Download as PDF, PPTX















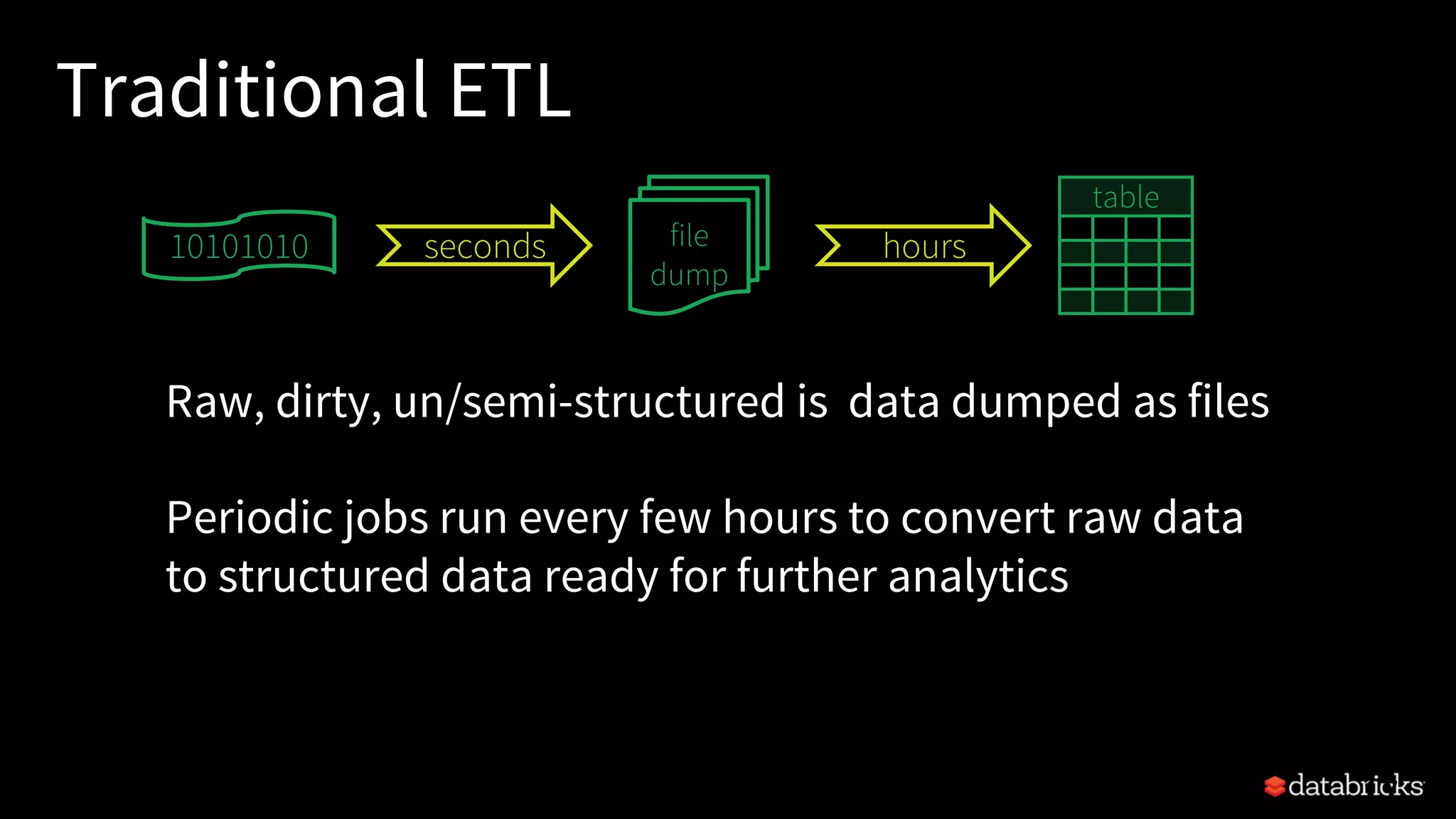
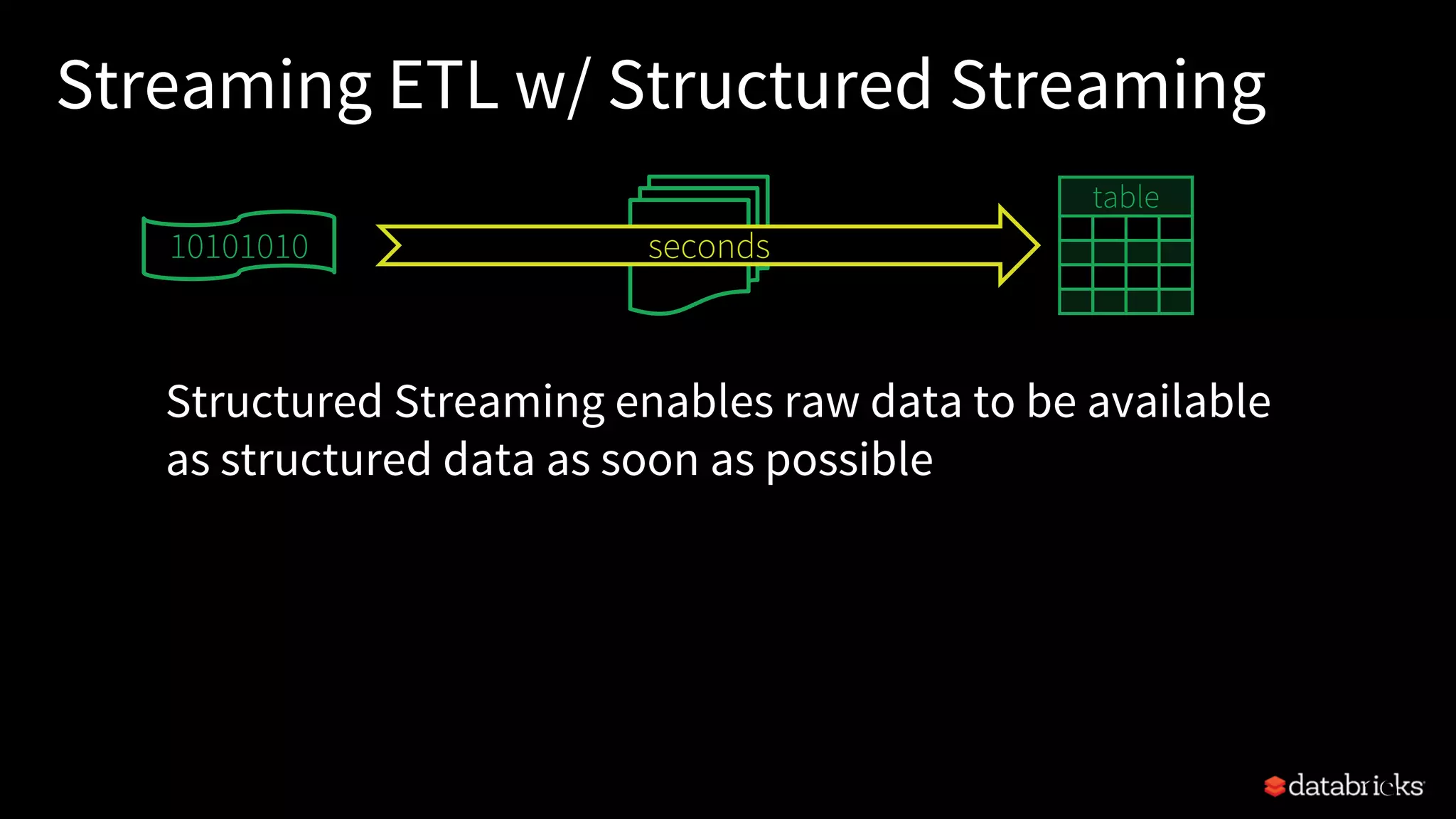
![Traditional ETL
Hours of delay before taking decisions on latest data
Unacceptable when time is of essence
[intrusion detection, anomaly detection, etc.]
file
dump
seconds hours
table
10101010](https://image.slidesharecdn.com/easyscalablefault-tolerantstreamprocessingwithstructuredstreaming-sparksummit2017-170608203443/75/Easy-scalable-fault-tolerant-stream-processing-with-structured-streaming-spark-summit-2017-18-2048.jpg)

