Download as PDF, PPTX




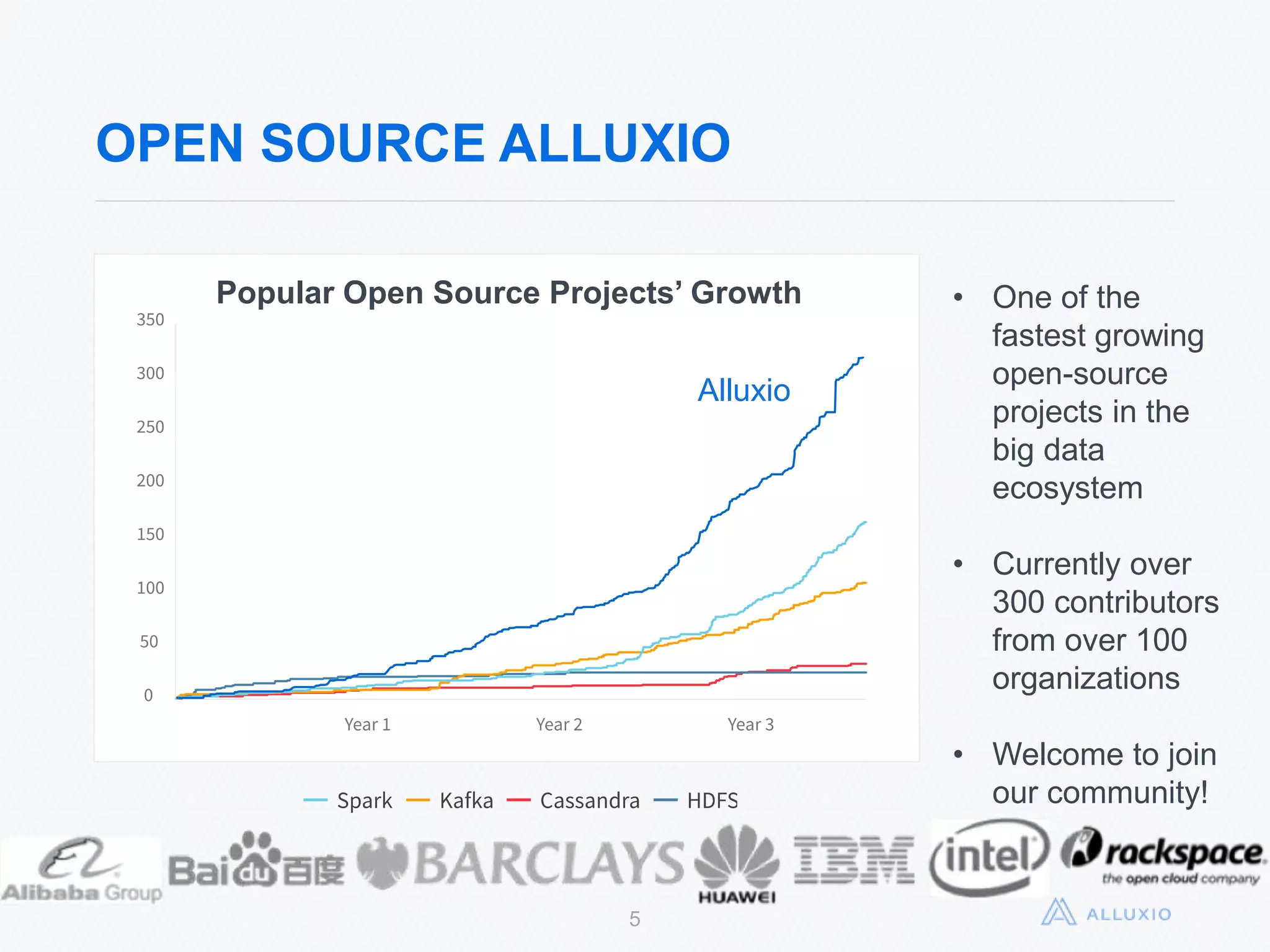
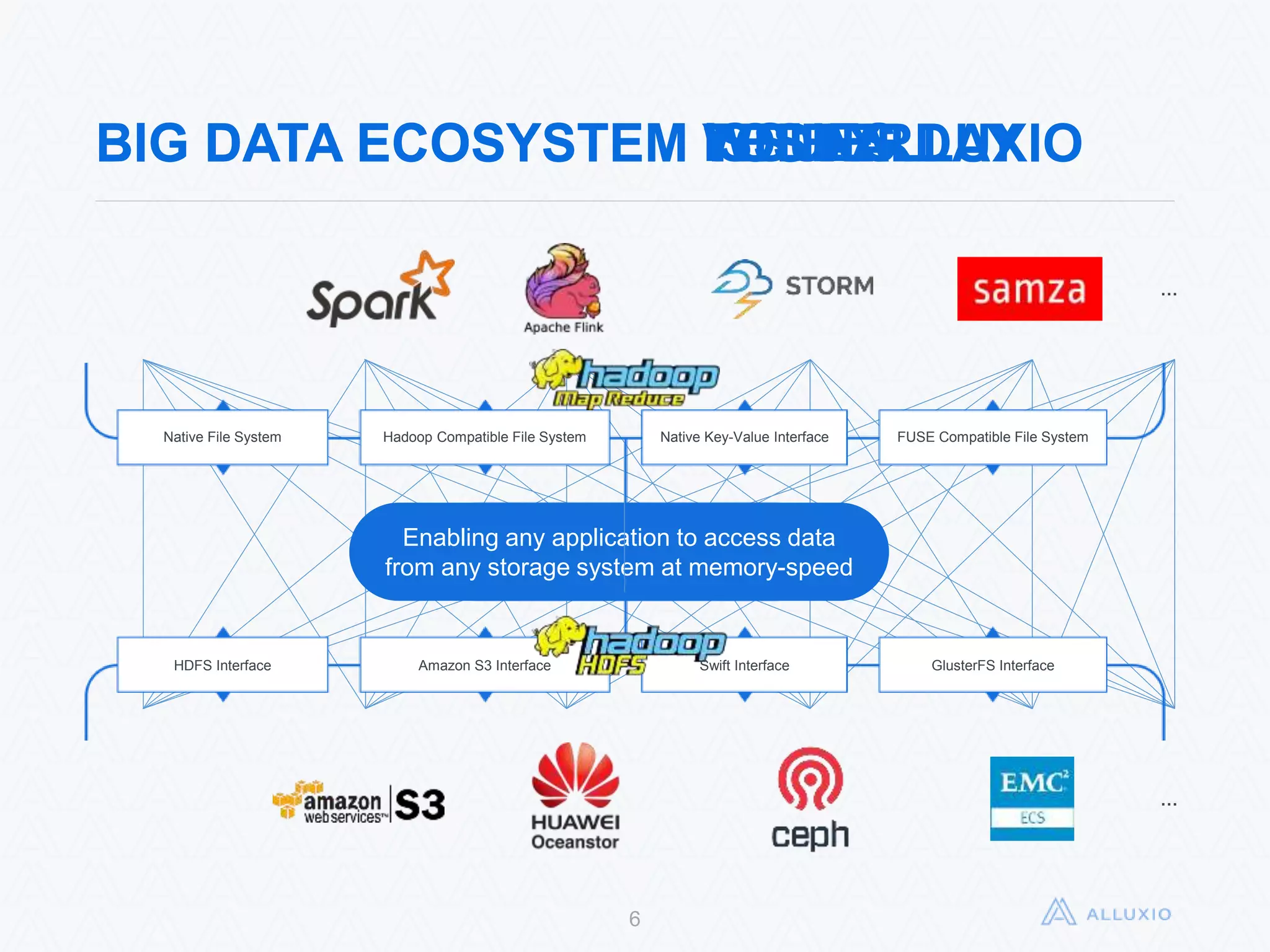
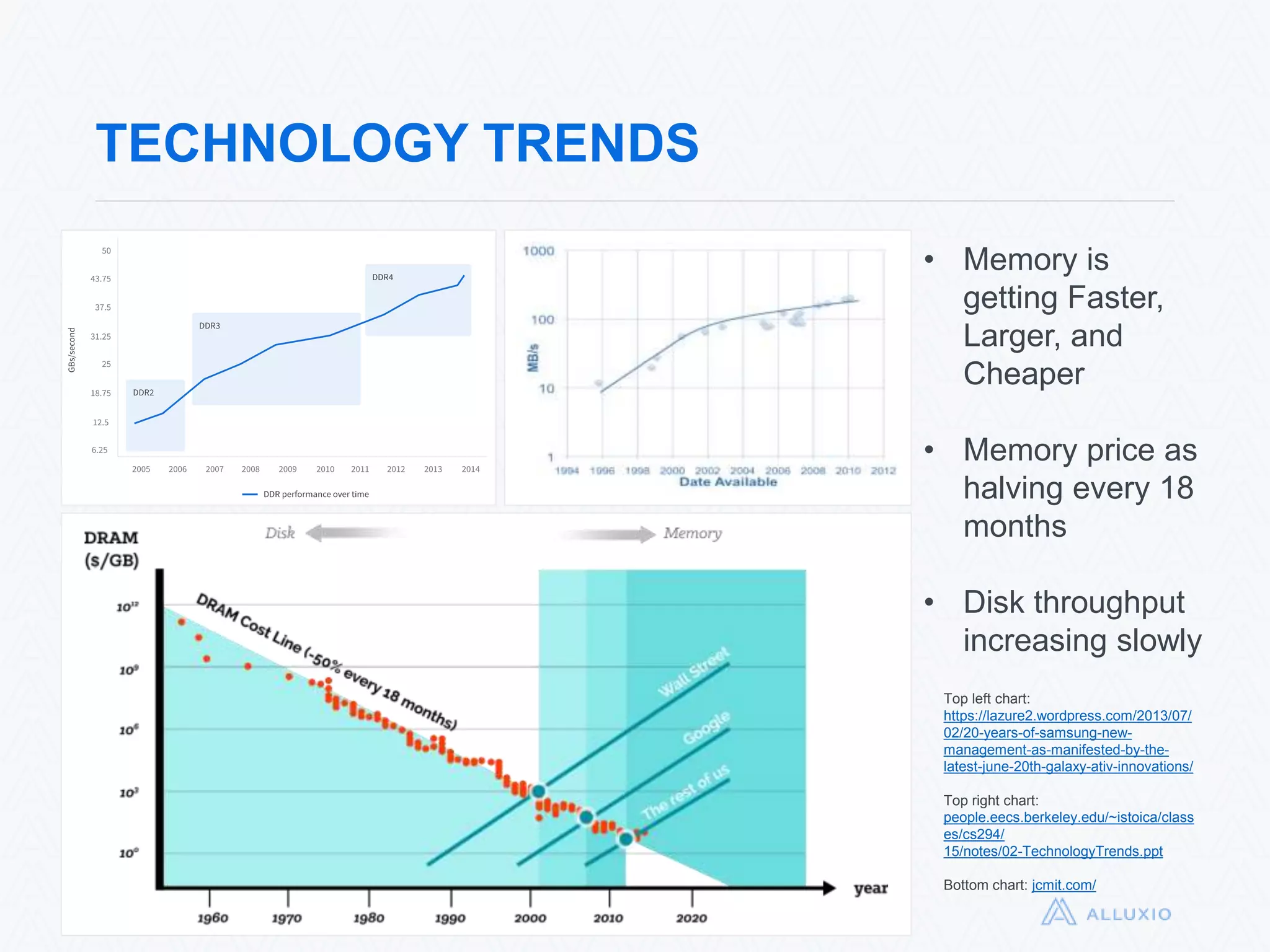

