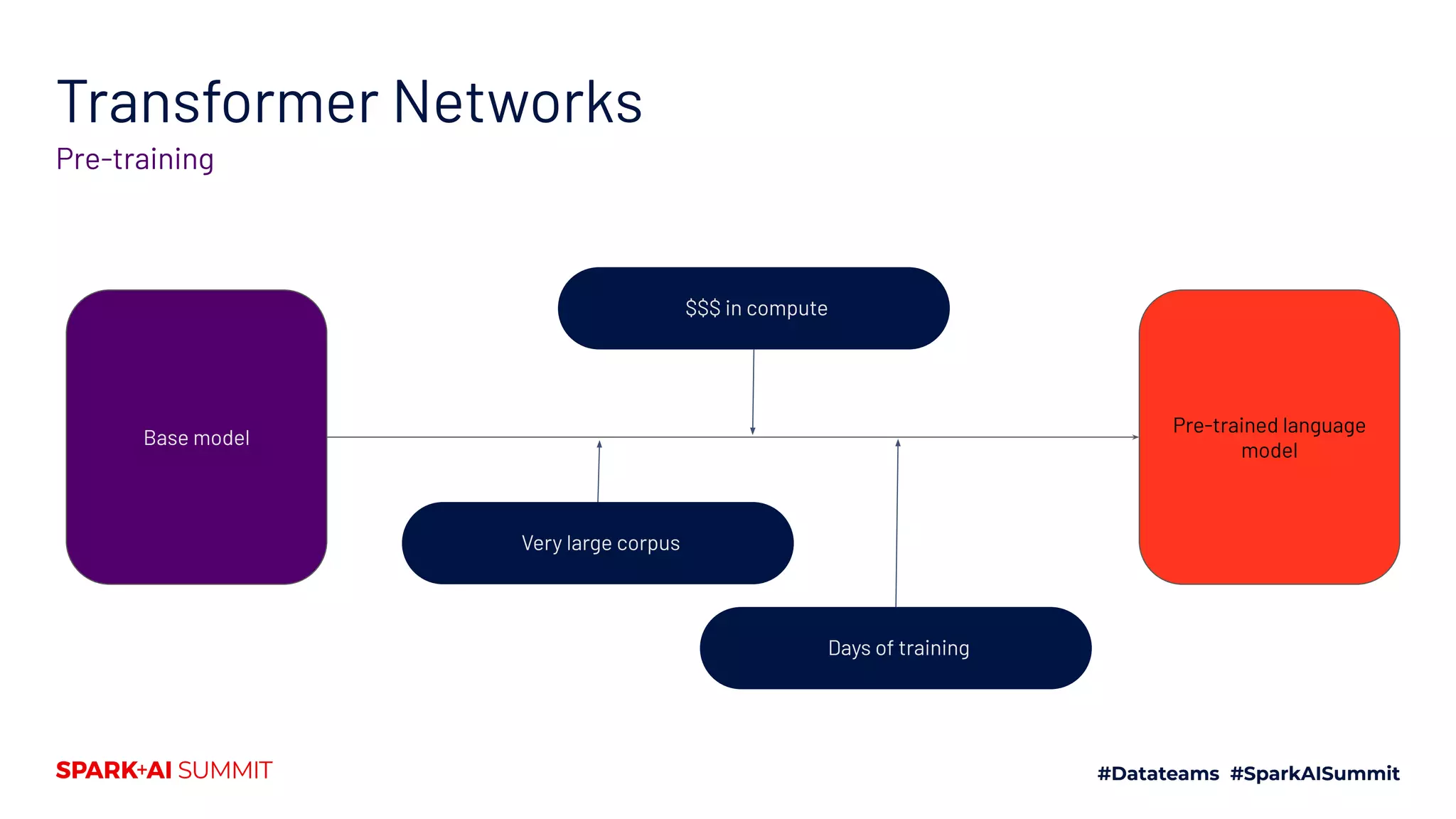
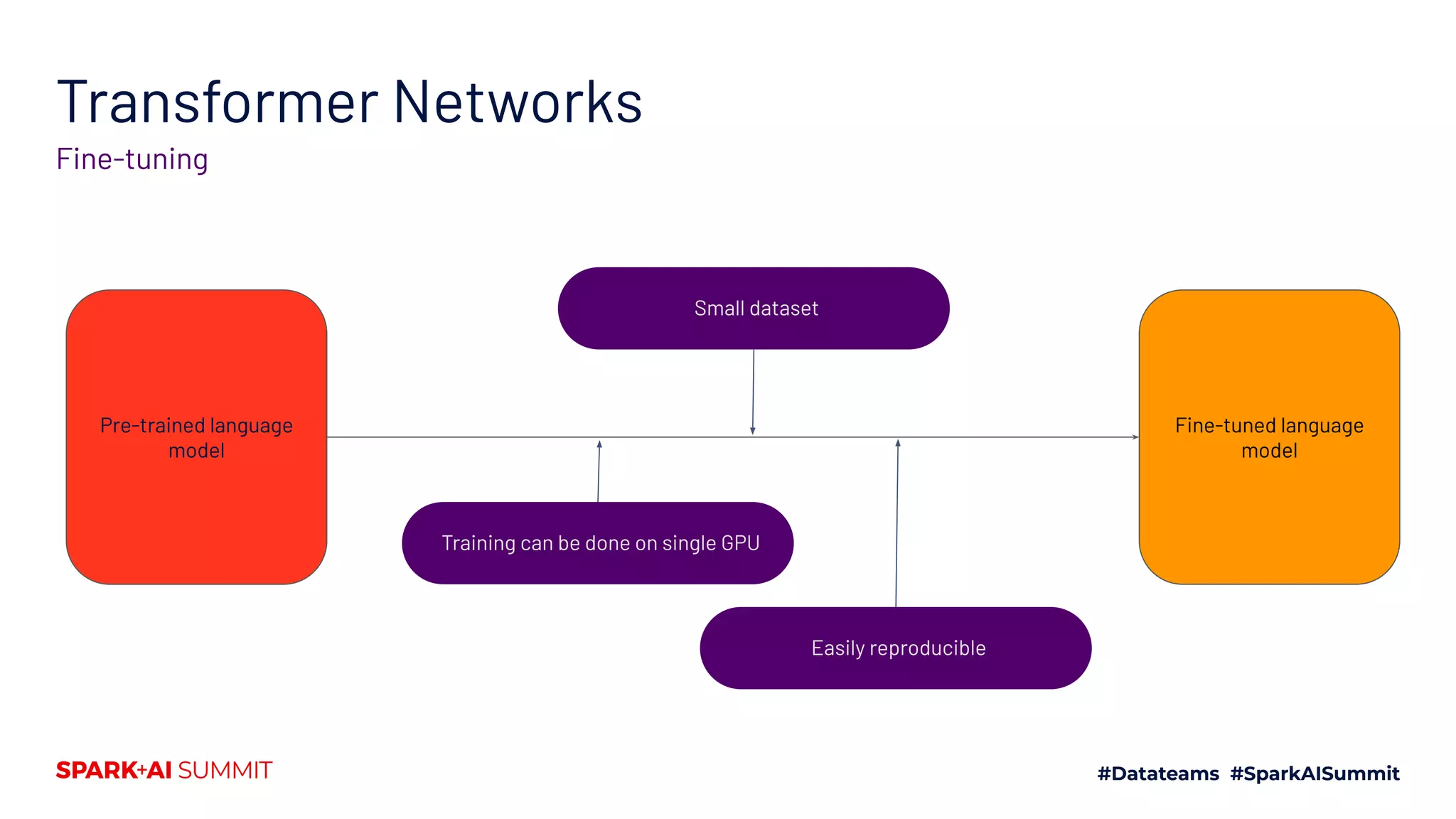
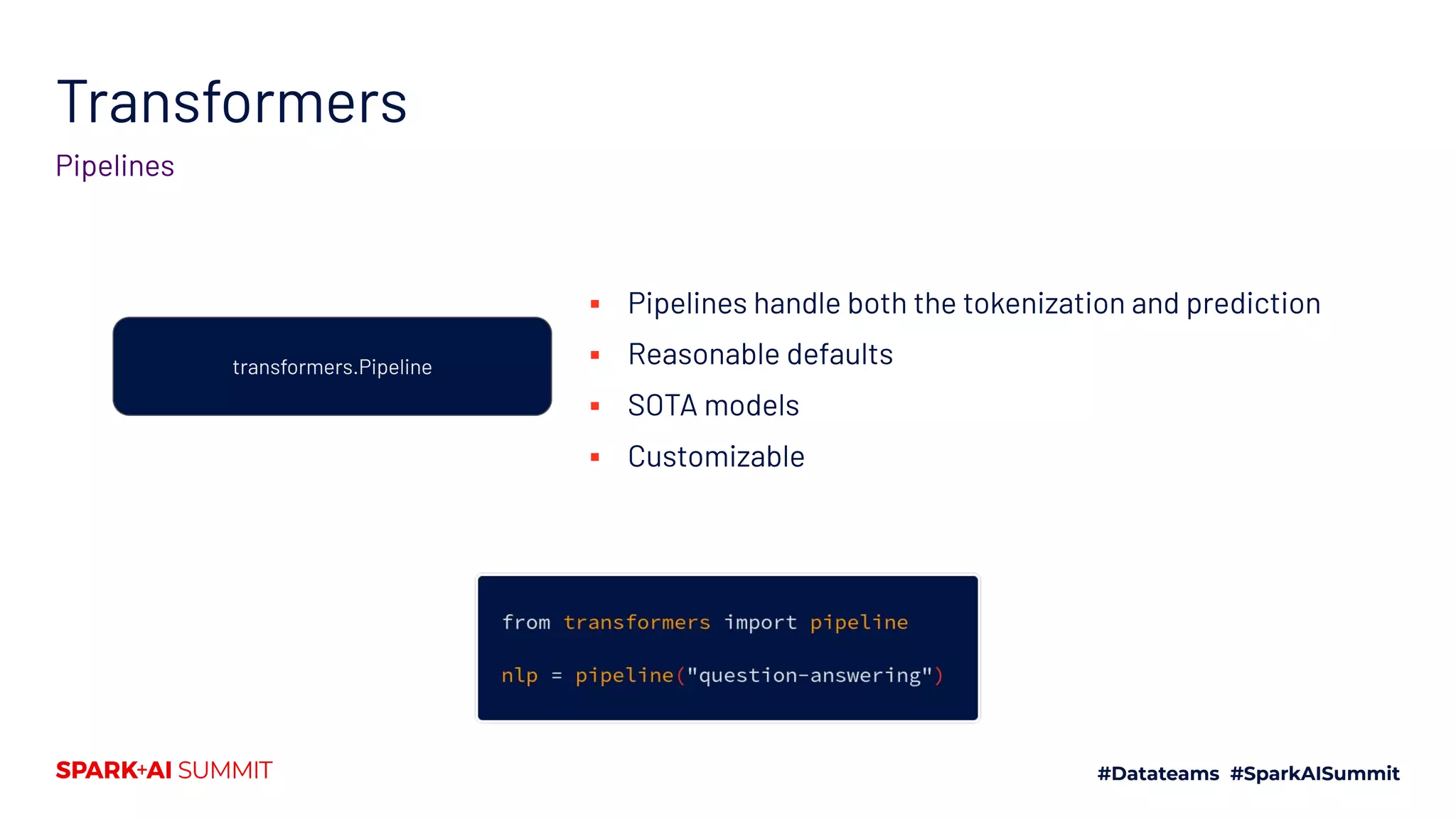
![Transformers
Tokenization to prediction
transformers.PreTrainedTokenizer
transformers.PreTrainedModel
The pipeline for State-of-the-Art Natural Language Processing
[[464, 11523, 329, 1812, 12, ..., 15417, 28403]]
Tensor(batch_size, sequence_length, hidden_size) Task-specific prediction
Base model With task-specific head](https://image.slidesharecdn.com/661lysandredebutanthonymoi-200629032103/75/Building-a-Pipeline-for-State-of-the-Art-Natural-Language-Processing-Using-Hugging-Face-Tools-49-2048.jpg)




































