





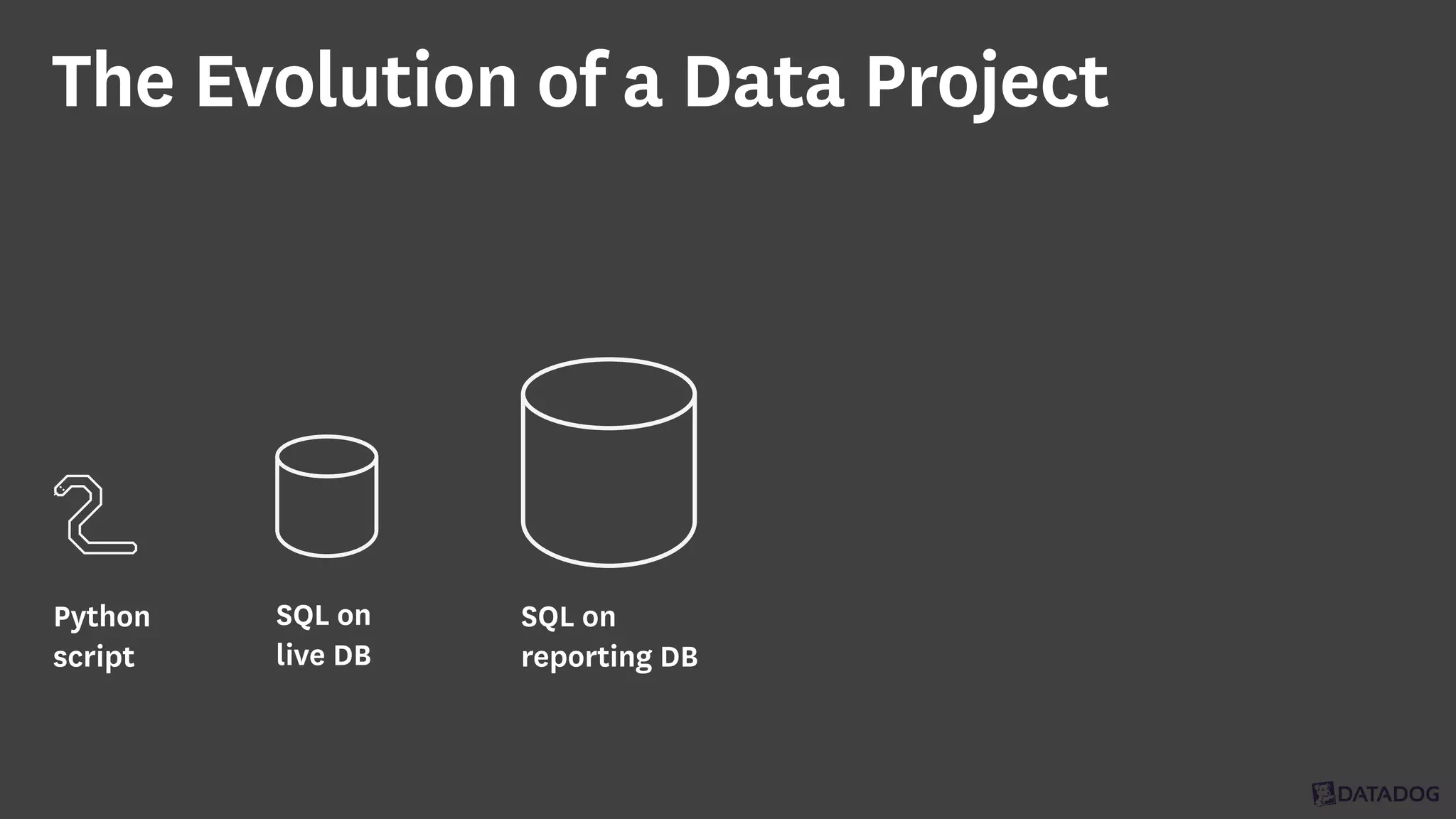
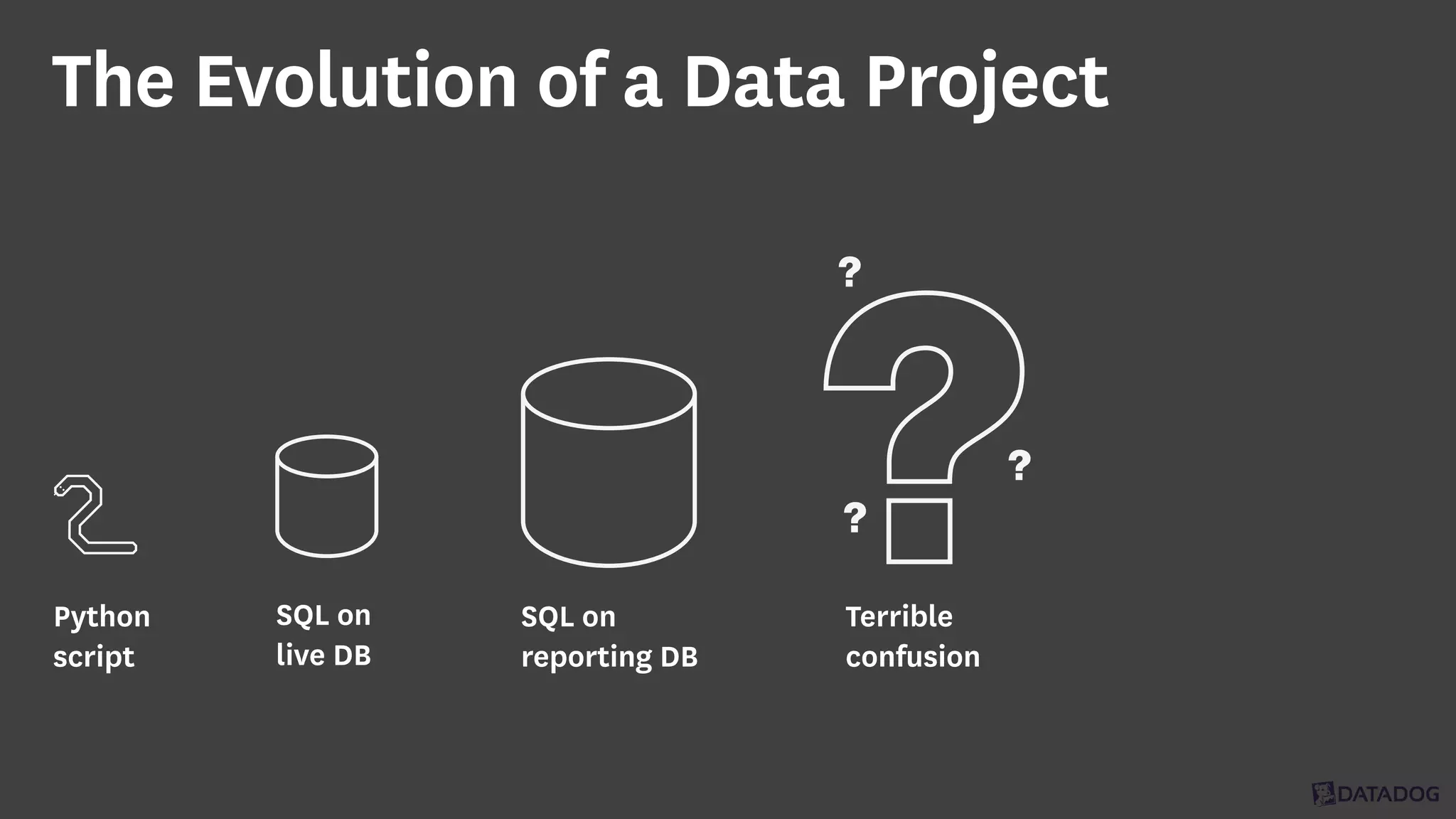
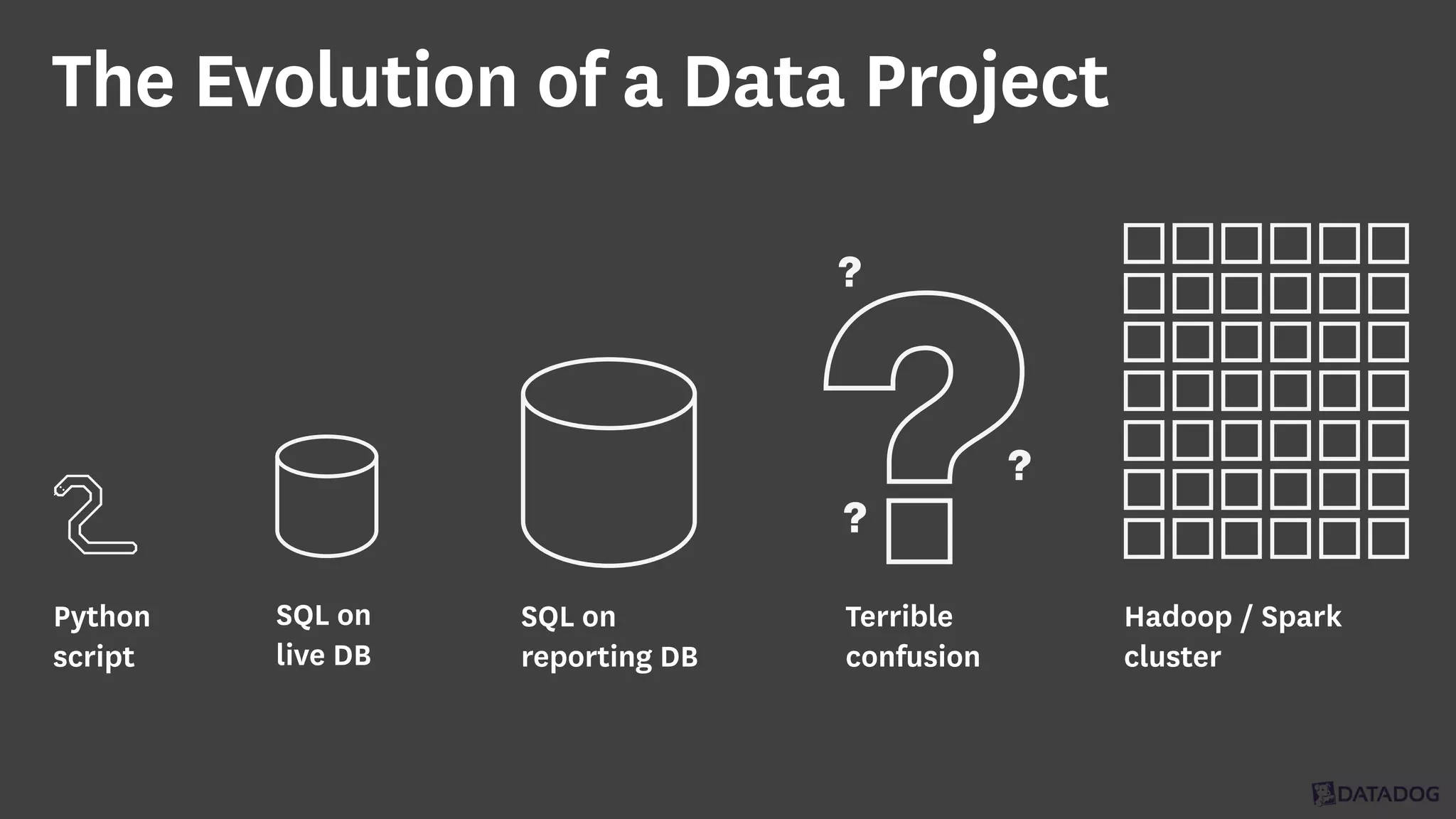






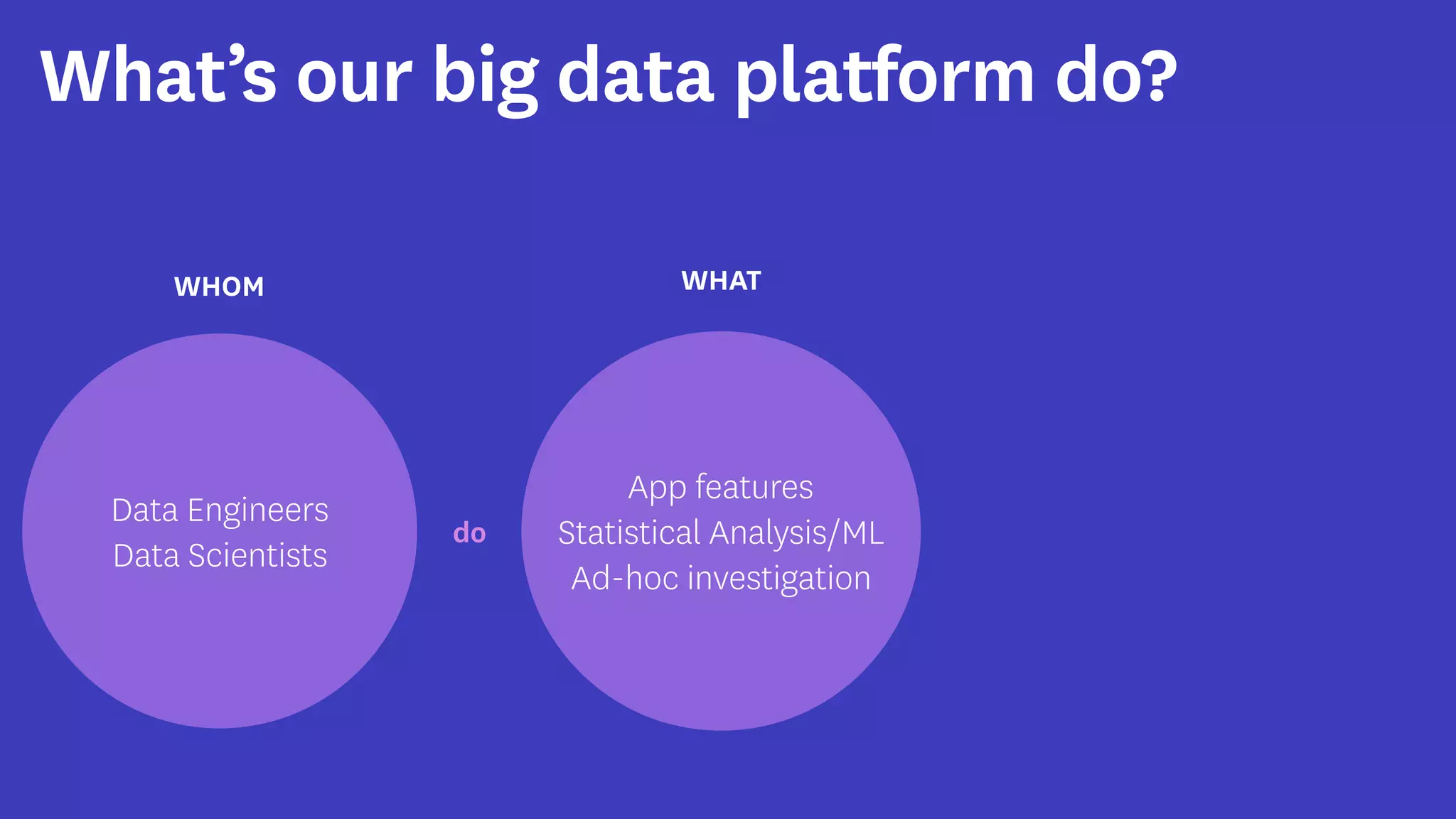
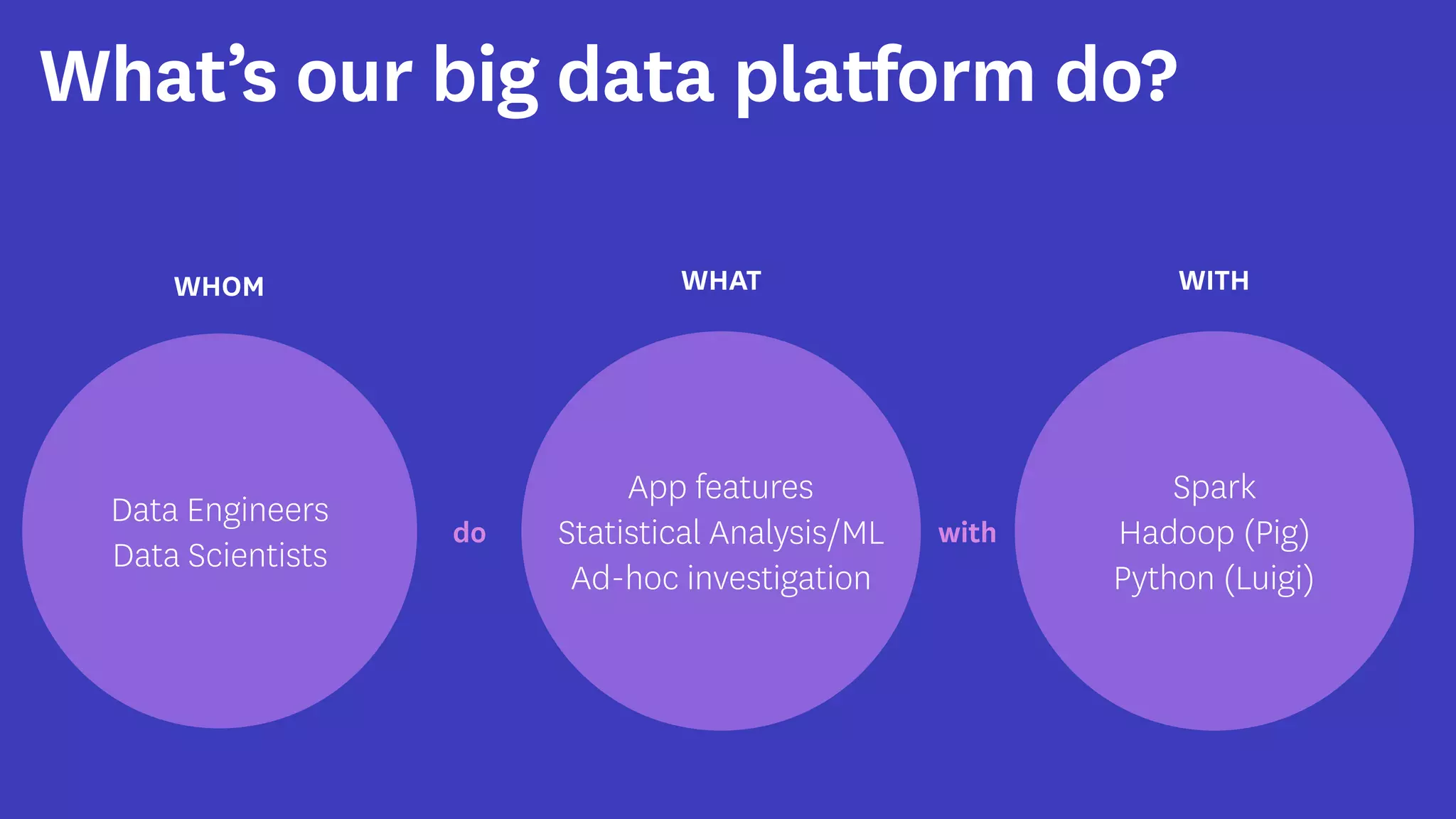
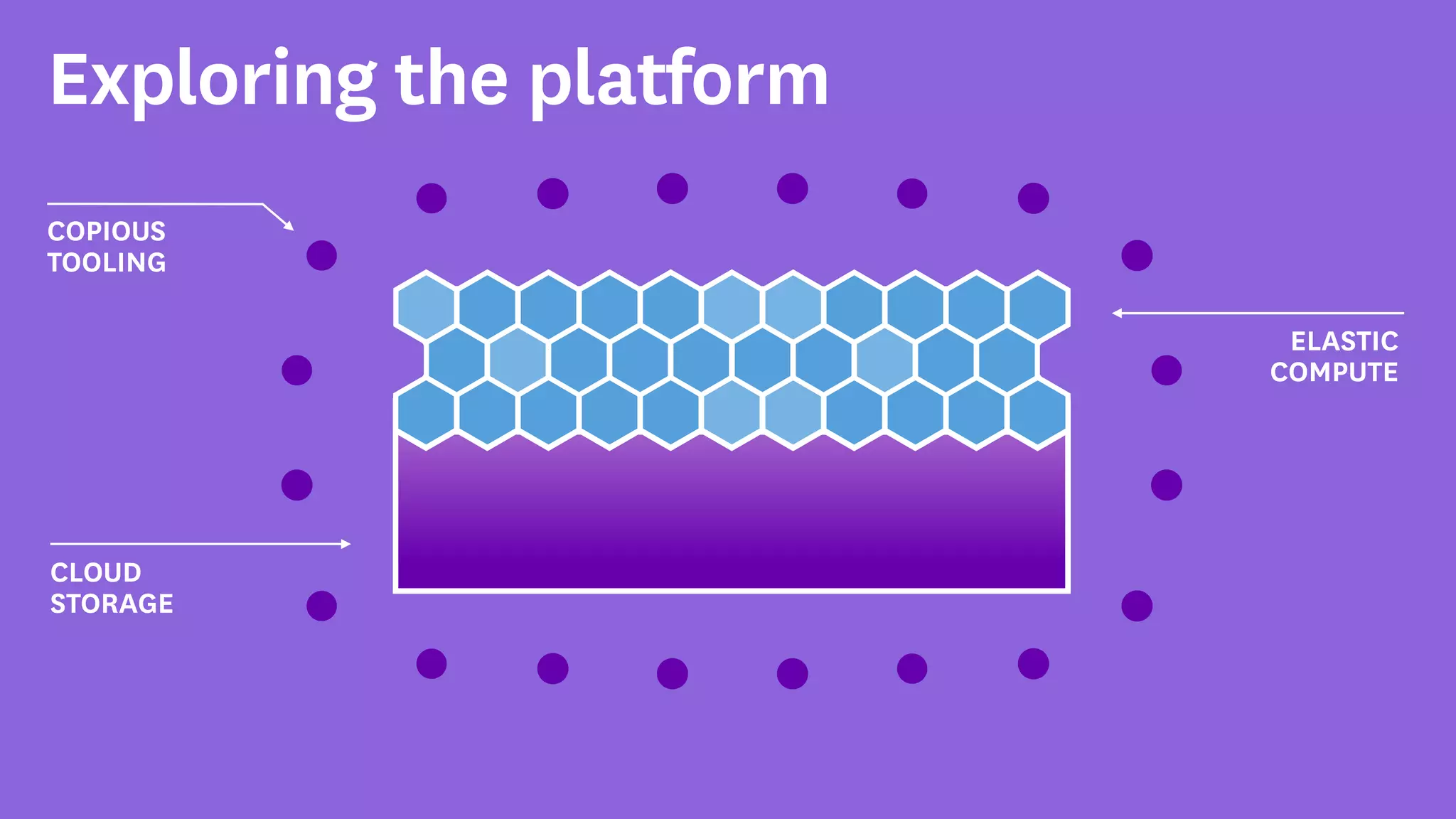




