Downloaded 482 times







































YOLO (You Only Look Once) is a real-time object detection system that frames object detection as a regression problem. It uses a single neural network that predicts bounding boxes and class probabilities directly from full images in one evaluation. This approach allows YOLO to process images and perform object detection over 45 frames per second while maintaining high accuracy compared to previous systems. YOLO was trained on natural images from PASCAL VOC and can generalize to new domains like artwork without significant degradation in performance, unlike other methods that struggle with domain shift.
Overview of YOLO (You Only Look Once) approach to real-time object detection by key researchers.
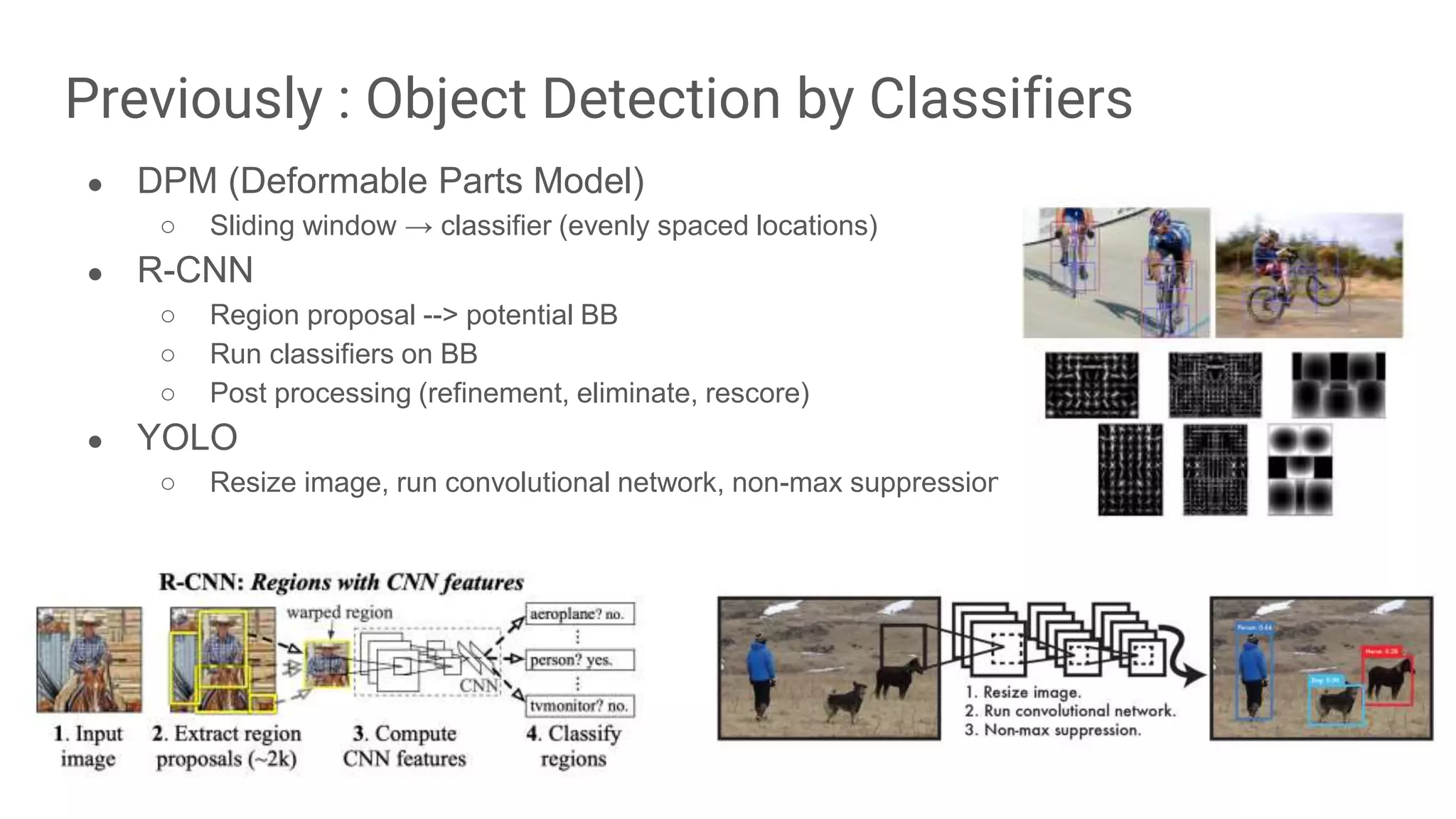
Comparison of previous methods like DPM and R-CNN with YOLO's approach involving convolutional networks.
YOLO treats object detection as a regression task using a single neural network for speed and accuracy.
