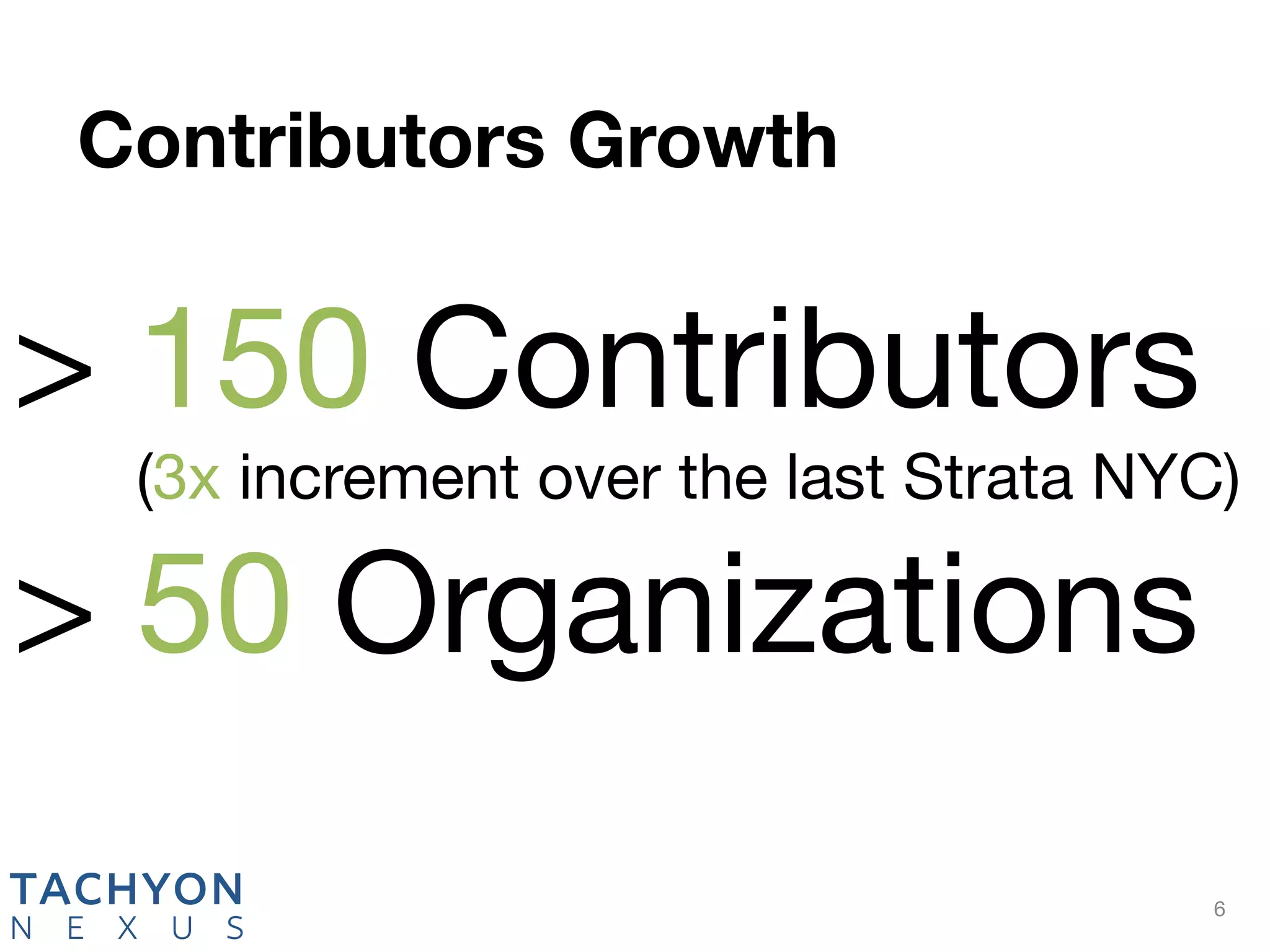
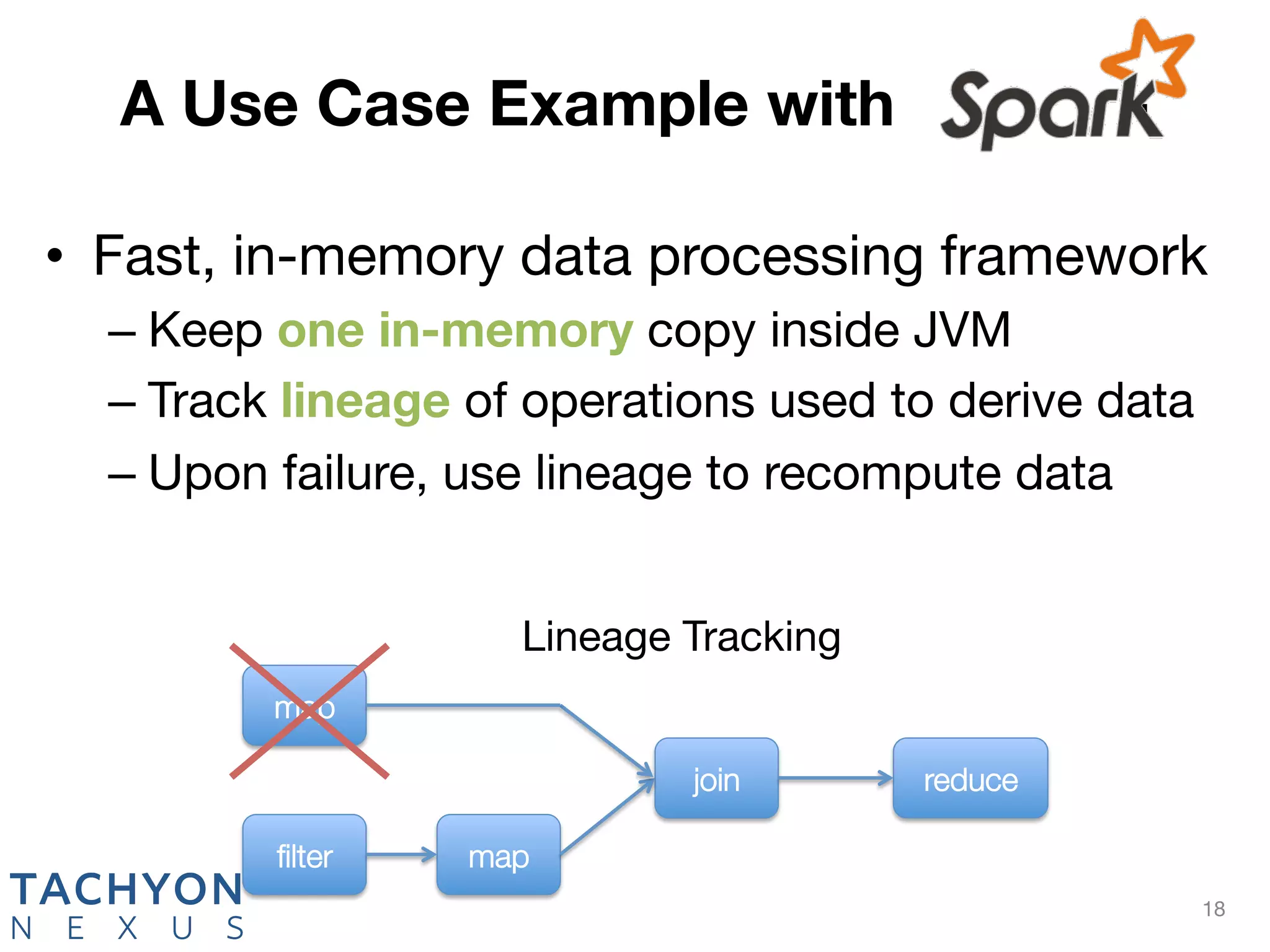
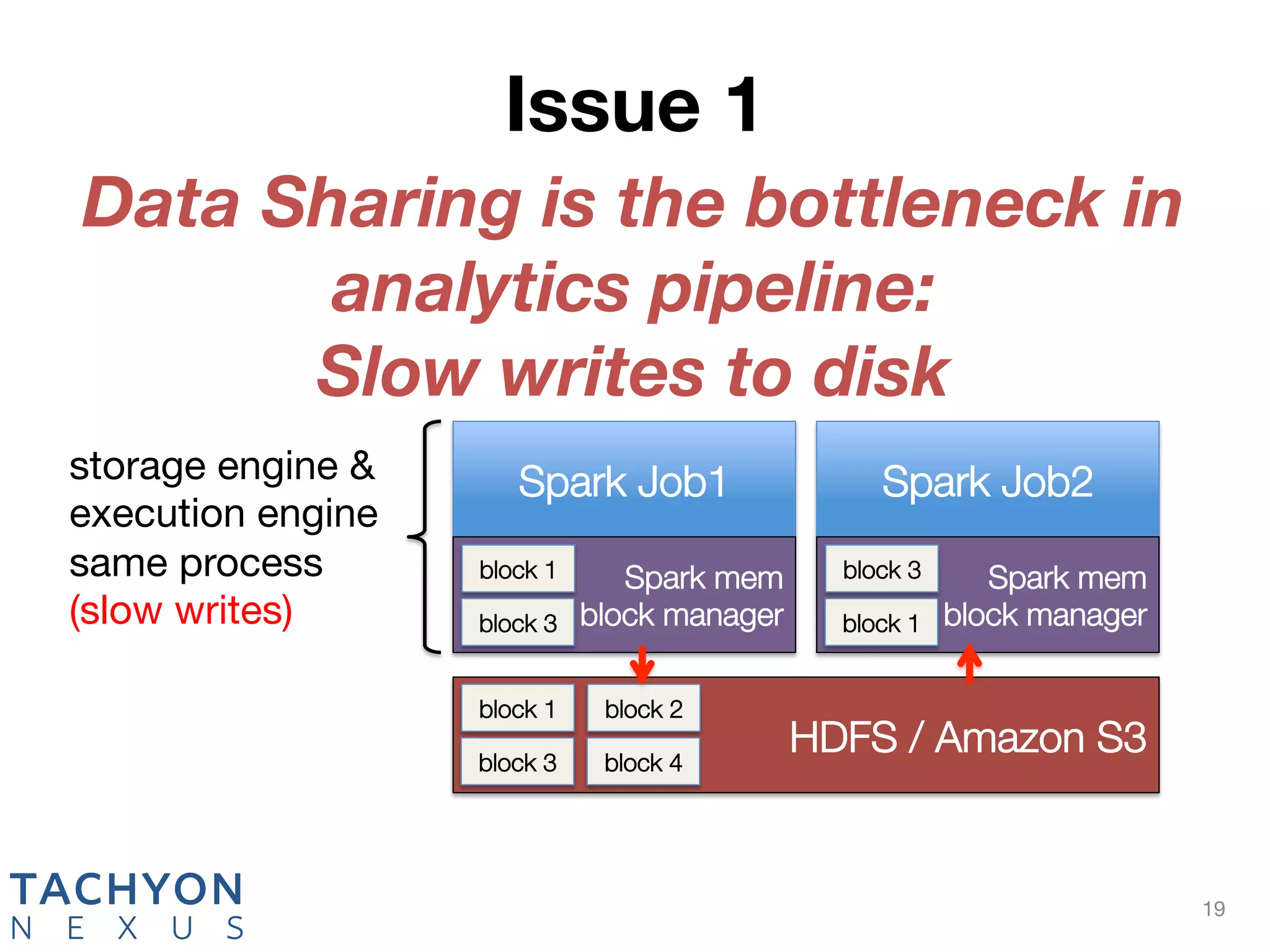
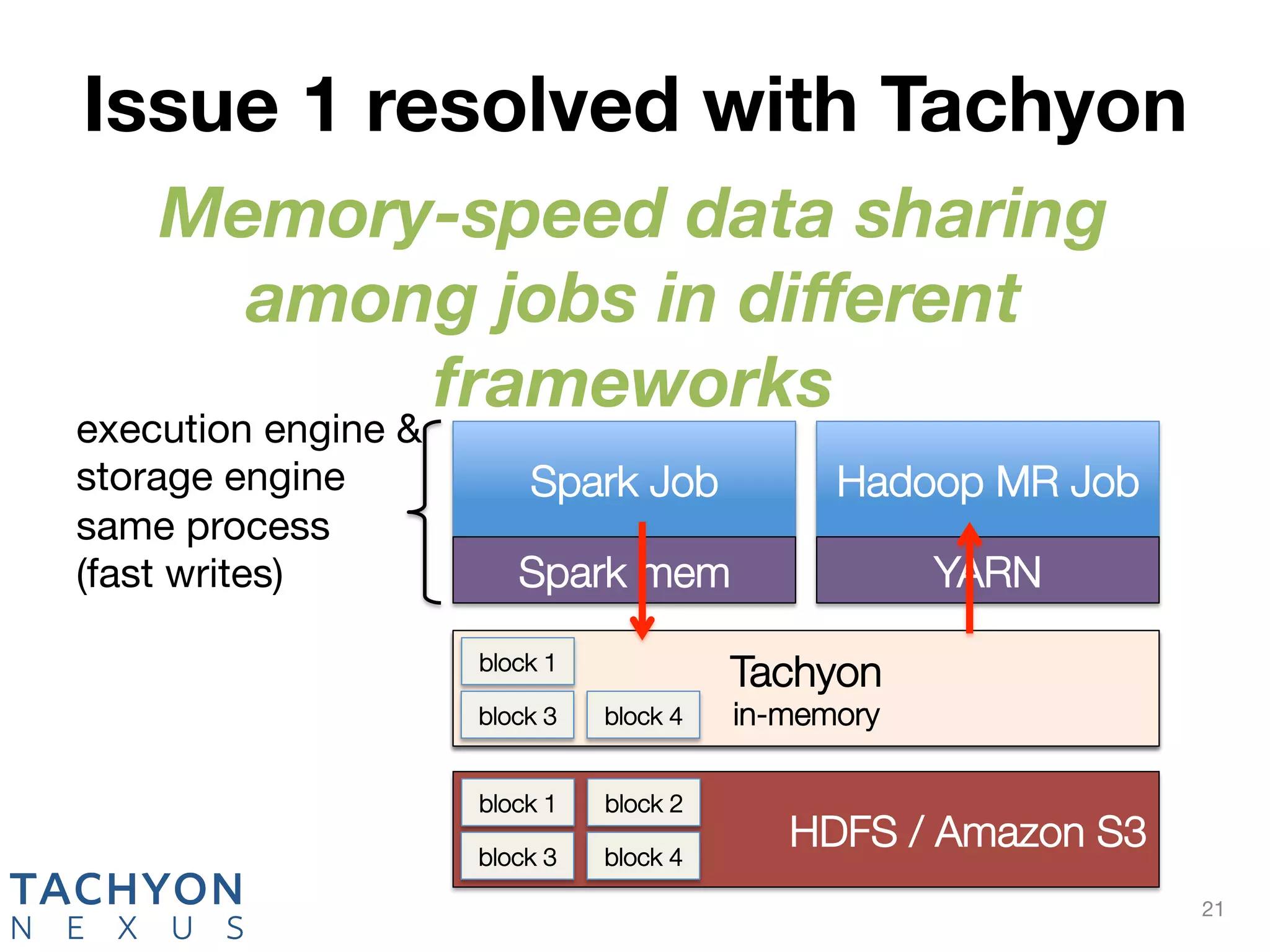
