Download as PDF, PPTX





![Discover hidden relations and learn about the data
o Clustering f(X) = [X1,…, Xk], k disjoint subsets
o Association f(Xi, Xj) = R, relation
Training
o All examples are positive
o No labeling / No teacher
o No single correct answer
Practical usage
o Derive groups, not explicitly labeled
o Market basket analysis (association among items)](https://image.slidesharecdn.com/azuremachinelearning-171205152750/75/Azure-Machine-Learning-and-ML-on-Premises-6-2048.jpg)

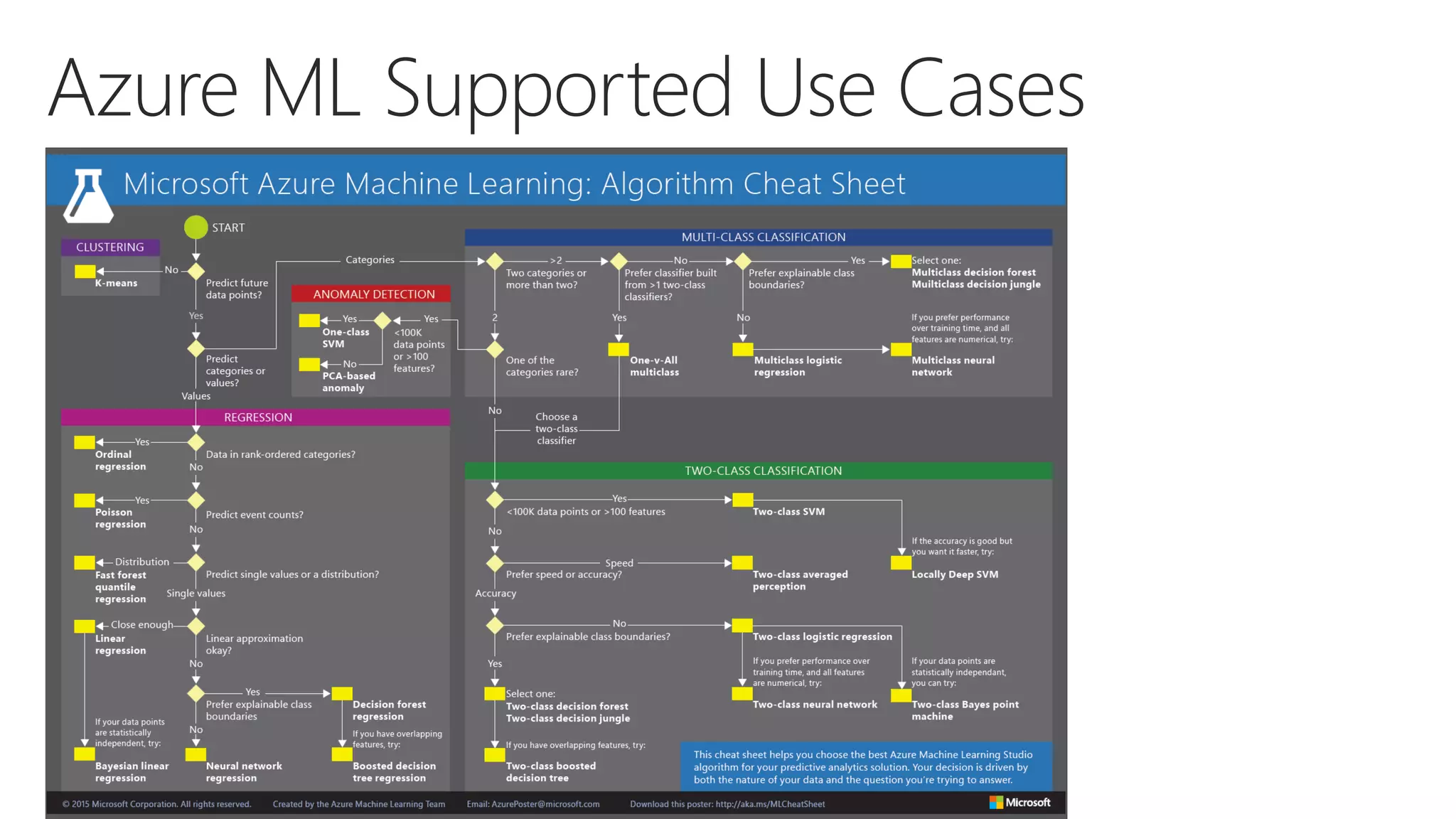




![5. Feature quality
Have you identified all useful features? Use domain knowledge of an expert.