![Language Modeling
Objectives - MLM
['The', 'pipeline', 'for', 'State', '-', 'of', '-', 'the', '-', 'Art', 'Natural', 'Language', 'Process', '##ing']
The pipeline for State-of-the-Art Natural Language Processing
['The', ‘pipeline’ 'for', 'State', '-', 'of', '-', 'the', '-', 'Art', [MASK], 'Language', 'Process', '##ing']
Tokenization
Masking
['The', ‘pipeline’, 'for', 'State', '-', 'of', '-', 'the', '-', 'Art', [MASK], 'Language', 'Process', '##ing']
‘Natural’
‘Artificial’
‘Machine’
‘Processing’
‘Speech’
Prediction](https://crownmelresort.com/image.slidesharecdn.com/661lysandredebutanthonymoi-200629032103/75/Building-a-Pipeline-for-State-of-the-Art-Natural-Language-Processing-Using-Hugging-Face-Tools-22-2048.jpg)
![Language Modeling
Objectives - CLM
['The', 'pipeline', 'for', 'State', '-', 'of', '-', 'the', '-', 'Art', 'Natural', 'Language', 'Process', '##ing']
The pipeline for State-of-the-Art Natural Language Processing
Tokenization
Prediction
['Process', '##ing', '(', 'NL', '##P', ')', 'software', 'which', 'will', 'allow', 'a', 'user', 'to', 'develop']](https://crownmelresort.com/image.slidesharecdn.com/661lysandredebutanthonymoi-200629032103/75/Building-a-Pipeline-for-State-of-the-Art-Natural-Language-Processing-Using-Hugging-Face-Tools-23-2048.jpg)














