Downloaded 58 times









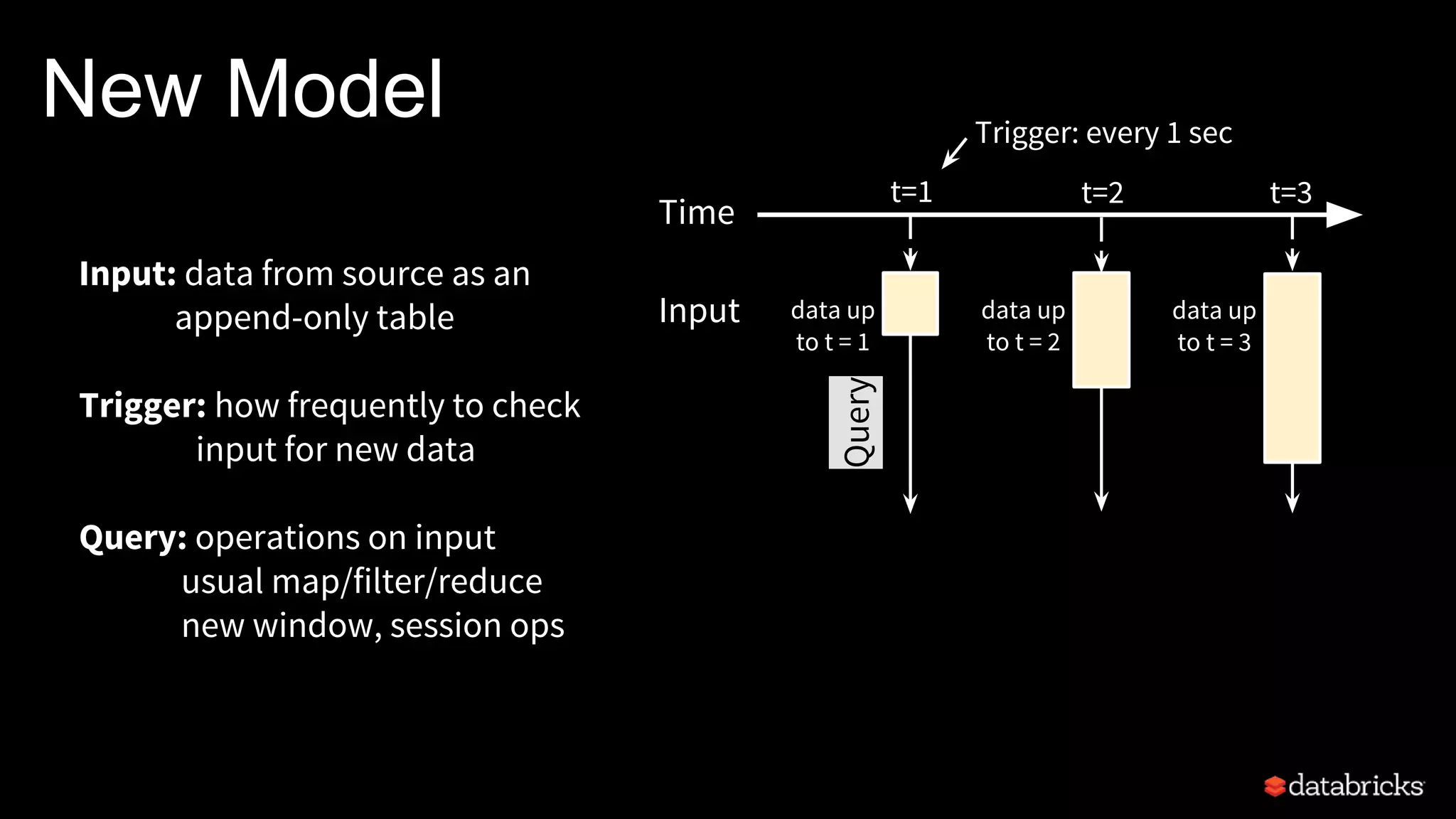
![New Model
result up
to t = 1
Result
Query
Time
data up
to t = 1
Input data up
to t = 2
result up
to t = 2
data up
to t = 3
result up
to t = 3
Result: final operated table
updated after every trigger
Output: what part of result to write
to storage after every trigger
Output
[complete mode]
write all rows in result table to storage
t=1 t=2 t=3
Complete output: write full result table every
time](https://image.slidesharecdn.com/whatsnewwithstructuredstreaming-170329132317/75/What-s-new-with-Apache-Spark-s-Structured-Streaming-13-2048.jpg)
![New Model
Query
Time
data up
to t = 1
Input data up
to t = 2
data up
to t = 3
Result: final operated table
updated after every trigger
Output: what part of result to write
to storage after every trigger
Complete output: write full result table every
time
Append output: write only new rows that got
added to result table since previous batch
t=1 t=2 t=3
Result result
up to t =
3
Output
[append mode] write new rows since last trigger to storage
result
up to t =
1
result
up to t =
2](https://image.slidesharecdn.com/whatsnewwithstructuredstreaming-170329132317/75/What-s-new-with-Apache-Spark-s-Structured-Streaming-14-2048.jpg)



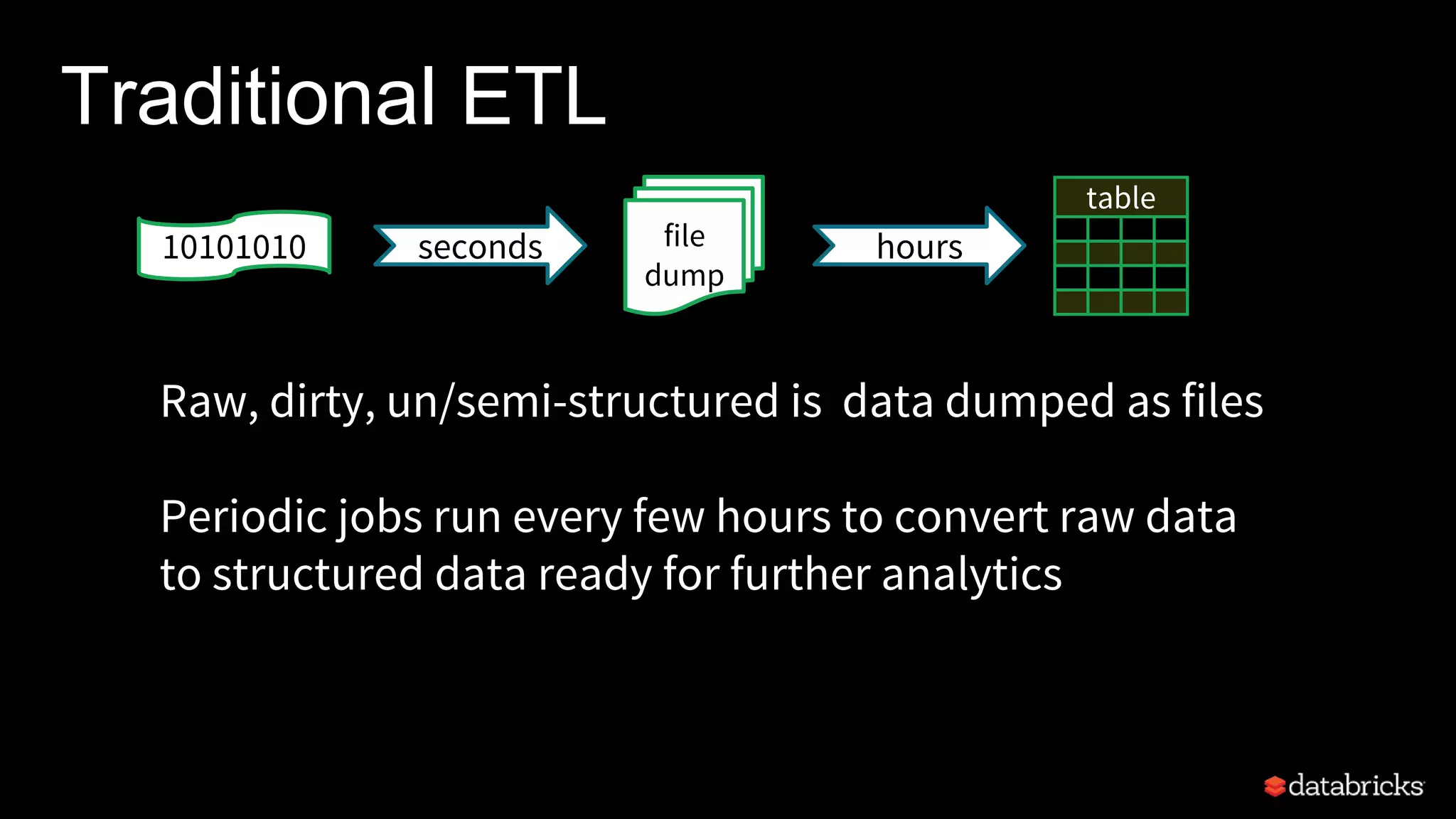
![Traditional ETL
Hours of delay before taking decisions on latest data
Unacceptable when time is of essence
[intrusion detection, anomaly detection, etc.]