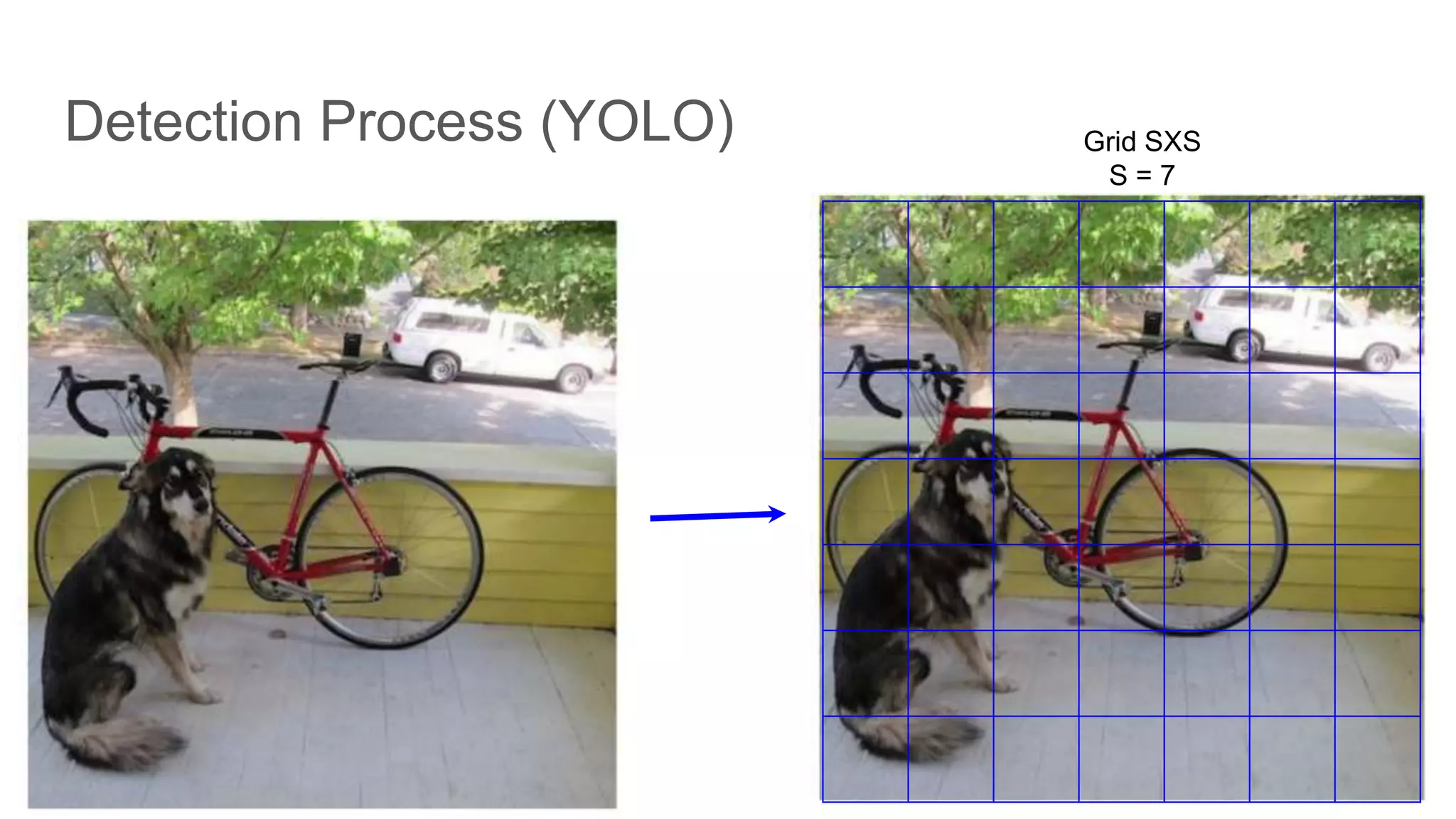
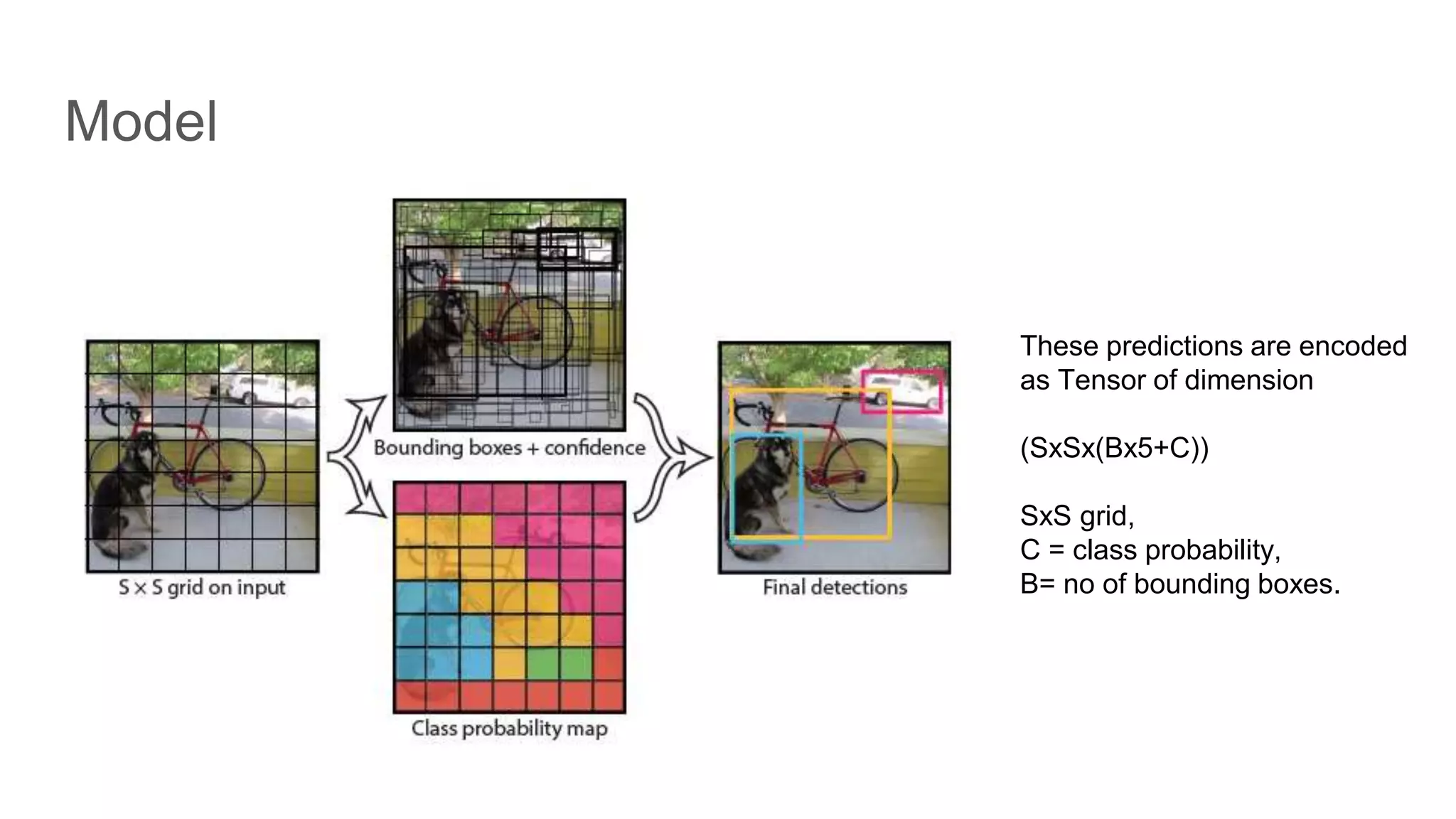
YOLO performs feature extraction and bounding box predictions through a grid-based method.
