Download as PDF, PPTX



![• (SRL)
• [DL ]
https://www.slideshare.net/DeepLearningJP2016/dl-124128933
• SRL VAE VAE
4](https://image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-4-2048.jpg)

![VAE
Variational Autoencoder (VAE) [Kingma+ 2014a]
•
• KL (ELBO)
• ELBO (VAE loss )
6
ℒVAE(θ, ϕ) = 𝔼 ̂p(x) [ 𝔼qϕ(z|x) [−log pθ(x|z)]] + 𝔼 ̂p(x) [
DKL (qϕ(z|x)∥p(z))]
※ VAE ELBO
𝔼 ̂p(x) [−log pθ(x)] = ℒVAE(θ, ϕ) − 𝔼 ̂p(x) [
DKL (qϕ(z|x)∥pθ(z|x))]
−ℒVAE 𝔼 ̂p(x) [−log pθ(x)]
ℒVAE
̂p(x)](https://image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-6-2048.jpg)
![VAE
VAE loss
• 1 reparametrization trick
• 2 closed-form
• ,
closed-form
•
7
ℒVAE(θ, ϕ) = 𝔼 ̂p(x) [ 𝔼qϕ(z|x) [−log pθ(x|z)]] + 𝔼 ̂p(x) [
DKL (qϕ(z|x)∥p(z))]
z(i)
∼ qϕ(z|x(i)
)
qϕ(z|x) = 𝒩
(
μϕ(x), diag (σϕ(x))) p(z) = 𝒩(0,I)](https://image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-7-2048.jpg)


![Maximum Mean Discrepancy (MMD)
MMD
• embedding
• ) MMD
•
10
k : 𝒳 → 𝒳 ℋ
φ : 𝒳 → ℋ px(x)
MMD (px, py) = 𝔼x∼px
[φ(x)] − 𝔼y∼py
[φ(y)]
2
ℋ
py(x)
𝒳 = ℋ = ℝd φ(x) = x
MMD (px, py) = μpx
− μpy
2
2
φ](https://image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-10-2048.jpg)

![Meta-Prior
Meta-prior [Bengio+ 2013]
•
•
•
• But
• →meta-prior
12](https://image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-12-2048.jpg)
![Meta-Prior [Bengio+ 2013]
Disentanglement
•
• )
•
•
• ) ( )
13](https://image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-13-2048.jpg)
![Meta-Prior [Bengio+ 2013]
•
•
•
•
14](https://image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-14-2048.jpg)



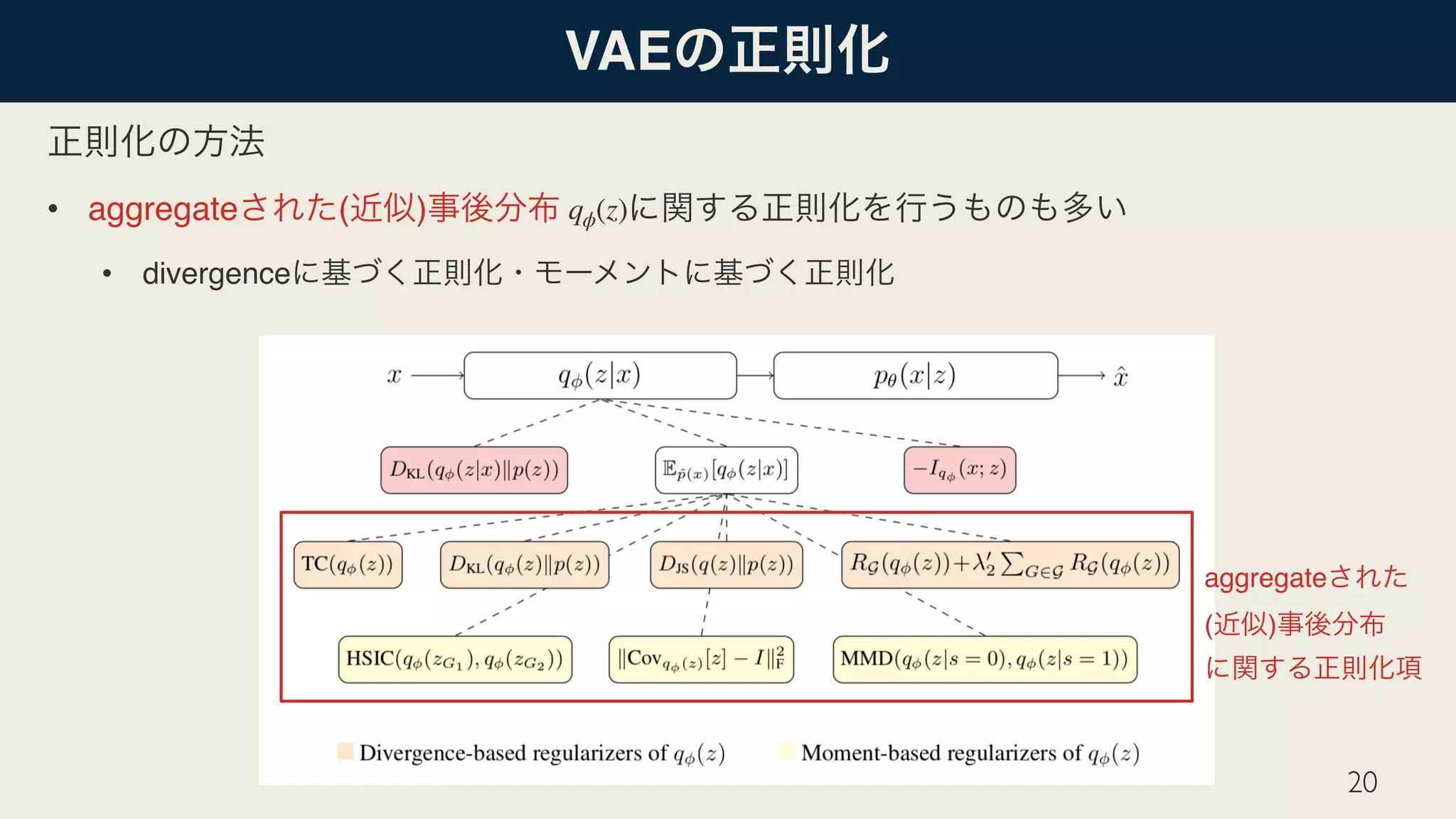
![VAE
meta-prior
aggregate ( )
VAE
• aggregate ( )
• VAE
18
z ∼ qϕ(z|x)
ℒVAE(θ, ϕ) + λ1 𝔼 ̂p(x) [
R1 (qϕ(z|x))]
+ λ2R2 (qϕ(z))
qϕ(z|x) qϕ(z) = 𝔼 ̂p(x) [qϕ(z|x)] =
1
N
N
∑
i=1
qϕ(z|x(i)
)
qϕ(z)
ℒVAE](https://image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-18-2048.jpg)
![VAE
19
ℒVAE(θ, ϕ) + λ1 𝔼 ̂p(x) [
R1 (qϕ(z|x))]
+ λ2R2 (qϕ(z))
Optional](https://image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-19-2048.jpg)

