Download as PDF, PPTX




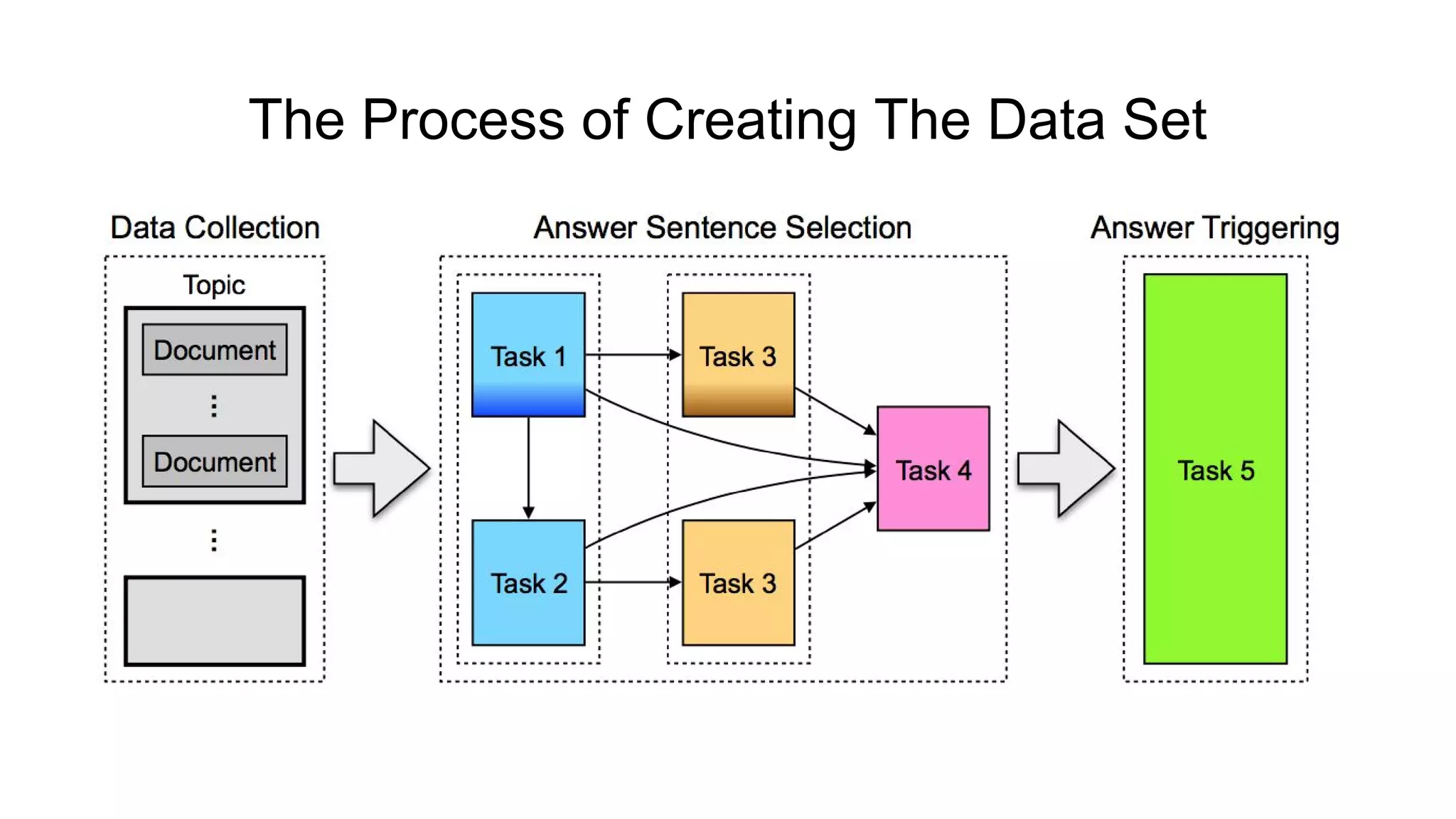



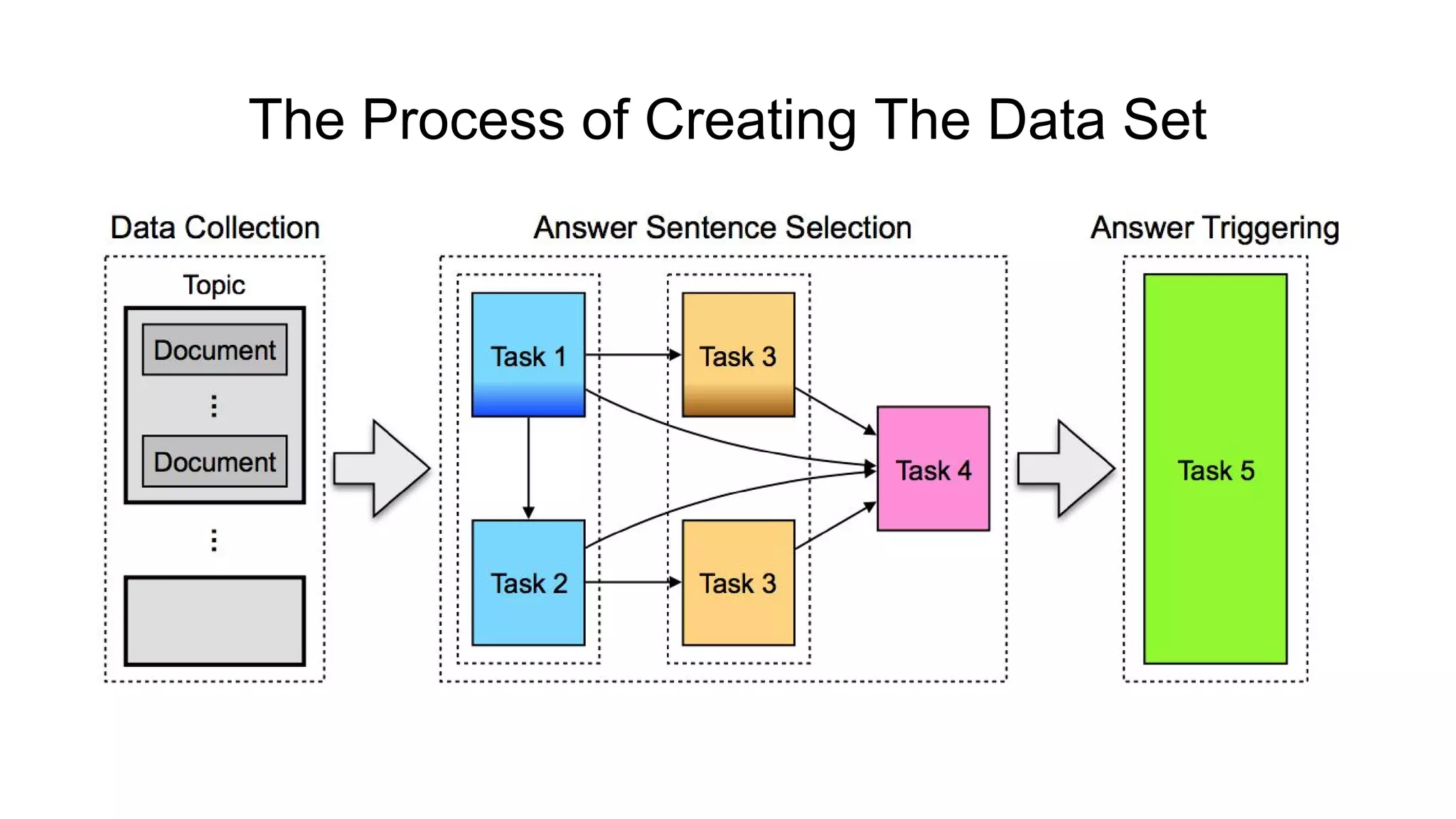

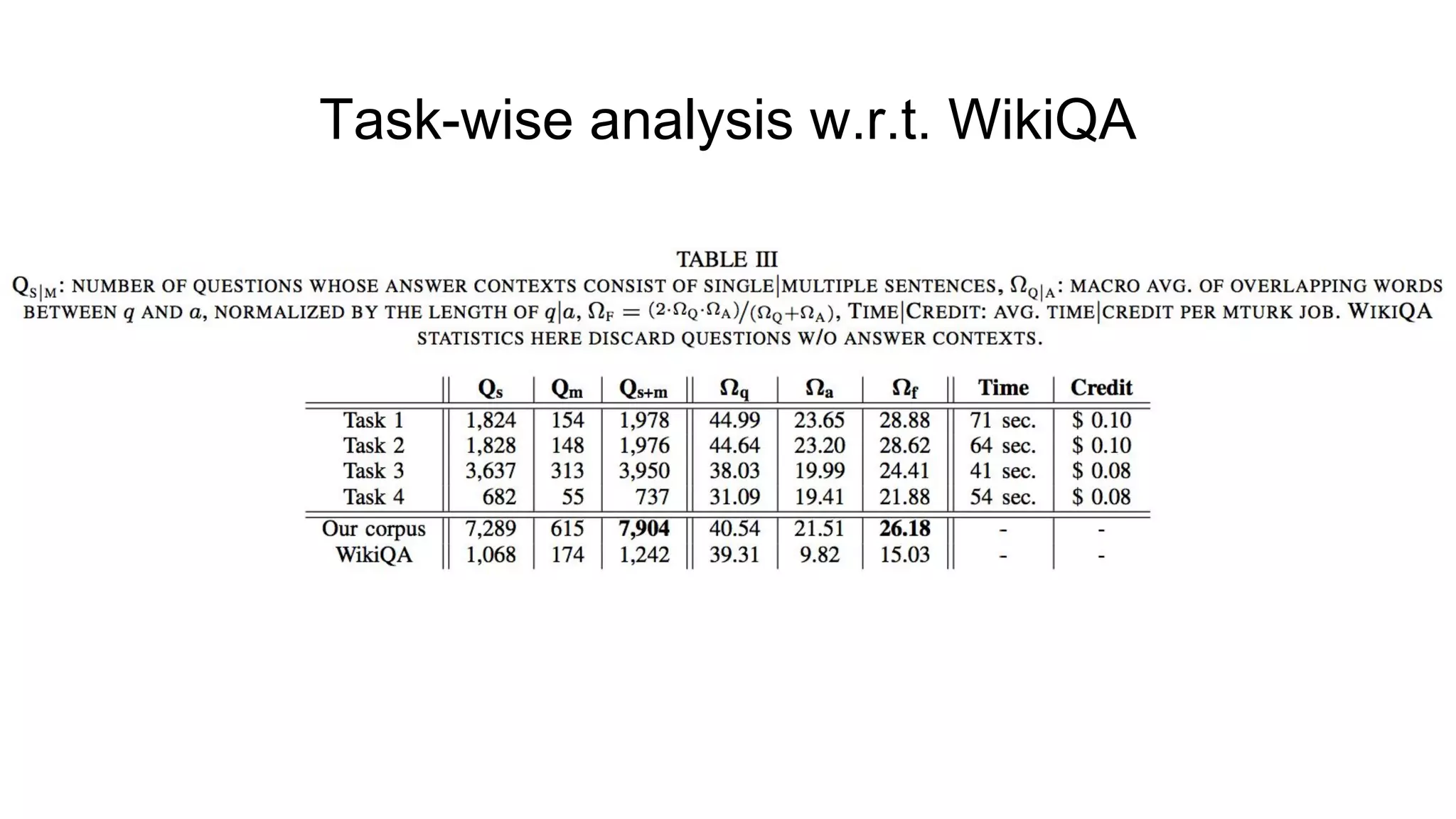
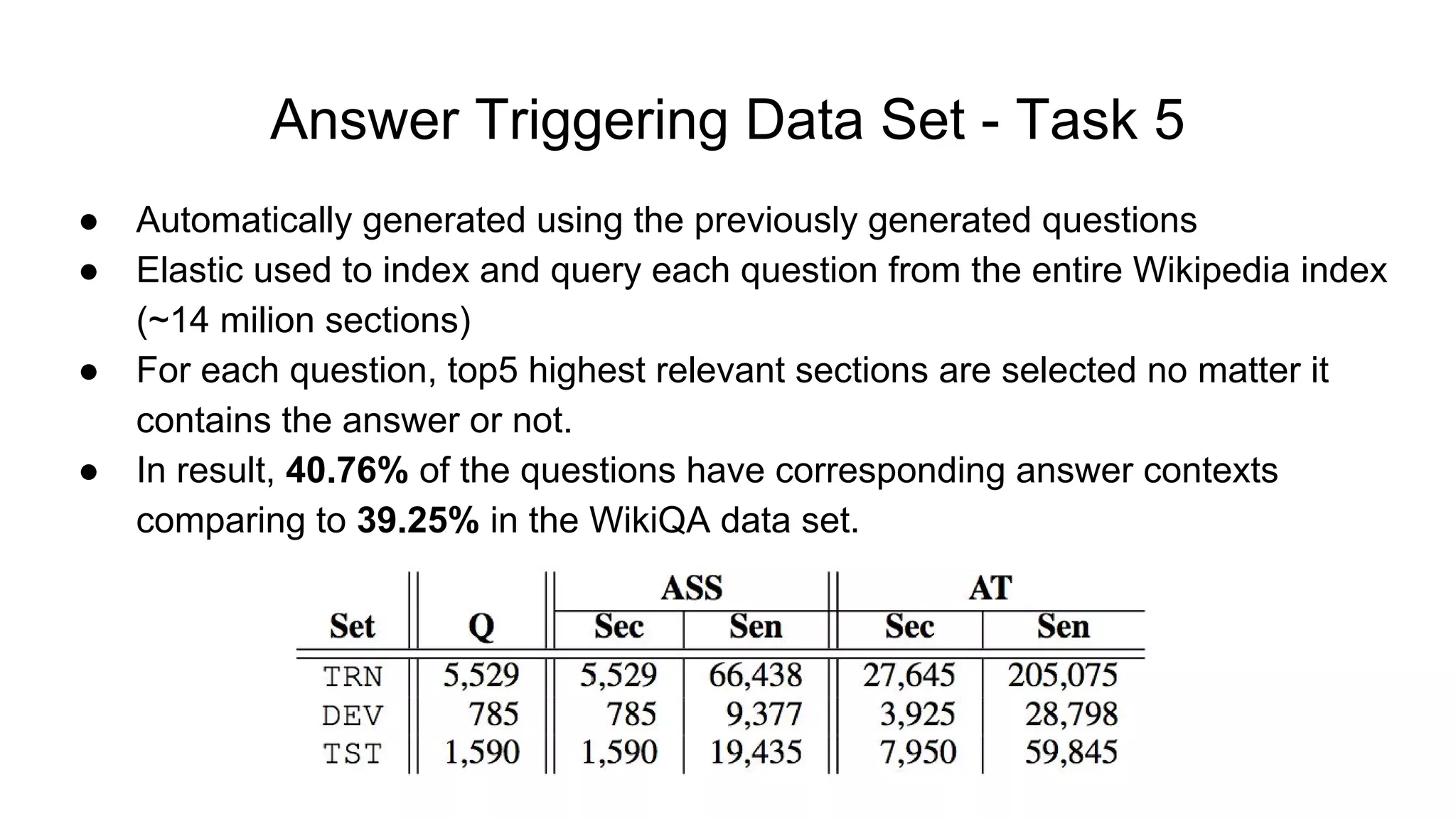

