

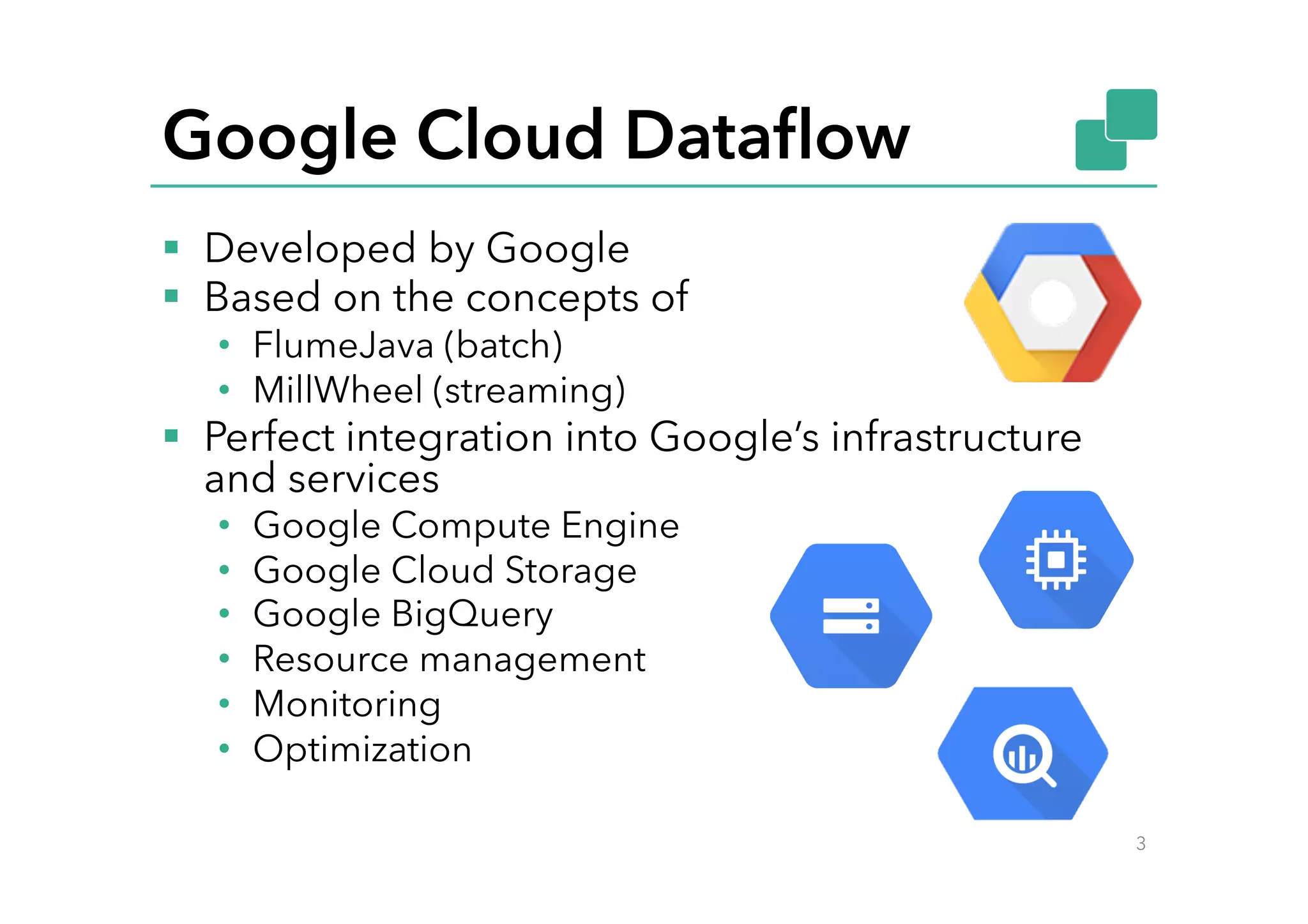

![WordCount in Dataflow #1
7
public static void main(String[] args) {
DataflowPipelineOptions options = PipelineOptionsFactory.create()
.as(DataflowPipelineOptions.class);
options.setRunner(DataflowPipelineRunner.class);
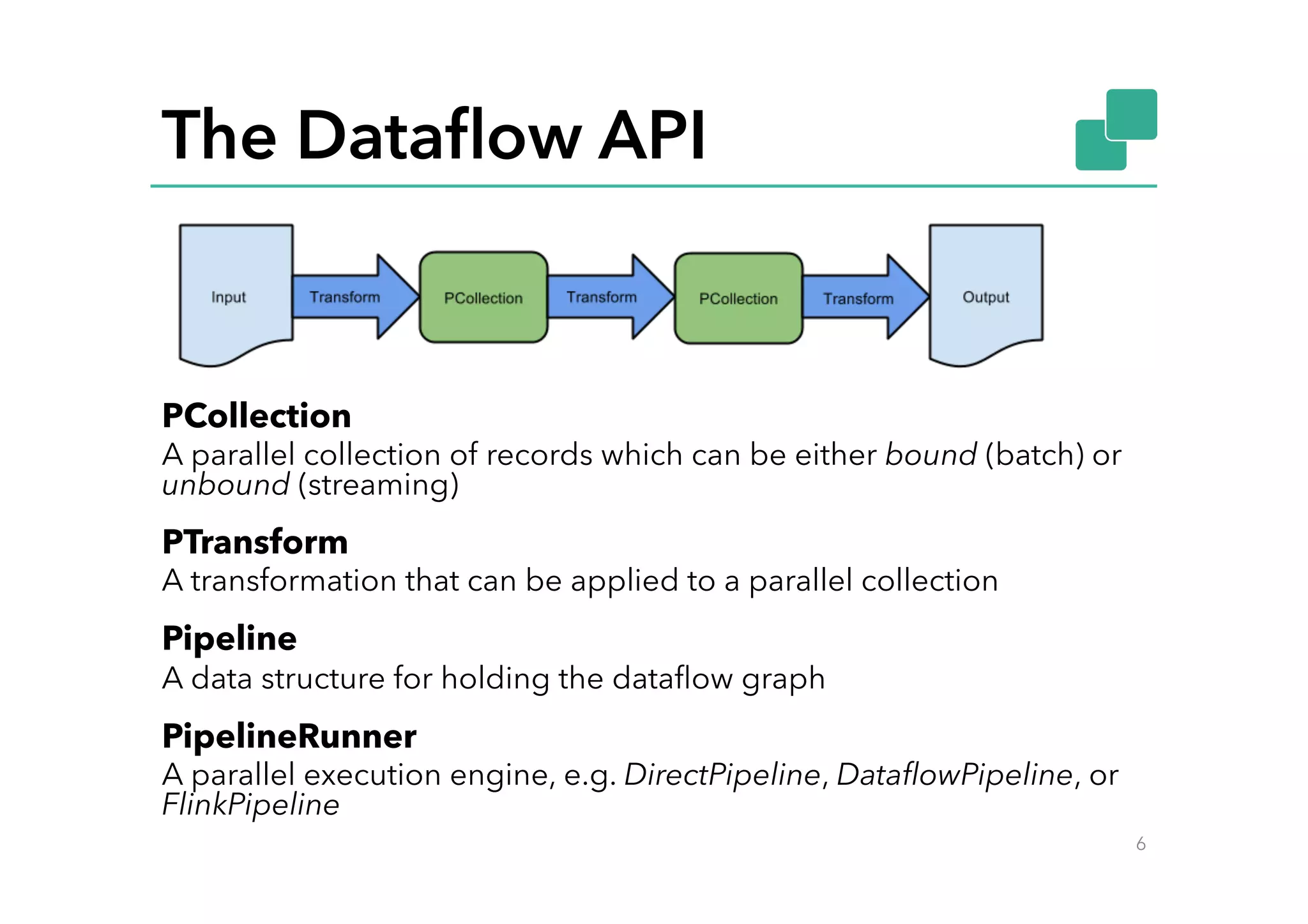
Pipeline p = Pipeline.create(options);
p.apply(TextIO.Read.from("gs://dataflow-samples/shakespeare/*"))
.apply(new CountWords())
.apply(TextIO.Write.to("gs://my-bucket/wordcounts"));
p.run();
}](https://image.slidesharecdn.com/googleclouddataflowontopofapacheflink-151019133340-lva1-app6892/75/Maximilian-Michels-Google-Cloud-Dataflow-on-Top-of-Apache-Flink-7-2048.jpg)

![Word Count Dataflow #3
public static class ExtractWordsFn extends DoFn<String, String> {
@Override
public void processElement(ProcessContext context) {
String[] words = context.element().split("[^a-zA-Z']+");
for (String word : words) {
if (!word.isEmpty()) {
context.output(word);
}
}
}
}
9
Extract
Words](https://image.slidesharecdn.com/googleclouddataflowontopofapacheflink-151019133340-lva1-app6892/75/Maximilian-Michels-Google-Cloud-Dataflow-on-Top-of-Apache-Flink-9-2048.jpg)


![From Dataflow to Flink
public class MinimalWordCount {
public static void main(String[] args) {
DataflowPipelineOptions options = PipelineOptionsFactory.create()
.as(DataflowPipelineOptions.class);