![Reading from Kafka
Specify options to configure
How?
kafka.boostrap.servers => broker1,broker2
What?
subscribe => topic1,topic2,topic3 // fixed list of topics
subscribePattern => topic* // dynamic list of topics
assign => {"topicA":[0,1] } // specific partitions
Where?
startingOffsets => latest(default) / earliest / {"topicA":{"0":23,"1":345} }
val rawData = spark.readStream
.format("kafka")
.option("kafka.boostrap.servers",...)
.option("subscribe", "topic")
.load()](https://image.slidesharecdn.com/easyscalablefault-tolerantstreamprocessingwithstructuredstreaming-sparksummit2017-170608203443/75/Easy-scalable-fault-tolerant-stream-processing-with-structured-streaming-spark-summit-2017-21-2048.jpg)
![Reading from Kafka
val rawData = spark.readStream
.format("kafka")
.option("kafka.boostrap.servers",...)
.option("subscribe", "topic")
.load()
rawData dataframe has
the following columns
key value topic partition offset timestamp
[binary] [binary] "topicA" 0 345 1486087873
[binary] [binary] "topicB" 3 2890 1486086721](https://image.slidesharecdn.com/easyscalablefault-tolerantstreamprocessingwithstructuredstreaming-sparksummit2017-170608203443/75/Easy-scalable-fault-tolerant-stream-processing-with-structured-streaming-spark-summit-2017-22-2048.jpg)

