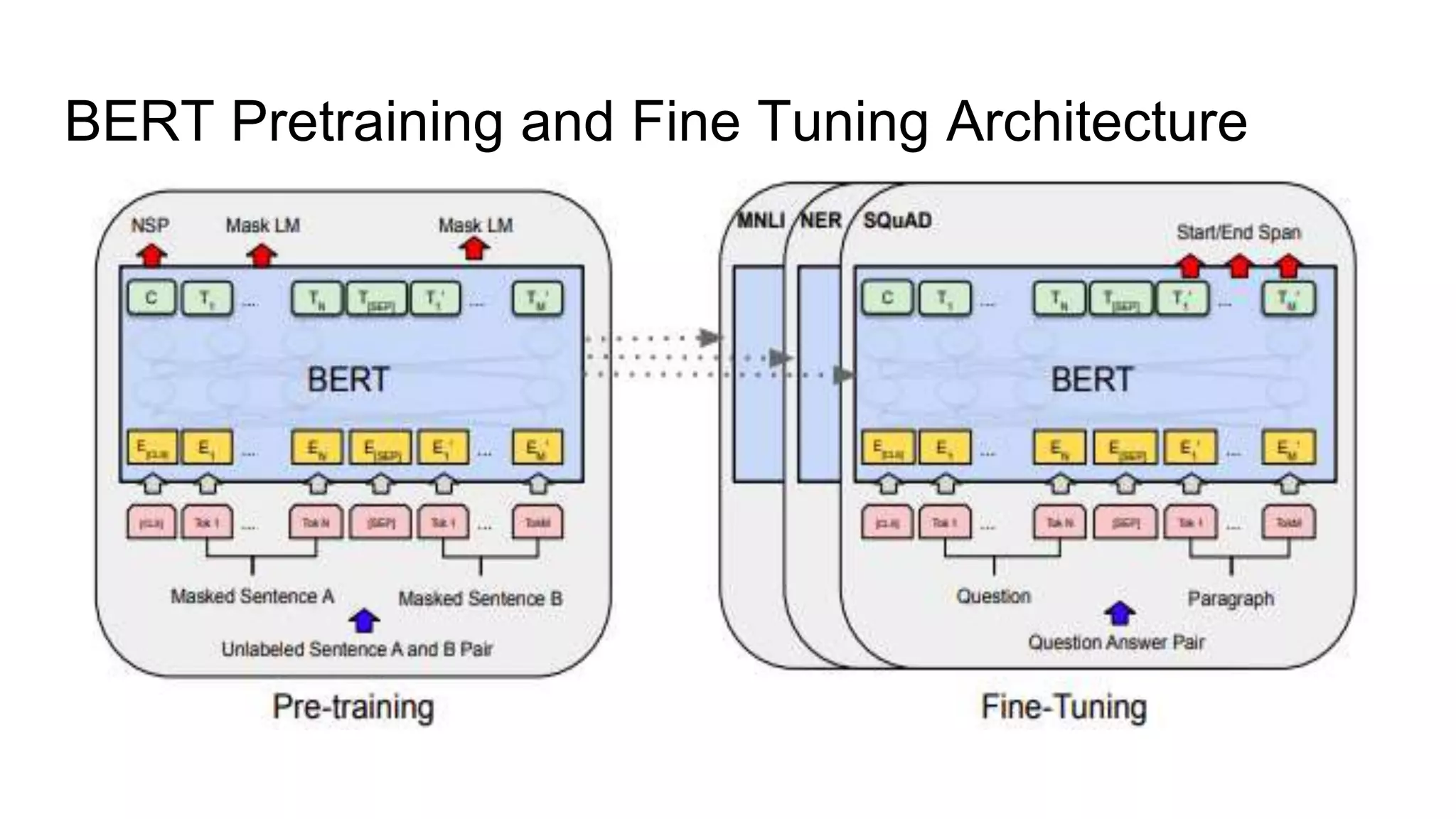
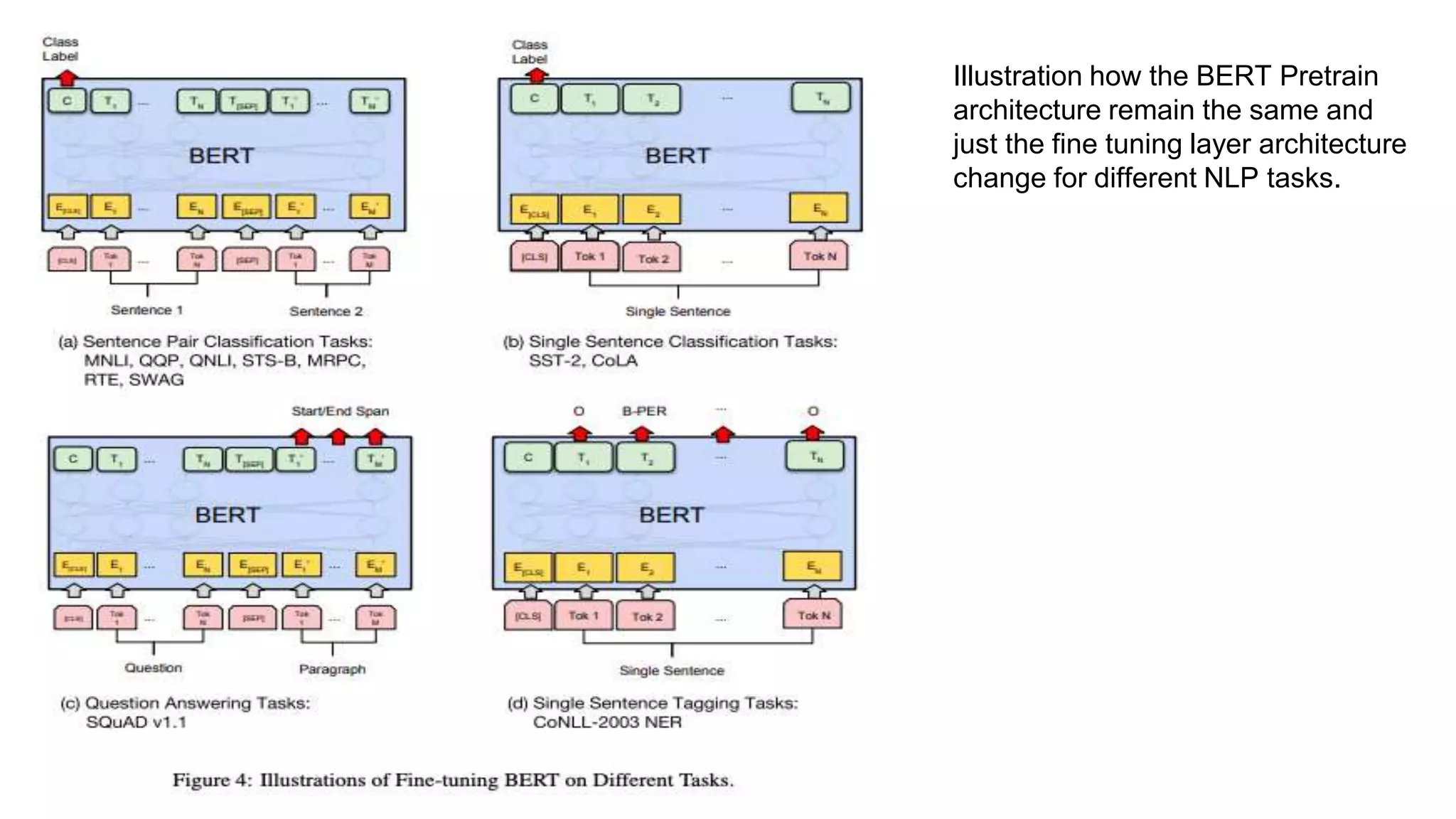
The document outlines BERT (Bidirectional Encoder Representations from Transformers), a pretrained model by Google that excels in various natural language processing tasks through its bidirectional context learning and attention mechanisms. It explains BERT's architecture, including its masked language modeling and next sentence prediction tasks, as well as its ability to handle out-of-vocabulary words through a word piece tokenizer. BERT's effectiveness and applications are highlighted, indicating its potential for practical uses in areas such as text classification and sentiment analysis.