![Disentanglement
Disentangle
•
• disentangle disentangle
• ( disentangle )
• [Locatello+ 2018]
•
• (a) ELBO
• (b) x z
• (c)
22](https://image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-22-2048.jpg)
![(a) ELBO
β-VAE [Higgins+ 2017]
• VAE Loss
2
•
23
ℒVAE(θ, ϕ) = 𝔼 ̂p(x) [ 𝔼qϕ(z|x) [−log pθ(x|z)]] + 𝔼 ̂p(x) [DKL (qKL(q|x)∥p(z))]
ℒβ−VAE(θ, ϕ) = ℒVAE(θ, ϕ) + λ1 𝔼 ̂p(x) [
DKL (qϕ(z|x)∥p(z))]
qϕ(z|x) p(z)
: [Higgins+ 2017]](https://image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-23-2048.jpg)
![(b) x z
VAE Loss
2
•
aggregate ( ) KL [Hoffman+ 2016]
• FactorVAE[Kim+ 2018]
• β-TCVAE[Chen+ 2018] InfoVAE[Zhao+ 2017a] DIP-VAE[Kumar+ 2018]
24
ℒVAE(θ, ϕ) = 𝔼 ̂p(x) [ 𝔼qϕ(z|x) [−log pθ(x|z)]] + 𝔼 ̂p(x) [DKL (qKL(q|x)∥p(z))]
𝔼 ̂p(x) [
DKL (qϕ(z|x)∥p(z))]
= Iqϕ
(x; z) + DKL (qϕ(z)∥p(z))
x z Iqϕ
(x; z)
qϕ(z) p(z)](https://image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-24-2048.jpg)
![(b) x z
Factor VAE [Kim+ 2018]
• βVAE loss
• toral correlation
• discriminator density ratio trick
• [DL ]Disentangling by Factorising
https://www.slideshare.net/DeepLearningJP2016/dldisentangling-by-factorising
25
ℒβ−VAE DKL (qϕ(z)∥p(z))
Iqϕ
(x; z)
TC (qϕ(z)) = DKL qϕ(z)∥
∏
j
qϕ (zj)
ℒFactorVAE(θ, ϕ) = ℒVAE(θ, ϕ) + λ2 TC (qϕ(z))](https://image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-25-2048.jpg)
![(c)
HSIC-VAE [Lopez+ 2018]
• Hilbert-Schmidt independence criterion (HSIC) [Gretton+2005]
• HSIC ( AppendixA )
•
•
HFVAE [Esmaeili+ 2018]
26
zG = {zk}k∈G
ℒHSIC−VAE(θ, ϕ) = ℒVAE(θ, ϕ) + λ2HSIC
(
qϕ (zG1), qϕ (zG2))
s
HSIC (qϕ(z), p(s))
p(s)](https://image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-26-2048.jpg)
![PixelGAN-AE [Makhzani+ 2017]
• PixelCNN[van den Oord+ 2016]
•
• VAE loss KL
• KL GAN
VIB[Alemi+ 2016]
Information dropout[Achille+ 2018] 27
ℒPixelGAN−AE(θ, ϕ) = ℒVAE(θ, ϕ) − Iqϕ
(x; z)
𝔼 ̂p(x) [
DKL (qϕ(z|x)∥p(z))]
= Iqϕ
(x; z) + DKL (qϕ(z)∥p(z))
Iqϕ
(x; z)
DKL (qϕ(z)∥p(z)) : [Makhzani+ 2017]](https://image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-27-2048.jpg)
![Variational Fair Autoencoder (VFAE) [Louizos+ 2016]
•
• VAE loss MMD
•
• MMD HSIC HSIC-VAE[Lopez+ 2018]
• 2 VFAE[Louizos+ 2016] HSIC-VAE [Lopez+ 2018]
Fader Network[Lample+ 2017]
DC-IGN[Kulkarni+ 2015] 28
q(z|s = k)
s
s
s z
ℒVAEq(z|s = k′)
ℒVFAE(θ, ϕ) = ℒVAE + λ2
K
∑
ℓ=2
MMD (qϕ(z|s = ℓ), qϕ(z|s = 1))
qϕ(z|s = ℓ) =
∑
i:s(i)=ℓ
1
{i : s(i) = ℓ}
qϕ(z|x(i)
, s(i)
)](https://image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-28-2048.jpg)

![VAE
M2 [Kingma+ 2014b]
•
•
• loss
• M1 (M1+M2 )
•
• DL Hacks Semi-supervised Learning with Deep Generative Models
https://www.slideshare.net/YuusukeIwasawa/dl-hacks2015-0421iwasawa
• Semi-Supervised Learning with Deep Generative Models pixyz
https://qiita.com/kogepan102/items/22b685ce7e9a51fbab98
31
qϕ(z, y|x) = qϕ(z|y, x)qϕ(y|x)
x z y
x
qϕ(z, y|x)
qϕ(z|y, x) ℒVAEy](https://image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-31-2048.jpg)
![VLAE
Varational Lossy Autoencoder (VLAE) [Chen+ 2017]
•
•
• )
PixelVAE[Gulrajani+ 2017]
LadderVAE[Sønderby+ 2016] VLaAE[Zhao+ 2017b] 32
pθ(x|z) z
z
pθ(x|z) W(j)
pθ(x|z) =
∏
j
pθ (xj |z, xW( j))
j](https://image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-32-2048.jpg)

![meta-prior
• meta-prior
• ) MNIST
) (SVAE) [Johnson+ 2016]
34
p(z)
N:
C: Categorical
M: mixture
G:
L; Learned Prior](https://image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-34-2048.jpg)
![JointVAE [Dupont 2018]
• disentanglement
•
• Gumbel-Softmax
• KL (β-VAE 2 )
VQ-VAE[van den Oord+ 2017]
35
z c
qϕ(c|x)qϕ(z|x)
qϕ(c|x)
DKL (qϕ(z|x)qϕ(c|x)∥p(z)p(c)) = DKL (qϕ(z|x)∥p(z)) + DKL (qϕ(c|x)∥p(c))
ℒβ−VAE](https://image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-35-2048.jpg)