file
dump
seconds hours
table
10101010](https://image.slidesharecdn.com/whatsnewwithstructuredstreaming-170329132317/75/What-s-new-with-Apache-Spark-s-Structured-Streaming-22-2048.jpg)

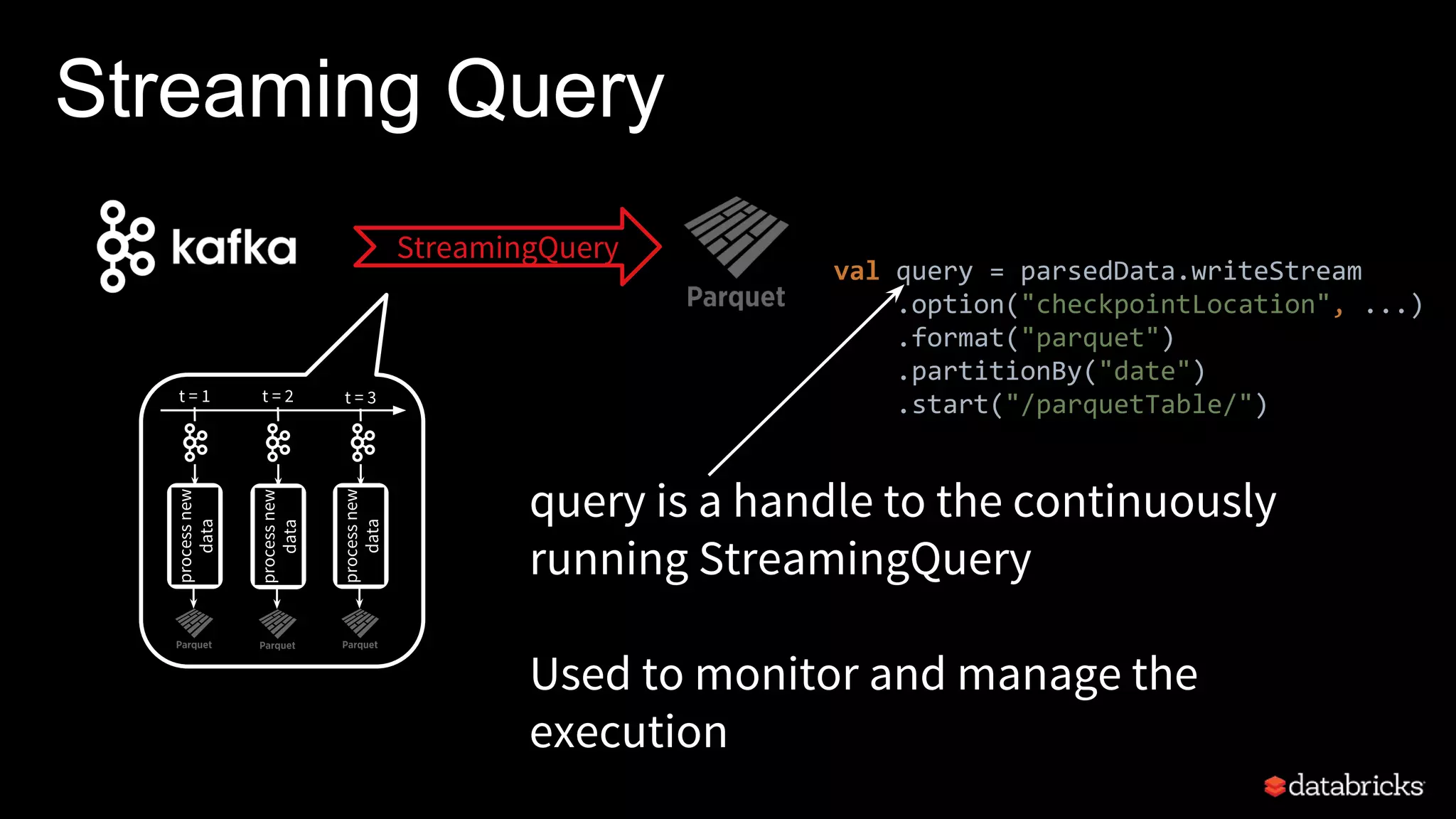
![Reading from Kafka [Spark 2.1]
Support Kafka 0.10.0.1
Specify options to configure
How?
kafka.boostrap.servers => broker1
What?
subscribe => topic1,topic2,topic3 // fixed list of topics
subscribePattern => topic* // dynamic list of topics
assign => {"topicA":[0,1] } // specific partitions
Where?
startingOffsets => latest(default)
/ earliest / {"topicA":{"0":23,"1":345} }
val rawData = spark.readStream
.format("kafka")
.option("kafka.boostrap.servers",...)
.option("subscribe", "topic")
.load()](https://image.slidesharecdn.com/whatsnewwithstructuredstreaming-170329132317/75/What-s-new-with-Apache-Spark-s-Structured-Streaming-25-2048.jpg)
![Reading from Kafka
rawData dataframe has
the following columns
key value topic partition offset timestamp
[binary] [binary] "topicA" 0 345 1486087873
[binary] [binary] "topicB" 3 2890 1486086721
val rawData = spark.readStream
.format("kafka")
.option("subscribe", "topic")
.option("kafka.boostrap.servers",...)