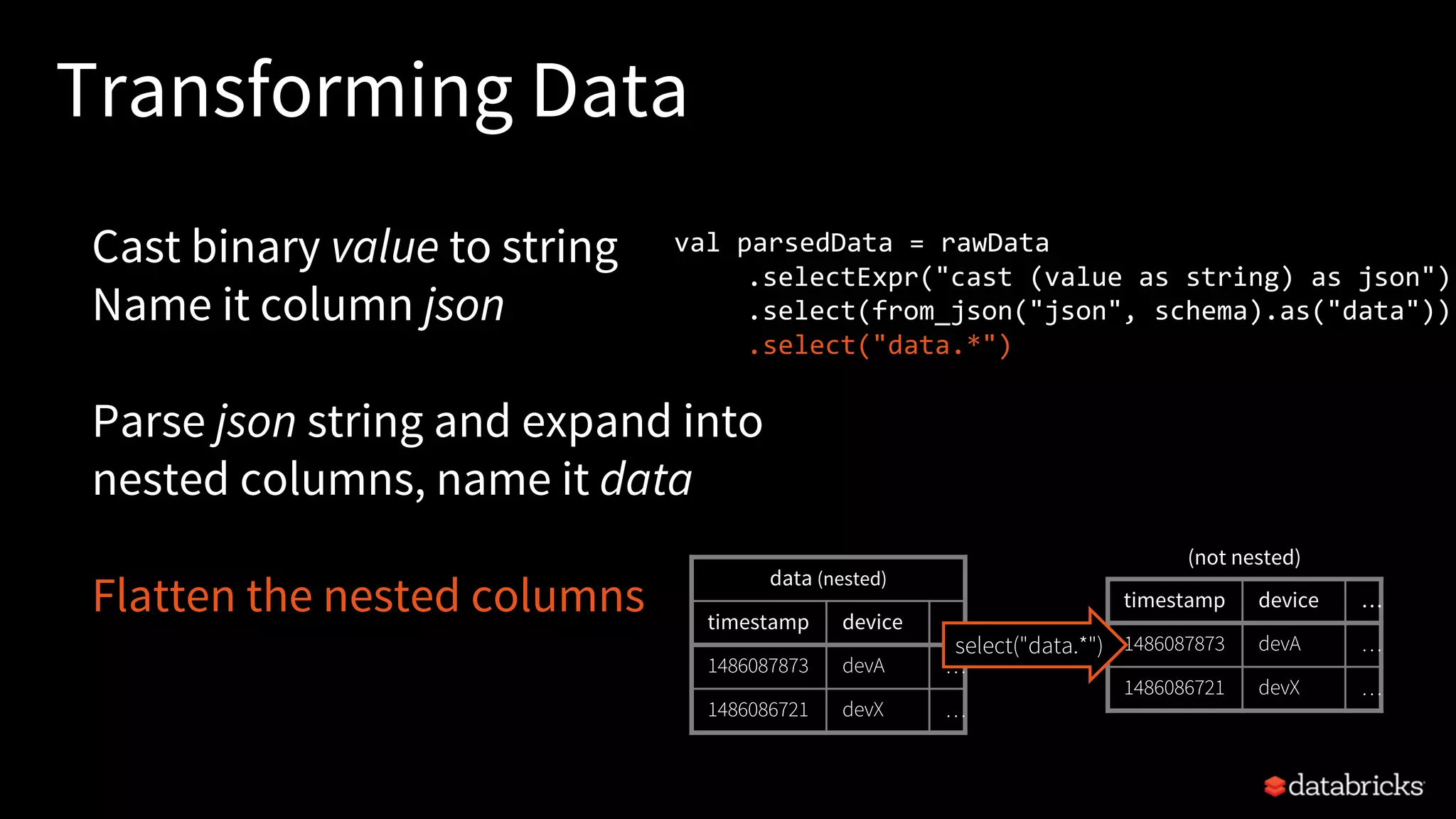




![More Kafka Support [Spark 2.2]
Write out to Kafka
Dataframe must have binary fields
named key and value
Direct, interactive and batch
queries on Kafka
Makes Kafka even more powerful
as a storage platform!
result.writeStream
.format("kafka")
.option("topic", "output")
.start()
val df = spark
.read // not readStream
.format("kafka")
.option("subscribe", "topic")
.load()
df.registerTempTable("topicData")
spark.sql("select value from topicData")](https://image.slidesharecdn.com/easyscalablefault-tolerantstreamprocessingwithstructuredstreaming-sparksummit2017-170608203443/75/Easy-scalable-fault-tolerant-stream-processing-with-structured-streaming-spark-summit-2017-31-2048.jpg)
![Amazon Kinesis [Databricks Runtime 3.0]
Configure with options (similar to Kafka)
How?
region => us-west-2 / us-east-1 / ...
awsAccessKey (optional) => AKIA...
awsSecretKey (optional) => ...
What?
streamName => name-of-the-stream
Where?
initialPosition => latest(default) / earliest / trim_horizon
spark.readStream
.format("kinesis")
.option("streamName", "myStream")
.option("region", "us-west-2")
.option("awsAccessKey", ...)
.option("awsSecretKey", ...)
.load()](https://image.slidesharecdn.com/easyscalablefault-tolerantstreamprocessingwithstructuredstreaming-sparksummit2017-170608203443/75/Easy-scalable-fault-tolerant-stream-processing-with-structured-streaming-spark-summit-2017-32-2048.jpg)











![Arbitrary Stateful Operations [Spark 2.2]
mapGroupsWithState
allows any user-defined
stateful function to a
user-defined state
Direct support for per-key
timeouts in event-time or
processing-time
Supports Scala and Java
46
ds.groupByKey(_.id)
.mapGroupsWithState
(timeoutConf)
(mappingWithStateFunc)
def mappingWithStateFunc(
key: K,
values: Iterator[V],
state: GroupState[S]): U = {
// update or remove state
// set timeouts
// return mapped value
}](https://image.slidesharecdn.com/easyscalablefault-tolerantstreamprocessingwithstructuredstreaming-sparksummit2017-170608203443/75/Easy-scalable-fault-tolerant-stream-processing-with-structured-streaming-spark-summit-2017-46-2048.jpg)