options.setRunner(BlockingDataflowPipelineRunner.class);
// Create the Pipeline object with the options we defined above.
Pipeline p = Pipeline.create(options);
// Apply the pipeline's transforms.
p.apply(TextIO.Read.from("gs://dataflow-samples/shakespeare/*"))
.apply(ParDo.named("ExtractWords").of(new DoFn<String, String>() {
private static final long serialVersionUID = 0;
@Override
public void processElement(ProcessContext c) {
for (String word : c.element().split("[^a-zA-Z']+")) {
if (!word.isEmpty()) {
c.output(word);
}
}
}
}))
.apply(Count.<String>perElement())
.apply(ParDo.named("FormatResults").of(new DoFn<KV<String, Long>,
String>() {
private static final long serialVersionUID = 0;
@Override
public void processElement(ProcessContext c) {
c.output(c.element().getKey() + ": " + c.element().getValue());
}
.apply(TextIO.Write.to("gs://my-bucket/wordcounts"));
// Run the pipeline.
p.run();
}
}
12
Dataflow
Flink
PCollec(on
DataSet
/
DataStream
PTransform
Operator
Pipeline
Execu(onEnvironment
PipelineRunner
Flink!
public class MinimalWordCount {
public static void main(String[] args) {
DataflowPipelineOptions options = PipelineOptionsFactory.create()
.as(DataflowPipelineOptions.class);
options.setRunner(BlockingDataflowPipelineRunner.class);
// Create the Pipeline object with the options we defined above.