.load()](https://image.slidesharecdn.com/whatsnewwithstructuredstreaming-170329132317/75/What-s-new-with-Apache-Spark-s-Structured-Streaming-26-2048.jpg)

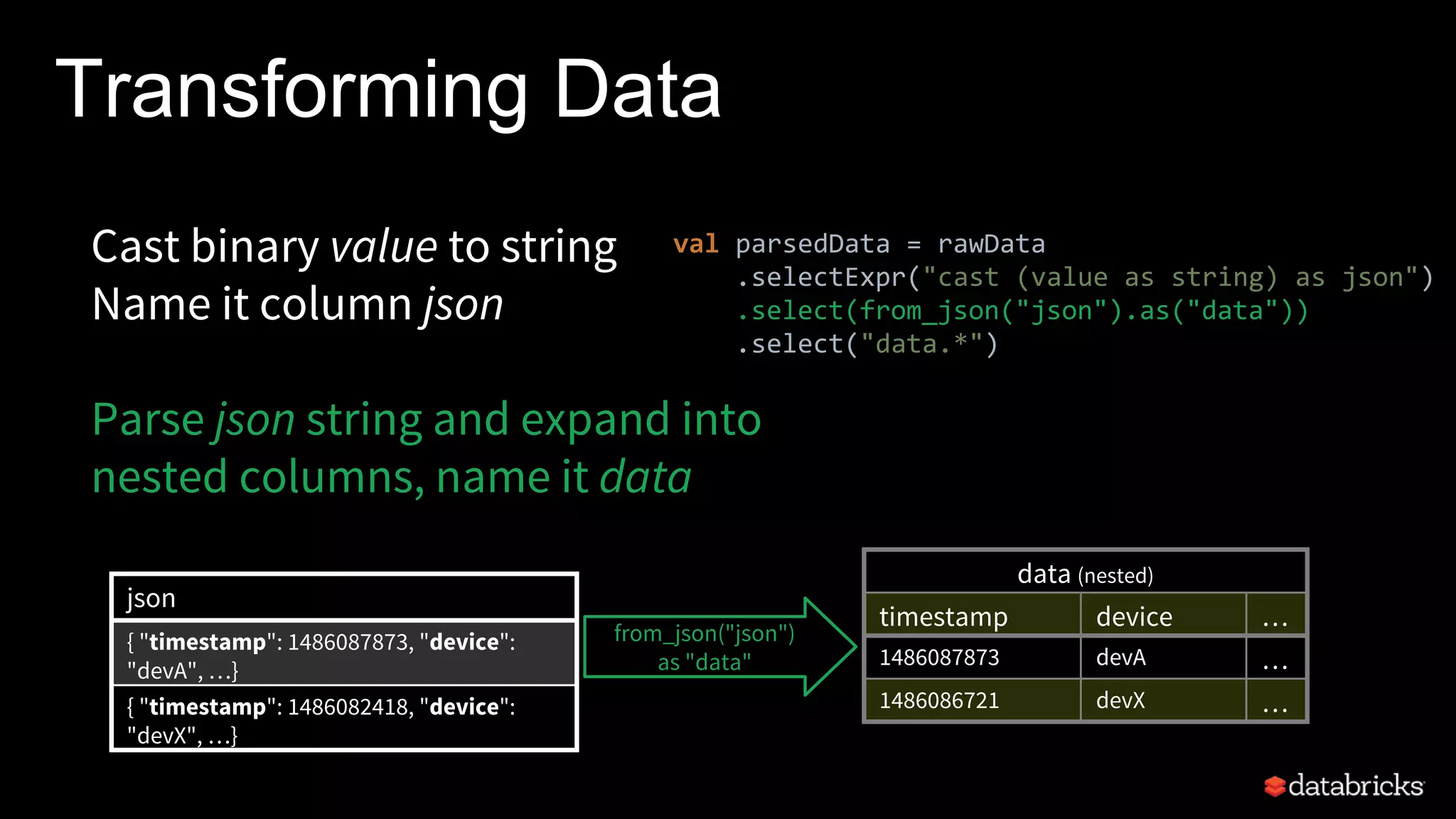








![Watermarking and Late Data
Watermark [Spark 2.1] - threshold
on how late an event is expected
to be in event time
Trails behind max seen event time
Trailing gap is configurable
event time
max event
time
watermark data older
than
watermark
not expected
12:30 PM
12:20 PM
trailing gap
of 10 mins](https://image.slidesharecdn.com/whatsnewwithstructuredstreaming-170329132317/75/What-s-new-with-Apache-Spark-s-Structured-Streaming-39-2048.jpg)


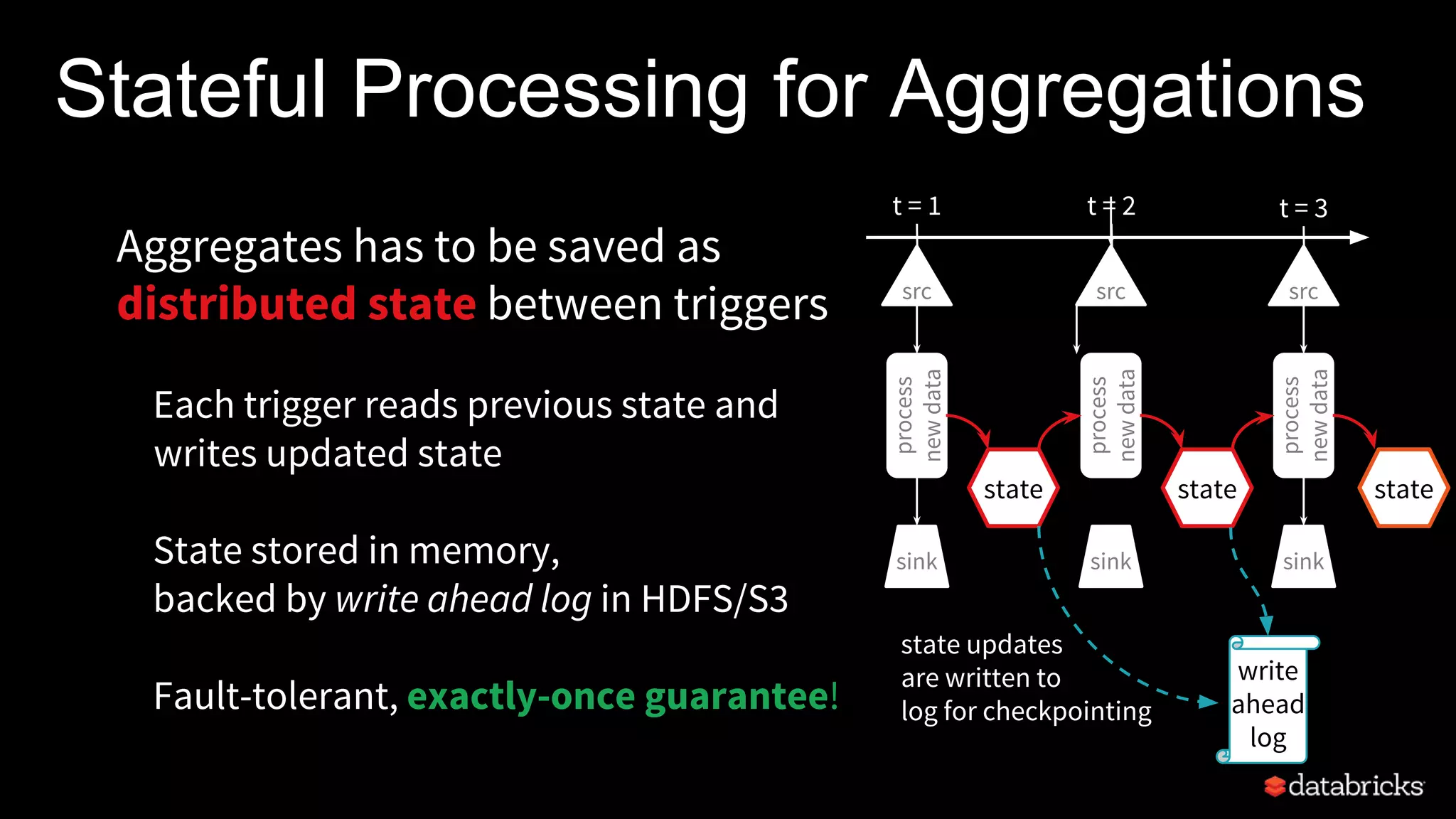
![Watermarking to Limit State [Spark 2.1]
data too late,
ignored in counts,
state dropped
Processing Time12:00
12:05
12:10
12:15
12:10 12:15
12:20
12:07
12:13
12:08
EventTime
12:15
12:18
12:04
watermark updated to
12:14 - 10m = 12:04
for next trigger,
state < 12:04 deleted
data is late, but
considered in counts
parsedData
.withWatermark("timestamp", "10 minutes")
.groupBy(window("timestamp","5 minutes"))
.count()
system tracks max
observed event time
12:08
wm = 12:04
10min
12:14
more details in online
programming guide](https://image.slidesharecdn.com/whatsnewwithstructuredstreaming-170329132317/75/What-s-new-with-Apache-Spark-s-Structured-Streaming-42-2048.jpg)
![mapGroupsWithState
allows any user-defined
stateful ops to a
user-defined state
--
supports timeouts
--
fault-tolerant,
exactly-once
--
supports Scala and Java
Arbitrary Stateful Operations [Spark 2.2]
dataset
.groupByKey(groupingFunc)
.mapGroupsWithState(mappingFunc)
def mappingFunc(
key: K,
values: Iterator[V],
state: KeyedState[S]): U = {
// update or remove state
// set timeouts
// return mapped value
}](https://image.slidesharecdn.com/whatsnewwithstructuredstreaming-170329132317/75/What-s-new-with-Apache-Spark-s-Structured-Streaming-43-2048.jpg)
![Many more updates!
StreamingQueryListener [Spark 2.1]
