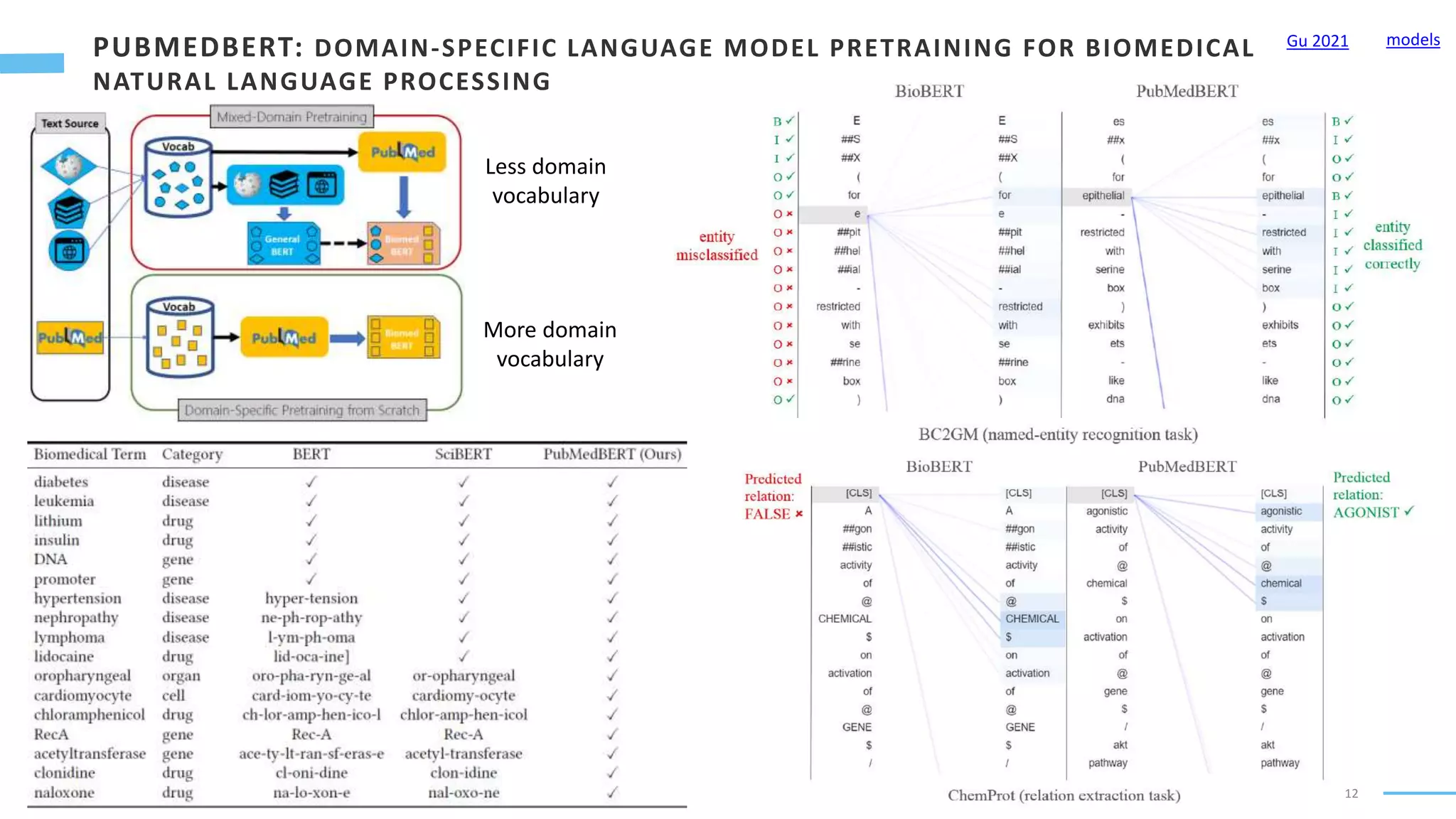
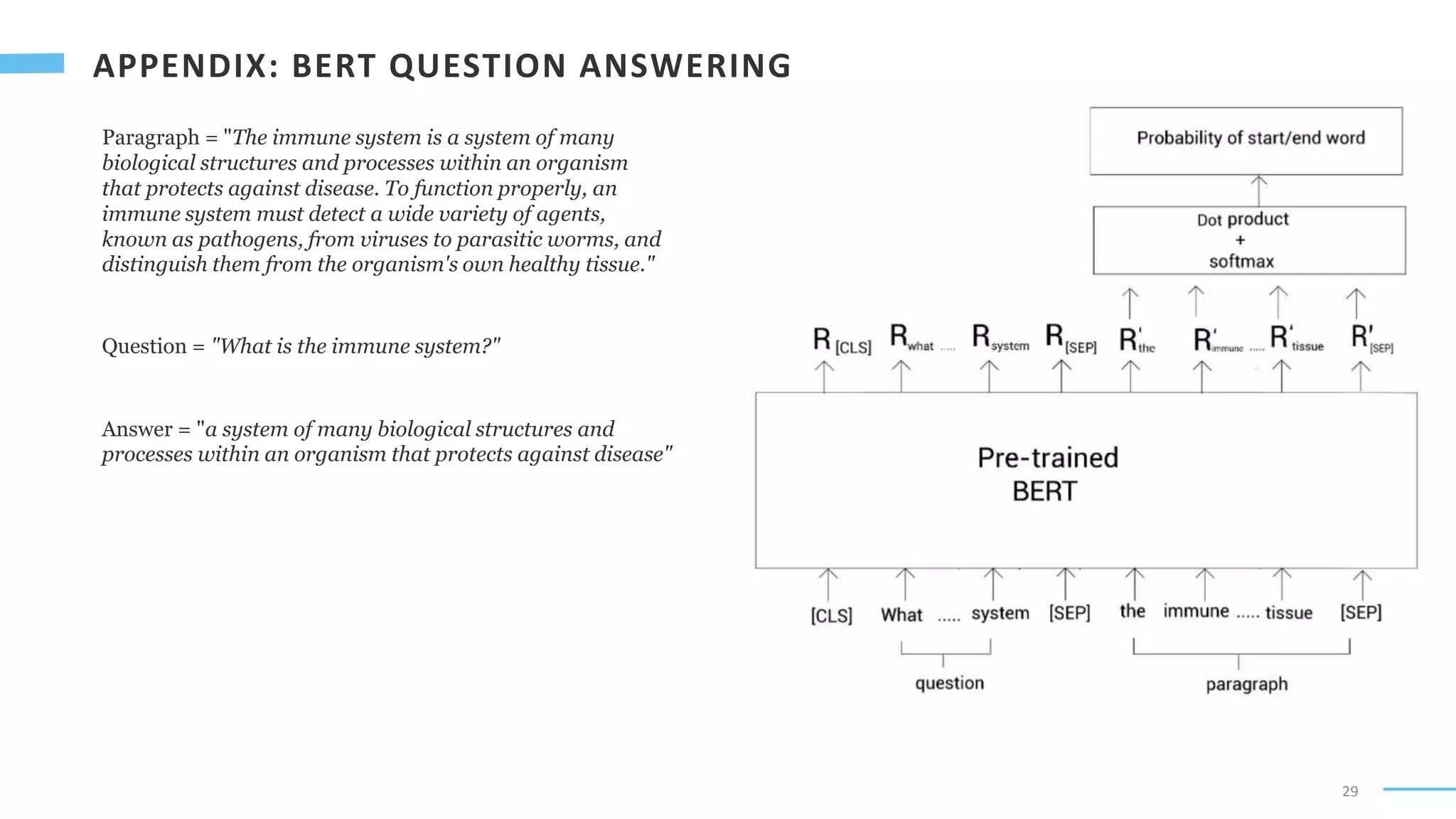
Downloaded 68 times


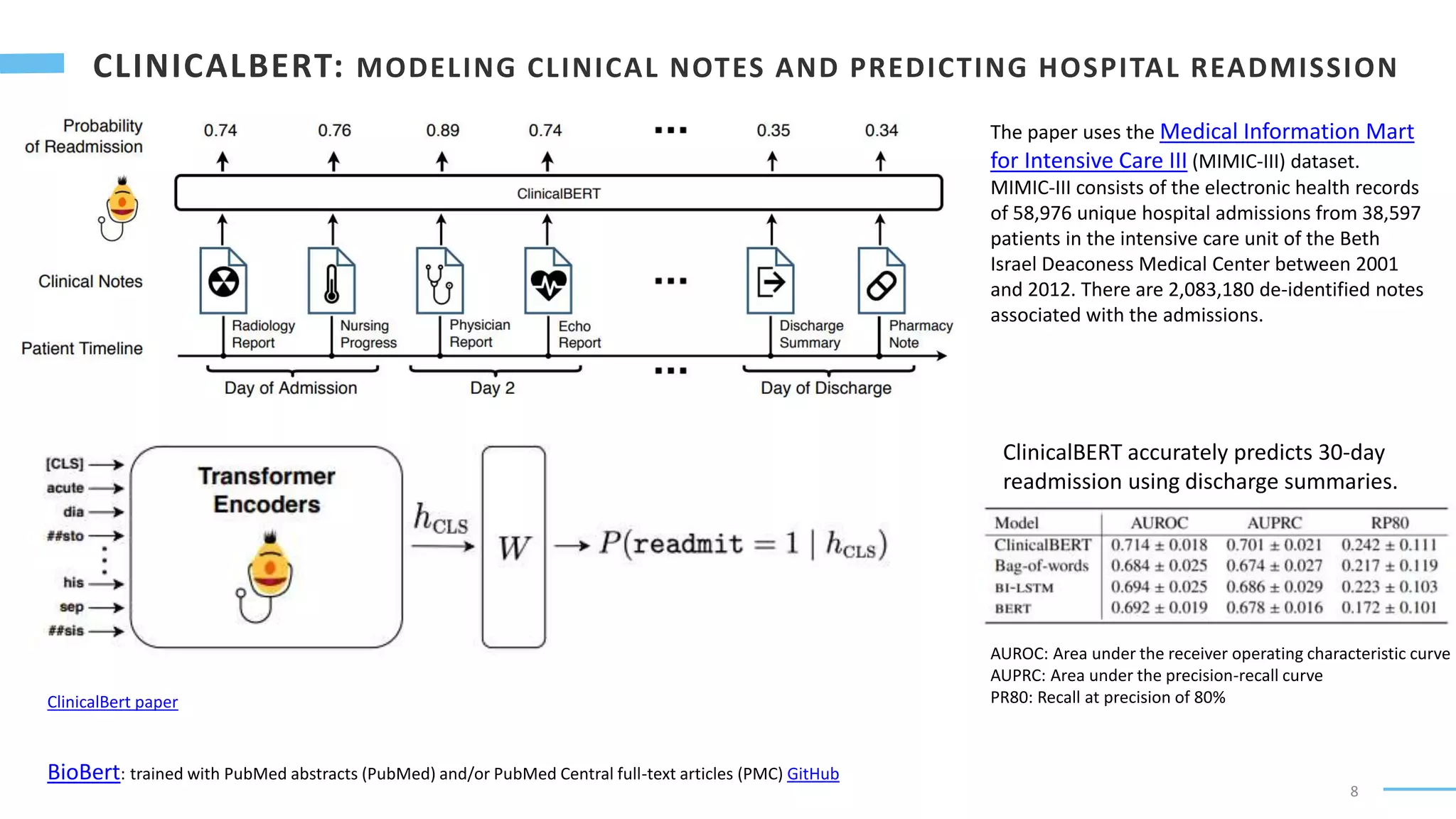
![9
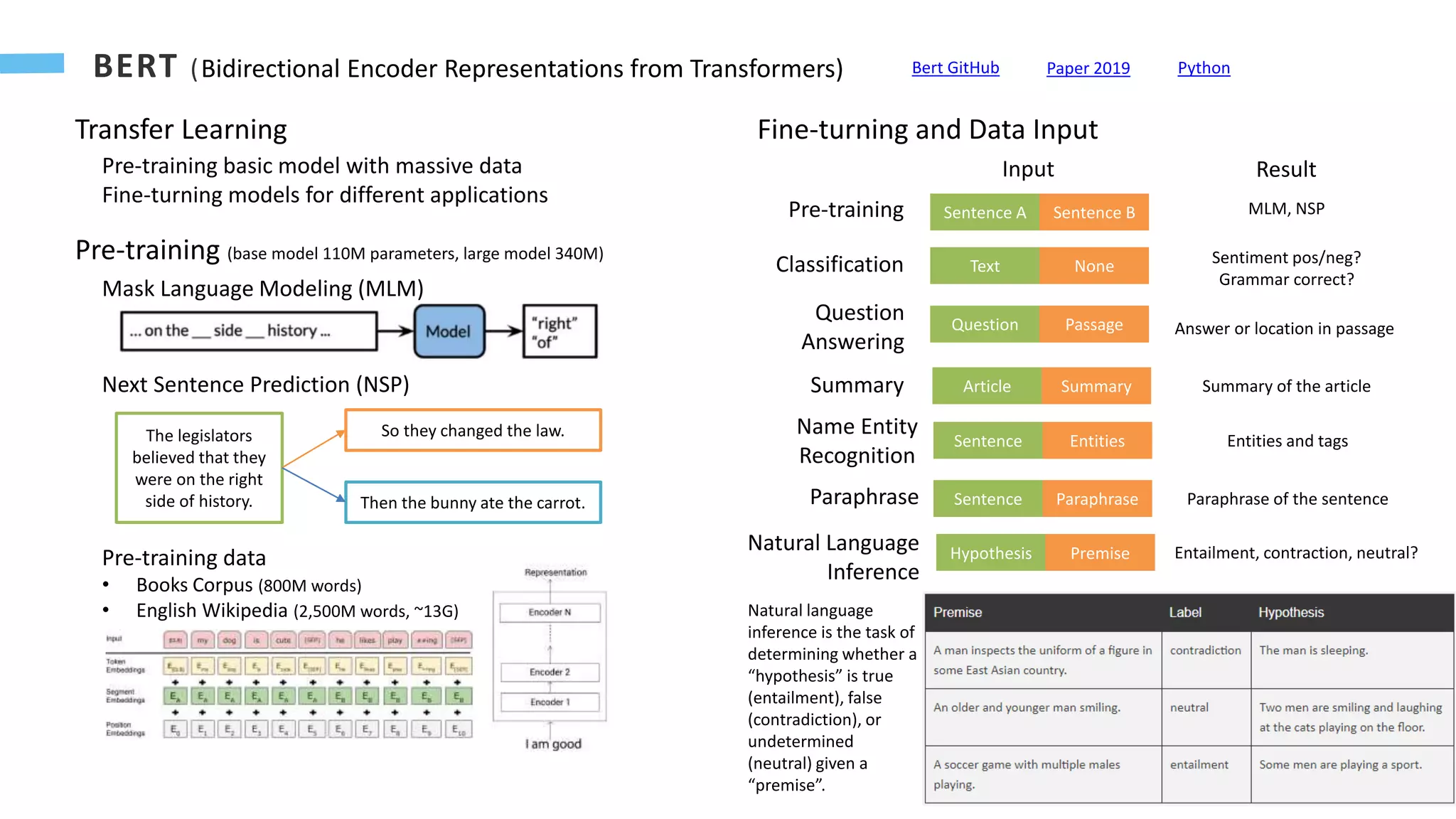
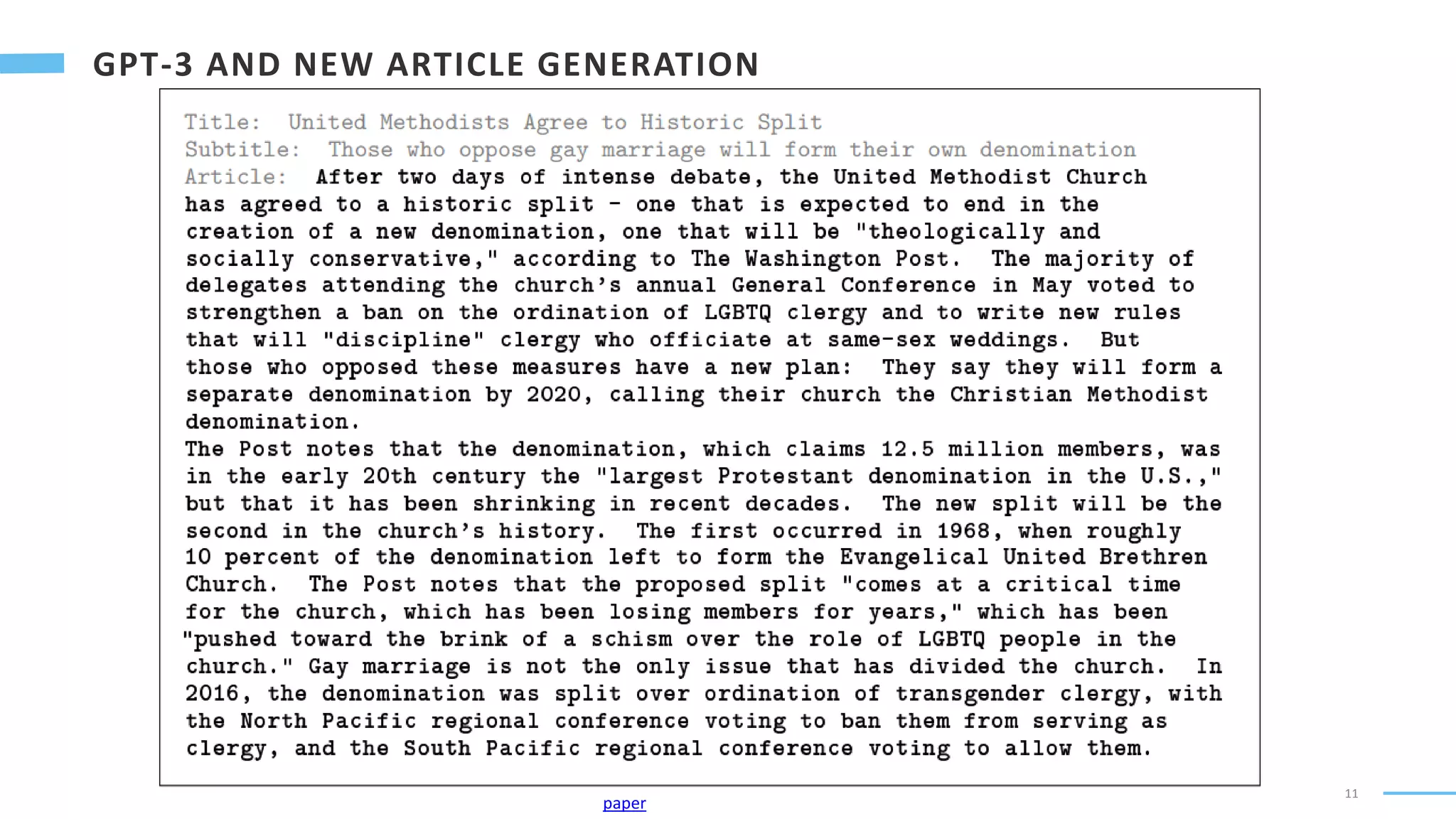
Text-to-Text Transfer Transformer)
Unified Multi-Task Framework: Text as Input, Text as Output
Cola: Corpus of Linguistic Acceptability
STSB: Semantic Textual Similarity Benchmark
RTE: Recognizing Textual Entailment
MNLI: Multi-Genre Natural Language Inference
MRPC: Microsoft Research Paraphrase Corpus
SQuAD: Stanford Question Answering Dataset
WMT English to German
COPA: Choice of Plausible Alternatives, causal reasoning
MultiRC: Multi-Sentence Reading Comprehension
