Variational autoencoders (VAEs) are generative models that learn to generate new data points from existing data distributions through unsupervised learning. They use an encoder-decoder architecture to represent data in a latent space, optimizing parameters to ensure meaningful outputs when sampling from this space. Challenges include calculating marginal probabilities and ensuring the generated data is not garbage, which VAEs address using methods like Monte Carlo integration and variational inference.
Generative Models
Theytake in data as input and learn to generate new data points from the same
data distribution.
They learn the hidden representations using unsupervised learning techniques
3.
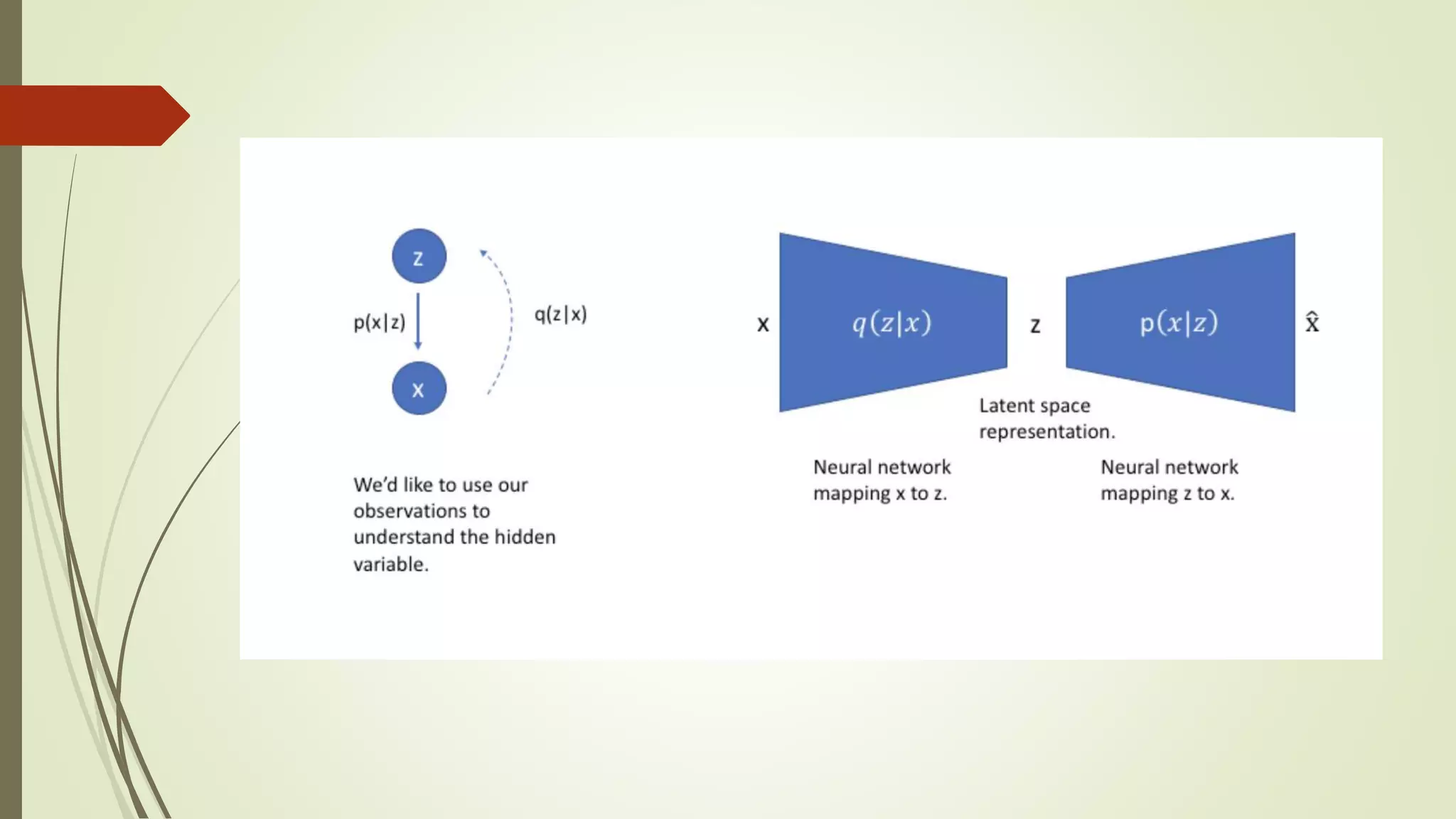
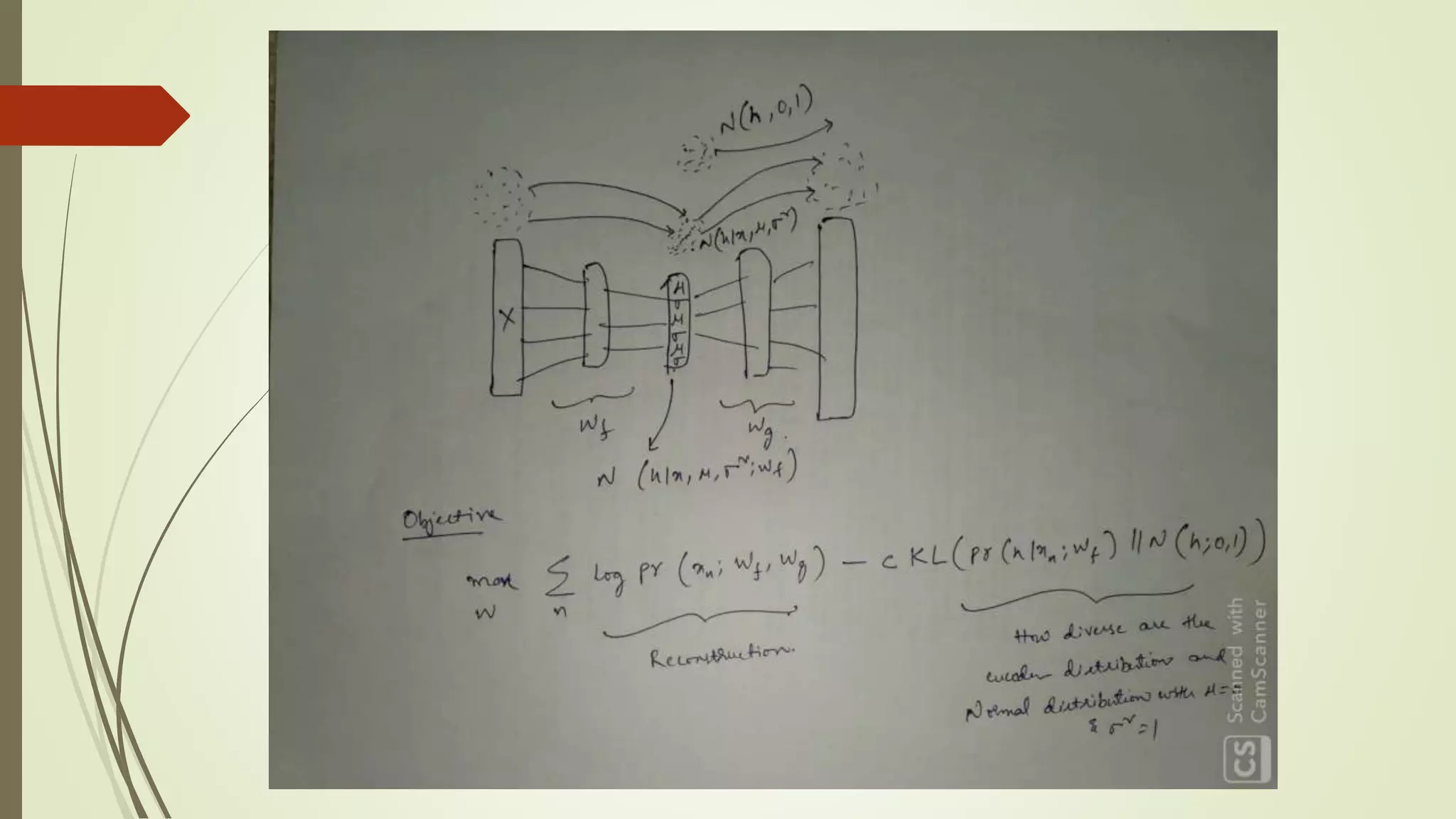
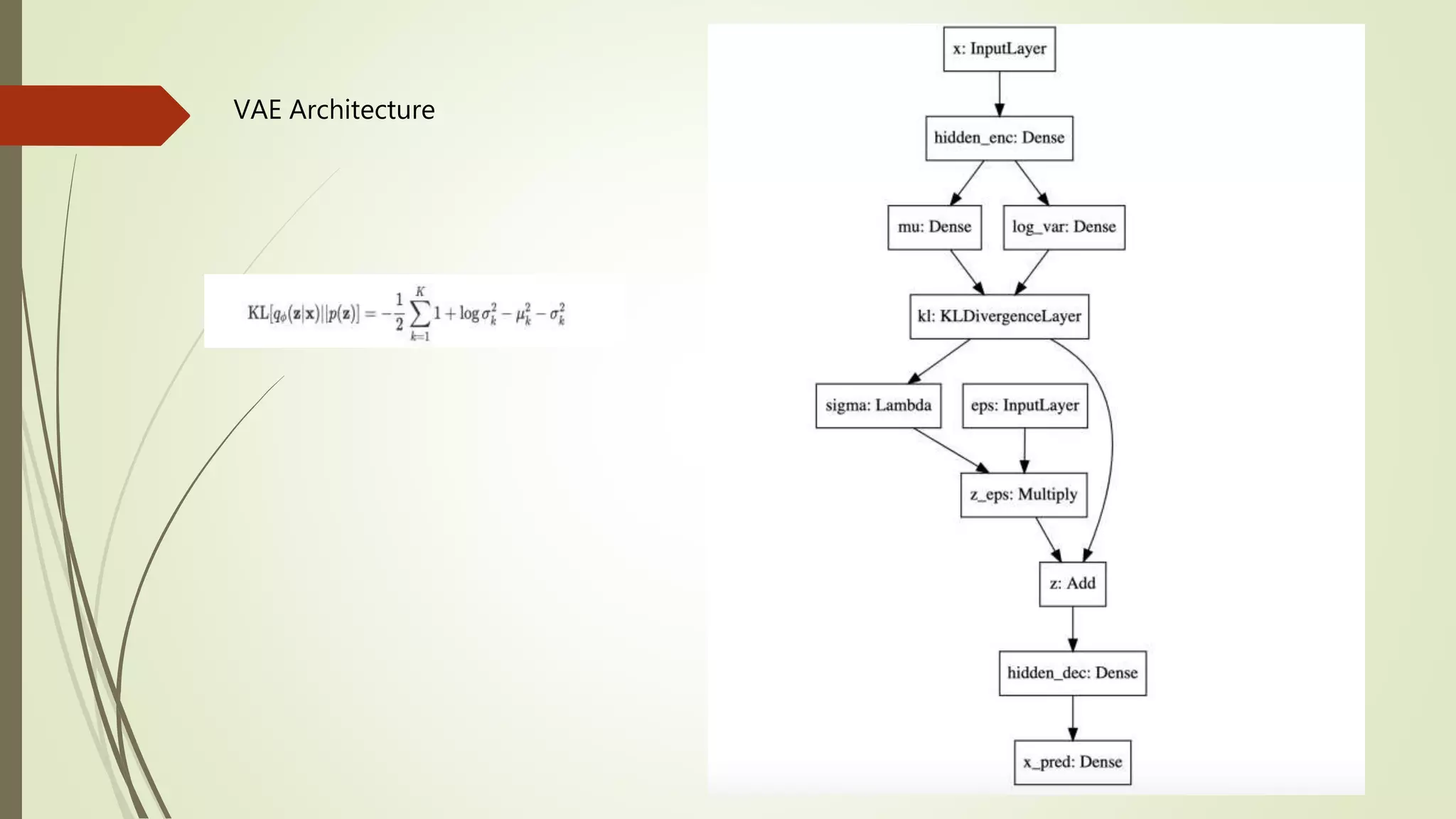
Variational Autoencoder
Asthe name suggests, it is an auto-encoder, which learns attributes from the data
points and represents them in terms of latent variables.
4.
