Download as PDF, PPTX

























































This document summarizes a technical paper about GPT-2, an unsupervised language model created by OpenAI. GPT-2 is a transformer-based model trained on a large corpus of internet text using byte-pair encoding. The paper describes experiments showing GPT-2 can perform various NLP tasks like summarization, translation, and question answering with limited or no supervision, though performance is still below supervised models. It concludes that unsupervised task learning is a promising area for further research.
Overview of GPT-2 language model, its researchers, and links to technical resources and related papers.
Description of datasets used, including BookCorpus, Wikipedia, Common Crawl, and WebText with details on size and selection.
Explanation of input representation methods, specifically Byte Pair Encoding (BPE), enhancing language modeling capabilities.
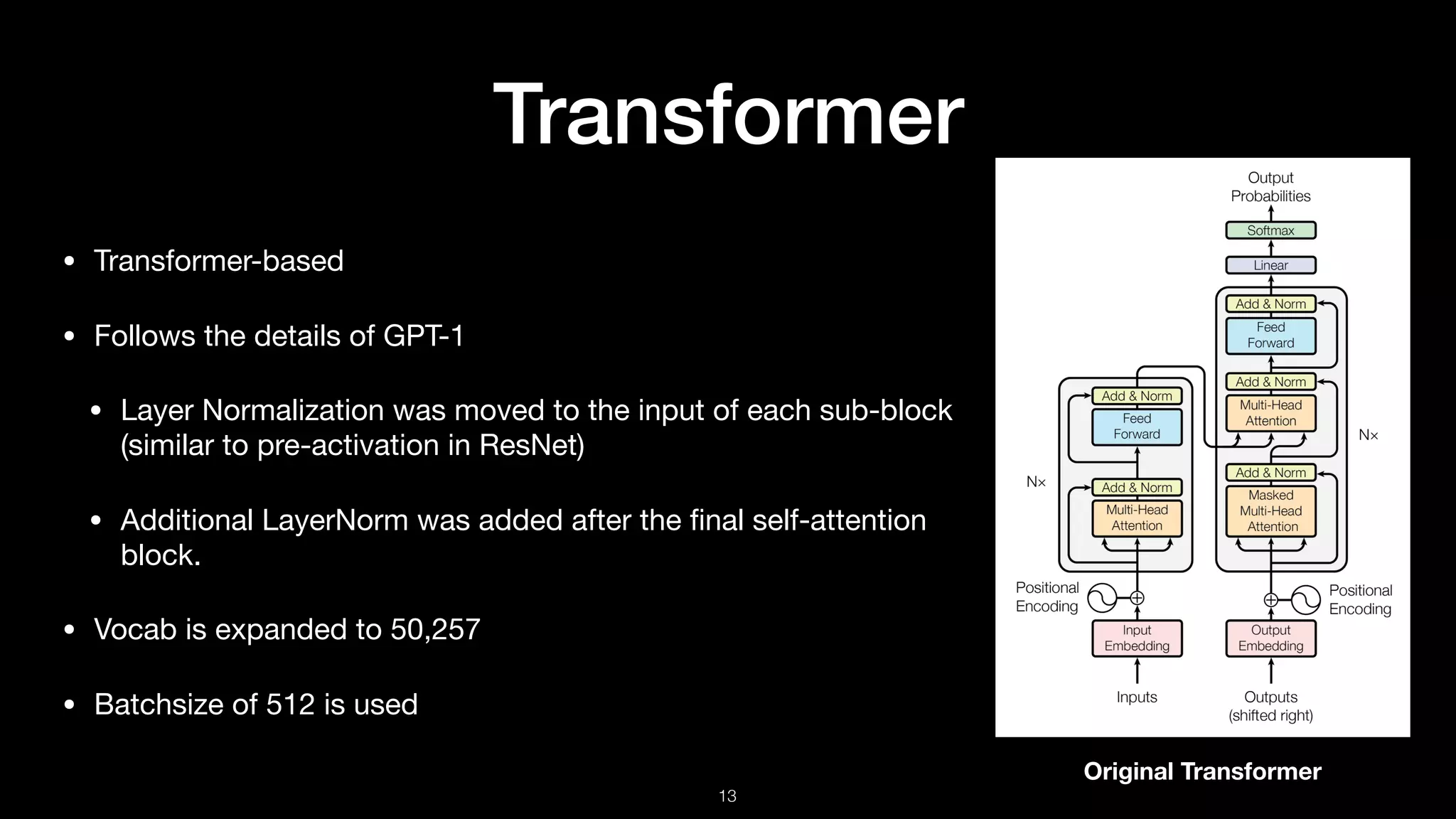
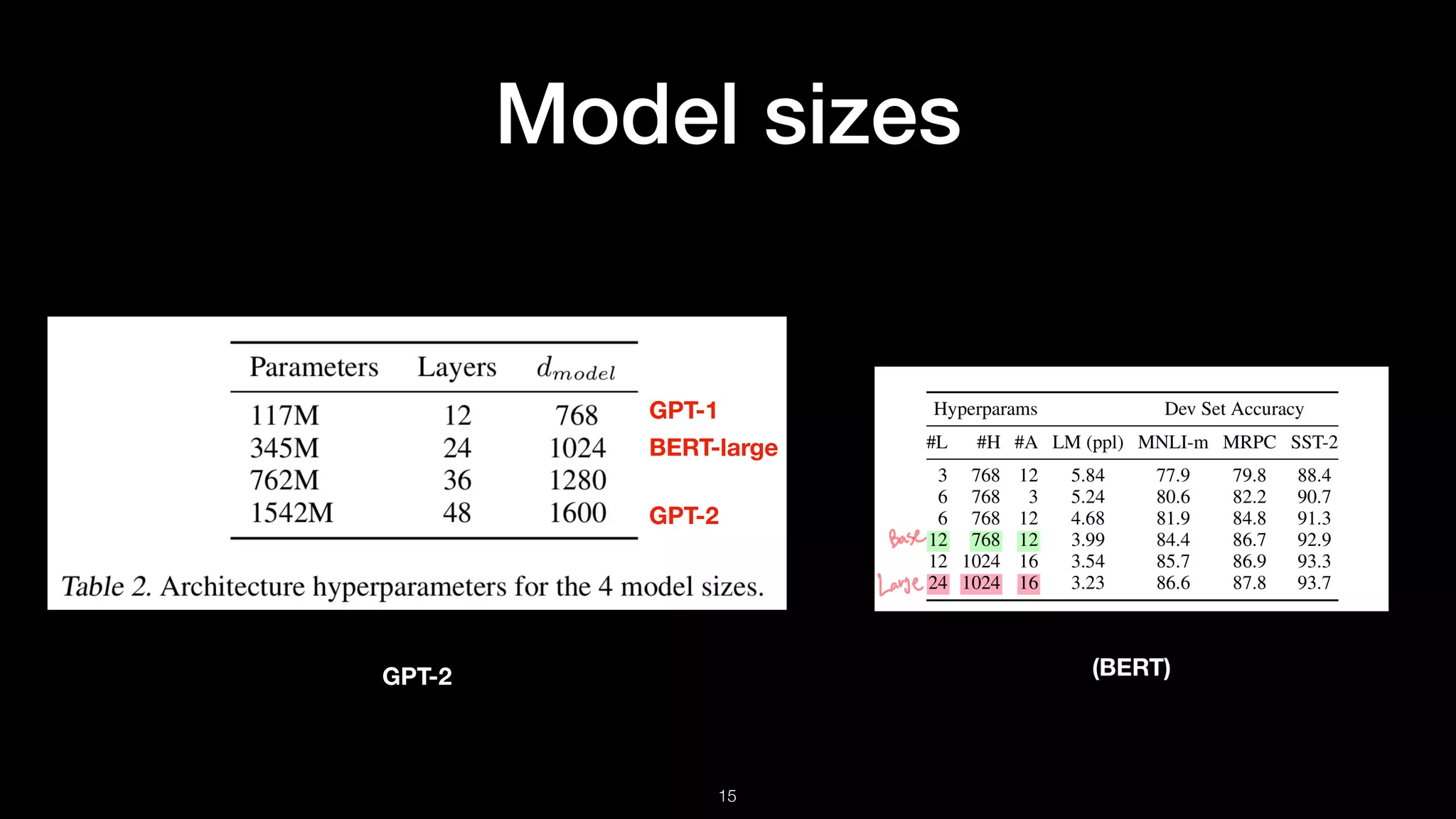
Details on the transformer architecture used in GPT-2, including layer normalization and vocabulary expansion.