WiC
Word in Context
WSC: Winograd Schema Challenge, resolve ambiguity
The city councilmen refused the demonstrators a permit
because they [feared/advocated] violence.
Question: “they” refers to?
Transfer Learning with C4 – Colossal Cleaned Crawl Corpus (~800G), base model with 220M parameters, large model 770M, largest 11B
T5 GitHub Paper 2020 Python](https://image.slidesharecdn.com/naturallanguageprocessingandtransformermodels-220212124442/75/Natural-language-processing-and-transformer-models-9-2048.jpg)







![2
3
N-Gram and Probability [Corpus: I am happy because I am learning]
• Unigram: {I, am, happy, because, learning} 𝑃 𝐼 =
𝐶 𝐼
𝐶(𝐴𝑙𝑙)
=
2
7
• Bigram: {I am, am happy, happy because…} 𝑃 ℎ𝑎𝑝𝑝𝑦 | 𝑎𝑚 =
𝐶 𝑎𝑚 ℎ𝑎𝑝𝑝𝑦
𝐶 𝑎𝑚
=
1
2
• Trigram: {I am happy, am happy because…} 𝑃 ℎ𝑎𝑝𝑝𝑦 | 𝐼 𝑎𝑚 =
𝐶 𝐼 𝑎𝑚 ℎ𝑎𝑝𝑝𝑦
𝐶 𝐼 𝑎𝑚
=
1
2
Approximation of Sequence Probability
• Use N-Gram for approximation since long sequences are rare
Use Bigram: 𝑃 𝑡ℎ𝑒 𝑡𝑒𝑎𝑐ℎ𝑒𝑟 𝑑𝑟𝑖𝑛𝑘𝑠 𝑡𝑒𝑎 ≈ 𝑃 𝑡ℎ𝑒 𝑃 𝑡𝑒𝑎𝑐ℎ𝑒𝑟 𝑡ℎ𝑒 𝑃 𝑑𝑟𝑖𝑛𝑘𝑠 𝑡𝑒𝑎𝑐ℎ𝑒𝑟 𝑃 𝑡𝑒𝑎 𝑑𝑟𝑖𝑛𝑘𝑠
• Interpolation for handle missing terms
Trigram: 𝑃 𝑡𝑒𝑎|𝑡𝑒𝑎𝑐ℎ𝑒𝑟 𝑑𝑟𝑖𝑛𝑘𝑠 ≈ 0.7 × 𝑃 𝑡𝑒𝑎 𝑡𝑒𝑎𝑐ℎ𝑒𝑟 𝑑𝑟𝑖𝑛𝑘𝑠 + 0.2 × 𝑃 𝑡𝑒𝑎 𝑑𝑟𝑖𝑛𝑘𝑠 + 0.1 × 𝑃(tea)
• Add start and end token of sentence: <s> the teacher drinks tea </s>
𝑃 𝑡ℎ𝑒 𝑡𝑒𝑎𝑐ℎ𝑒𝑟 𝑑𝑟𝑖𝑛𝑘𝑠 𝑡𝑒𝑎 ≈ 𝑃 𝑡ℎ𝑒| < 𝑠 > 𝑃 𝑡𝑒𝑎𝑐ℎ𝑒𝑟 𝑡ℎ𝑒 𝑃 𝑑𝑟𝑖𝑛𝑘𝑠 𝑡𝑒𝑎𝑐ℎ𝑒𝑟 𝑃 𝑡𝑒𝑎 𝑑𝑟𝑖𝑛𝑘𝑠 P(</s>|tea)
Probability Matrix [Corpus: I study I learn]
Applications
Auto Complete
Generative Text
Python code](https://image.slidesharecdn.com/naturallanguageprocessingandtransformermodels-220212124442/75/Natural-language-processing-and-transformer-models-23-2048.jpg)
![24
TF -IDF (Term Frequency – Inverse Document Frequency)
tf = frequency of a term in a document
𝑖𝑑𝑓 = log
𝑁𝑎𝑙𝑙
𝑁𝑡
,
tf - idf = 𝑡𝑓 × 𝑖𝑑𝑓 = 𝑡𝑓 × log
𝑁
𝑁𝑡
Wikipedia TF-IDF Dataset Release
Nall: total articles
𝑁𝑡: articles with term t
Term Nt Nall idf
the 5,457,533 5,989,879 0.09
disease 67,085 5.989,879 4.49
encephalitis 904 5,989,879 8.80
TextRank (based on graph of co-occurrence words)
Important words are
surrounded by other
important words.