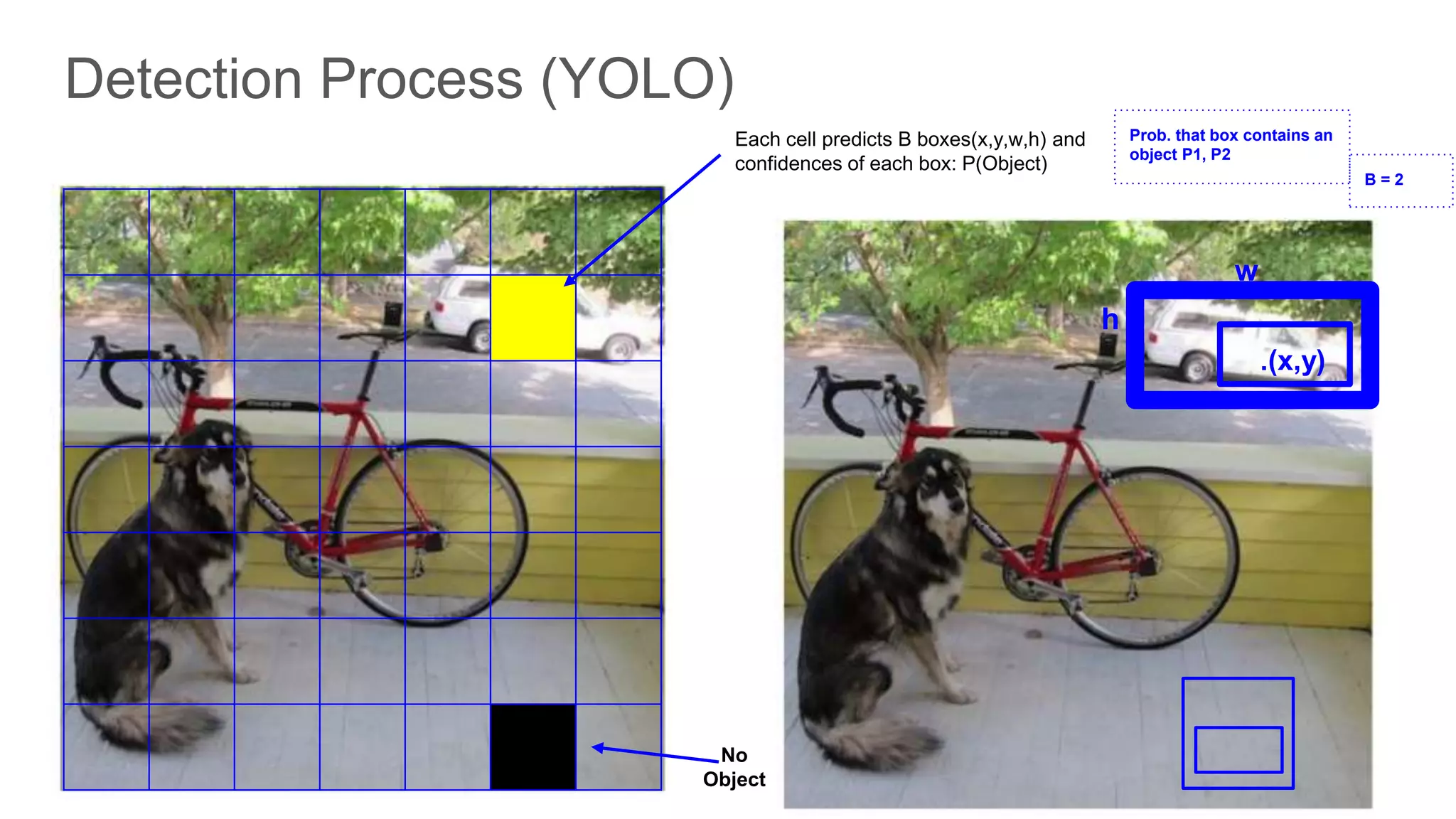
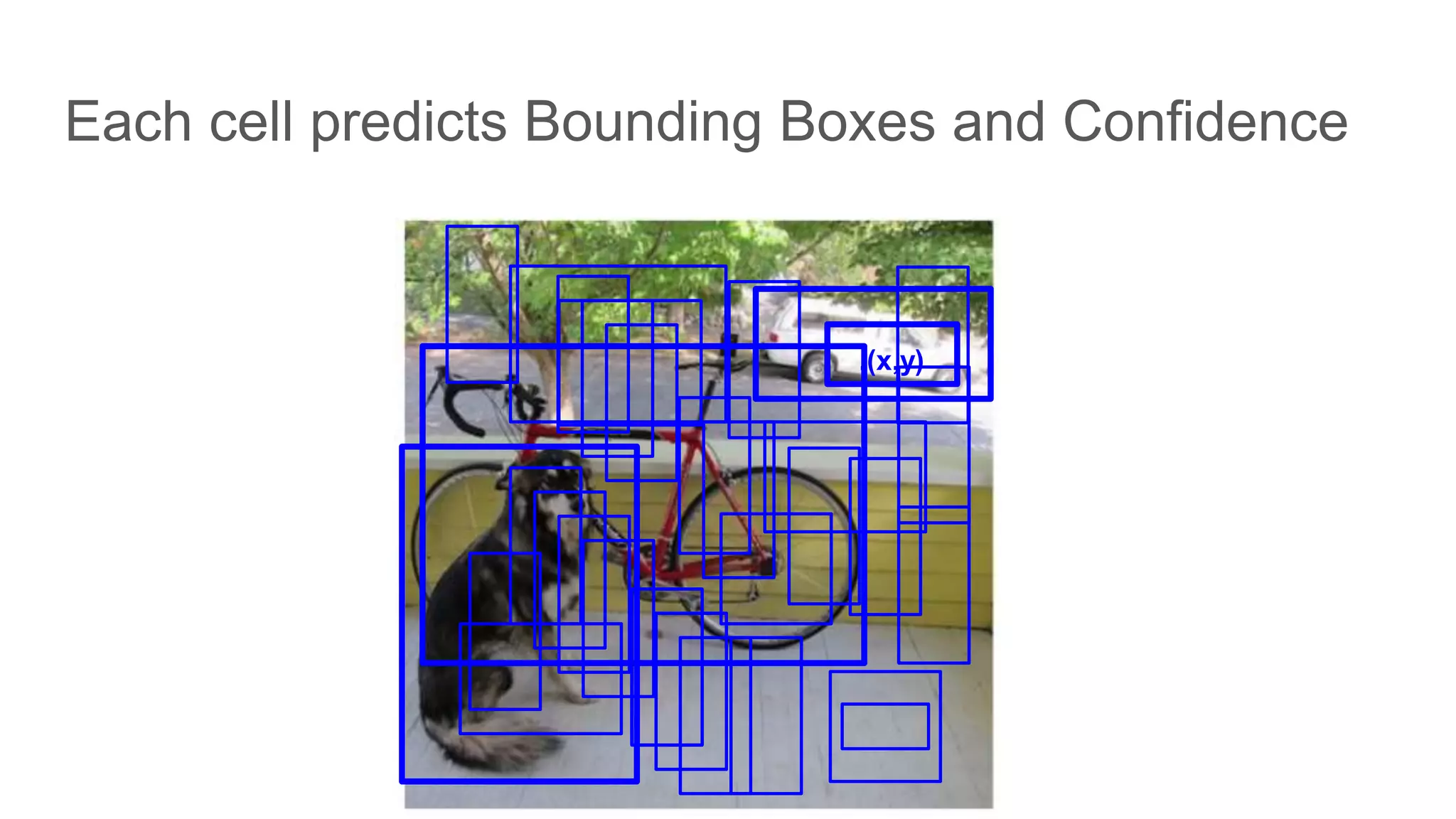
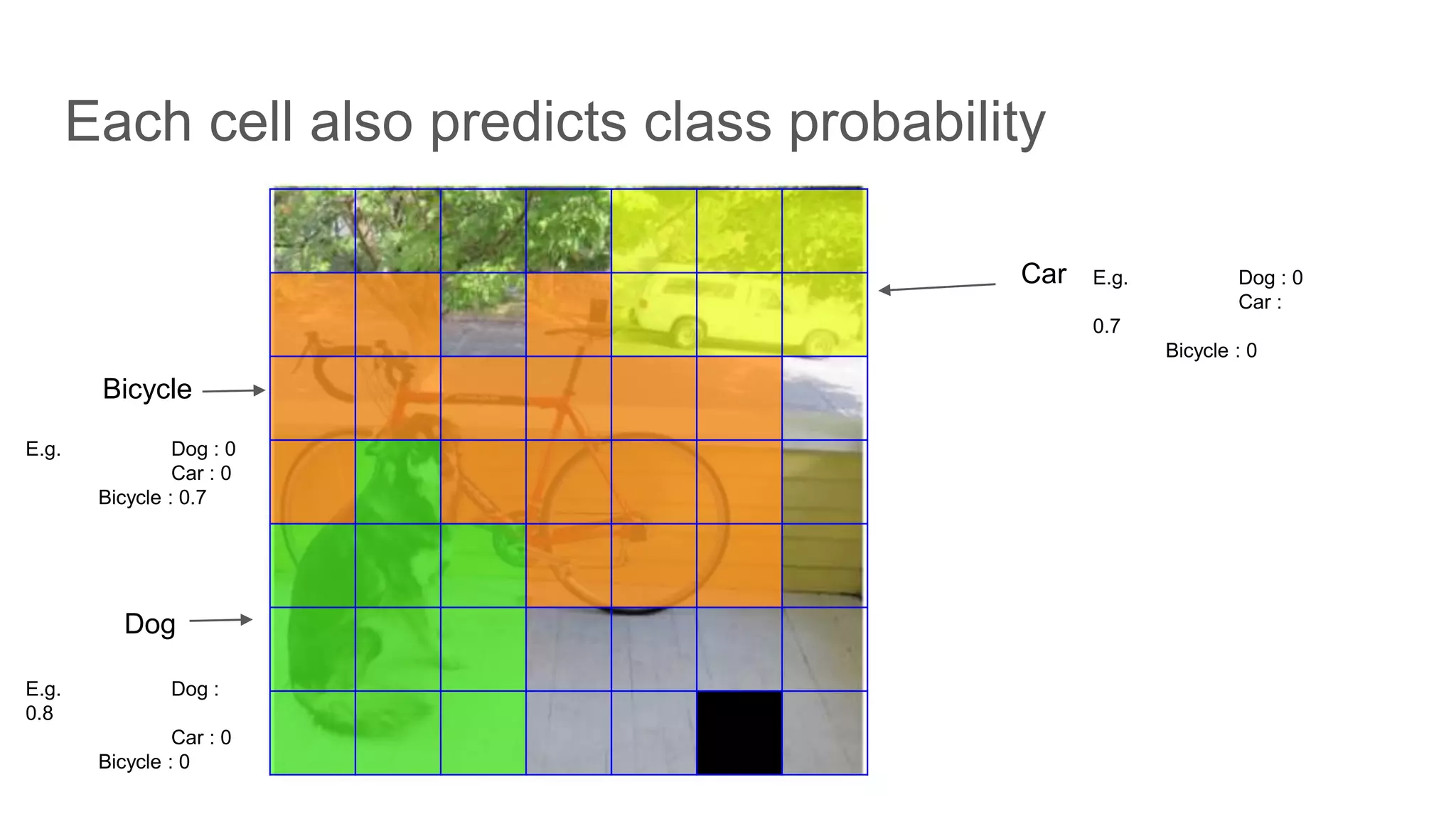
Each grid cell predicts multiple bounding boxes and confidence scores based on IOU with ground truth.