Receive of regular progress heartbeats for health and perf monitoring
Automatic in Databricks, come to the Databricks booth for a demo!!
Kafka Batch Queries [Spark 2.2]
Run batch queries on Kafka just like a file system
Kafka Sink [Spark 2.2]
Write to Kafka, can only give at-least-once guarantee as
Kafka doesn't support transactional updates
Kinesis Source
Read from Amazon Kinesis
44](https://image.slidesharecdn.com/whatsnewwithstructuredstreaming-170329132317/75/What-s-new-with-Apache-Spark-s-Structured-Streaming-44-2048.jpg)



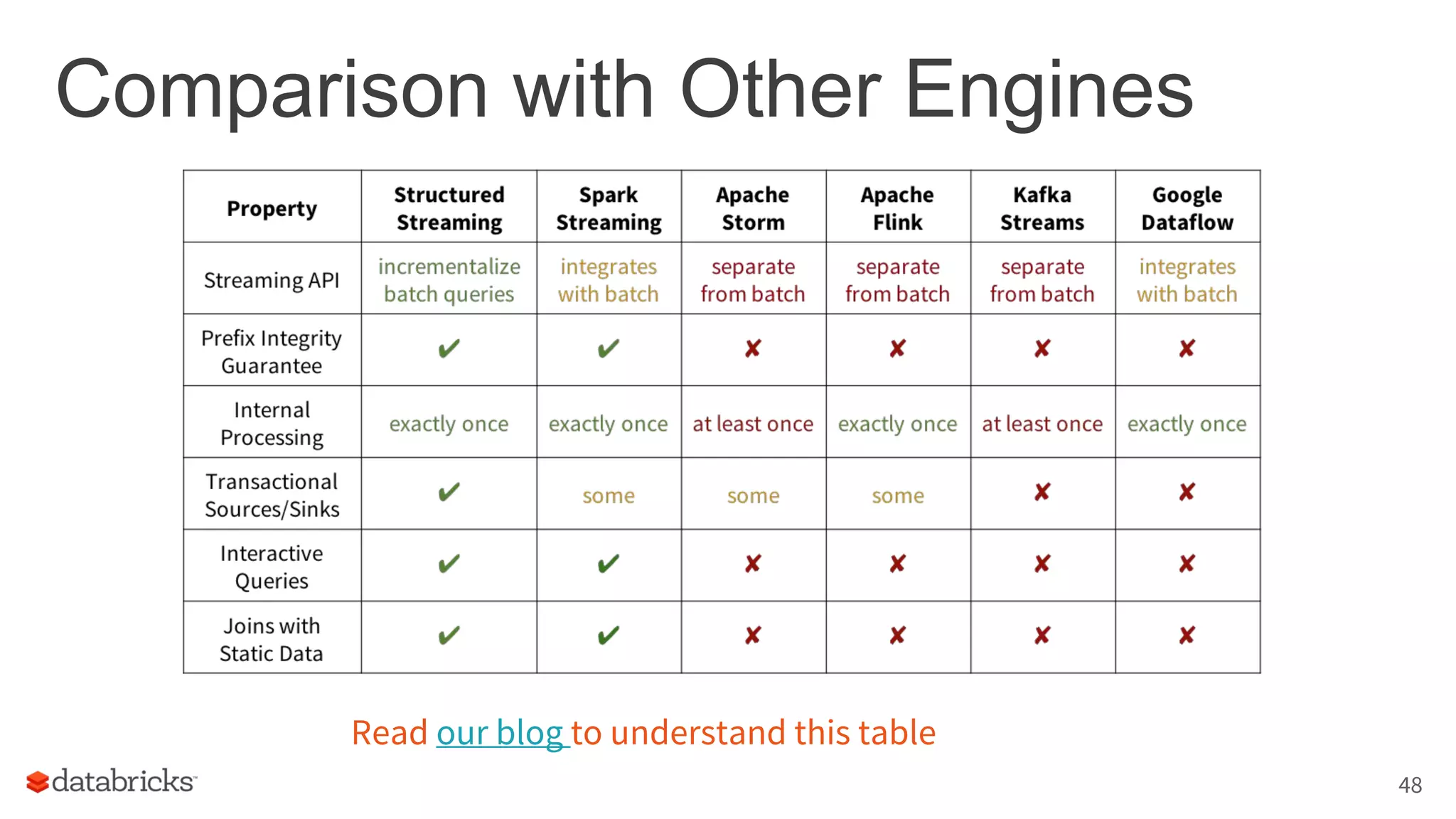













![New Model
result up
to t = 1
Result
Query
Time
data up
to t = 1
Input data up
to t = 2
result up
to t = 2
data up
to t = 3
result up
to t = 3
Result: final operated table
updated after every trigger
Output: what part of result to write
to storage after every trigger
Output
[complete mode]
write all rows in result table to storage
t=1 t=2 t=3
Complete output: write full result table every
time](https://crownmelresort.com/image.slidesharecdn.com/whatsnewwithstructuredstreaming-170329132317/75/What-s-new-with-Apache-Spark-s-Structured-Streaming-13-2048.jpg)
![New Model
Query
Time
data up
to t = 1
Input data up
to t = 2
data up
to t = 3
Result: final operated table
updated after every trigger
Output: what part of result to write
to storage after every trigger
Complete output: write full result table every
time
Append output: write only new rows that got
added to result table since previous batch
t=1 t=2 t=3
Result result
up to t =
3
Output
[append mode] write new rows since last trigger to storage
result
up to t =
1
result
up to t =
2](https://crownmelresort.com/image.slidesharecdn.com/whatsnewwithstructuredstreaming-170329132317/75/What-s-new-with-Apache-Spark-s-Structured-Streaming-14-2048.jpg)







![Traditional ETL
Hours of delay before taking decisions on latest data
Unacceptable when time is of essence
[intrusion detection, anomaly detection, etc.]