Word distance: 2 ~ 10
Similar to PageRank
Python Lib: Summa
YAKE (Yet Another Keyword Extractor)
Paper published in 2020
Jellyfish package is used to calculate word distance
KeyBERT (Keyword Extraction with BERT)
SentenceTransformer: word embedding for article and keywords
Supported Pretrained Models:
• stsb-roberta-large 1.31G
• nli-roberta-large 1.31G
• distilbert-base-nli-mean-tokens 244M
0 1 2 3 4 5 6 … 1023
Article 1.35 0.98 -0.34 0.94 -0.17 1.38 -0.07 … 1.09
Key 1 0.04 -0.22 -0.87 0.92 0.82 1.15 0.14 … 1.71
Then compute the similarity between the article and keywords
Setence meaning can
be pooled from:
• [CLS]
• Mean of all words
• Max of all words](https://image.slidesharecdn.com/naturallanguageprocessingandtransformermodels-220212124442/75/Natural-language-processing-and-transformer-models-24-2048.jpg)
![2
5
File Operation
f = open(filename, mode) f.close()
f.readline() f.read(n) f.write(message)
for line in f: do_something(line)
df = pd.read_csv(filename) df.to_csv(filename)
Extract Text from HTML File
from bs4 import BeautifulSoup
html_soup = BeautifulSoup(html_str, 'html.parser')
html_text = html_soup.get_text()
Contraction Expansion
“can’t” → “cannot”; “We’re” → “We are”
Regular expression pattern substitution
Word Comparison
s.startwith(t) s.endswith(t)
t in s
s.isupper() s.islower() s.istitle()
s.isalpha() s.isdigit() s.isalmum()
String Operations
s.lower() s.upper() s.titlecase()
s.split(t) s.splitlines() s.join(t)
s.strip() s.rstrip()
s.find(t) s.rfint(t) s.replace(u,v)
Regular Expression
import re
Remove punctuation: re.sub(r'[^ws]',‘’,s) w: word characters, s: whitespace
Find call out: re.search(‘@[A-Za-z0-9_]+’, s) re.search(@[w]+, s)
Remove Stop Words [NLTK: Natural Language Toolkit]
from nltk.corpus import stopwords
nltk.download()
stop = stopwords.words('english')
" ".join(x for x in s.split() if x not in stop)
Tokenization
nltk.word_tokenize(text)
nltk.sent_tokenize(text)
Stemming
“fish”, “fishing”, “fishes” → “fish”, “leaves” → “leav”
porter = nltk.PorterStemmer()
porter.stem(‘fishing’)
Lemmatization
“good”, “better”, “best” → “good”, “leaves” → “leaf”
lemma = nltk.WordNetLemmatizer()
lemma.lemmatize(‘leaves’)
Part of Speech (POS) Tagging
nltk.pos_tag()](https://image.slidesharecdn.com/naturallanguageprocessingandtransformermodels-220212124442/75/Natural-language-processing-and-transformer-models-25-2048.jpg)
![2
6
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
import torch
import transformers as ppb
df = pd.read_csv('https://github.com/clairett/pytorch-sentiment-classification/raw/master/data/SST2/train.tsv',
delimiter='t', header=None)
model_class, tokenizer_class, pretrained_weights = (ppb.BertModel, ppb.BertTokenizer, 'bert-base-uncased’)
tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
model = model_class.from_pretrained(pretrained_weights)
tokenized = df[0].apply((lambda x: tokenizer.encode(x, add_special_tokens=True)))
max_len = max(len(x) for x in tokenized.values)
padded = np.array([i + [0] * (max_len - len(i)) for i in tokenized.values])
attention_mask = np.where(padded != 0, 1, 0)
input_ids = torch.tensor(padded).to(torch.int64)
attention_mask = torch.tensor(attention_mask).to(torch.int64)
with torch.no_grad():
last_hidden_states = model(input_ids, attention_mask=attention_mask)
features = last_hidden_states[0][:, 0, :].numpy()
labels = df[1]
train_features, test_features, train_labels, test_labels = train_test_split(features, labels)
lr_clf = LogisticRegression()
lr_clf.fit(train_features, train_labels)
lr_clf.score(test_features, test_labels)
df
tokenized
Sentence embedding in [CLS]
Logistic regression is applied to the 768 embedding values of each
sentence to decide its sentiment classification.
