Downloaded 27 times



![Language Modelling
𝑃(𝑤𝑡|𝑤𝑡−1, 𝑤𝑡−2, … )
See you later […]
alligator
today
𝑃(𝑤𝑡|𝑤𝑡+1, 𝑤𝑡+2, … )
[…] abhors a vacuum
Nature
Fido](https://image.slidesharecdn.com/naturallanguageprocessingadvances-191007035949/75/Recent-Advances-in-Natural-Language-Processing-4-2048.jpg)













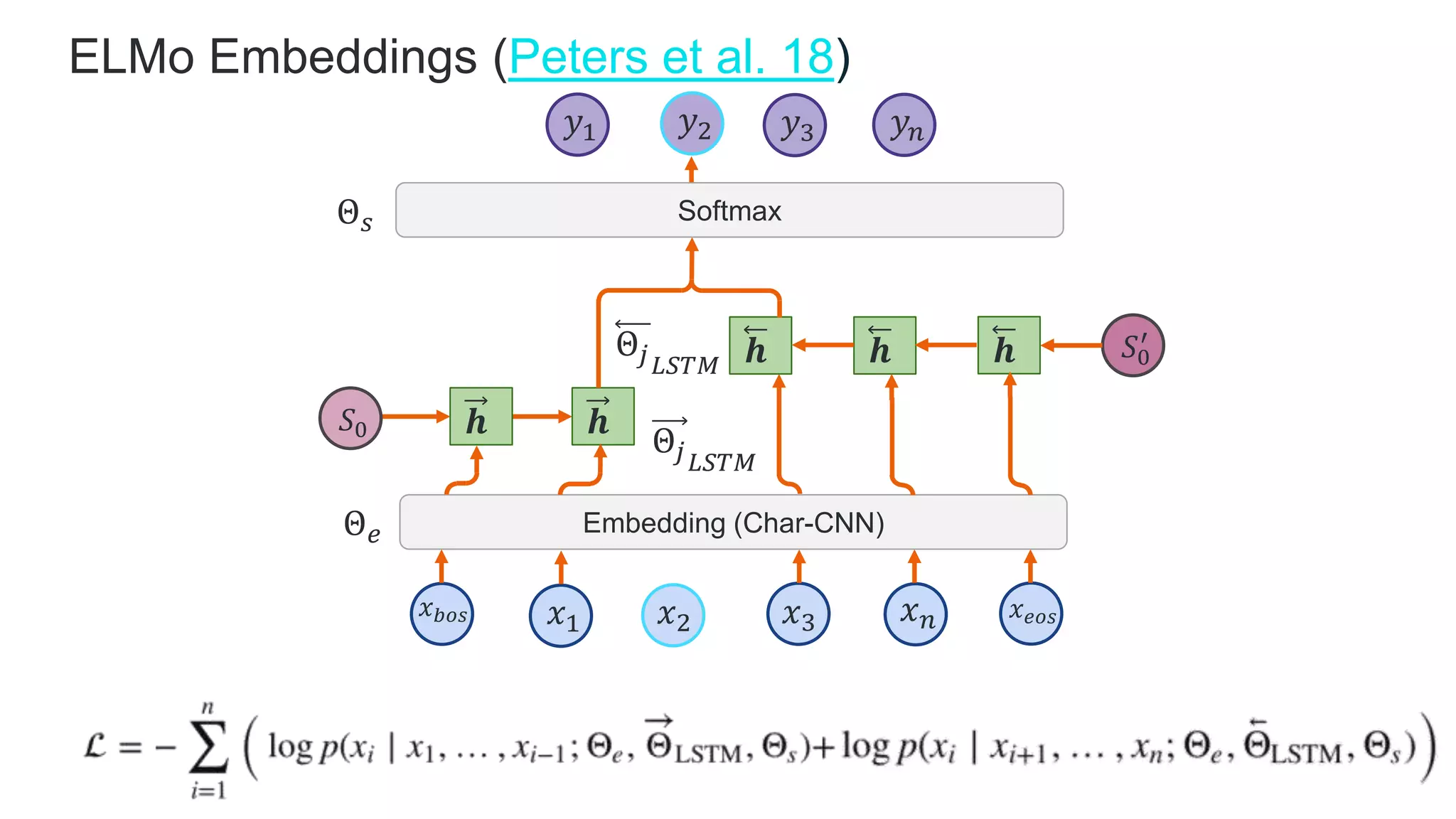
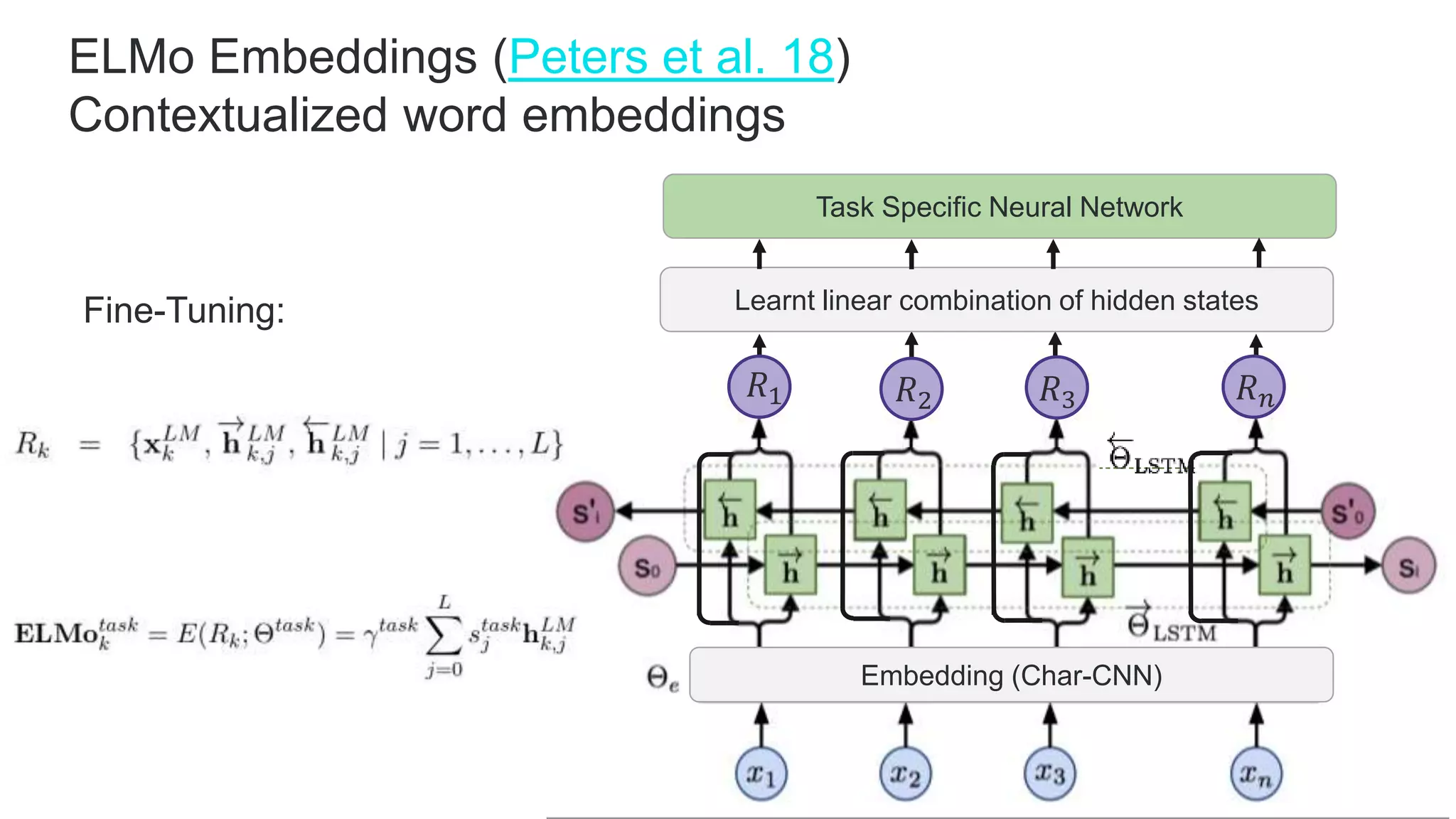

