Download to read offline

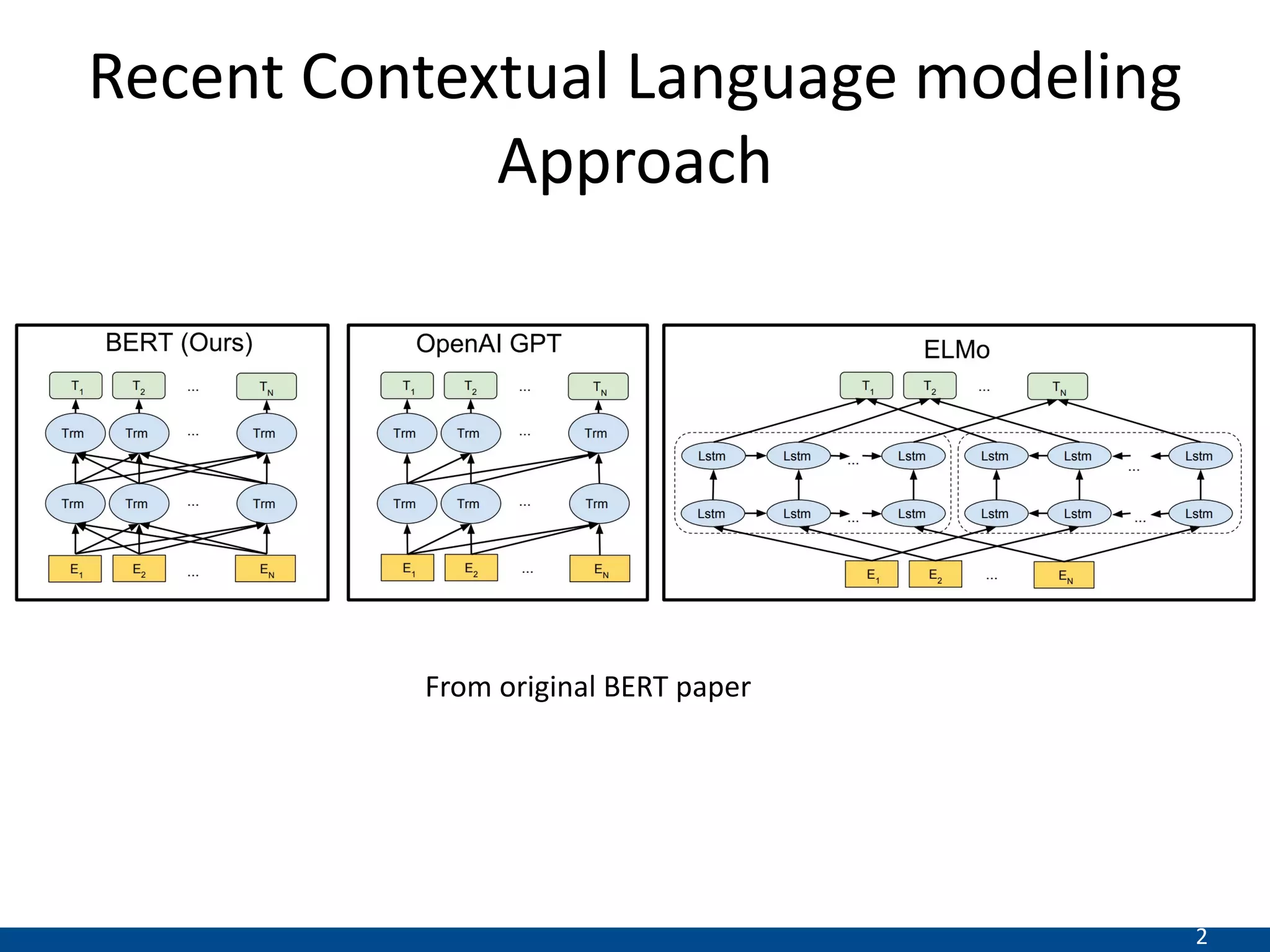






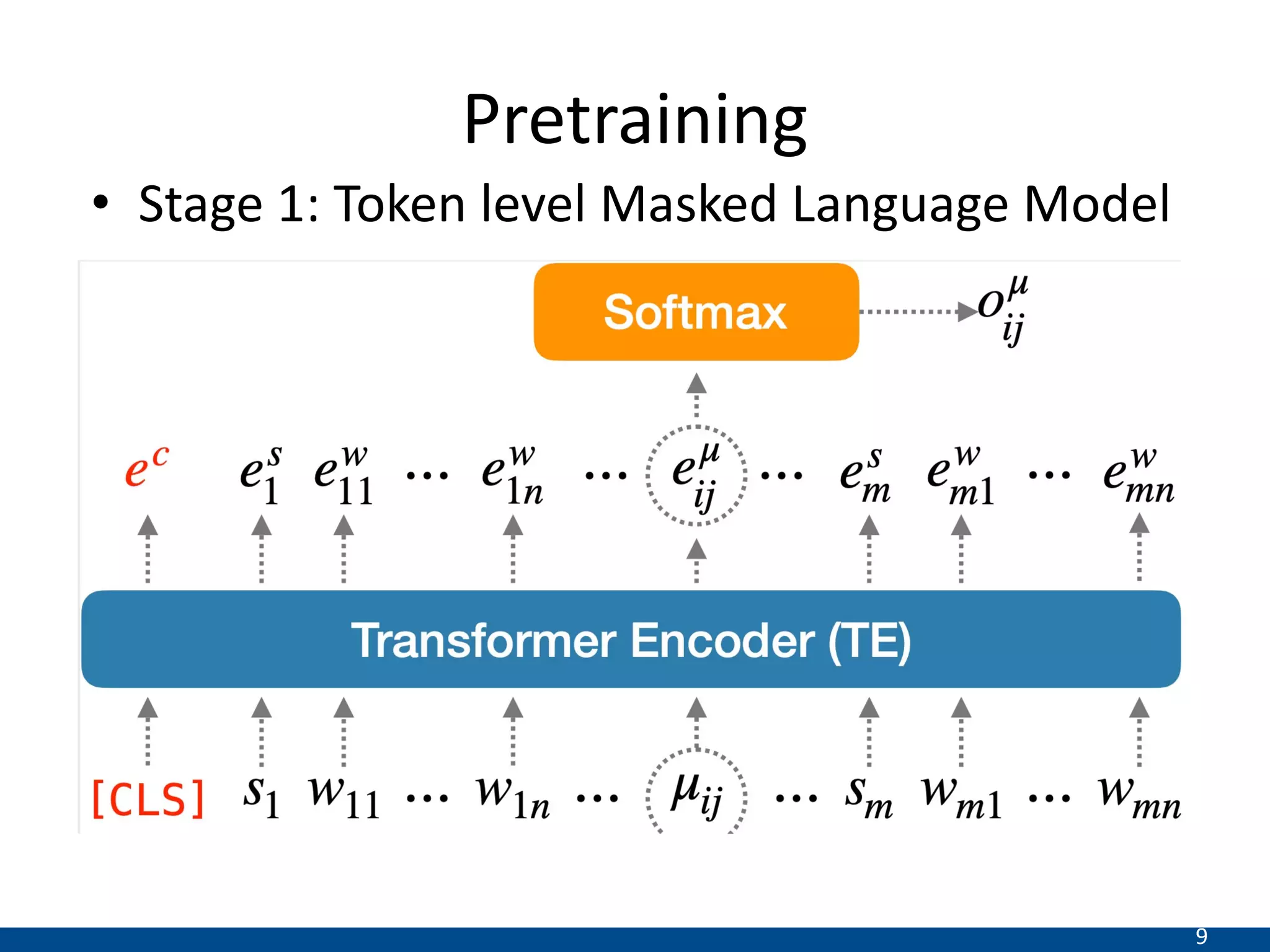
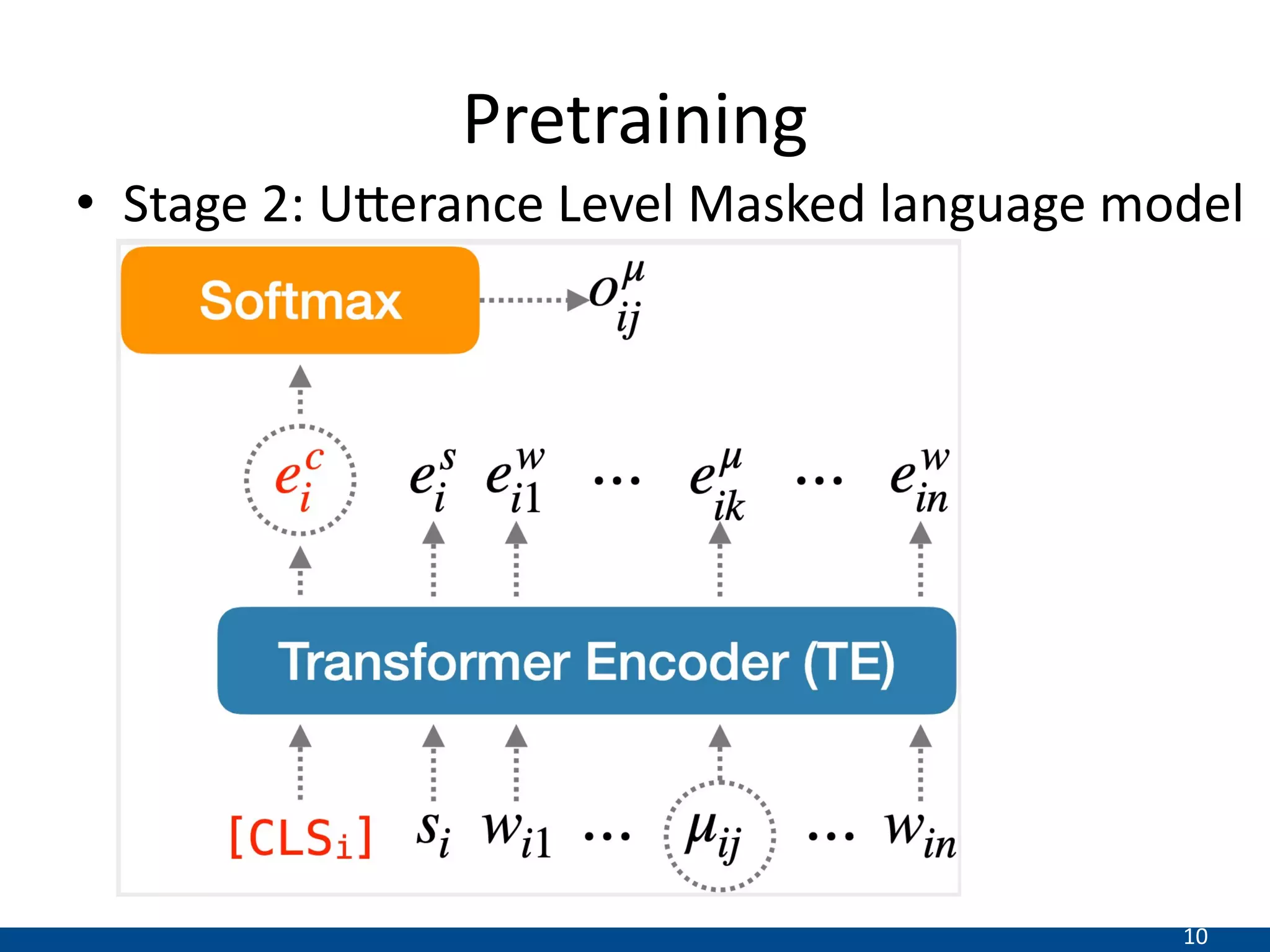
