Downloaded 80 times








![My dog is hairy My dog is hairy
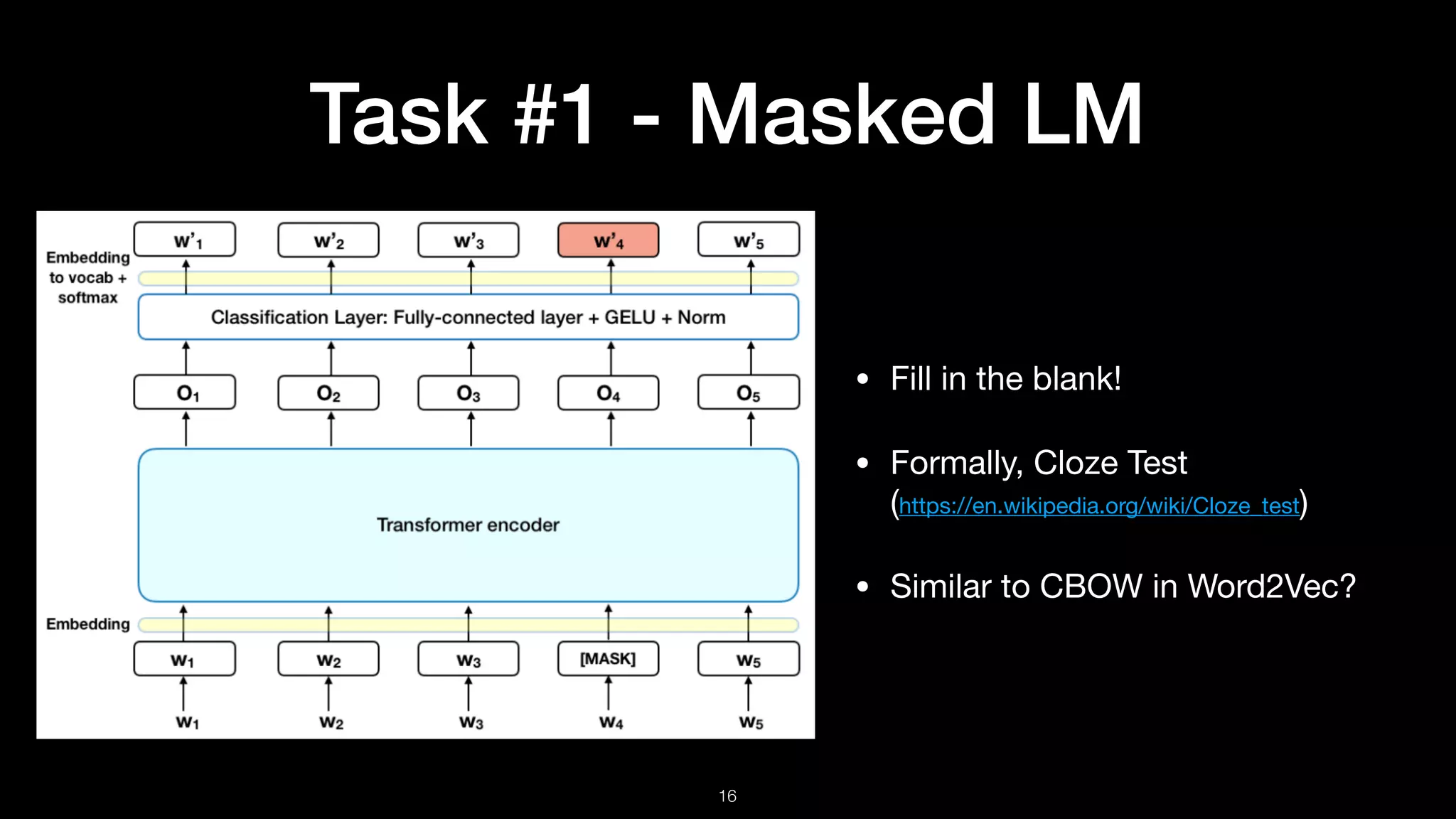
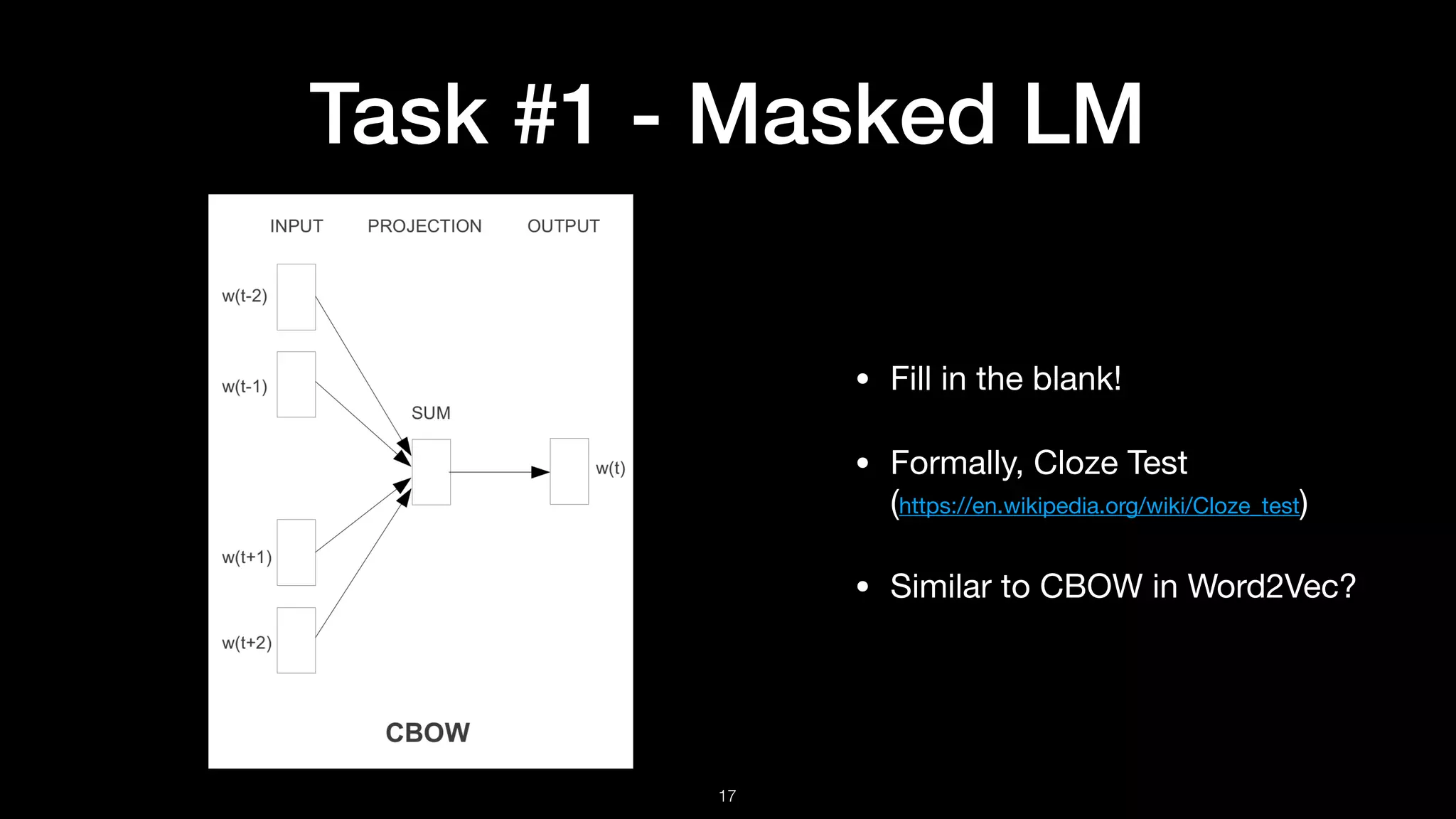
Choose 15% of tokens at random
80%
10%
10%
My dog is [Mask]
My dog is hairy
My dog is apple
Masked LM Procedure](https://image.slidesharecdn.com/bert-190114085327/75/BERT-Pre-training-of-Deep-Bidirectional-Transformers-for-Language-Understanding-18-2048.jpg)
![Task #2 - Next Sentence Prediction (NSP)
• Classification - [IsNext, NotNext]
• Final pre-trained model achieved 97-98%
accuracy.
!19](https://image.slidesharecdn.com/bert-190114085327/75/BERT-Pre-training-of-Deep-Bidirectional-Transformers-for-Language-Understanding-19-2048.jpg)
![!22
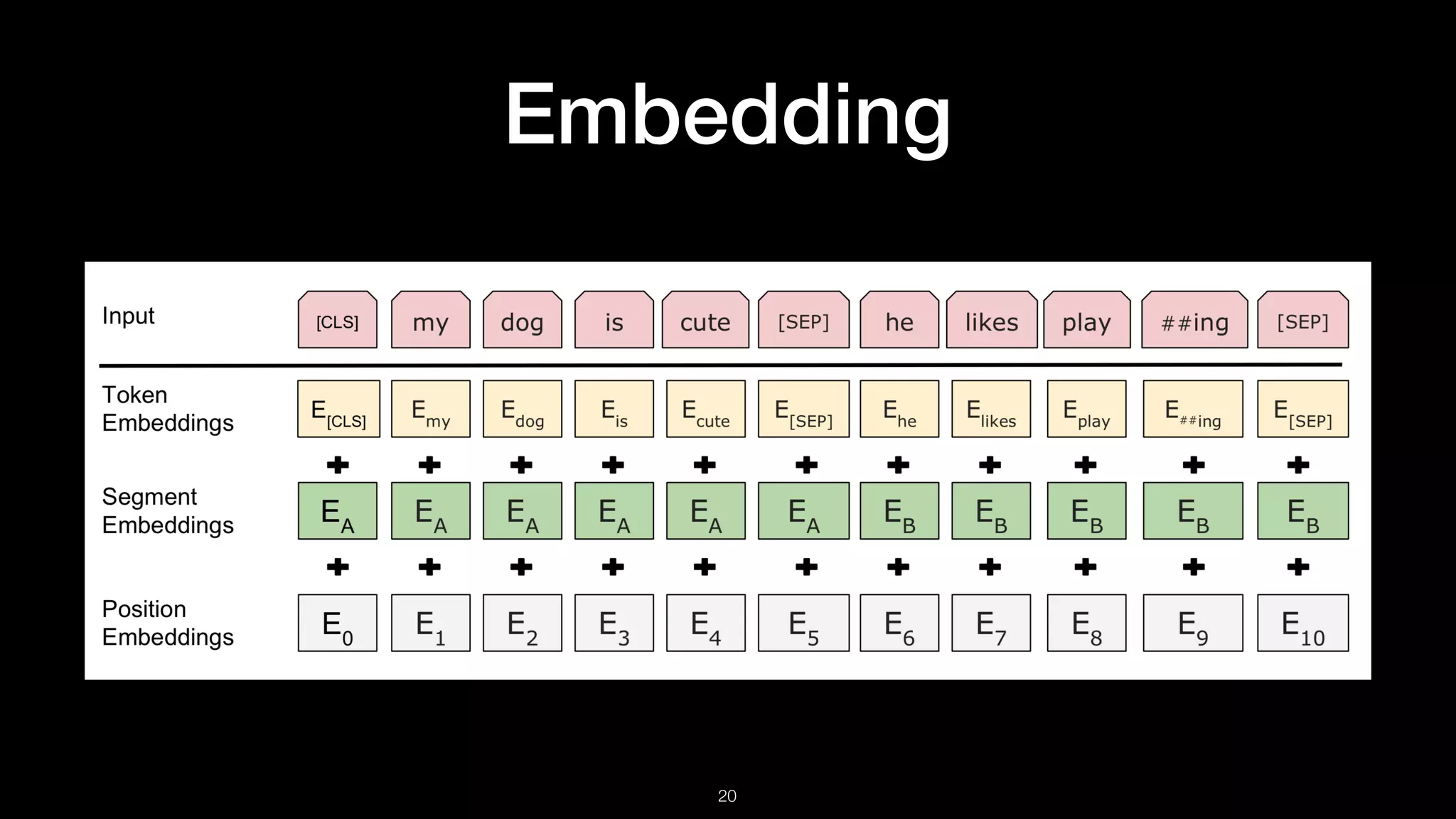
• The first token of every sequence is
always the special classification
embedding [CLS]. The final hidden state
corresponding to this token is used as the
aggregate sequence representation for
classification tasks. For non-classifcation