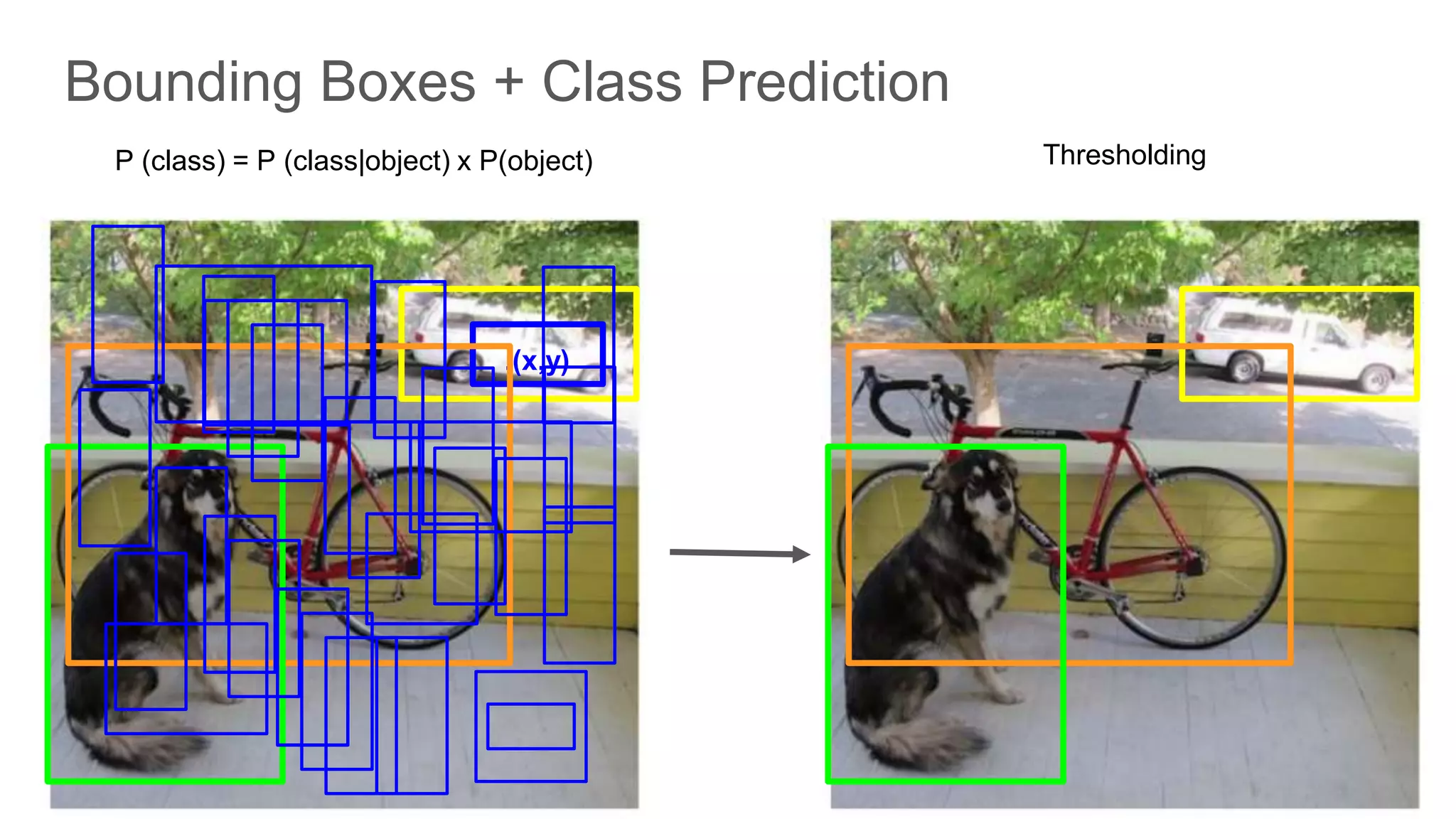
Prediction of class probabilities alongside bounding box coordinates, utilizing thresholding techniques.
Model predictions are encoded in a tensor format incorporating bounding box and class probabilities.
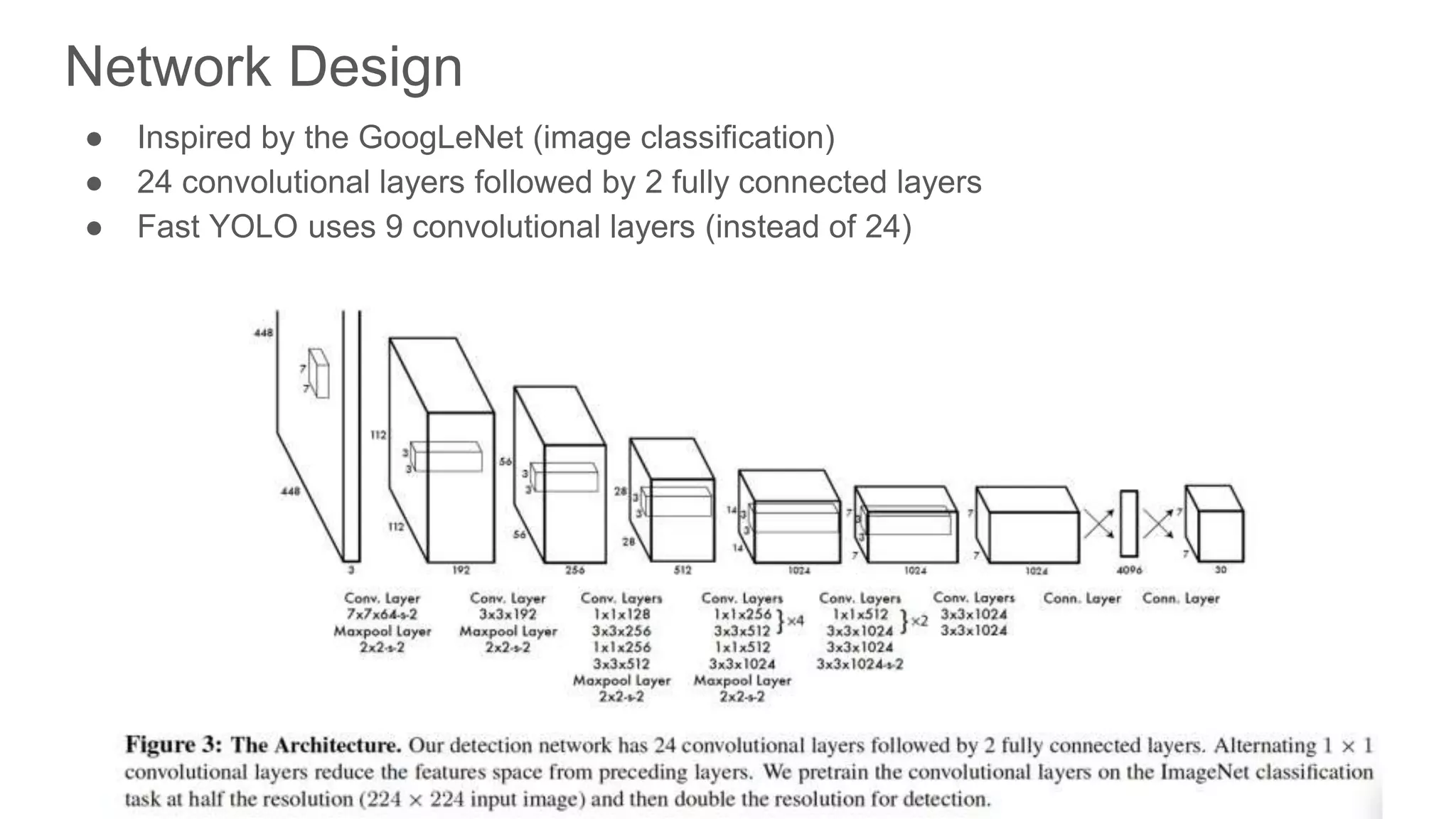
Detailed breakdown of the neural network design inspired by GoogLeNet for effective image classification.