Result: 0.86
Colab](https://image.slidesharecdn.com/naturallanguageprocessingandtransformermodels-220212124442/75/Natural-language-processing-and-transformer-models-26-2048.jpg)
![27
Context-based Embedding
Sentence A: He got bit by Python.
Sentence B: Python is my favorite programming language.
BERT Configurations
L (# of encoders) A (attention heads) H (hidden units)
Bert-base 12 12 768
Bert-large 24 16 1024
BERT uses Wordpiece Tokenizer
"Let us start pretraining the model."
tokens = [let, us, start, pre, ##train, ##ing, the, model]
Masked Language Model
The feedforward network
takes representation of masked
token as input and returns the
probability of all the words in
our vocabulary to be the
masked word](https://image.slidesharecdn.com/naturallanguageprocessingandtransformermodels-220212124442/75/Natural-language-processing-and-transformer-models-27-2048.jpg)

![30
Extractive summarization
• Pick important sentences from a text.
• Add [CLS] to represent each sentences and judge
whether the sentence should be included.
Abstractive summarization
• Paraphrasing the given text and holding
essential meaning.
Fine-tune BERT for Extractive Summarization Text Summarization with Pretrained Encoders](https://image.slidesharecdn.com/naturallanguageprocessingandtransformermodels-220212124442/75/Natural-language-processing-and-transformer-models-30-2048.jpg)
![3
1
monoBERT
The final representation of the token is fed to a fully-connected layer that
produces the [CLS] relevance score s of that text with respect to the query.
Birch](https://image.slidesharecdn.com/naturallanguageprocessingandtransformermodels-220212124442/75/Natural-language-processing-and-transformer-models-31-2048.jpg)








![9
Text-to-Text Transfer Transformer)
Unified Multi-Task Framework: Text as Input, Text as Output
Cola: Corpus of Linguistic Acceptability
STSB: Semantic Textual Similarity Benchmark
RTE: Recognizing Textual Entailment
MNLI: Multi-Genre Natural Language Inference
MRPC: Microsoft Research Paraphrase Corpus
SQuAD: Stanford Question Answering Dataset
WMT English to German
COPA: Choice of Plausible Alternatives, causal reasoning
MultiRC: Multi-Sentence Reading Comprehension
WiC
Word in Context
WSC: Winograd Schema Challenge, resolve ambiguity
The city councilmen refused the demonstrators a permit
because they [feared/advocated] violence.
Question: “they” refers to?
Transfer Learning with C4 – Colossal Cleaned Crawl Corpus (~800G), base model with 220M parameters, large model 770M, largest 11B
T5 GitHub Paper 2020 Python](https://crownmelresort.com/image.slidesharecdn.com/naturallanguageprocessingandtransformermodels-220212124442/75/Natural-language-processing-and-transformer-models-9-2048.jpg)













![2
3
N-Gram and Probability [Corpus: I am happy because I am learning]
• Unigram: {I, am, happy, because, learning} 𝑃 𝐼 =
𝐶 𝐼
𝐶(𝐴𝑙𝑙)
=
2
7
• Bigram: {I am, am happy, happy because…} 𝑃 ℎ𝑎𝑝𝑝𝑦 | 𝑎𝑚 =
𝐶 𝑎𝑚 ℎ𝑎𝑝𝑝𝑦
𝐶 𝑎𝑚
=
1
2
• Trigram: {I am happy, am happy because…} 𝑃 ℎ𝑎𝑝𝑝𝑦 | 𝐼 𝑎𝑚 =
𝐶 𝐼 𝑎𝑚 ℎ𝑎𝑝𝑝𝑦
𝐶 𝐼 𝑎𝑚
=
1
2
Approximation of Sequence Probability
• Use N-Gram for approximation since long sequences are rare
Use Bigram: 𝑃 𝑡ℎ𝑒 𝑡𝑒𝑎𝑐ℎ𝑒𝑟 𝑑𝑟𝑖𝑛𝑘𝑠 𝑡𝑒𝑎 ≈ 𝑃 𝑡ℎ𝑒 𝑃 𝑡𝑒𝑎𝑐ℎ𝑒𝑟 𝑡ℎ𝑒 𝑃 𝑑𝑟𝑖𝑛𝑘𝑠 𝑡𝑒𝑎𝑐ℎ𝑒𝑟 𝑃 𝑡𝑒𝑎 𝑑𝑟𝑖𝑛𝑘𝑠
• Interpolation for handle missing terms
Trigram: 𝑃 𝑡𝑒𝑎|𝑡𝑒𝑎𝑐ℎ𝑒𝑟 𝑑𝑟𝑖𝑛𝑘𝑠 ≈ 0.7 × 𝑃 𝑡𝑒𝑎 𝑡𝑒𝑎𝑐ℎ𝑒𝑟 𝑑𝑟𝑖𝑛𝑘𝑠 + 0.2 × 𝑃 𝑡𝑒𝑎 𝑑𝑟𝑖𝑛𝑘𝑠 + 0.1 × 𝑃(tea)
• Add start and end token of sentence: <s> the teacher drinks tea </s>
𝑃 𝑡ℎ𝑒 𝑡𝑒𝑎𝑐ℎ𝑒𝑟 𝑑𝑟𝑖𝑛𝑘𝑠 𝑡𝑒𝑎 ≈ 𝑃 𝑡ℎ𝑒| < 𝑠 > 𝑃 𝑡𝑒𝑎𝑐ℎ𝑒𝑟 𝑡ℎ𝑒 𝑃 𝑑𝑟𝑖𝑛𝑘𝑠 𝑡𝑒𝑎𝑐ℎ𝑒𝑟 𝑃 𝑡𝑒𝑎 𝑑𝑟𝑖𝑛𝑘𝑠 P(</s>|tea)
Probability Matrix [Corpus: I study I learn]
Applications
Auto Complete
Generative Text
Python code](https://crownmelresort.com/image.slidesharecdn.com/naturallanguageprocessingandtransformermodels-220212124442/75/Natural-language-processing-and-transformer-models-23-2048.jpg)
![24
TF -IDF (Term Frequency – Inverse Document Frequency)
tf = frequency of a term in a document
𝑖𝑑𝑓 = log
𝑁𝑎𝑙𝑙
𝑁𝑡
,
tf - idf = 𝑡𝑓 × 𝑖𝑑𝑓 = 𝑡𝑓 × log
𝑁
𝑁𝑡
Wikipedia TF-IDF Dataset Release
Nall: total articles
𝑁𝑡: articles with term t
Term Nt Nall idf
the 5,457,533 5,989,879 0.09
disease 67,085 5.989,879 4.49
encephalitis 904 5,989,879 8.80
TextRank (based on graph of co-occurrence words)
Important words are
surrounded by other
important words.