Pipeline p = Pipeline.create(options);
// Apply the pipeline's transforms.
p.apply(TextIO.Read.from("gs://dataflow-samples/shakespeare/*"))
.apply(ParDo.named("ExtractWords").of(new DoFn<String, String>() {
private static final long serialVersionUID = 0;
@Override
public void processElement(ProcessContext c) {
for (String word : c.element().split("[^a-zA-Z']+")) {
if (!word.isEmpty()) {
c.output(word);
}
}
}
}))
.apply(Count.<String>perElement())
.apply(ParDo.named("FormatResults").of(new DoFn<KV<String, Long>,
String>() {
private static final long serialVersionUID = 0;
@Override
public void processElement(ProcessContext c) {
c.output(c.element().getKey() + ": " + c.element().getValue());
}
.apply(TextIO.Write.to("gs://my-bucket/wordcounts"));
// Run the pipeline.
p.run();
}
}](https://image.slidesharecdn.com/googleclouddataflowontopofapacheflink-151019133340-lva1-app6892/75/Maximilian-Michels-Google-Cloud-Dataflow-on-Top-of-Apache-Flink-12-2048.jpg)





















![WordCount in Dataflow #1
7
public static void main(String[] args) {
DataflowPipelineOptions options = PipelineOptionsFactory.create()
.as(DataflowPipelineOptions.class);
options.setRunner(DataflowPipelineRunner.class);
Pipeline p = Pipeline.create(options);
p.apply(TextIO.Read.from("gs://dataflow-samples/shakespeare/*"))
.apply(new CountWords())
.apply(TextIO.Write.to("gs://my-bucket/wordcounts"));
p.run();
}](https://crownmelresort.com/image.slidesharecdn.com/googleclouddataflowontopofapacheflink-151019133340-lva1-app6892/75/Maximilian-Michels-Google-Cloud-Dataflow-on-Top-of-Apache-Flink-7-2048.jpg)

![Word Count Dataflow #3
public static class ExtractWordsFn extends DoFn<String, String> {
@Override
public void processElement(ProcessContext context) {
String[] words = context.element().split("[^a-zA-Z']+");
for (String word : words) {
if (!word.isEmpty()) {
context.output(word);
}
}
}
}
9
Extract
Words](https://crownmelresort.com/image.slidesharecdn.com/googleclouddataflowontopofapacheflink-151019133340-lva1-app6892/75/Maximilian-Michels-Google-Cloud-Dataflow-on-Top-of-Apache-Flink-9-2048.jpg)


![From Dataflow to Flink
public class MinimalWordCount {
public static void main(String[] args) {
DataflowPipelineOptions options = PipelineOptionsFactory.create()
.as(DataflowPipelineOptions.class);
options.setRunner(BlockingDataflowPipelineRunner.class);
// Create the Pipeline object with the options we defined above.
Pipeline p = Pipeline.create(options);
// Apply the pipeline's transforms.
p.apply(TextIO.Read.from("gs://dataflow-samples/shakespeare/*"))
.apply(ParDo.named("ExtractWords").of(new DoFn<String, String>() {
private static final long serialVersionUID = 0;
@Override
public void processElement(ProcessContext c) {
for (String word : c.element().split("[^a-zA-Z']+")) {
if (!word.isEmpty()) {
c.output(word);
}
}
}
}))
.apply(Count.<String>perElement())
.apply(ParDo.named("FormatResults").of(new DoFn<KV<String, Long>,
String>() {
private static final long serialVersionUID = 0;
@Override
public void processElement(ProcessContext c) {
c.output(c.element().getKey() + ": " + c.element().getValue());
}
.apply(TextIO.Write.to("gs://my-bucket/wordcounts"));
// Run the pipeline.
p.run();
}
}
12
Dataflow
Flink
PCollec(on
DataSet
/
DataStream
PTransform
Operator
Pipeline
Execu(onEnvironment
PipelineRunner
Flink!
public class MinimalWordCount {
public static void main(String[] args) {
DataflowPipelineOptions options = PipelineOptionsFactory.create()
.as(DataflowPipelineOptions.class);
options.setRunner(BlockingDataflowPipelineRunner.class);
// Create the Pipeline object with the options we defined above.
Pipeline p = Pipeline.create(options);
// Apply the pipeline's transforms.
p.apply(TextIO.Read.from("gs://dataflow-samples/shakespeare/*"))
.apply(ParDo.named("ExtractWords").of(new DoFn<String, String>() {
private static final long serialVersionUID = 0;
@Override
public void processElement(ProcessContext c) {
for (String word : c.element().split("[^a-zA-Z']+")) {
if (!word.isEmpty()) {
c.output(word);
}
}
}
}))
.apply(Count.<String>perElement())
.apply(ParDo.named("FormatResults").of(new DoFn<KV<String, Long>,
String>() {
private static final long serialVersionUID = 0;
@Override
public void processElement(ProcessContext c) {
c.output(c.element().getKey() + ": " + c.element().getValue());
}
.apply(TextIO.Write.to("gs://my-bucket/wordcounts"));
// Run the pipeline.