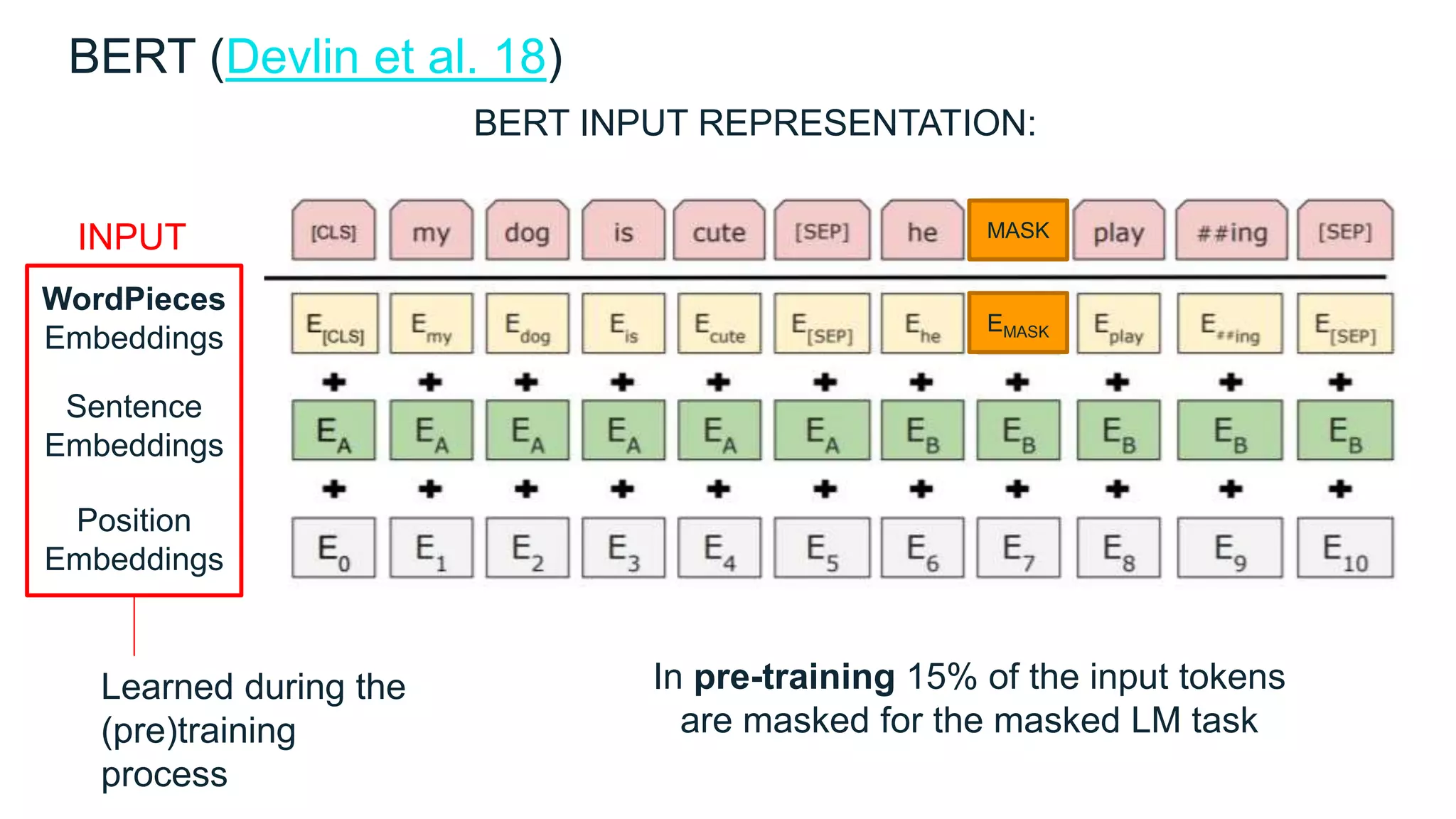
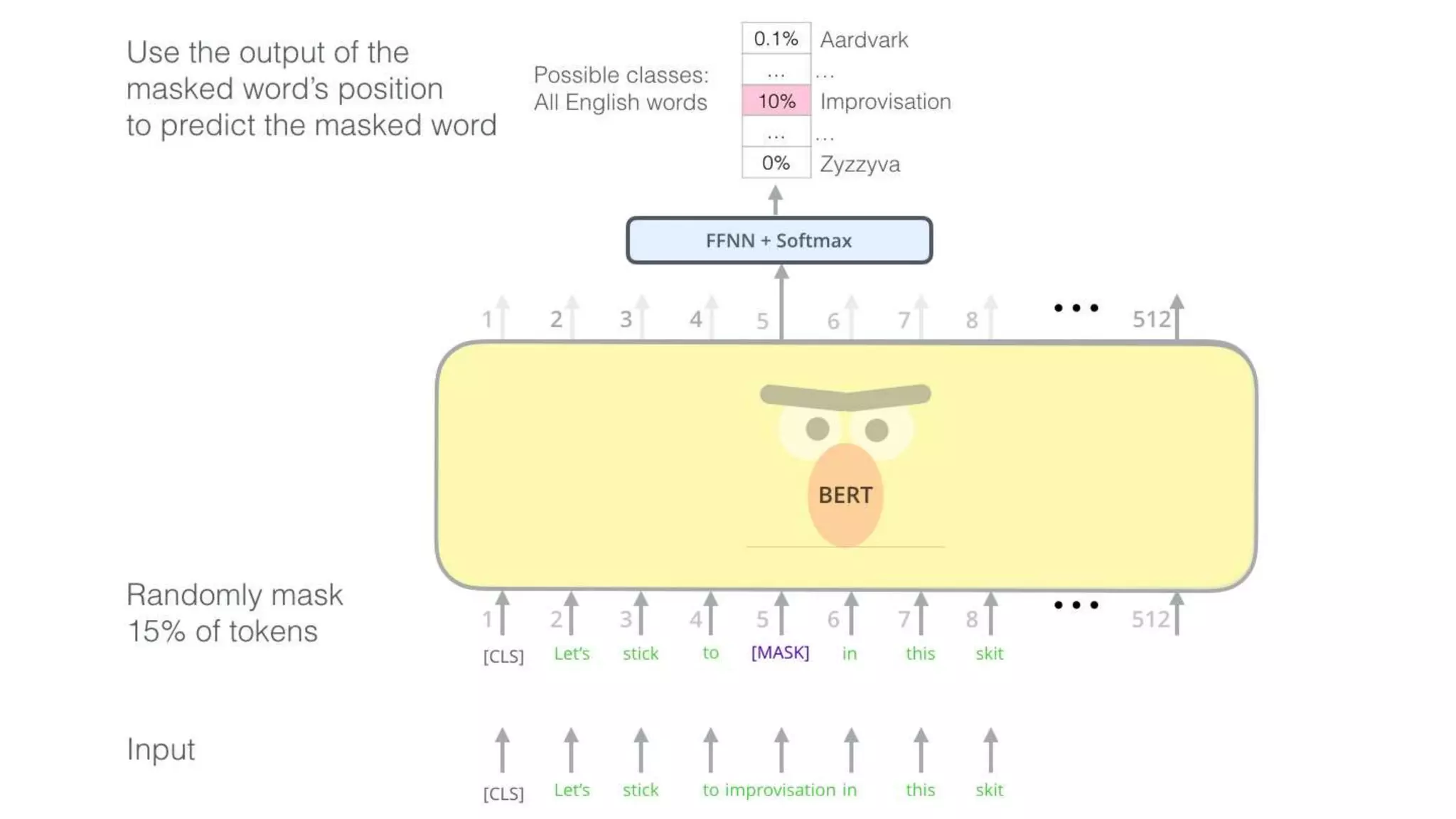
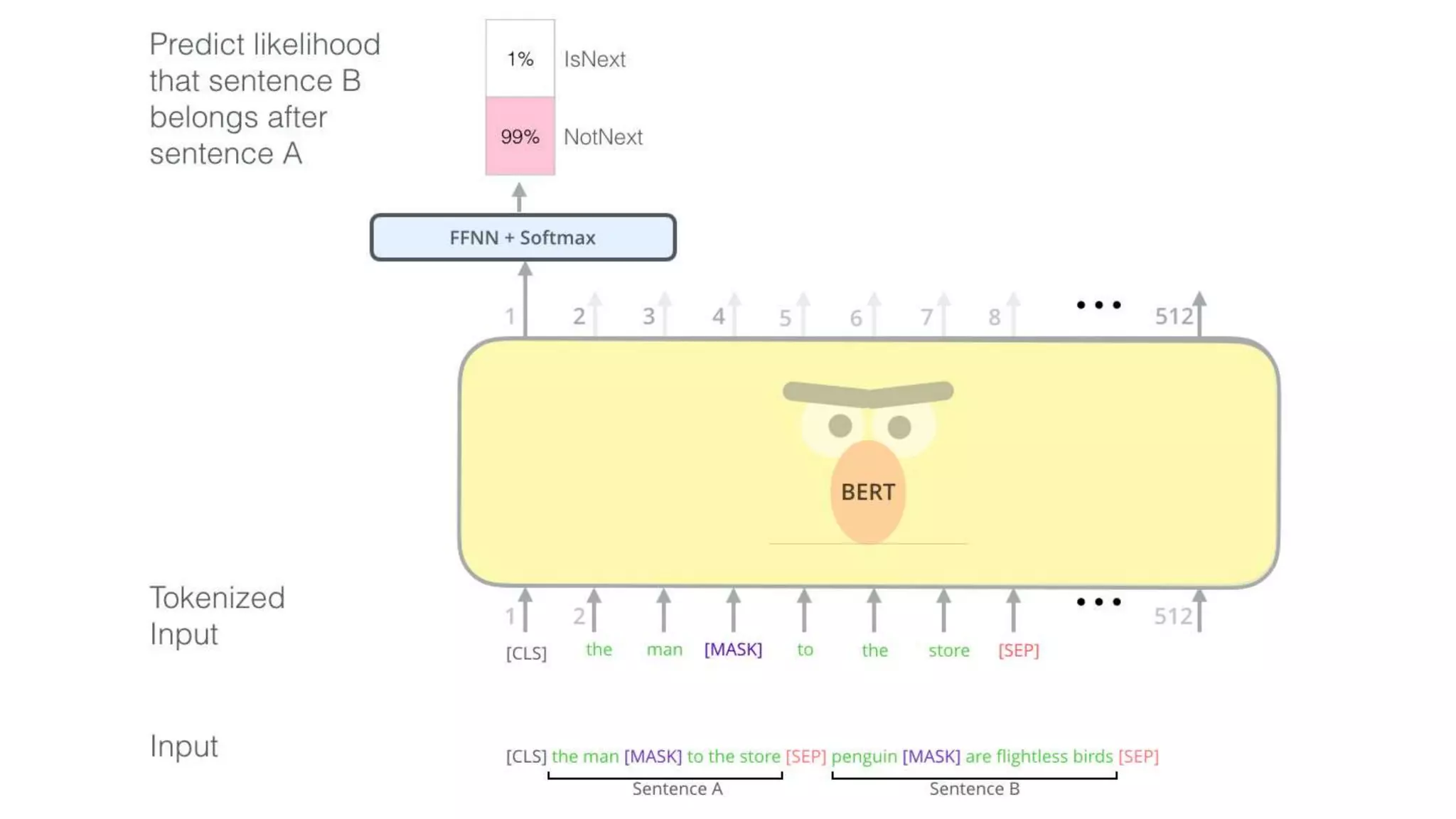
![Training objects in slightly modified BERT models for downstream
tasks. (Image source: original paper)
Fine-tuning
For classification tasks:
token 𝐶𝐿𝑆 , 𝒉 𝐿
[𝐶𝐿𝑆]
Small weight matrix W:
𝑠𝑜𝑓𝑡𝑚𝑎𝑥(𝒉 𝐿
𝐶𝐿𝑆
𝑾 𝐶𝐿𝑆)
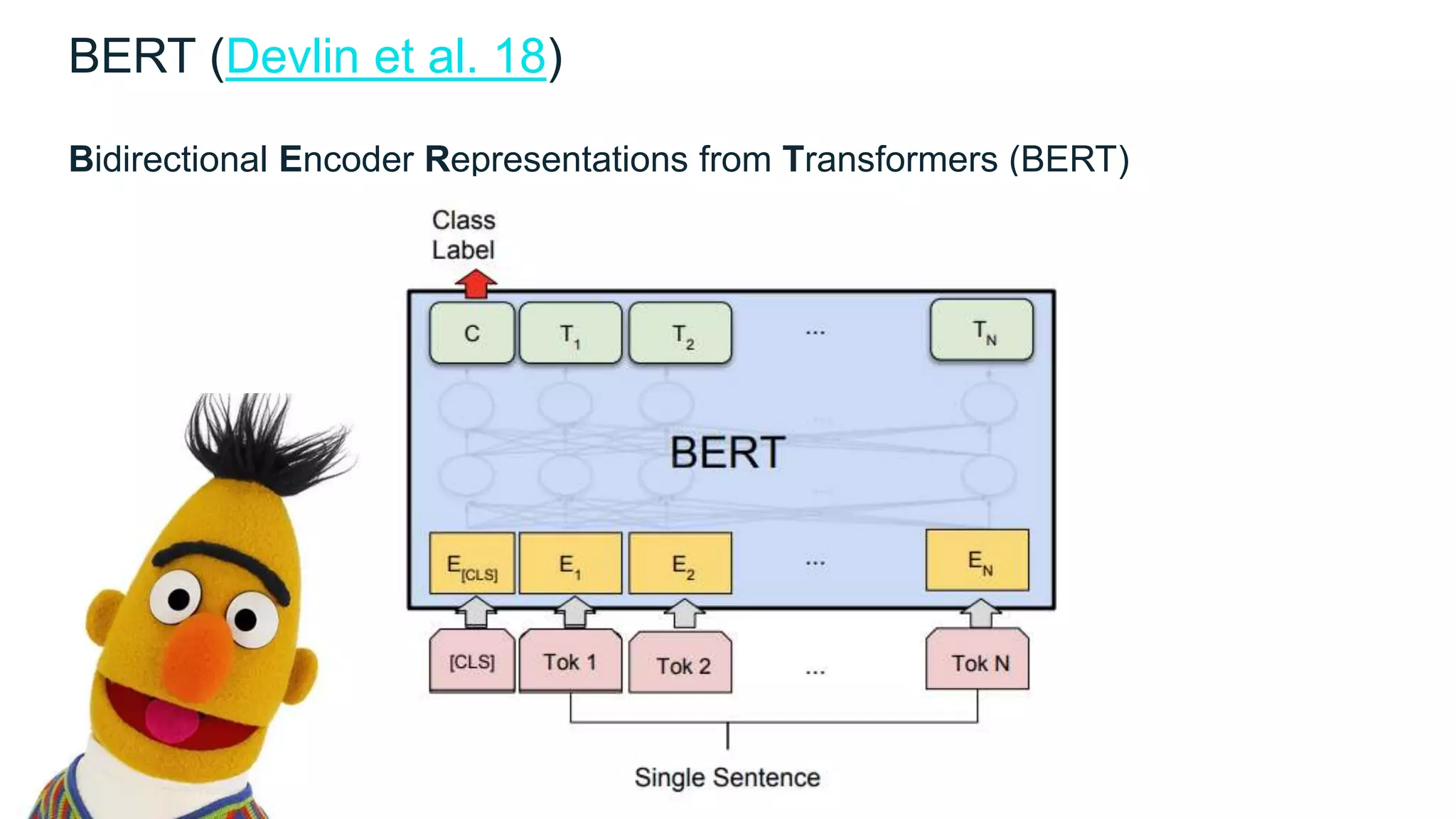
