






![Technology inside Flink
Technology inspired by compilers +
MPP databases + distributed systems
For ease of use, reliable performance,
and scalability
case class Path (from: Long, to:
Long)
val tc = edges.iterate(10) {
paths: DataSet[Path] =>
val next = paths
.join(edges)
.where("to")
.equalTo("from") {
(path, edge) =>
Path(path.from, edge.to)
}
.union(paths)
.distinct()
next
}
Cost-based
optimizer
Type extraction
stack
Memory
manager
Out-of-core
algos
real-time
streaming
Task
scheduling
Recovery
metadata
Data
serialization
stack
Streaming
network
stack
...
Pre-flight
(client) Master
Workers](https://image.slidesharecdn.com/flinkyahoomeetup-150123191312-conversion-gate02/75/January-2015-HUG-Apache-Flink-Fast-and-reliable-large-scale-data-processing-9-2048.jpg)






![Example: Transitive Closure
20
case class Path (from: Long, to: Long)
val env =
ExecutionEnvironment.getExecutionEnvironment
val edges = ...
val tc = edges.iterate (10) { paths: DataSet[Path] =>
val next = paths
.join(edges).where("to").equalTo("from") {
(path, edge) => Path(path.from, edge.to)
}
.union(paths).distinct()
next
}
tc.print()
env.execute()](https://image.slidesharecdn.com/flinkyahoomeetup-150123191312-conversion-gate02/75/January-2015-HUG-Apache-Flink-Fast-and-reliable-large-scale-data-processing-20-2048.jpg)











![Technology inside Flink
Technology inspired by compilers +
MPP databases + distributed systems
For ease of use, reliable performance,
and scalability
case class Path (from: Long, to:
Long)
val tc = edges.iterate(10) {
paths: DataSet[Path] =>
val next = paths
.join(edges)
.where("to")
.equalTo("from") {
(path, edge) =>
Path(path.from, edge.to)
}
.union(paths)
.distinct()
next
}
Cost-based
optimizer
Type extraction