Introduction to the experiments conducted to evaluate model sizes and test performance across various NLP tasks.
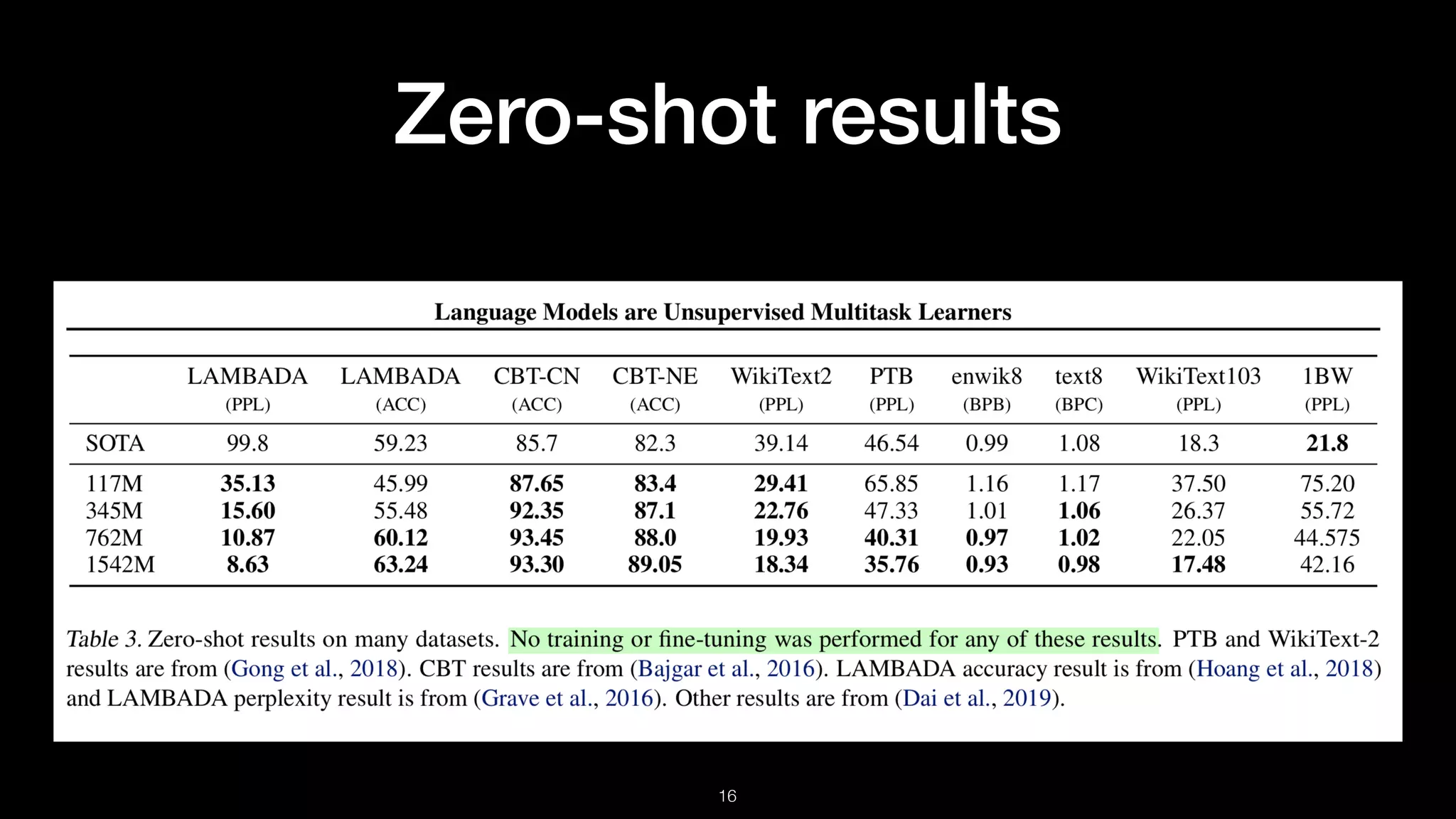