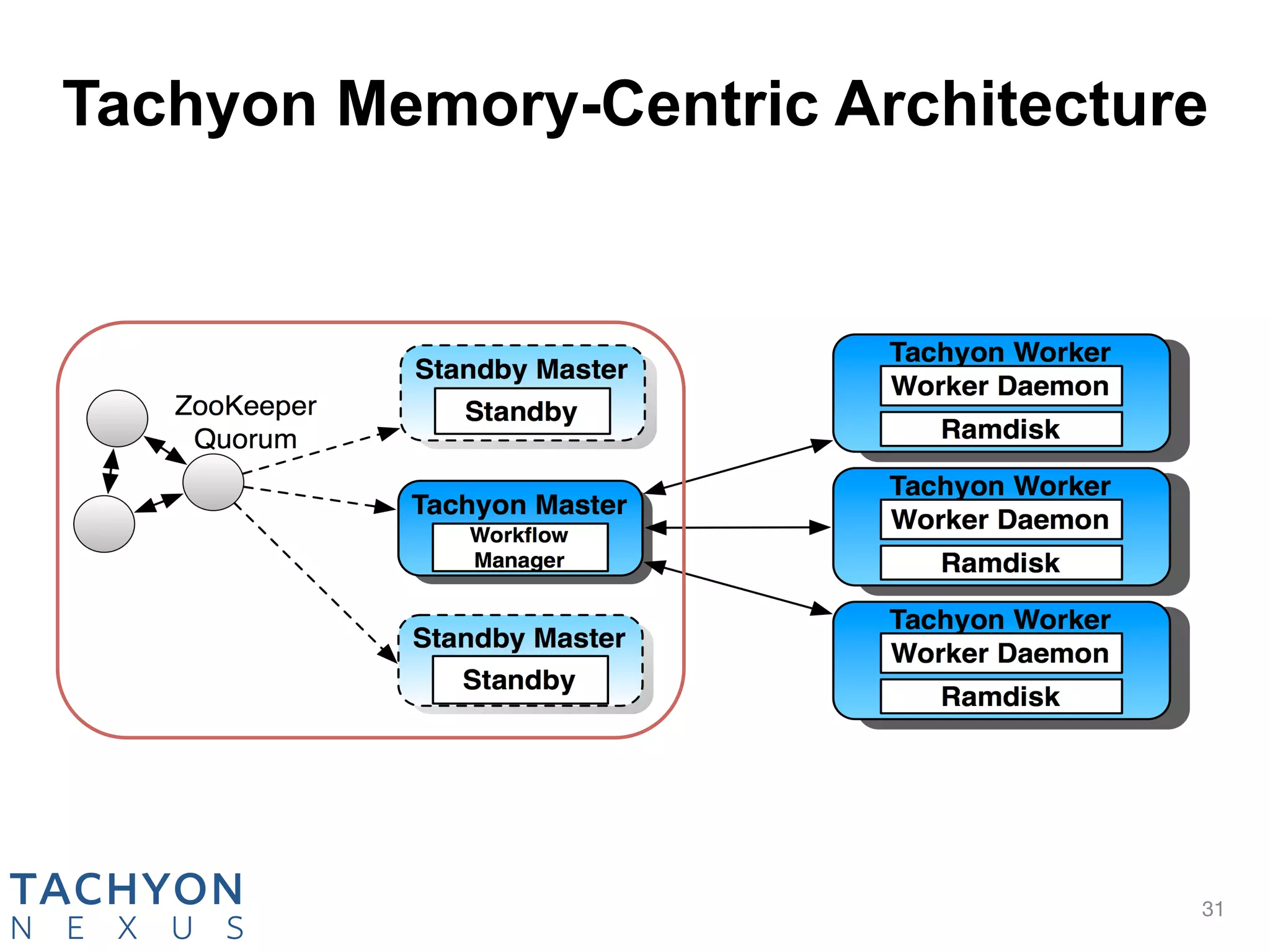
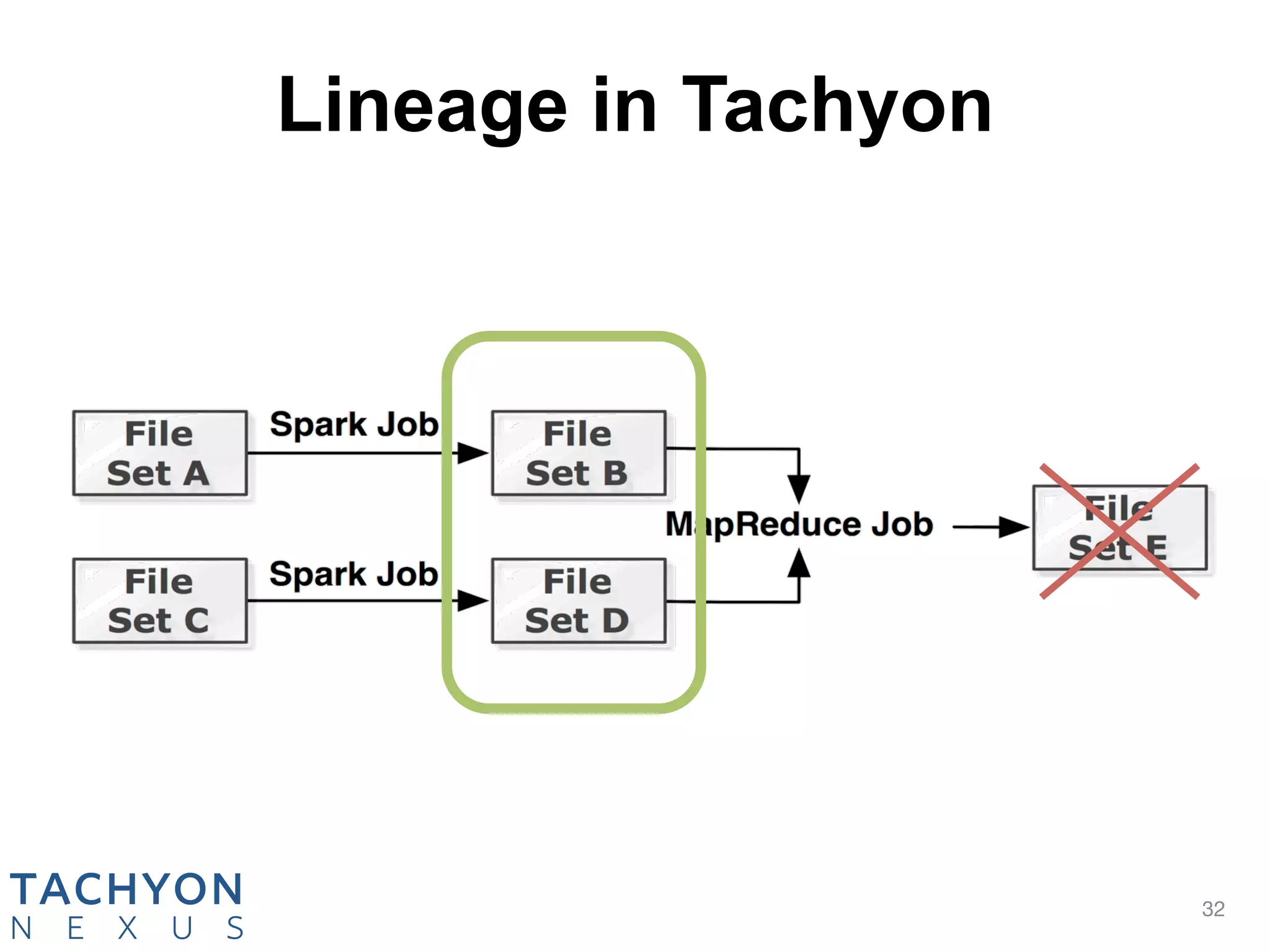
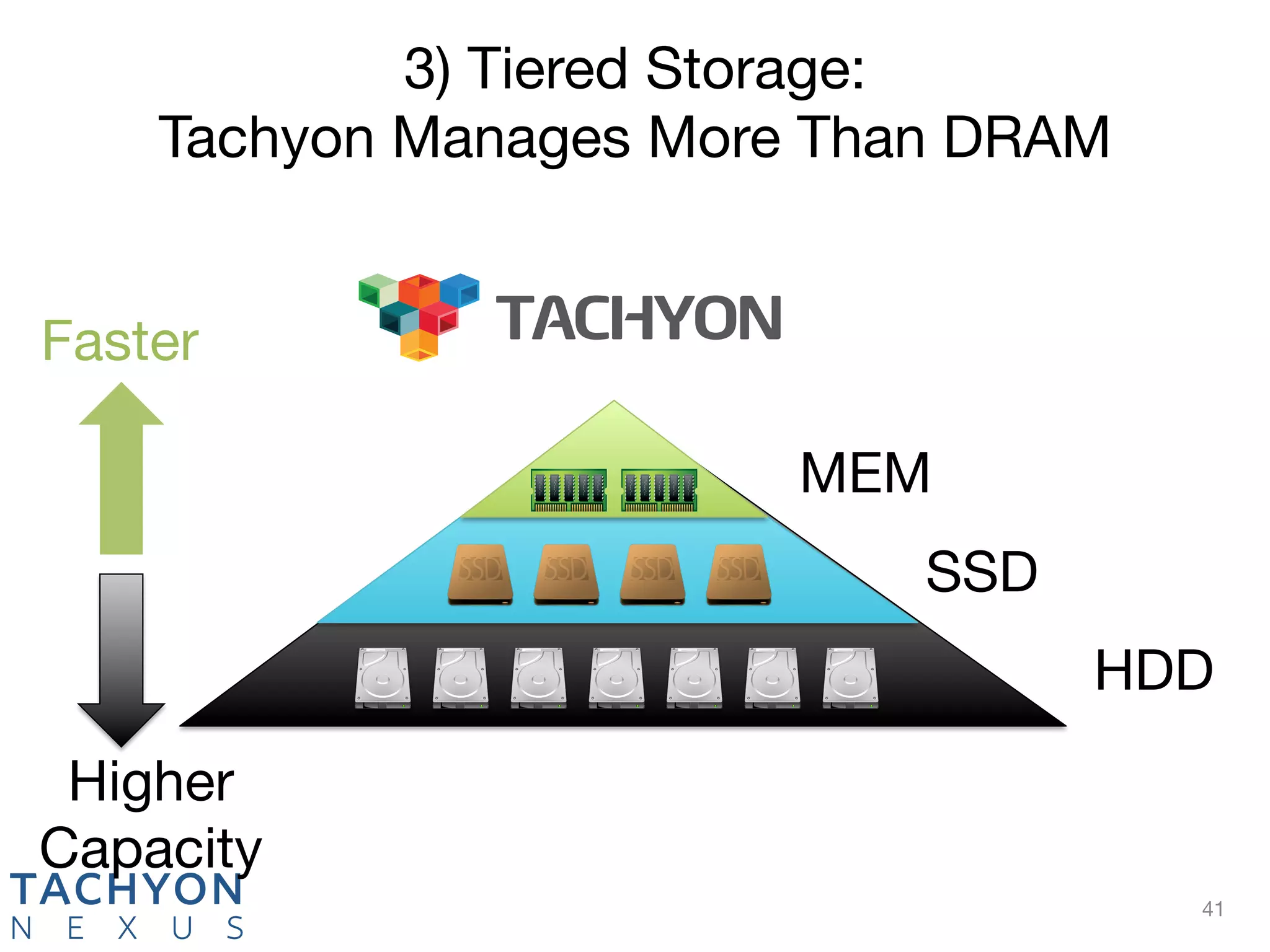
