Download as PDF, PPTX

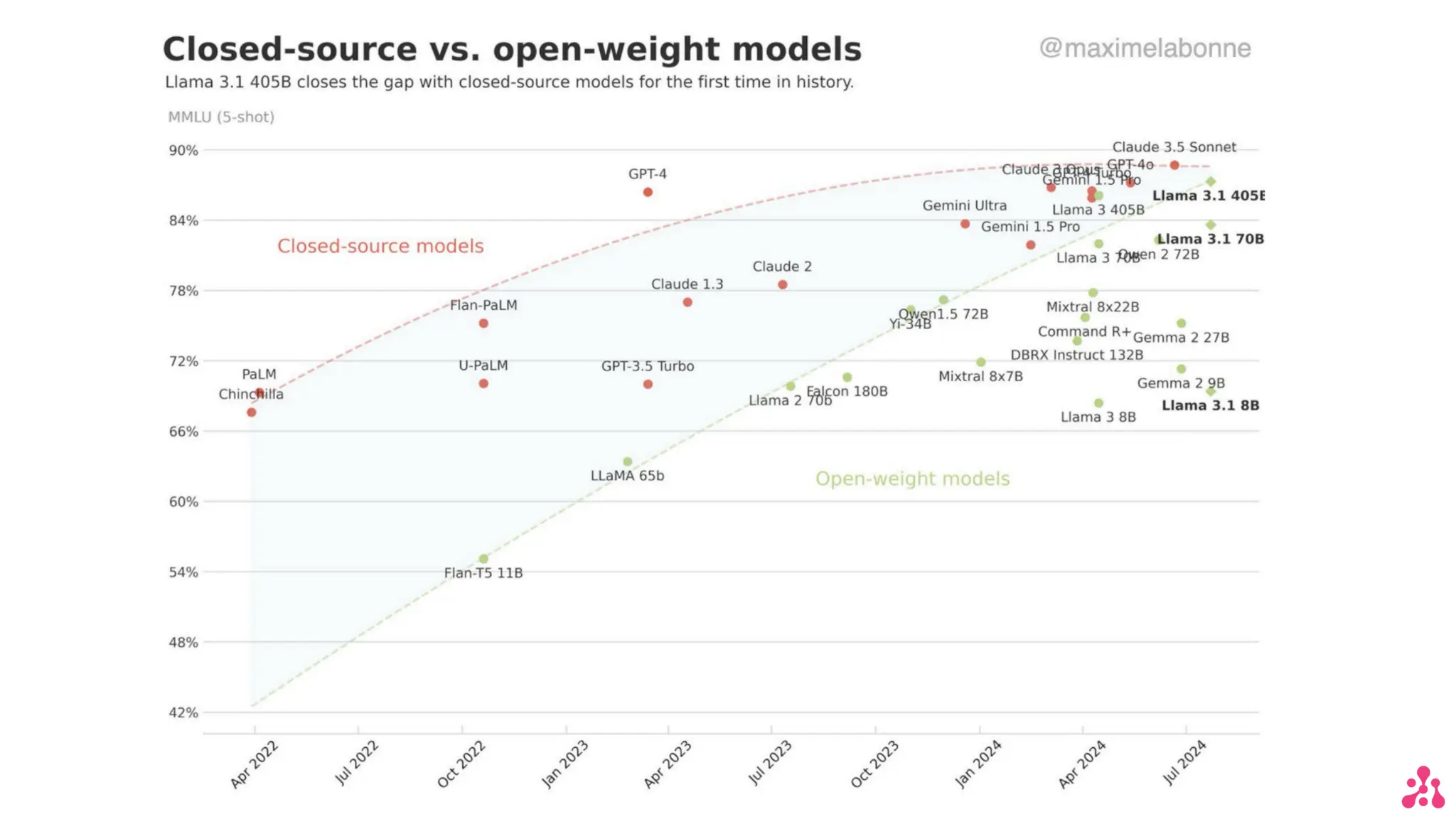

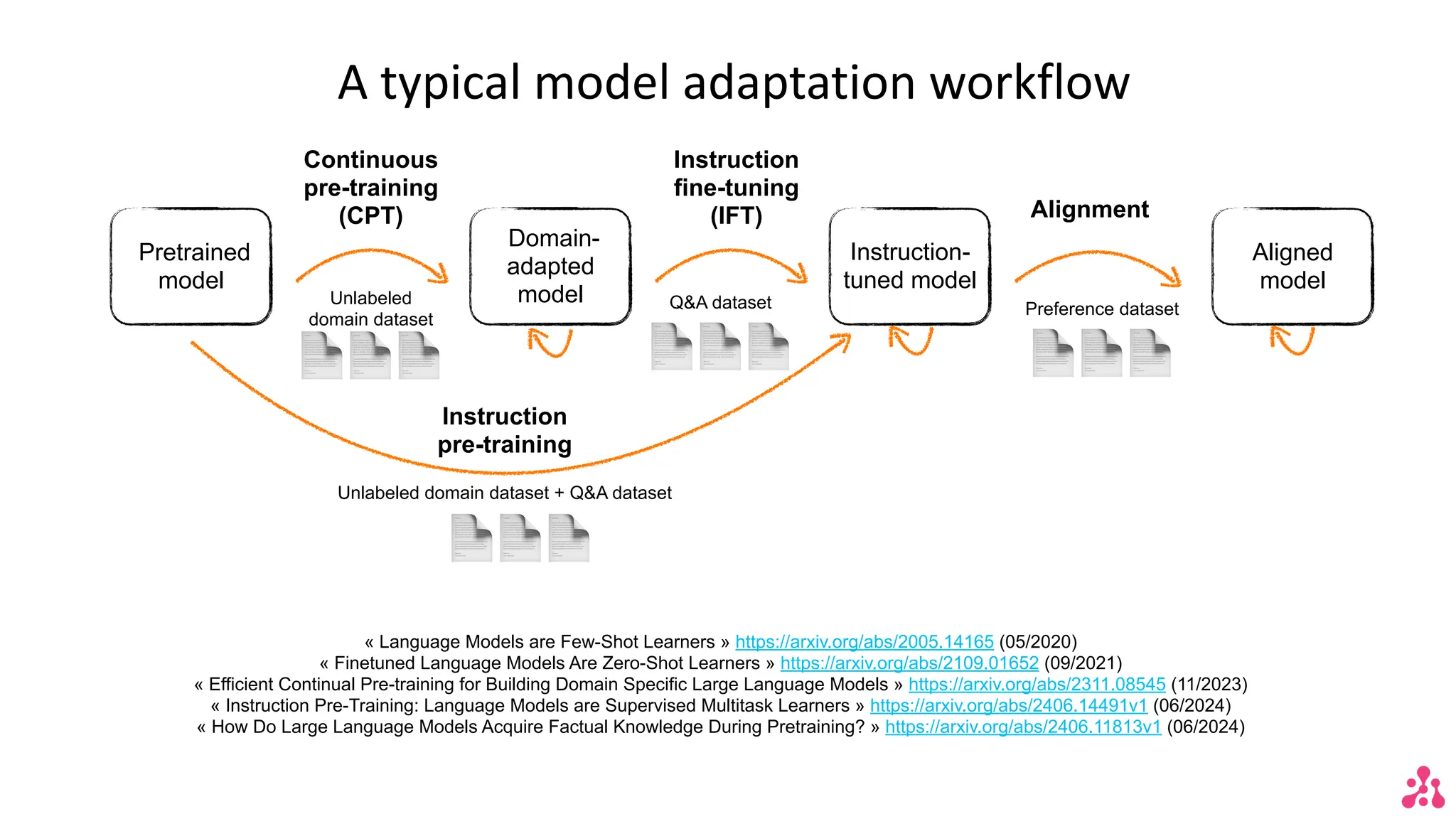


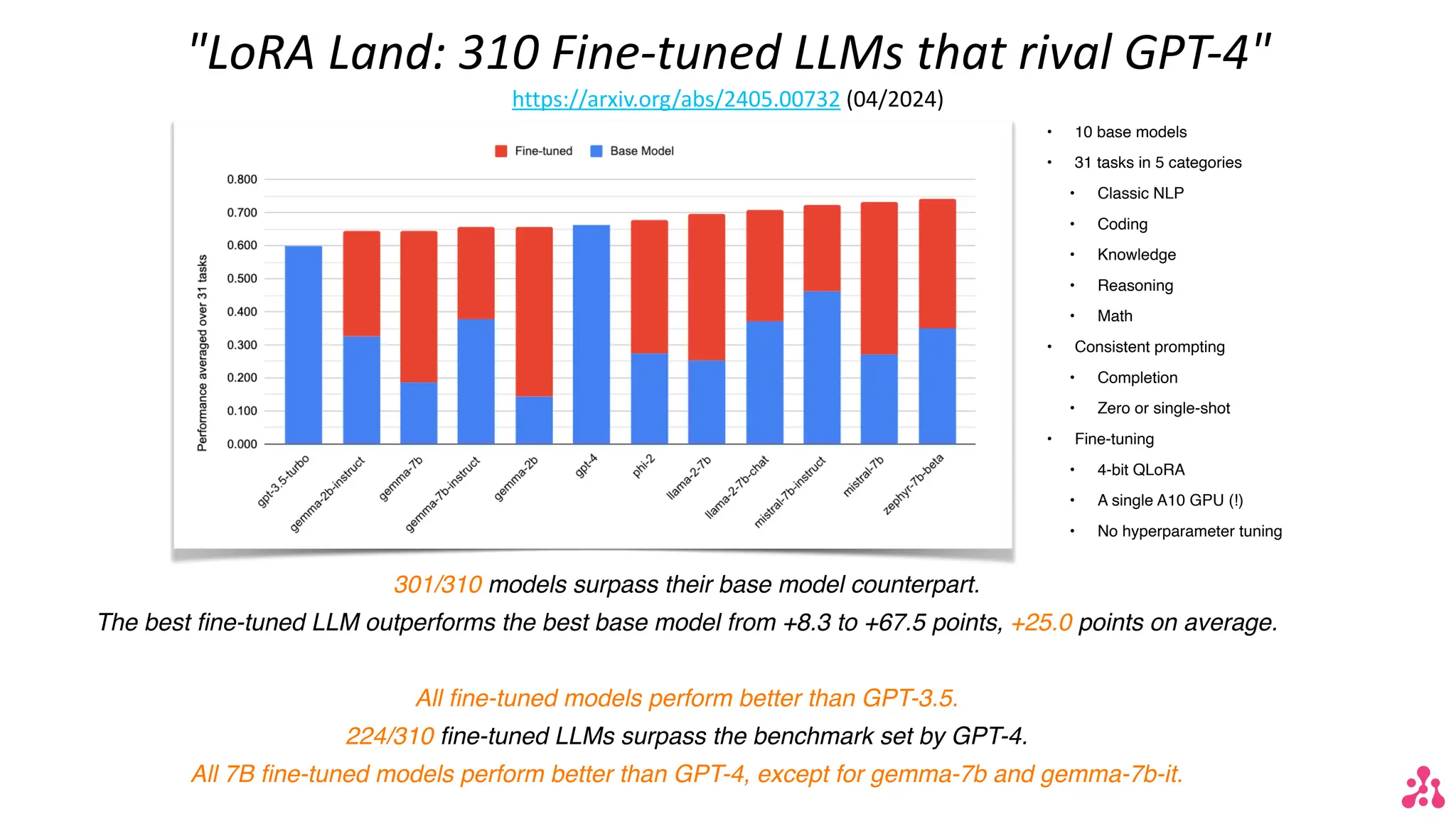
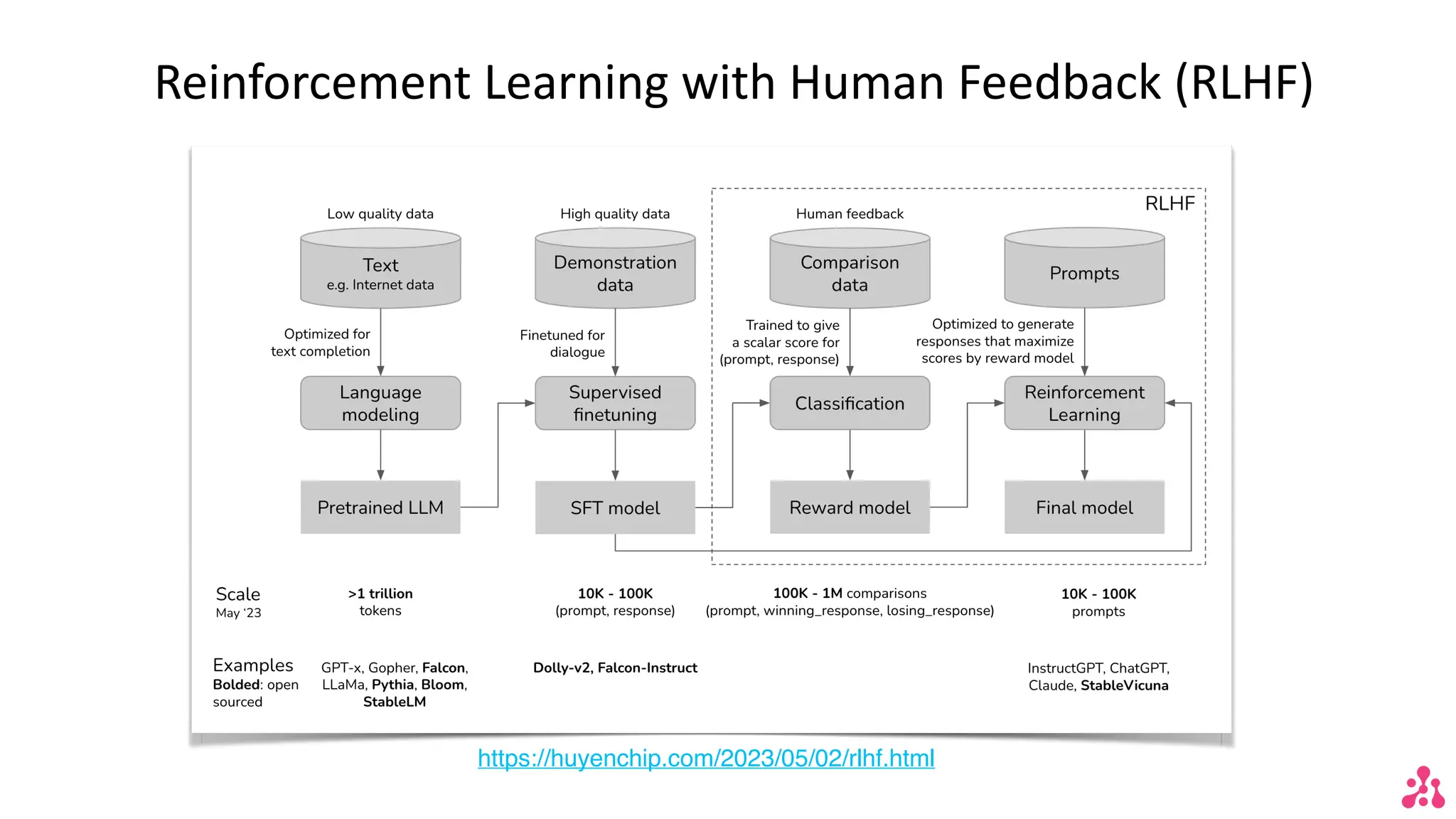