BERT (Devlin et al. 18)](https://image.slidesharecdn.com/naturallanguageprocessingadvances-191007035949/75/Recent-Advances-in-Natural-Language-Processing-47-2048.jpg)

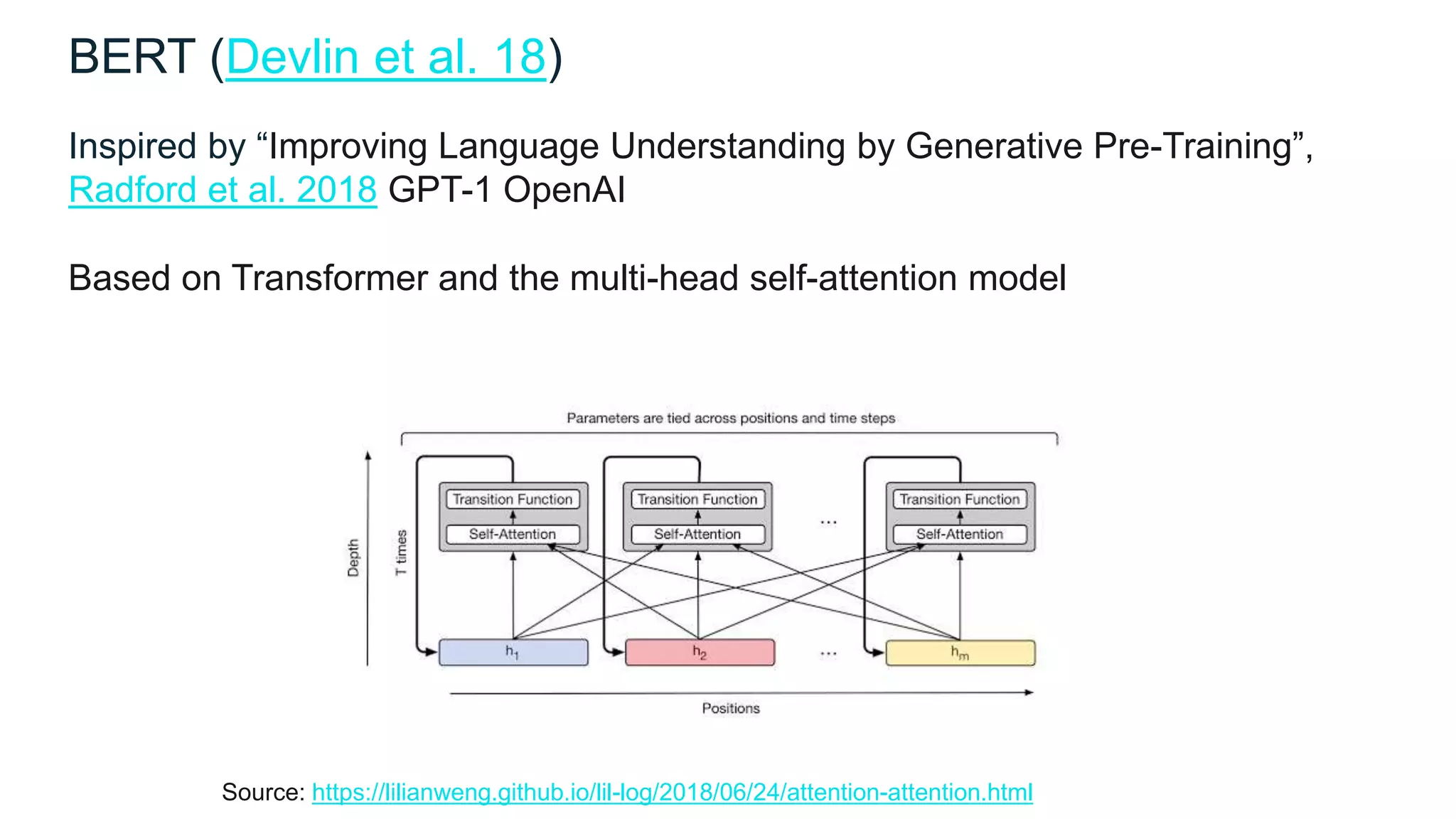
![XLNet (Yang et al. 19)
XLNet: Generalized Autoregressive Pretraining for Language
Understanding
Problems with Bert:
1. The [MASK] token used in training does not appear during fine-tuning
2. BERT generates predictions independently