file
dump
seconds hours
table
10101010](https://crownmelresort.com/image.slidesharecdn.com/whatsnewwithstructuredstreaming-170329132317/75/What-s-new-with-Apache-Spark-s-Structured-Streaming-22-2048.jpg)


![Reading from Kafka [Spark 2.1]
Support Kafka 0.10.0.1
Specify options to configure
How?
kafka.boostrap.servers => broker1
What?
subscribe => topic1,topic2,topic3 // fixed list of topics
subscribePattern => topic* // dynamic list of topics
assign => {"topicA":[0,1] } // specific partitions
Where?
startingOffsets => latest(default)
/ earliest / {"topicA":{"0":23,"1":345} }
val rawData = spark.readStream
.format("kafka")
.option("kafka.boostrap.servers",...)
.option("subscribe", "topic")
.load()](https://crownmelresort.com/image.slidesharecdn.com/whatsnewwithstructuredstreaming-170329132317/75/What-s-new-with-Apache-Spark-s-Structured-Streaming-25-2048.jpg)
![Reading from Kafka
rawData dataframe has
the following columns
key value topic partition offset timestamp
[binary] [binary] "topicA" 0 345 1486087873
[binary] [binary] "topicB" 3 2890 1486086721
val rawData = spark.readStream
.format("kafka")
.option("subscribe", "topic")
