





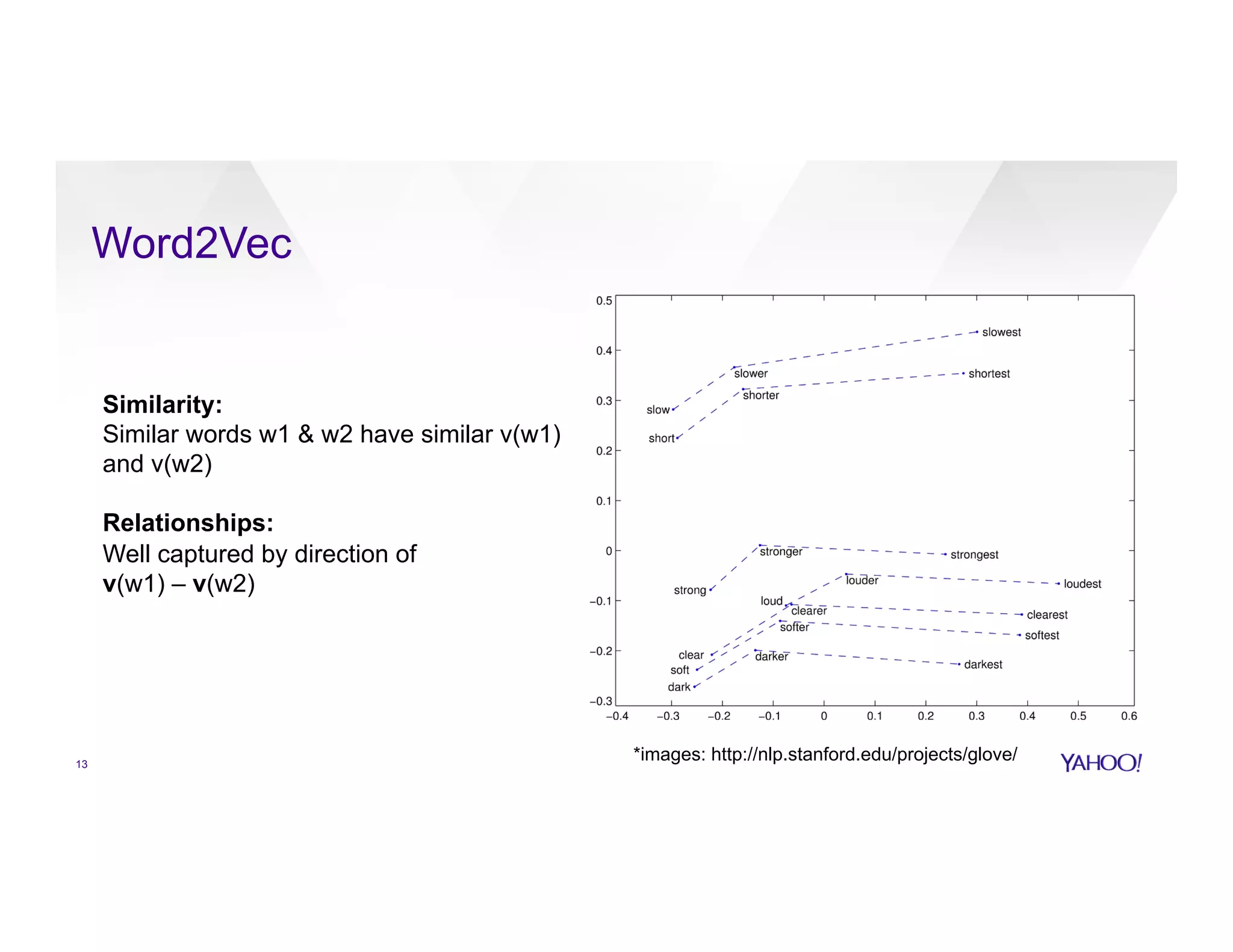
![Algorithm 1: Word2Vec (arXiv:1301.3781)
v(paris) = [0.13, -0.4, 0.22, …., -0.45]
v(lion) = [-0.23, -0.1, 0.98, …., 0.65]
v(quark) = [1.4, 0.32, -0.01, …, 0.023]
…
• compute vector of words
• captures word