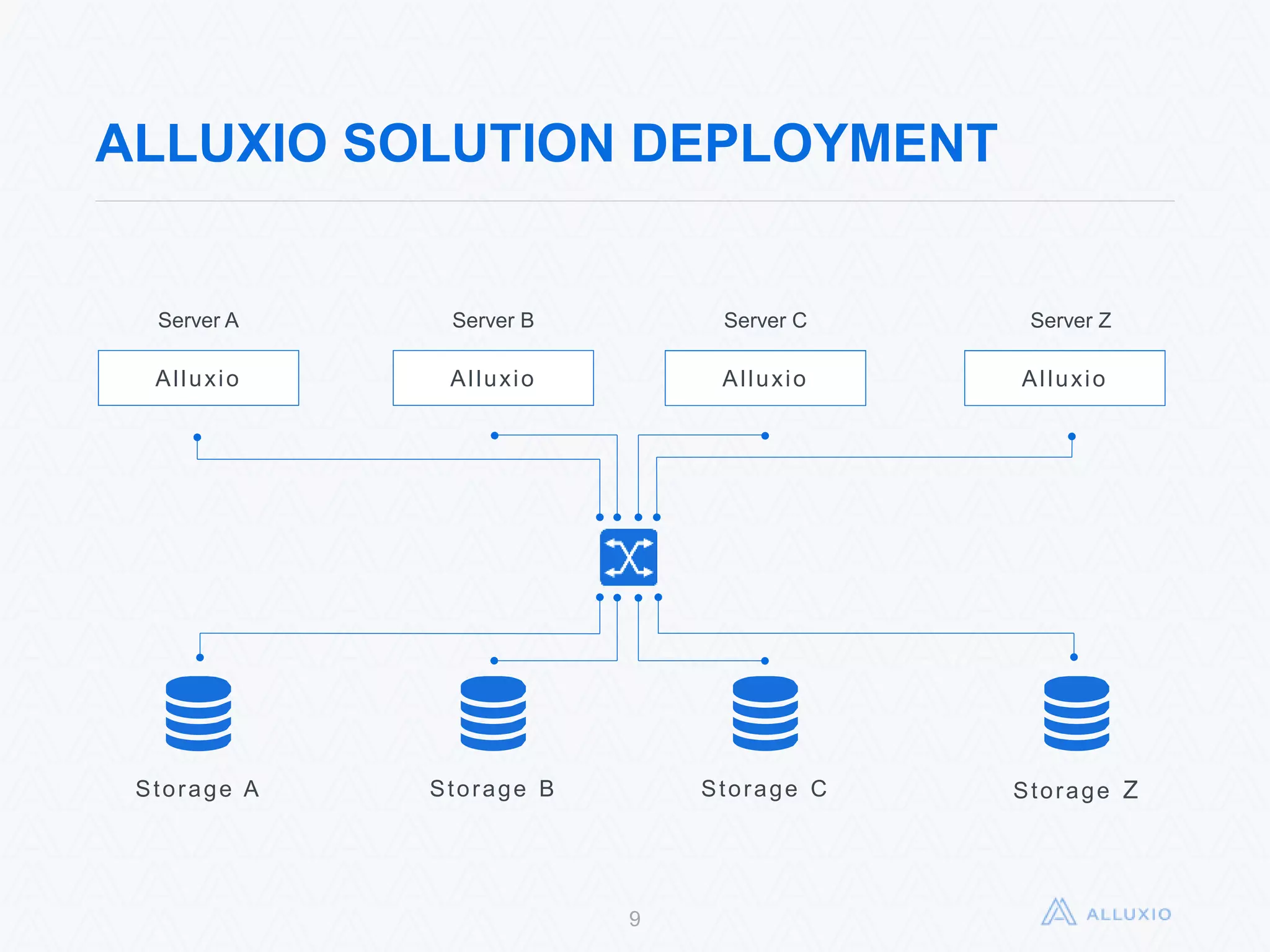


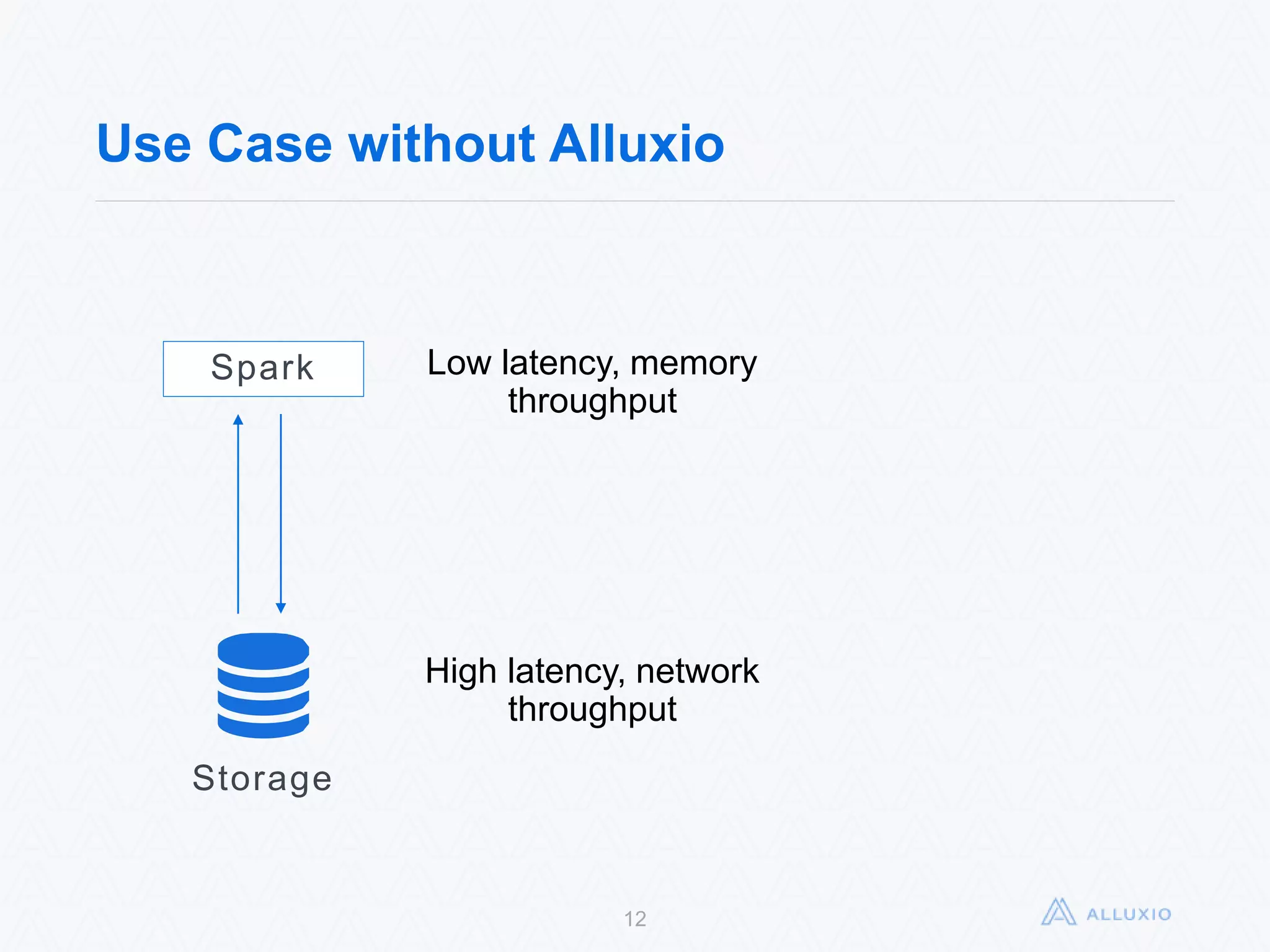
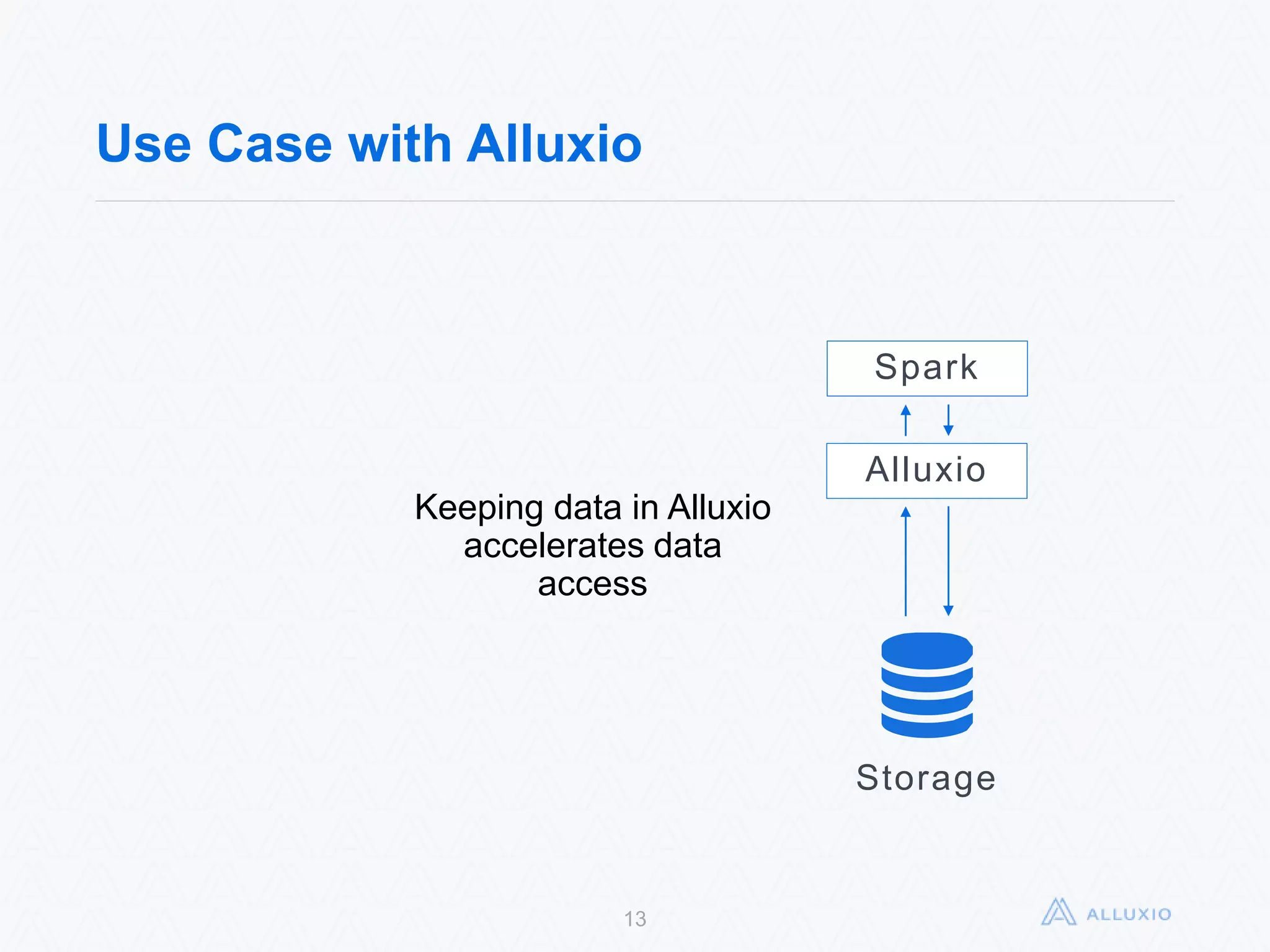