Word distance: 2 ~ 10
Similar to PageRank
Python Lib: Summa
YAKE (Yet Another Keyword Extractor)
Paper published in 2020
Jellyfish package is used to calculate word distance
KeyBERT (Keyword Extraction with BERT)
SentenceTransformer: word embedding for article and keywords
Supported Pretrained Models:
• stsb-roberta-large 1.31G
• nli-roberta-large 1.31G
• distilbert-base-nli-mean-tokens 244M
0 1 2 3 4 5 6 … 1023
Article 1.35 0.98 -0.34 0.94 -0.17 1.38 -0.07 … 1.09
Key 1 0.04 -0.22 -0.87 0.92 0.82 1.15 0.14 … 1.71
Then compute the similarity between the article and keywords
Setence meaning can
be pooled from:
• [CLS]
• Mean of all words
• Max of all words](https://crownmelresort.com/image.slidesharecdn.com/naturallanguageprocessingandtransformermodels-220212124442/75/Natural-language-processing-and-transformer-models-24-2048.jpg)
![2
5
File Operation
f = open(filename, mode) f.close()
f.readline() f.read(n) f.write(message)
for line in f: do_something(line)
df = pd.read_csv(filename) df.to_csv(filename)
Extract Text from HTML File
from bs4 import BeautifulSoup
html_soup = BeautifulSoup(html_str, 'html.parser')
html_text = html_soup.get_text()
Contraction Expansion
“can’t” → “cannot”; “We’re” → “We are”
Regular expression pattern substitution
Word Comparison
s.startwith(t) s.endswith(t)
t in s
s.isupper() s.islower() s.istitle()
s.isalpha() s.isdigit() s.isalmum()
String Operations
s.lower() s.upper() s.titlecase()
s.split(t) s.splitlines() s.join(t)
s.strip() s.rstrip()
s.find(t) s.rfint(t) s.replace(u,v)
Regular Expression
import re
Remove punctuation: re.sub(r'[^ws]',‘’,s) w: word characters, s: whitespace
Find call out: re.search(‘@[A-Za-z0-9_]+’, s) re.search(@[w]+, s)
Remove Stop Words [NLTK: Natural Language Toolkit]
from nltk.corpus import stopwords
nltk.download()
stop = stopwords.words('english')
" ".join(x for x in s.split() if x not in stop)
Tokenization
nltk.word_tokenize(text)
nltk.sent_tokenize(text)
Stemming
“fish”, “fishing”, “fishes” → “fish”, “leaves” → “leav”
porter = nltk.PorterStemmer()
porter.stem(‘fishing’)
Lemmatization
“good”, “better”, “best” → “good”, “leaves” → “leaf”
lemma = nltk.WordNetLemmatizer()
lemma.lemmatize(‘leaves’)
Part of Speech (POS) Tagging
nltk.pos_tag()](https://crownmelresort.com/image.slidesharecdn.com/naturallanguageprocessingandtransformermodels-220212124442/75/Natural-language-processing-and-transformer-models-25-2048.jpg)
![2
6
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
import torch
import transformers as ppb
df = pd.read_csv('https://github.com/clairett/pytorch-sentiment-classification/raw/master/data/SST2/train.tsv',
delimiter='t', header=None)
model_class, tokenizer_class, pretrained_weights = (ppb.BertModel, ppb.BertTokenizer, 'bert-base-uncased’)
tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
model = model_class.from_pretrained(pretrained_weights)
tokenized = df[0].apply((lambda x: tokenizer.encode(x, add_special_tokens=True)))
max_len = max(len(x) for x in tokenized.values)
padded = np.array([i + [0] * (max_len - len(i)) for i in tokenized.values])
attention_mask = np.where(padded != 0, 1, 0)
input_ids = torch.tensor(padded).to(torch.int64)
attention_mask = torch.tensor(attention_mask).to(torch.int64)
with torch.no_grad():
last_hidden_states = model(input_ids, attention_mask=attention_mask)
features = last_hidden_states[0][:, 0, :].numpy()
labels = df[1]
train_features, test_features, train_labels, test_labels = train_test_split(features, labels)
lr_clf = LogisticRegression()
lr_clf.fit(train_features, train_labels)
lr_clf.score(test_features, test_labels)
df
tokenized
Sentence embedding in [CLS]
Logistic regression is applied to the 768 embedding values of each
sentence to decide its sentiment classification.
Result: 0.86
Colab](https://crownmelresort.com/image.slidesharecdn.com/naturallanguageprocessingandtransformermodels-220212124442/75/Natural-language-processing-and-transformer-models-26-2048.jpg)
![27
Context-based Embedding
Sentence A: He got bit by Python.
Sentence B: Python is my favorite programming language.