p.run();
}
}](https://crownmelresort.com/image.slidesharecdn.com/googleclouddataflowontopofapacheflink-151019133340-lva1-app6892/75/Maximilian-Michels-Google-Cloud-Dataflow-on-Top-of-Apache-Flink-12-2048.jpg)






















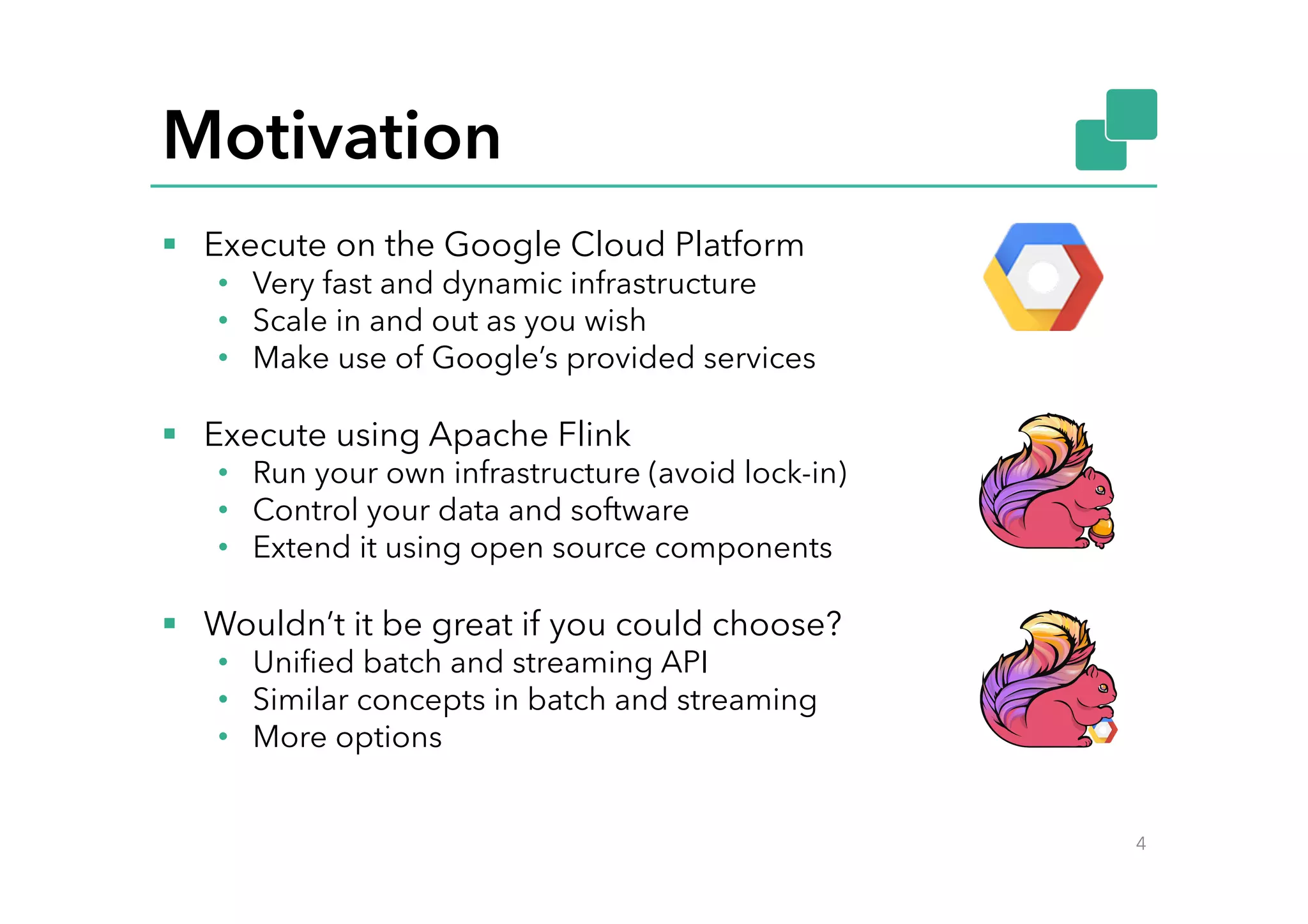
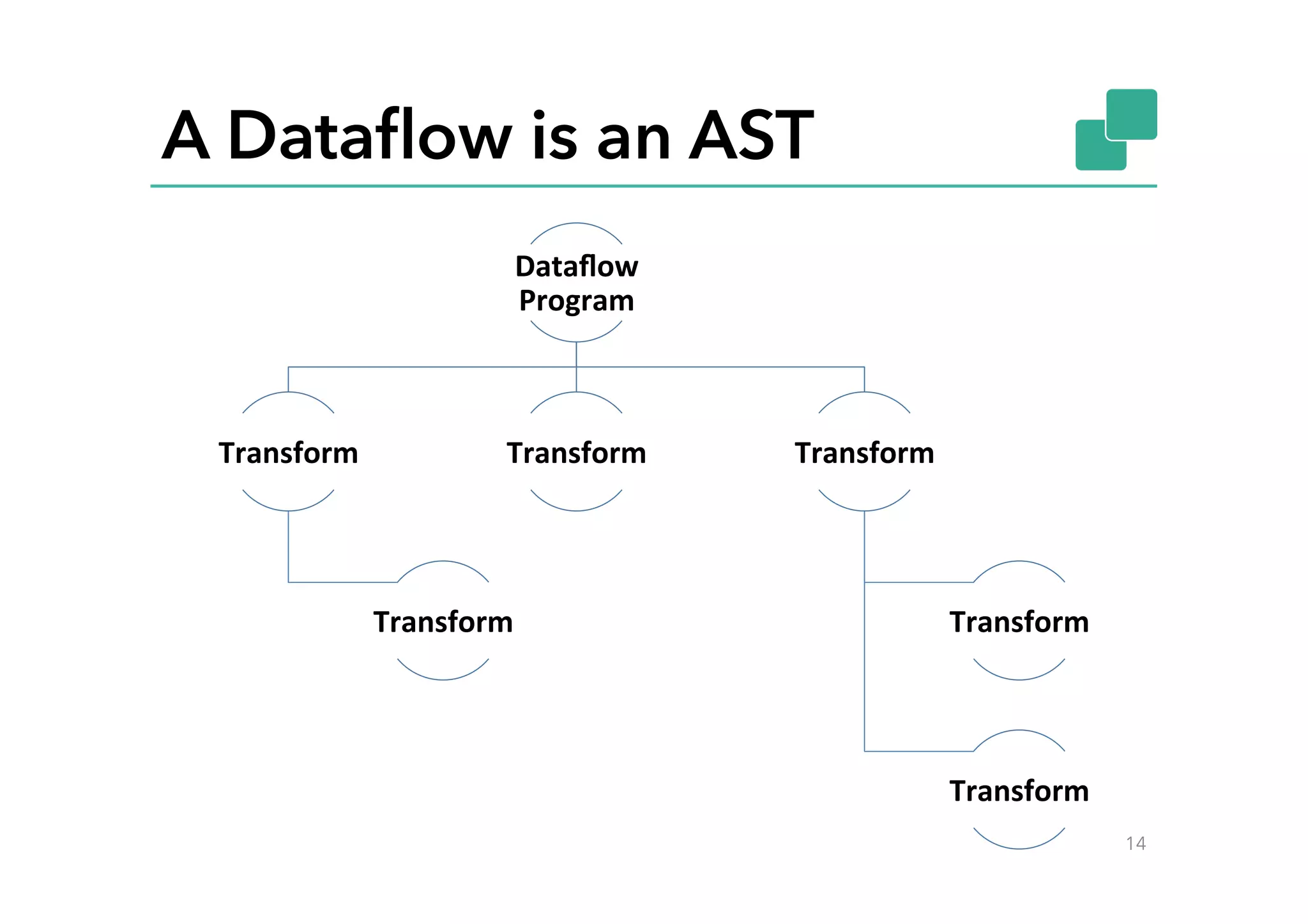
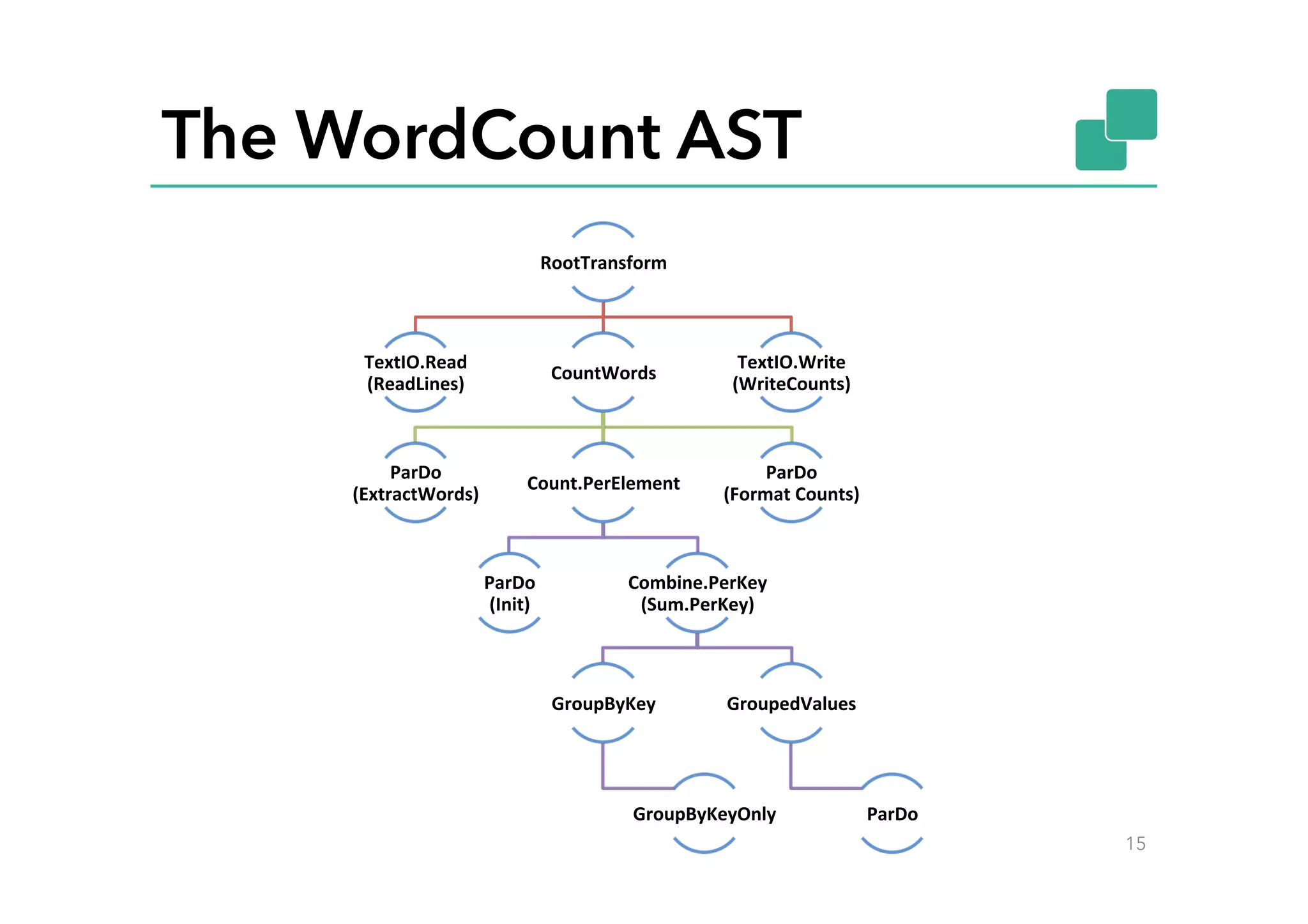
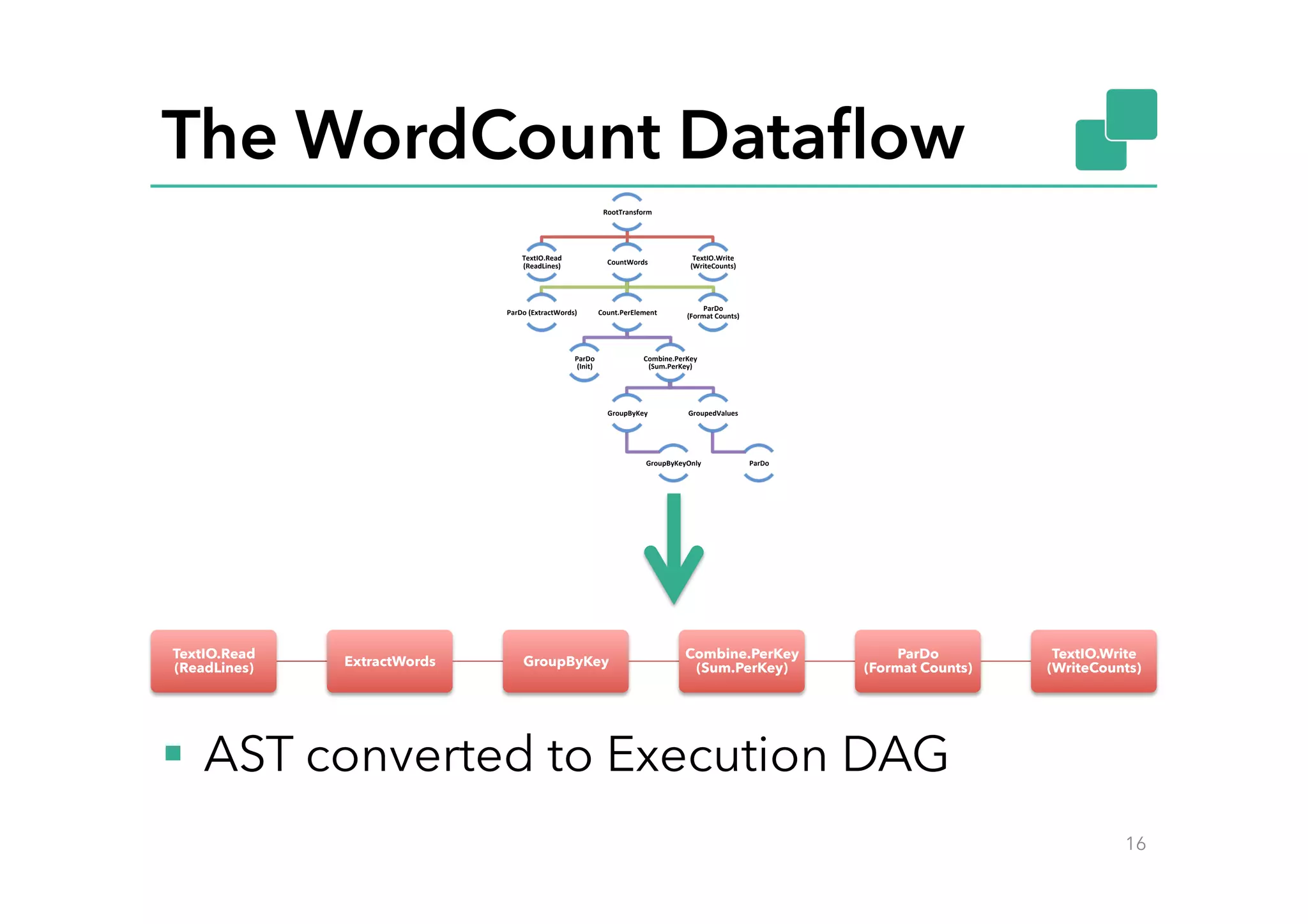
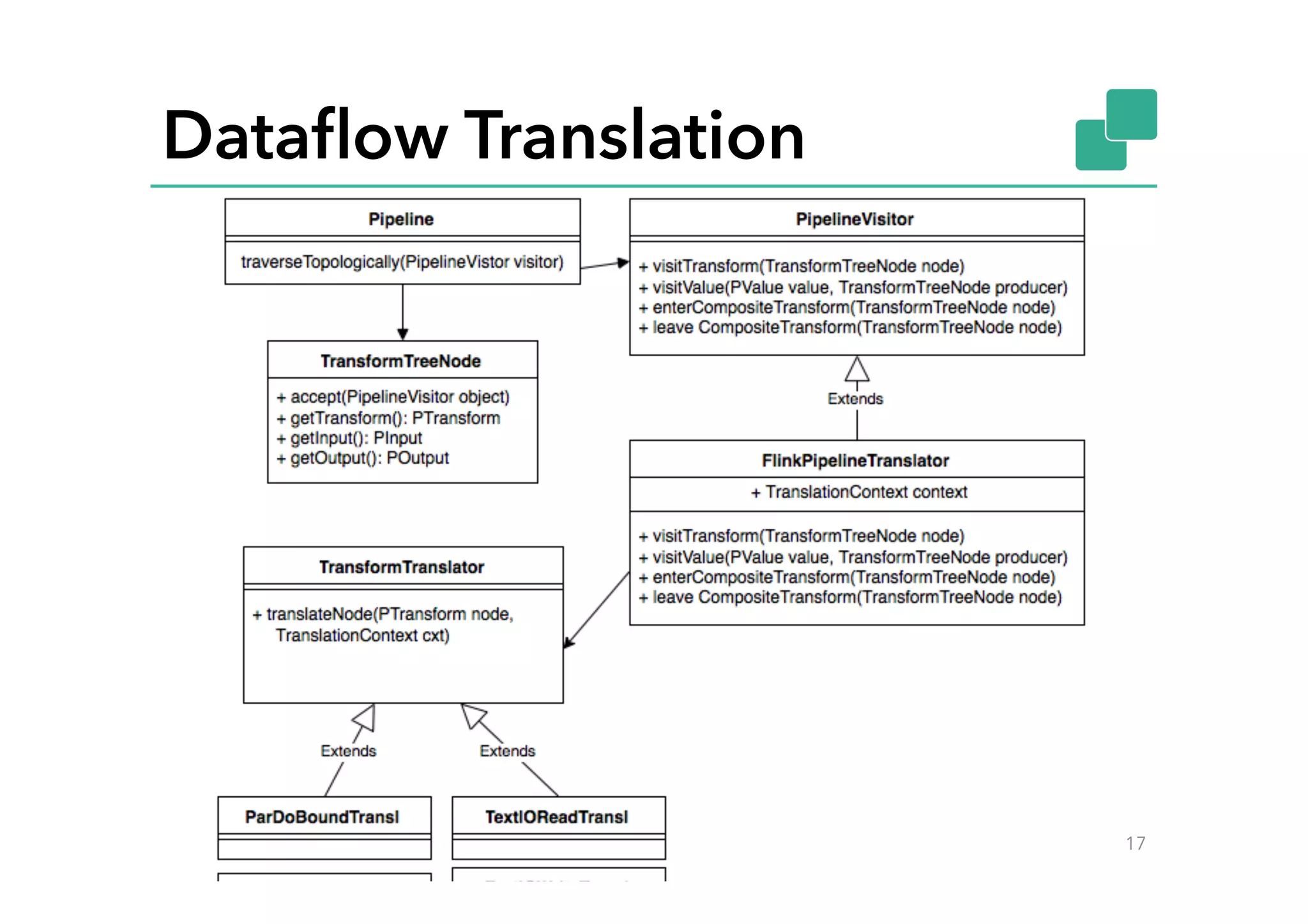
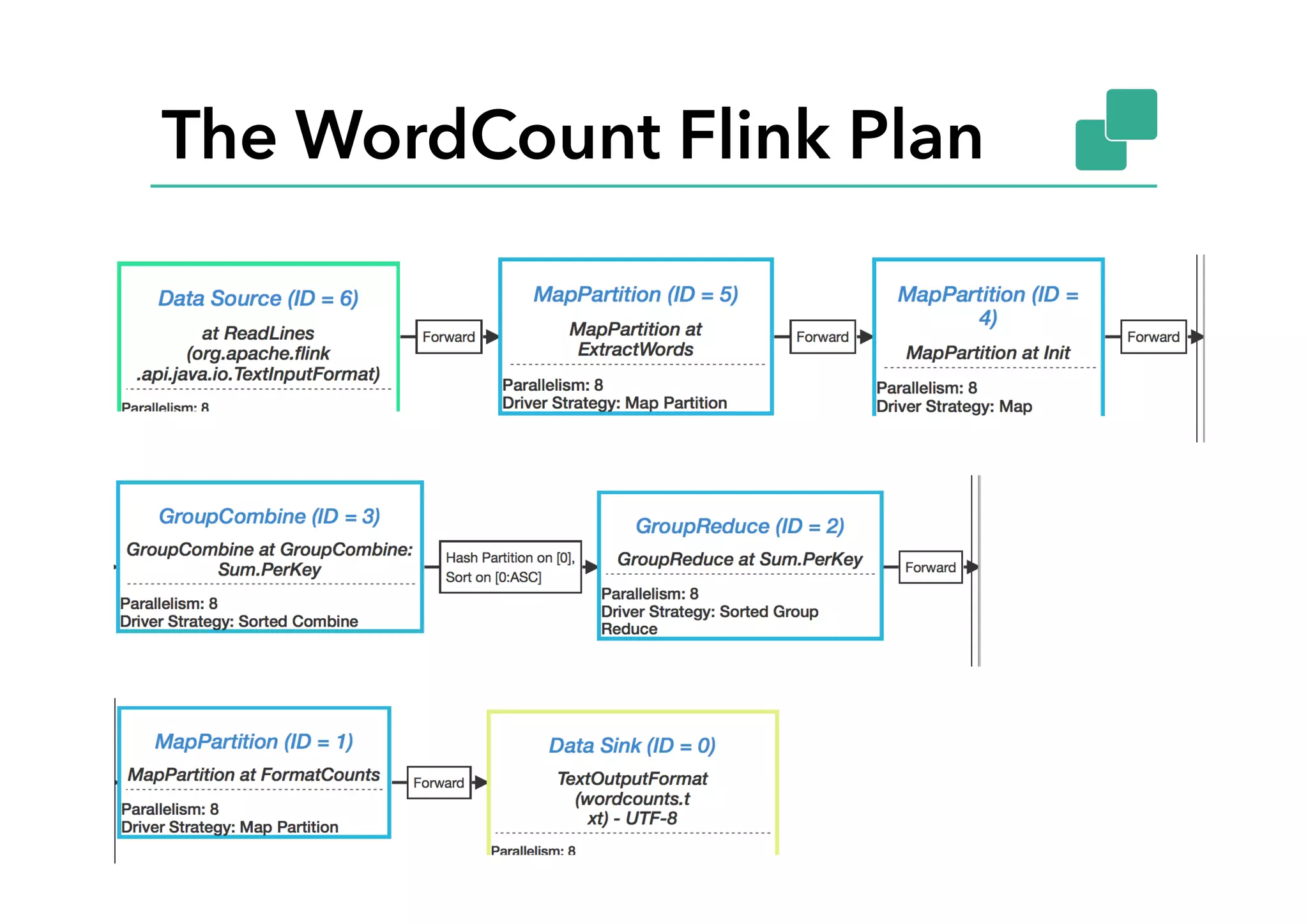