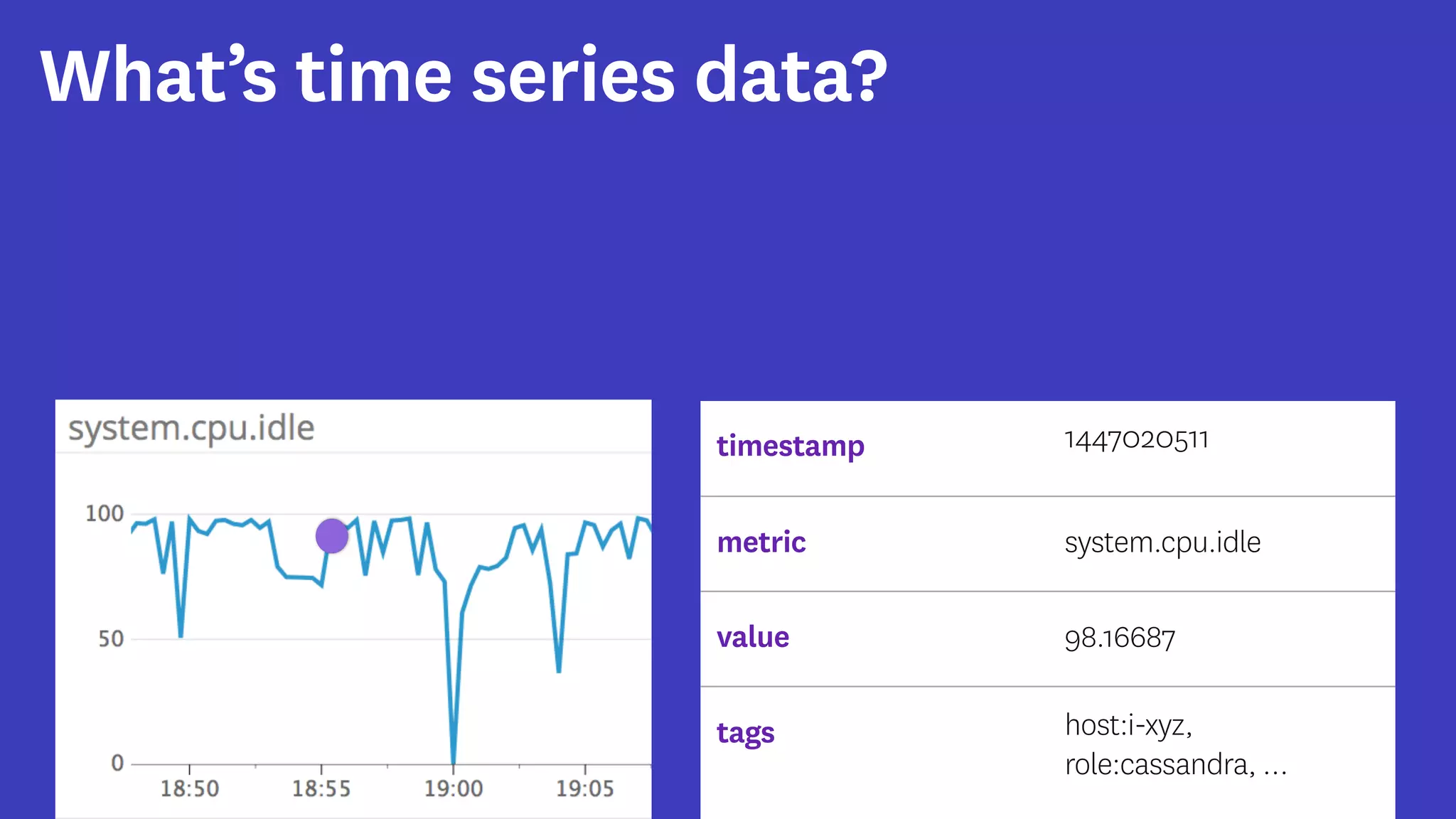


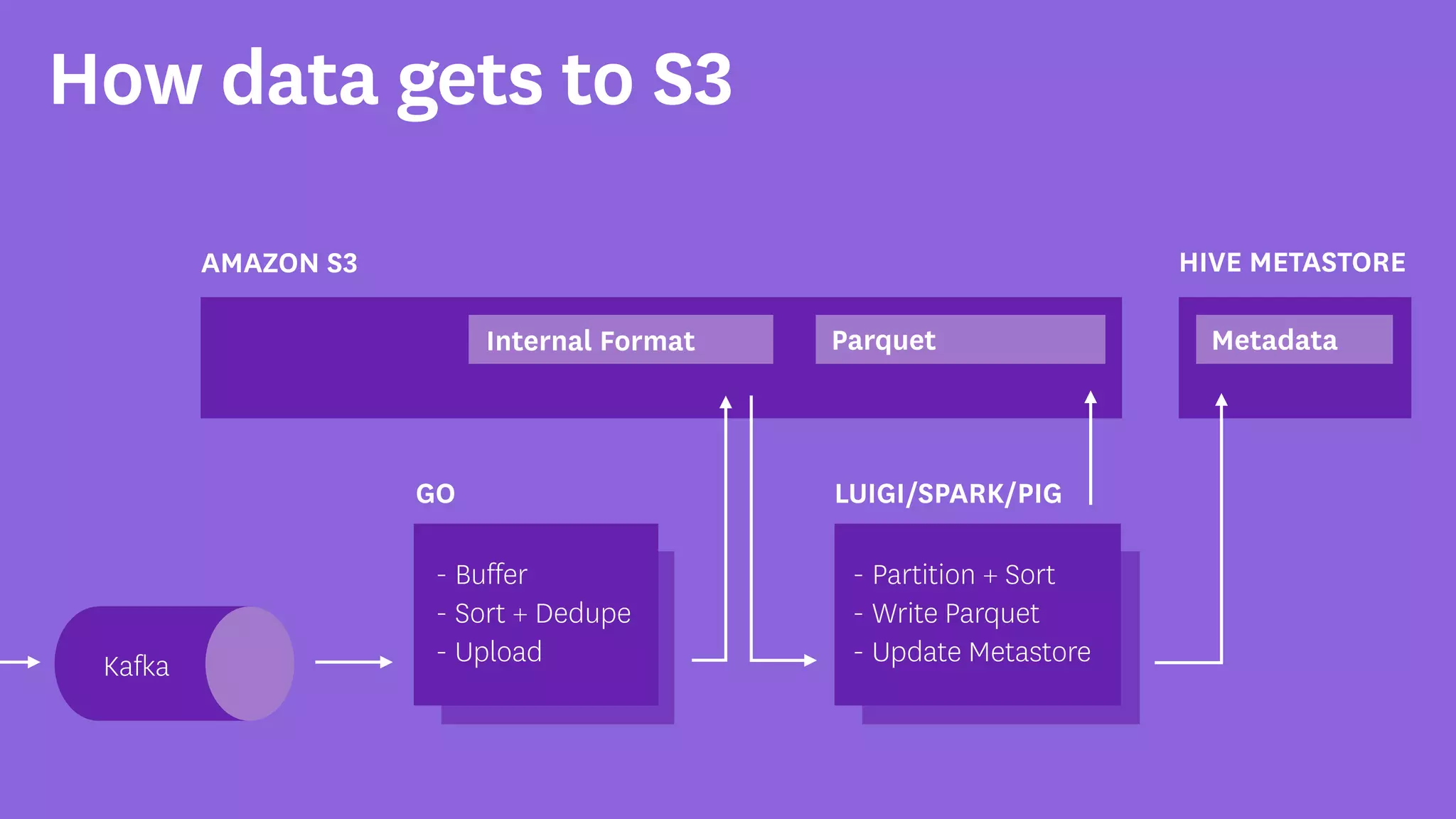





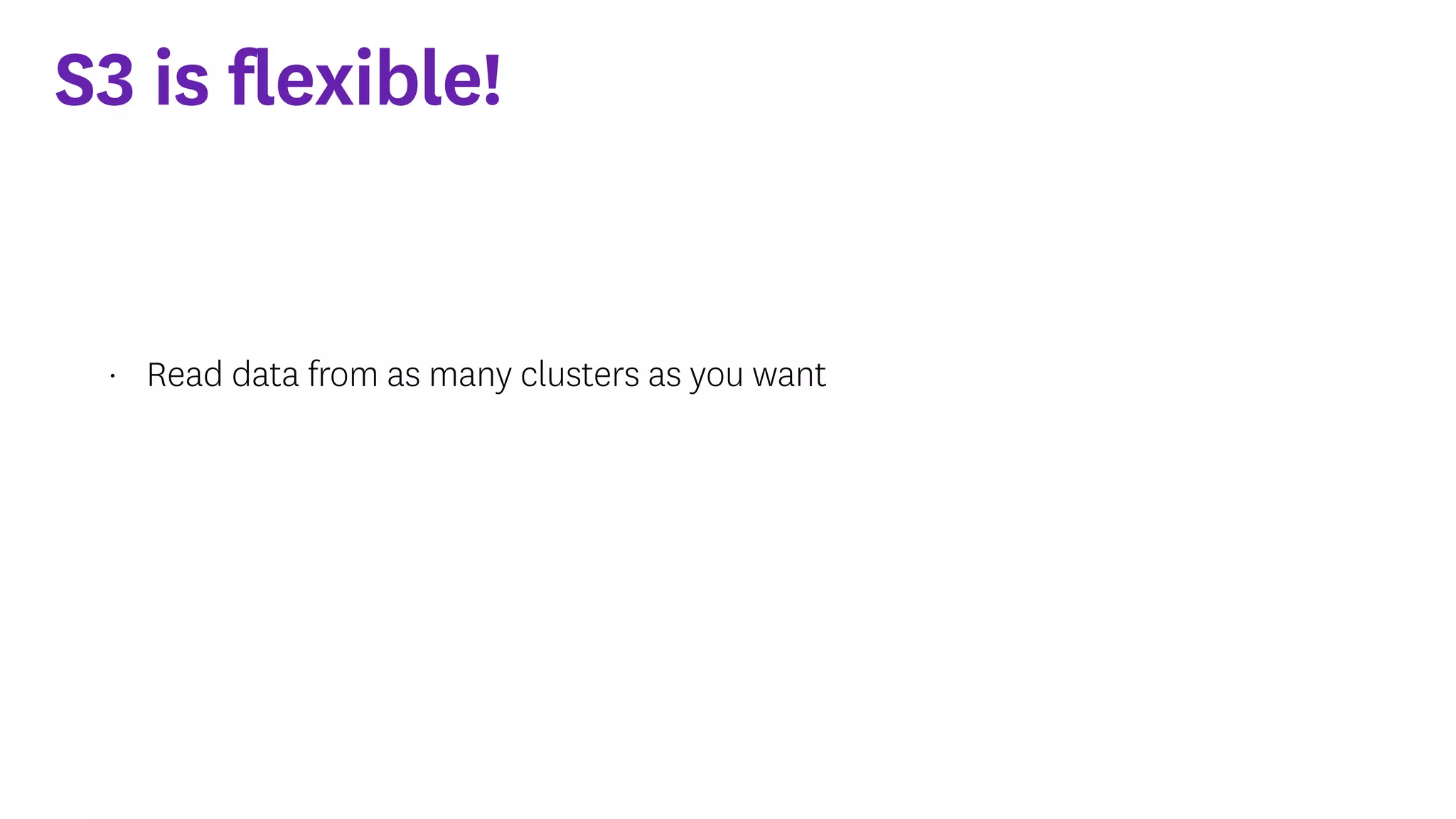
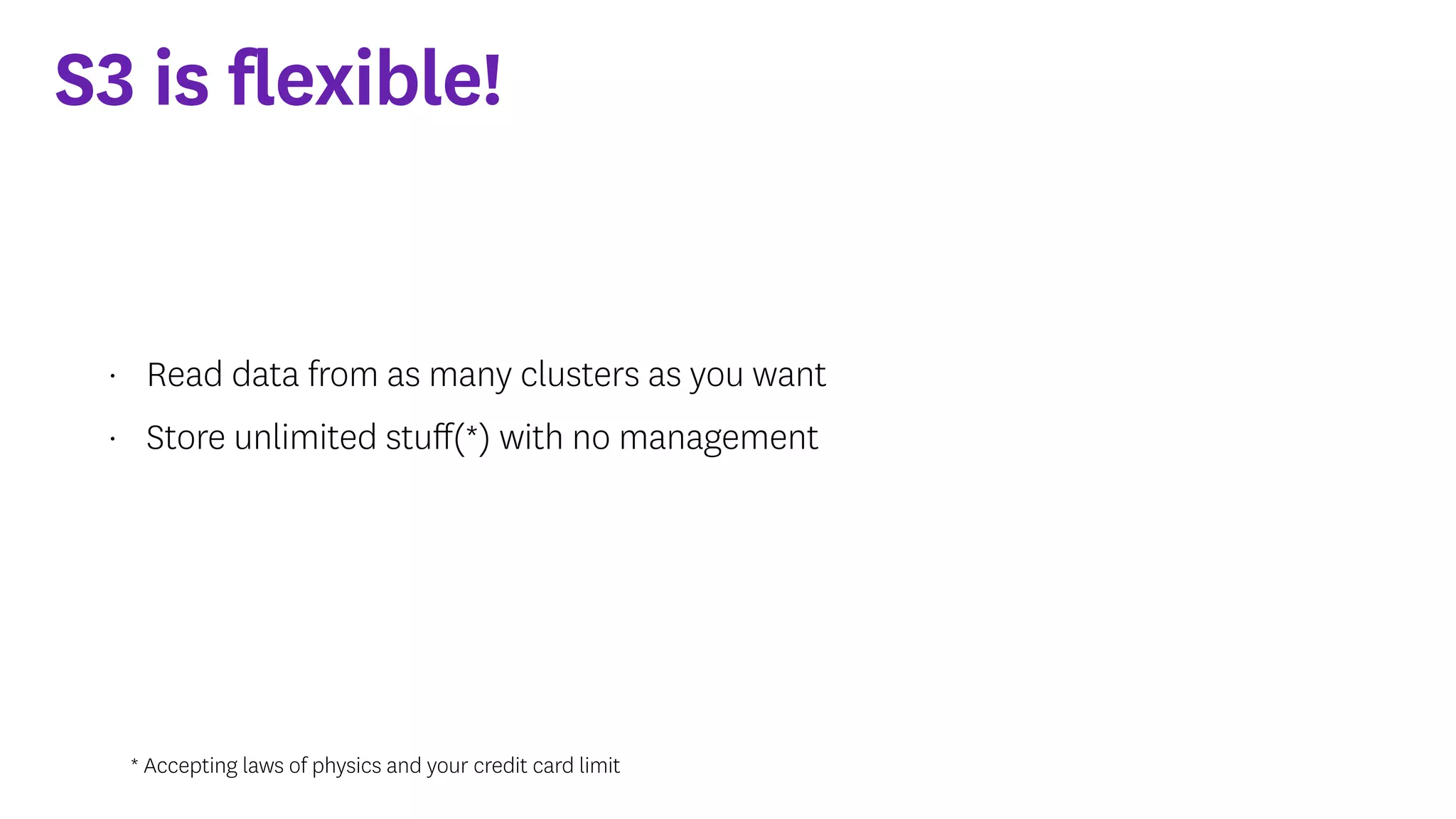
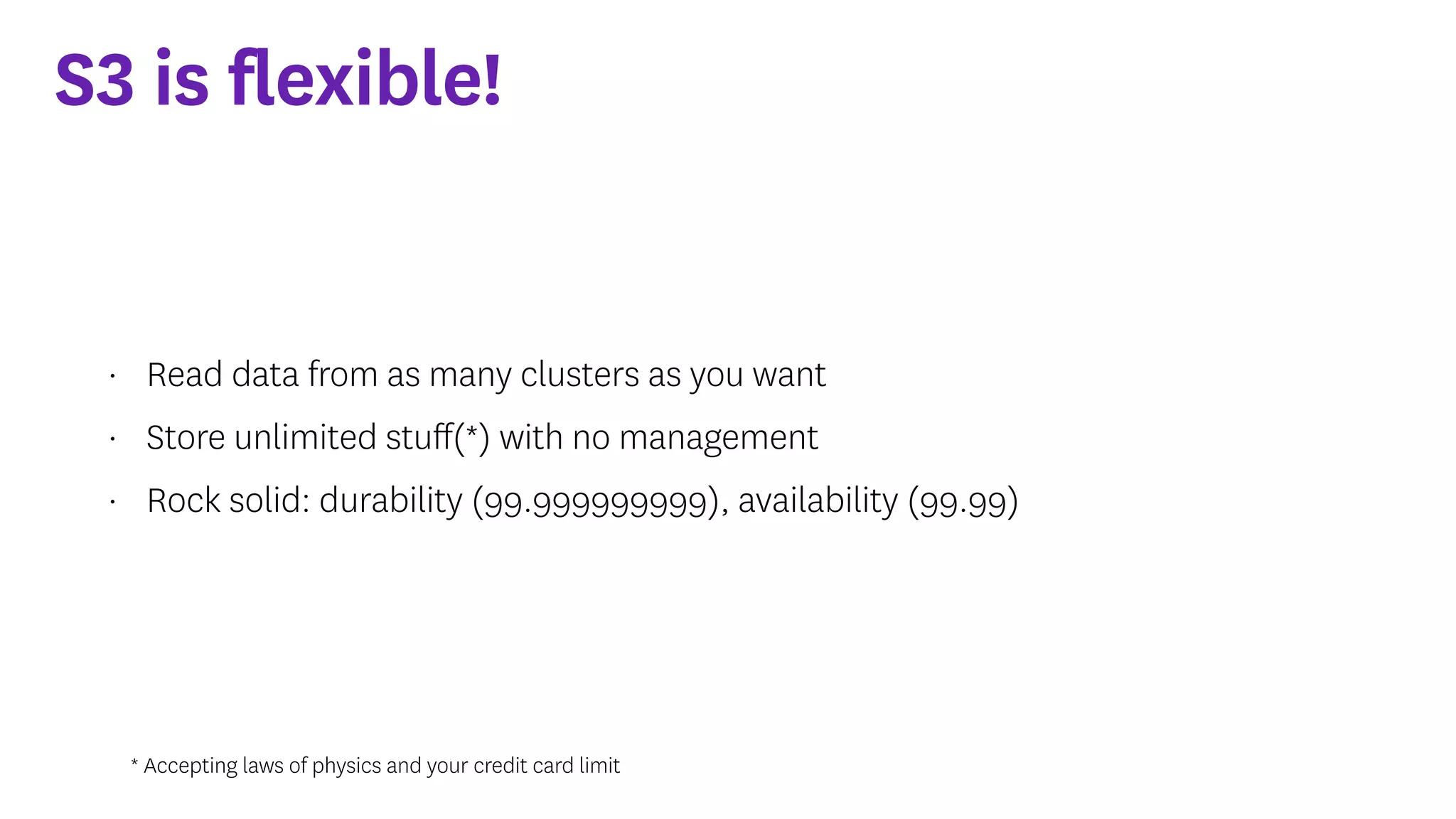