Problems
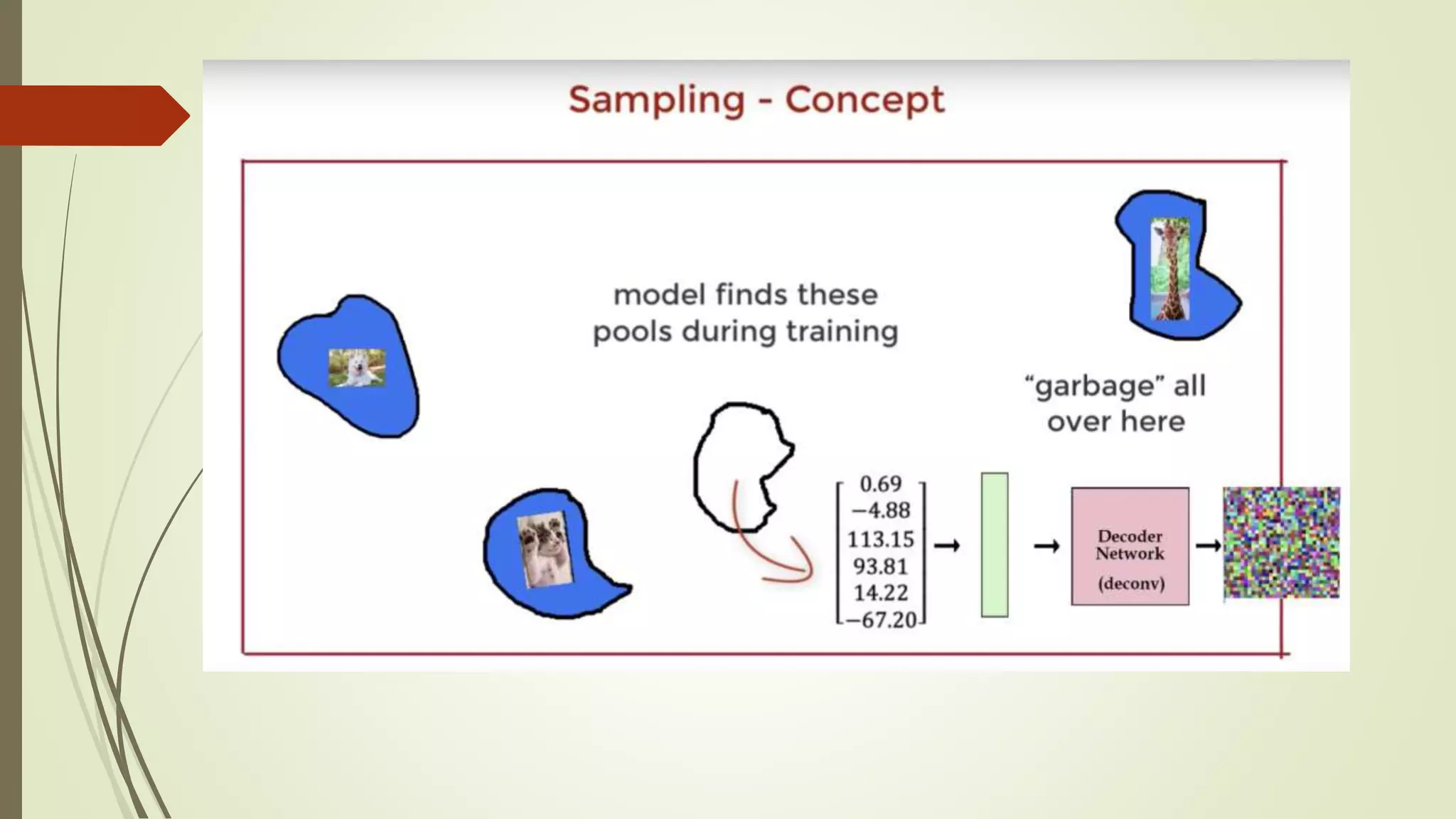
How canwe make use of the auto-encoder architecture to generate new data points ?
Assuming we can pass a vector from that learnt latent space to the decoder, how can
guarantee it’s not going to result in a garbage output.
VAEs address the above problems
5.