stack
Memory
manager
Out-of-core
algos
real-time
streaming
Task
scheduling
Recovery
metadata
Data
serialization
stack
Streaming
network
stack
...
Pre-flight
(client) Master
Workers](https://crownmelresort.com/image.slidesharecdn.com/flinkyahoomeetup-150123191312-conversion-gate02/75/January-2015-HUG-Apache-Flink-Fast-and-reliable-large-scale-data-processing-9-2048.jpg)










![Example: Transitive Closure
20
case class Path (from: Long, to: Long)
val env =
ExecutionEnvironment.getExecutionEnvironment
val edges = ...
val tc = edges.iterate (10) { paths: DataSet[Path] =>
val next = paths
.join(edges).where("to").equalTo("from") {
(path, edge) => Path(path.from, edge.to)
}
.union(paths).distinct()
next
}
tc.print()
env.execute()](https://crownmelresort.com/image.slidesharecdn.com/flinkyahoomeetup-150123191312-conversion-gate02/75/January-2015-HUG-Apache-Flink-Fast-and-reliable-large-scale-data-processing-20-2048.jpg)









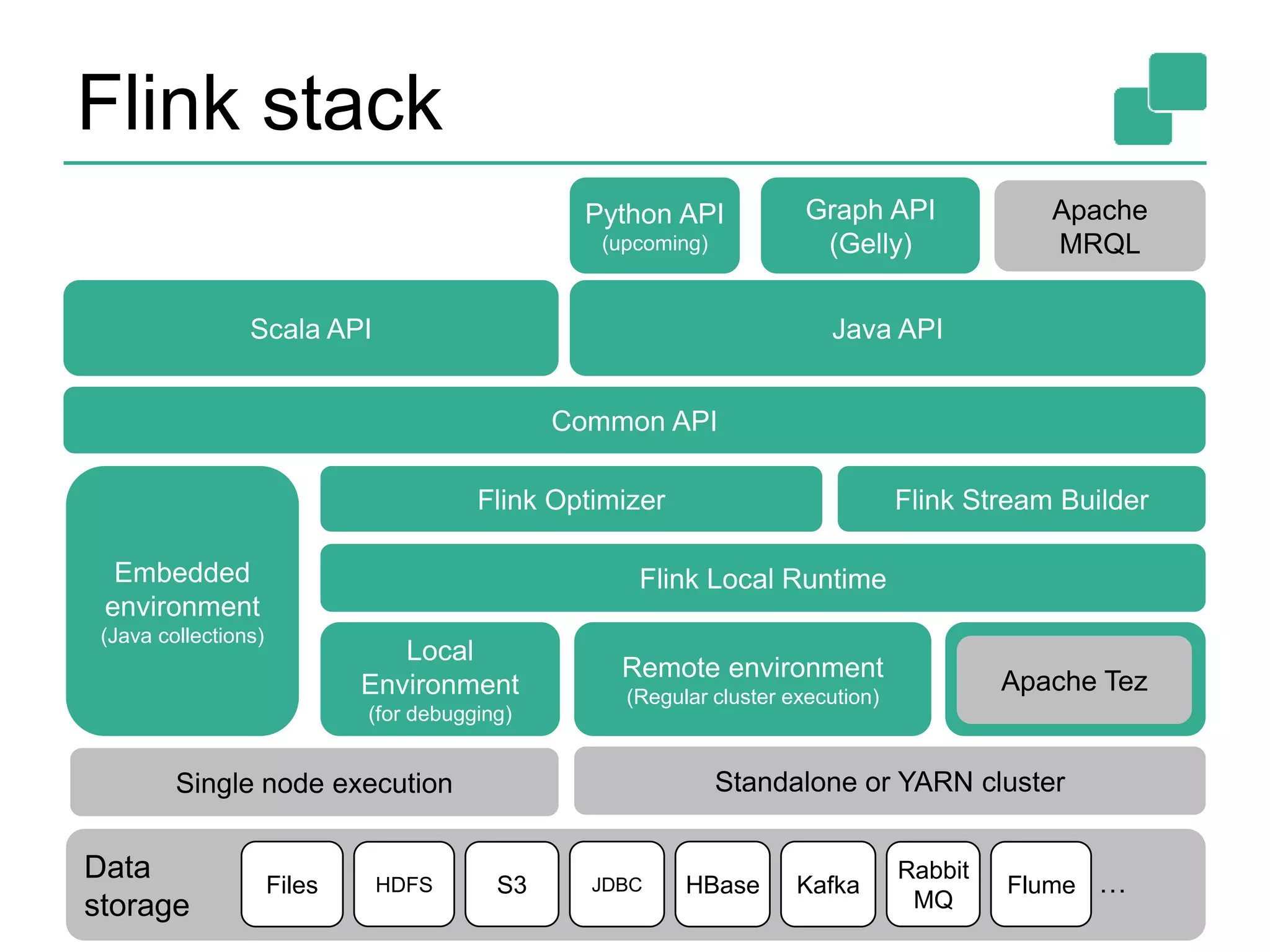
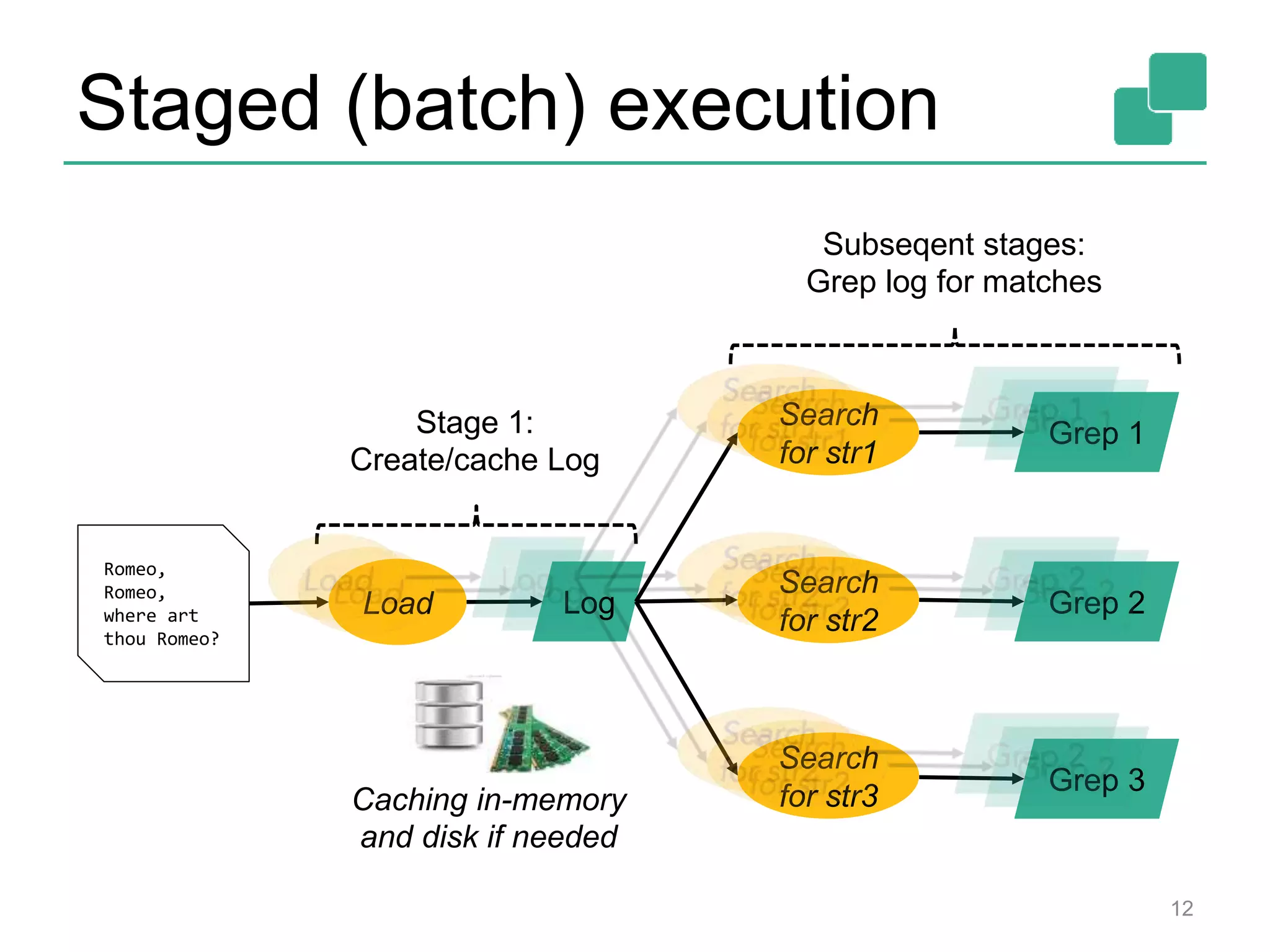
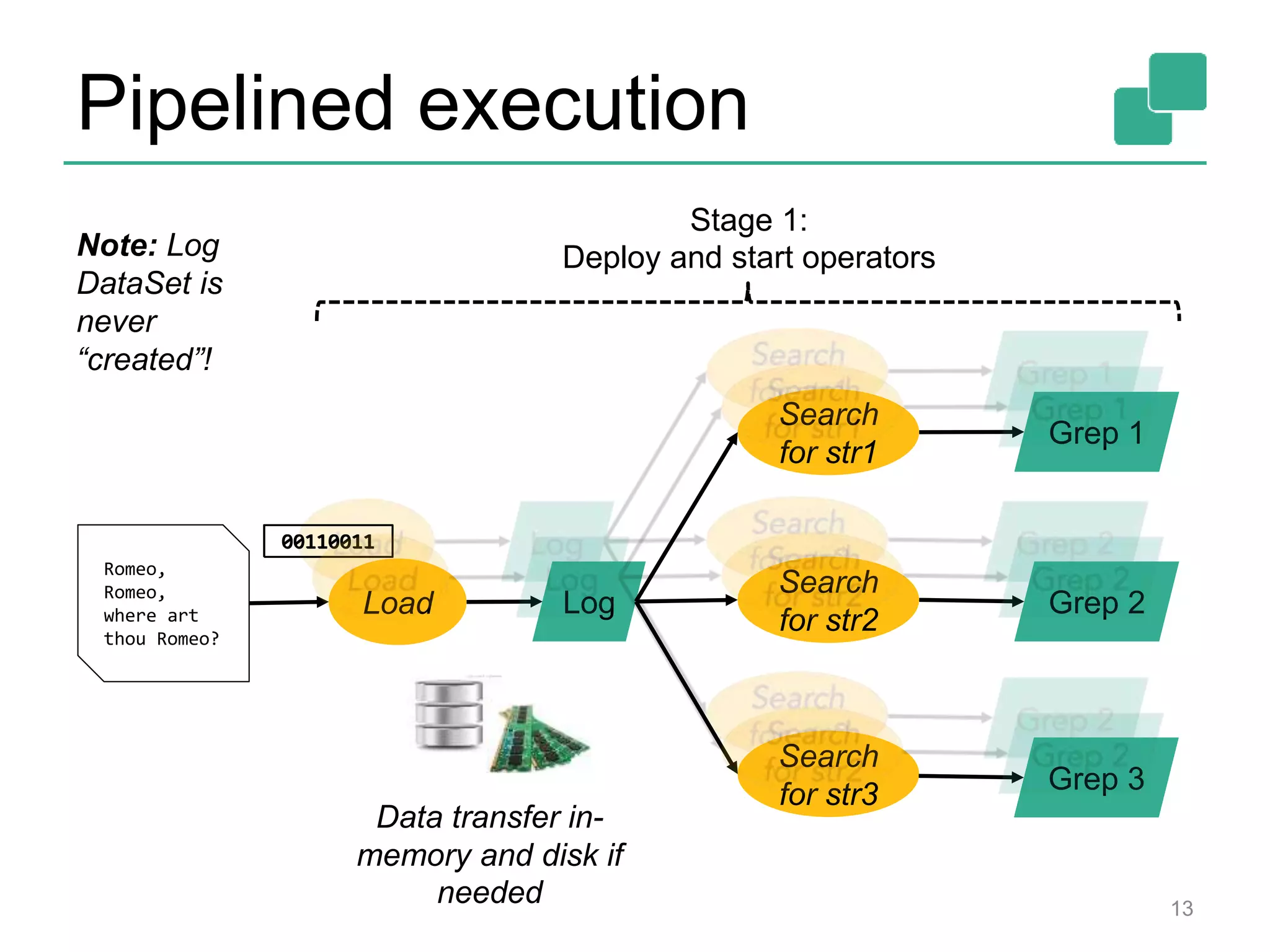
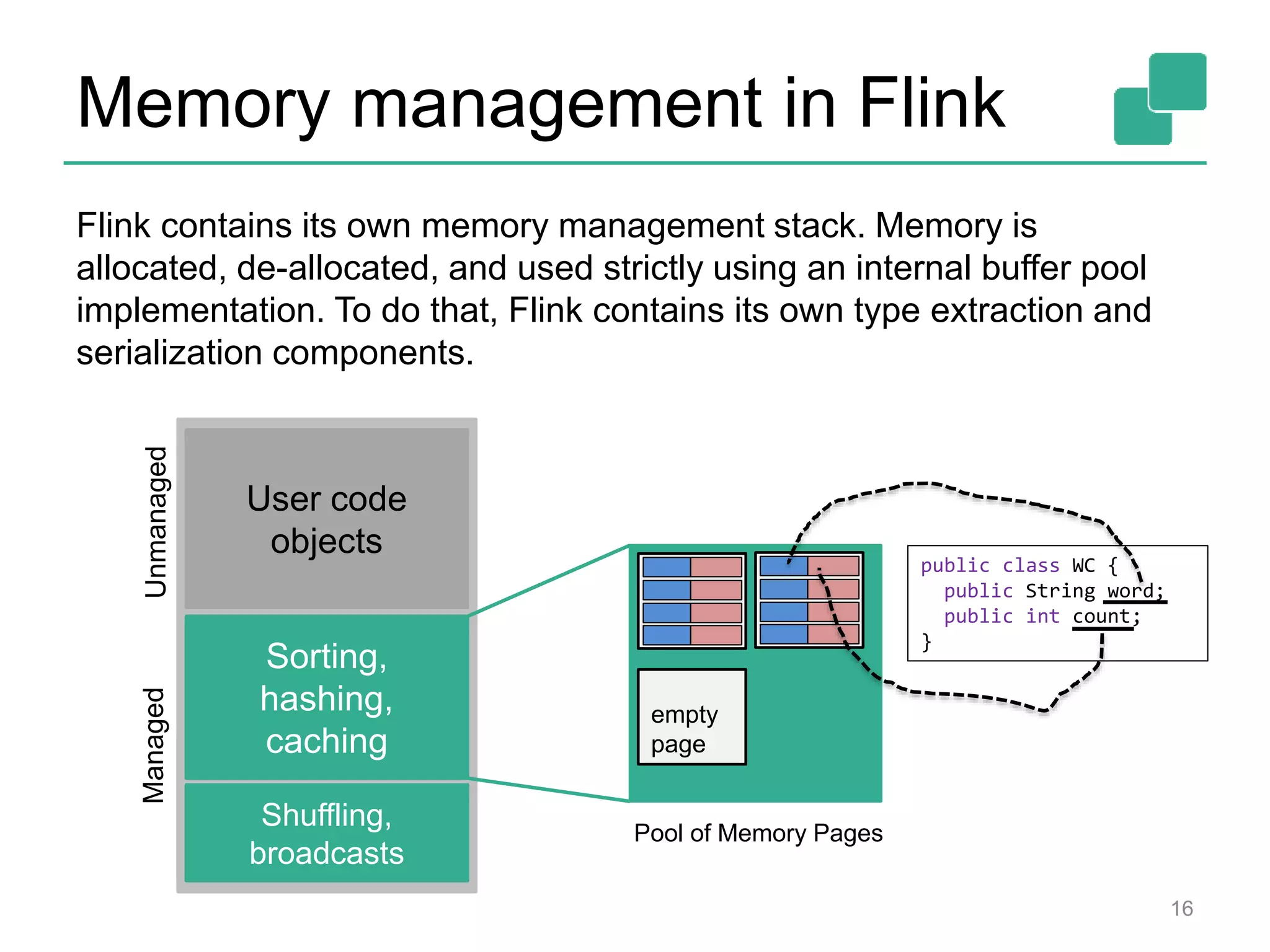
Apache Flink is a data processing framework that offers a unified programming model for batch and real-time streaming analysis, featuring a robust execution backend with true streaming capabilities and a cost-based optimizer. It supports a range of APIs in Java, Scala, and Python, and can integrate with various data sources while managing memory and execution efficiently. The framework's roadmap includes plans for enhanced batch and streaming functions, machine learning libraries, and improvements in graph processing.











































































