semantics](https://image.slidesharecdn.com/2017junmlusecasetechnology-170622221201/75/Jun-2017-HUG-Large-Scale-Machine-Learning-Use-Cases-and-Technologies-12-2048.jpg)



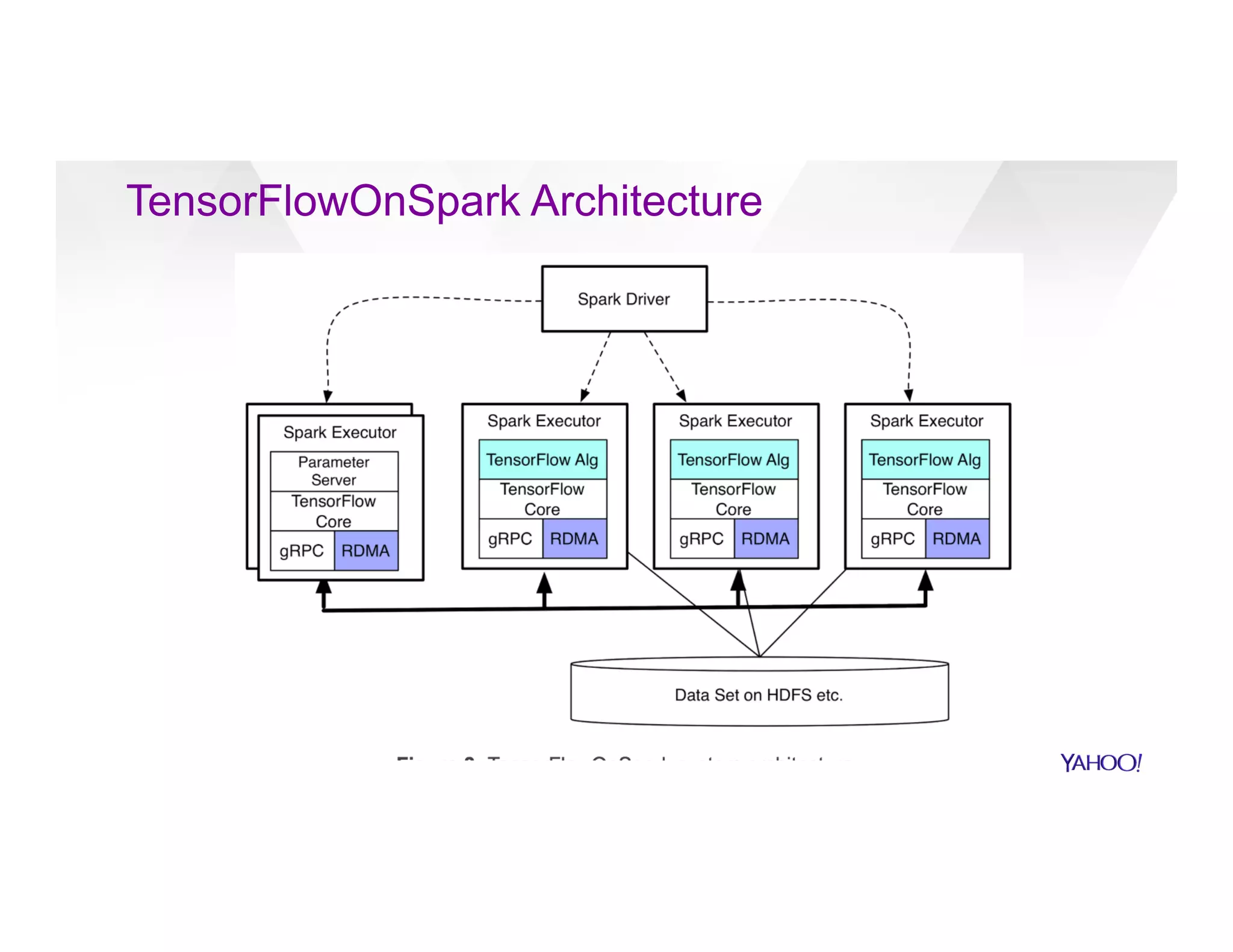
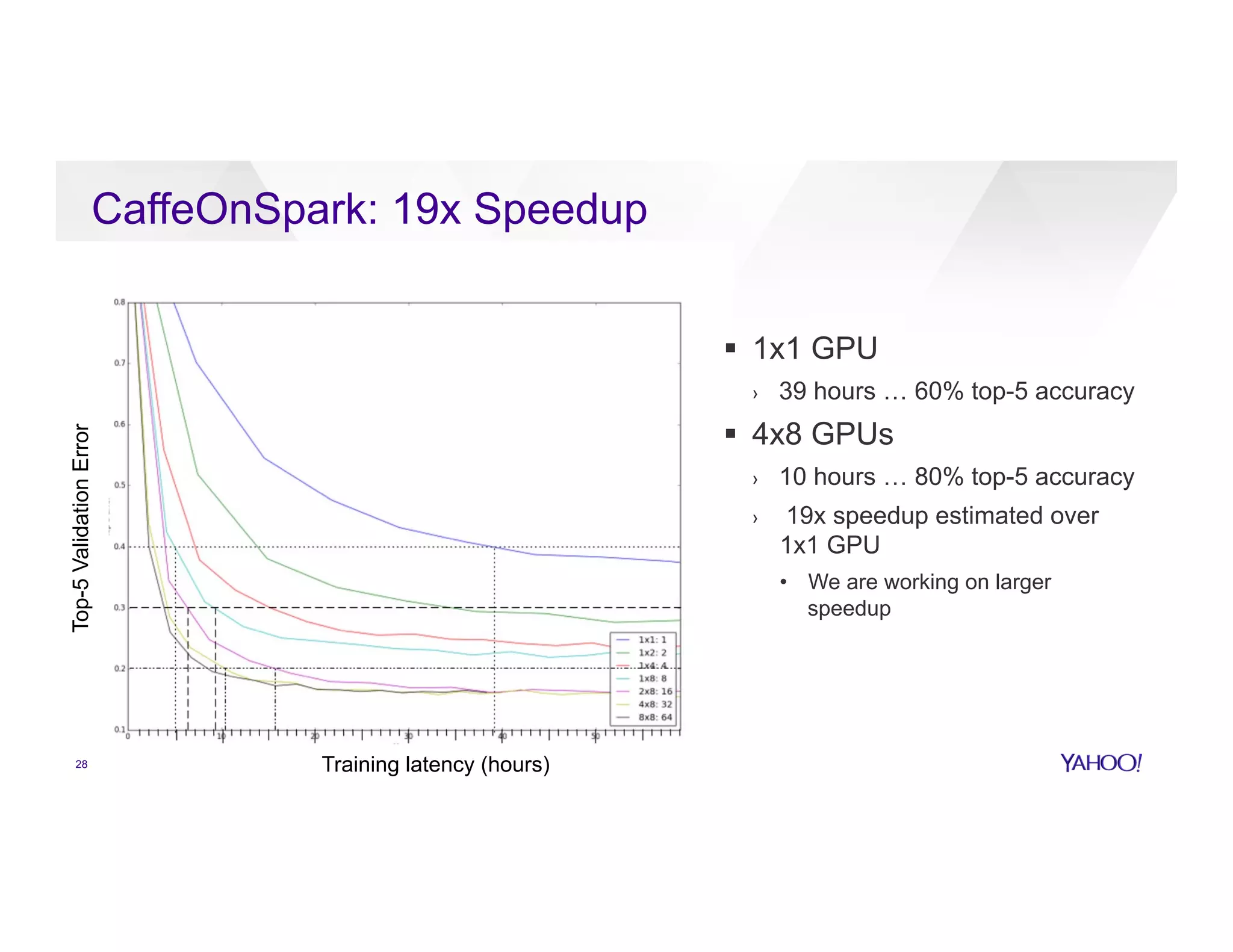
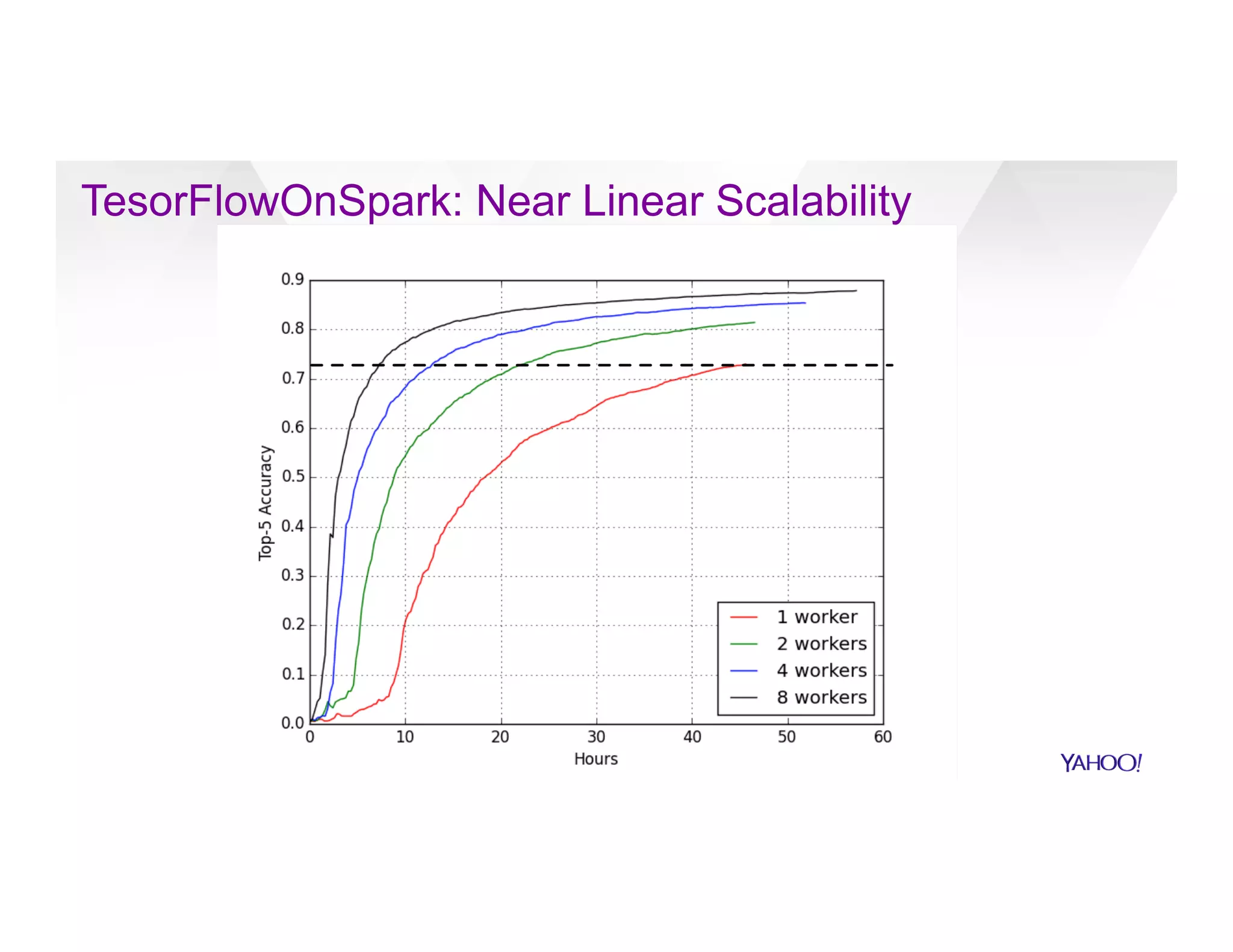