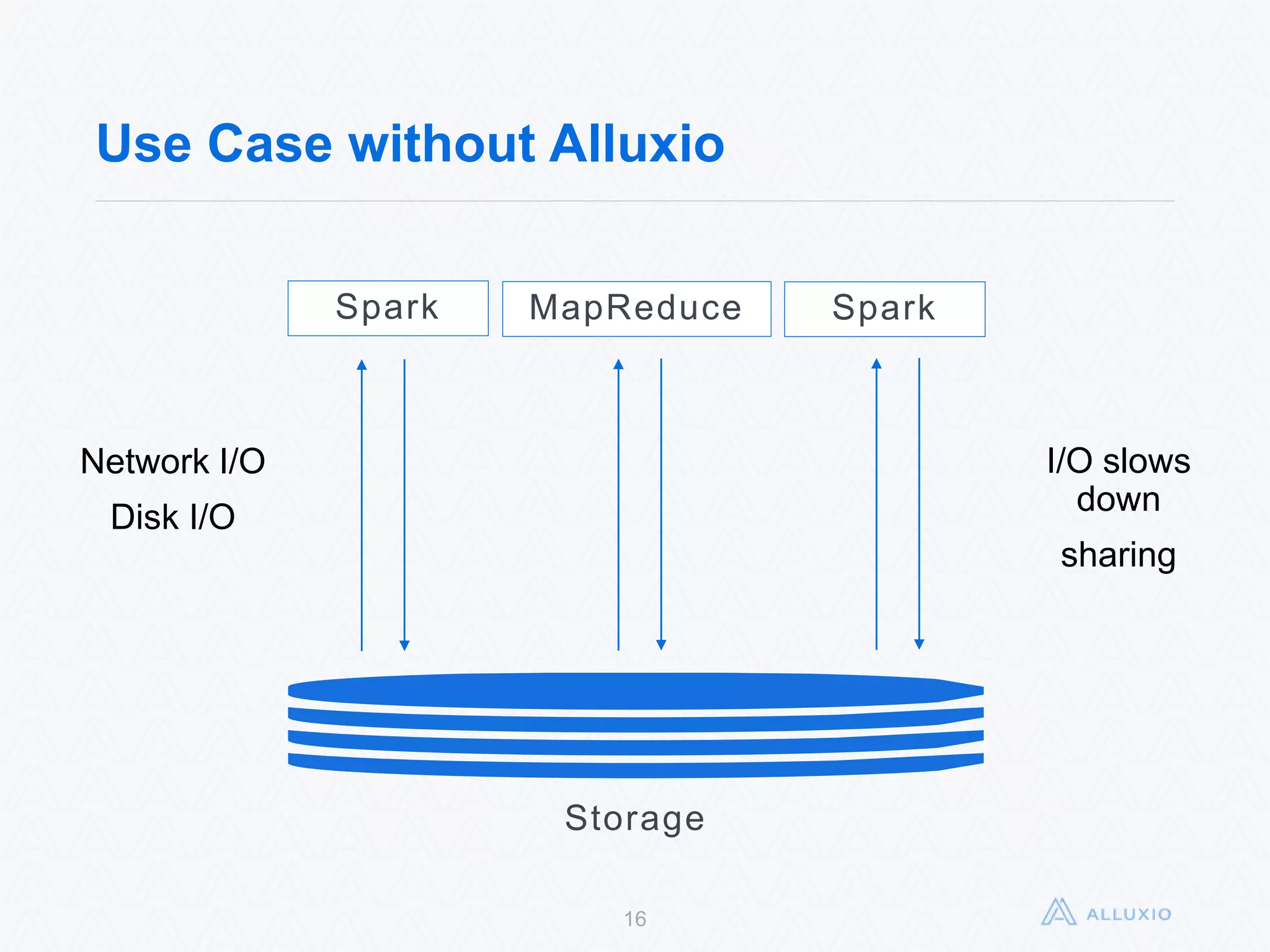
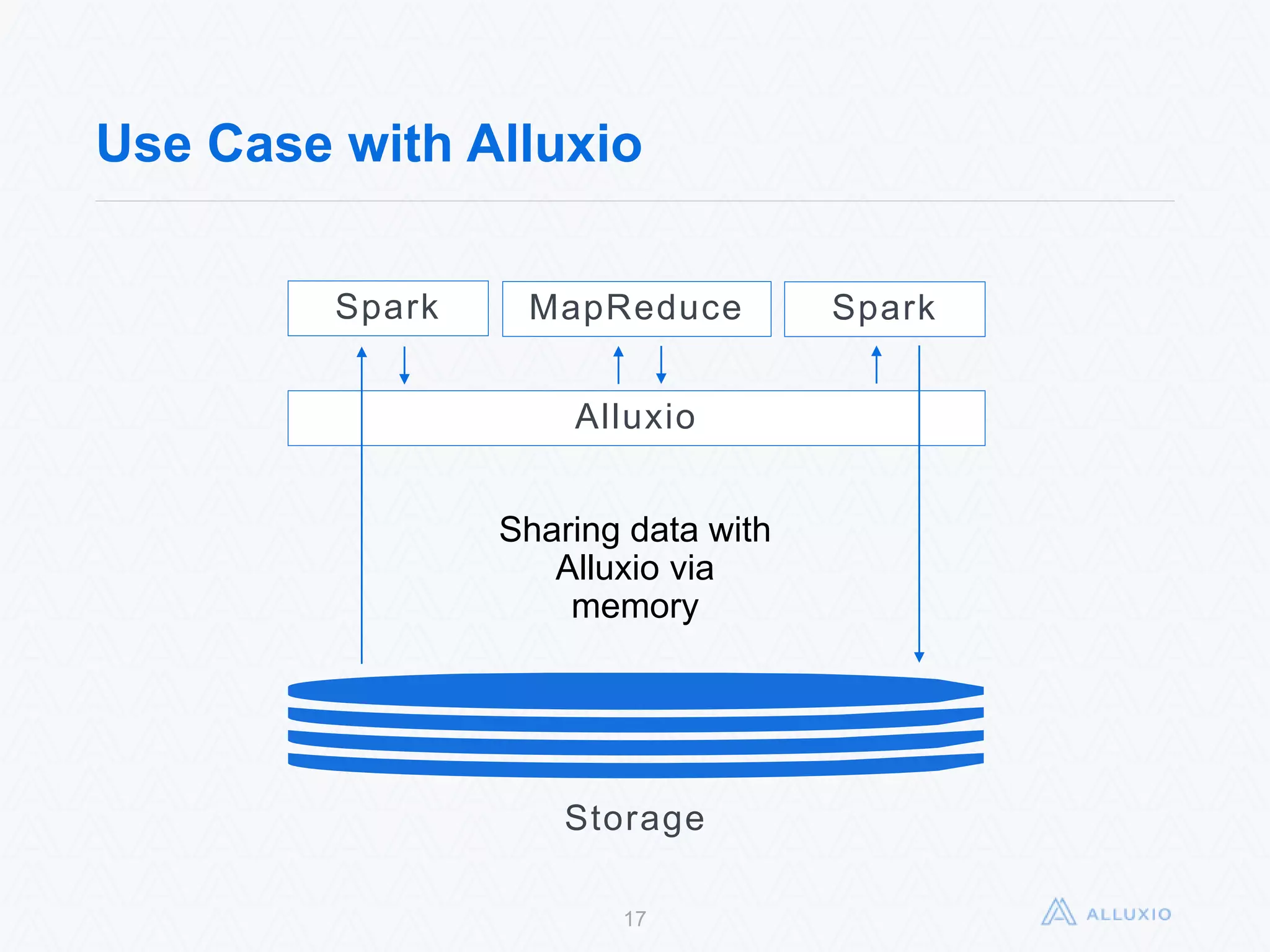


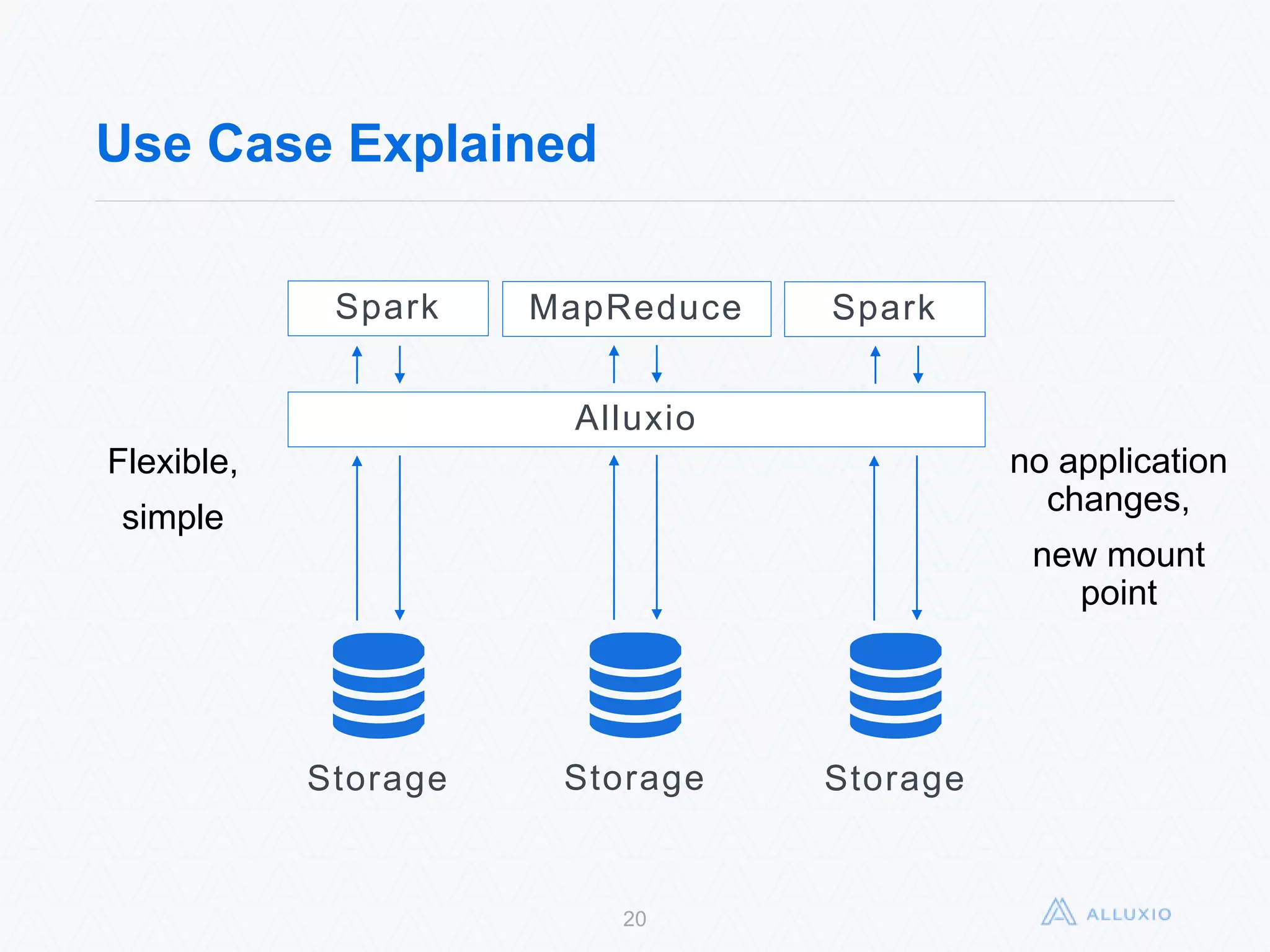