![• Denoising Autoencoder (DAE) [Vincent+ 2008]
• [Yingzhen+ 2018] [Hsieh+2018]
• [Villegas+ 2017] [Denton+ 2017] [Fraccaro+ 2017]
37](https://image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-37-2048.jpg)
![discriminator
•
• Adversarially Learned Inference (ALI) [Dumoulin+ 2017]
• Bidirectional GAN (BiGAN) [Donahue+ 2017]
38
qϕ(z|x) pθ(x|z)
pθ(x|z)p(z) qϕ(z|x) ̂p(x)
: [Dumoulin+ 2017]
: [Donahue+ 2017]](https://image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-38-2048.jpg)

![Rate-Distortion Tradeoff
meta-prior
• ) βVAE [Higgins+ 2017]
FaderNetwork[Lample+ 2017]
”Rate-Distortion Tradeoff”[Alemi+ 2018a]
40](https://image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-40-2048.jpg)
![Rate-Distortion Tradeoff
•
• Distortion:
• Rate: KL
• VAE ELBO
41
H = −
∫
p(x)log p(x)dx = Ep(x)[−log p(x)]
D = −
∬
p(x)qϕ(z|x)log pθ(x|z)dxdz = Ep(x) [ 𝔼qϕ(z|x) [−log pθ(x|z)]]
R =
∬
p(x)qϕ(z|x)log
qϕ(z|x)
p(z)
dxdz = 𝔼p(x) [DKL (qθ(q|x)∥p(z))]
qϕ(z|x) p(z)
ELBO = − ℒVAE = − (D + R)](https://image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-41-2048.jpg)
![Rate-Distortion Tradeoff
Rate-Distortion Tradeoff [Alemi+ 2018a]
• Rate Distortion )
• ELBO
• Rate
•
• [Alemi+ 2018a] Rate
•
42
H − D ≤ R
: [Alemi+ 2018a]
D = H − R
min
ϕ,θ
D + |σ − R|
σ](https://image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-42-2048.jpg)


![Rate-Distortion-Usefulness Tradeoff
Usefulness
•
•
•
• [Alemi+ 2018b]
….?( )
45
Dy = −
∬
p(x, y)qϕ(z|x)log pθ(y|z)dxdydz = 𝔼p(x,y) [ 𝔼qϕ(z|x) [−log pθ(y|z)]]
y
R − Dy](https://image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-45-2048.jpg)


![• Rate-Distortion-Usefulness
• z
ex) GQN
• Meta-Prior
• meta-learning
• [DL ]Meta-Learning Probabilistic Inference for Prediction
https://www.slideshare.net/DeepLearningJP2016/dlmetalearning-probabilistic-inference-for-
prediction-126167192
• usefulnes ( )
•
• Pixyz Pixyzoo ( )
48](https://image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-48-2048.jpg)
![Pixyz & Pixyzoo
Pixyz https://github.com/masa-su/pixyz
• (Pytorch )
•
Pixyzoo https://github.com/masa-su/pixyzoo
• Pixyz
• GQN VIB
• [DLHacks]PyTorch, Pixyz Generative Query Network
https://www.slideshare.net/DeepLearningJP2016/dlhackspytorch-pixyzgenerative-query-
network-126329901
49](https://image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-49-2048.jpg)