![What does BERT learn, how it tokenize and handle
OOV?
Consider the input example:- I went to the store. At the store, I bought fresh
strawberries.
BERT uses a WORD PIECE Tokenizer which breaks a OOV(out of vocab) word
into segments. For example, if play, ##ing, and ##ed are present in the
vocabulary but playing and played are OOV words then they will be broken down
into play + ##ing and play + ##ed respectively. (## is used to represent sub-
words).
BERT also requires a [CLS] special classifier token at beginning and [SEP] at end
of a sequence.
[CLS] I went to the store. [SEP] At the store I bought fresh straw ##berries.[SEP]](https://image.slidesharecdn.com/bertbidirectionalencoderrepresentationfromtransformer1-190716142412/75/NLP-State-of-the-Art-BERT-8-2048.jpg)
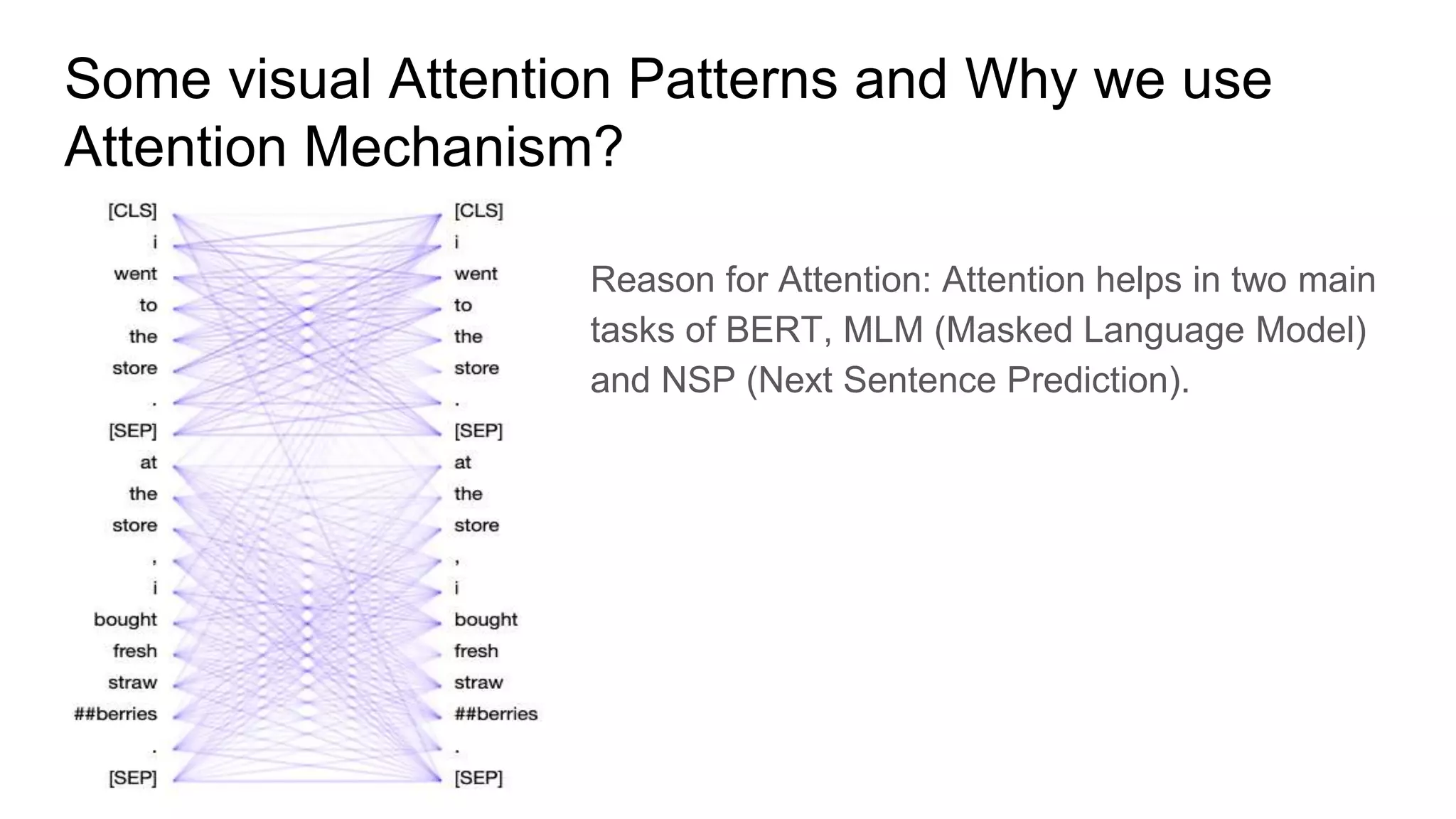
![Visual Pattern from Attention mechanism
● Attention to next word. [ Layer 2, Head 0 ] | Backward RNN