.option("kafka.boostrap.servers",...)
.load()](https://crownmelresort.com/image.slidesharecdn.com/whatsnewwithstructuredstreaming-170329132317/75/What-s-new-with-Apache-Spark-s-Structured-Streaming-26-2048.jpg)












![Watermarking and Late Data
Watermark [Spark 2.1] - threshold
on how late an event is expected
to be in event time
Trails behind max seen event time
Trailing gap is configurable
event time
max event
time
watermark data older
than
watermark
not expected
12:30 PM
12:20 PM
trailing gap
of 10 mins](https://crownmelresort.com/image.slidesharecdn.com/whatsnewwithstructuredstreaming-170329132317/75/What-s-new-with-Apache-Spark-s-Structured-Streaming-39-2048.jpg)


![Watermarking to Limit State [Spark 2.1]
data too late,
ignored in counts,
state dropped
Processing Time12:00
12:05
12:10
12:15
12:10 12:15
12:20
12:07
12:13
12:08
EventTime
12:15
12:18
12:04
watermark updated to
12:14 - 10m = 12:04
for next trigger,
state < 12:04 deleted
data is late, but
considered in counts
parsedData
.withWatermark("timestamp", "10 minutes")
.groupBy(window("timestamp","5 minutes"))
.count()
system tracks max
observed event time
