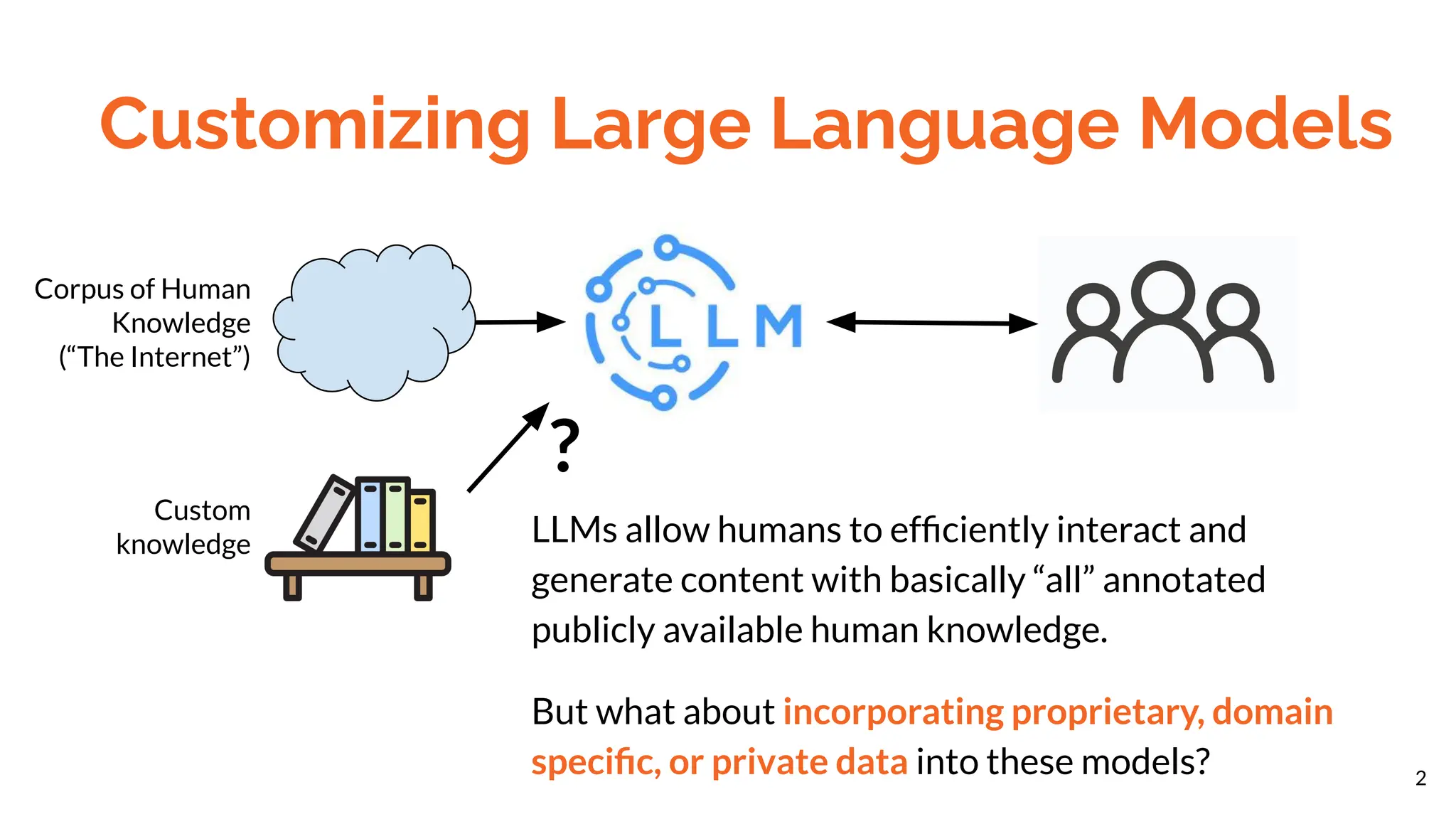
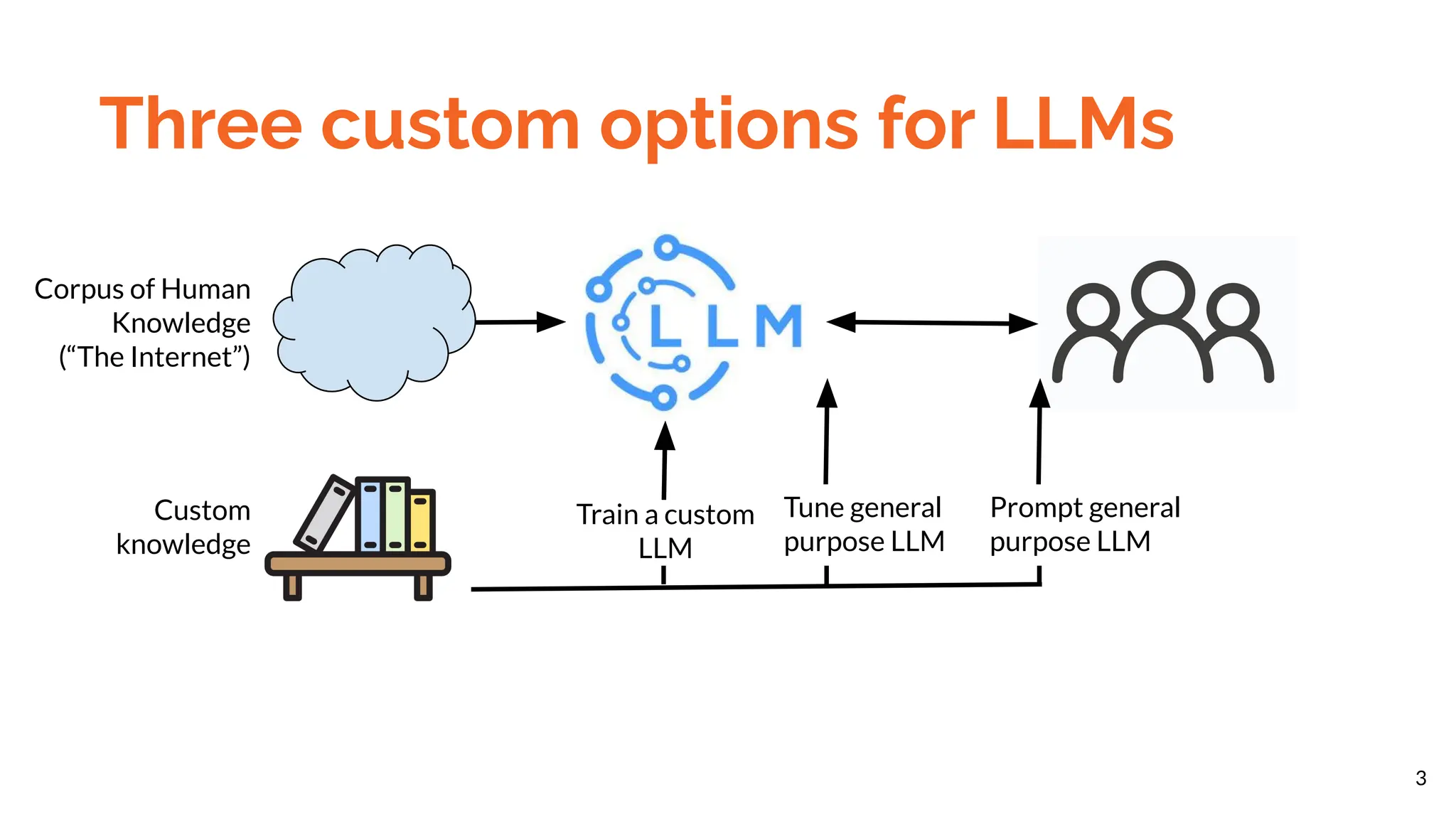
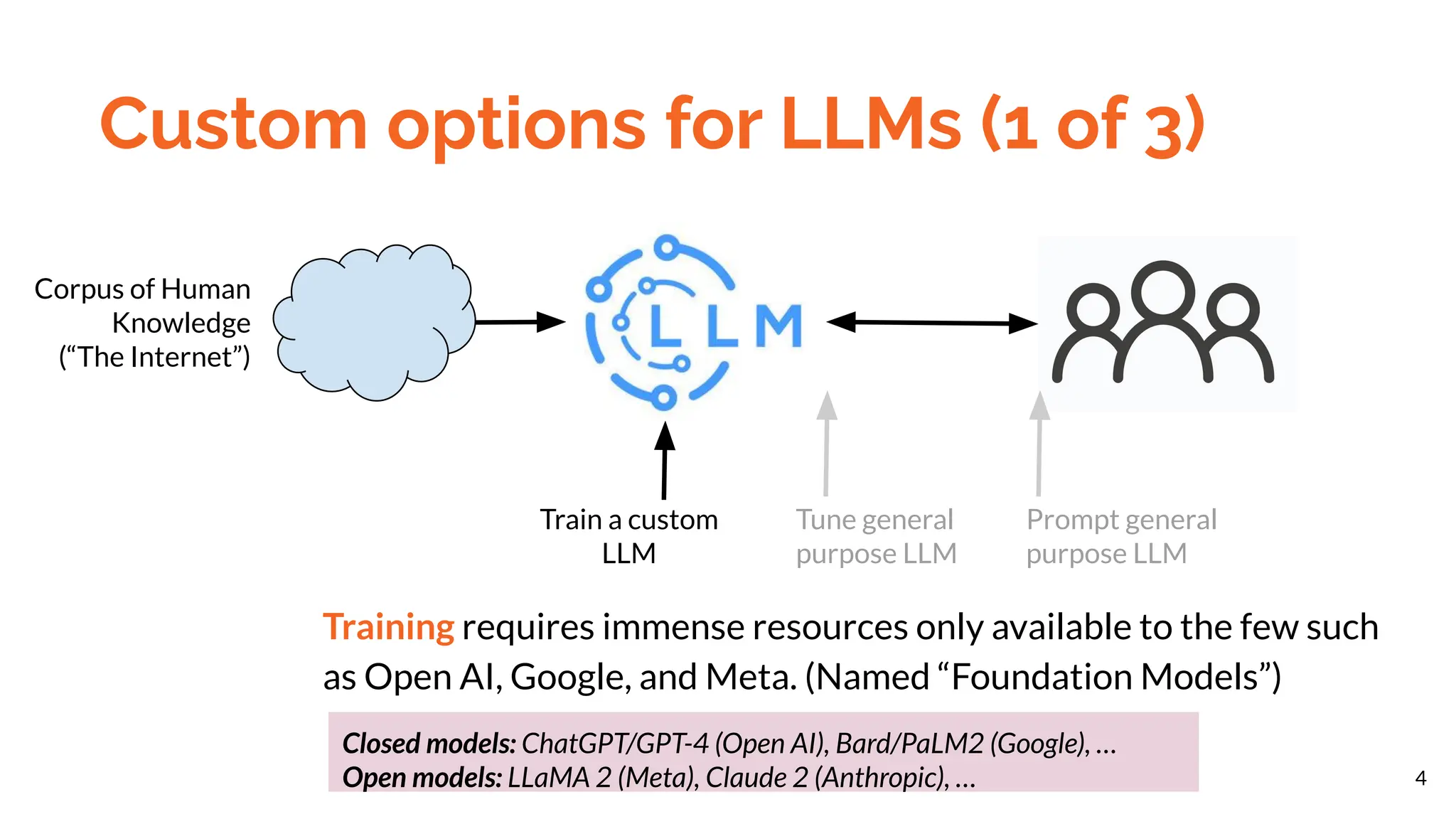
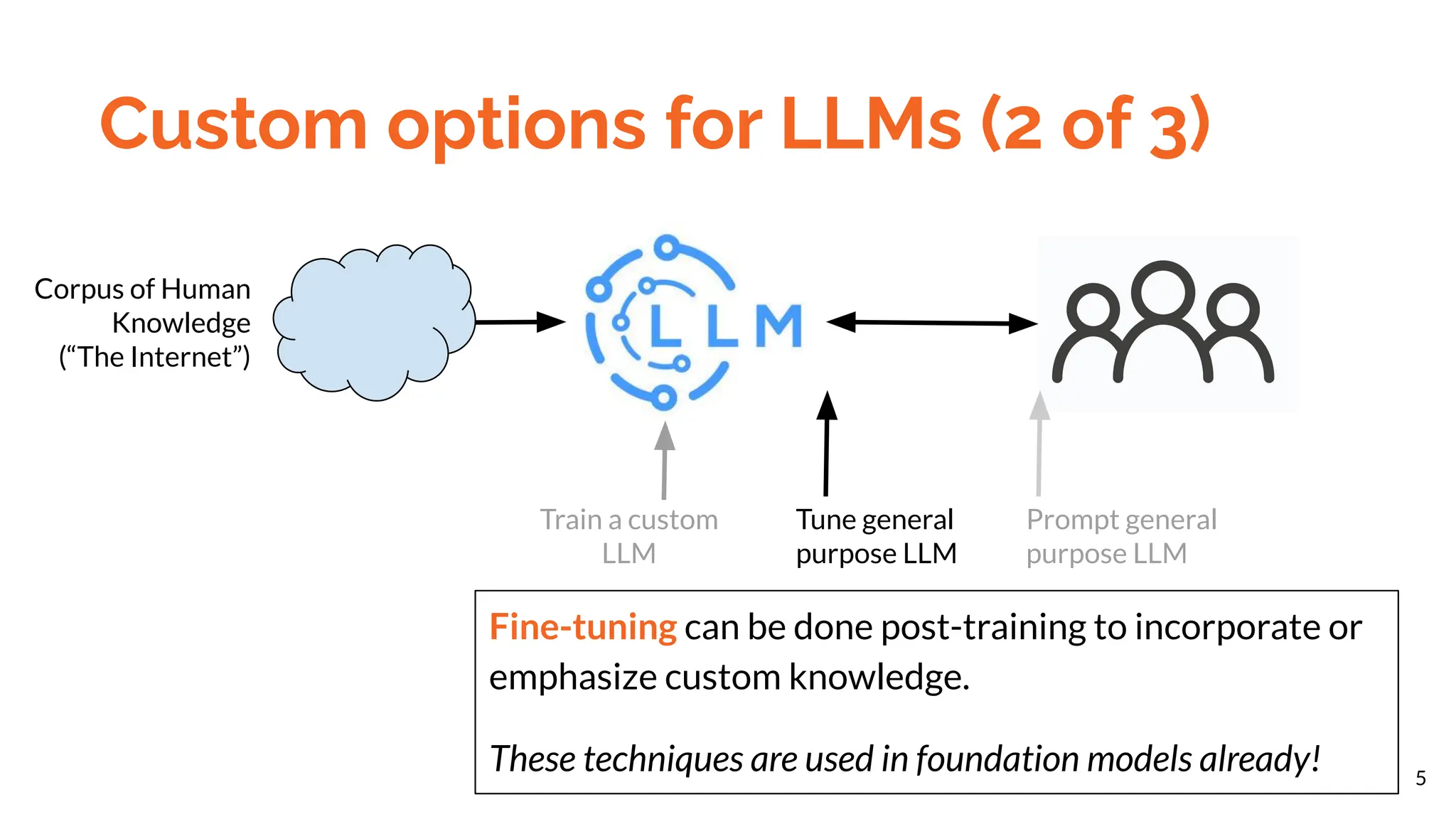
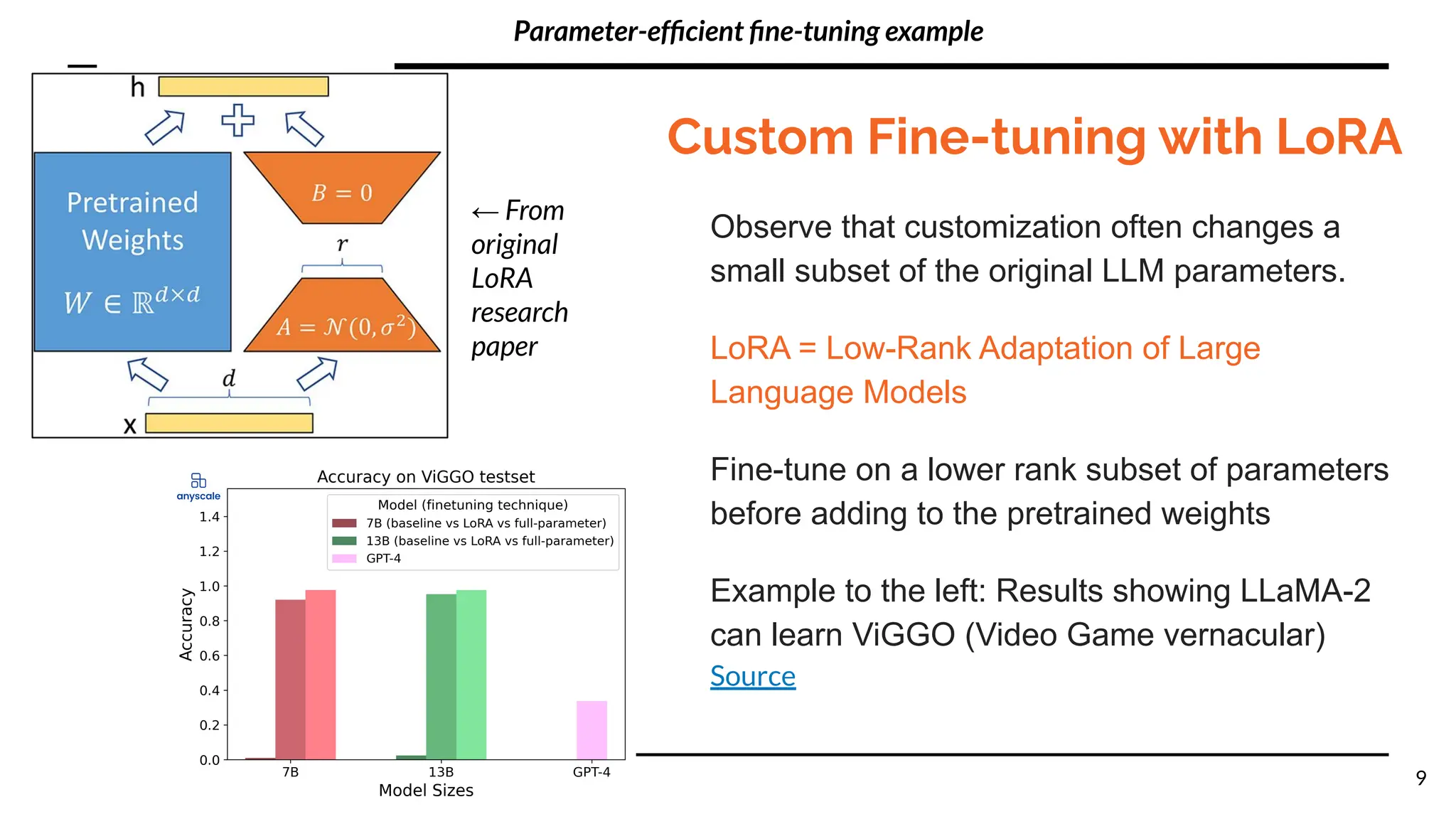
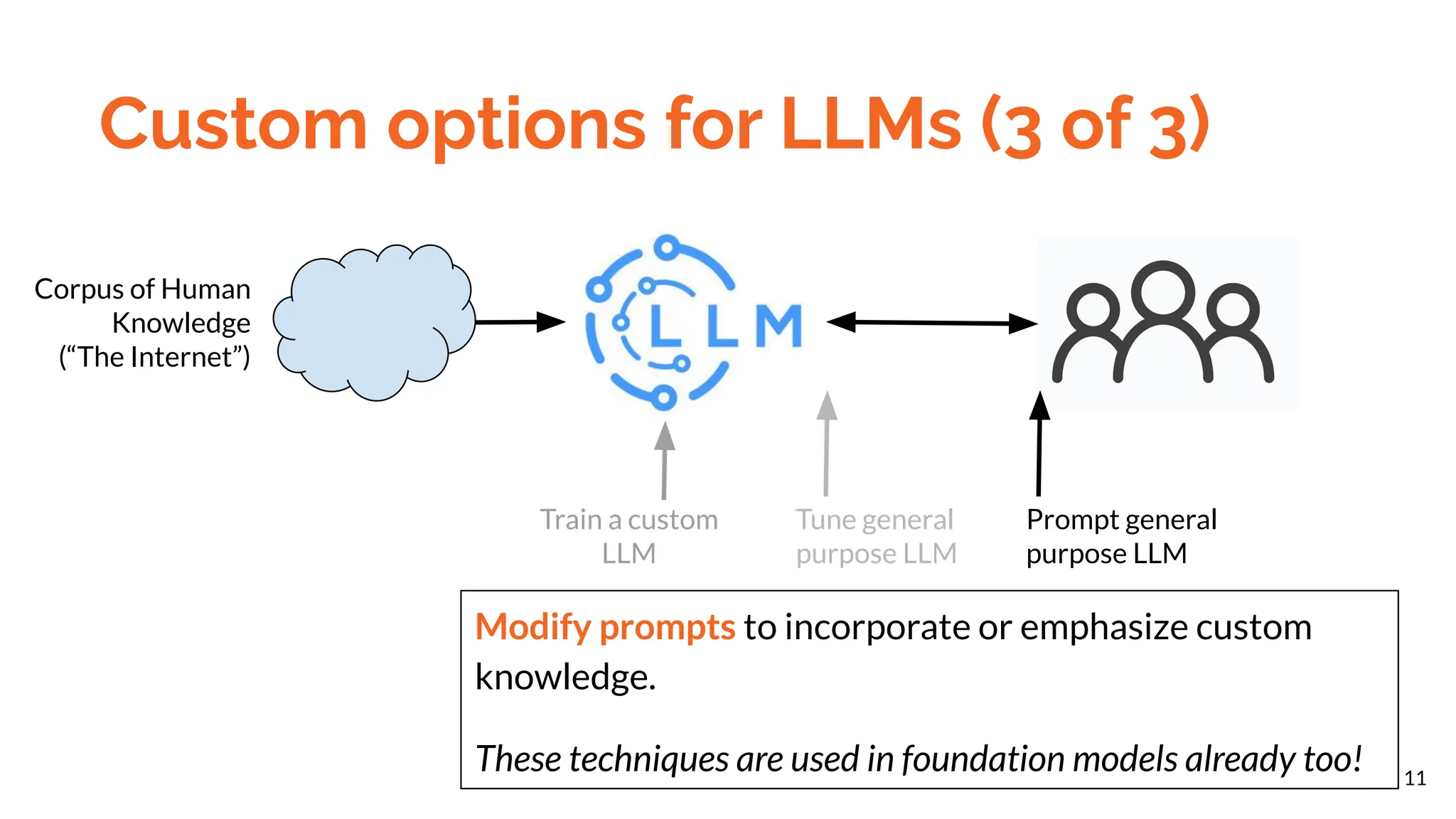