![The tokenization pipeline
Inner workings
Normalization Pre-tokenization Tokenization Post-processing
▪ Add special tokens: for example [CLS], [SEP] with BERT
▪ Truncate to match the maximum length of the model
▪ Pad all sequence in a batch to the same length
▪ ...](https://crownmelresort.com/image.slidesharecdn.com/661lysandredebutanthonymoi-200629032103/75/Building-a-Pipeline-for-State-of-the-Art-Natural-Language-Processing-Using-Hugging-Face-Tools-38-2048.jpg)










![Transformers
Tokenization to prediction
transformers.PreTrainedTokenizer
transformers.PreTrainedModel
The pipeline for State-of-the-Art Natural Language Processing
[[464, 11523, 329, 1812, 12, ..., 15417, 28403]]
Tensor(batch_size, sequence_length, hidden_size) Task-specific prediction
Base model With task-specific head](https://crownmelresort.com/image.slidesharecdn.com/661lysandredebutanthonymoi-200629032103/75/Building-a-Pipeline-for-State-of-the-Art-Natural-Language-Processing-Using-Hugging-Face-Tools-49-2048.jpg)


















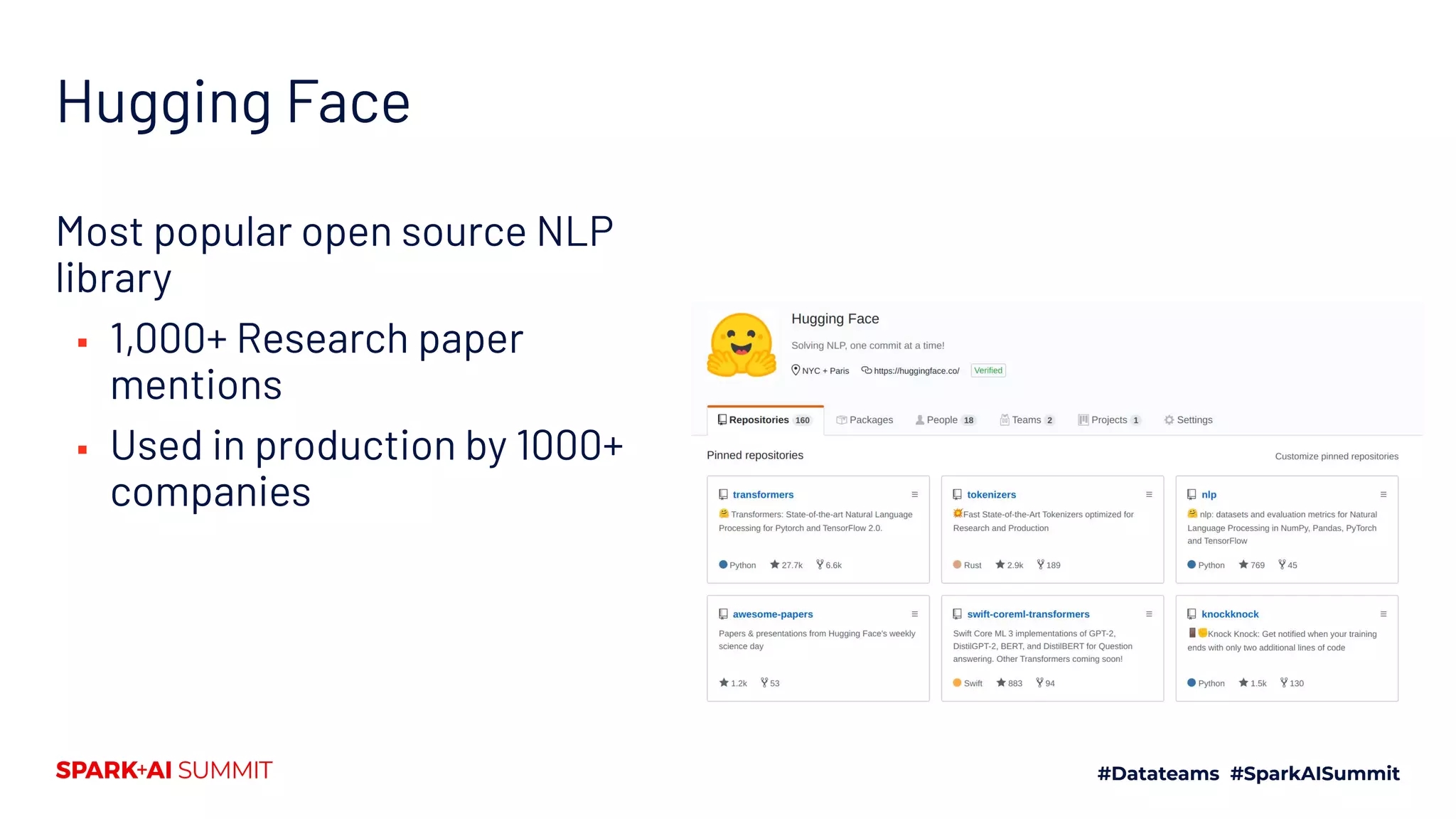
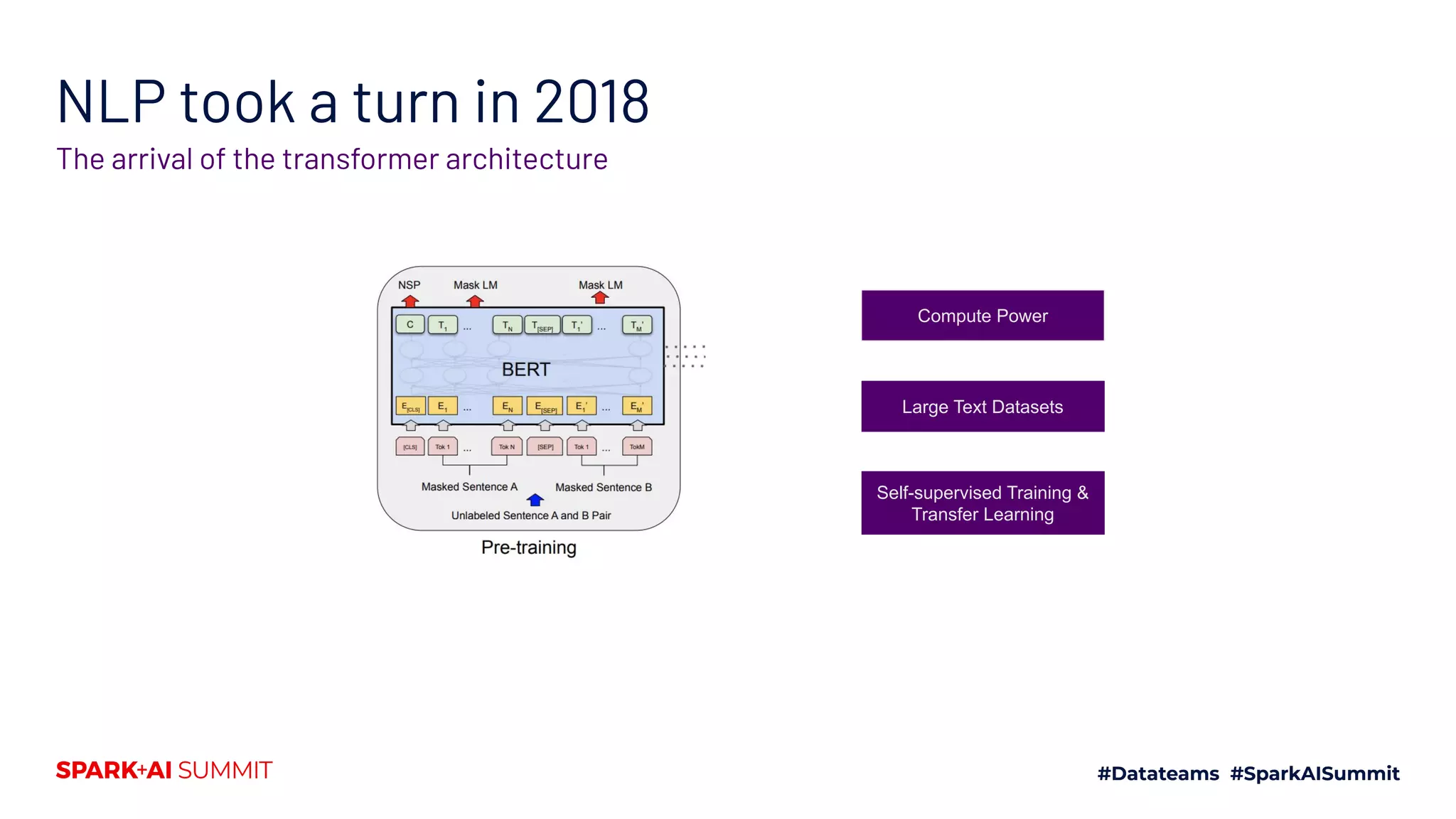
The document summarizes a presentation about state-of-the-art natural language processing (NLP) techniques. It discusses how transformer networks have achieved state-of-the-art results in many NLP tasks using transfer learning from large pre-trained models. It also describes how Hugging Face's Transformers library and Tokenizers library provide tools for tokenization and using pre-trained transformer models through a simple interface.




















![[Paper Reading] Attention is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/reading20181228-190111054908-thumbnail.jpg?width=640&height=640&fit=bounds)


































