![References
[Achille+ 2018] A. Achille and S. Soatto, “Information dropout: Learning optimal representations through noisy computation,”
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018. https://ieeexplore.ieee.org/document/8253482
[Alemi+ 2016] A. A. Alemi, I. Fischer, J. V. Dillon, and K. Murphy, “Deep variational information bottleneck,” in International
Conference on Learning Representations, 2016. https://openreview.net/forum?id=HyxQzBceg
[Alemi+ 2018a] A. Alemi, B. Poole, I. Fischer, J. Dillon, R. A. Saurous, and K. Murphy, “Fixing a broken ELBO,” in Proc. of the
International Conference on Machine Learning, 2018, pp. 159–168. http://proceedings.mlr.press/v80/alemi18a.html
[Alemi+ 2018b] A. A. Alemi and I. Fischer, “TherML: Thermodynamics of machine learning,” arXiv:1807.04162, 2018. https://
arxiv.org/abs/1807.04162
[Bengio+ 2013] Y. Bengio, A. Courville, and P. Vincent, “Representation learning: A review and new perspectives,” IEEE
Transactions on Pattern Analysis and Machine Intelligence, vol. 35, no. 8, pp. 1798–1828, 2013. https://ieeexplore.ieee.org/
document/6472238
[Chen+ 2017] X. Chen, D. P. Kingma, T. Salimans, Y. Duan, P. Dhariwal, J. Schulman, I. Sutskever, and P. Abbeel, “Variational
lossy autoencoder,” in International Conference on Learning Representations, 2017. https://openreview.net/forum?
id=BysvGP5ee
[Chen+ 2018] T. Q. Chen, X. Li, R. Grosse, and D. Duvenaud, “Isolating sources of disentanglement in variational
autoencoders,” in Advances in Neural Information Processing Systems, 2018. http://papers.nips.cc/paper/7527-isolating-
sources-of-disentanglement-in-variational-autoencoders
51](https://image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-51-2048.jpg)
![[Denton+ 2017] E. L. Denton and V. Birodkar, “Unsupervised learning of disentangled representations from video,” in Advances
in Neural Information Processing Systems, 2017, pp. 4414–4423. https://papers.nips.cc/paper/7028-unsupervised-learning-of-
disentangled-representations-from-video
[Donahue+ 2017] J. Donahue, P. Krahenb ¨ uhl, and T. Darrell, “Adversarial feature learning,” in ¨ International Conference on
Learning Representations, 2017. https://openreview.net/forum?id=BJtNZAFgg
[Dumoulin+ 2017] V. Dumoulin, I. Belghazi, B. Poole, O. Mastropietro, A. Lamb, M. Arjovsky, and A. Courville, “Adversarially
learned inference,” in International Conference on Learning Representations, 2017. https://openreview.net/forum?id=B1ElR4cgg
[Dupont 2018] E. Dupont, “Learning disentangled joint continuous and discrete representations,” in Advances in Neural
Information Processing Systems, 2018. http://papers.nips.cc/paper/7351-learning-disentangled-joint-continuous-and-discrete-
representations
[Esmaeili+ 2018] B.Esmaeili,H.Wu,S.Jain,A.Bozkurt,N.Siddharth,B.Paige,D.H.Brooks,J.Dy,andJ.-W. van de Meent, “Structured
disentangled representations,” arXiv:1804.02086, 2018. https://arxiv.org/abs/1804.02086
[Fraccaro+ 2017] M. Fraccaro, S. Kamronn, U. Paquet, and O. Winther, “A disentangled recognition and nonlinear dynamics
model for unsupervised learning,” in Advances in Neural Information Processing Systems, 2017, pp. 3601–3610. https://
papers.nips.cc/paper/6951-a-disentangled-recognition-and-nonlinear-dynamics-model-for-unsupervised-learning
[Gretton+ 2005] A. Gretton, O. Bousquet, A. Smola, and B. Scho ̈lkopf, “Measuring statistical dependence with Hilbert-Schmidt
norms,” in International Conference on Algorithmic Learning Theory. Springer, 2005, pp. 63–77. https://link.springer.com/chapter/
10.1007/11564089_7
[Gulrajani+ 2017] I. Gulrajani, K. Kumar, F. Ahmed, A. A. Taiga, F. Visin, D. Vazquez, and A. Courville, “PixelVAE: A latent
variable model for natural images,” in International Conference on Learning Representations, 2017. https://openreview.net/
forum?id=BJKYvt5lg
References
52](https://image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-52-2048.jpg)
![[Higgins+ 2017] I. Higgins, L. Matthey, A. Pal, C. Burgess, X. Glorot, M. Botvinick, S. Mohamed, and A. Lerchner, “beta-VAE:
Learning basic visual concepts with a constrained variational framework,” in International Conference on Learning
Representations, 2017. https://openreview.net/forum?id=Sy2fzU9gl
[Hoffman+ 2016] M. D. Hoffman and M. J. Johnson, “Elbo surgery: yet another way to carve up the variational evidence lower
bound,” in Workshop in Advances in Approximate Bayesian Inference, NIPS, 2016. http://approximateinference.org/accepted/
HoffmanJohnson2016.pdf
[Hsieh+2018] J.-T. Hsieh, B. Liu, D.-A. Huang, L. Fei-Fei, and J. C. Niebles, “Learning to decompose and disentangle
representations for video prediction,” in Advances in Neural Information Processing Systems, 2018. http://papers.nips.cc/paper/
7333-learning-to-decompose-and-disentangle-representations-for-video-prediction
[Johnson+ 2016] M. Johnson, D. K. Duvenaud, A. Wiltschko, R. P. Adams, and S. R. Datta, “Composing graphical models with
neural networks for structured representations and fast inference,” in Advances in Neural Information Processing Systems,
2016, pp. 2946–2954. https://papers.nips.cc/paper/6379-composing-graphical-models-with-neural-networks-for-structured-
representations-and-fast-inference
[Kim+ 2018] H. Kim and A. Mnih, “Disentangling by factorising,” in Proc. of the International Conference on Machine Learning,
2018, pp. 2649–2658. http://proceedings.mlr.press/v80/kim18b.html
[Kingma+ 2014a] D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” in International Conference on Learning
Representations, 2014. https://openreview.net/forum?id=33X9fd2-9FyZd
[Kingma+ 2014b] D. P. Kingma, S. Mohamed, D. J. Rezende, and M. Welling, “Semi-supervised learning with deep generative
models,” in Advances in Neural Information Processing Systems, 2014, pp. 3581–3589. https://papers.nips.cc/paper/5352-semi-
supervised-learning-with-deep-generative-models
References
53](https://image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-53-2048.jpg)
![[Kulkarni+ 2015] T.D.Kulkarni, W.F.Whitney, P.Kohli, and J.Tenenbaum, “Deep convolutional inverse graphics network,” in
Advances in Neural Information Processing Systems, 2015, pp. 2539–2547. https://papers.nips.cc/paper/5851-deep-
convolutional-inverse-graphics-network
[Kumar+ 2018] A. Kumar, P. Sattigeri, and A. Balakrishnan, “Variational inference of disentangled latent concepts from
unlabeled observations,” in International Conference on Learning Representations, 2018. https://openreview.net/forum?
id=H1kG7GZAW
[Lample+ 2017] G. Lample, N. Zeghidour, N. Usunier, A. Bordes, L. Denoyer et al., “Fader networks: Manipulating images by
sliding attributes,” in Advances in Neural Information Processing Systems, 2017, pp. 5967–5976. https://papers.nips.cc/paper/
7178-fader-networksmanipulating-images-by-sliding-attributes
[Locatello+ 2018] F. Locatello, S. Bauer, M. Lucic, S. Gelly, B. Scho ̈lkopf, and O. Bachem, “Challenging common assumptions
in the unsupervised learning of disentangled representations,” arXiv:1811.12359, 2018. https://arxiv.org/abs/1811.12359
[Lopez+ 2018] R. Lopez, J. Regier, M. I. Jordan, and N. Yosef, “Information constraints on auto-encoding variational bayes,” in
Advances in Neural Information Processing Systems, 2018. https://papers.nips.cc/paper/7850-information-constraints-on-auto-
encoding-variational-bayes
[Louizos+ 2016] C. Louizos, K. Swersky, Y. Li, M. Welling, and R. Zemel, “The variational fair autoencoder,” in International
Conference on Learning Representations, 2016. https://arxiv.org/abs/1511.00830
[Makhzani+ 2017] A. Makhzani and B. J. Frey, “PixelGAN autoencoders,” in Advances in Neural Information Processing
Systems, 2017, pp. 1975–1985. https://papers.nips.cc/paper/6793-pixelgan-autoencoders
[Sønderby+ 2016] C. K. Sønderby, T. Raiko, L. Maaløe, S. K. Sønderby, and O. Winther, “Ladder variational autoencoders,” in
Advances in Neural Information Processing Systems, 2016, pp. 3738–3746. https://papers.nips.cc/paper/6275-ladder-
variational-autoencoders
References
54](https://image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-54-2048.jpg)
![[van den Oord+ 2016] A. van den Oord, N. Kalchbrenner, L. Espeholt, O. Vinyals, and A. Graves, “Conditional image
generation with PixelCNN decoders,” in Advances in Neural Information Processing Systems, 2016, pp. 4790–4798. https://
papers.nips.cc/paper/6527-conditional-image-generation-with-pixelcnn-decoders
[van den Oord+ 2017] A. van den Oord, O. Vinyals et al., “Neural discrete representation learning,” in Advances in Neural
Information Processing Systems, 2017, pp. 6306–6315. https://papers.nips.cc/paper/7210-neural-discrete-representation-
learning
[Villegas+ 2017] R. Villegas, J. Yang, S. Hong, X. Lin, and H. Lee, “Decomposing motion and content for natural video
sequence prediction,” in International Conference on Learning Representations, 2017. https://openreview.net/forum?
id=rkEFLFqee
[Vincent+ 2008] P. Vincent, H. Larochelle, Y. Bengio, and P.-A. Manzagol, “Extracting and composing robust features with
denoising autoencoders,” in Proc. of the International Conference on Machine Learning, 2008, pp. 1096–1103. https://
dl.acm.org/citation.cfm?id=1390294
[Yingzhen+ 2018] L. Yingzhen and S. Mandt, “Disentangled sequential autoencoder,” in Proc. of the International Conference
on Machine Learning, 2018, pp. 5656–5665. http://proceedings.mlr.press/v80/yingzhen18a.html
[Zhao+ 2017a] S.Zhao, J.Song, and S.Ermon,“InfoVAE: Information maximizing variational autoencoders,” arXiv:1706.02262,
2017. https://arxiv.org/abs/1706.02262
[Zhao+ 2017b] S. Zhao, J. Song, and S. Ermon, “Learning hierarchical features from deep generative models,” in Proc. of the
International Conference on Machine Learning, 2017, pp. 4091–4099. http://proceedings.mlr.press/v70/zhao17c.html
References
55](https://image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-55-2048.jpg)