Steps involved in training YOLO on the ImageNet dataset and PASCAL VOC with parameters for optimal results.
Describes the inference stage in YOLO, with emphasis on bounding box predictions and non-maximal suppression.
Identifies limitations of YOLO, particularly in detecting small objects and handling various object ratios.
Comparative analysis of YOLO against other real-time detection systems highlighting efficiency and design.
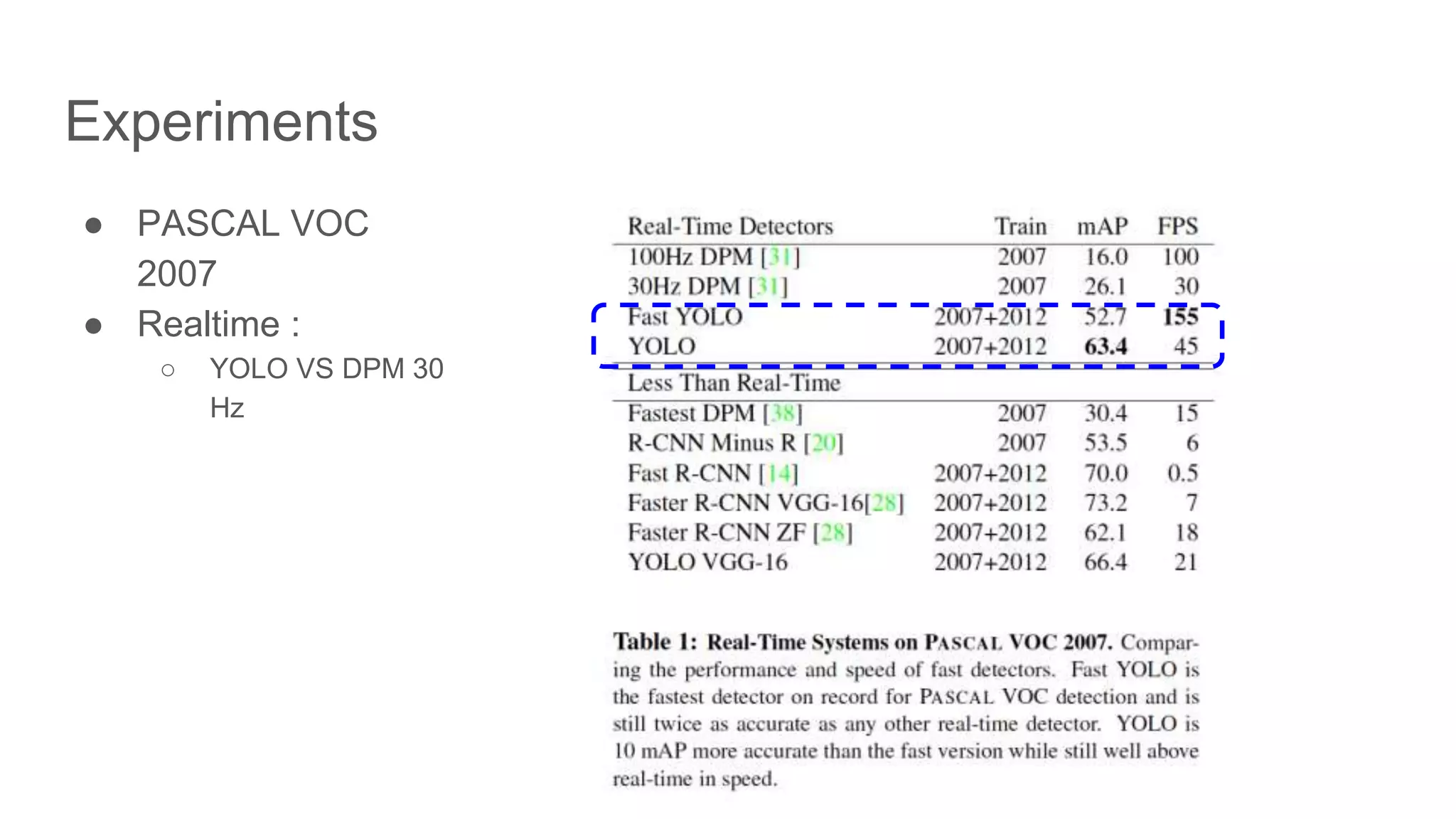
Results of YOLO experiments on PASCAL VOC 2007, including real-time performance metrics.