tasks, this vector is ignored.
• Sentence pairs are packed together into a
single sequence. The authors separate
them in two ways.
1. Separate with special token [SEP].
2. Add learned sentence embedding to
every token of corresponding
sentence.](https://image.slidesharecdn.com/bert-190114085327/75/BERT-Pre-training-of-Deep-Bidirectional-Transformers-for-Language-Understanding-22-2048.jpg)

![Differences between OpenAI GPT
!24
Model Corpus [CLS] / [SEP] tokens Steps Learning rate
BERT
BooksCorpus
+
Wikipedia
Learns during
pre-training
1M steps with batch
size of
128,000 words
Task-specific
fine-tuning
learning rate
OpenAI GPT BooksCorpus
Only introduced at
fine-tuning time
1M steps with batch
size of
32,000 words
Same learning rate of
5e-5](https://image.slidesharecdn.com/bert-190114085327/75/BERT-Pre-training-of-Deep-Bidirectional-Transformers-for-Language-Understanding-24-2048.jpg)



































![My dog is hairy My dog is hairy
Choose 15% of tokens at random
80%
10%
10%
My dog is [Mask]
My dog is hairy
My dog is apple
Masked LM Procedure](https://crownmelresort.com/image.slidesharecdn.com/bert-190114085327/75/BERT-Pre-training-of-Deep-Bidirectional-Transformers-for-Language-Understanding-18-2048.jpg)
![Task #2 - Next Sentence Prediction (NSP)
• Classification - [IsNext, NotNext]
• Final pre-trained model achieved 97-98%
accuracy.
!19](https://crownmelresort.com/image.slidesharecdn.com/bert-190114085327/75/BERT-Pre-training-of-Deep-Bidirectional-Transformers-for-Language-Understanding-19-2048.jpg)

![!22
• The first token of every sequence is
always the special classification
embedding [CLS]. The final hidden state
corresponding to this token is used as the
aggregate sequence representation for
classification tasks. For non-classifcation
tasks, this vector is ignored.
• Sentence pairs are packed together into a
single sequence. The authors separate
them in two ways.