![• (SRL)
• [DL ]
https://www.slideshare.net/DeepLearningJP2016/dl-124128933
• SRL VAE VAE
4](https://crownmelresort.com/image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-4-2048.jpg)

![VAE
Variational Autoencoder (VAE) [Kingma+ 2014a]
•
• KL (ELBO)
• ELBO (VAE loss )
6
ℒVAE(θ, ϕ) = 𝔼 ̂p(x) [ 𝔼qϕ(z|x) [−log pθ(x|z)]] + 𝔼 ̂p(x) [
DKL (qϕ(z|x)∥p(z))]
※ VAE ELBO
𝔼 ̂p(x) [−log pθ(x)] = ℒVAE(θ, ϕ) − 𝔼 ̂p(x) [
DKL (qϕ(z|x)∥pθ(z|x))]
−ℒVAE 𝔼 ̂p(x) [−log pθ(x)]
ℒVAE
̂p(x)](https://crownmelresort.com/image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-6-2048.jpg)
![VAE
VAE loss
• 1 reparametrization trick
• 2 closed-form
• ,
closed-form
•
7
ℒVAE(θ, ϕ) = 𝔼 ̂p(x) [ 𝔼qϕ(z|x) [−log pθ(x|z)]] + 𝔼 ̂p(x) [
DKL (qϕ(z|x)∥p(z))]
z(i)
∼ qϕ(z|x(i)
)
qϕ(z|x) = 𝒩
(
μϕ(x), diag (σϕ(x))) p(z) = 𝒩(0,I)](https://crownmelresort.com/image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-7-2048.jpg)


![Maximum Mean Discrepancy (MMD)
MMD
• embedding
• ) MMD
•
10
k : 𝒳 → 𝒳 ℋ
φ : 𝒳 → ℋ px(x)
MMD (px, py) = 𝔼x∼px
[φ(x)] − 𝔼y∼py
[φ(y)]
2
ℋ
py(x)
𝒳 = ℋ = ℝd φ(x) = x
MMD (px, py) = μpx
− μpy
2
2
φ](https://crownmelresort.com/image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-10-2048.jpg)

![Meta-Prior
Meta-prior [Bengio+ 2013]
•
•
•
• But
• →meta-prior
12](https://crownmelresort.com/image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-12-2048.jpg)
![Meta-Prior [Bengio+ 2013]
Disentanglement
•
• )
•
•
• ) ( )
13](https://crownmelresort.com/image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-13-2048.jpg)
![Meta-Prior [Bengio+ 2013]
•
•
•
•
14](https://crownmelresort.com/image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-14-2048.jpg)



![VAE
meta-prior
aggregate ( )
VAE
• aggregate ( )
• VAE
18
z ∼ qϕ(z|x)
ℒVAE(θ, ϕ) + λ1 𝔼 ̂p(x) [
R1 (qϕ(z|x))]
+ λ2R2 (qϕ(z))
qϕ(z|x) qϕ(z) = 𝔼 ̂p(x) [qϕ(z|x)] =
1
N
N
∑
i=1
qϕ(z|x(i)
)
qϕ(z)
ℒVAE](https://crownmelresort.com/image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-18-2048.jpg)
![VAE
19
ℒVAE(θ, ϕ) + λ1 𝔼 ̂p(x) [
R1 (qϕ(z|x))]
+ λ2R2 (qϕ(z))
Optional](https://crownmelresort.com/image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-19-2048.jpg)


![Disentanglement
Disentangle
•
• disentangle disentangle
• ( disentangle )
• [Locatello+ 2018]
•
• (a) ELBO
• (b) x z
• (c)
22](https://crownmelresort.com/image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-22-2048.jpg)
![(a) ELBO
β-VAE [Higgins+ 2017]
• VAE Loss
2
•
23
ℒVAE(θ, ϕ) = 𝔼 ̂p(x) [ 𝔼qϕ(z|x) [−log pθ(x|z)]] + 𝔼 ̂p(x) [DKL (qKL(q|x)∥p(z))]
ℒβ−VAE(θ, ϕ) = ℒVAE(θ, ϕ) + λ1 𝔼 ̂p(x) [
DKL (qϕ(z|x)∥p(z))]
qϕ(z|x) p(z)
: [Higgins+ 2017]](https://crownmelresort.com/image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-23-2048.jpg)
![(b) x z
VAE Loss
2
•
aggregate ( ) KL [Hoffman+ 2016]
• FactorVAE[Kim+ 2018]
• β-TCVAE[Chen+ 2018] InfoVAE[Zhao+ 2017a] DIP-VAE[Kumar+ 2018]
24
ℒVAE(θ, ϕ) = 𝔼 ̂p(x) [ 𝔼qϕ(z|x) [−log pθ(x|z)]] + 𝔼 ̂p(x) [DKL (qKL(q|x)∥p(z))]
𝔼 ̂p(x) [
DKL (qϕ(z|x)∥p(z))]
= Iqϕ
(x; z) + DKL (qϕ(z)∥p(z))
x z Iqϕ
(x; z)
qϕ(z) p(z)](https://crownmelresort.com/image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-24-2048.jpg)
![(b) x z
Factor VAE [Kim+ 2018]
• βVAE loss
• toral correlation
• discriminator density ratio trick
• [DL ]Disentangling by Factorising
https://www.slideshare.net/DeepLearningJP2016/dldisentangling-by-factorising
25
ℒβ−VAE DKL (qϕ(z)∥p(z))
Iqϕ
(x; z)
TC (qϕ(z)) = DKL qϕ(z)∥
∏
j
qϕ (zj)
ℒFactorVAE(θ, ϕ) = ℒVAE(θ, ϕ) + λ2 TC (qϕ(z))](https://crownmelresort.com/image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-25-2048.jpg)
![(c)
HSIC-VAE [Lopez+ 2018]
• Hilbert-Schmidt independence criterion (HSIC) [Gretton+2005]
• HSIC ( AppendixA )
•
•
HFVAE [Esmaeili+ 2018]
26
zG = {zk}k∈G
ℒHSIC−VAE(θ, ϕ) = ℒVAE(θ, ϕ) + λ2HSIC
(
qϕ (zG1), qϕ (zG2))
s
HSIC (qϕ(z), p(s))
p(s)](https://crownmelresort.com/image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-26-2048.jpg)
![PixelGAN-AE [Makhzani+ 2017]
• PixelCNN[van den Oord+ 2016]
•
• VAE loss KL
• KL GAN
VIB[Alemi+ 2016]
Information dropout[Achille+ 2018] 27
ℒPixelGAN−AE(θ, ϕ) = ℒVAE(θ, ϕ) − Iqϕ
(x; z)
𝔼 ̂p(x) [
DKL (qϕ(z|x)∥p(z))]
= Iqϕ
(x; z) + DKL (qϕ(z)∥p(z))
Iqϕ
(x; z)
DKL (qϕ(z)∥p(z)) : [Makhzani+ 2017]](https://crownmelresort.com/image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-27-2048.jpg)
![Variational Fair Autoencoder (VFAE) [Louizos+ 2016]
•
• VAE loss MMD
•
• MMD HSIC HSIC-VAE[Lopez+ 2018]
• 2 VFAE[Louizos+ 2016] HSIC-VAE [Lopez+ 2018]
Fader Network[Lample+ 2017]
DC-IGN[Kulkarni+ 2015] 28
q(z|s = k)
s
s
s z
ℒVAEq(z|s = k′)
ℒVFAE(θ, ϕ) = ℒVAE + λ2
K
∑
ℓ=2
MMD (qϕ(z|s = ℓ), qϕ(z|s = 1))
qϕ(z|s = ℓ) =
∑
i:s(i)=ℓ
1
{i : s(i) = ℓ}
qϕ(z|x(i)
, s(i)
)](https://crownmelresort.com/image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-28-2048.jpg)