![Algorithm 1: Word2Vec (arXiv:1301.3781)
v(paris) = [0.13, -0.4, 0.22, …., -0.45]
v(lion) = [-0.23, -0.1, 0.98, …., 0.65]
v(quark) = [1.4, 0.32, -0.01, …, 0.023]
…
• compute vector of words
• captures word semantics](https://crownmelresort.com/image.slidesharecdn.com/2017junmlusecasetechnology-170622221201/75/Jun-2017-HUG-Large-Scale-Machine-Learning-Use-Cases-and-Technologies-12-2048.jpg)





















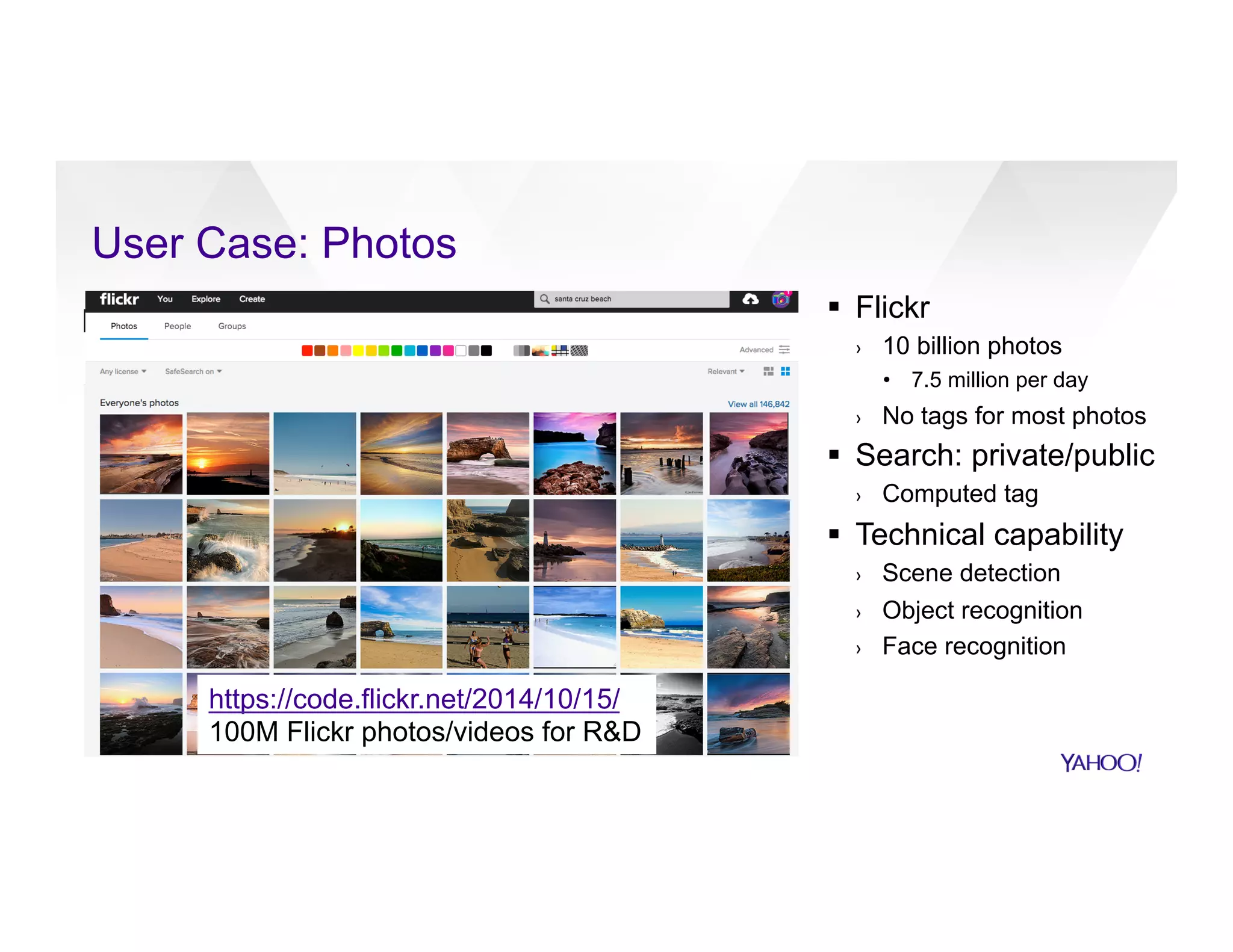
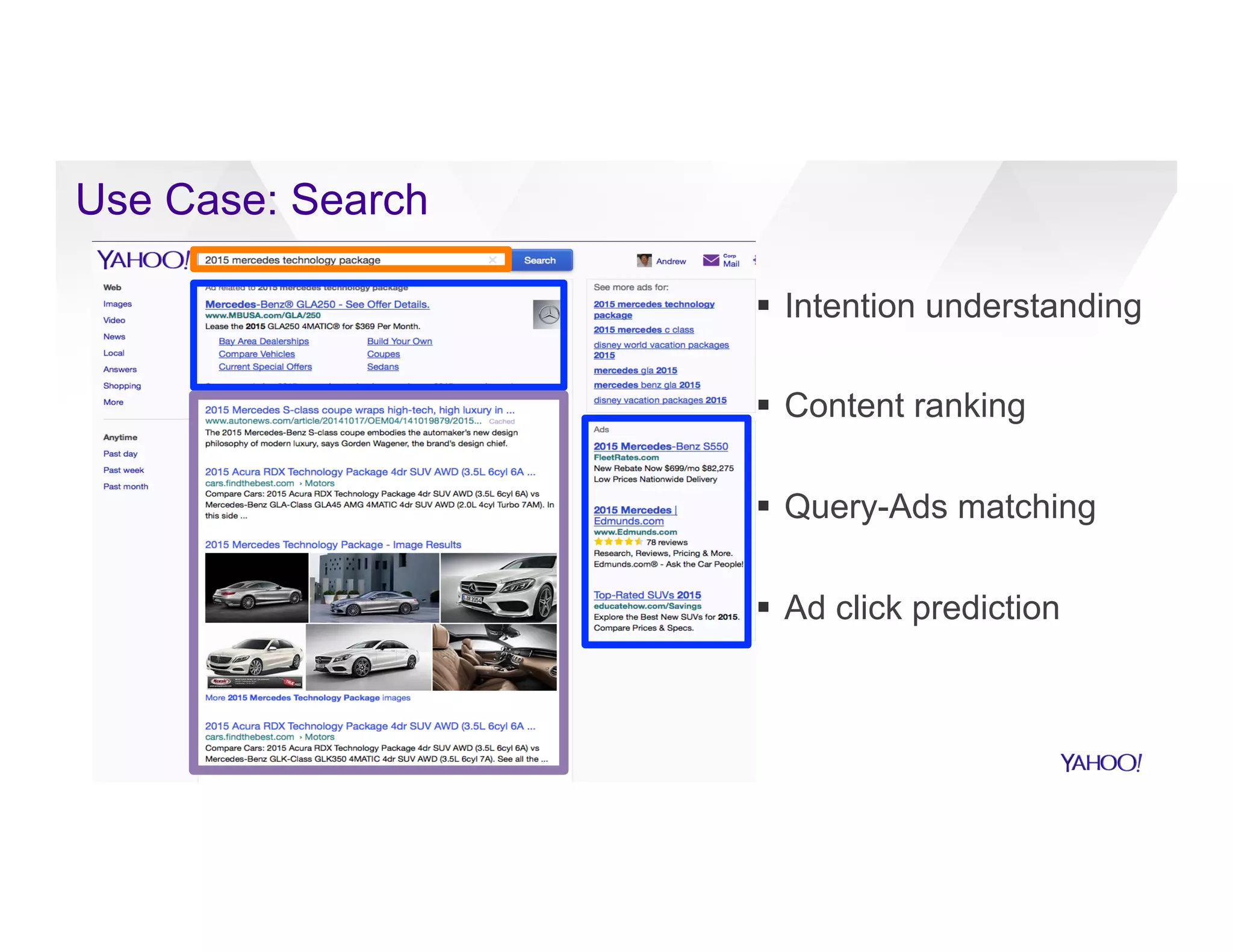
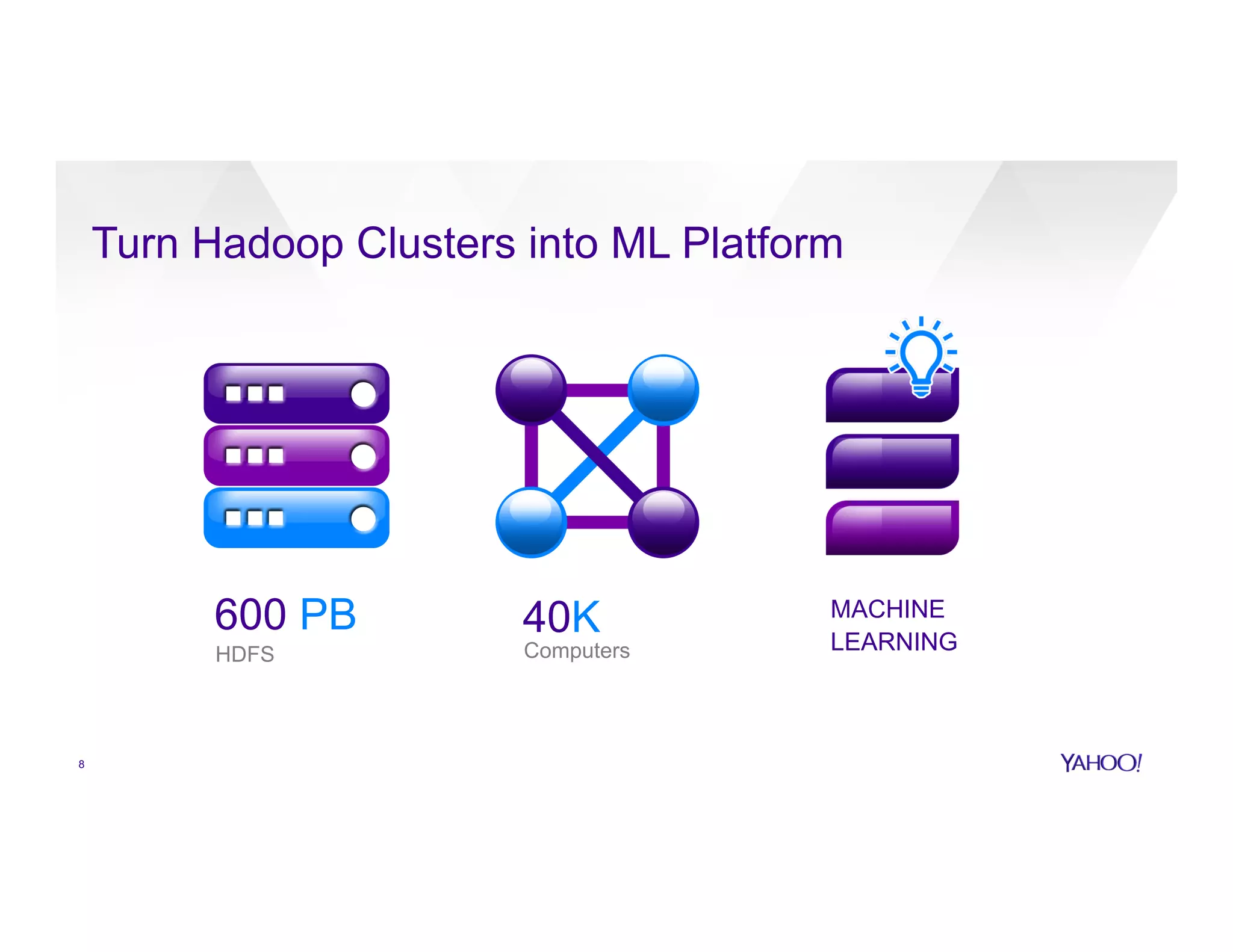
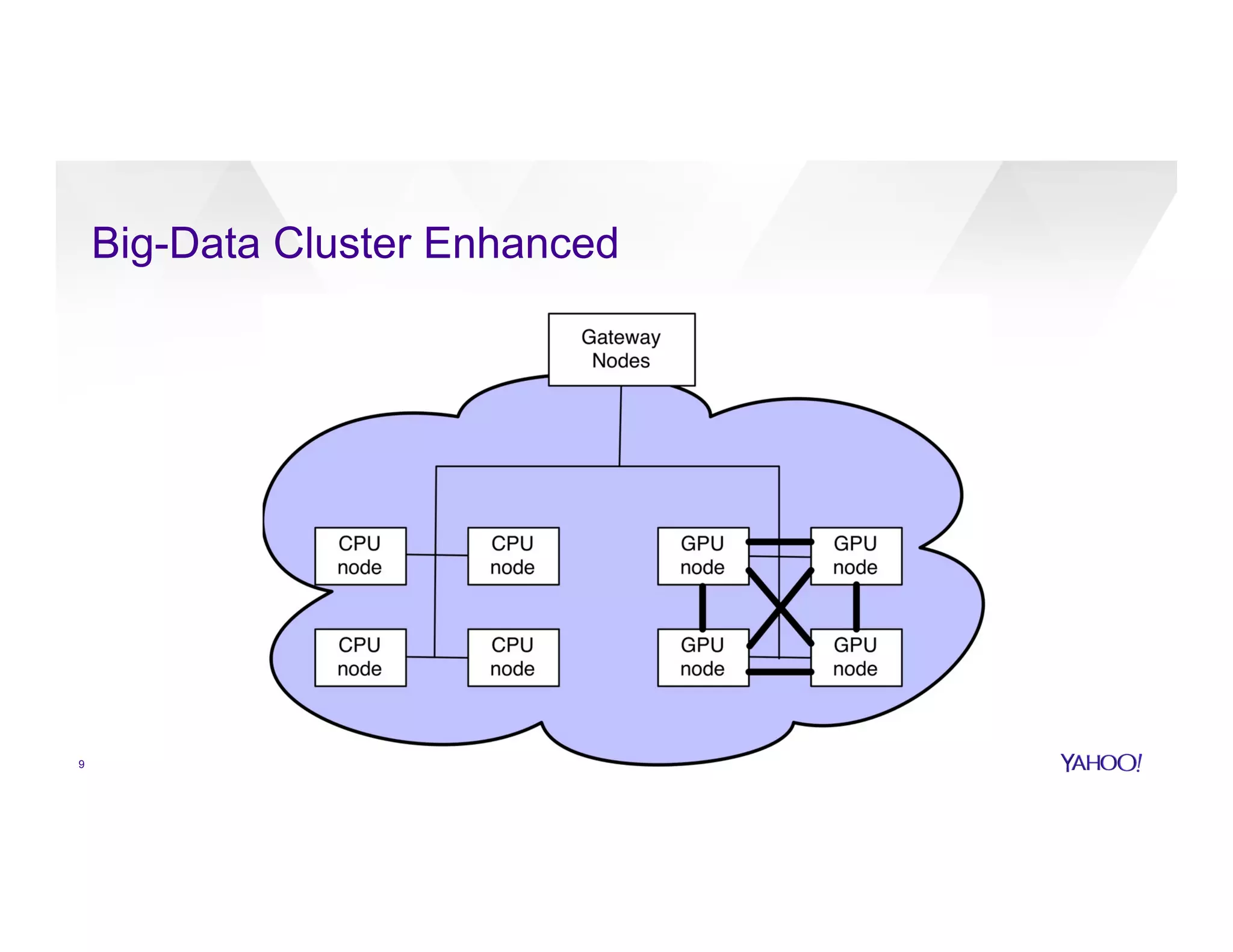