12:08
wm = 12:04
10min
12:14
more details in online
programming guide](https://crownmelresort.com/image.slidesharecdn.com/whatsnewwithstructuredstreaming-170329132317/75/What-s-new-with-Apache-Spark-s-Structured-Streaming-42-2048.jpg)
![mapGroupsWithState
allows any user-defined
stateful ops to a
user-defined state
--
supports timeouts
--
fault-tolerant,
exactly-once
--
supports Scala and Java
Arbitrary Stateful Operations [Spark 2.2]
dataset
.groupByKey(groupingFunc)
.mapGroupsWithState(mappingFunc)
def mappingFunc(
key: K,
values: Iterator[V],
state: KeyedState[S]): U = {
// update or remove state
// set timeouts
// return mapped value
}](https://crownmelresort.com/image.slidesharecdn.com/whatsnewwithstructuredstreaming-170329132317/75/What-s-new-with-Apache-Spark-s-Structured-Streaming-43-2048.jpg)
![Many more updates!
StreamingQueryListener [Spark 2.1]
Receive of regular progress heartbeats for health and perf monitoring
Automatic in Databricks, come to the Databricks booth for a demo!!
Kafka Batch Queries [Spark 2.2]
Run batch queries on Kafka just like a file system
Kafka Sink [Spark 2.2]
Write to Kafka, can only give at-least-once guarantee as