![VAE
M2 [Kingma+ 2014b]
•
•
• loss
• M1 (M1+M2 )
•
• DL Hacks Semi-supervised Learning with Deep Generative Models
https://www.slideshare.net/YuusukeIwasawa/dl-hacks2015-0421iwasawa
• Semi-Supervised Learning with Deep Generative Models pixyz
https://qiita.com/kogepan102/items/22b685ce7e9a51fbab98
31
qϕ(z, y|x) = qϕ(z|y, x)qϕ(y|x)
x z y
x
qϕ(z, y|x)
qϕ(z|y, x) ℒVAEy](https://crownmelresort.com/image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-31-2048.jpg)
![VLAE
Varational Lossy Autoencoder (VLAE) [Chen+ 2017]
•
•
• )
PixelVAE[Gulrajani+ 2017]
LadderVAE[Sønderby+ 2016] VLaAE[Zhao+ 2017b] 32
pθ(x|z) z
z
pθ(x|z) W(j)
pθ(x|z) =
∏
j
pθ (xj |z, xW( j))
j](https://crownmelresort.com/image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-32-2048.jpg)

![meta-prior
• meta-prior
• ) MNIST
) (SVAE) [Johnson+ 2016]
34
p(z)
N:
C: Categorical
M: mixture
G:
L; Learned Prior](https://crownmelresort.com/image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-34-2048.jpg)
![JointVAE [Dupont 2018]
• disentanglement
•
• Gumbel-Softmax
• KL (β-VAE 2 )
VQ-VAE[van den Oord+ 2017]
35
z c
qϕ(c|x)qϕ(z|x)
qϕ(c|x)
DKL (qϕ(z|x)qϕ(c|x)∥p(z)p(c)) = DKL (qϕ(z|x)∥p(z)) + DKL (qϕ(c|x)∥p(c))
ℒβ−VAE](https://crownmelresort.com/image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-35-2048.jpg)

![• Denoising Autoencoder (DAE) [Vincent+ 2008]
• [Yingzhen+ 2018] [Hsieh+2018]
• [Villegas+ 2017] [Denton+ 2017] [Fraccaro+ 2017]
37](https://crownmelresort.com/image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-37-2048.jpg)
![discriminator
•
• Adversarially Learned Inference (ALI) [Dumoulin+ 2017]
• Bidirectional GAN (BiGAN) [Donahue+ 2017]
38
qϕ(z|x) pθ(x|z)
pθ(x|z)p(z) qϕ(z|x) ̂p(x)
: [Dumoulin+ 2017]
: [Donahue+ 2017]](https://crownmelresort.com/image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-38-2048.jpg)

![Rate-Distortion Tradeoff
meta-prior
• ) βVAE [Higgins+ 2017]
FaderNetwork[Lample+ 2017]
”Rate-Distortion Tradeoff”[Alemi+ 2018a]
40](https://crownmelresort.com/image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-40-2048.jpg)
![Rate-Distortion Tradeoff
•
• Distortion:
• Rate: KL
• VAE ELBO
41
H = −
∫
p(x)log p(x)dx = Ep(x)[−log p(x)]
D = −
∬
p(x)qϕ(z|x)log pθ(x|z)dxdz = Ep(x) [ 𝔼qϕ(z|x) [−log pθ(x|z)]]
R =
∬
p(x)qϕ(z|x)log
qϕ(z|x)
p(z)
dxdz = 𝔼p(x) [DKL (qθ(q|x)∥p(z))]
qϕ(z|x) p(z)
ELBO = − ℒVAE = − (D + R)](https://crownmelresort.com/image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-41-2048.jpg)
![Rate-Distortion Tradeoff
Rate-Distortion Tradeoff [Alemi+ 2018a]
• Rate Distortion )
• ELBO
• Rate
•
• [Alemi+ 2018a] Rate
•
42
H − D ≤ R
: [Alemi+ 2018a]
D = H − R
min
ϕ,θ
D + |σ − R|
σ](https://crownmelresort.com/image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-42-2048.jpg)


![Rate-Distortion-Usefulness Tradeoff
Usefulness
•
•
•
• [Alemi+ 2018b]
….?( )
45
Dy = −
∬
p(x, y)qϕ(z|x)log pθ(y|z)dxdydz = 𝔼p(x,y) [ 𝔼qϕ(z|x) [−log pθ(y|z)]]
y
R − Dy](https://crownmelresort.com/image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-45-2048.jpg)


![• Rate-Distortion-Usefulness
• z
ex) GQN
• Meta-Prior
• meta-learning
• [DL ]Meta-Learning Probabilistic Inference for Prediction
https://www.slideshare.net/DeepLearningJP2016/dlmetalearning-probabilistic-inference-for-
prediction-126167192
• usefulnes ( )
•
• Pixyz Pixyzoo ( )
48](https://crownmelresort.com/image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-48-2048.jpg)
![Pixyz & Pixyzoo
Pixyz https://github.com/masa-su/pixyz
• (Pytorch )
•
Pixyzoo https://github.com/masa-su/pixyzoo
• Pixyz
• GQN VIB
• [DLHacks]PyTorch, Pixyz Generative Query Network
https://www.slideshare.net/DeepLearningJP2016/dlhackspytorch-pixyzgenerative-query-
network-126329901
49](https://crownmelresort.com/image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-49-2048.jpg)