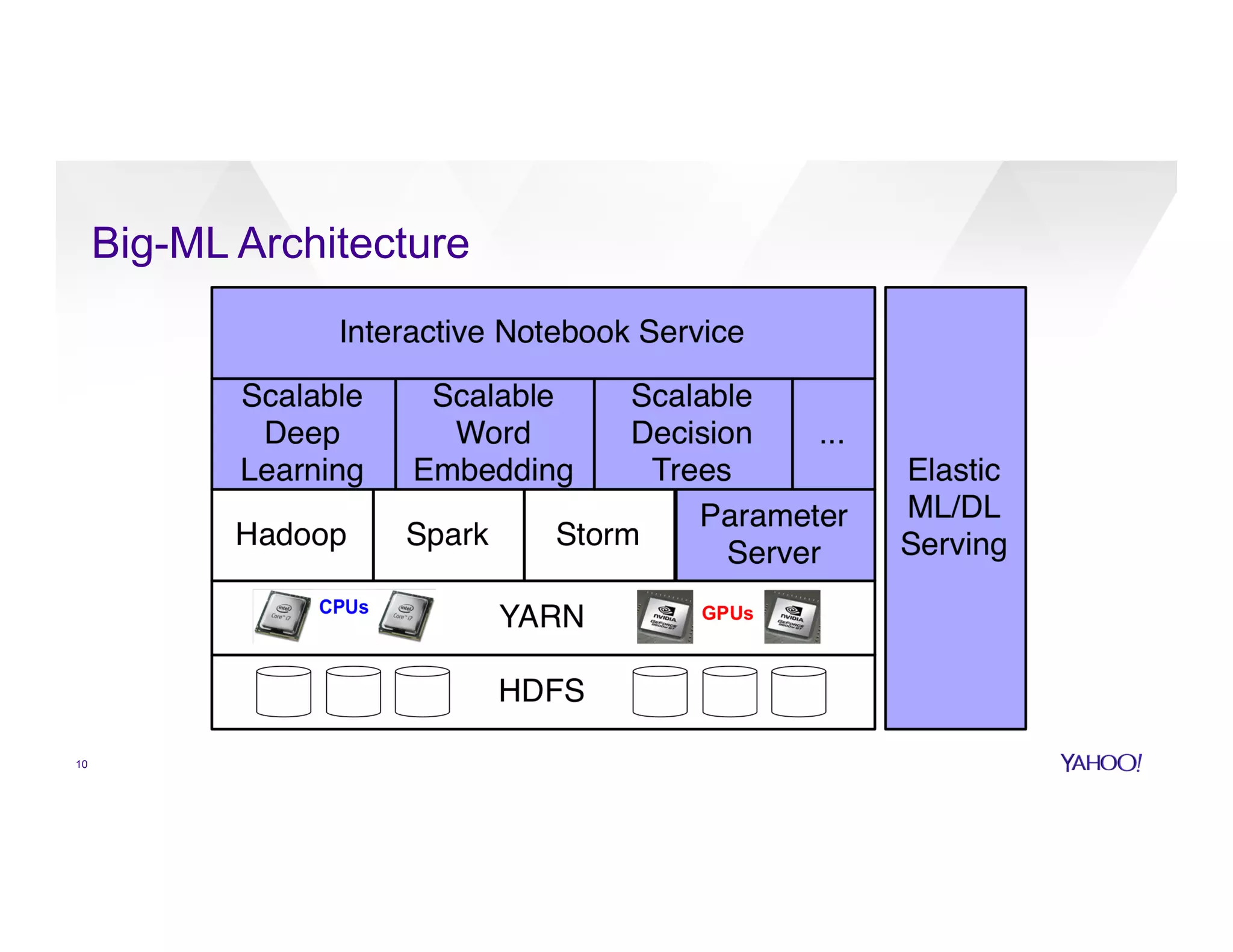
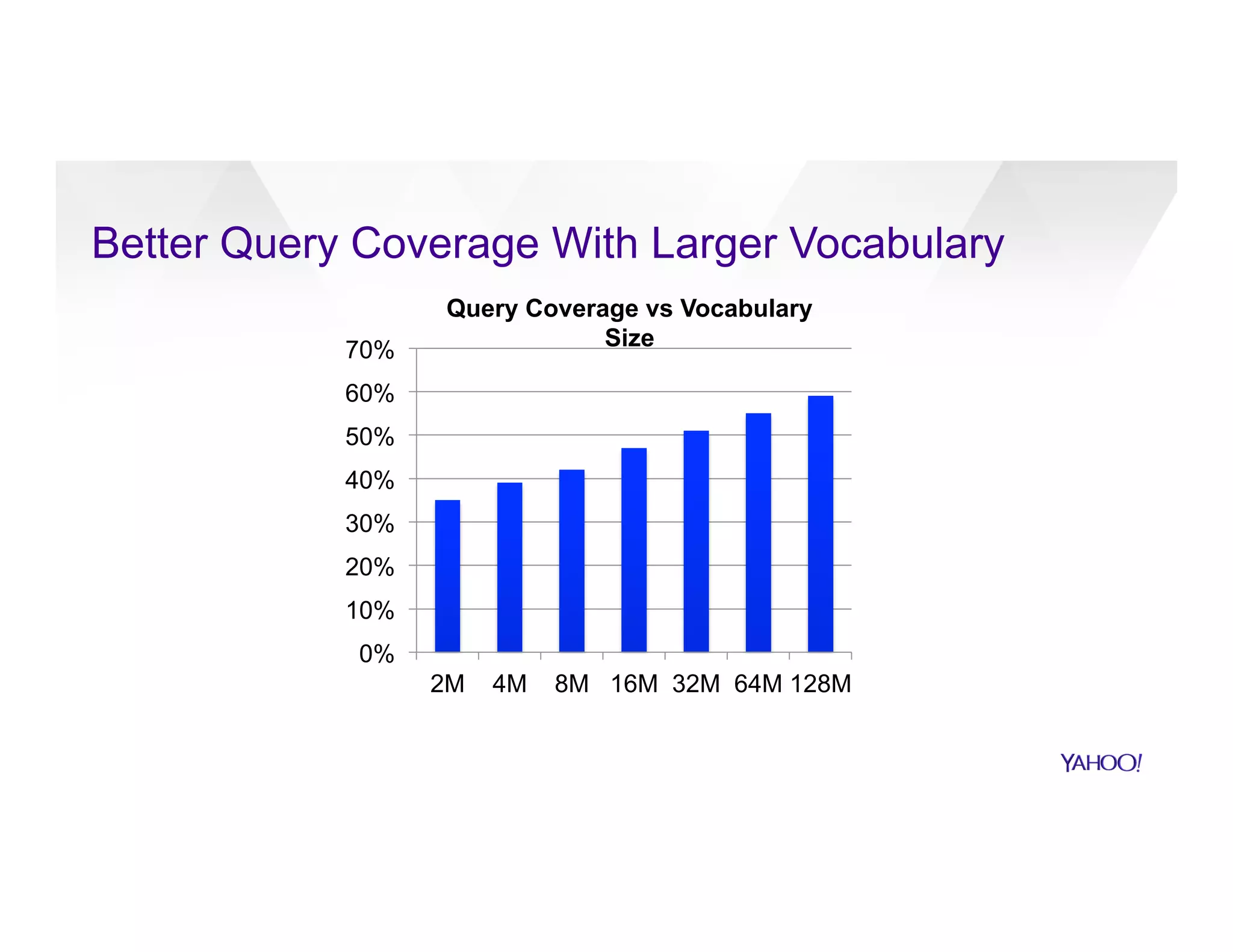
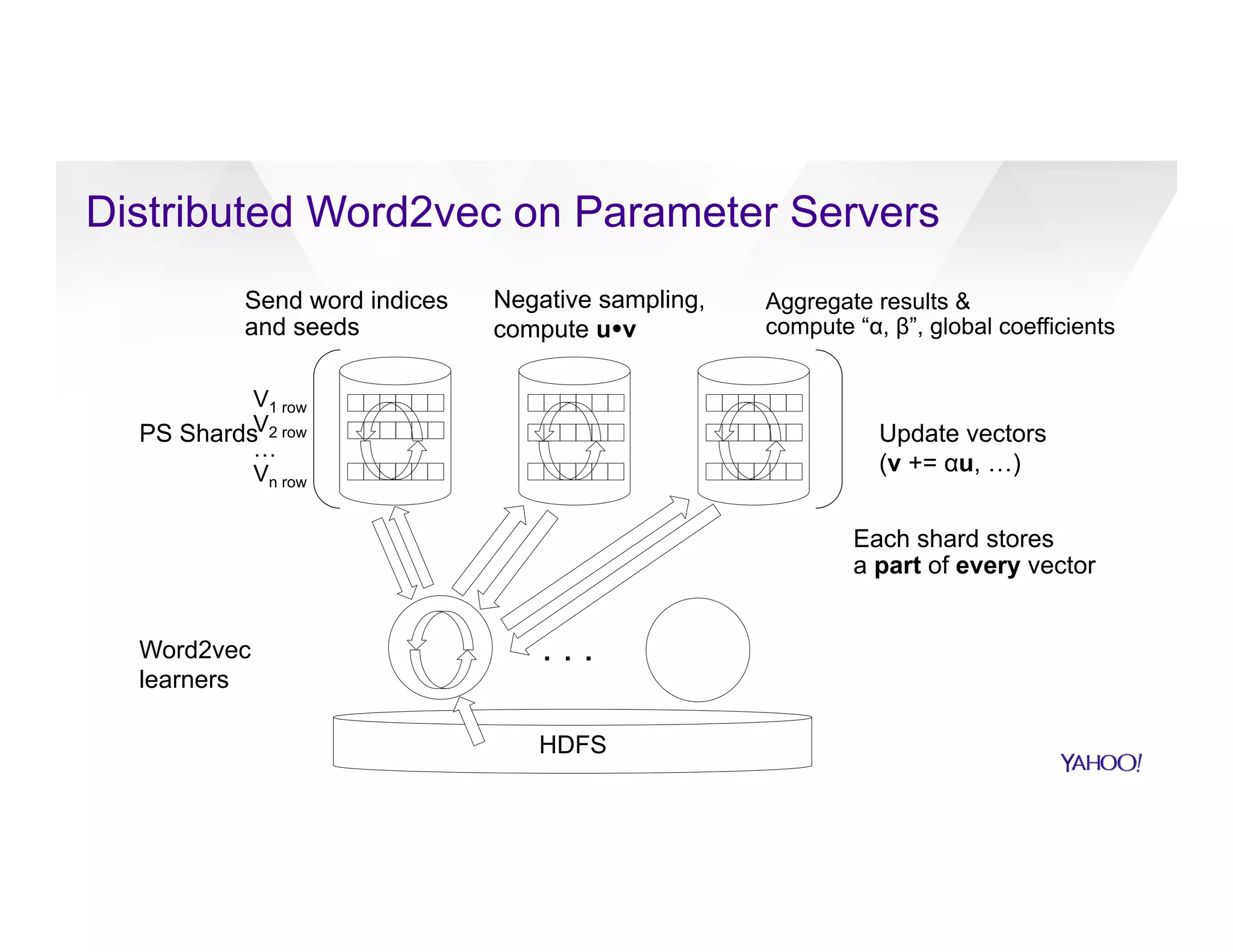
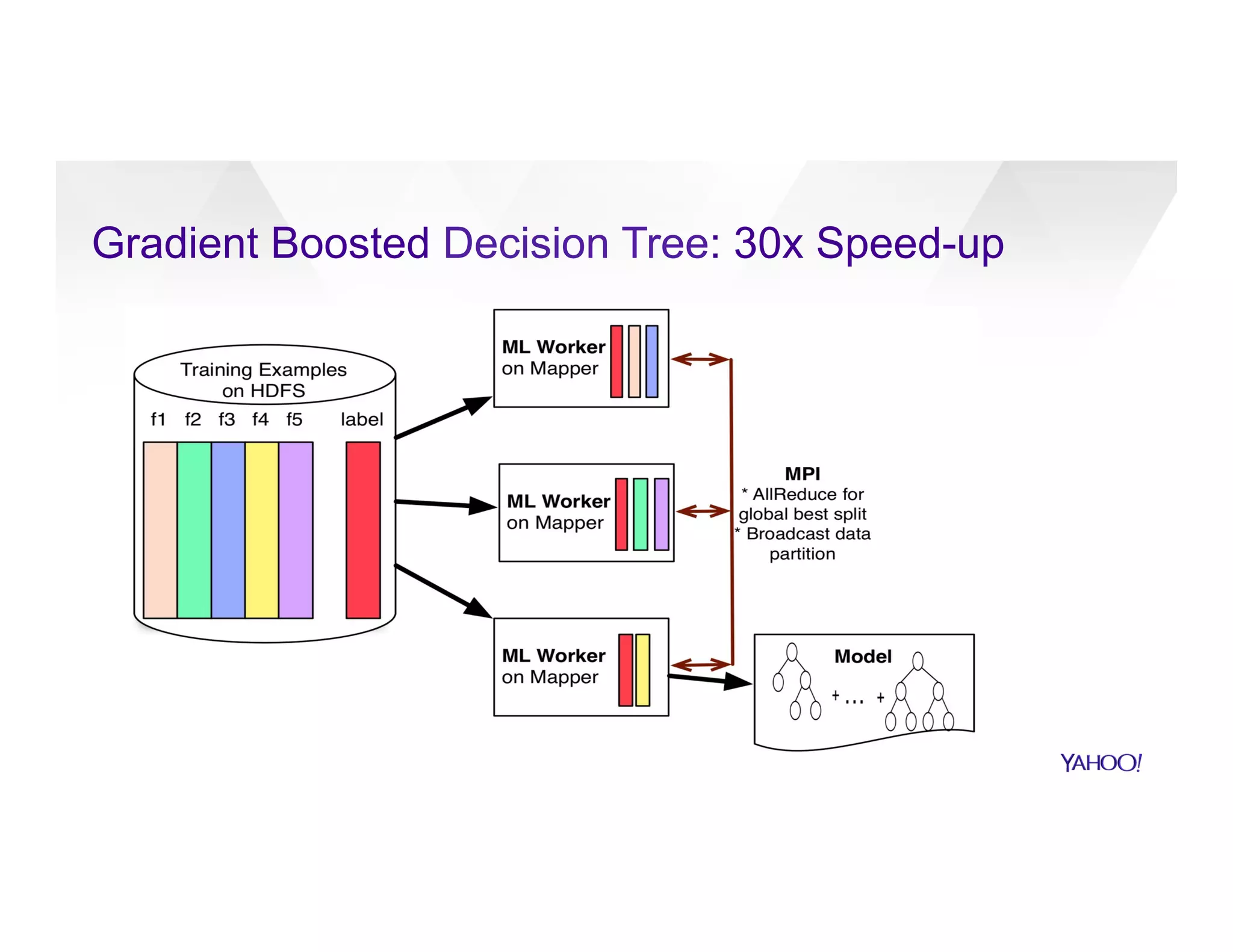
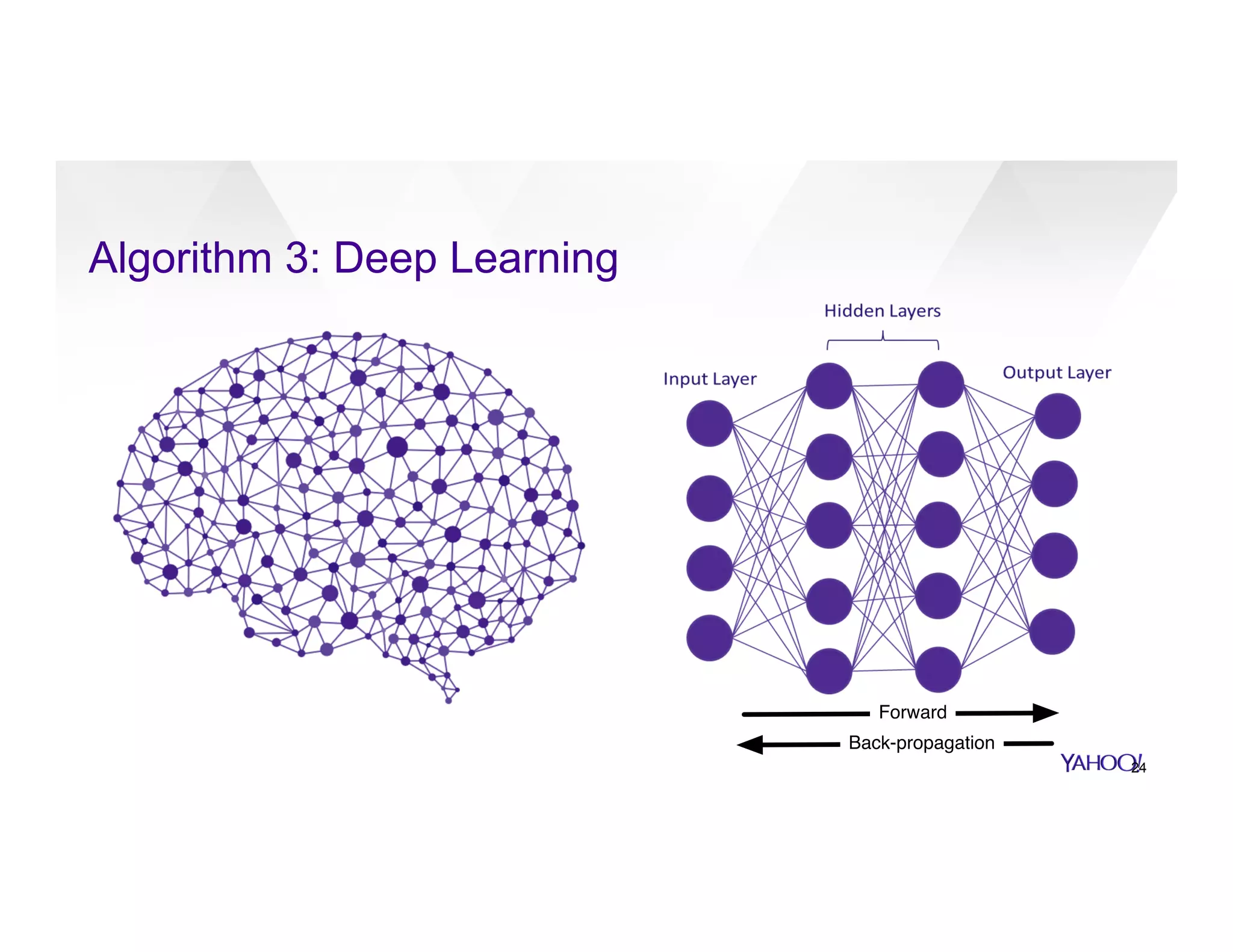
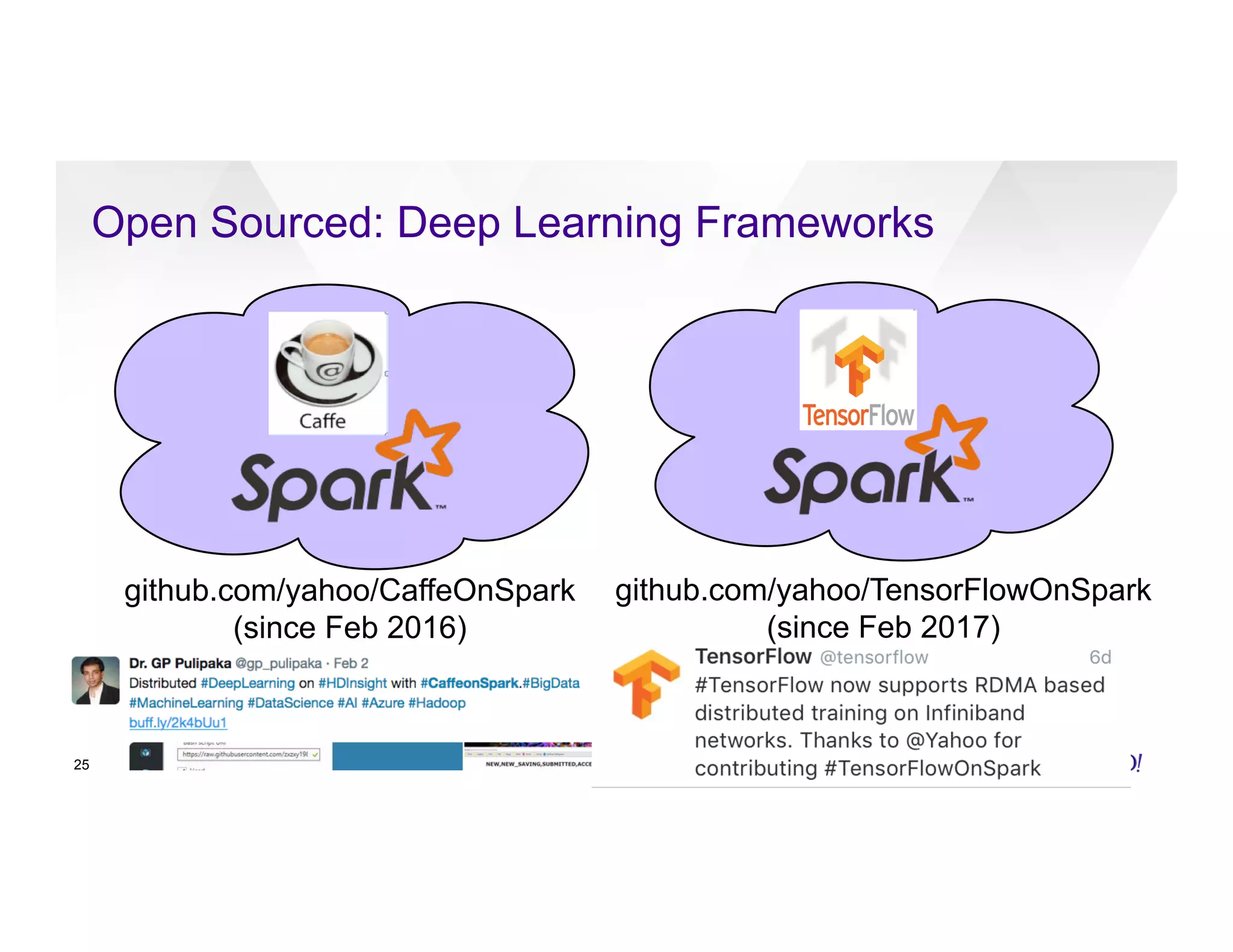
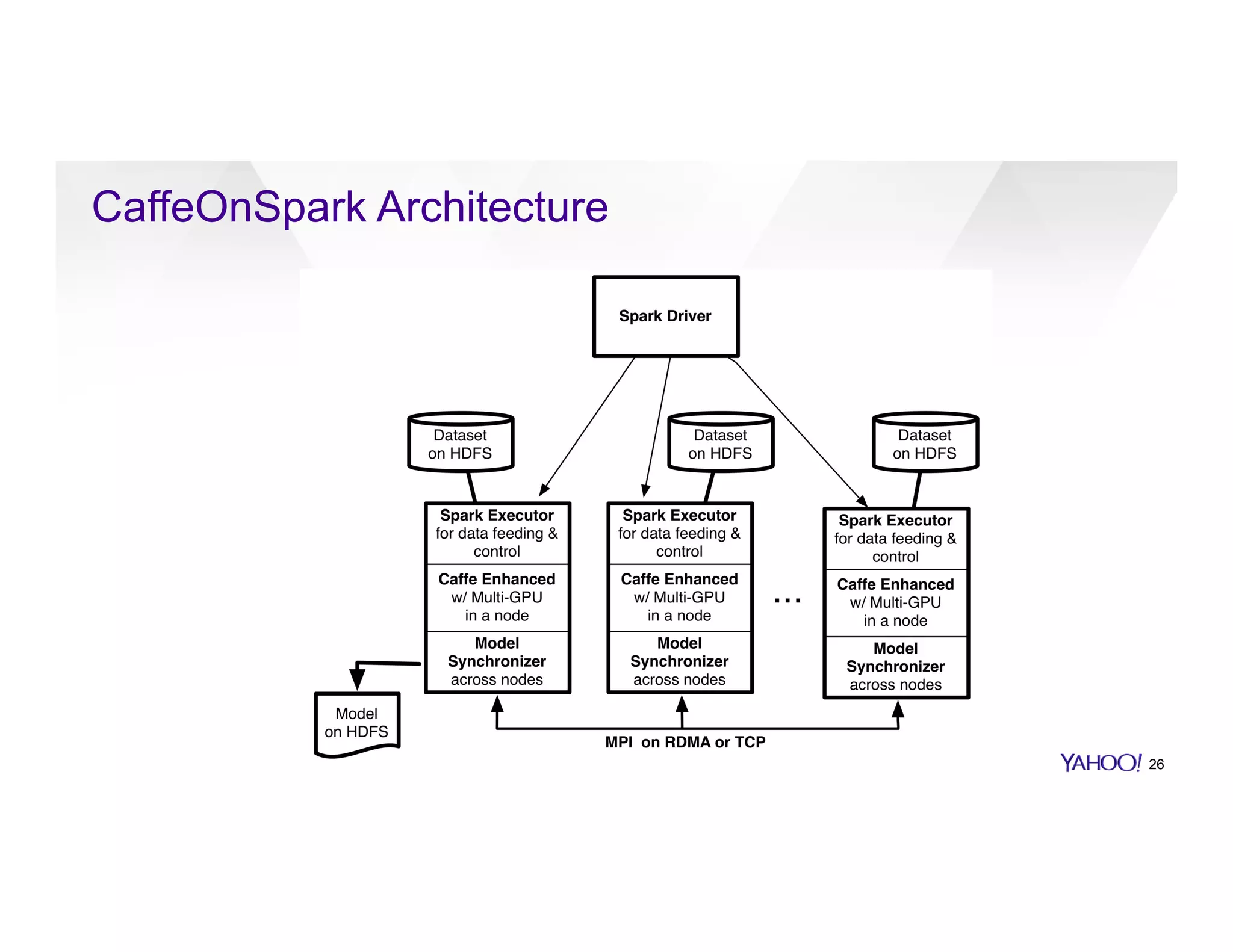
The document discusses large-scale machine learning use cases and technologies, including applications in photo tagging, search optimization, and advertisement targeting. It highlights challenges such as managing massive datasets and presents solutions like word2vec, decision trees, and deep learning frameworks. The importance of scalable ML platforms in business applications, particularly within big-data clusters, is emphasized, alongside R&D opportunities for innovation.







![[Research] azure ml anatomy of a machine learning service - Sharat Chikkerur](https://cdn.slidesharecdn.com/ss_thumbnails/researchazuremlanatomyofamachinelearningservice-sharatchikkerur-150820102331-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
































































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)