Kafka doesn't support transactional updates
Kinesis Source
Read from Amazon Kinesis
44](https://crownmelresort.com/image.slidesharecdn.com/whatsnewwithstructuredstreaming-170329132317/75/What-s-new-with-Apache-Spark-s-Structured-Streaming-44-2048.jpg)






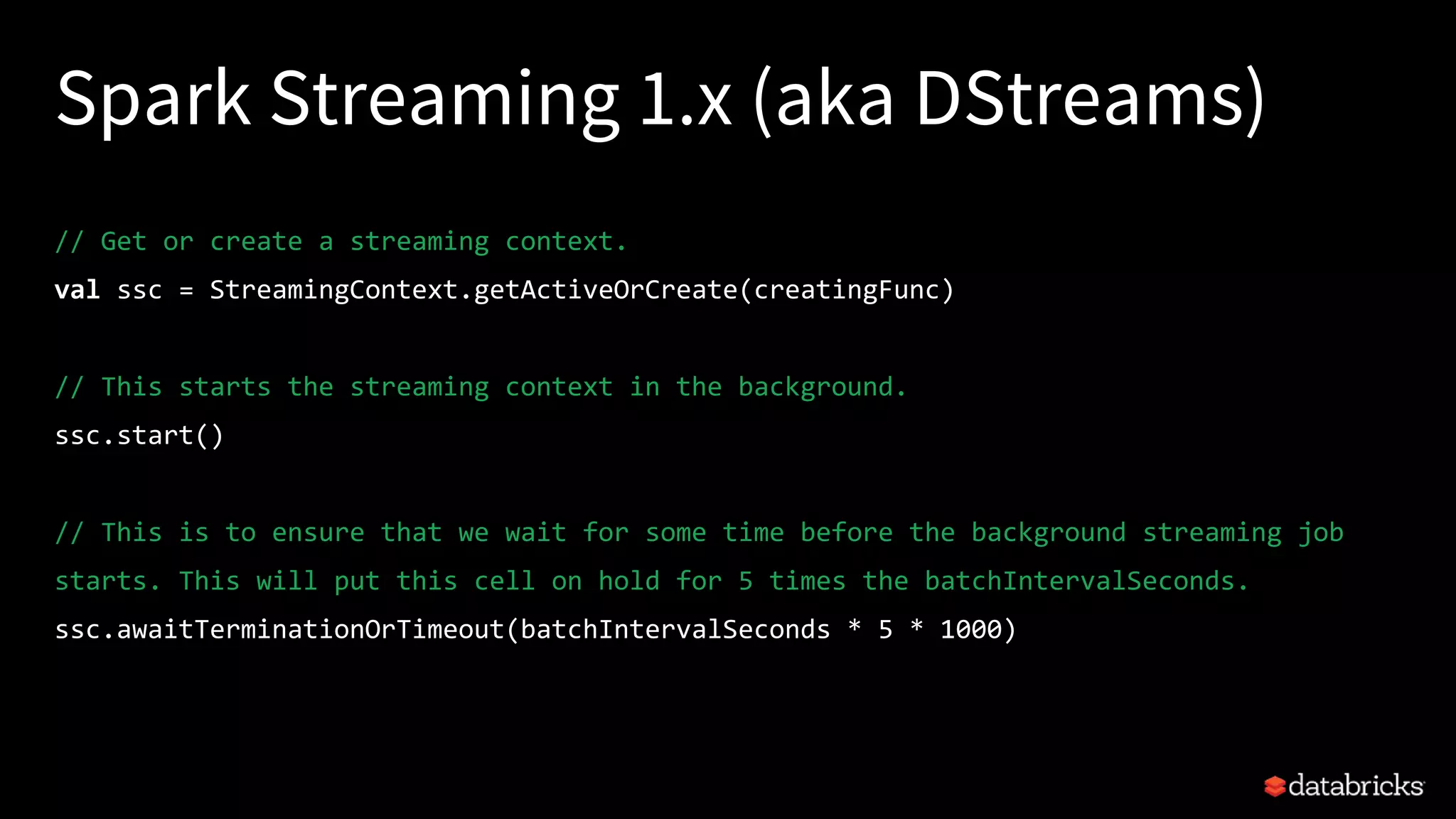
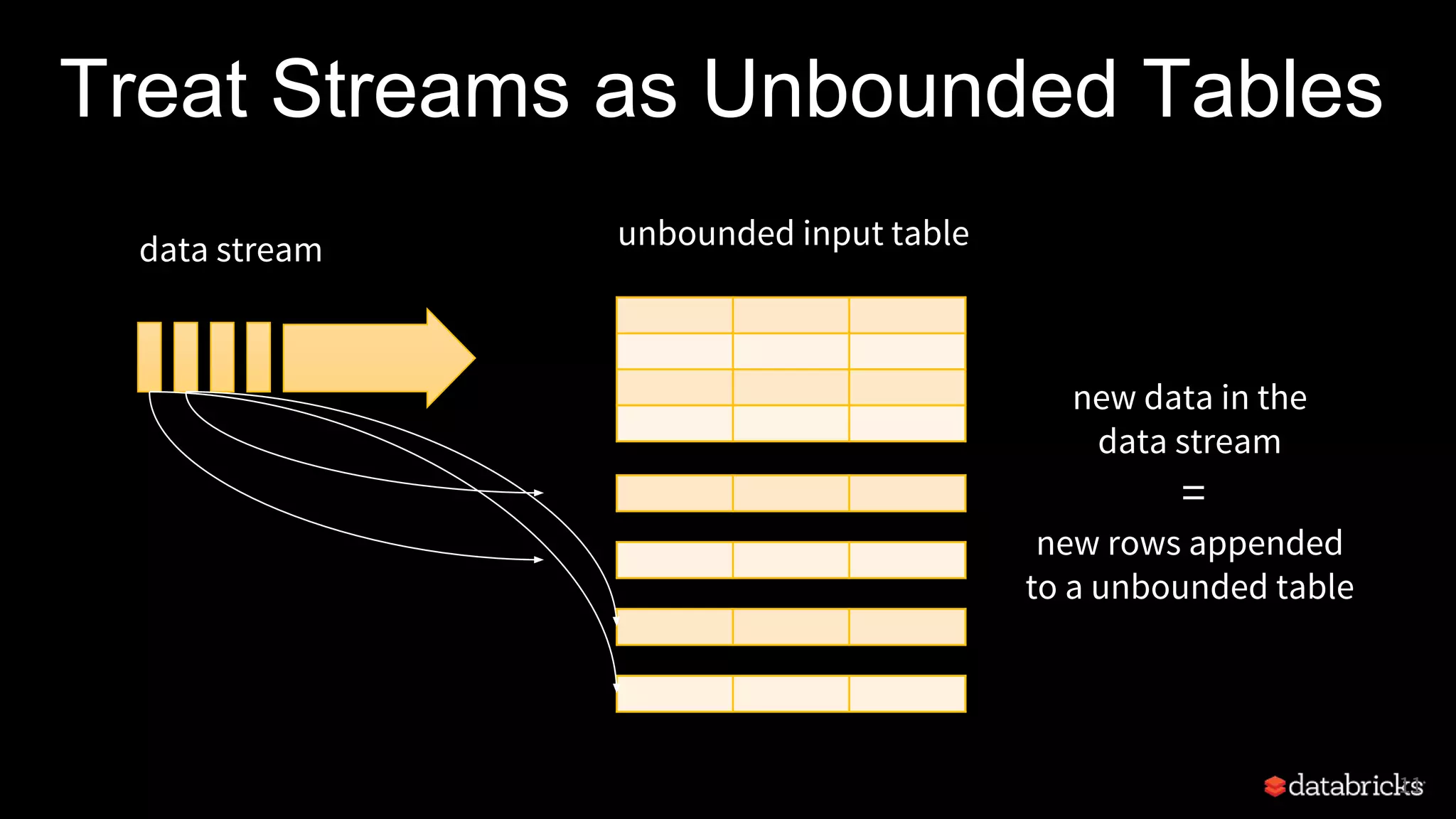
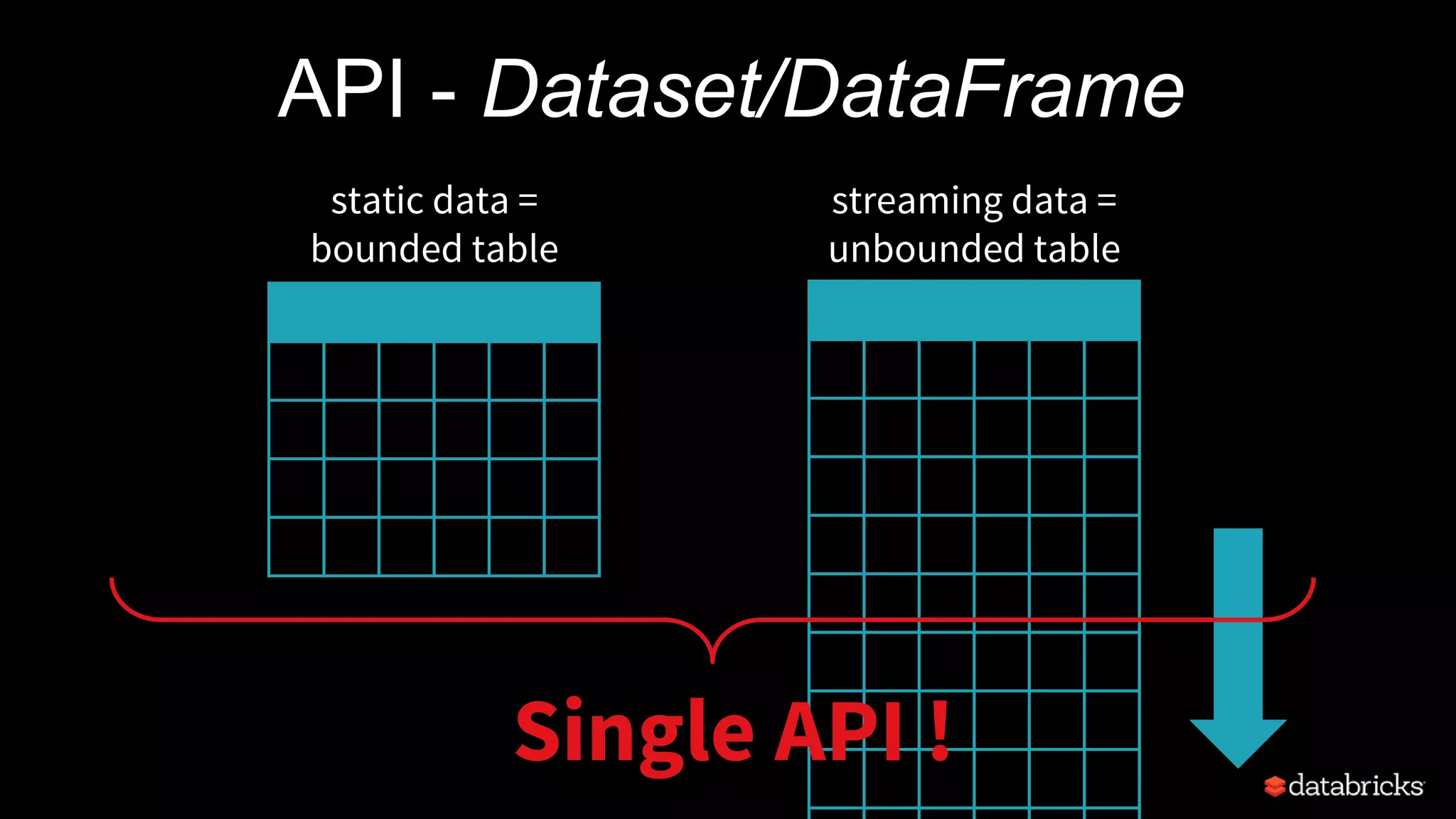
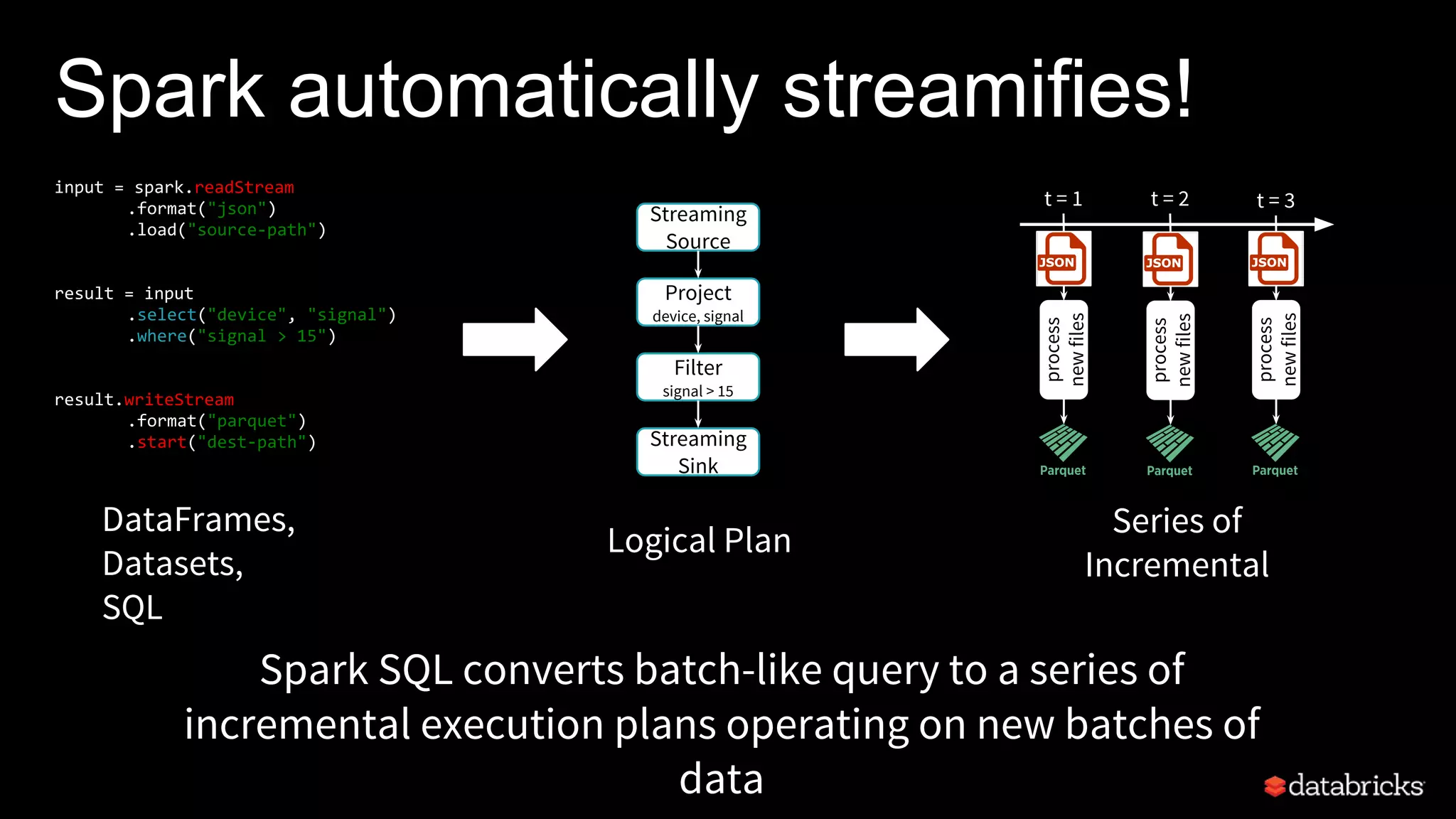
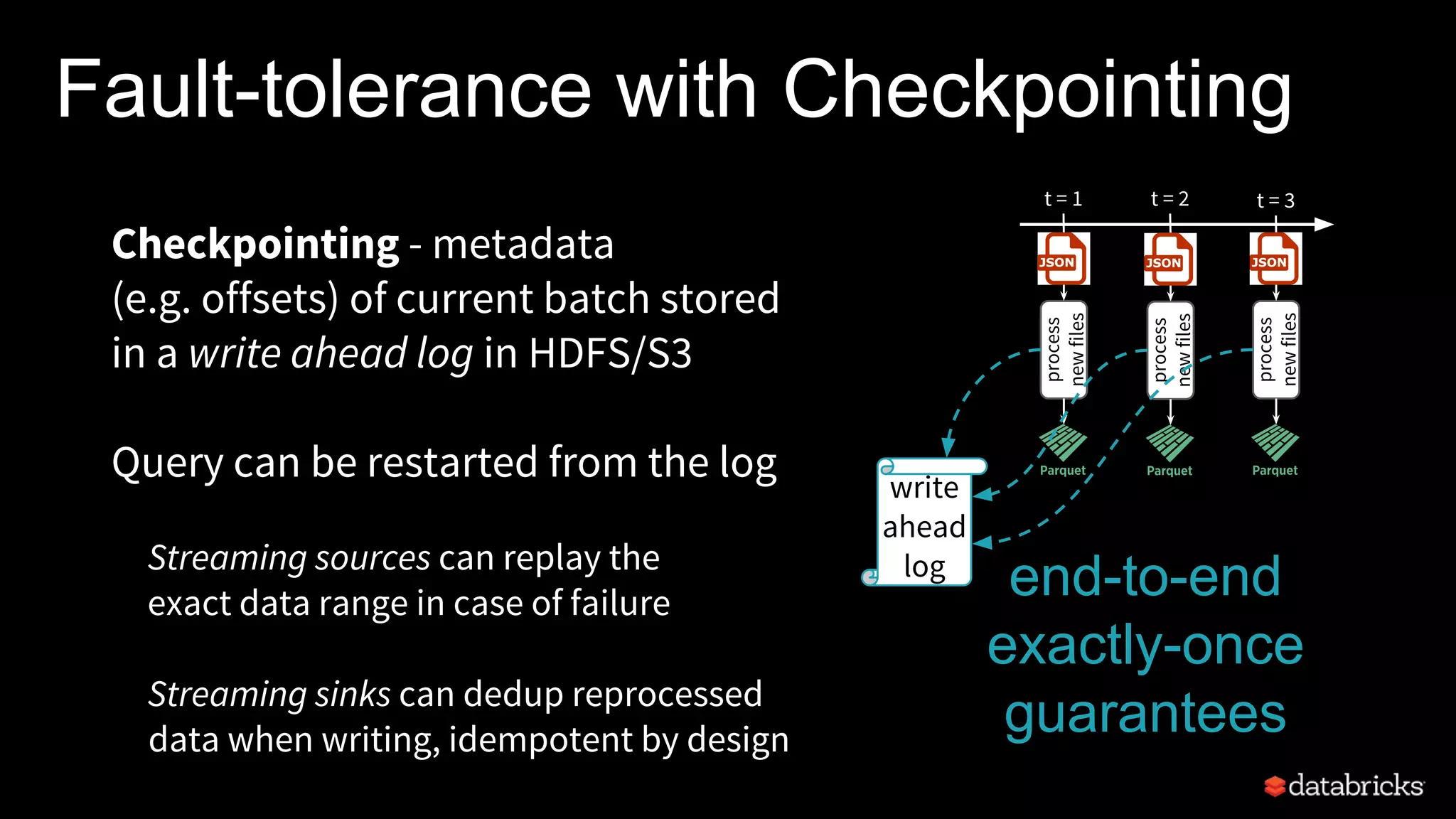
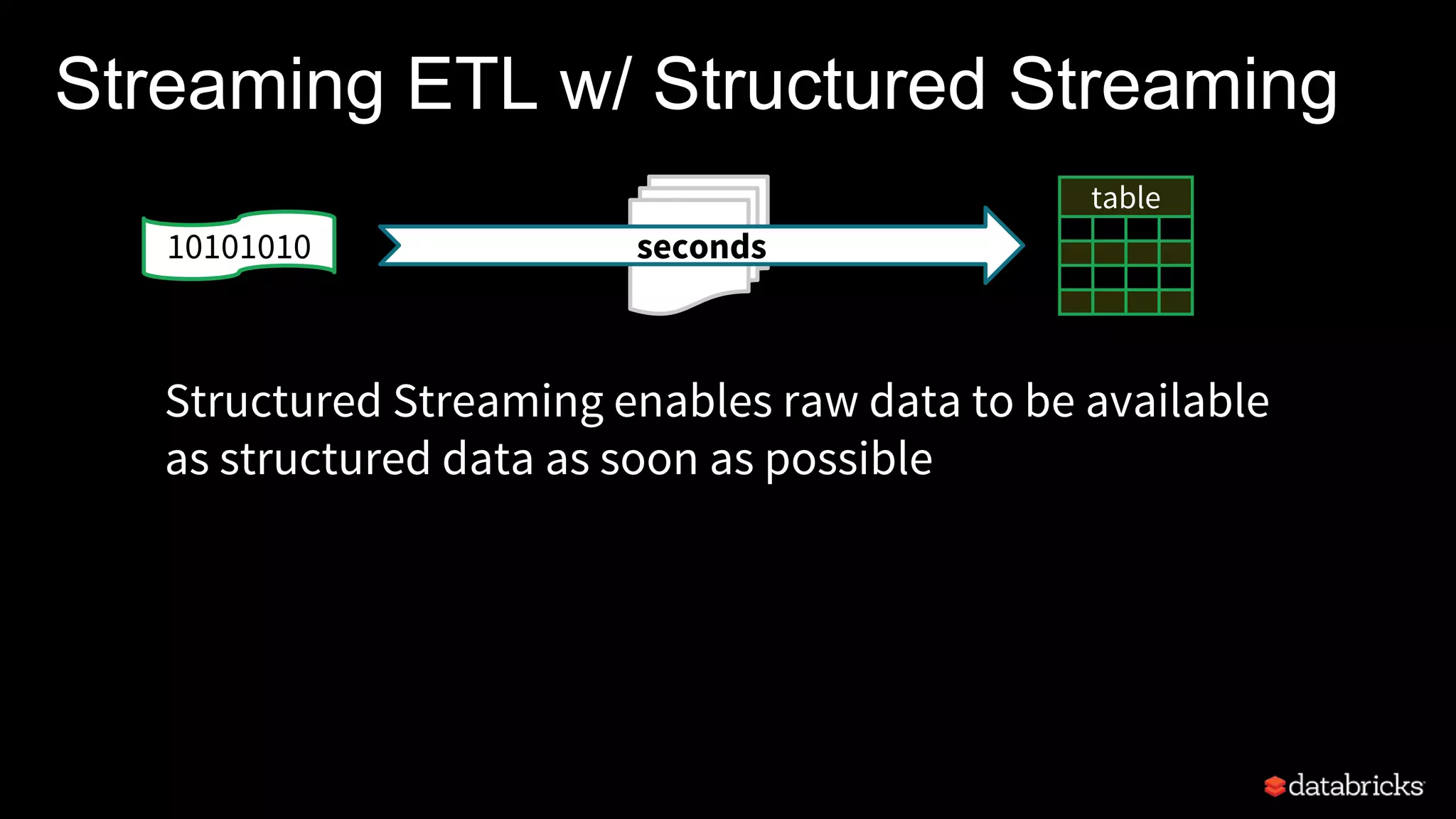
Structured Streaming in Apache Spark allows users to write streaming applications as batch-style queries on static or streaming data sources. It treats streams as continuous unbounded tables and allows batch queries written on DataFrames/Datasets to be automatically converted into incremental execution plans to process streaming data in micro-batches. This provides a simple yet powerful API for building robust stream processing applications with end-to-end fault tolerance guarantees and integration with various data sources and sinks.











































































