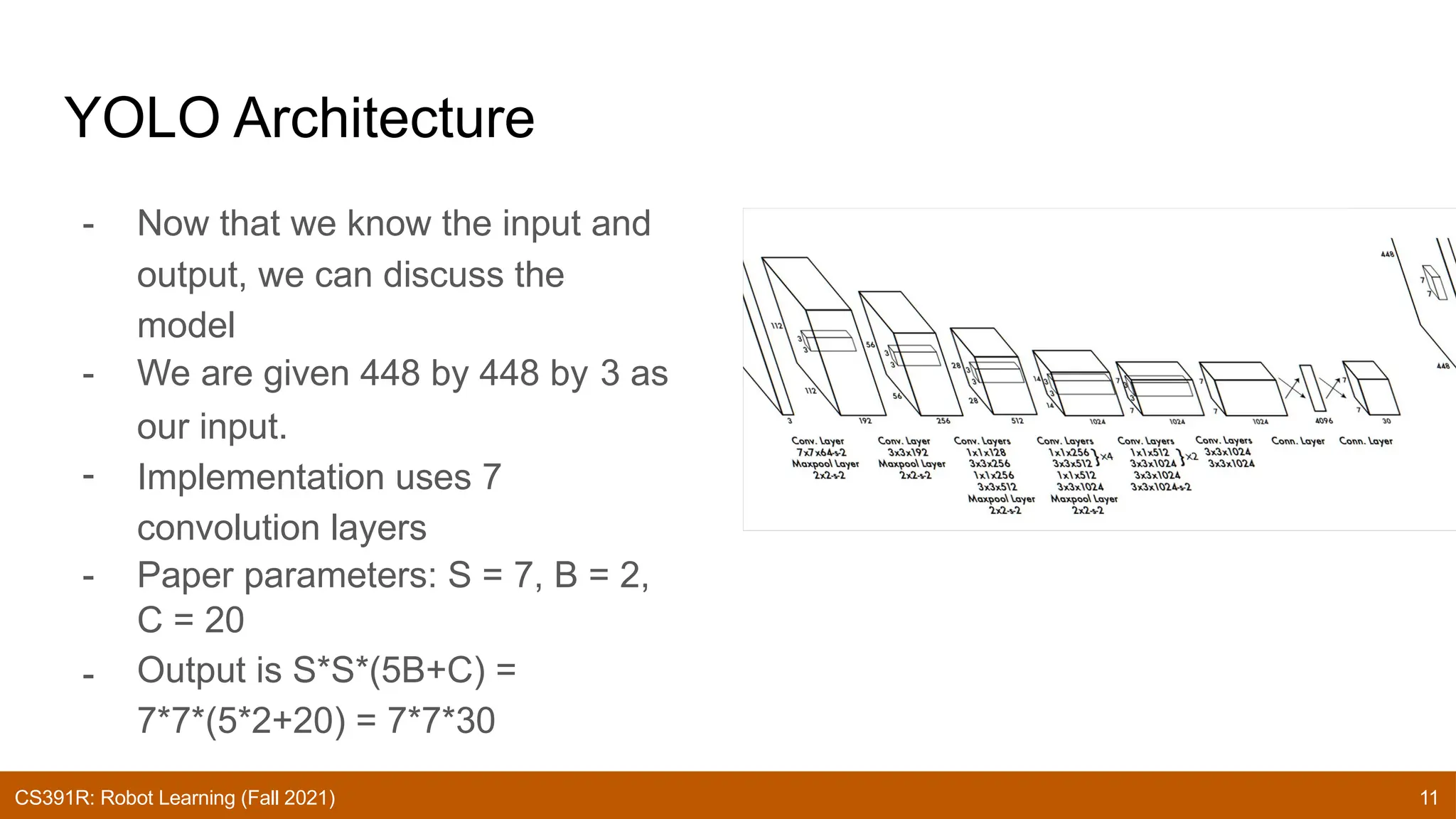
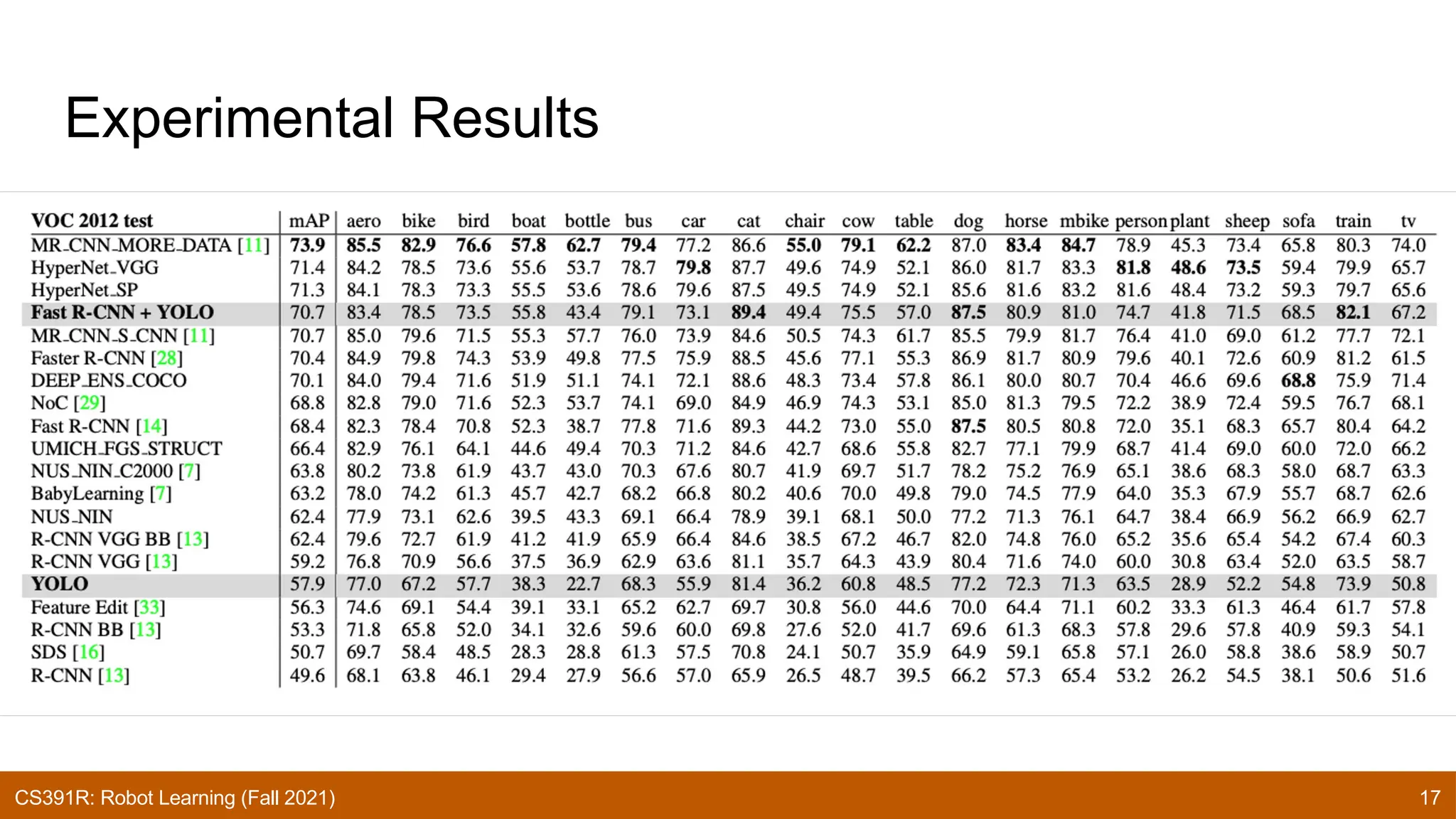
The document discusses the YOLO (You Only Look Once) algorithm for real-time object detection, addressing its efficiency and high accuracy through a unified model that performs localization and classification in a single inference. It compares YOLO with previous paradigms, noting its advantages in speed and contextual understanding, while also acknowledging limitations such as localization errors and constraints on object shapes. Future improvements and subsequent versions of YOLO are mentioned, aiming to enhance generalizability and performance.
















































![[PR12] You Only Look Once (YOLO): Unified Real-Time Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/yolo-170616085751-thumbnail.jpg?width=640&height=640&fit=bounds)












