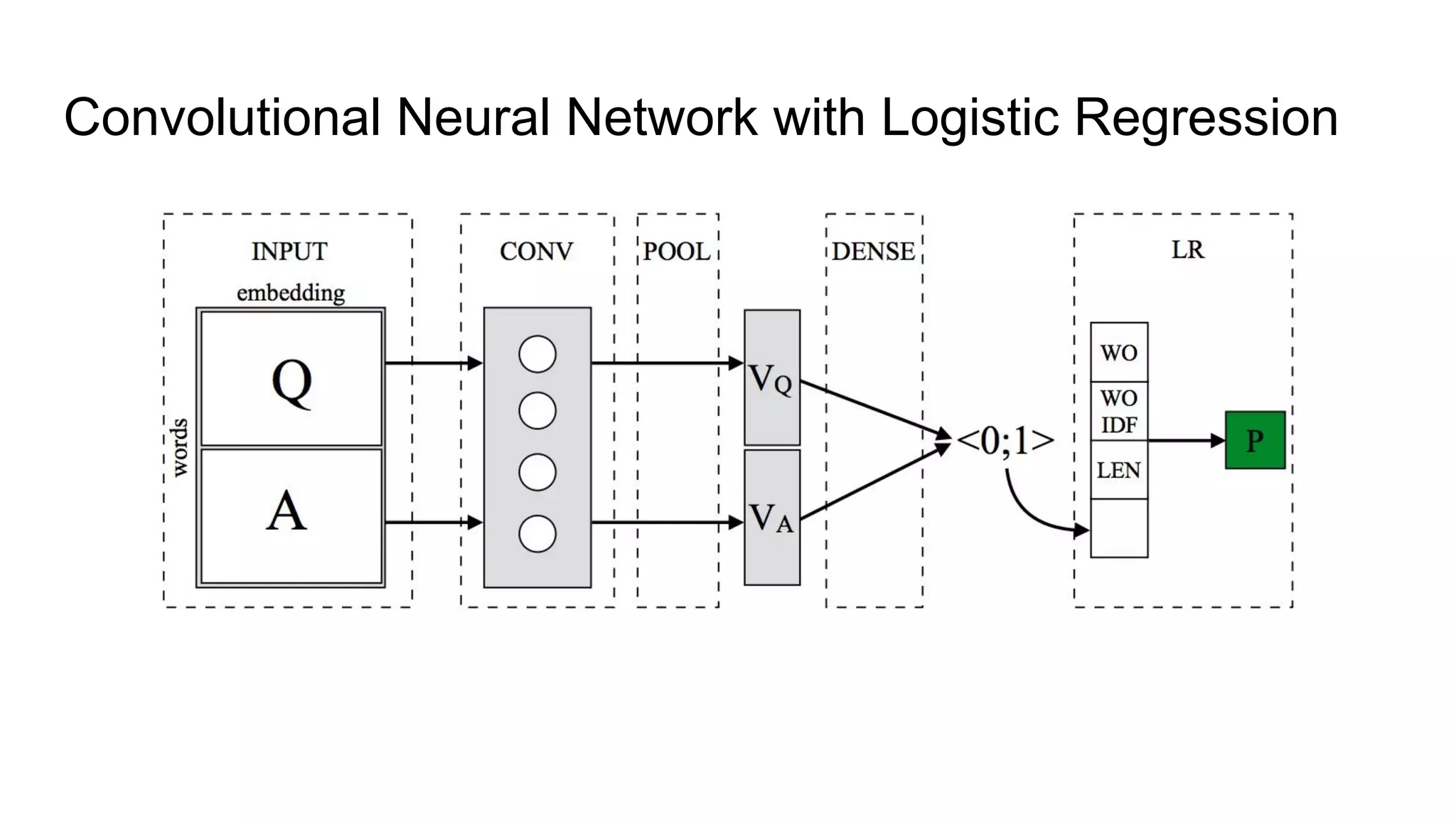
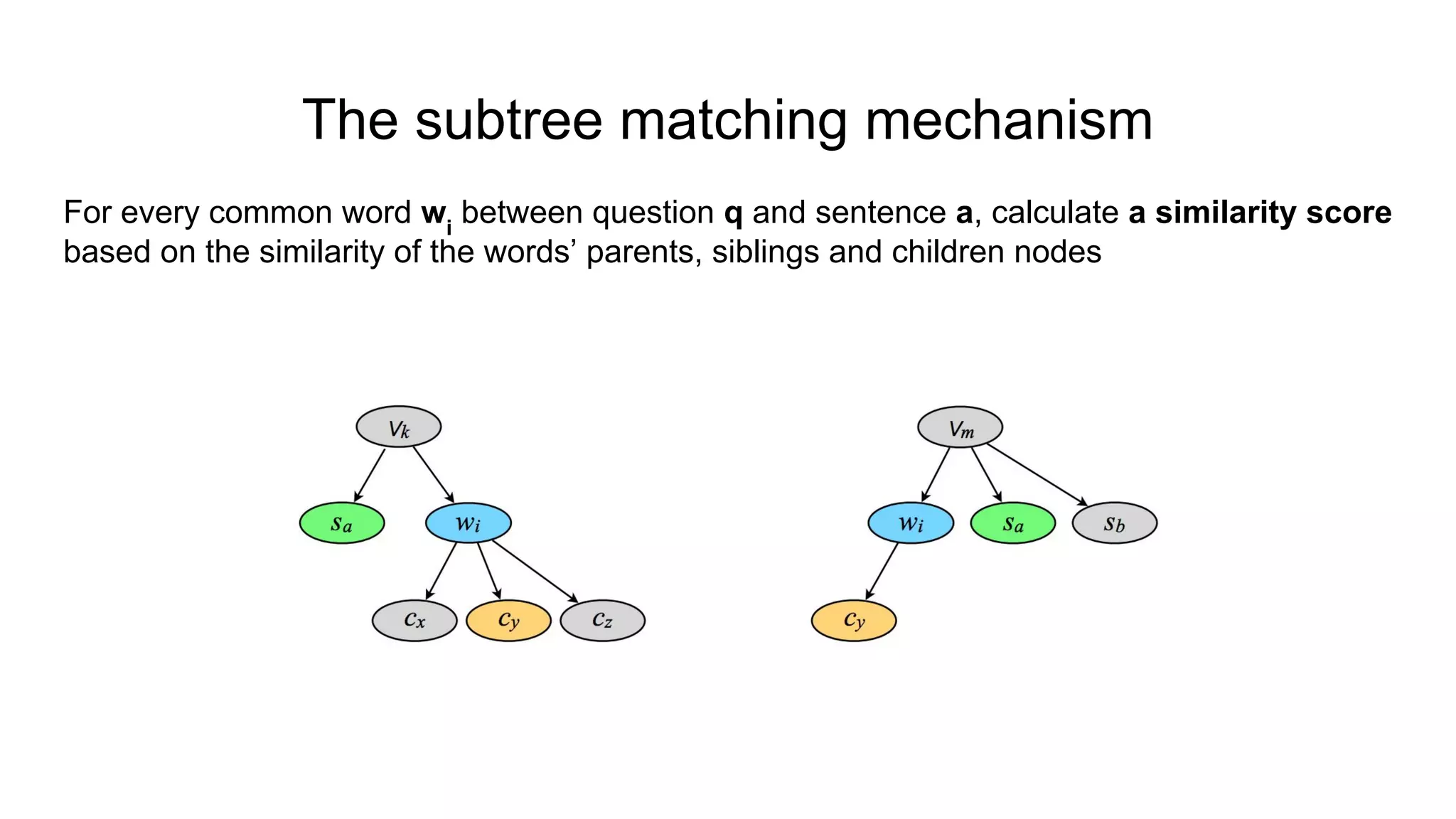
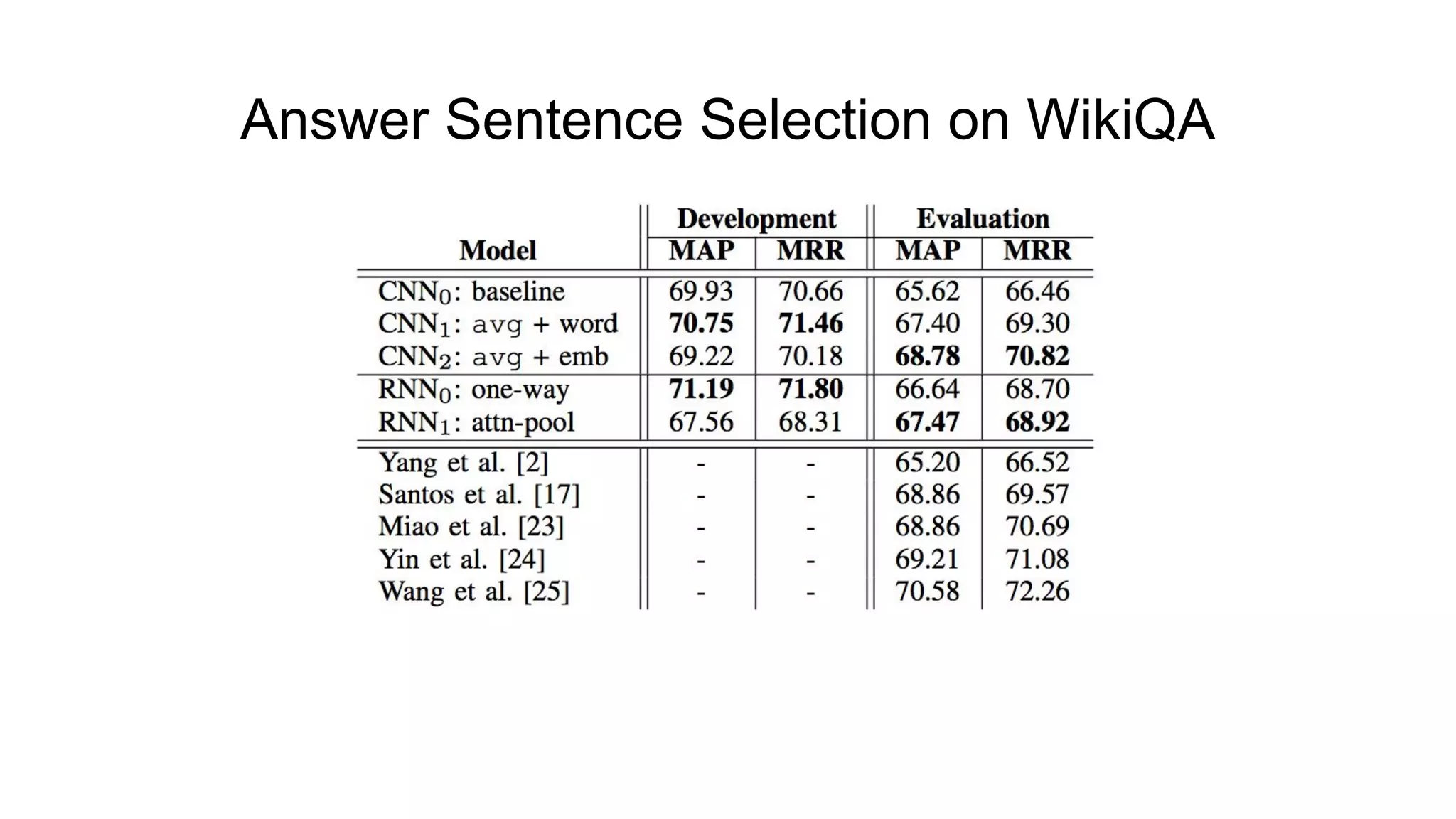
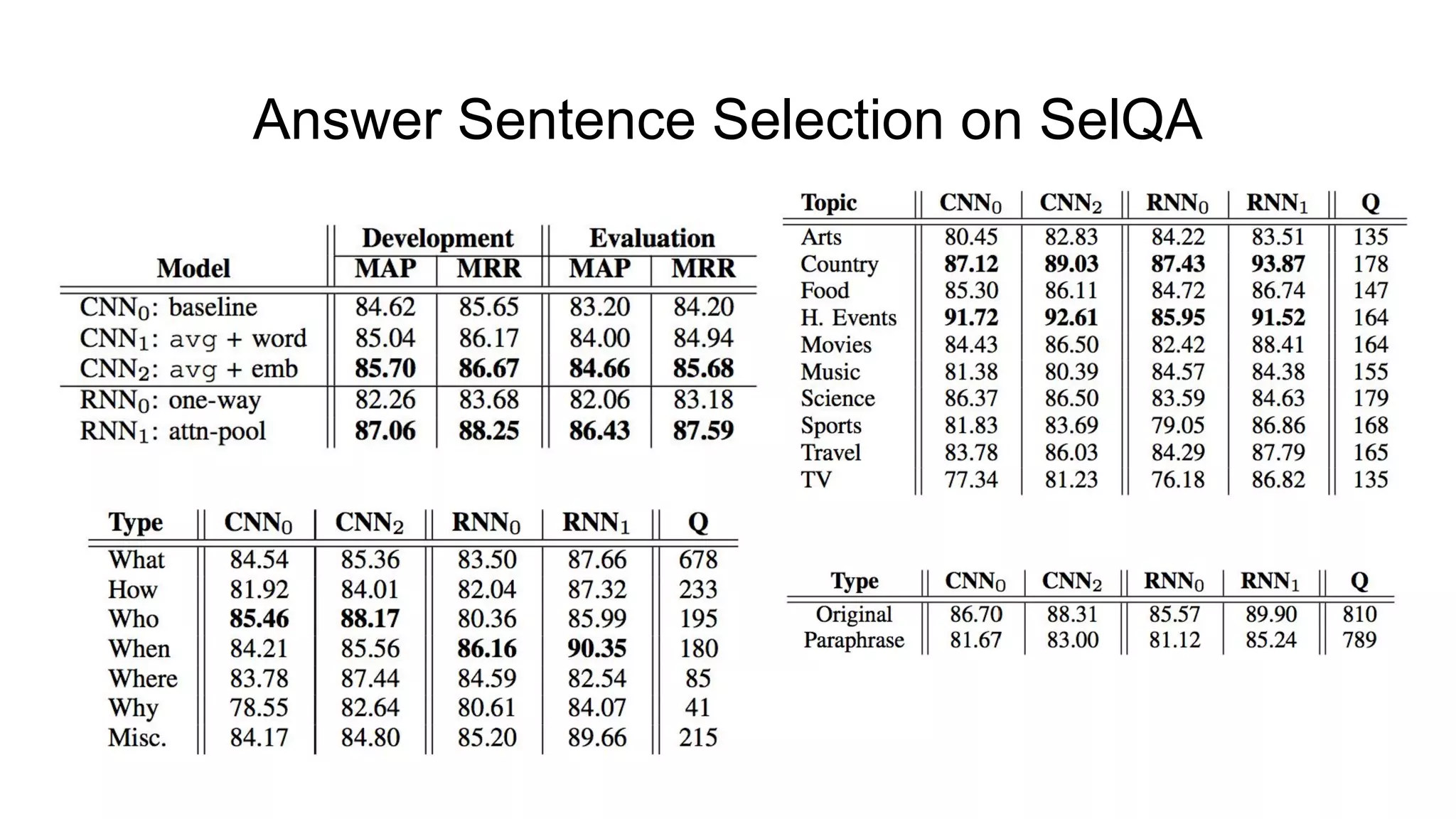