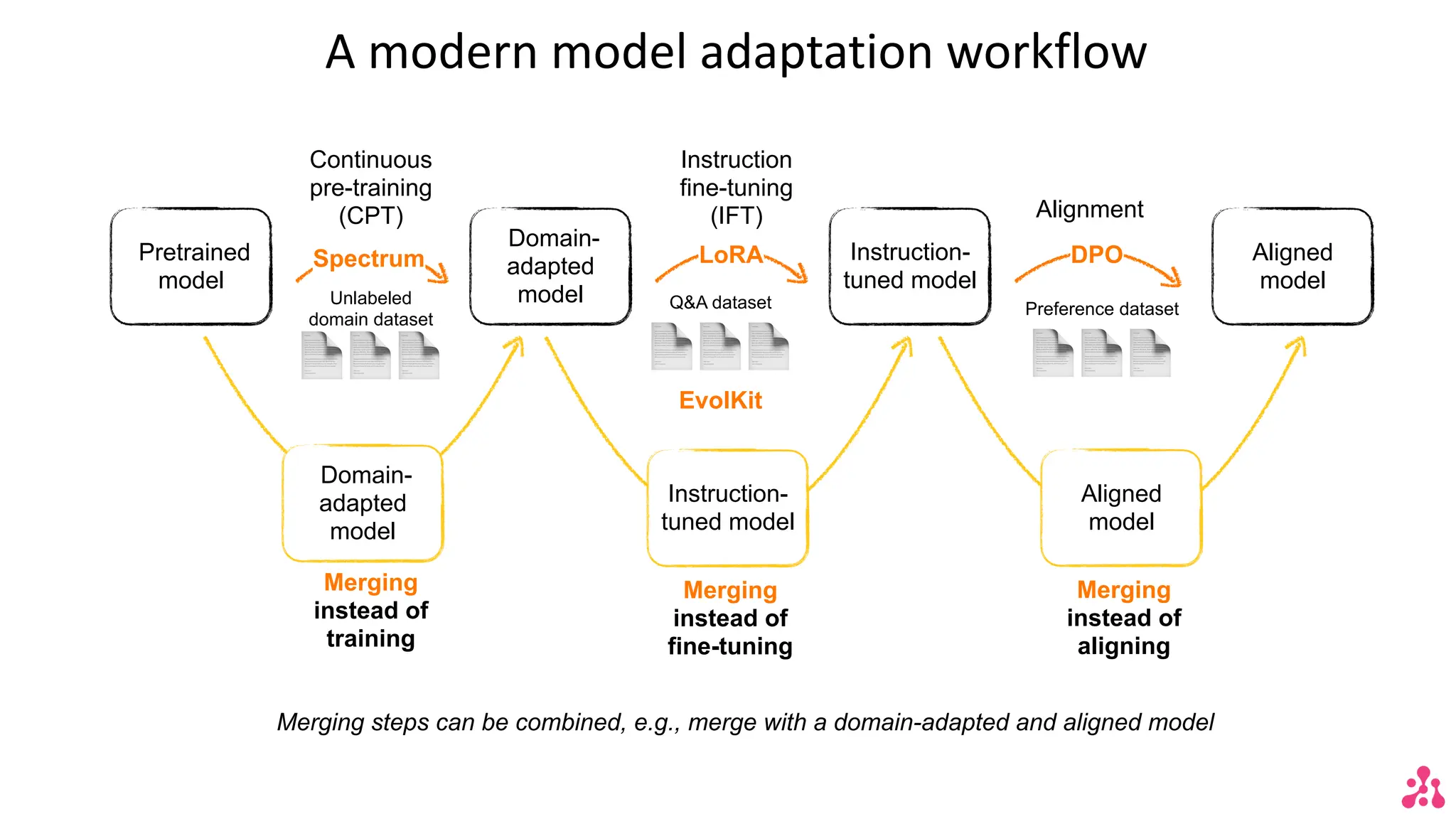
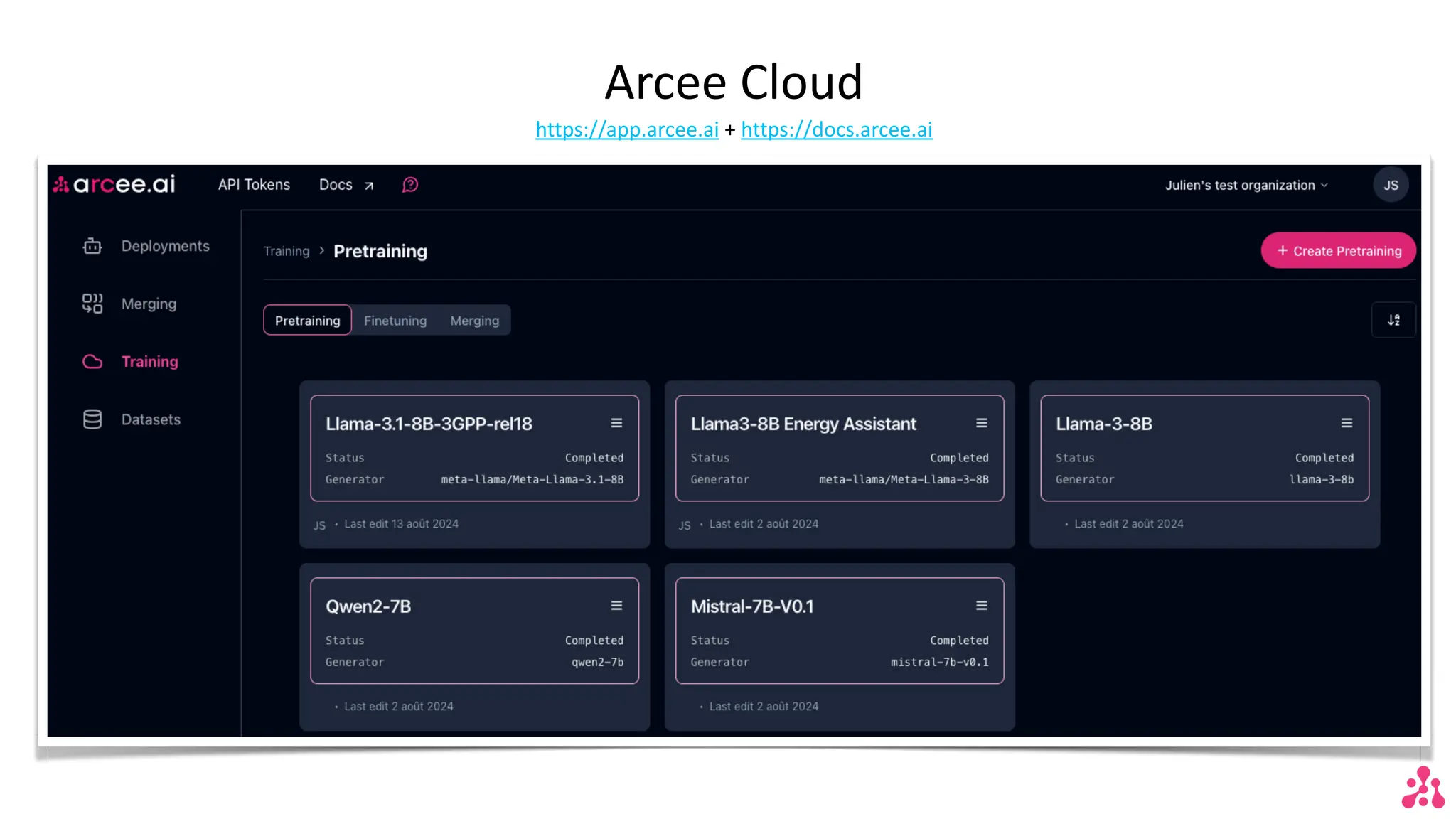




















The document discusses the advantages of small language models (SLMs) for enterprise applications, emphasizing accessibility, transparency, privacy, and cost optimization. It outlines various workflows for model adaptation including continuous pre-training and fine-tuning techniques like low-rank adaptation (LoRA) and direct preference optimization (DPO). Additionally, it highlights innovative approaches to model merging and the recent developments of Arcee's models that outperform current benchmarks.

![[DSC Europe 23] Ivan Petrovic - Approach to Architecting Generative AI Solutions](https://cdn.slidesharecdn.com/ss_thumbnails/ivanpetrovic-approachtoarchitectinggenerativeaisolutions-231129100808-16df2918-thumbnail.jpg?width=640&height=640&fit=bounds)






























































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)