1. Separate with special token [SEP].
2. Add learned sentence embedding to
every token of corresponding
sentence.](https://crownmelresort.com/image.slidesharecdn.com/bert-190114085327/75/BERT-Pre-training-of-Deep-Bidirectional-Transformers-for-Language-Understanding-22-2048.jpg)

![Differences between OpenAI GPT
!24
Model Corpus [CLS] / [SEP] tokens Steps Learning rate
BERT
BooksCorpus
+
Wikipedia
Learns during
pre-training
1M steps with batch
size of
128,000 words
Task-specific
fine-tuning
learning rate
OpenAI GPT BooksCorpus
Only introduced at
fine-tuning time
1M steps with batch
size of
32,000 words
Same learning rate of
5e-5](https://crownmelresort.com/image.slidesharecdn.com/bert-190114085327/75/BERT-Pre-training-of-Deep-Bidirectional-Transformers-for-Language-Understanding-24-2048.jpg)























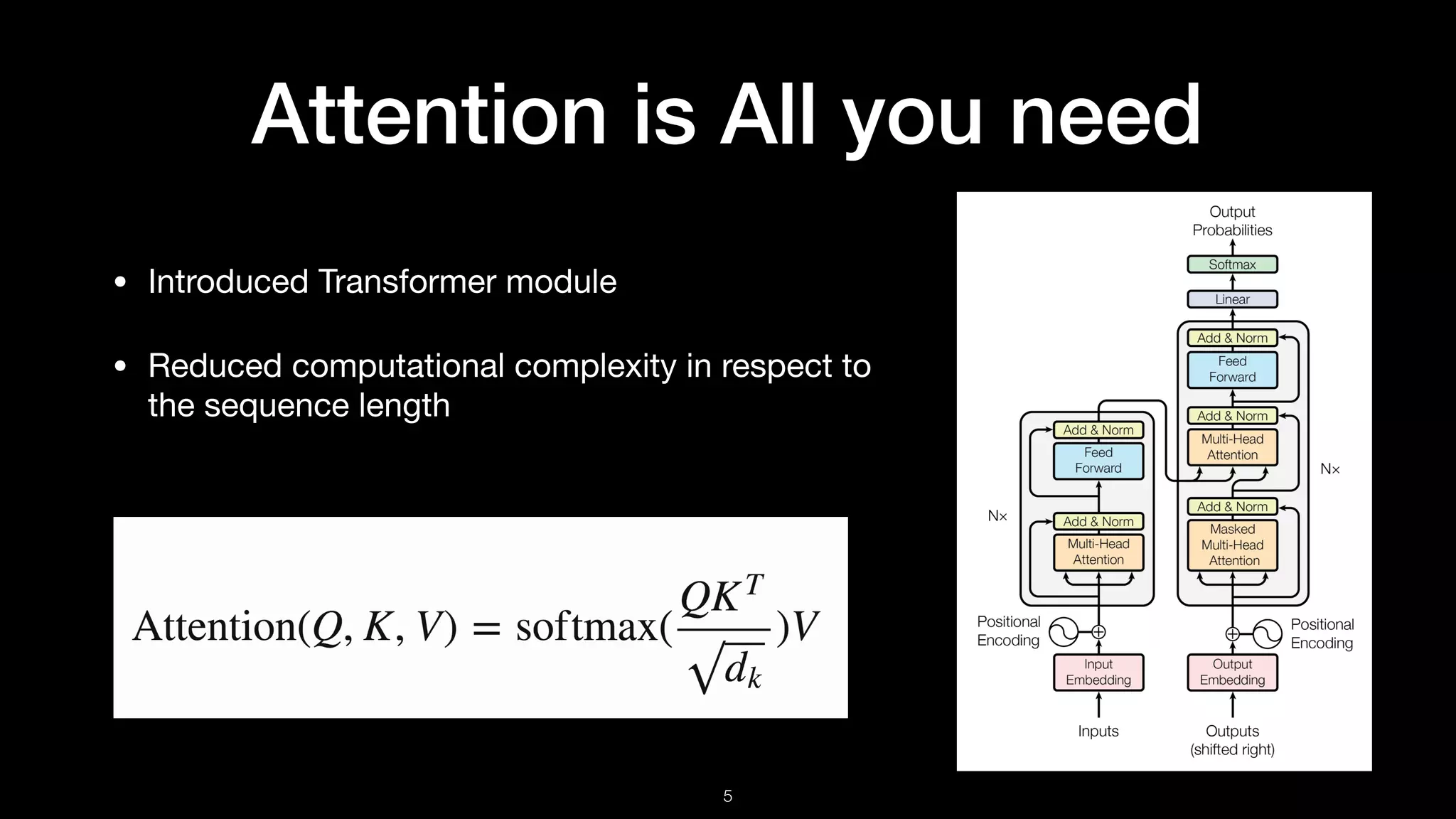