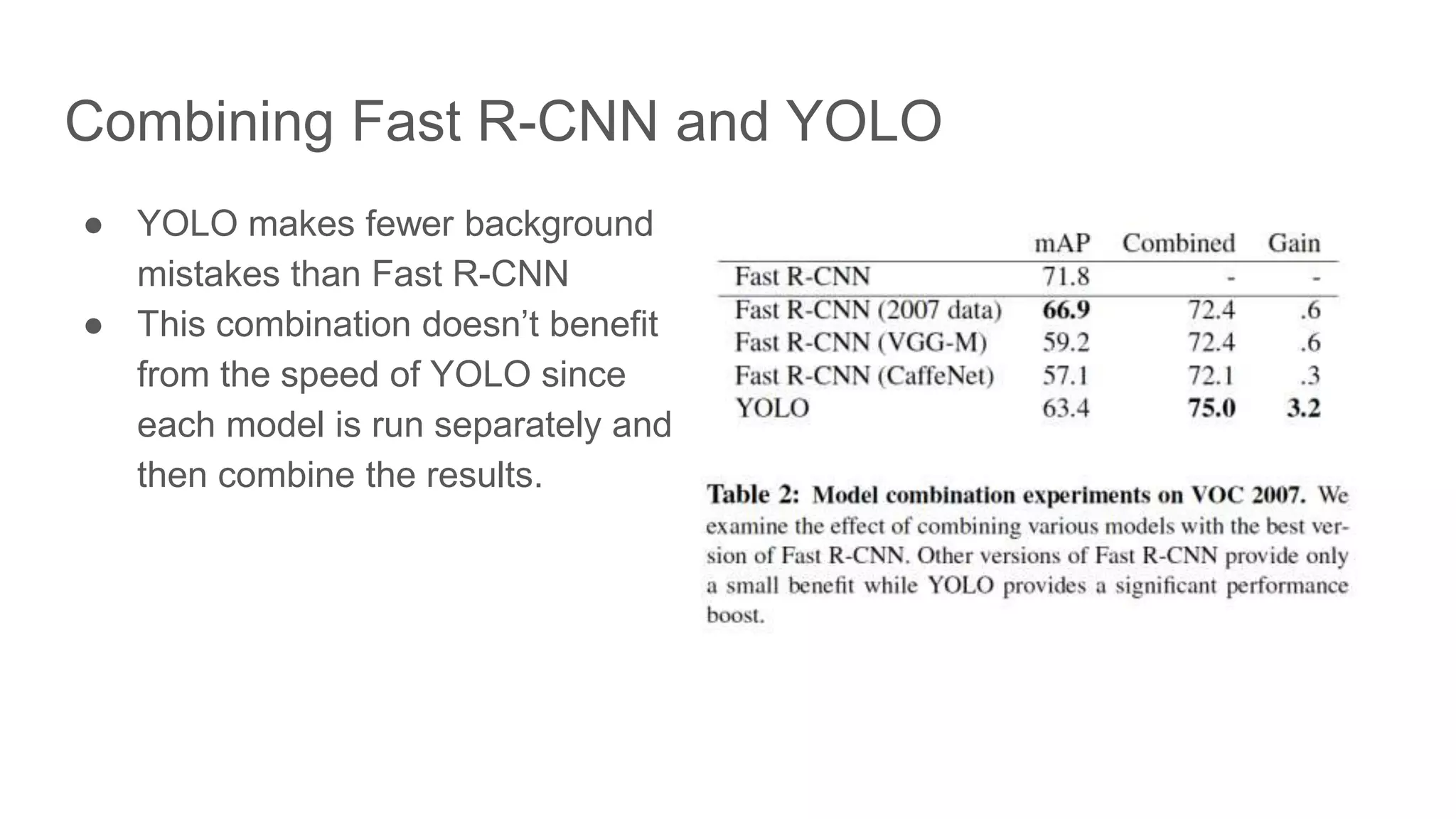
Exploration of combining YOLO with Fast R-CNN, noting improved detection with potential speed trade-off.
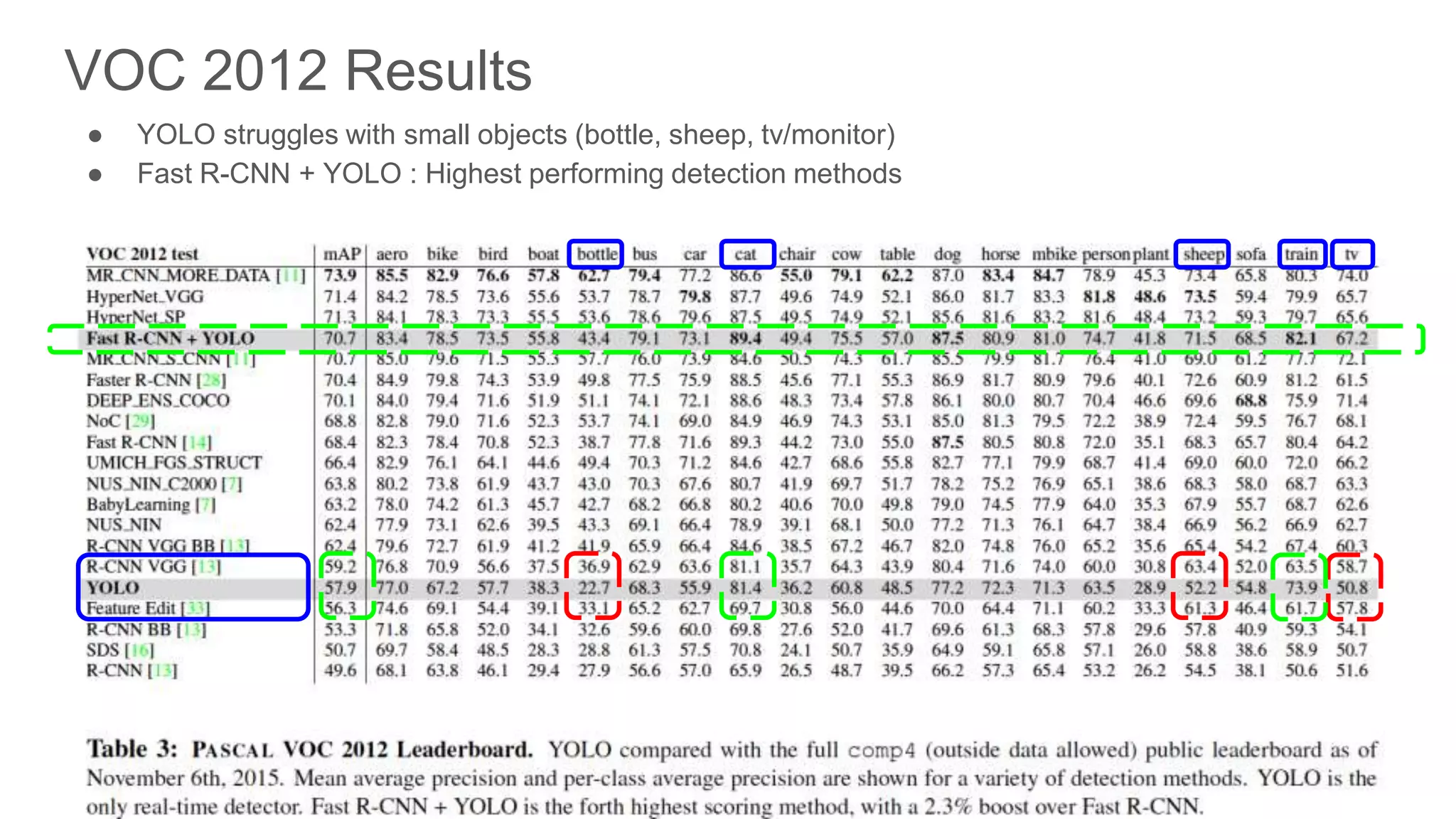
Assessment of YOLO's performance in detecting small objects and the combined efficiency with R-CNN.