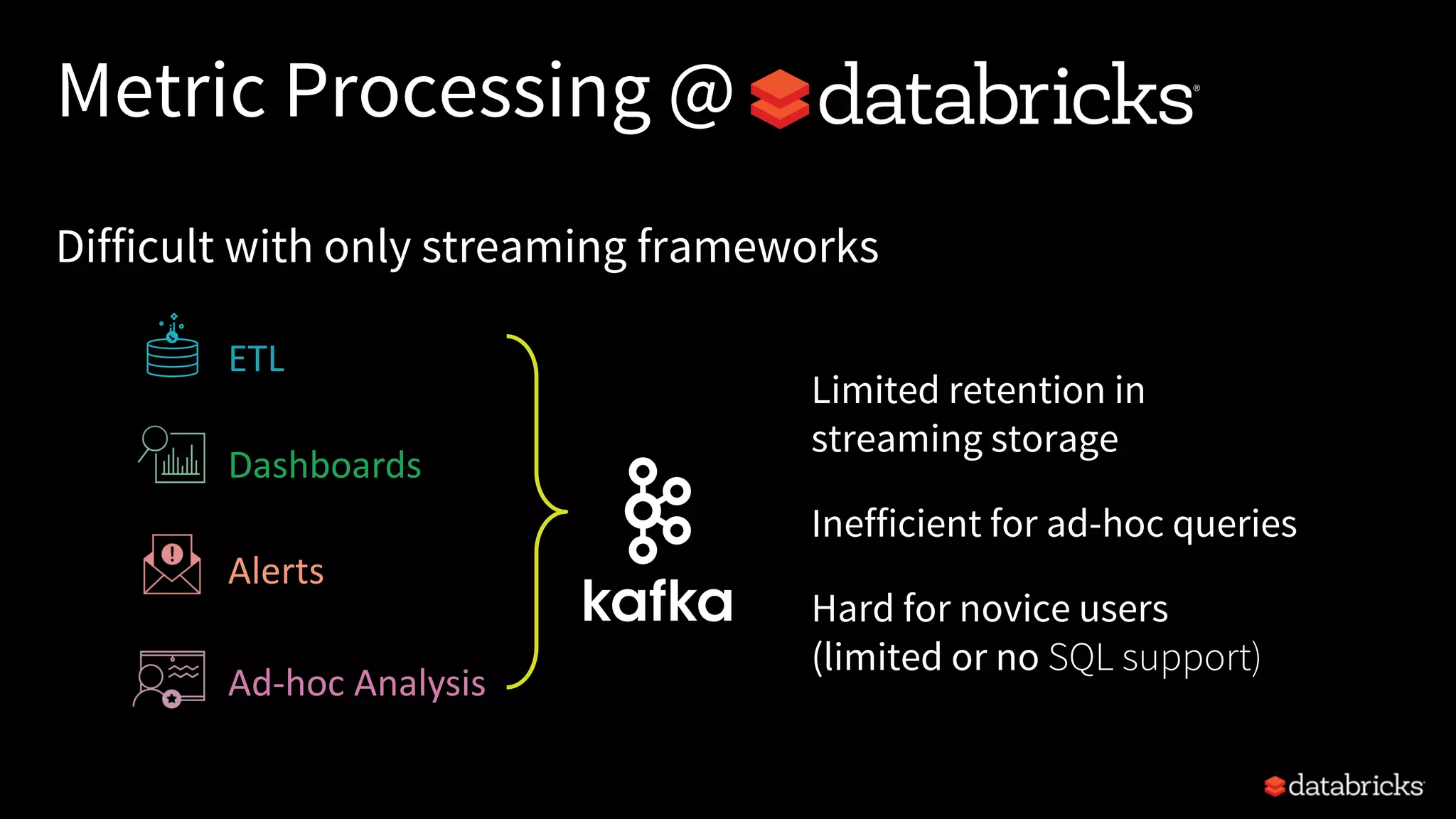
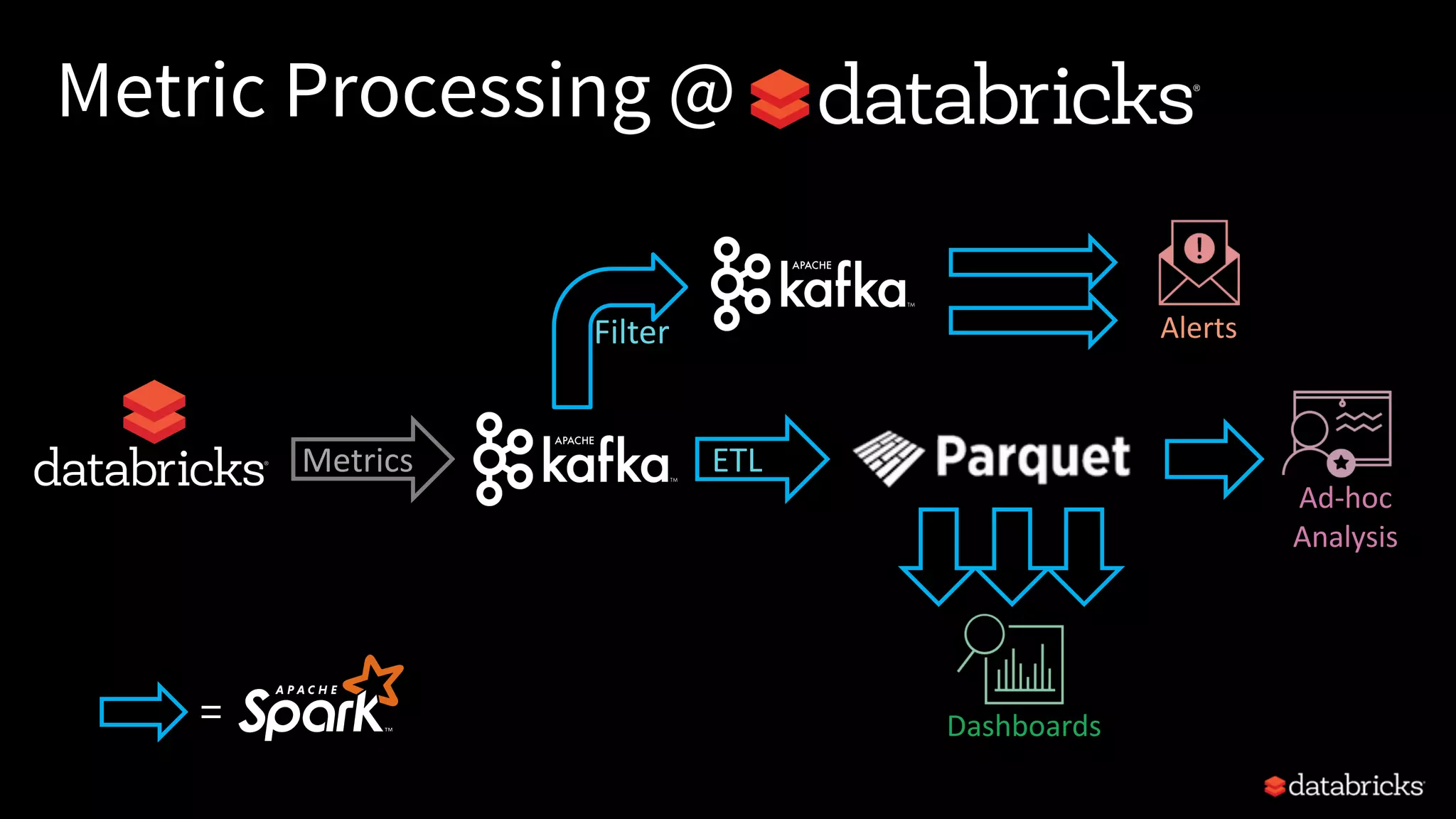
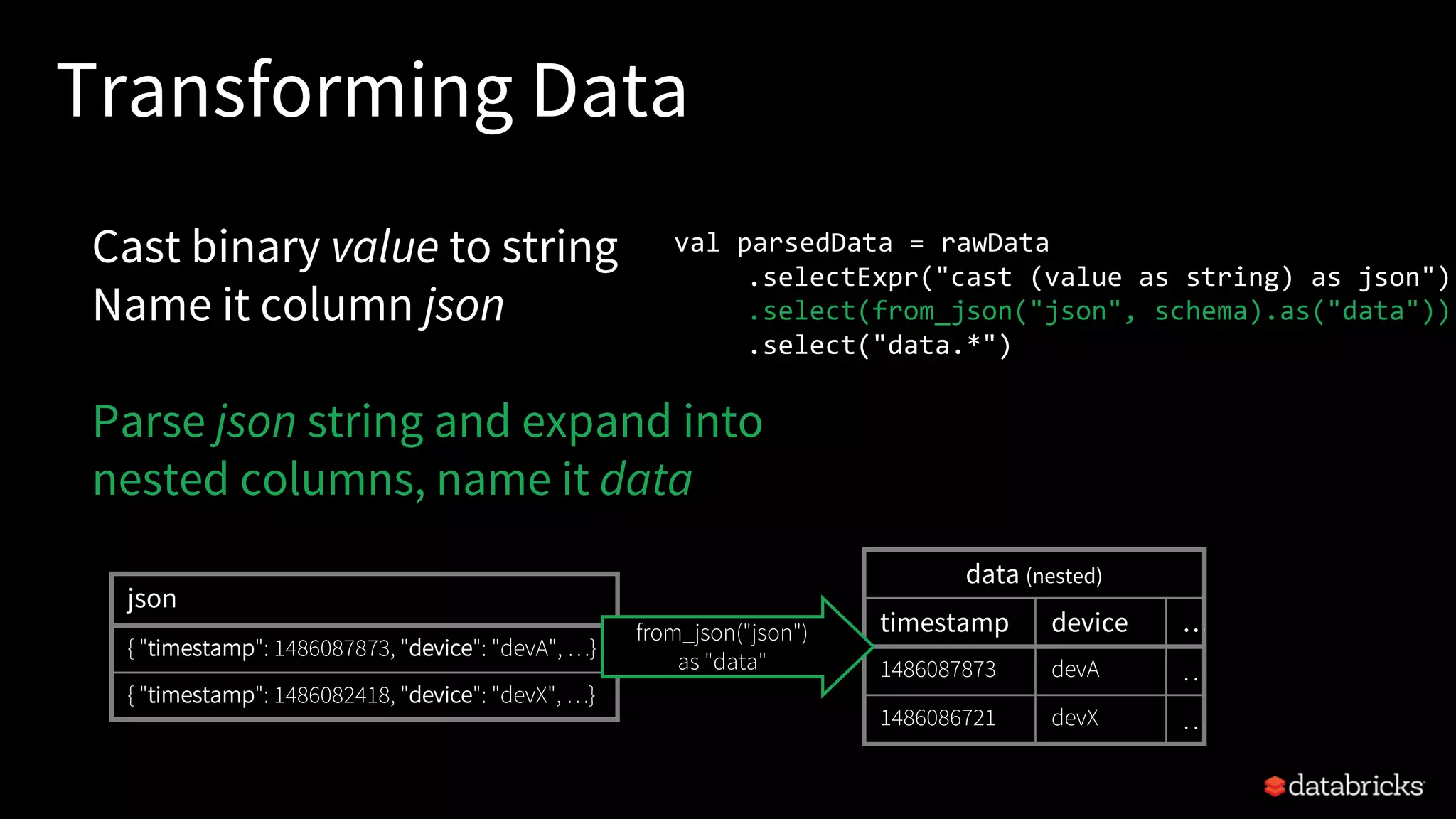
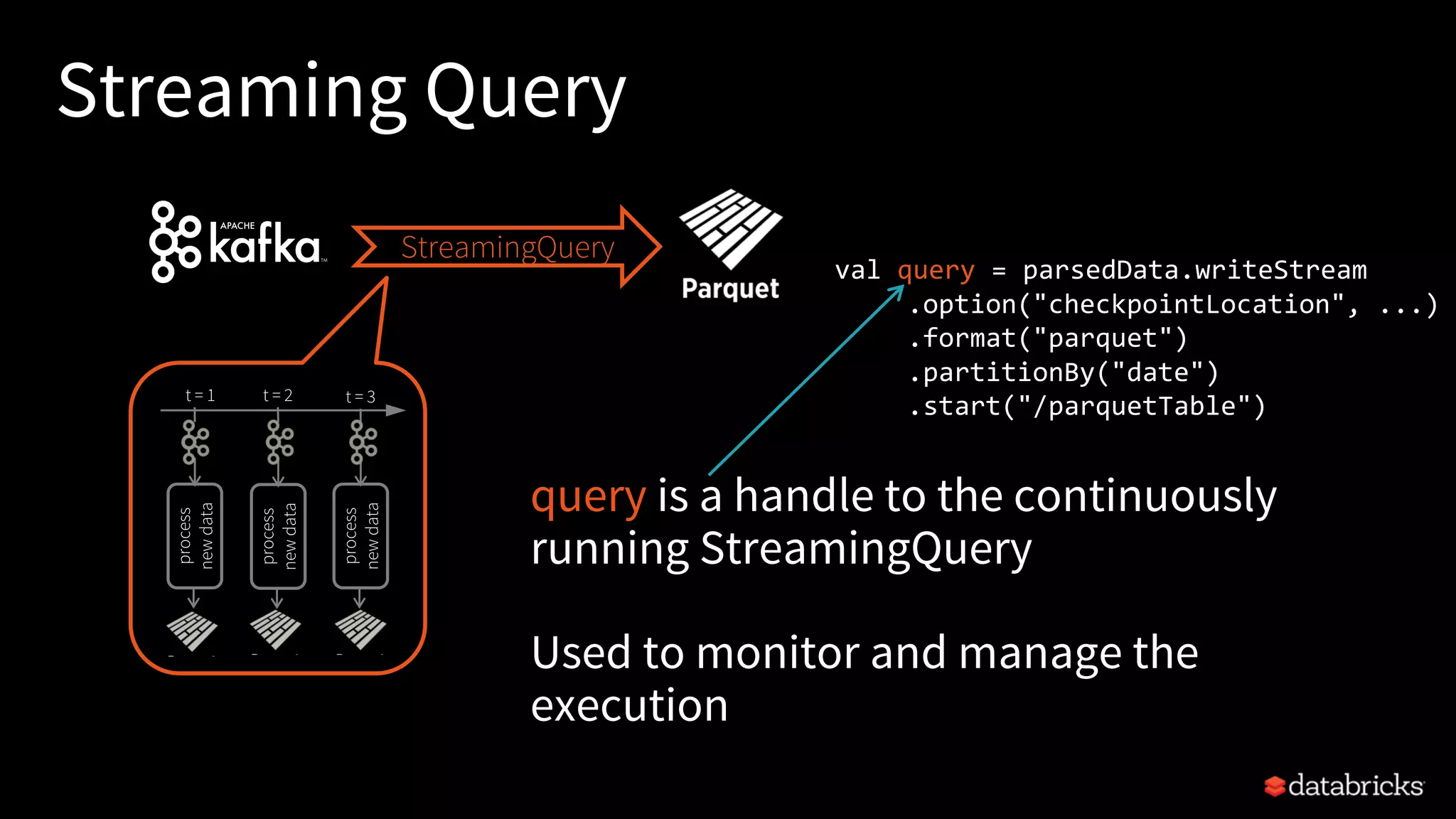
![Read from
rawLogs = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", ...)
.option("subscribe", "rawLogs")
.load()
augmentedLogs = rawLogs
.withColumn("msg",
from_json($"value".cast("string"),
schema))
.select("timestamp", "msg.*")
.join(table("customers"), ["customer_id"])
DataFrames can be
reused for multiple
streams
Can build libraries of
useful DataFrames and
share code between
applications
JSON ETL](https://image.slidesharecdn.com/easyscalablefault-tolerantstreamprocessingwithstructuredstreaming-sparksummit2017-170608203443/75/Easy-scalable-fault-tolerant-stream-processing-with-structured-streaming-spark-summit-2017-52-2048.jpg)