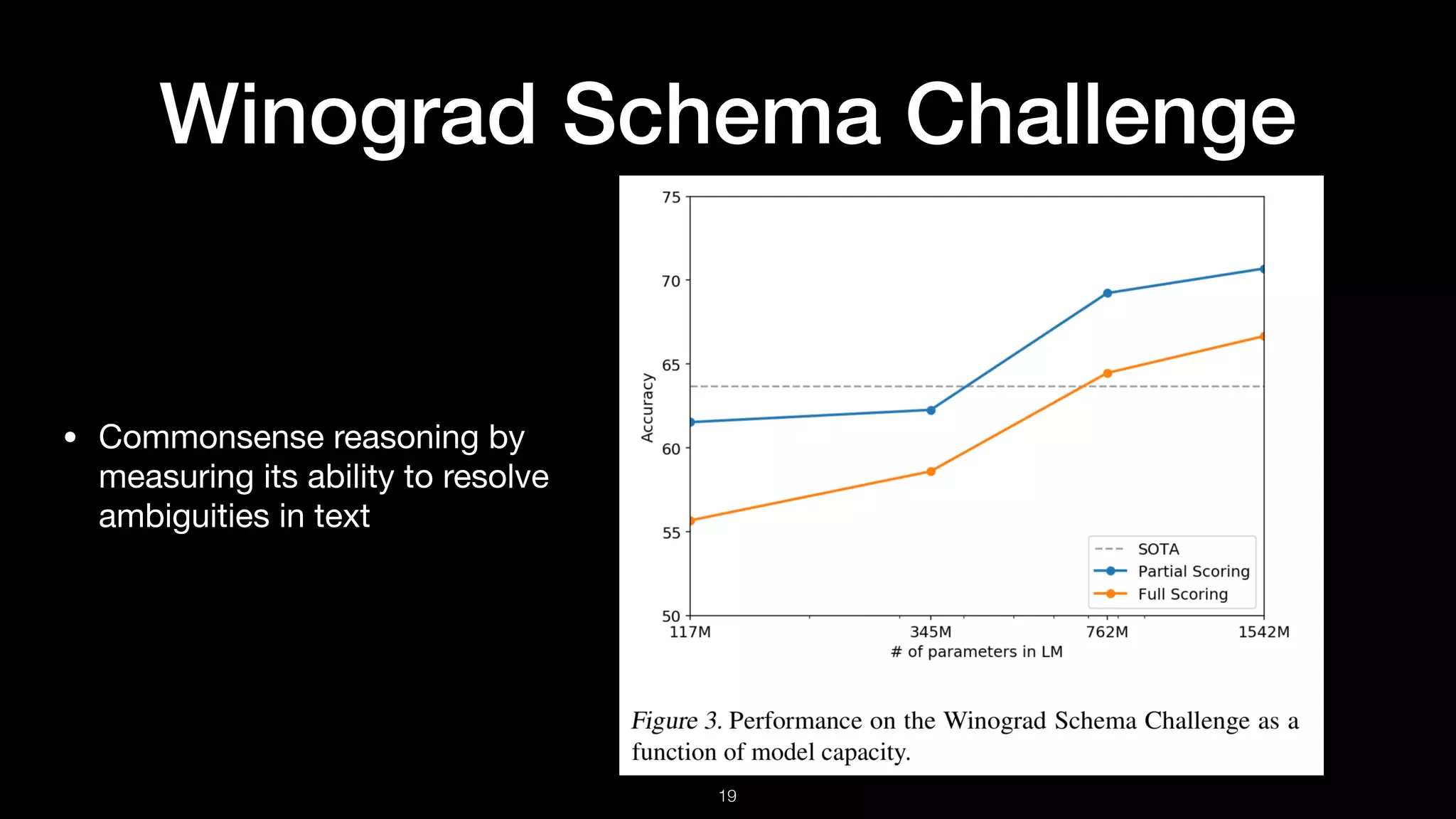
Summary of evaluations including children’s book test, LAMBADA dataset, Winograd Schema Challenge, summarization, translation, and question answering.