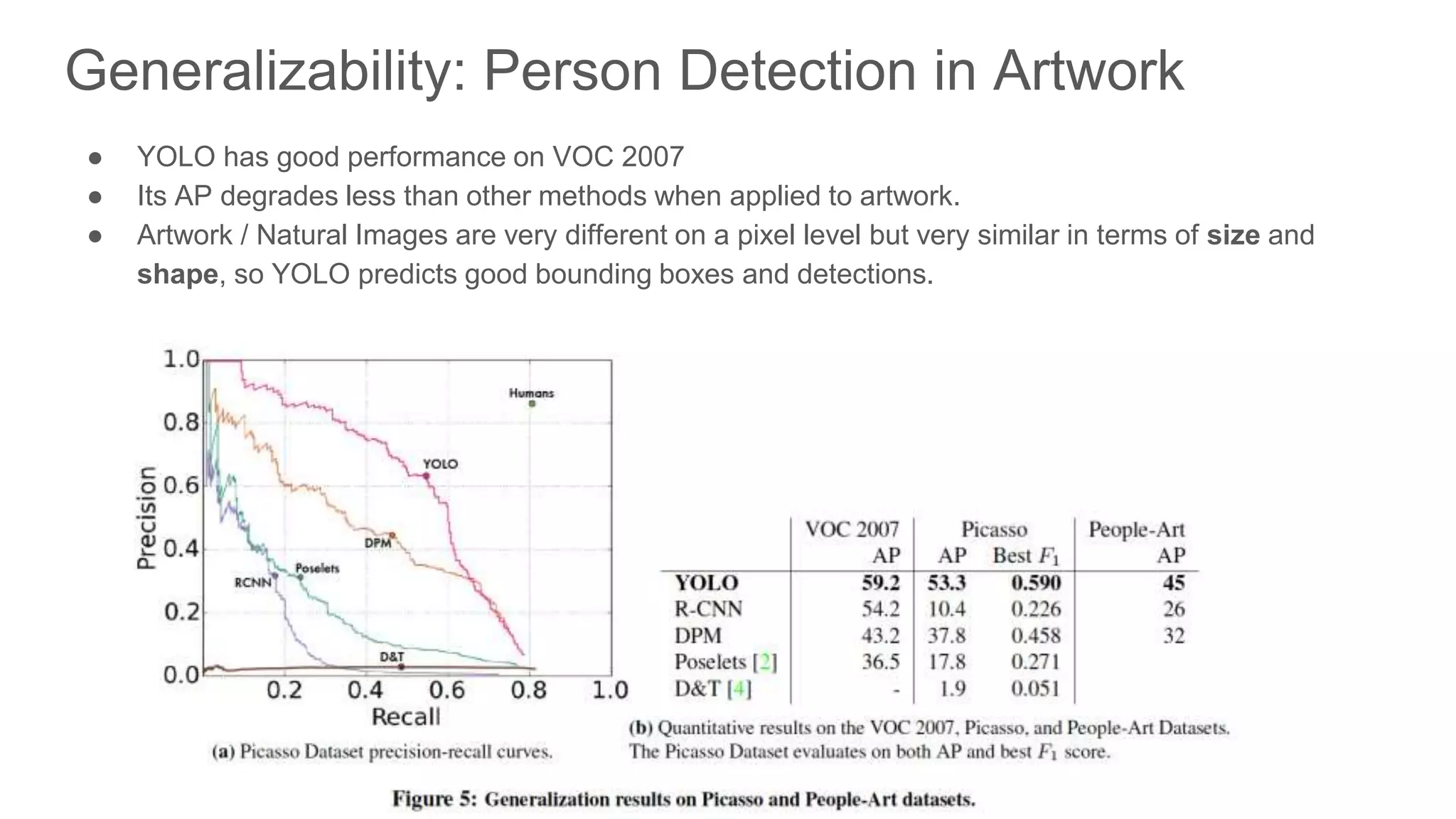
YOLO's effectiveness in detecting people in artwork, showcasing its robust generalizability.
Summary of YOLO results on various images demonstrating its object detection capabilities.

![[PR12] You Only Look Once (YOLO): Unified Real-Time Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/yolo-170616085751-thumbnail.jpg?width=640&height=640&fit=bounds)














































