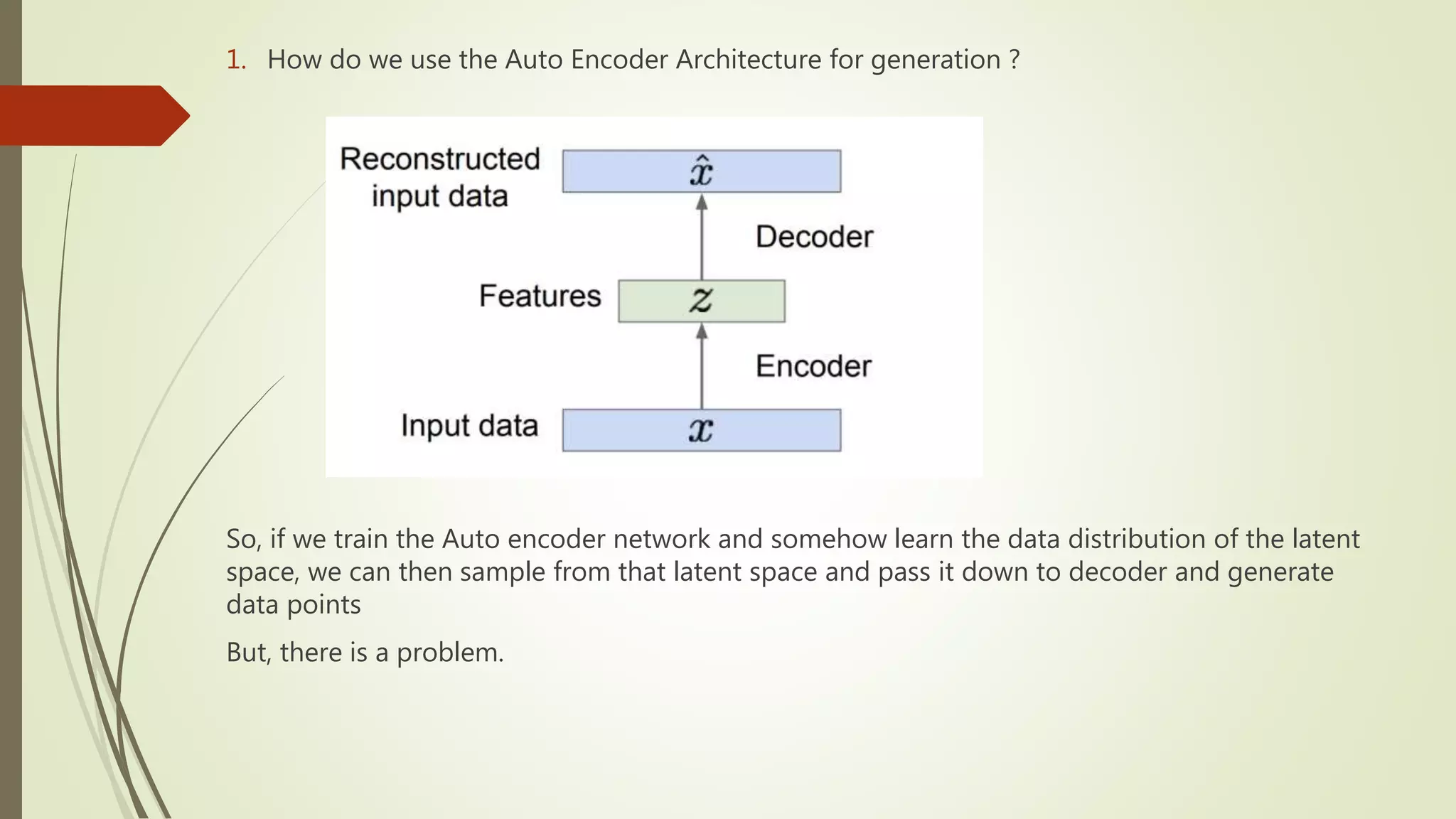
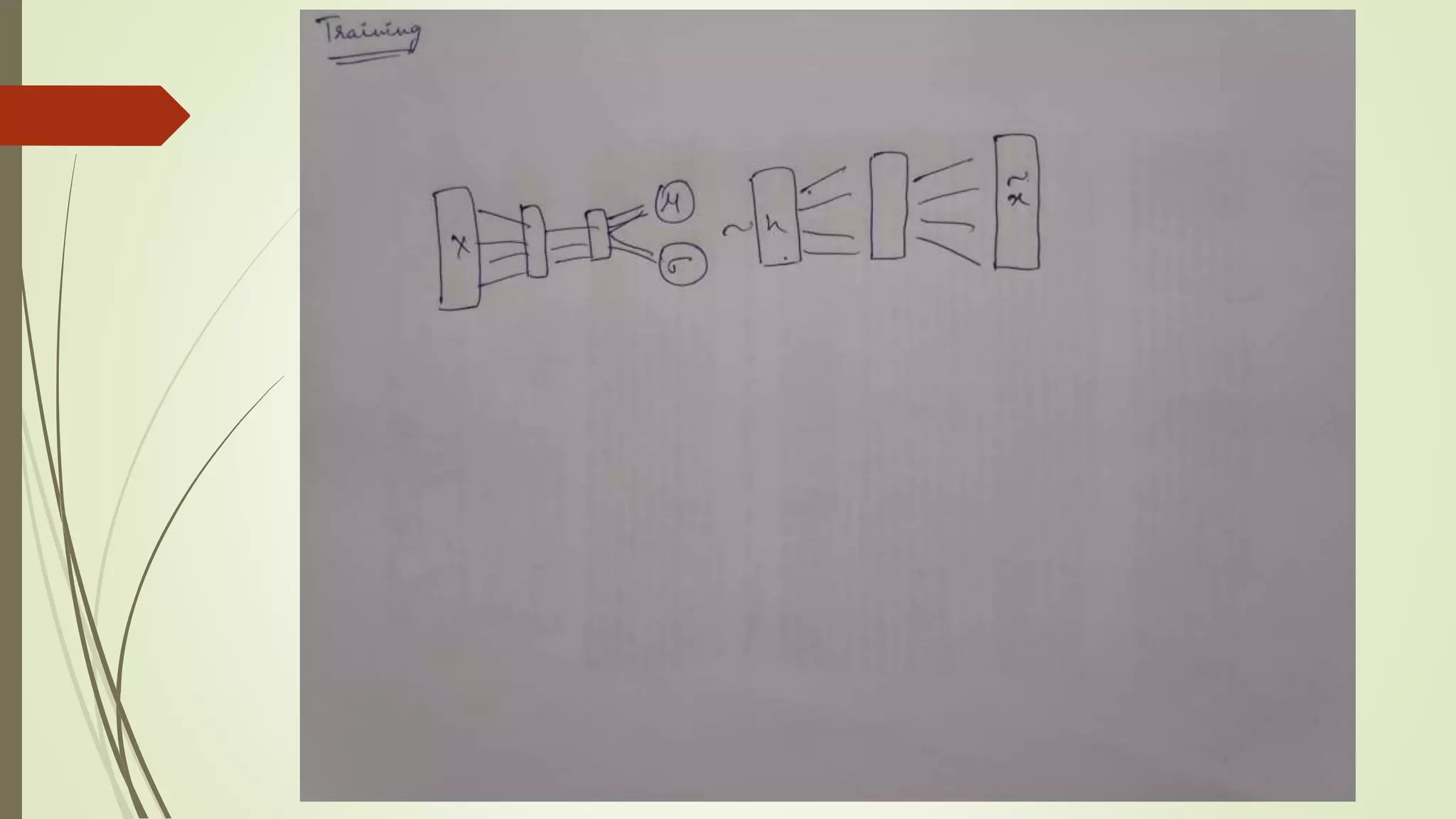
1. How dowe use the Auto Encoder Architecture for generation ?
So, if we train the Auto encoder network and somehow learn the data distribution of the latent
space, we can then sample from that latent space and pass it down to decoder and generate
data points
But, there is a problem.
7.