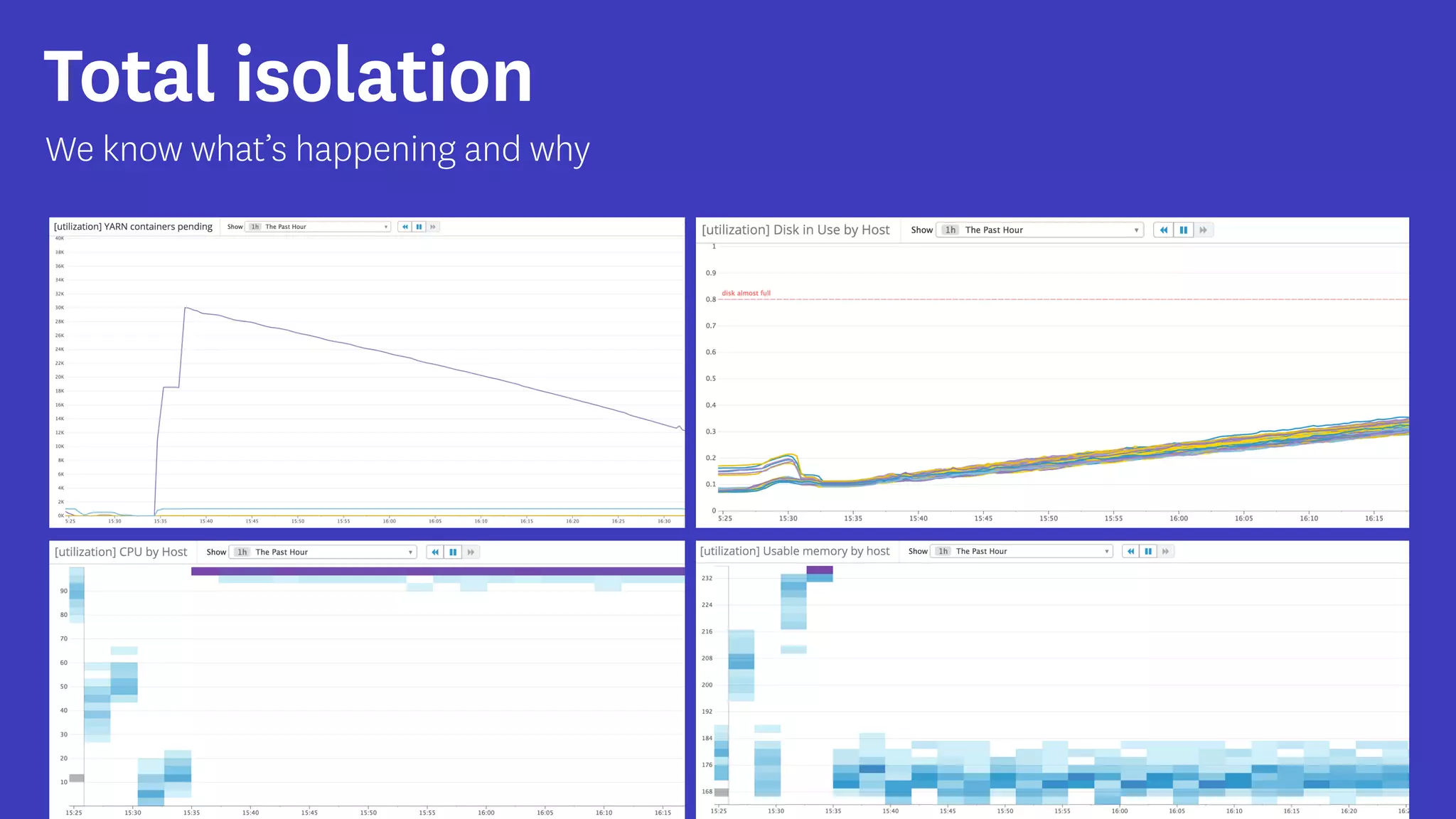

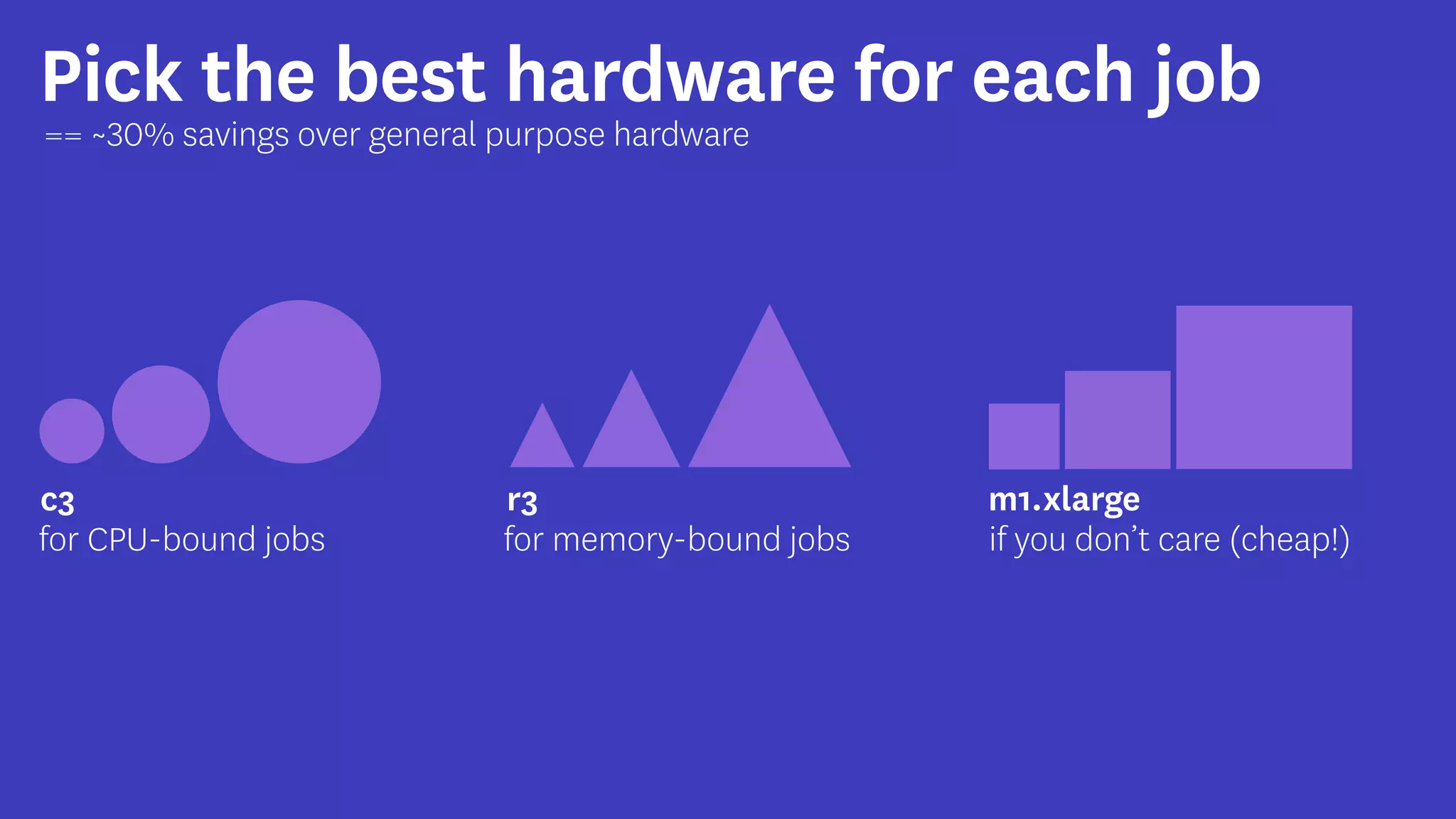


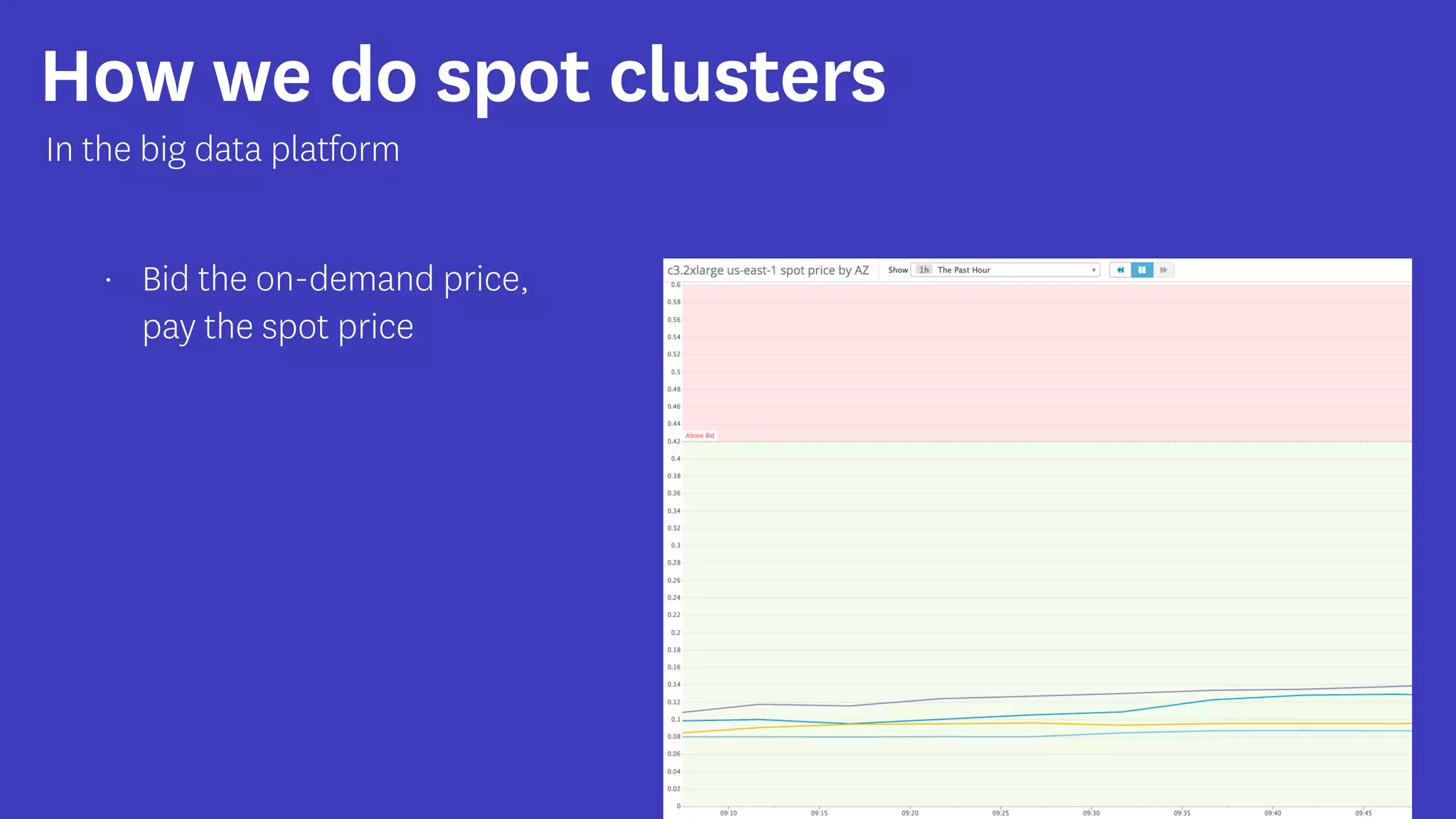
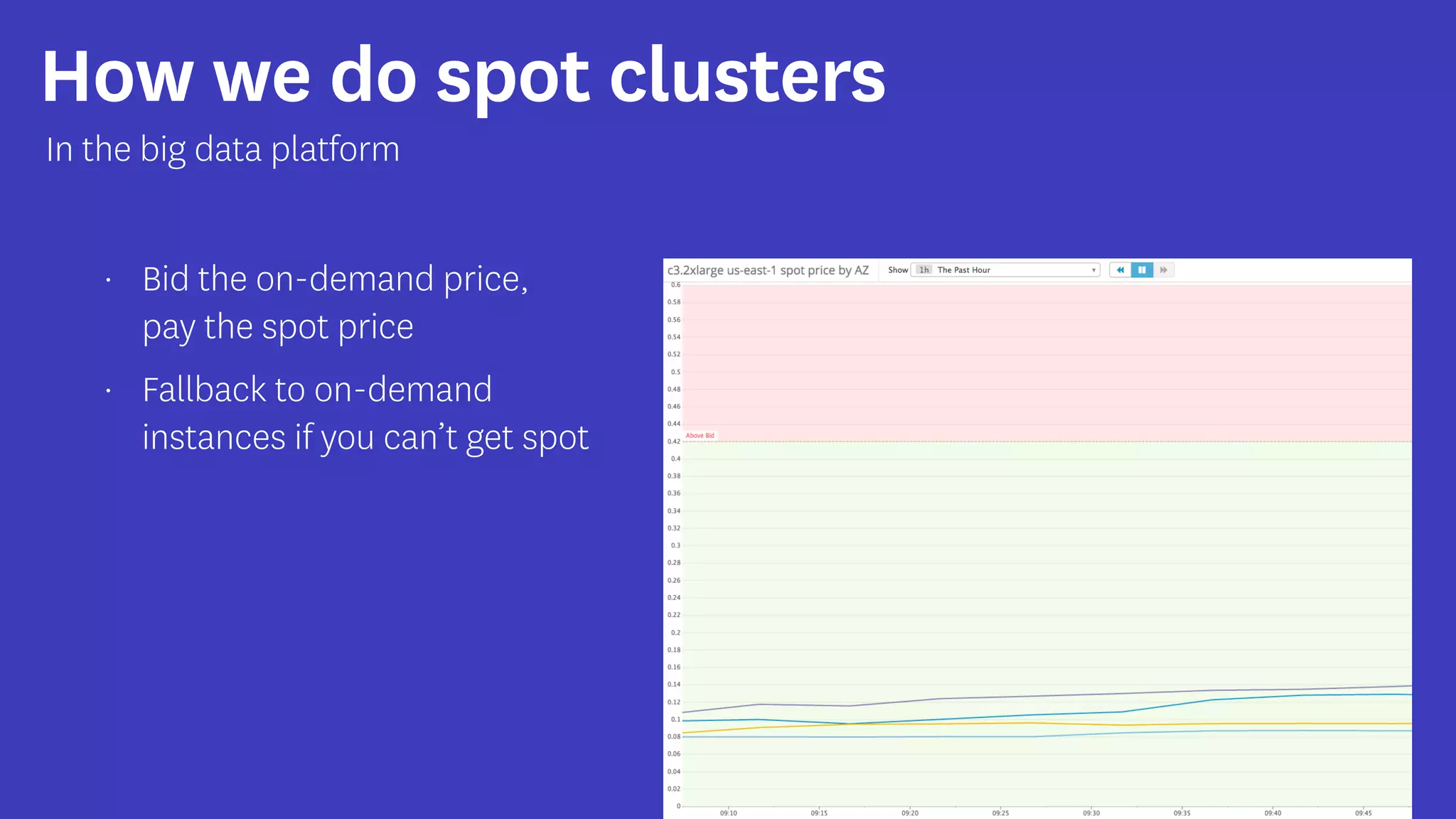
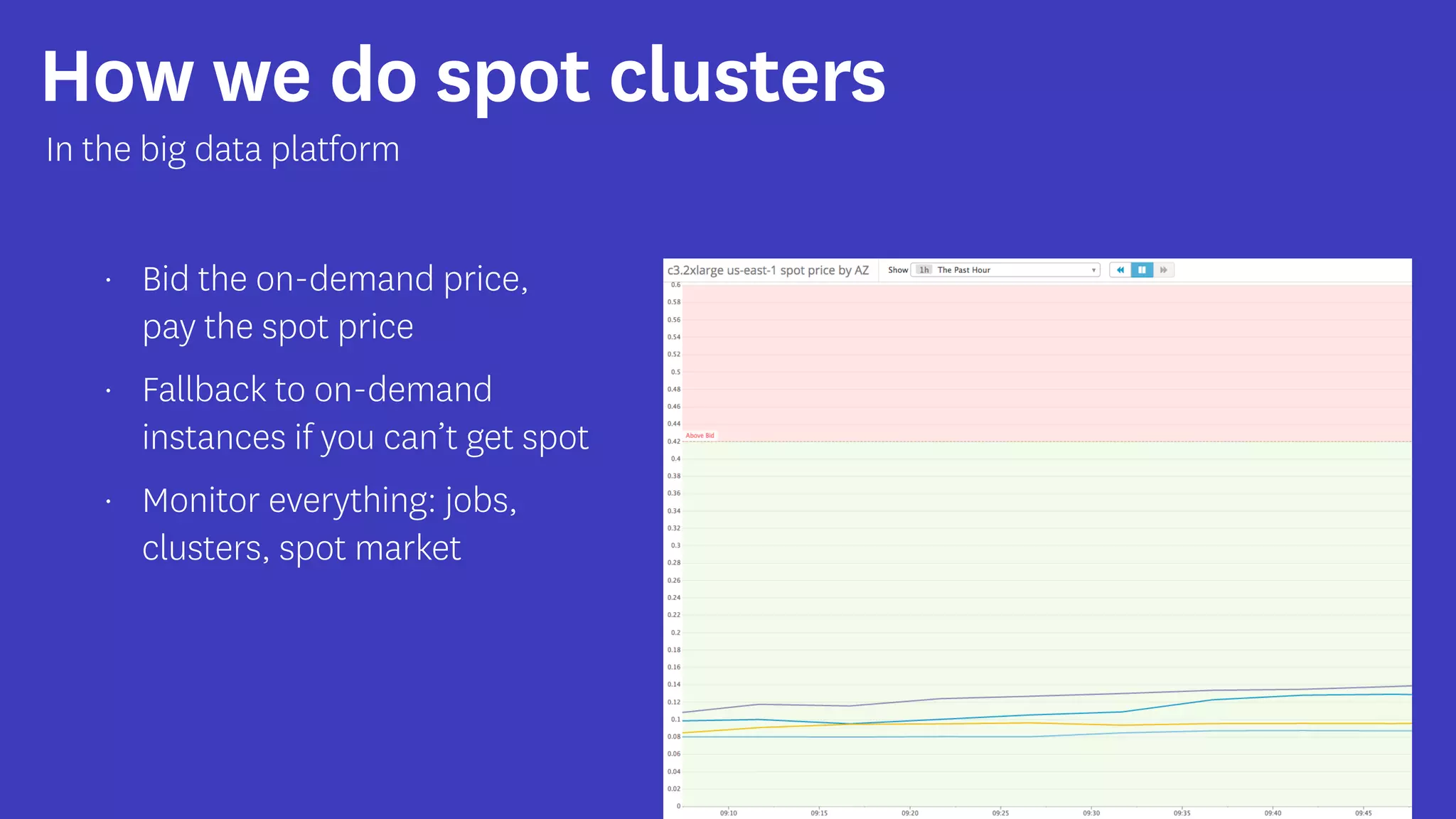
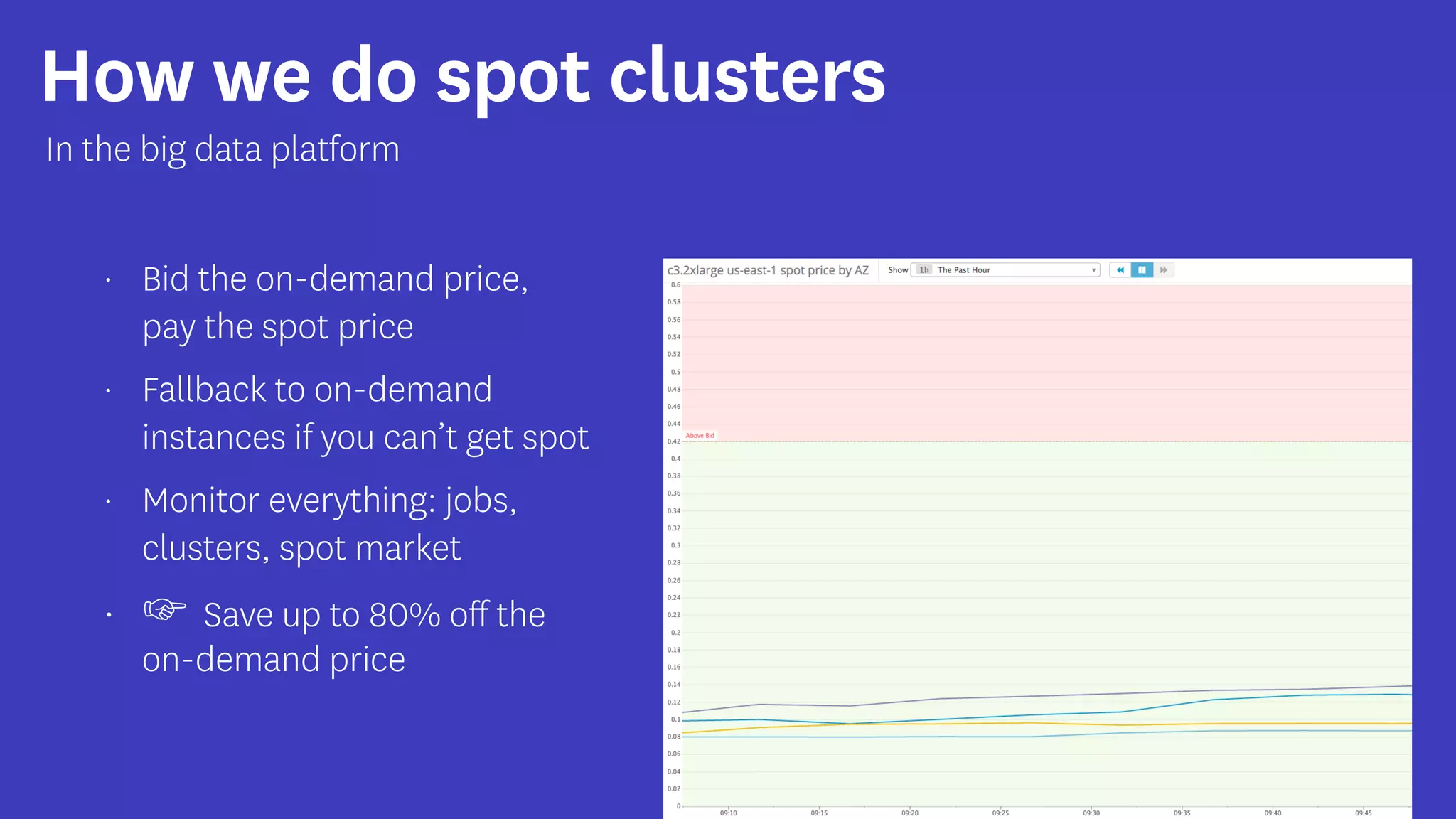