![References
[Achille+ 2018] A. Achille and S. Soatto, “Information dropout: Learning optimal representations through noisy computation,”
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018. https://ieeexplore.ieee.org/document/8253482
[Alemi+ 2016] A. A. Alemi, I. Fischer, J. V. Dillon, and K. Murphy, “Deep variational information bottleneck,” in International
Conference on Learning Representations, 2016. https://openreview.net/forum?id=HyxQzBceg
[Alemi+ 2018a] A. Alemi, B. Poole, I. Fischer, J. Dillon, R. A. Saurous, and K. Murphy, “Fixing a broken ELBO,” in Proc. of the
International Conference on Machine Learning, 2018, pp. 159–168. http://proceedings.mlr.press/v80/alemi18a.html
[Alemi+ 2018b] A. A. Alemi and I. Fischer, “TherML: Thermodynamics of machine learning,” arXiv:1807.04162, 2018. https://
arxiv.org/abs/1807.04162
[Bengio+ 2013] Y. Bengio, A. Courville, and P. Vincent, “Representation learning: A review and new perspectives,” IEEE
Transactions on Pattern Analysis and Machine Intelligence, vol. 35, no. 8, pp. 1798–1828, 2013. https://ieeexplore.ieee.org/
document/6472238
[Chen+ 2017] X. Chen, D. P. Kingma, T. Salimans, Y. Duan, P. Dhariwal, J. Schulman, I. Sutskever, and P. Abbeel, “Variational
lossy autoencoder,” in International Conference on Learning Representations, 2017. https://openreview.net/forum?
id=BysvGP5ee
[Chen+ 2018] T. Q. Chen, X. Li, R. Grosse, and D. Duvenaud, “Isolating sources of disentanglement in variational
autoencoders,” in Advances in Neural Information Processing Systems, 2018. http://papers.nips.cc/paper/7527-isolating-
sources-of-disentanglement-in-variational-autoencoders
51](https://crownmelresort.com/image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-51-2048.jpg)
![[Denton+ 2017] E. L. Denton and V. Birodkar, “Unsupervised learning of disentangled representations from video,” in Advances
in Neural Information Processing Systems, 2017, pp. 4414–4423. https://papers.nips.cc/paper/7028-unsupervised-learning-of-
disentangled-representations-from-video
[Donahue+ 2017] J. Donahue, P. Krahenb ¨ uhl, and T. Darrell, “Adversarial feature learning,” in ¨ International Conference on
Learning Representations, 2017. https://openreview.net/forum?id=BJtNZAFgg
[Dumoulin+ 2017] V. Dumoulin, I. Belghazi, B. Poole, O. Mastropietro, A. Lamb, M. Arjovsky, and A. Courville, “Adversarially
learned inference,” in International Conference on Learning Representations, 2017. https://openreview.net/forum?id=B1ElR4cgg
[Dupont 2018] E. Dupont, “Learning disentangled joint continuous and discrete representations,” in Advances in Neural
Information Processing Systems, 2018. http://papers.nips.cc/paper/7351-learning-disentangled-joint-continuous-and-discrete-
representations
[Esmaeili+ 2018] B.Esmaeili,H.Wu,S.Jain,A.Bozkurt,N.Siddharth,B.Paige,D.H.Brooks,J.Dy,andJ.-W. van de Meent, “Structured
disentangled representations,” arXiv:1804.02086, 2018. https://arxiv.org/abs/1804.02086
[Fraccaro+ 2017] M. Fraccaro, S. Kamronn, U. Paquet, and O. Winther, “A disentangled recognition and nonlinear dynamics
model for unsupervised learning,” in Advances in Neural Information Processing Systems, 2017, pp. 3601–3610. https://
papers.nips.cc/paper/6951-a-disentangled-recognition-and-nonlinear-dynamics-model-for-unsupervised-learning
[Gretton+ 2005] A. Gretton, O. Bousquet, A. Smola, and B. Scho ̈lkopf, “Measuring statistical dependence with Hilbert-Schmidt
norms,” in International Conference on Algorithmic Learning Theory. Springer, 2005, pp. 63–77. https://link.springer.com/chapter/
10.1007/11564089_7
[Gulrajani+ 2017] I. Gulrajani, K. Kumar, F. Ahmed, A. A. Taiga, F. Visin, D. Vazquez, and A. Courville, “PixelVAE: A latent
variable model for natural images,” in International Conference on Learning Representations, 2017. https://openreview.net/
forum?id=BJKYvt5lg
References
52](https://crownmelresort.com/image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-52-2048.jpg)
![[Higgins+ 2017] I. Higgins, L. Matthey, A. Pal, C. Burgess, X. Glorot, M. Botvinick, S. Mohamed, and A. Lerchner, “beta-VAE:
Learning basic visual concepts with a constrained variational framework,” in International Conference on Learning
Representations, 2017. https://openreview.net/forum?id=Sy2fzU9gl
[Hoffman+ 2016] M. D. Hoffman and M. J. Johnson, “Elbo surgery: yet another way to carve up the variational evidence lower
bound,” in Workshop in Advances in Approximate Bayesian Inference, NIPS, 2016. http://approximateinference.org/accepted/
HoffmanJohnson2016.pdf
[Hsieh+2018] J.-T. Hsieh, B. Liu, D.-A. Huang, L. Fei-Fei, and J. C. Niebles, “Learning to decompose and disentangle
representations for video prediction,” in Advances in Neural Information Processing Systems, 2018. http://papers.nips.cc/paper/
7333-learning-to-decompose-and-disentangle-representations-for-video-prediction
[Johnson+ 2016] M. Johnson, D. K. Duvenaud, A. Wiltschko, R. P. Adams, and S. R. Datta, “Composing graphical models with
neural networks for structured representations and fast inference,” in Advances in Neural Information Processing Systems,
2016, pp. 2946–2954. https://papers.nips.cc/paper/6379-composing-graphical-models-with-neural-networks-for-structured-
representations-and-fast-inference
[Kim+ 2018] H. Kim and A. Mnih, “Disentangling by factorising,” in Proc. of the International Conference on Machine Learning,
2018, pp. 2649–2658. http://proceedings.mlr.press/v80/kim18b.html
[Kingma+ 2014a] D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” in International Conference on Learning
Representations, 2014. https://openreview.net/forum?id=33X9fd2-9FyZd
[Kingma+ 2014b] D. P. Kingma, S. Mohamed, D. J. Rezende, and M. Welling, “Semi-supervised learning with deep generative
models,” in Advances in Neural Information Processing Systems, 2014, pp. 3581–3589. https://papers.nips.cc/paper/5352-semi-
supervised-learning-with-deep-generative-models
References
53](https://crownmelresort.com/image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-53-2048.jpg)
![[Kulkarni+ 2015] T.D.Kulkarni, W.F.Whitney, P.Kohli, and J.Tenenbaum, “Deep convolutional inverse graphics network,” in
Advances in Neural Information Processing Systems, 2015, pp. 2539–2547. https://papers.nips.cc/paper/5851-deep-
convolutional-inverse-graphics-network
[Kumar+ 2018] A. Kumar, P. Sattigeri, and A. Balakrishnan, “Variational inference of disentangled latent concepts from
unlabeled observations,” in International Conference on Learning Representations, 2018. https://openreview.net/forum?
id=H1kG7GZAW
[Lample+ 2017] G. Lample, N. Zeghidour, N. Usunier, A. Bordes, L. Denoyer et al., “Fader networks: Manipulating images by
sliding attributes,” in Advances in Neural Information Processing Systems, 2017, pp. 5967–5976. https://papers.nips.cc/paper/
7178-fader-networksmanipulating-images-by-sliding-attributes
[Locatello+ 2018] F. Locatello, S. Bauer, M. Lucic, S. Gelly, B. Scho ̈lkopf, and O. Bachem, “Challenging common assumptions
in the unsupervised learning of disentangled representations,” arXiv:1811.12359, 2018. https://arxiv.org/abs/1811.12359
[Lopez+ 2018] R. Lopez, J. Regier, M. I. Jordan, and N. Yosef, “Information constraints on auto-encoding variational bayes,” in
Advances in Neural Information Processing Systems, 2018. https://papers.nips.cc/paper/7850-information-constraints-on-auto-
encoding-variational-bayes
[Louizos+ 2016] C. Louizos, K. Swersky, Y. Li, M. Welling, and R. Zemel, “The variational fair autoencoder,” in International
Conference on Learning Representations, 2016. https://arxiv.org/abs/1511.00830
[Makhzani+ 2017] A. Makhzani and B. J. Frey, “PixelGAN autoencoders,” in Advances in Neural Information Processing
Systems, 2017, pp. 1975–1985. https://papers.nips.cc/paper/6793-pixelgan-autoencoders
[Sønderby+ 2016] C. K. Sønderby, T. Raiko, L. Maaløe, S. K. Sønderby, and O. Winther, “Ladder variational autoencoders,” in
Advances in Neural Information Processing Systems, 2016, pp. 3738–3746. https://papers.nips.cc/paper/6275-ladder-
variational-autoencoders
References
54](https://crownmelresort.com/image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-54-2048.jpg)
![[van den Oord+ 2016] A. van den Oord, N. Kalchbrenner, L. Espeholt, O. Vinyals, and A. Graves, “Conditional image
generation with PixelCNN decoders,” in Advances in Neural Information Processing Systems, 2016, pp. 4790–4798. https://
papers.nips.cc/paper/6527-conditional-image-generation-with-pixelcnn-decoders
[van den Oord+ 2017] A. van den Oord, O. Vinyals et al., “Neural discrete representation learning,” in Advances in Neural
Information Processing Systems, 2017, pp. 6306–6315. https://papers.nips.cc/paper/7210-neural-discrete-representation-
learning
[Villegas+ 2017] R. Villegas, J. Yang, S. Hong, X. Lin, and H. Lee, “Decomposing motion and content for natural video
sequence prediction,” in International Conference on Learning Representations, 2017. https://openreview.net/forum?
id=rkEFLFqee
[Vincent+ 2008] P. Vincent, H. Larochelle, Y. Bengio, and P.-A. Manzagol, “Extracting and composing robust features with
denoising autoencoders,” in Proc. of the International Conference on Machine Learning, 2008, pp. 1096–1103. https://
dl.acm.org/citation.cfm?id=1390294
[Yingzhen+ 2018] L. Yingzhen and S. Mandt, “Disentangled sequential autoencoder,” in Proc. of the International Conference
on Machine Learning, 2018, pp. 5656–5665. http://proceedings.mlr.press/v80/yingzhen18a.html
[Zhao+ 2017a] S.Zhao, J.Song, and S.Ermon,“InfoVAE: Information maximizing variational autoencoders,” arXiv:1706.02262,
2017. https://arxiv.org/abs/1706.02262
[Zhao+ 2017b] S. Zhao, J. Song, and S. Ermon, “Learning hierarchical features from deep generative models,” in Proc. of the
International Conference on Machine Learning, 2017, pp. 4091–4099. http://proceedings.mlr.press/v70/zhao17c.html
References
55](https://crownmelresort.com/image.slidesharecdn.com/20190119dljournalclubweb-190401063633/75/DL-Recent-Advances-in-Autoencoder-Based-Representation-Learning-55-2048.jpg)