I went to [MASK] [MASK] and saw the [MASK] [MASK] [MASK].](https://image.slidesharecdn.com/naturallanguageprocessingadvances-191007035949/75/Recent-Advances-in-Natural-Language-Processing-49-2048.jpg)










![Language Modelling
𝑃(𝑤𝑡|𝑤𝑡−1, 𝑤𝑡−2, … )
See you later […]
alligator
today
𝑃(𝑤𝑡|𝑤𝑡+1, 𝑤𝑡+2, … )
[…] abhors a vacuum
Nature
Fido](https://crownmelresort.com/image.slidesharecdn.com/naturallanguageprocessingadvances-191007035949/75/Recent-Advances-in-Natural-Language-Processing-4-2048.jpg)










































![Training objects in slightly modified BERT models for downstream
tasks. (Image source: original paper)
Fine-tuning
For classification tasks:
token 𝐶𝐿𝑆 , 𝒉 𝐿
[𝐶𝐿𝑆]
Small weight matrix W:
𝑠𝑜𝑓𝑡𝑚𝑎𝑥(𝒉 𝐿
𝐶𝐿𝑆
𝑾 𝐶𝐿𝑆)
BERT (Devlin et al. 18)](https://crownmelresort.com/image.slidesharecdn.com/naturallanguageprocessingadvances-191007035949/75/Recent-Advances-in-Natural-Language-Processing-47-2048.jpg)

![XLNet (Yang et al. 19)
XLNet: Generalized Autoregressive Pretraining for Language
Understanding
Problems with Bert:
1. The [MASK] token used in training does not appear during fine-tuning
2. BERT generates predictions independently
I went to [MASK] [MASK] and saw the [MASK] [MASK] [MASK].](https://crownmelresort.com/image.slidesharecdn.com/naturallanguageprocessingadvances-191007035949/75/Recent-Advances-in-Natural-Language-Processing-49-2048.jpg)











The document provides an overview of recent advances in natural language processing (NLP), including traditional methods like bag-of-words models and word2vec, as well as more recent contextualized word embedding techniques like ELMo and BERT. It discusses applications of NLP like text classification, language modeling, machine translation and question answering, and how different models like recurrent neural networks, convolutional neural networks, and transformer models are used.





















































