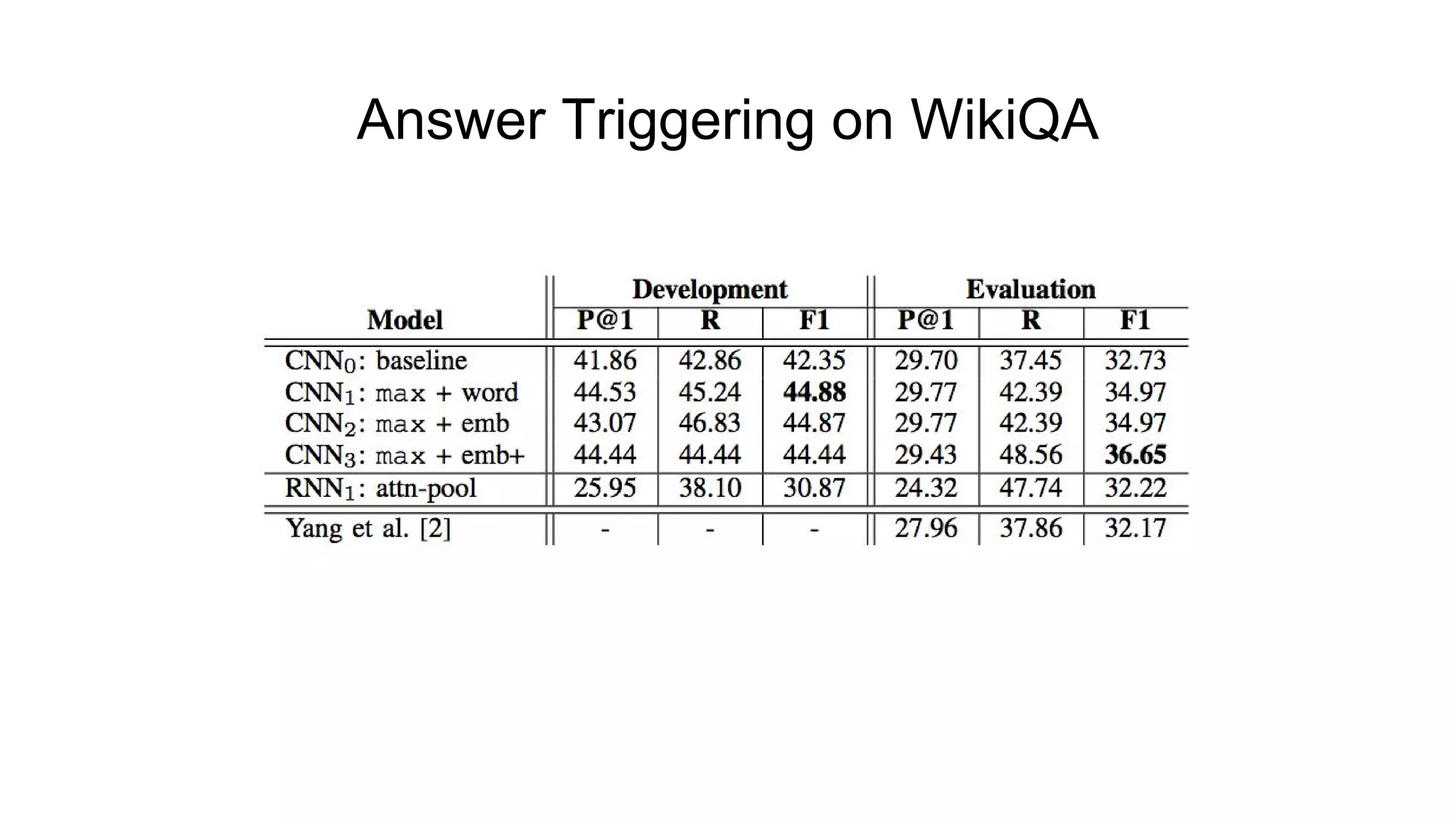
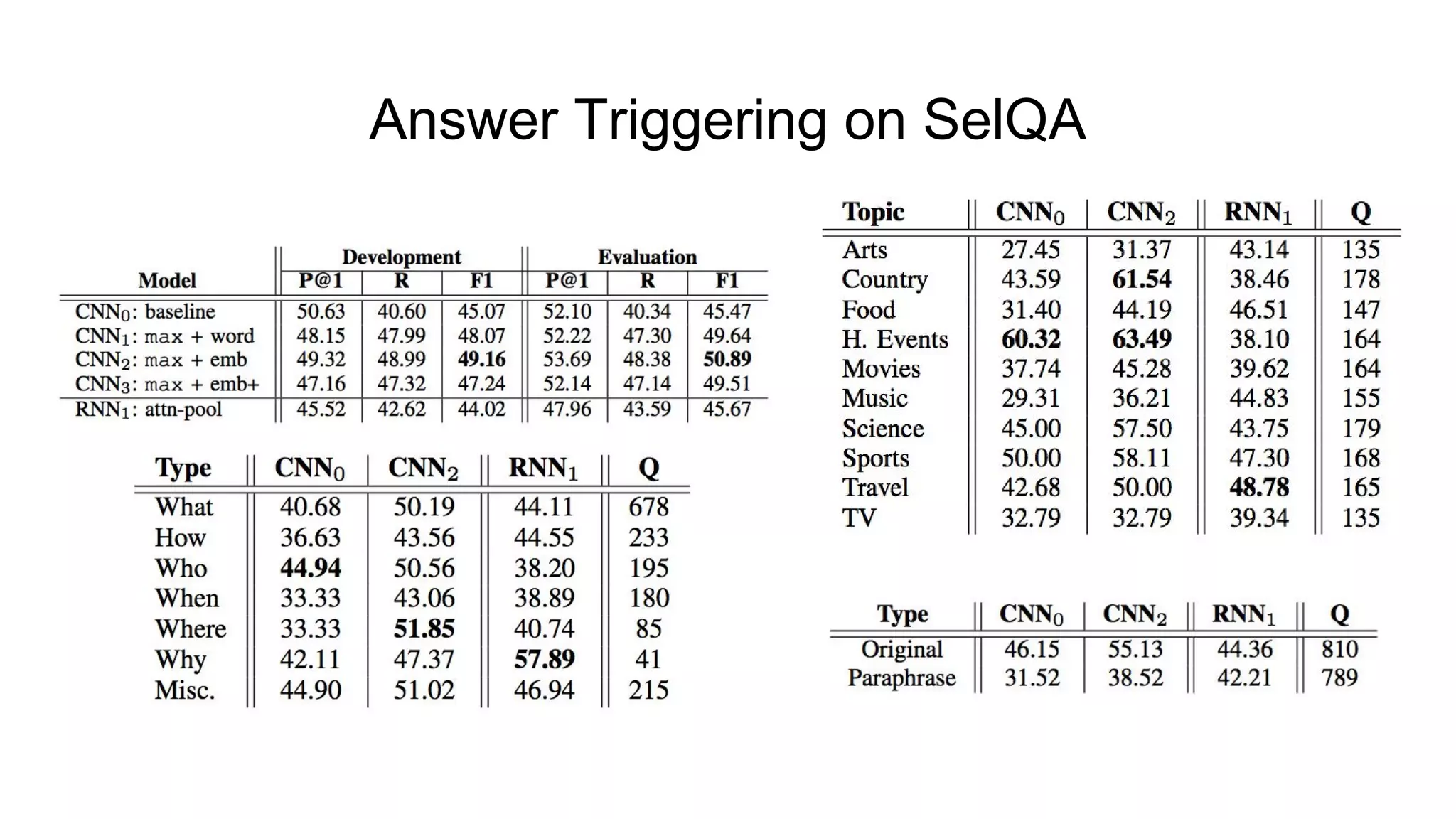
























The document introduces SELQA, a new benchmark for selection-based question answering that emphasizes the complexity of identifying answers within a corpus derived from Wikipedia. It outlines tasks involved in generating questions and evaluating comprehension through various neural network models, including Convolutional and Recurrent Neural Networks. The study highlights the effectiveness of their annotation scheme and the need for further research on context-aware question answering systems.



![[slide] A Compare-Aggregate Model with Latent Clustering for Answer Selection](https://cdn.slidesharecdn.com/ss_thumbnails/cikm-19-presentationsyoon-191106032817-thumbnail.jpg?width=640&height=640&fit=bounds)























![[WI 2017] Context Suggestion: Empirical Evaluations vs User Studies](https://cdn.slidesharecdn.com/ss_thumbnails/slidewicontextsuggestion-170812014320-thumbnail.jpg?width=640&height=640&fit=bounds)


























































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)