1. Recent advances in autoencoder-based representation learning include incorporating meta-priors to encourage disentanglement and using rate-distortion and rate-distortion-usefulness tradeoffs to balance compression and reconstruction. 2. Variational autoencoders introduce priors to disentangle latent factors, but recent work aggregates posteriors to directly encourage disentanglement. 3. The rate-distortion framework balances the rate of information transmission against reconstruction distortion, while rate-distortion-usefulness also considers downstream task usefulness.
![[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...](https://cdn.slidesharecdn.com/ss_thumbnails/20190426akuzawa-190426020057-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Learning Latent Dynamics for Planning from Pixels](https://cdn.slidesharecdn.com/ss_thumbnails/taniguchi20181221-190104064850-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Disentangling by Factorising](https://cdn.slidesharecdn.com/ss_thumbnails/20180720disentanglingbyfactorising-180720000930-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]`強化学習のための状態表現学習 -より良い「世界モデル」の獲得に向けて-](https://cdn.slidesharecdn.com/ss_thumbnails/20181026staterepresenration-181127055206-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...](https://cdn.slidesharecdn.com/ss_thumbnails/20200626journalclubpub-200630064755-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]World Models](https://cdn.slidesharecdn.com/ss_thumbnails/20180427-180427003856-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DLHacks]StyleGANとBigGANのStyle mixing, morphing](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks0805-190815052222-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspectralnorm1-170907072536-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Temporal Abstraction in NeurIPS2019](https://cdn.slidesharecdn.com/ss_thumbnails/20191115-191112082849-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]SlowFast Networks for Video Recognition](https://cdn.slidesharecdn.com/ss_thumbnails/20191206slowfastnetworkkuboshizuma-191206010601-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Progressive Growing of GANs for Improved Quality, Stability, and Varia...](https://cdn.slidesharecdn.com/ss_thumbnails/kuboshizuma20180316-180525003941-thumbnail.jpg?width=640&height=640&fit=bounds)







































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)


