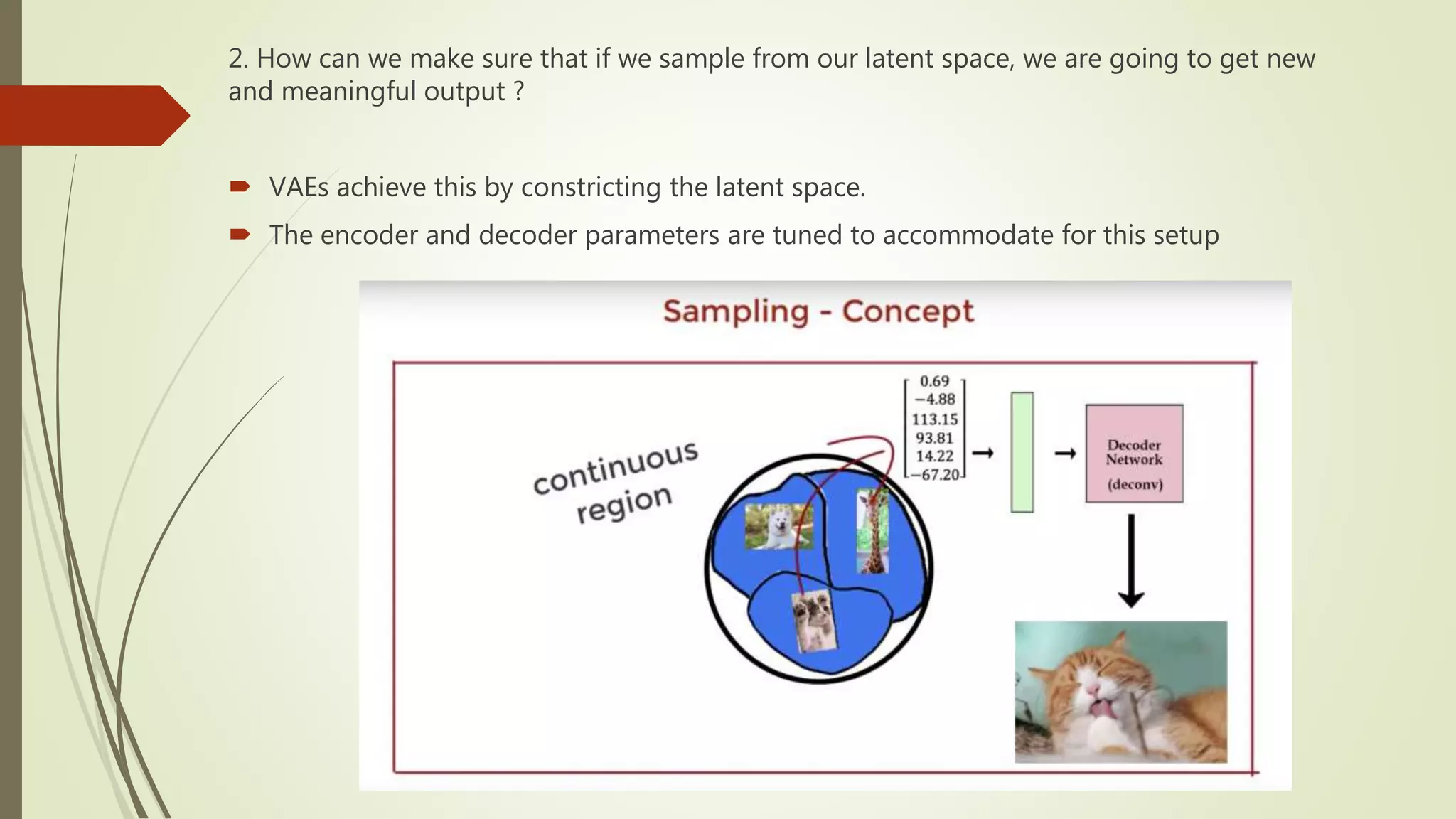
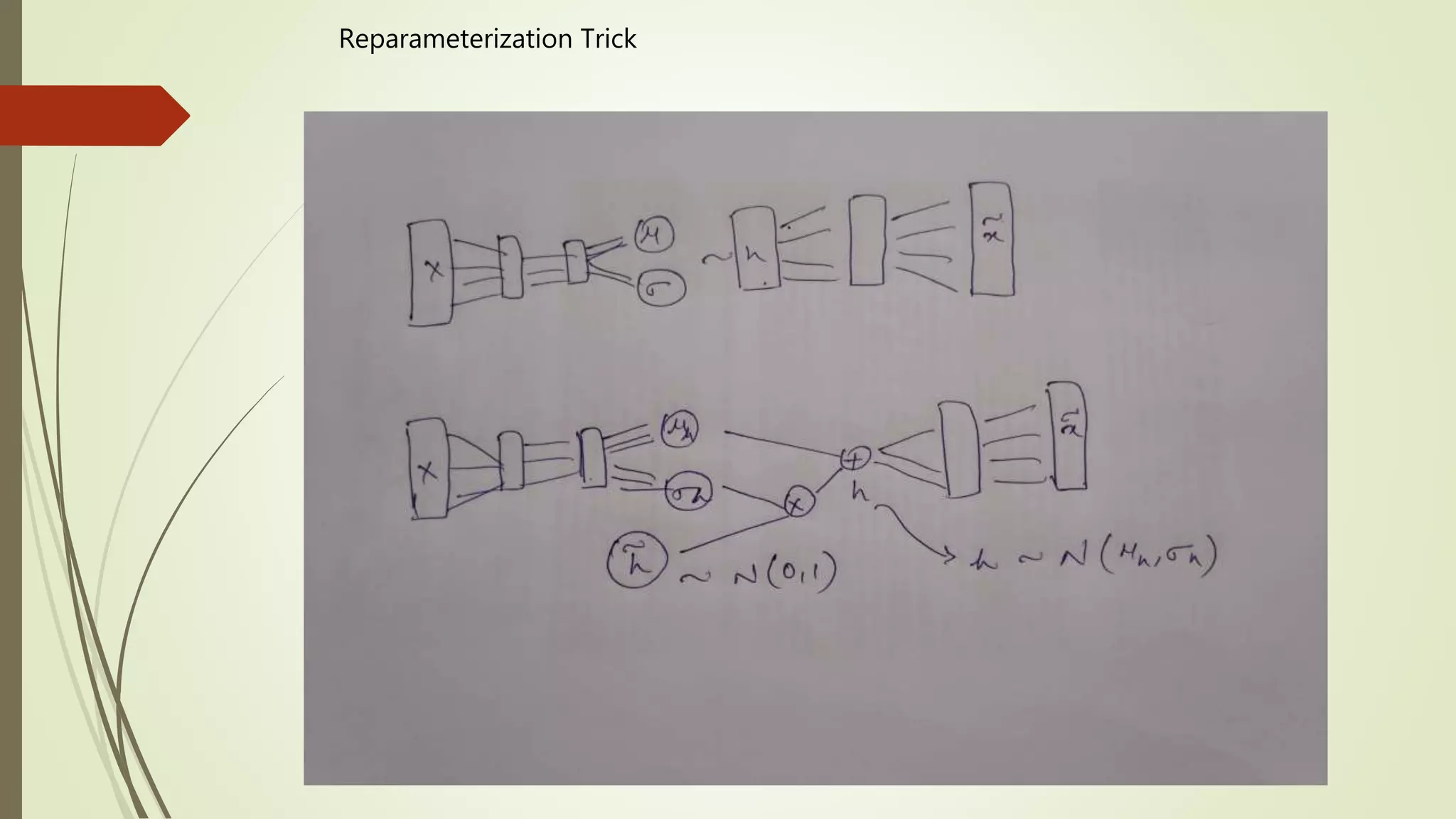
2. How canwe make sure that if we sample from our latent space, we are going to get new
and meaningful output ?
VAEs achieve this by constricting the latent space.
The encoder and decoder parameters are tuned to accommodate for this setup
Calculating Marginal Probability
If X = (x1, x2, x3) and Z = (z1, z2)
then,
𝑃 𝑍 𝑋 =
𝑃(𝑋|𝑍)∗𝑃(𝑍)
𝑃(𝑋)
Here, the P(X) is very difficult to calculate, especially in higher dimensions.
It takes the form of 𝑧1
𝑧2
𝑃 𝑋1, 𝑋2, 𝑋3, 𝑍1, 𝑍2 𝑑𝑧1 ∗ 𝑑𝑧2 and is intractable.
There are ways to solving this by using,
1. Using Monte Carlo Integration techniques
2. Variational Inference
As x isalready given, log p(x) is a constant.
And KL(q(z) || p(z|x)) is what we wanted to minimize and it is always
>= 0
0 <= p(x) <= 1 and KL >= 0
So, it is equivalent to maximizing the 3rd term.
It is called Variational Lower bound
12.
This is nothingbut,
Expectation of p(x|z) w.r.t q(z|x) +
KL(q(z) || p(z|x))
So, Maximizing lower bound means,
Minimizing KL (as >=0), and
For a given q and z, maximize the the likelihood of observing the x









































































![[DL輪読会]Recent Advances in Autoencoder-Based Representation Learning](https://cdn.slidesharecdn.com/ss_thumbnails/20190119dljournalclubweb-190401063633-thumbnail.jpg?width=640&height=640&fit=bounds)




























![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)