● Attention to Previous word. [Layer 0, Head 2 ] | Forward RNN
● Attention to identical/related word.
● Attention to identical words in other sentence. | Helps in nextsentence prediction task
● Attention to other words predictive of word.
● Attention to delimiter tokens [CLS], [SEP]
● Attention to Bag of Words.](https://image.slidesharecdn.com/bertbidirectionalencoderrepresentationfromtransformer1-190716142412/75/NLP-State-of-the-Art-BERT-11-2048.jpg)

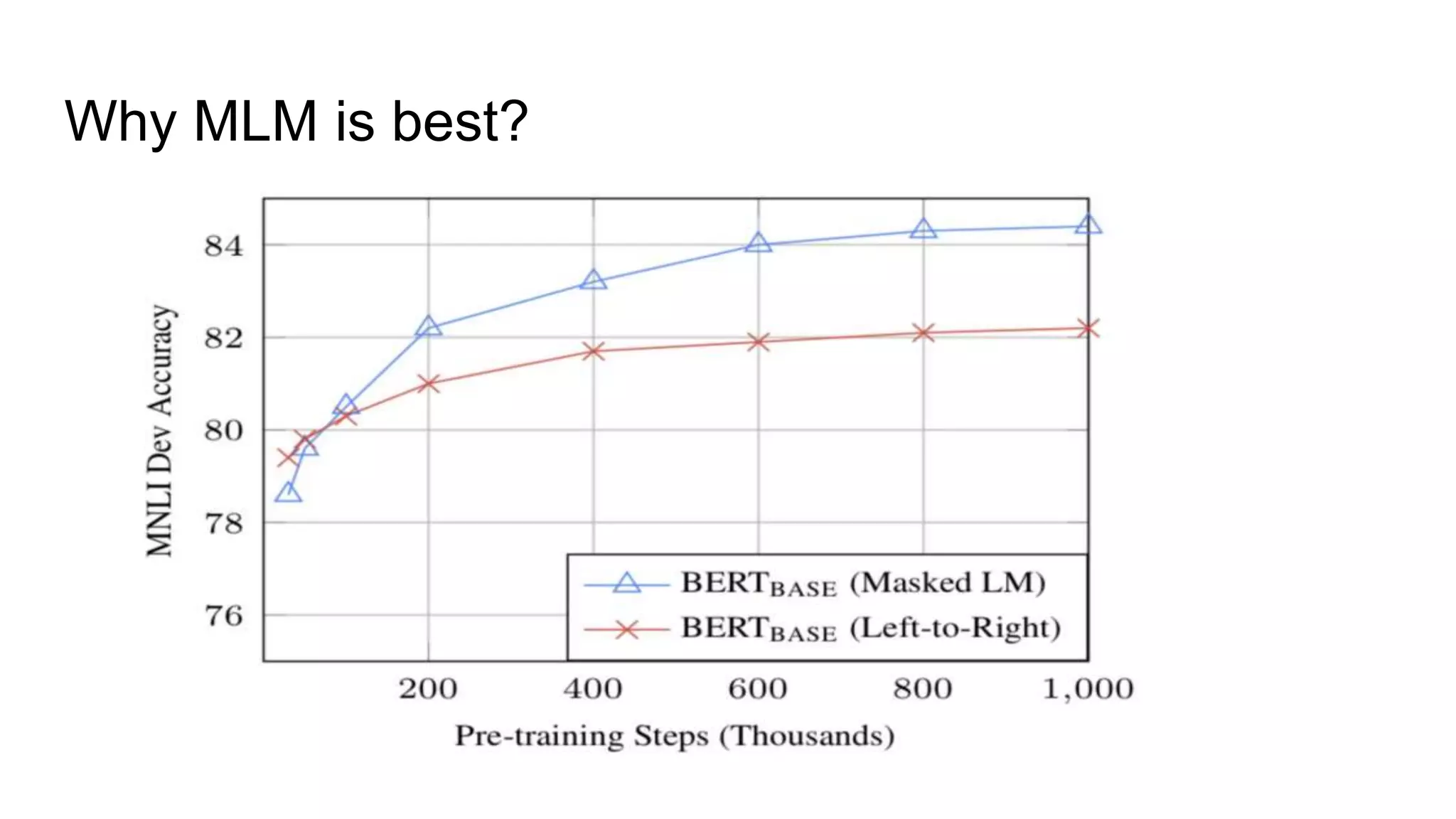
![MLM: Masked Language Model
Input: My dog is hairy.
Masking is done randomly, and 15% of all WordPiece tokens in each input
sequence in masked. We only predict the masked tokens rather than predicting
the entire input sequence.
Procedure:
+ 80% of the time: Replace the word with [MASK]. My dog is [MASK].
+ 10% of time: Replace word randomly. My dog is apple.
+ 10% of time: Keep same My dog is hairy.](https://image.slidesharecdn.com/bertbidirectionalencoderrepresentationfromtransformer1-190716142412/75/NLP-State-of-the-Art-BERT-13-2048.jpg)