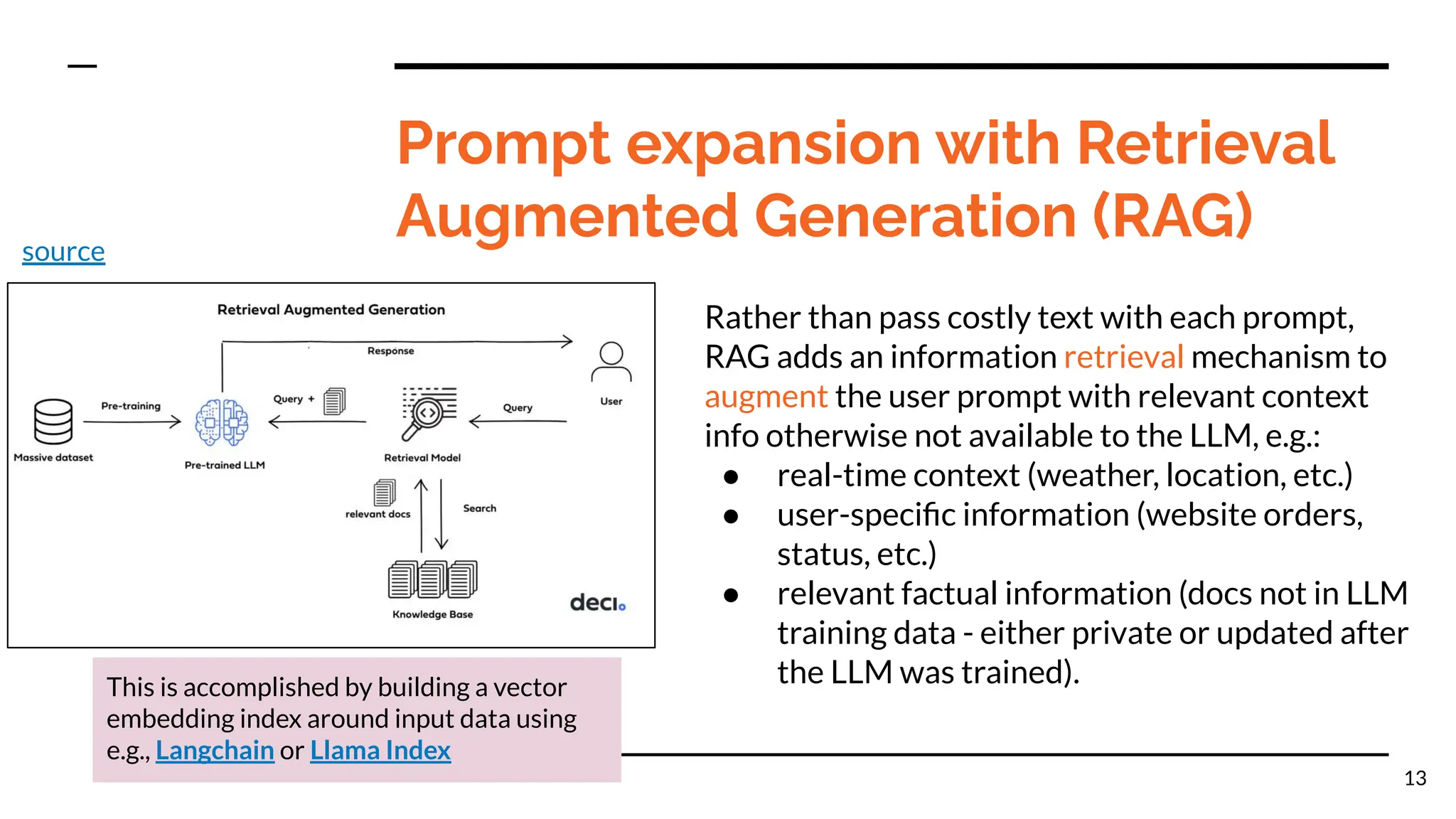
The document discusses different methods for customizing large language models (LLMs) with proprietary or private data, including training a custom model, fine-tuning a general model, and prompting with expanded inputs. Fine-tuning techniques like low-rank adaptation and supervised fine-tuning allow emphasizing custom knowledge without full retraining. Prompt expansion using techniques like retrieval augmented generation can provide additional context beyond the character limit.






![Summary
Beyond an all-out retraining, there are two
main techniques to improve LLM output
relevance summarized as [ref]:
● Fine-tune model for form (e.g., LoRA)
● Prompt expansion for fact (e.g., RAG)
Also, more LLMs are providing tools for
custom data (see demo: NotebookLM)
14
Source](https://image.slidesharecdn.com/customizingllms-231103202846-426ebdf1/75/Customizing-LLMs-14-2048.jpg)
















![Summary
Beyond an all-out retraining, there are two
main techniques to improve LLM output
relevance summarized as [ref]:
● Fine-tune model for form (e.g., LoRA)
● Prompt expansion for fact (e.g., RAG)
Also, more LLMs are providing tools for
custom data (see demo: NotebookLM)
14
Source](https://crownmelresort.com/image.slidesharecdn.com/customizingllms-231103202846-426ebdf1/75/Customizing-LLMs-14-2048.jpg)






































