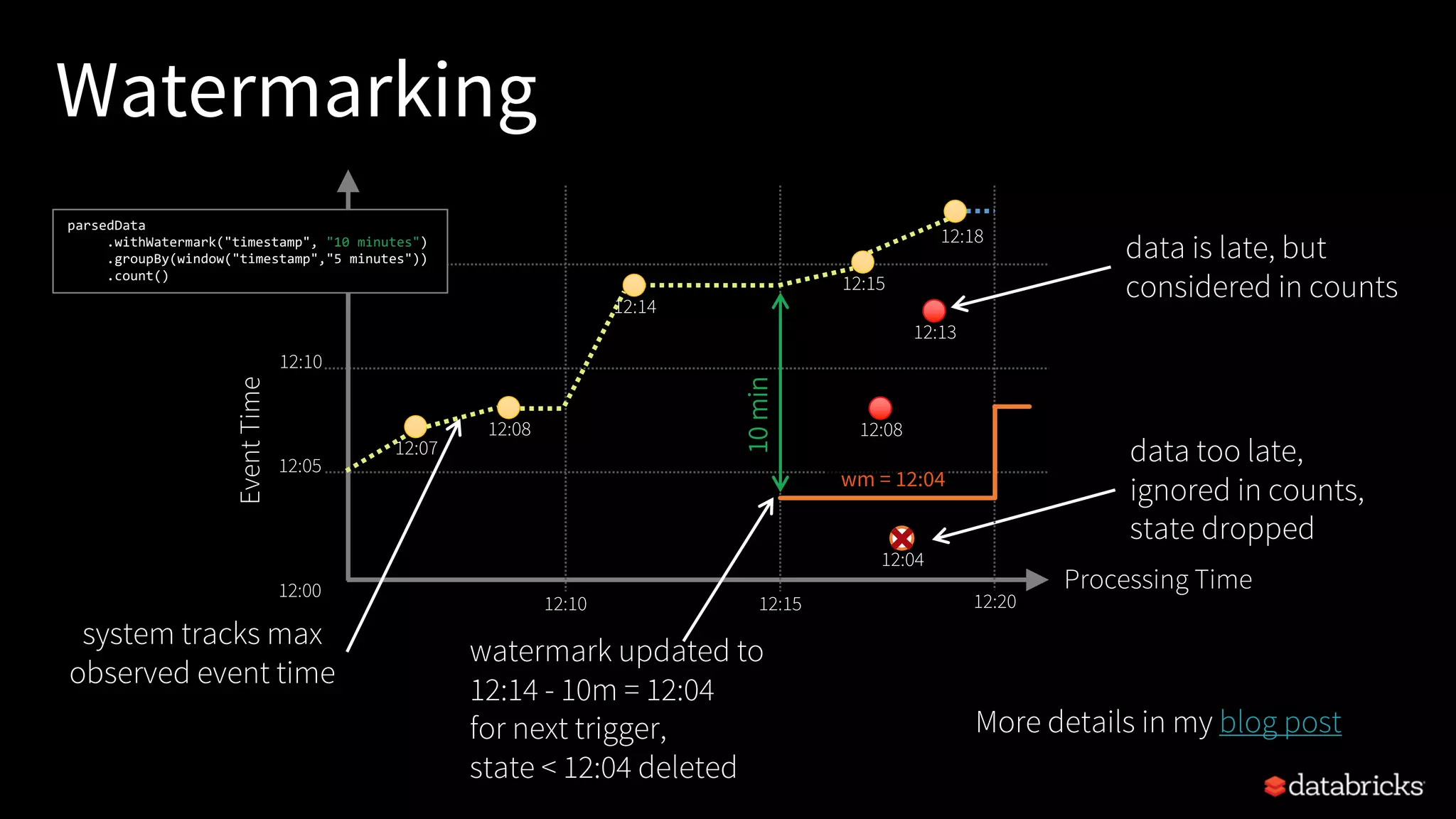
![Simple Alerts
sparkErrors
.as[ClusterHeartBeat]
.filter(_.load > 99)
.writeStream
.foreach(new PagerdutySink(credentials))
E.g. Alert when Spark cluster load > threshold
Latency: ~100 ms
Alerts
Notify PagerDuty](https://image.slidesharecdn.com/easyscalablefault-tolerantstreamprocessingwithstructuredstreaming-sparksummit2017-170608203443/75/Easy-scalable-fault-tolerant-stream-processing-with-structured-streaming-spark-summit-2017-56-2048.jpg)
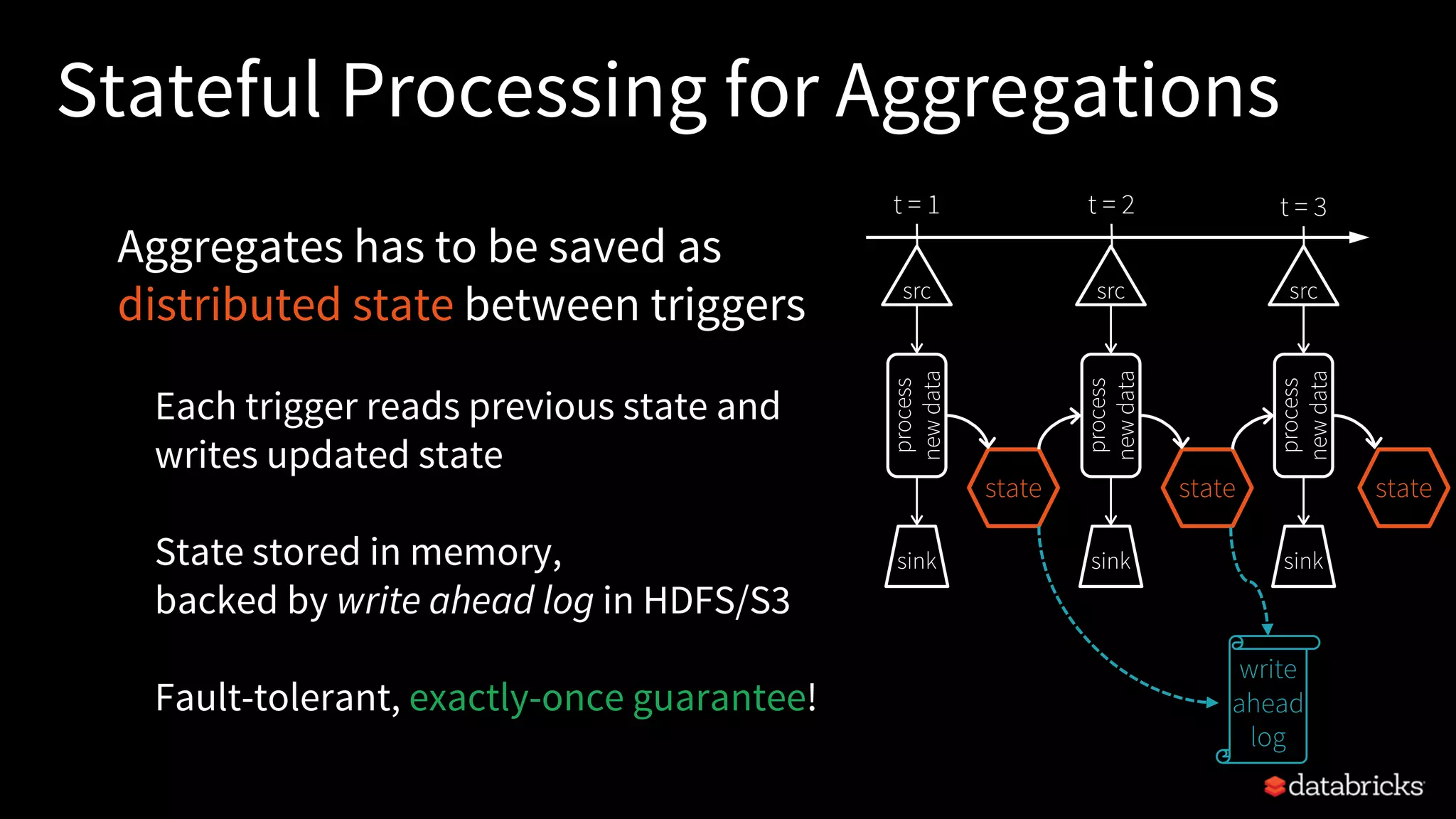
![Complex Alerts
sparkErrors
.as[ClusterHeartBeat]
.groupBy(_.id)
.flatMapGroupsWithState(Update, ProcessingTimeTimeout("1 minute")) {
(id: Int, events: Iterator[ClusterHeartBeat], state: GroupState[ClusterState]) =>
... // check if cluster non-responsive for a while
}
E.g. Monitor health of Spark clusters
using custom stateful logic
Latency: ~10 seconds
Alerts
React if no heartbeat
from cluster for 1 min](https://image.slidesharecdn.com/easyscalablefault-tolerantstreamprocessingwithstructuredstreaming-sparksummit2017-170608203443/75/Easy-scalable-fault-tolerant-stream-processing-with-structured-streaming-spark-summit-2017-57-2048.jpg)