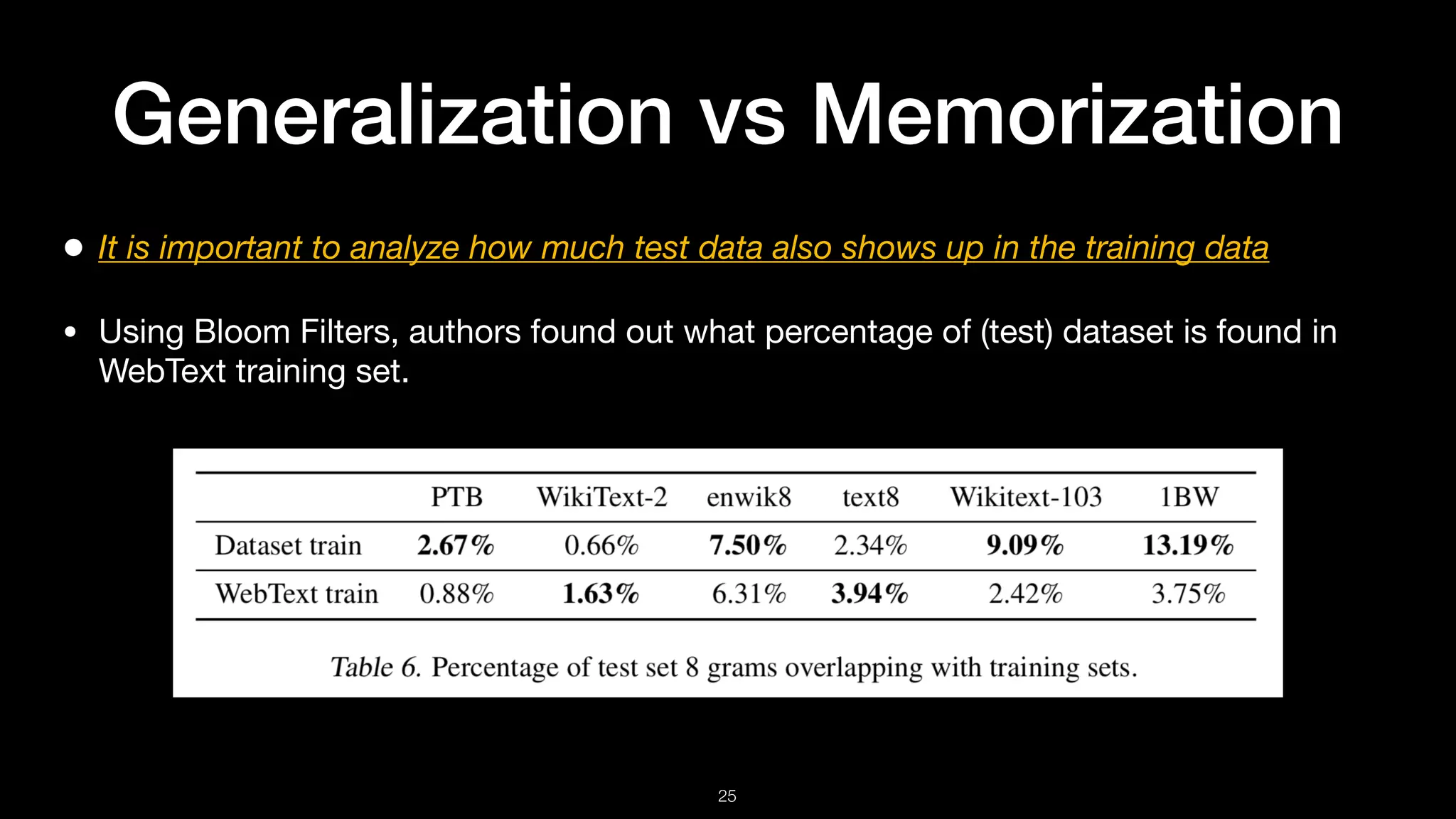
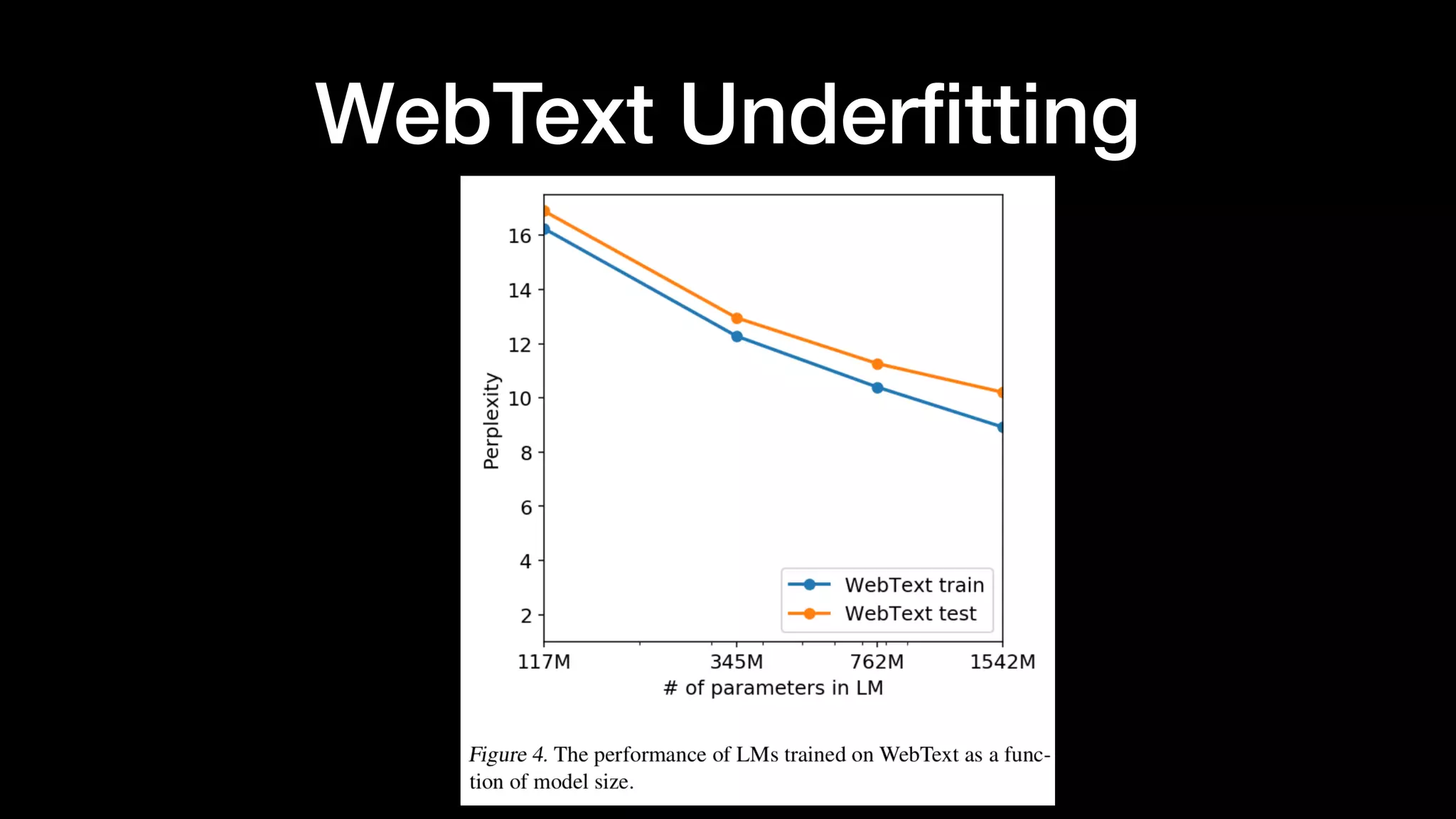
Discussion on generalization versus memorization, performance in zero-shot settings, and limitations in some tasks.
Personal thoughts on model scaling, the importance of unsupervised learning, and ethical considerations regarding OpenAI's model release.
Conclusion and thanks for attention.
![[Paper review] BERT](https://cdn.slidesharecdn.com/ss_thumbnails/paperreviewbert-190507052754-thumbnail.jpg?width=640&height=640&fit=bounds)


































