Include any feature that could be found and investigate model performance
6. Feature engineering
The best strategy to improve performance and reveal important input
Encode features, normalize [0:1], combine features, resolve dependencies
7. Combine models
If multiple models have similar performance there is a chance of improvement
Use one model for one subset of data and another model for the other
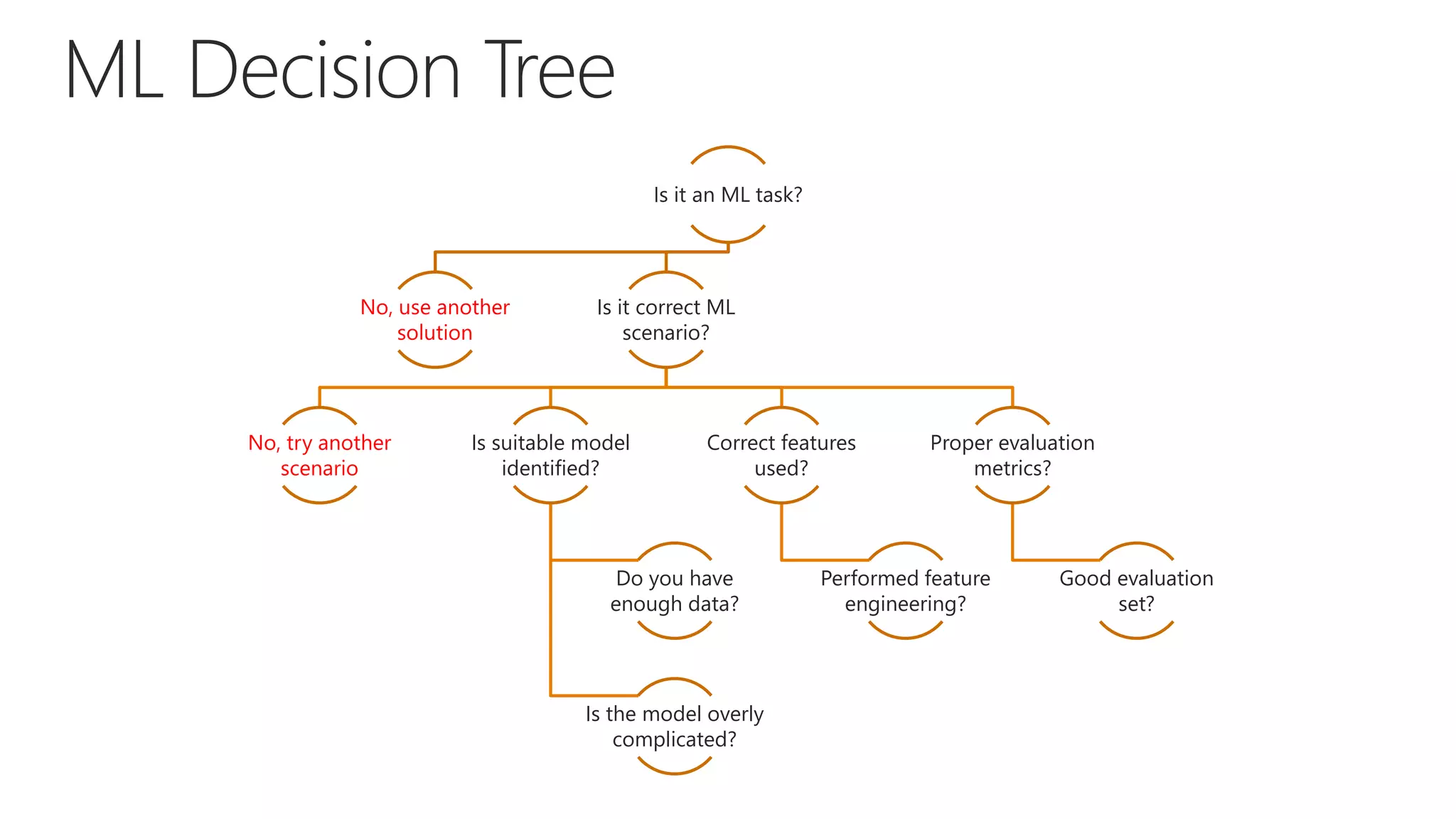
8. Model Validation and Tuning
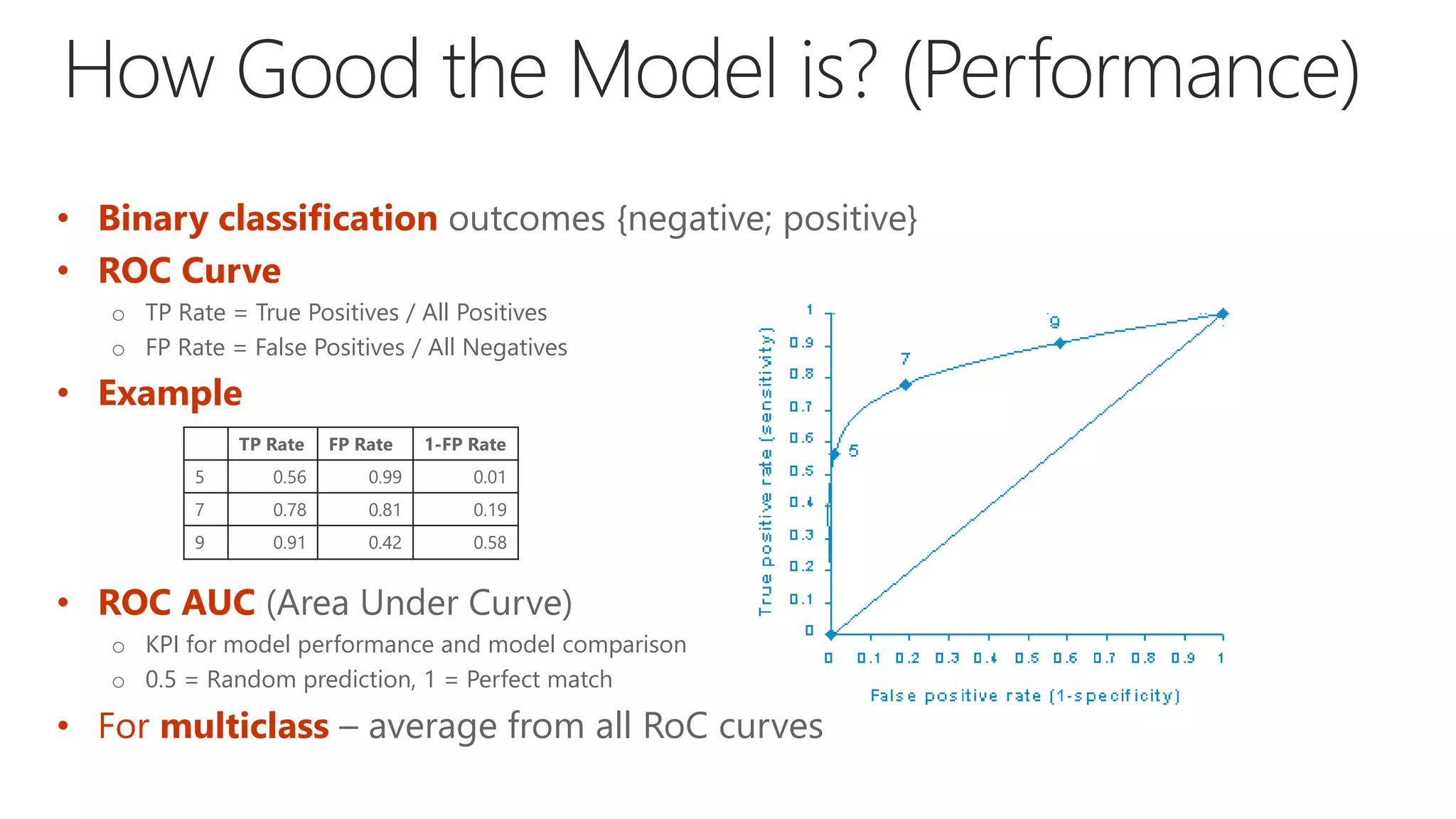
Use appropriate performance indicator (Accuracy, Precision, Recall, F1, etc.)