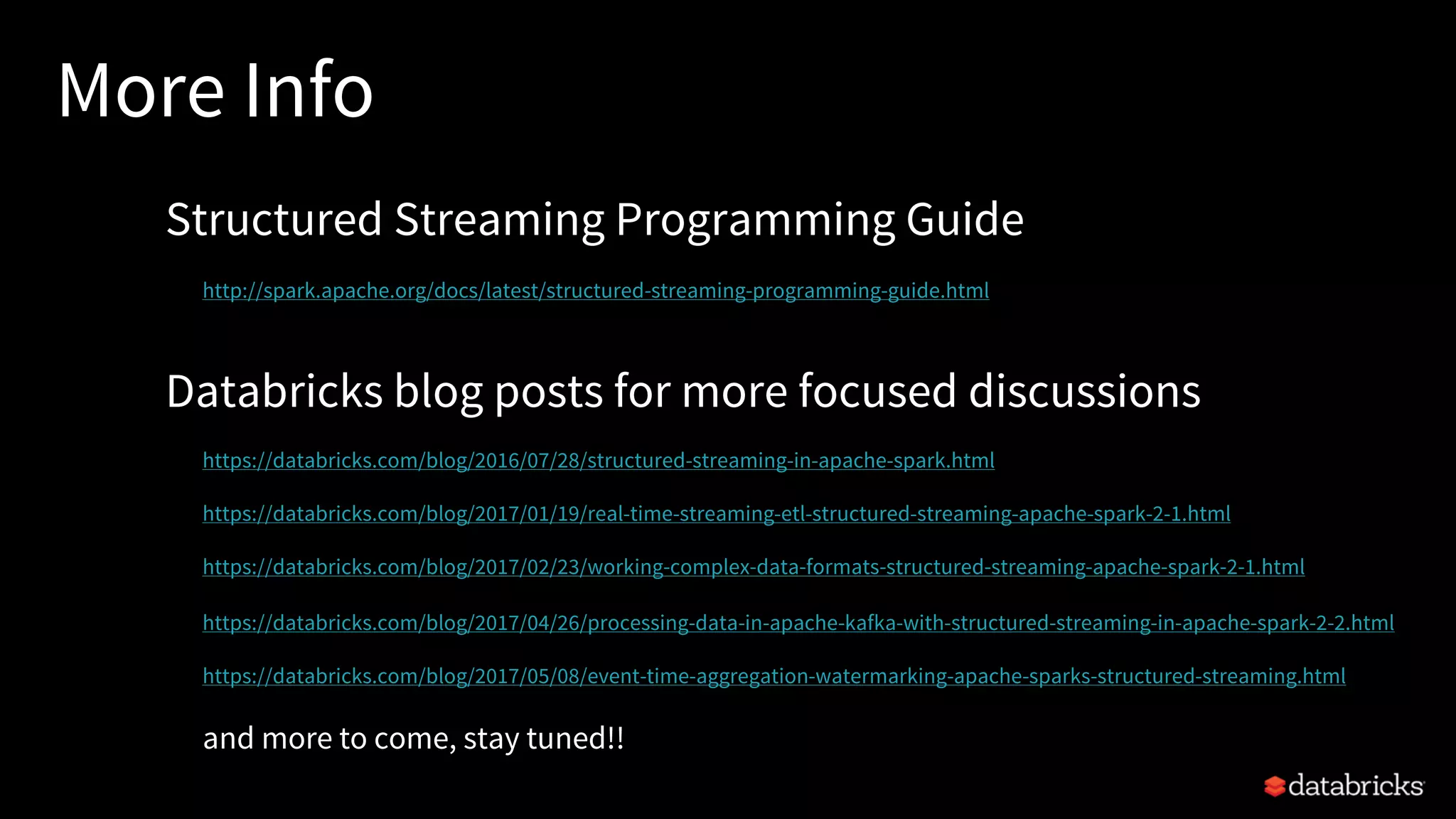


















![Traditional ETL
Hours of delay before taking decisions on latest data
Unacceptable when time is of essence
[intrusion detection, anomaly detection, etc.]
file
dump
seconds hours
table
10101010](https://crownmelresort.com/image.slidesharecdn.com/easyscalablefault-tolerantstreamprocessingwithstructuredstreaming-sparksummit2017-170608203443/75/Easy-scalable-fault-tolerant-stream-processing-with-structured-streaming-spark-summit-2017-18-2048.jpg)