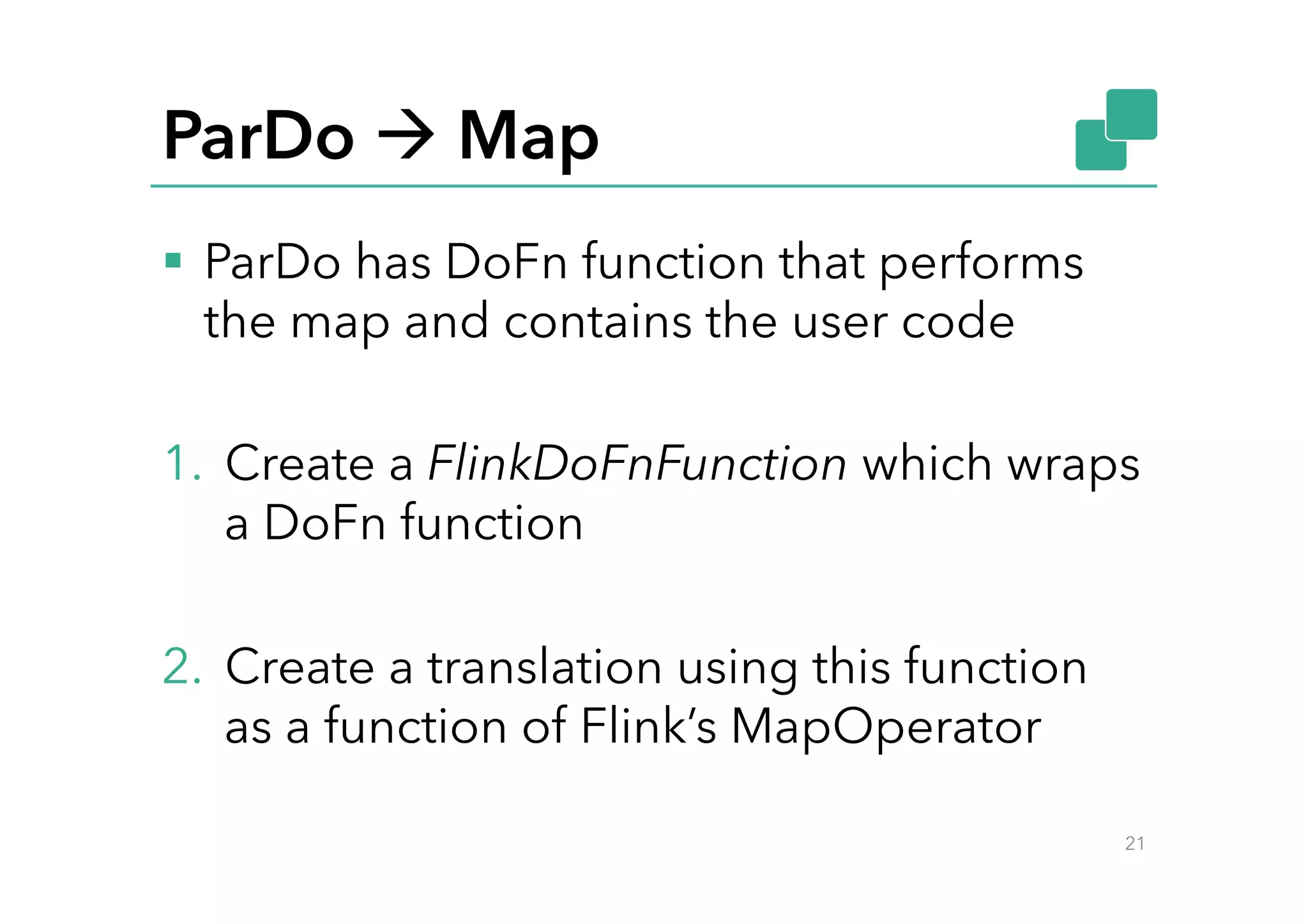
This document discusses Google Cloud Dataflow and how it can be executed using Apache Flink. It provides an overview of Dataflow and its API, which is similar to batch and streaming concepts in Flink. It then describes how a Dataflow program is translated to an Abstract Syntax Tree (AST) and how the AST is converted to a Flink execution graph by implementing translators for specific Dataflow transforms like ParDo and Combine. Finally, it mentions the FlinkPipelineRunner that is available on GitHub to execute Dataflow pipelines using Flink.











































































