How well does the model describe data? (AUC)
Data typically divided into Training and Validation
Tune model hyper parameters (i.e. number of iterations)](https://image.slidesharecdn.com/azuremachinelearning-171205152750/75/Azure-Machine-Learning-and-ML-on-Premises-18-2048.jpg)
















![Discover hidden relations and learn about the data
o Clustering f(X) = [X1,…, Xk], k disjoint subsets
o Association f(Xi, Xj) = R, relation
Training
o All examples are positive
o No labeling / No teacher
o No single correct answer
Practical usage
o Derive groups, not explicitly labeled
o Market basket analysis (association among items)](https://crownmelresort.com/image.slidesharecdn.com/azuremachinelearning-171205152750/75/Azure-Machine-Learning-and-ML-on-Premises-6-2048.jpg)











![5. Feature quality
Have you identified all useful features? Use domain knowledge of an expert.
Include any feature that could be found and investigate model performance
6. Feature engineering
The best strategy to improve performance and reveal important input
Encode features, normalize [0:1], combine features, resolve dependencies
7. Combine models
If multiple models have similar performance there is a chance of improvement
Use one model for one subset of data and another model for the other
8. Model Validation and Tuning
Use appropriate performance indicator (Accuracy, Precision, Recall, F1, etc.)
How well does the model describe data? (AUC)
Data typically divided into Training and Validation
Tune model hyper parameters (i.e. number of iterations)](https://crownmelresort.com/image.slidesharecdn.com/azuremachinelearning-171205152750/75/Azure-Machine-Learning-and-ML-on-Premises-18-2048.jpg)













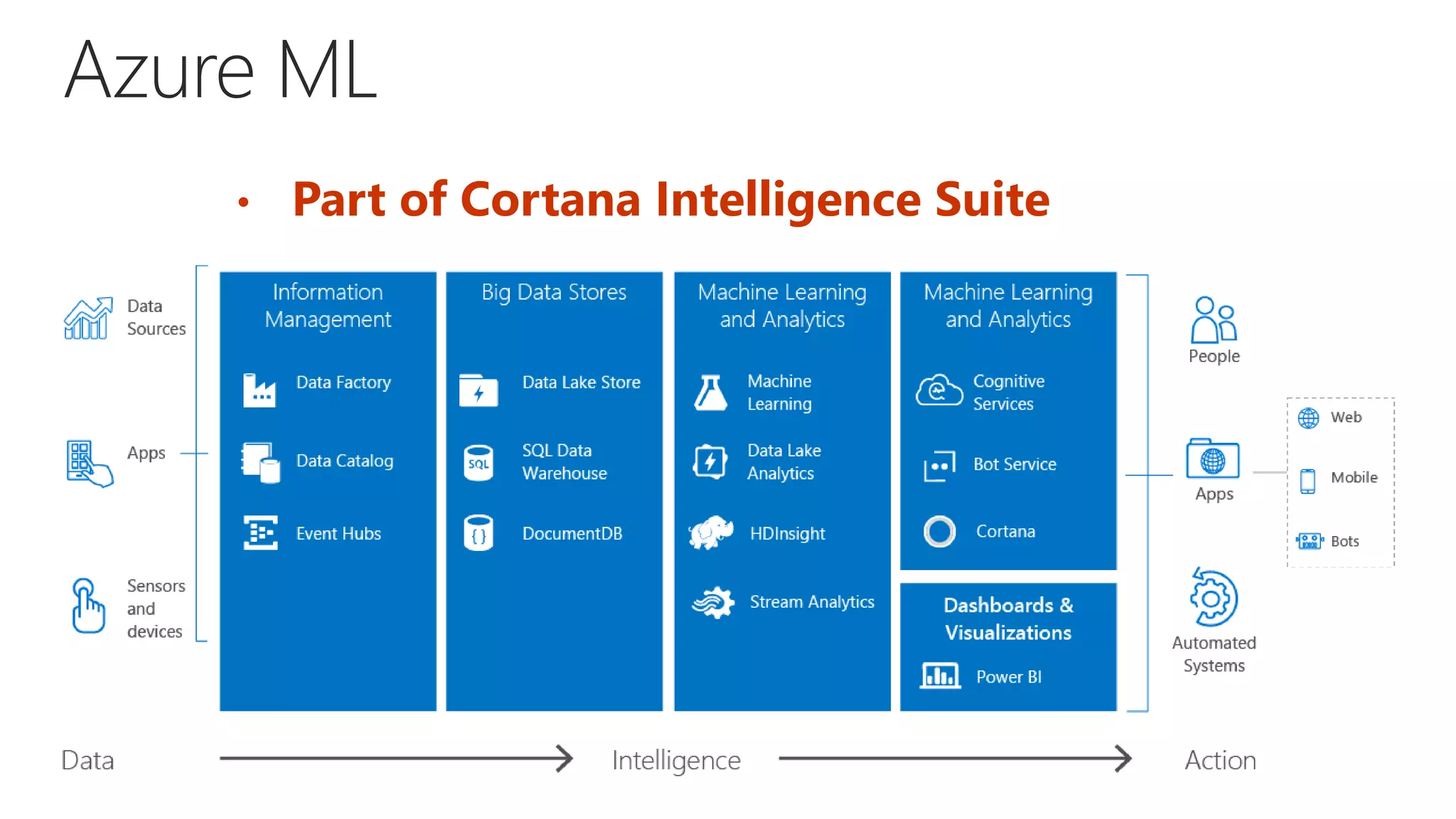
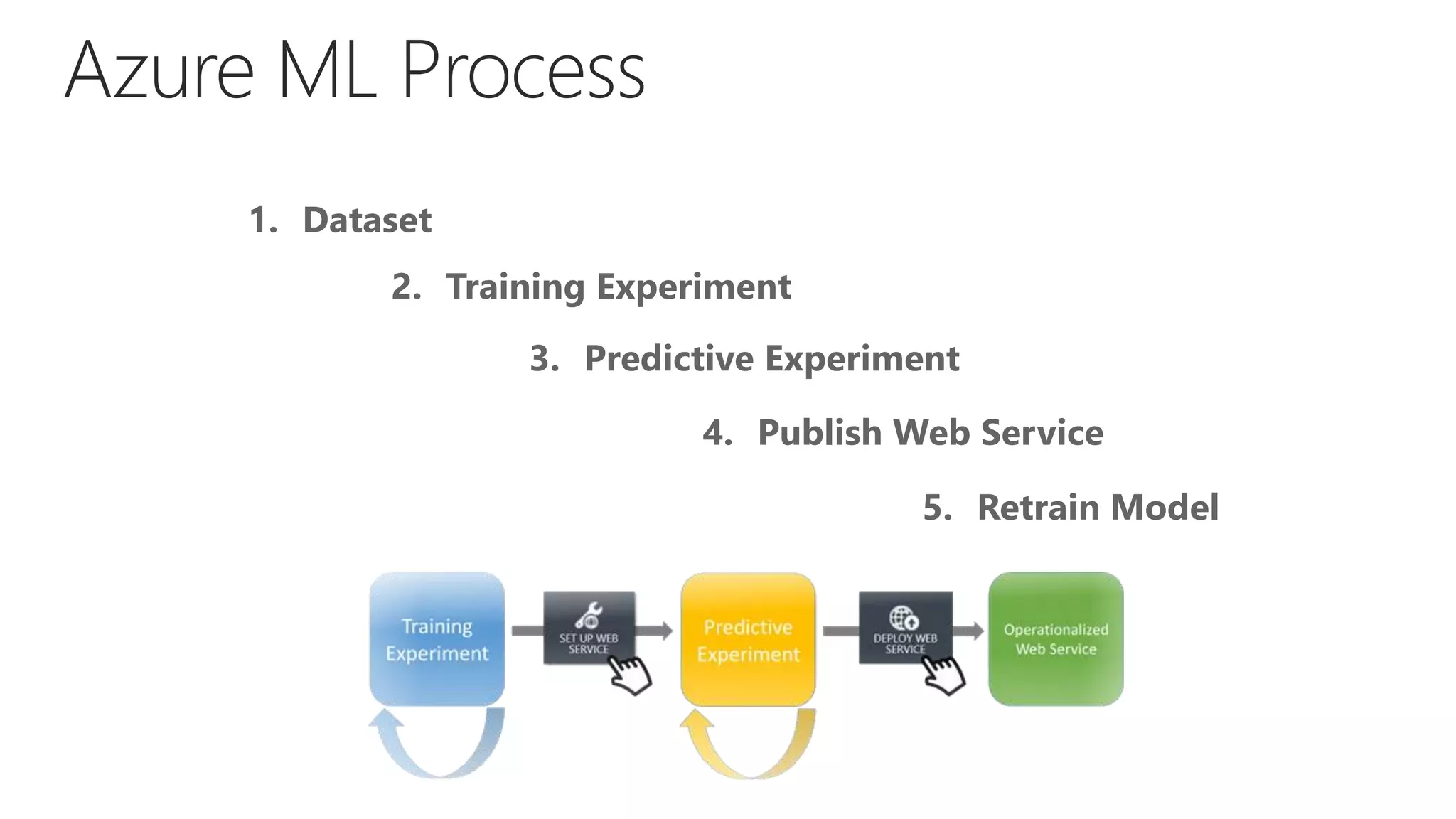