BERT Configurations
L (# of encoders) A (attention heads) H (hidden units)
Bert-base 12 12 768
Bert-large 24 16 1024
BERT uses Wordpiece Tokenizer
"Let us start pretraining the model."
tokens = [let, us, start, pre, ##train, ##ing, the, model]
Masked Language Model
The feedforward network
takes representation of masked
token as input and returns the
probability of all the words in
our vocabulary to be the
masked word](https://crownmelresort.com/image.slidesharecdn.com/naturallanguageprocessingandtransformermodels-220212124442/75/Natural-language-processing-and-transformer-models-27-2048.jpg)


![30
Extractive summarization
• Pick important sentences from a text.
• Add [CLS] to represent each sentences and judge
whether the sentence should be included.
Abstractive summarization
• Paraphrasing the given text and holding
essential meaning.
Fine-tune BERT for Extractive Summarization Text Summarization with Pretrained Encoders](https://crownmelresort.com/image.slidesharecdn.com/naturallanguageprocessingandtransformermodels-220212124442/75/Natural-language-processing-and-transformer-models-30-2048.jpg)
![3
1
monoBERT
The final representation of the token is fed to a fully-connected layer that
produces the [CLS] relevance score s of that text with respect to the query.
Birch](https://crownmelresort.com/image.slidesharecdn.com/naturallanguageprocessingandtransformermodels-220212124442/75/Natural-language-processing-and-transformer-models-31-2048.jpg)

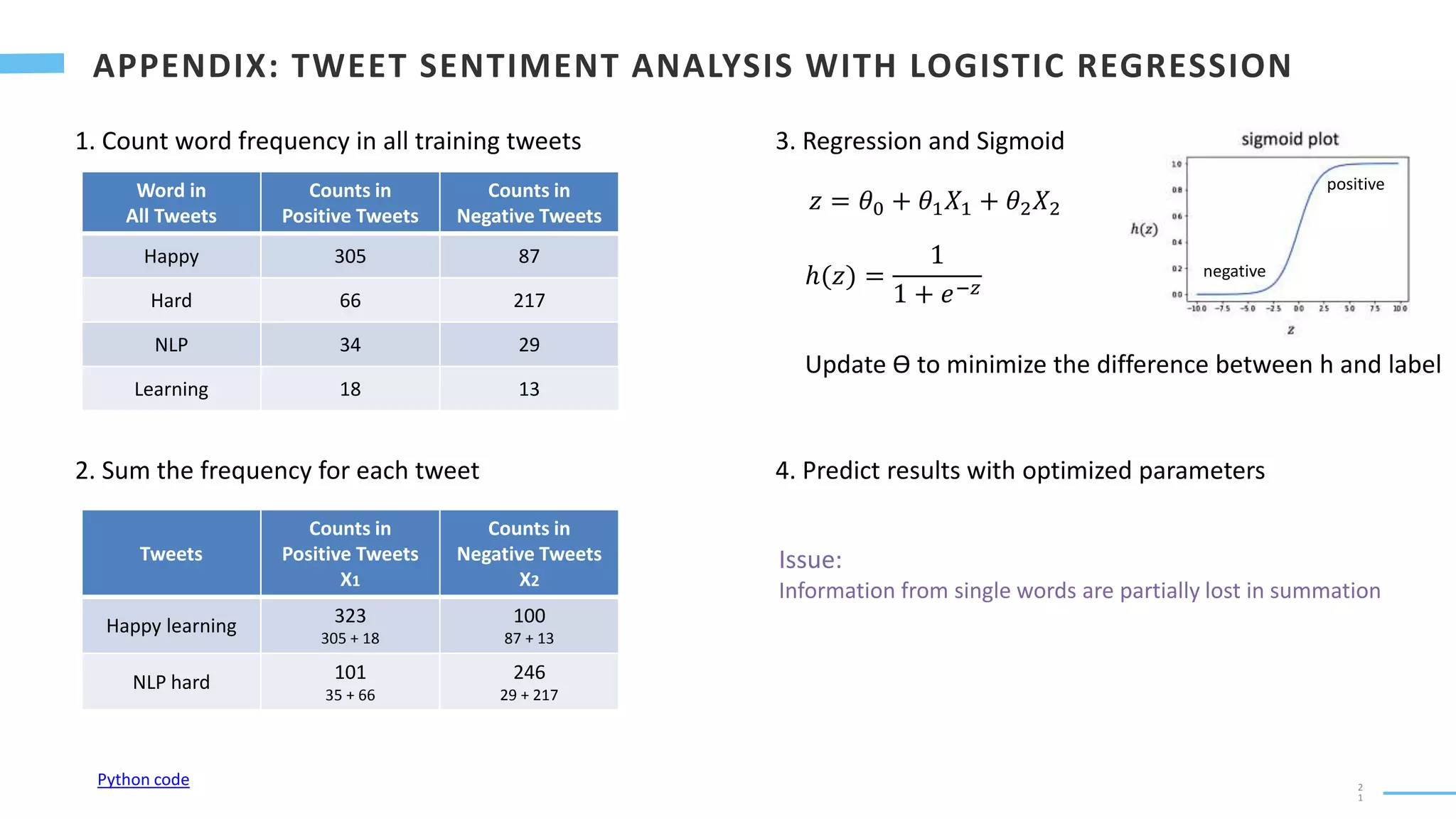
The document discusses several approaches for text classification using machine learning algorithms: 1. Count the frequency of individual words in tweets and sum for each tweet to create feature vectors for classification models like regression. However, this loses some word context information. 2. Use Bayes' rule and calculate word probabilities conditioned on class to perform naive Bayes classification. Laplacian smoothing is used to handle zero probabilities. 3. Incorporate word n-grams and context by calculating word probabilities within n-gram contexts rather than independently. This captures more linguistic information than the first two approaches.















































