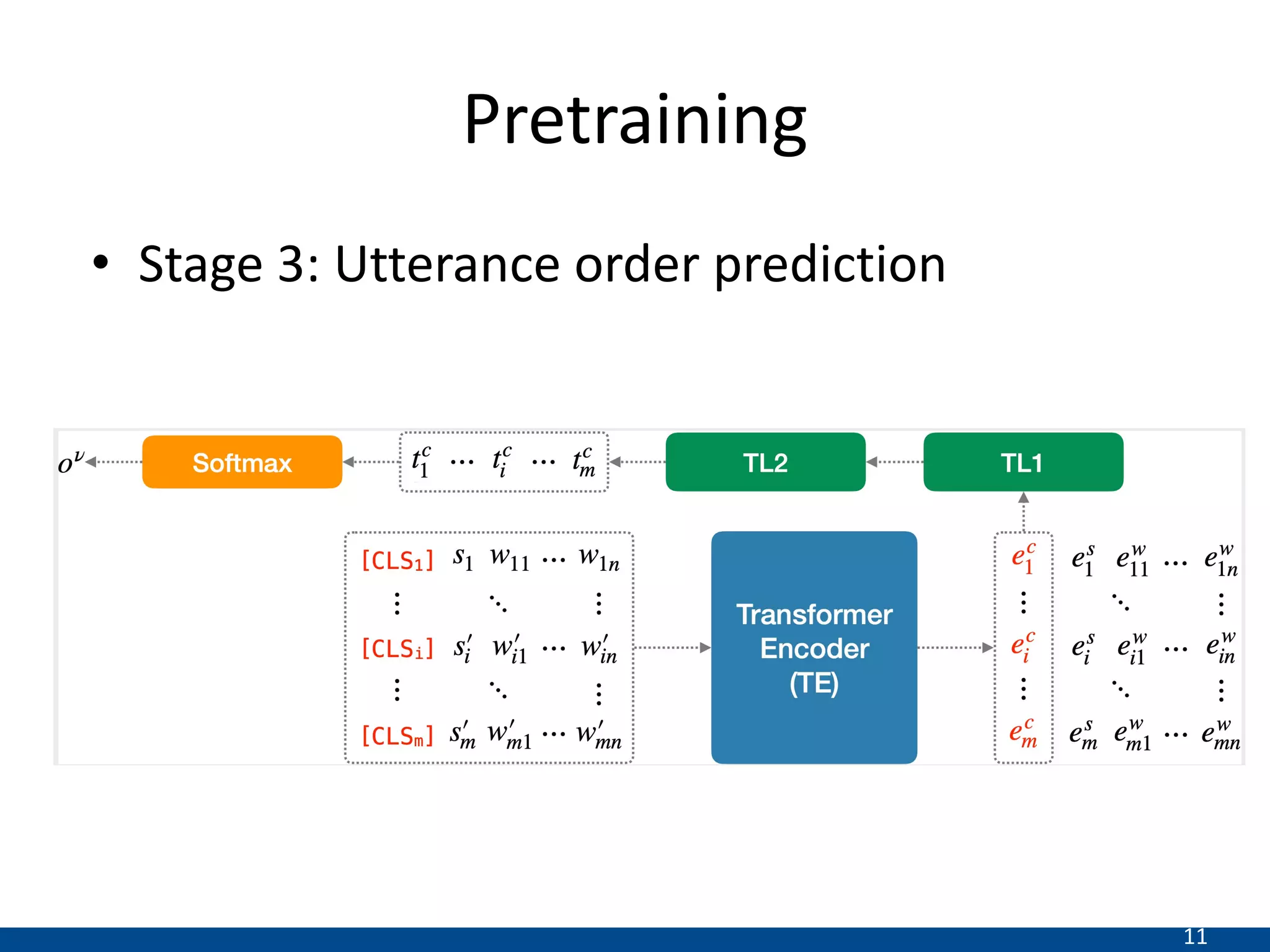
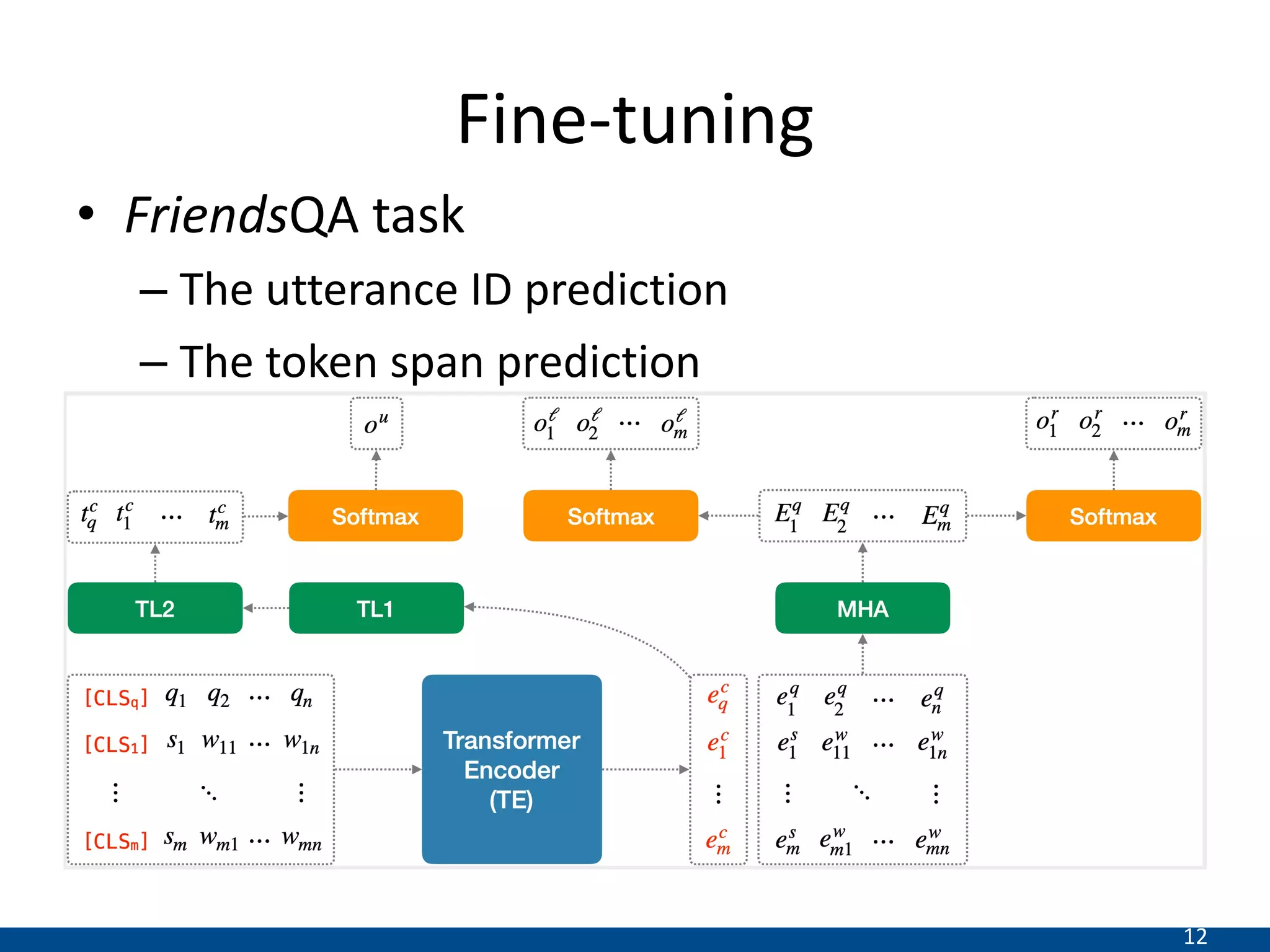




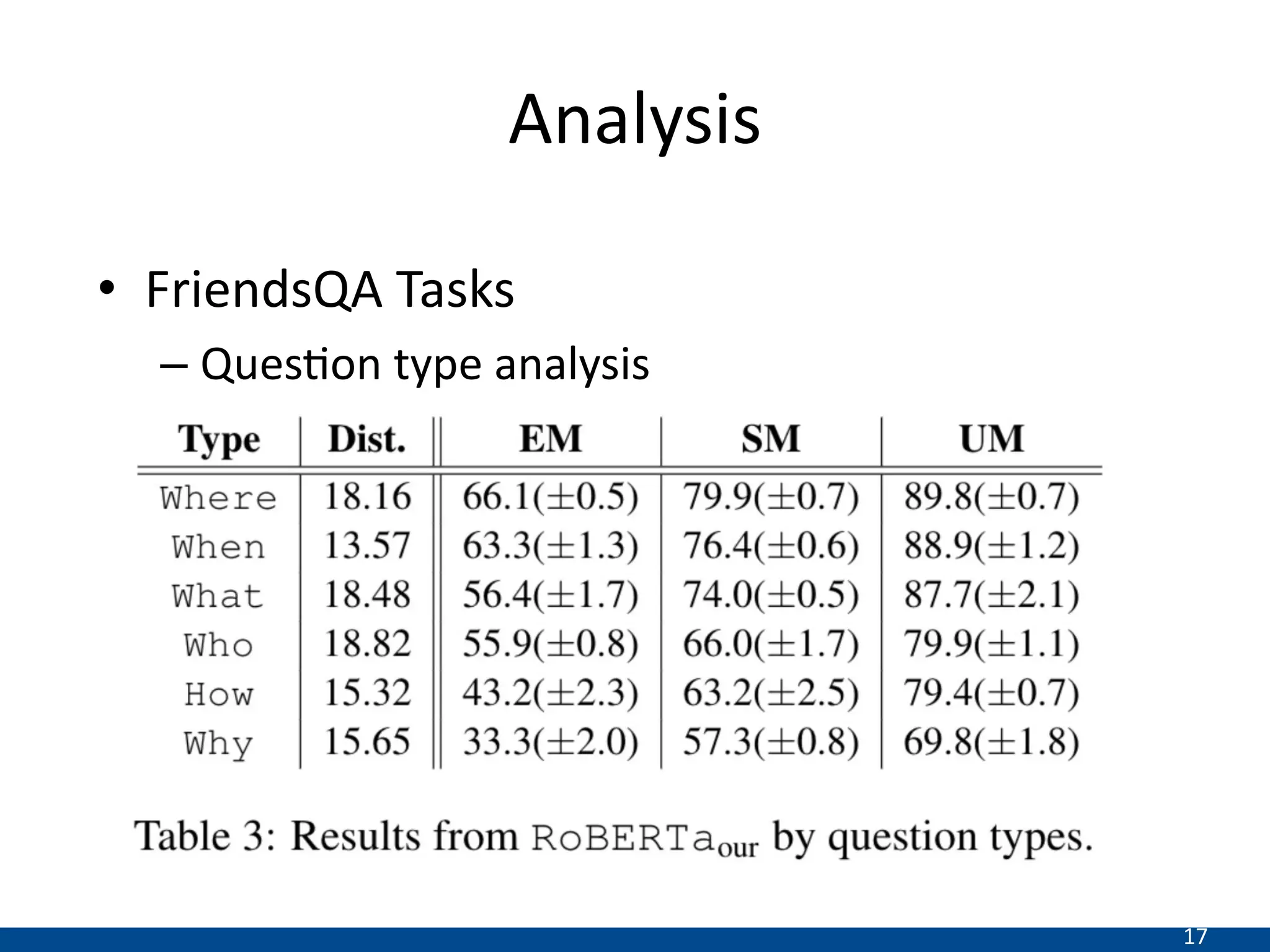