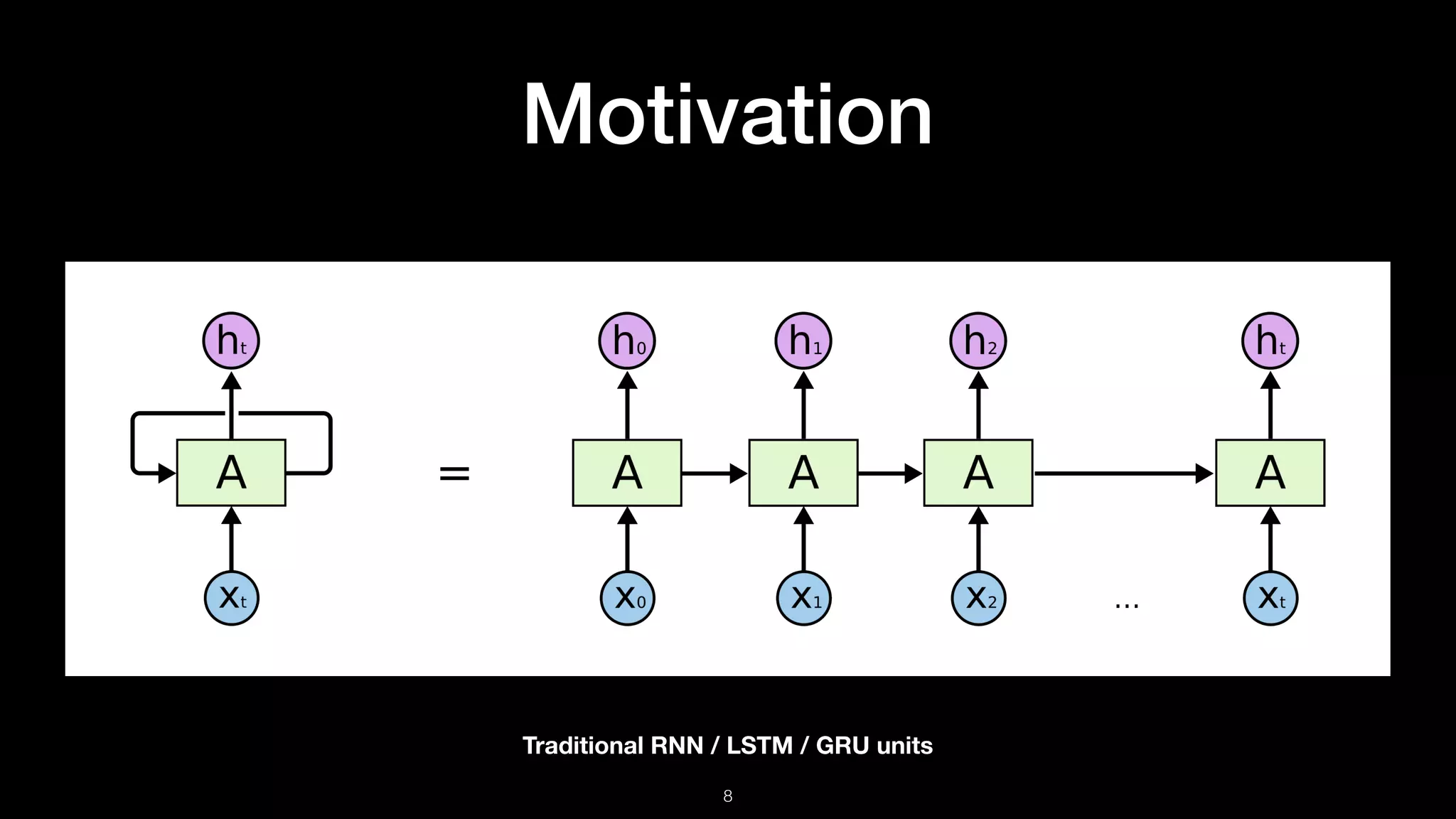
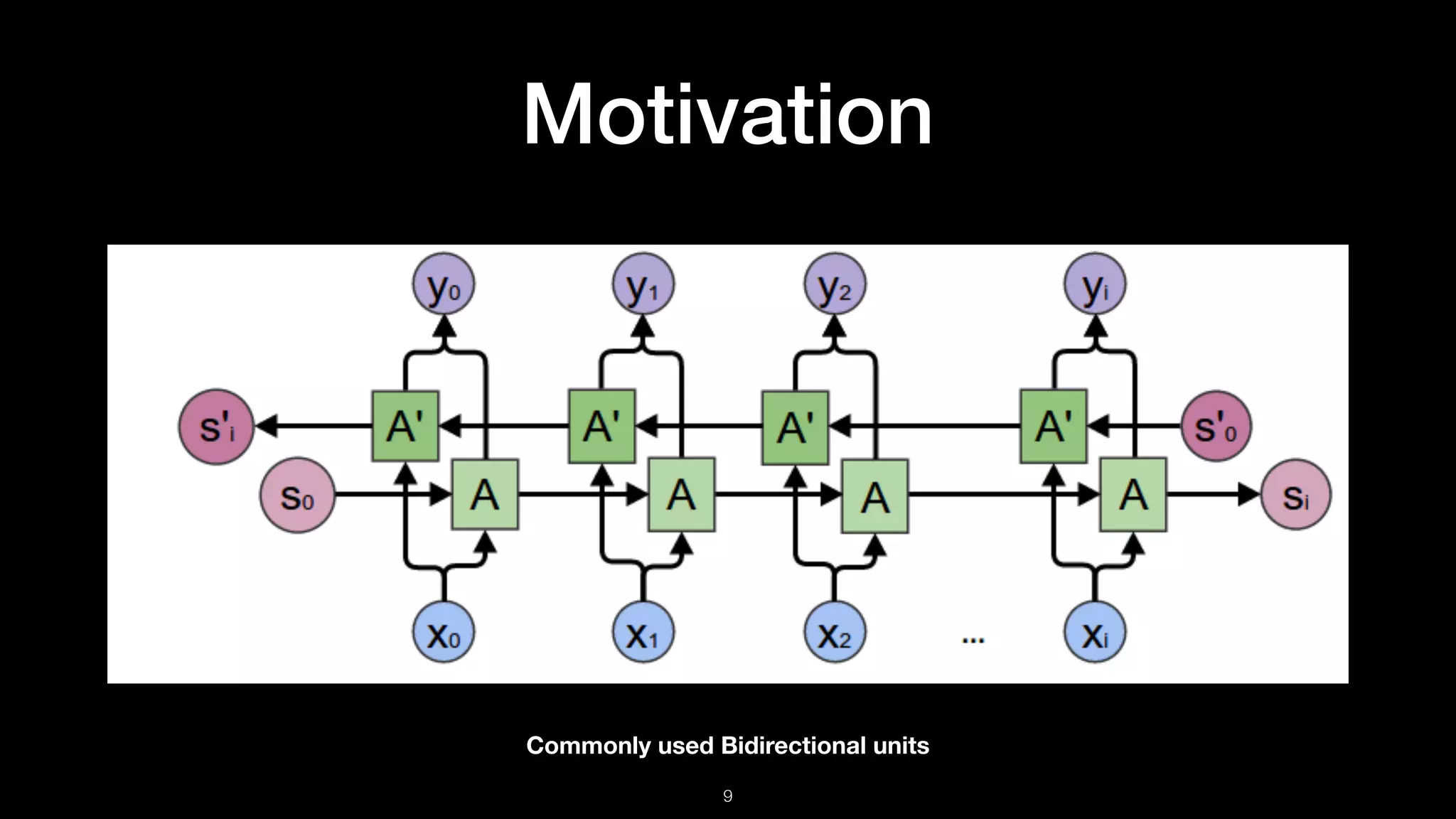
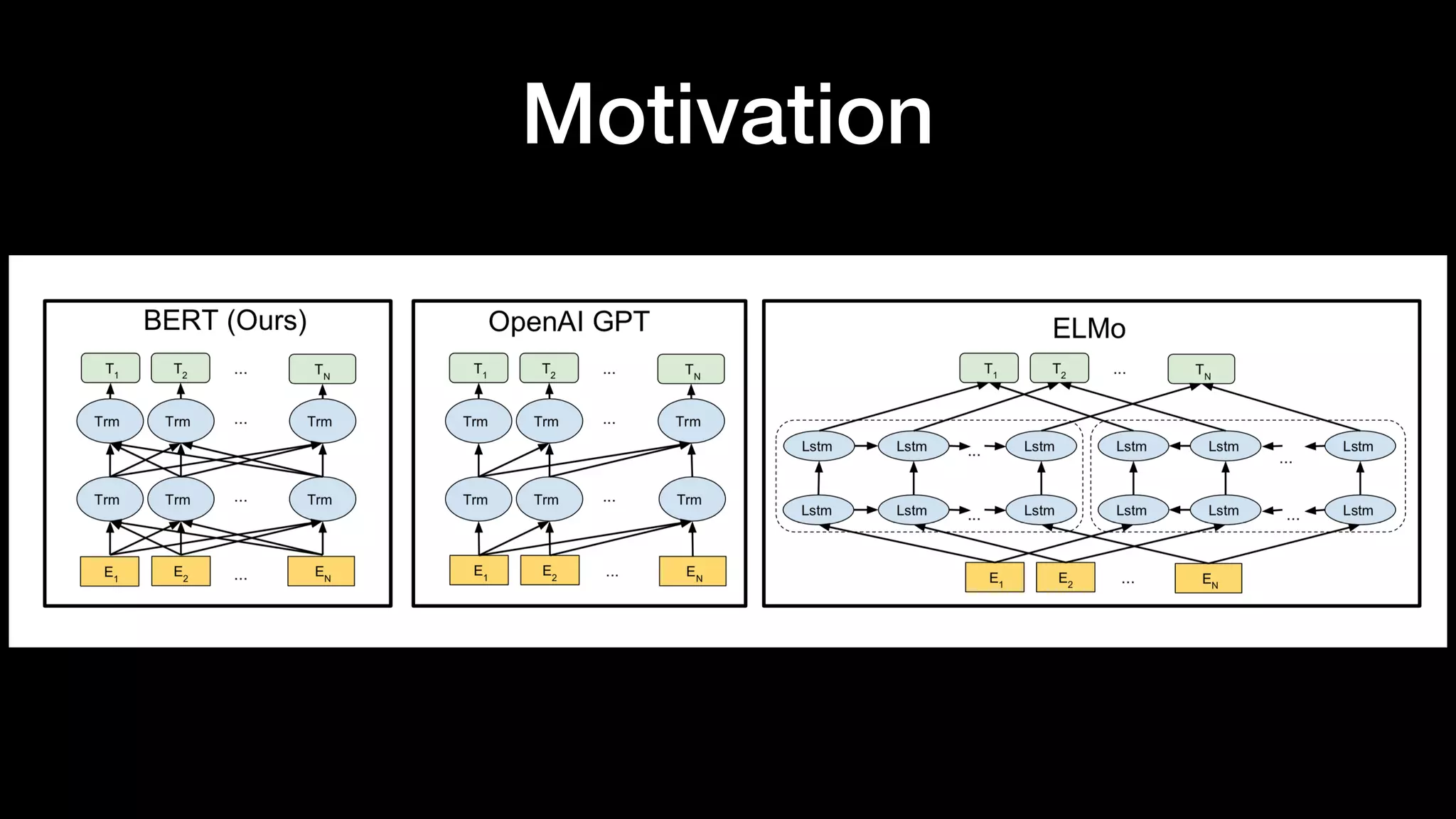
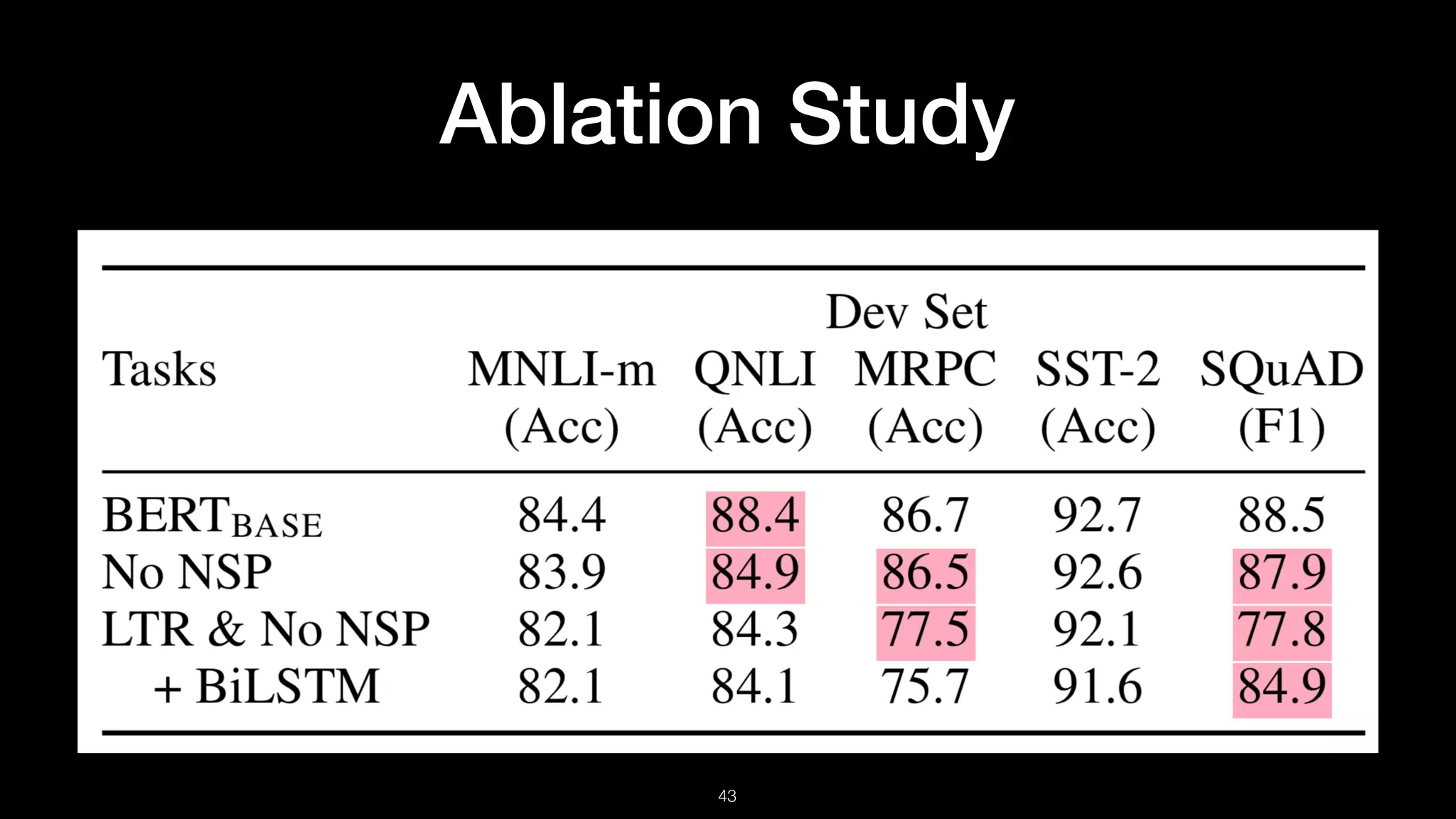
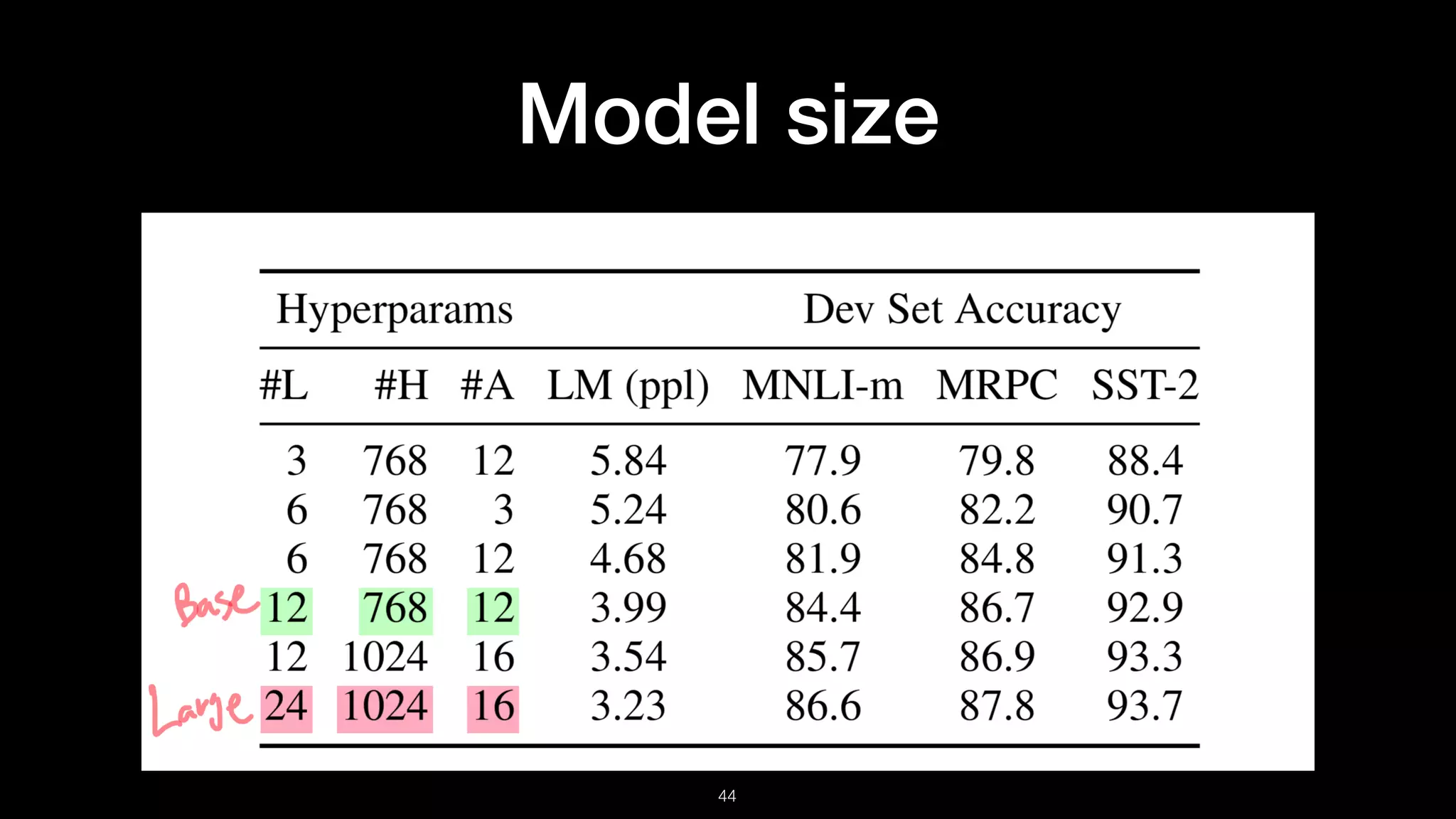
The document presents BERT (Bidirectional Encoder Representations from Transformers), which utilizes deep bidirectional transformers to improve language understanding through unsupervised pre-training. It details the training methodologies, including masked language modeling and next sentence prediction, while highlighting its state-of-the-art performance across various NLP tasks. BERT serves as a baseline for future research, demonstrating the effectiveness of deep bidirectional architectures in natural language processing.








![ViT (Vision Transformer) Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/vitreviewcdm-201012184226-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper Reading] Attention is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/reading20181228-190111054908-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper review] BERT](https://cdn.slidesharecdn.com/ss_thumbnails/paperreviewbert-190507052754-thumbnail.jpg?width=640&height=640&fit=bounds)






















































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)