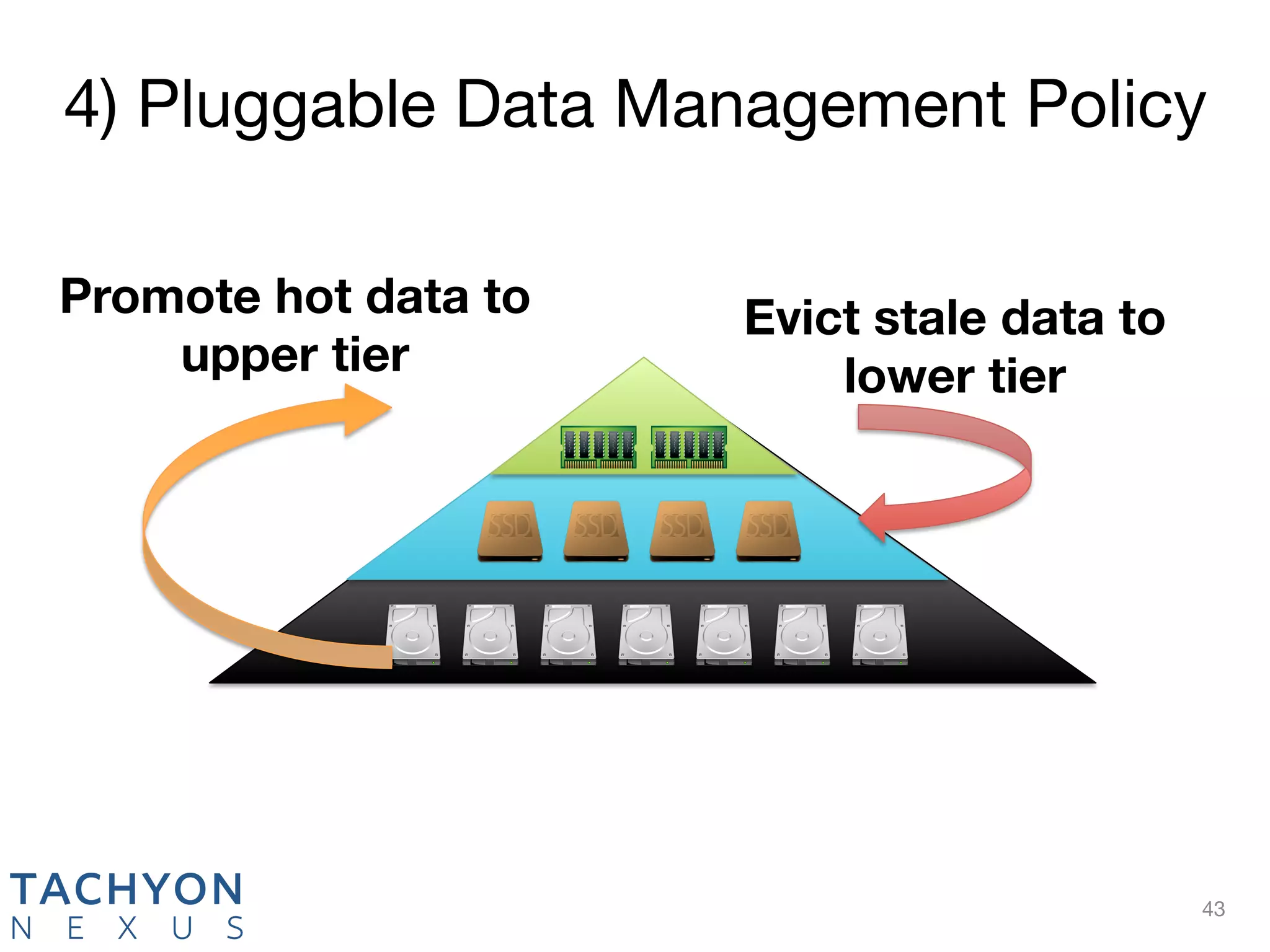
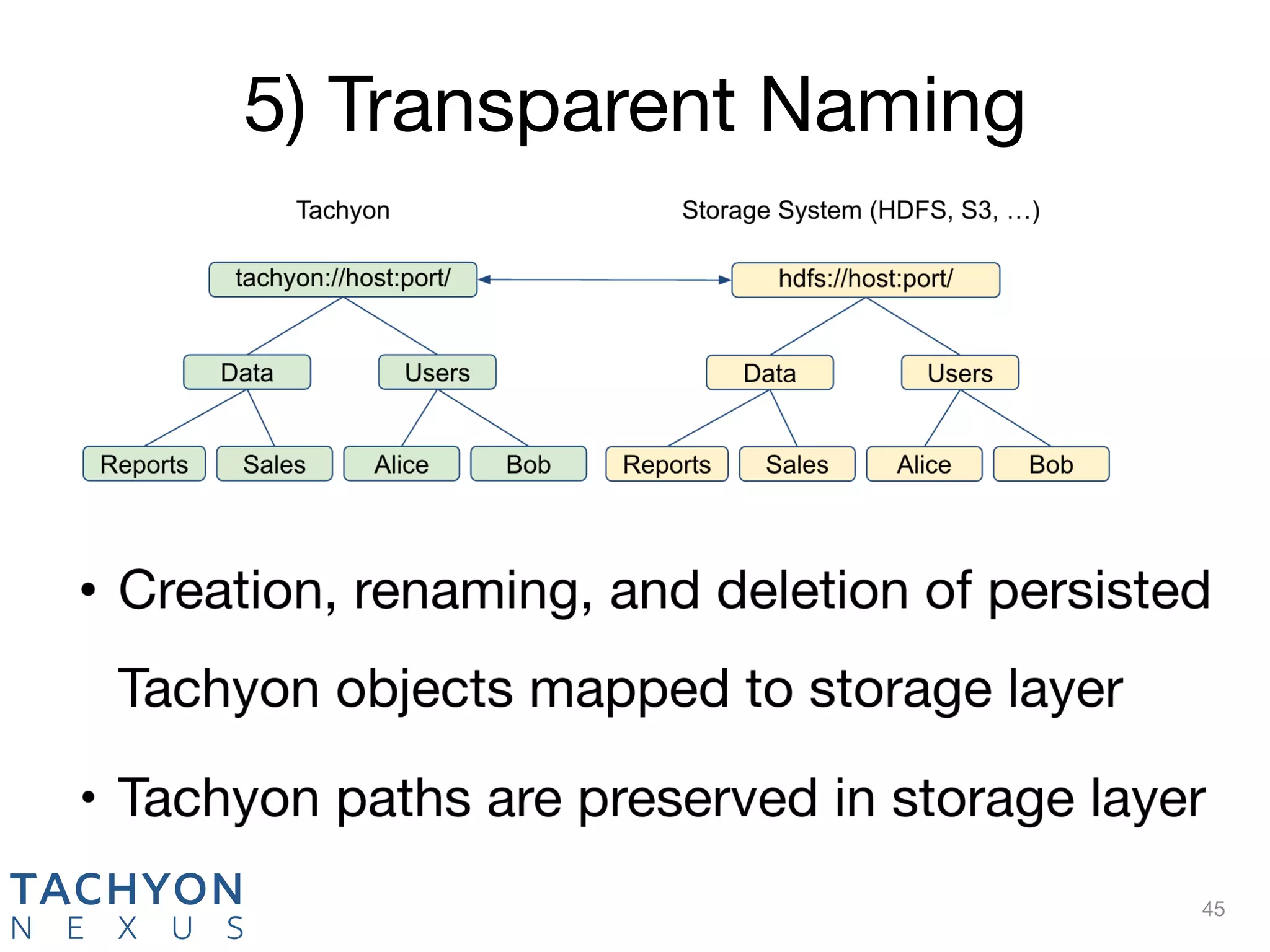
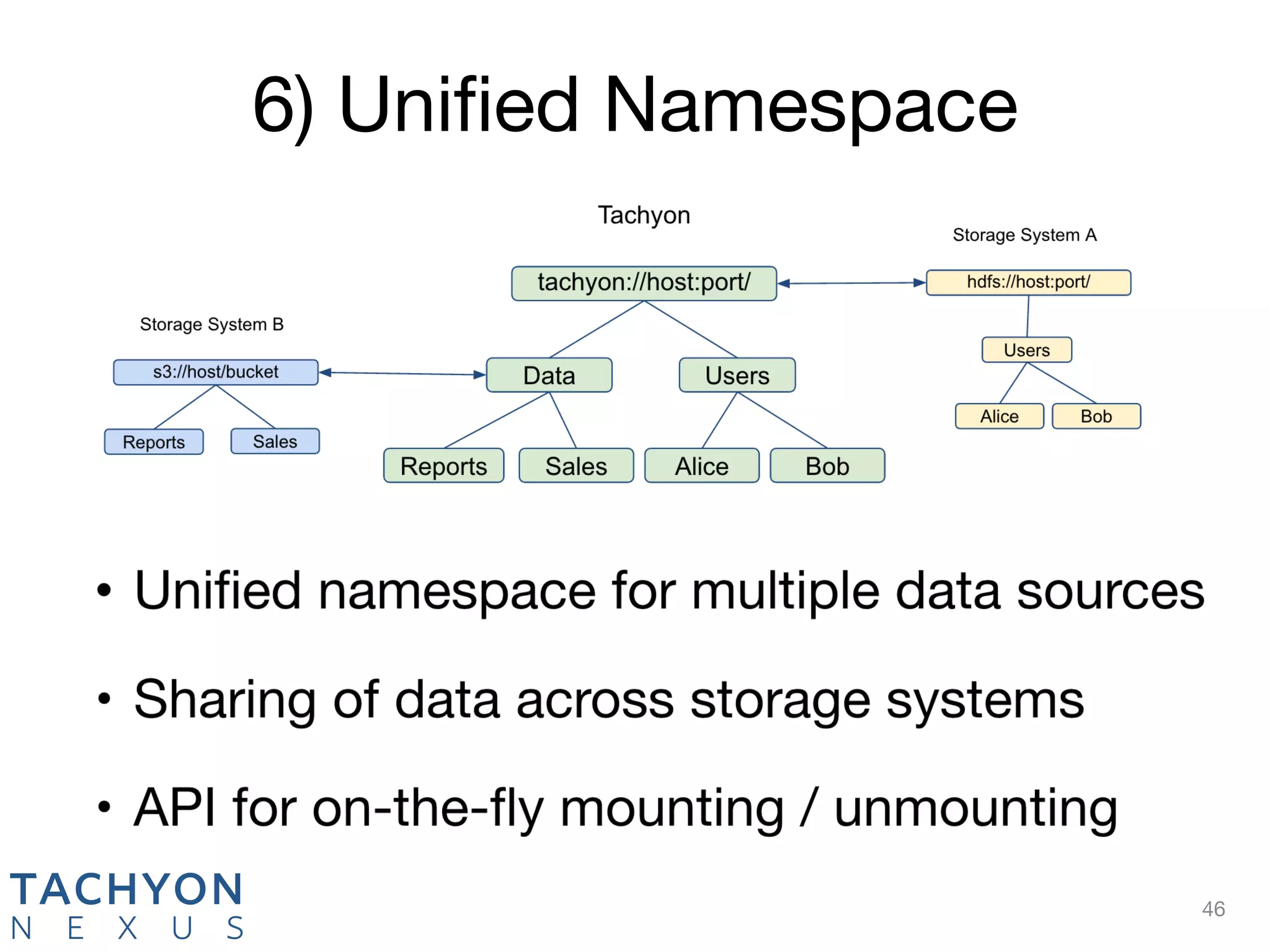
Tachyon is an open-source memory-centric distributed storage system that aims to enhance data processing performance by allowing fast, in-memory data sharing among jobs in various frameworks. Originally developed at UC Berkeley's AMPLab and deployed by over 100 companies, Tachyon addresses critical issues in the analytics pipeline such as slow writes and data duplication. The system provides features like tiered storage and lineage support, making it suitable for both cloud and on-premises environments.











































































































































































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)