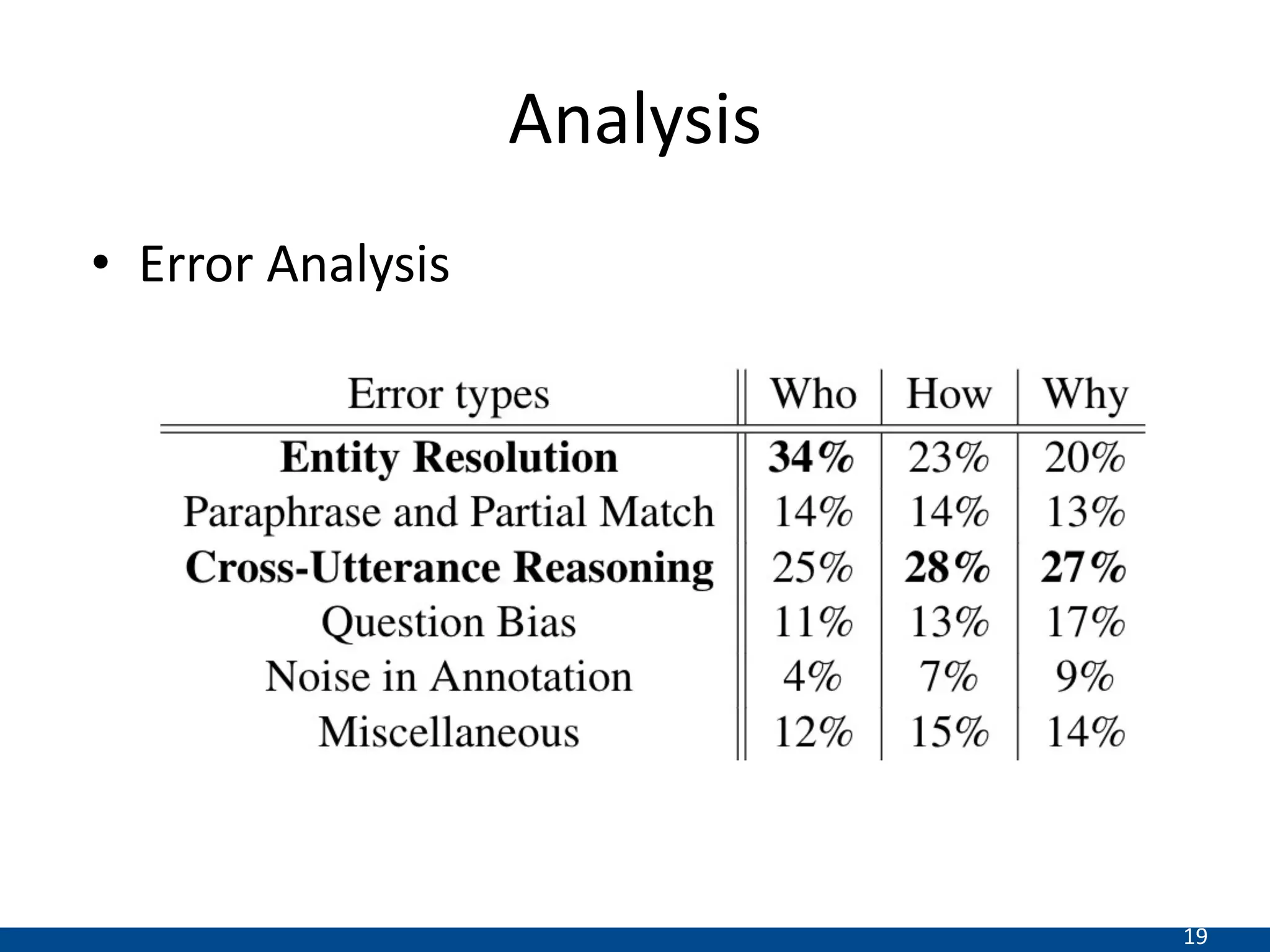





































This document summarizes a research paper that proposes a new transformer model for span-based question answering on dialogue transcripts. The model is pretrained on tasks like masked language modeling at the token and utterance level, as well as utterance order prediction, using the Friends TV show transcript corpus. It is then fine-tuned jointly on two tasks: utterance ID prediction and token span prediction. Evaluation on the FriendsQA dataset shows the proposed model outperforms BERT and RoBERTa baselines. However, analysis finds the model still struggles with inference in dialogues and representing speakers.





















































