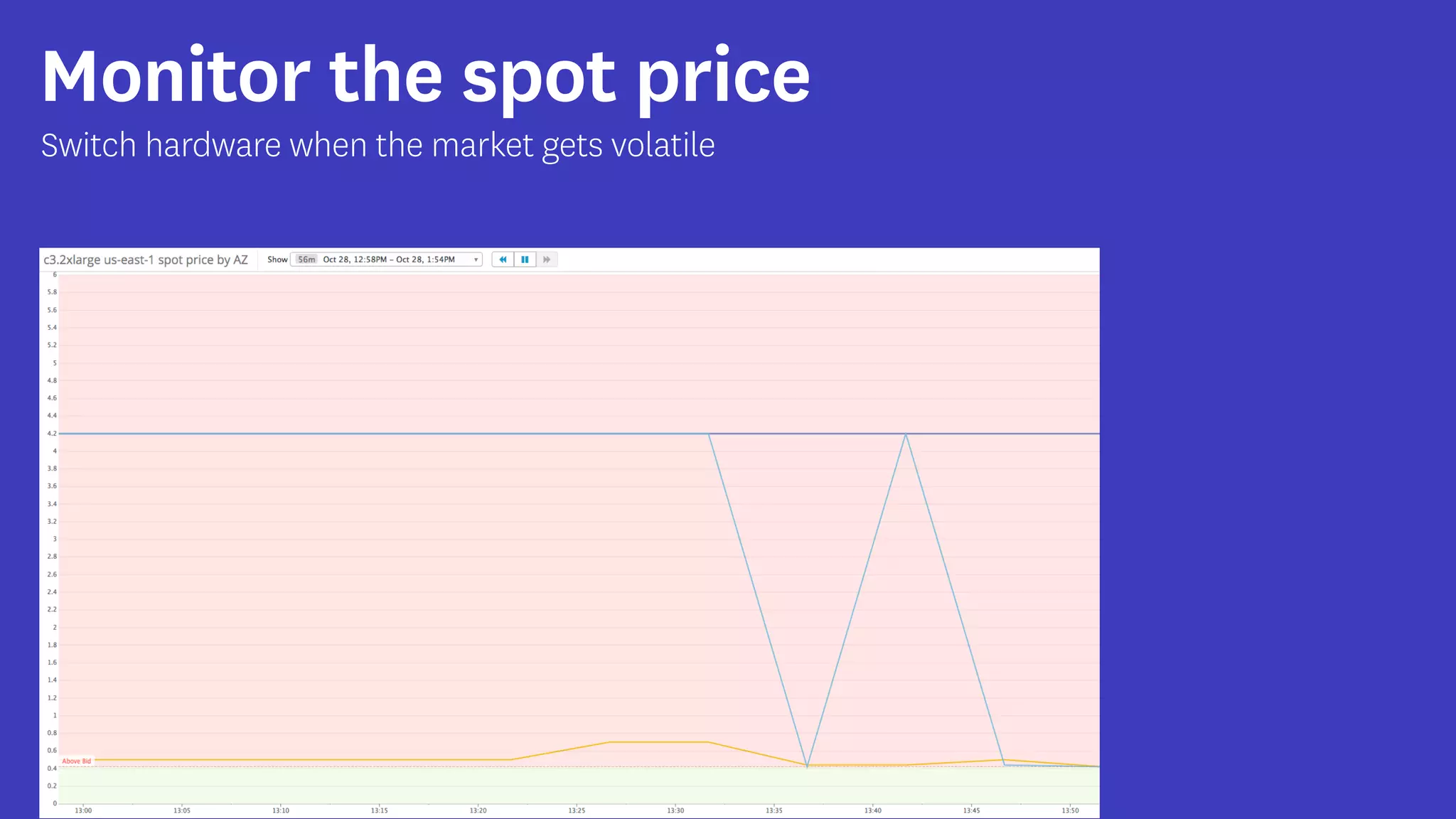



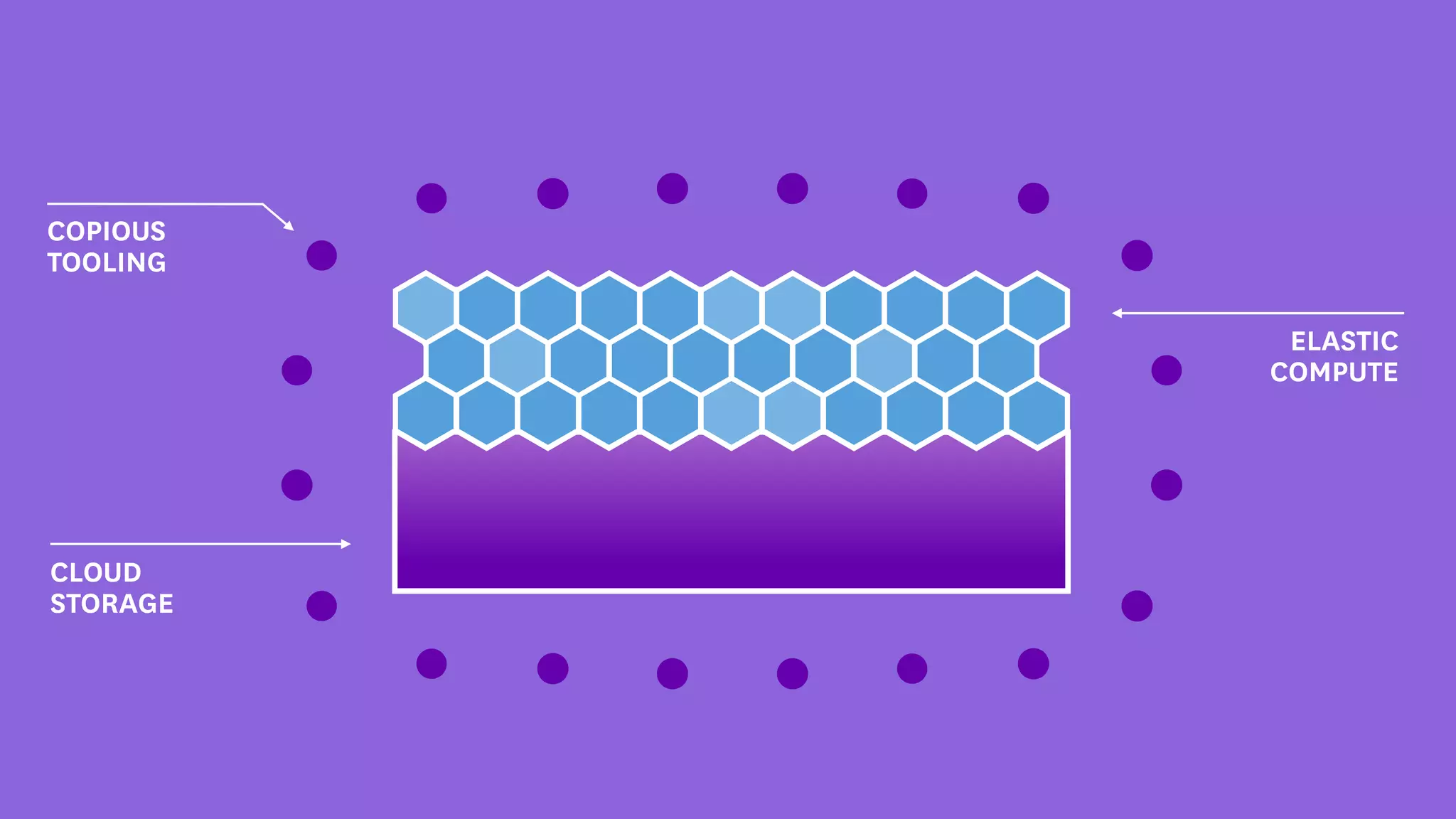
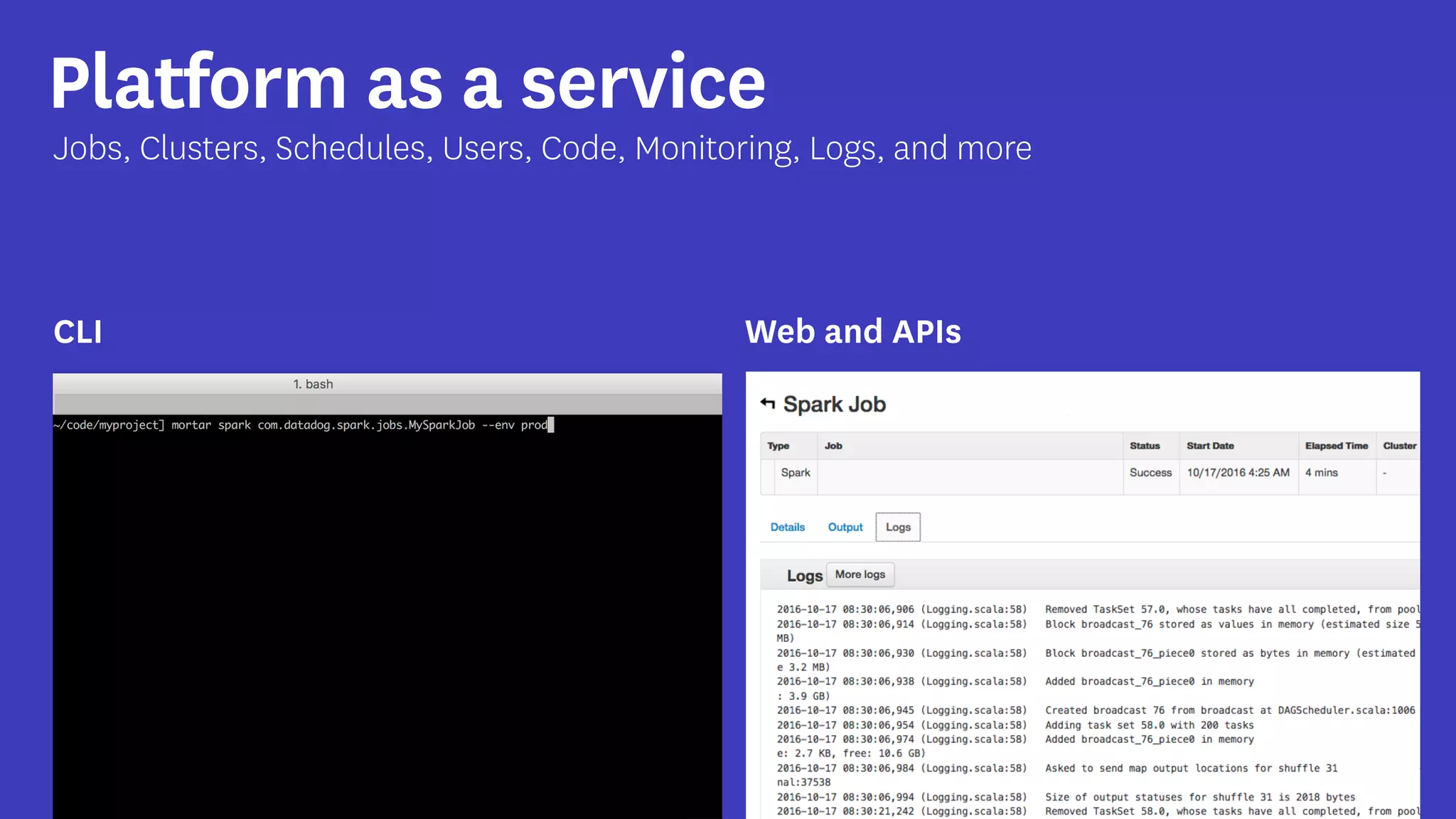








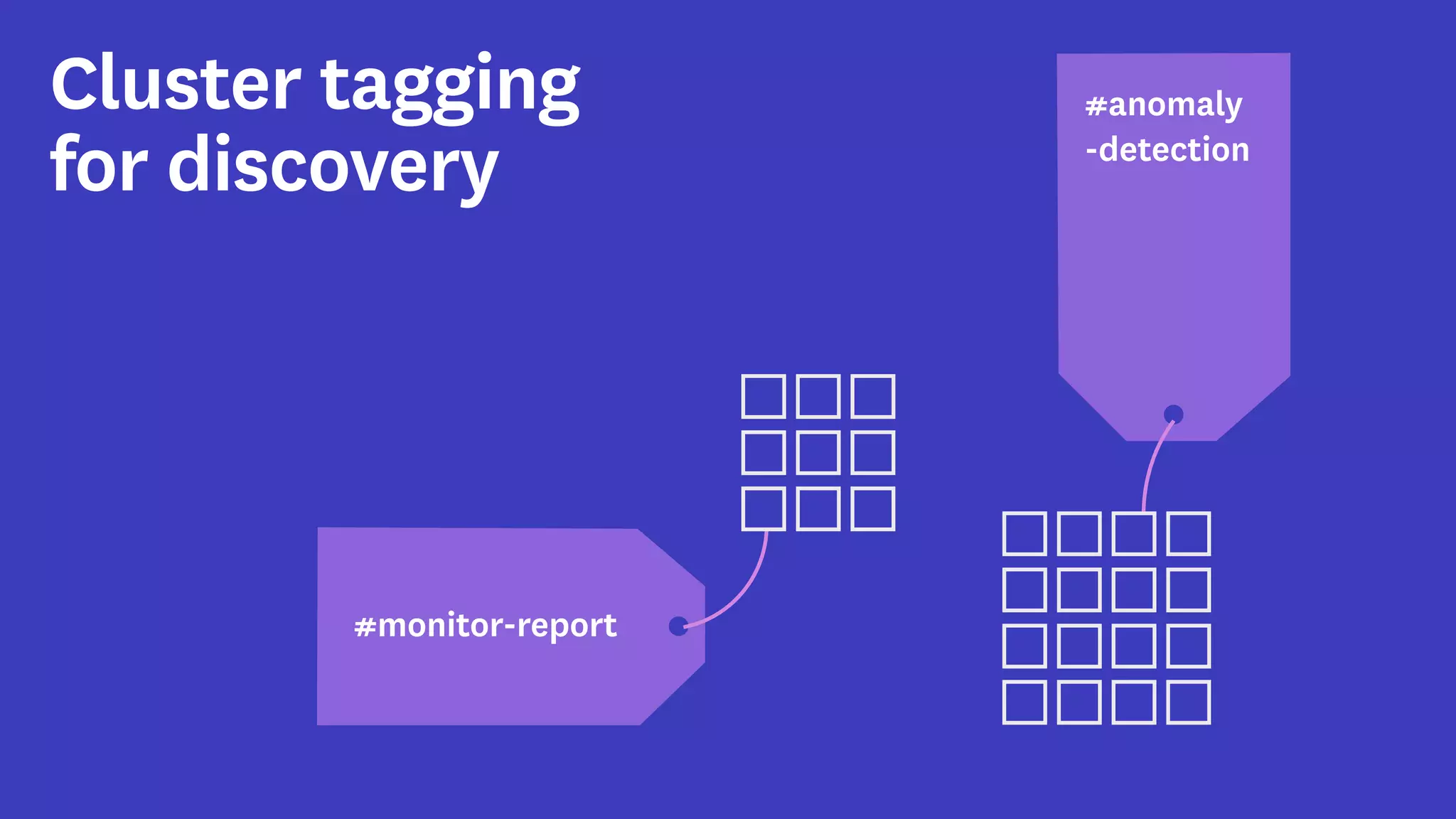

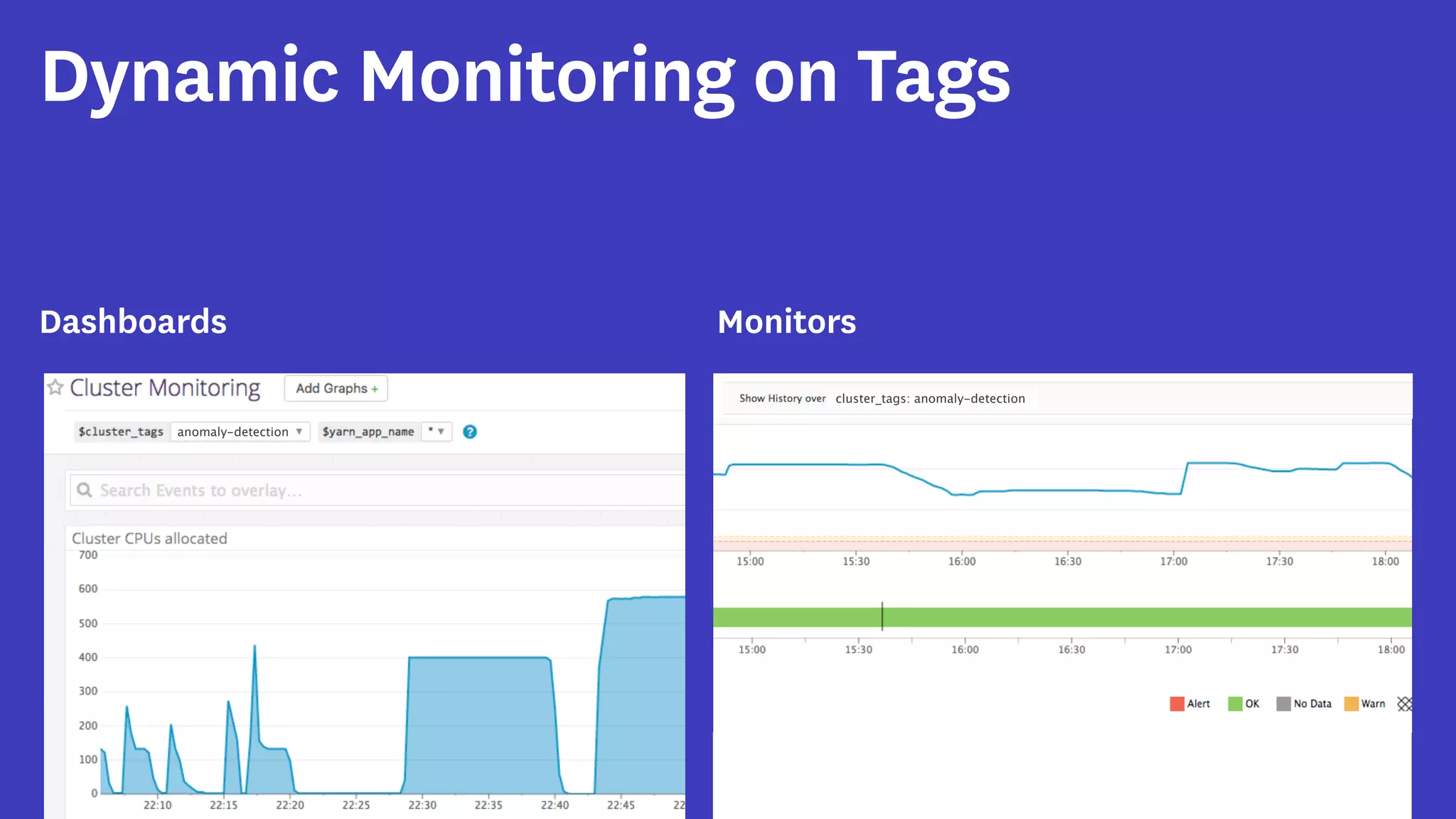