![Reading from Kafka
Specify options to configure
How?
kafka.boostrap.servers => broker1,broker2
What?
subscribe => topic1,topic2,topic3 // fixed list of topics
subscribePattern => topic* // dynamic list of topics
assign => {"topicA":[0,1] } // specific partitions
Where?
startingOffsets => latest(default) / earliest / {"topicA":{"0":23,"1":345} }
val rawData = spark.readStream
.format("kafka")
.option("kafka.boostrap.servers",...)
.option("subscribe", "topic")
.load()](https://crownmelresort.com/image.slidesharecdn.com/easyscalablefault-tolerantstreamprocessingwithstructuredstreaming-sparksummit2017-170608203443/75/Easy-scalable-fault-tolerant-stream-processing-with-structured-streaming-spark-summit-2017-21-2048.jpg)
![Reading from Kafka
val rawData = spark.readStream
.format("kafka")
.option("kafka.boostrap.servers",...)
.option("subscribe", "topic")
.load()
rawData dataframe has
the following columns
key value topic partition offset timestamp
[binary] [binary] "topicA" 0 345 1486087873
[binary] [binary] "topicB" 3 2890 1486086721](https://crownmelresort.com/image.slidesharecdn.com/easyscalablefault-tolerantstreamprocessingwithstructuredstreaming-sparksummit2017-170608203443/75/Easy-scalable-fault-tolerant-stream-processing-with-structured-streaming-spark-summit-2017-22-2048.jpg)








![More Kafka Support [Spark 2.2]
Write out to Kafka
Dataframe must have binary fields
named key and value
Direct, interactive and batch
queries on Kafka
Makes Kafka even more powerful
as a storage platform!
result.writeStream
.format("kafka")
.option("topic", "output")
.start()
val df = spark
.read // not readStream
.format("kafka")
.option("subscribe", "topic")
.load()
df.registerTempTable("topicData")
spark.sql("select value from topicData")](https://crownmelresort.com/image.slidesharecdn.com/easyscalablefault-tolerantstreamprocessingwithstructuredstreaming-sparksummit2017-170608203443/75/Easy-scalable-fault-tolerant-stream-processing-with-structured-streaming-spark-summit-2017-31-2048.jpg)
![Amazon Kinesis [Databricks Runtime 3.0]
Configure with options (similar to Kafka)
How?
region => us-west-2 / us-east-1 / ...
awsAccessKey (optional) => AKIA...
awsSecretKey (optional) => ...
What?
streamName => name-of-the-stream
Where?
initialPosition => latest(default) / earliest / trim_horizon
spark.readStream
.format("kinesis")
.option("streamName", "myStream")
.option("region", "us-west-2")
.option("awsAccessKey", ...)
.option("awsSecretKey", ...)
.load()](https://crownmelresort.com/image.slidesharecdn.com/easyscalablefault-tolerantstreamprocessingwithstructuredstreaming-sparksummit2017-170608203443/75/Easy-scalable-fault-tolerant-stream-processing-with-structured-streaming-spark-summit-2017-32-2048.jpg)













![Arbitrary Stateful Operations [Spark 2.2]
mapGroupsWithState
allows any user-defined
stateful function to a
user-defined state
Direct support for per-key
timeouts in event-time or
processing-time
Supports Scala and Java
46
ds.groupByKey(_.id)
.mapGroupsWithState
(timeoutConf)
(mappingWithStateFunc)
def mappingWithStateFunc(
key: K,
values: Iterator[V],
state: GroupState[S]): U = {
// update or remove state
// set timeouts
// return mapped value
}](https://crownmelresort.com/image.slidesharecdn.com/easyscalablefault-tolerantstreamprocessingwithstructuredstreaming-sparksummit2017-170608203443/75/Easy-scalable-fault-tolerant-stream-processing-with-structured-streaming-spark-summit-2017-46-2048.jpg)





![Read from
rawLogs = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", ...)
.option("subscribe", "rawLogs")
.load()
augmentedLogs = rawLogs
.withColumn("msg",
from_json($"value".cast("string"),
schema))
.select("timestamp", "msg.*")
.join(table("customers"), ["customer_id"])
DataFrames can be
reused for multiple
streams
Can build libraries of
useful DataFrames and
share code between
applications
JSON ETL](https://crownmelresort.com/image.slidesharecdn.com/easyscalablefault-tolerantstreamprocessingwithstructuredstreaming-sparksummit2017-170608203443/75/Easy-scalable-fault-tolerant-stream-processing-with-structured-streaming-spark-summit-2017-52-2048.jpg)



![Simple Alerts
sparkErrors
.as[ClusterHeartBeat]
.filter(_.load > 99)
.writeStream
.foreach(new PagerdutySink(credentials))
E.g. Alert when Spark cluster load > threshold
Latency: ~100 ms
Alerts
Notify PagerDuty](https://crownmelresort.com/image.slidesharecdn.com/easyscalablefault-tolerantstreamprocessingwithstructuredstreaming-sparksummit2017-170608203443/75/Easy-scalable-fault-tolerant-stream-processing-with-structured-streaming-spark-summit-2017-56-2048.jpg)
![Complex Alerts
sparkErrors
.as[ClusterHeartBeat]
.groupBy(_.id)
.flatMapGroupsWithState(Update, ProcessingTimeTimeout("1 minute")) {
(id: Int, events: Iterator[ClusterHeartBeat], state: GroupState[ClusterState]) =>
... // check if cluster non-responsive for a while
}
E.g. Monitor health of Spark clusters
using custom stateful logic
Latency: ~10 seconds
Alerts
React if no heartbeat
from cluster for 1 min](https://crownmelresort.com/image.slidesharecdn.com/easyscalablefault-tolerantstreamprocessingwithstructuredstreaming-sparksummit2017-170608203443/75/Easy-scalable-fault-tolerant-stream-processing-with-structured-streaming-spark-summit-2017-57-2048.jpg)





The document discusses structured streaming with Apache Spark, focusing on its ease of use, scalability, and fault tolerance for stream processing applications. It highlights key features such as data integration from various sources, checkpointing for fault tolerance, and advanced transformations to handle complex workloads and data types. The presentation also covers practical examples of implementing streaming queries, event-time aggregations, and stateful processing with benefits for real-time analytics and decision-making.
































































