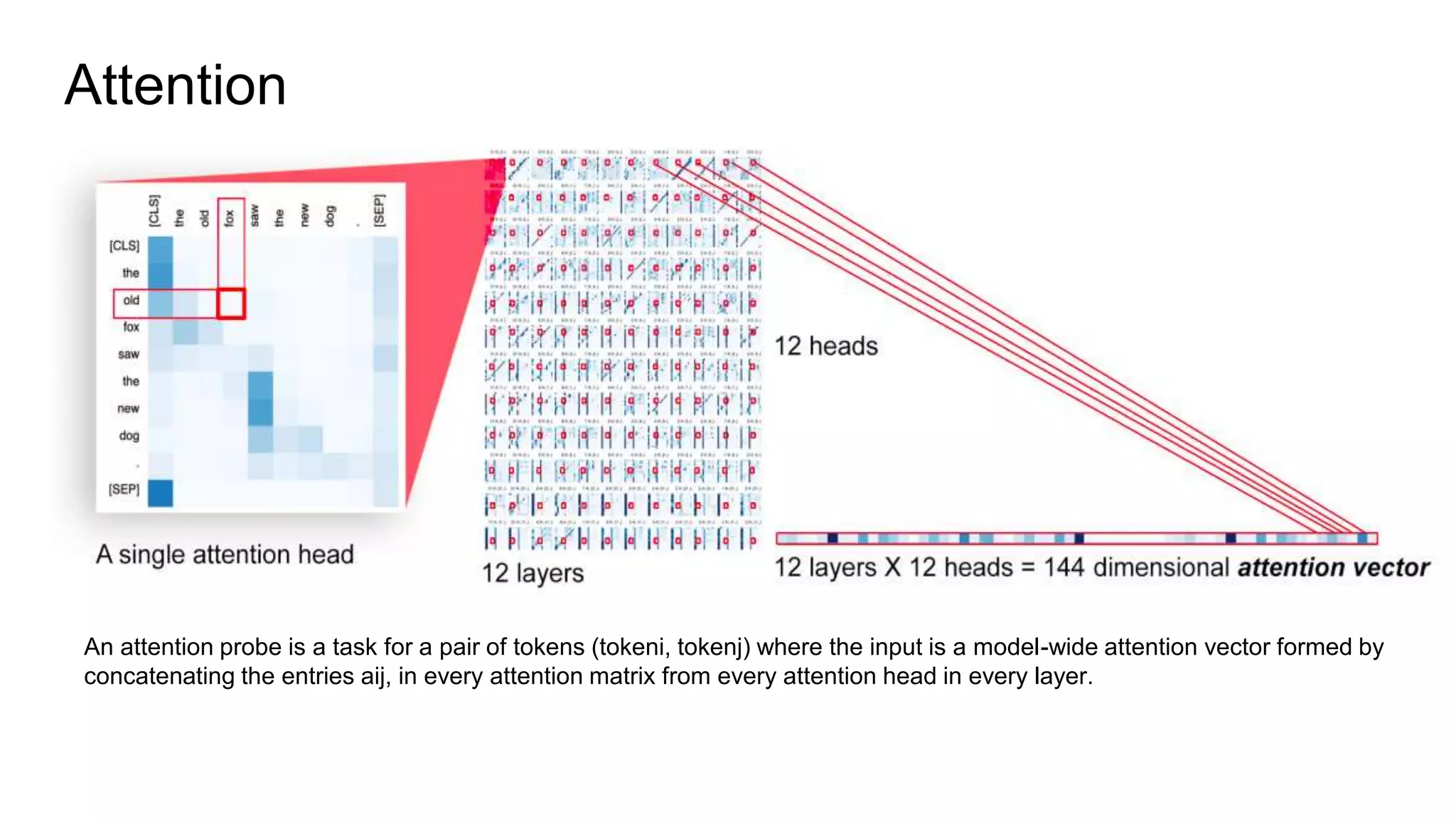
![How BERT Outperforms others?
In the paper Visualizing and Measuring the Geometry of BERT, we prove how
BERT holds semantic and syntax features of a text.
In this paper aims to show how attention matrix contains grammatical
representations. Turning to semantics, using visualizations of the activations
created by different pieces of text, we show suggestive evidence that BERT
distinguishes word senses at a very fine level.
BERT’s internals consist of two parts. First, an initial embedding for each token is created by combining a
pre-trained word piece embedding with position and segment information. Next, this initial sequence of
embeddings is run through multiple transformer layers, producing a new sequence of context embeddings
at each step. Implicit in each transformer layer is a set of attention matrices, one for each attention head,
each of which contains a scalar value for each ordered pair (tokeni , tokenj ). [SLIDE 11]](https://image.slidesharecdn.com/bertbidirectionalencoderrepresentationfromtransformer1-190716142412/75/NLP-State-of-the-Art-BERT-20-2048.jpg)
![Experiment for Syntax Representation
Experiment on corpus of Penn TreeBank (3.1M dependency relations). With
PyStanford Dependency Library we found the grammatical dependency on which
we ran BERT-base through each sentence and obtained model-wide attention
matrix. [ SLIDE 9].
On this dataset we train test split of 30% and achieve an accuracy of 85.8% on
binary probe and 71.9% on multiclass probe.
Proved: Attention mechanism contains syntactic features.](https://image.slidesharecdn.com/bertbidirectionalencoderrepresentationfromtransformer1-190716142412/75/NLP-State-of-the-Art-BERT-21-2048.jpg)











![What does BERT learn, how it tokenize and handle
OOV?