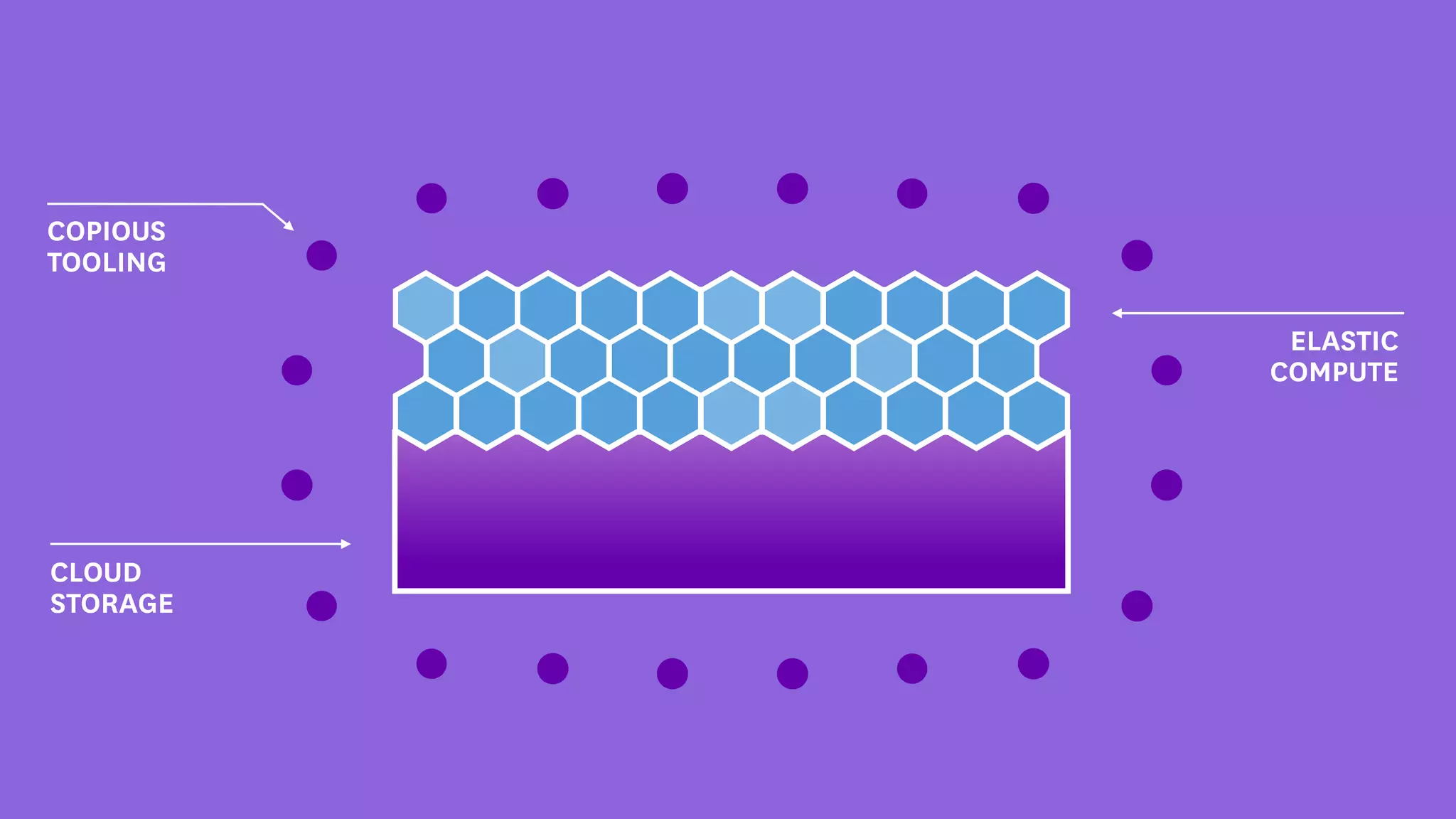








































































































InfoQ is a global community site for over a million software developers, offering resources like newsletters, podcasts, and content from QCon conferences to empower innovation in software development. It highlights the importance of data platforms, especially Amazon S3, for managing big data with flexibility and efficiency, while recommending strategies like dynamic monitoring and designing for failure. The document also emphasizes the shift towards utilizing multiple clusters for job isolation and adjusting resources according to workload demands.












































![big_data_topic2_[hadoop]_[thanh_binh_nguyen].TextMark.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/bigdatatopic2hadoopthanhbinhnguyen-250717150423-37c8b12c-thumbnail.jpg?width=640&height=640&fit=bounds)

























