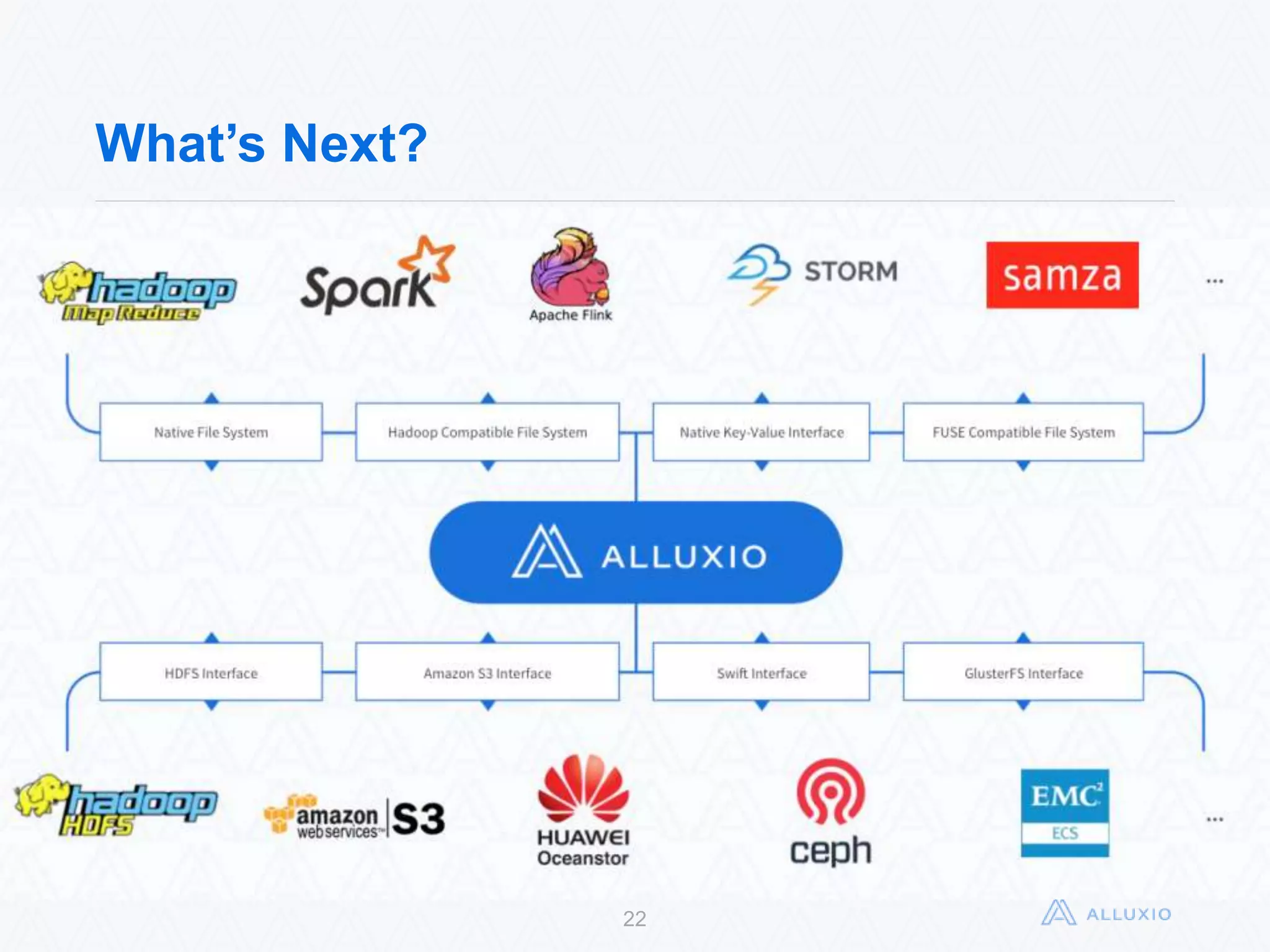

























Alluxio, formerly known as Tachyon, is an open-source, memory-speed virtual distributed storage system founded in 2012 at UC Berkeley. The platform allows for seamless data access across various storage systems, significantly improving data access speed and enabling efficient workflows for big data applications. With a community of over 300 contributors, Alluxio is one of the fastest-growing open-source projects in the big data ecosystem, offering benefits like unification of data workflows and enhanced performance.



































































