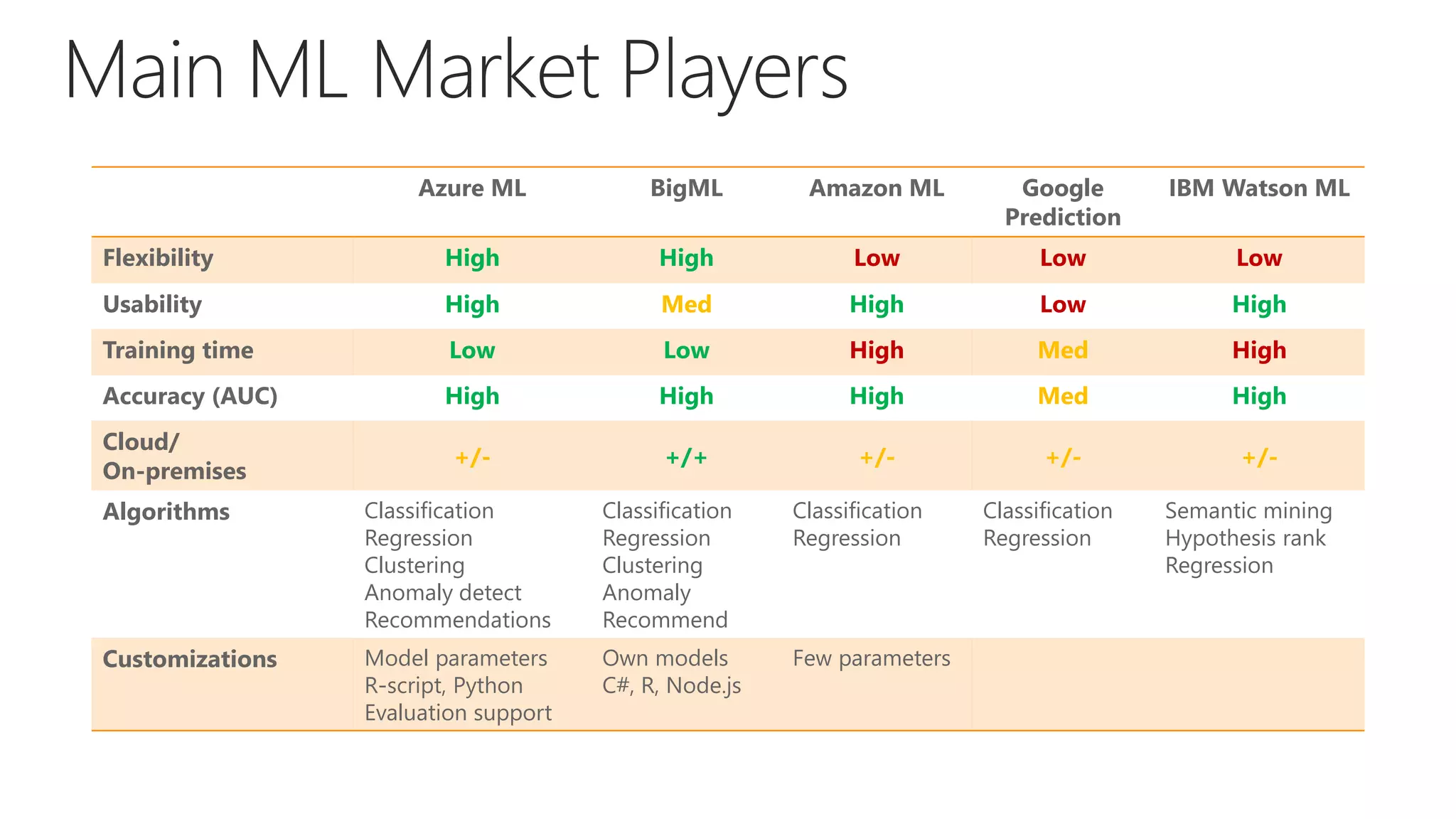
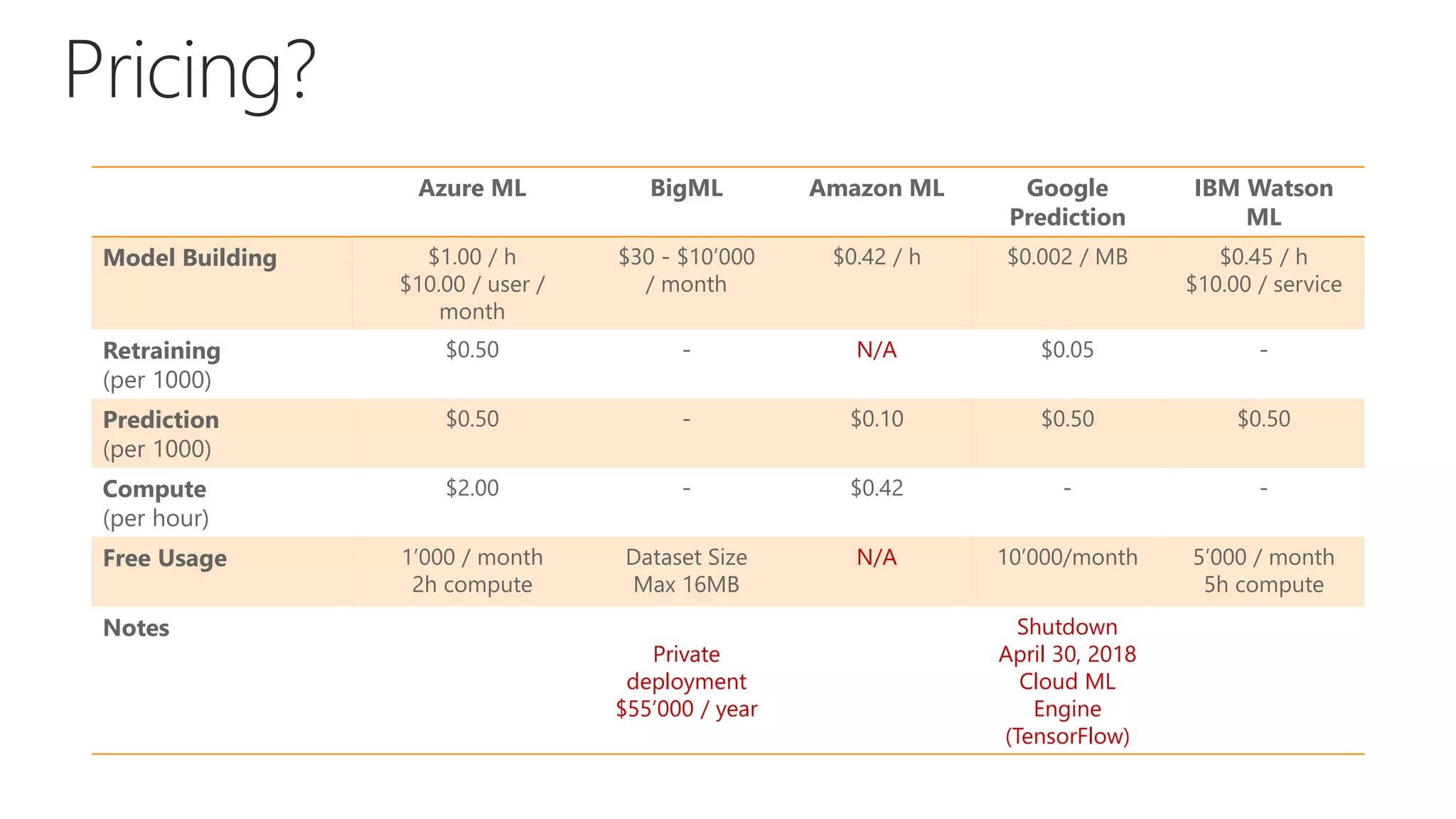
The document outlines the fundamentals of machine learning (ML), focusing on supervised learning algorithms, model evaluation, and Azure ML capabilities. It elaborates on the process of developing ML models, highlights the importance of data quality, feature engineering, and choosing the right algorithms. Additionally, it compares various ML platforms and discusses performance metrics for model evaluation.






















































