Consider the input example:- I went to the store. At the store, I bought fresh
strawberries.
BERT uses a WORD PIECE Tokenizer which breaks a OOV(out of vocab) word
into segments. For example, if play, ##ing, and ##ed are present in the
vocabulary but playing and played are OOV words then they will be broken down
into play + ##ing and play + ##ed respectively. (## is used to represent sub-
words).
BERT also requires a [CLS] special classifier token at beginning and [SEP] at end
of a sequence.
[CLS] I went to the store. [SEP] At the store I bought fresh straw ##berries.[SEP]](https://crownmelresort.com/image.slidesharecdn.com/bertbidirectionalencoderrepresentationfromtransformer1-190716142412/75/NLP-State-of-the-Art-BERT-8-2048.jpg)


![Visual Pattern from Attention mechanism
● Attention to next word. [ Layer 2, Head 0 ] | Backward RNN
● Attention to Previous word. [Layer 0, Head 2 ] | Forward RNN
● Attention to identical/related word.
● Attention to identical words in other sentence. | Helps in nextsentence prediction task
● Attention to other words predictive of word.
● Attention to delimiter tokens [CLS], [SEP]
● Attention to Bag of Words.](https://crownmelresort.com/image.slidesharecdn.com/bertbidirectionalencoderrepresentationfromtransformer1-190716142412/75/NLP-State-of-the-Art-BERT-11-2048.jpg)

![MLM: Masked Language Model
Input: My dog is hairy.
Masking is done randomly, and 15% of all WordPiece tokens in each input
sequence in masked. We only predict the masked tokens rather than predicting
the entire input sequence.
Procedure:
+ 80% of the time: Replace the word with [MASK]. My dog is [MASK].
+ 10% of time: Replace word randomly. My dog is apple.
+ 10% of time: Keep same My dog is hairy.](https://crownmelresort.com/image.slidesharecdn.com/bertbidirectionalencoderrepresentationfromtransformer1-190716142412/75/NLP-State-of-the-Art-BERT-13-2048.jpg)






![How BERT Outperforms others?
In the paper Visualizing and Measuring the Geometry of BERT, we prove how
BERT holds semantic and syntax features of a text.
In this paper aims to show how attention matrix contains grammatical
representations. Turning to semantics, using visualizations of the activations
created by different pieces of text, we show suggestive evidence that BERT
distinguishes word senses at a very fine level.
BERT’s internals consist of two parts. First, an initial embedding for each token is created by combining a
pre-trained word piece embedding with position and segment information. Next, this initial sequence of
embeddings is run through multiple transformer layers, producing a new sequence of context embeddings
at each step. Implicit in each transformer layer is a set of attention matrices, one for each attention head,
each of which contains a scalar value for each ordered pair (tokeni , tokenj ). [SLIDE 11]](https://crownmelresort.com/image.slidesharecdn.com/bertbidirectionalencoderrepresentationfromtransformer1-190716142412/75/NLP-State-of-the-Art-BERT-20-2048.jpg)
![Experiment for Syntax Representation
Experiment on corpus of Penn TreeBank (3.1M dependency relations). With
PyStanford Dependency Library we found the grammatical dependency on which
we ran BERT-base through each sentence and obtained model-wide attention
matrix. [ SLIDE 9].
On this dataset we train test split of 30% and achieve an accuracy of 85.8% on
binary probe and 71.9% on multiclass probe.
Proved: Attention mechanism contains syntactic features.](https://crownmelresort.com/image.slidesharecdn.com/bertbidirectionalencoderrepresentationfromtransformer1-190716142412/75/NLP-State-of-the-Art-BERT-21-2048.jpg)






![[Paper review] BERT](https://cdn.slidesharecdn.com/ss_thumbnails/paperreviewbert-190507052754-thumbnail.jpg?width=640&height=640&fit=bounds)