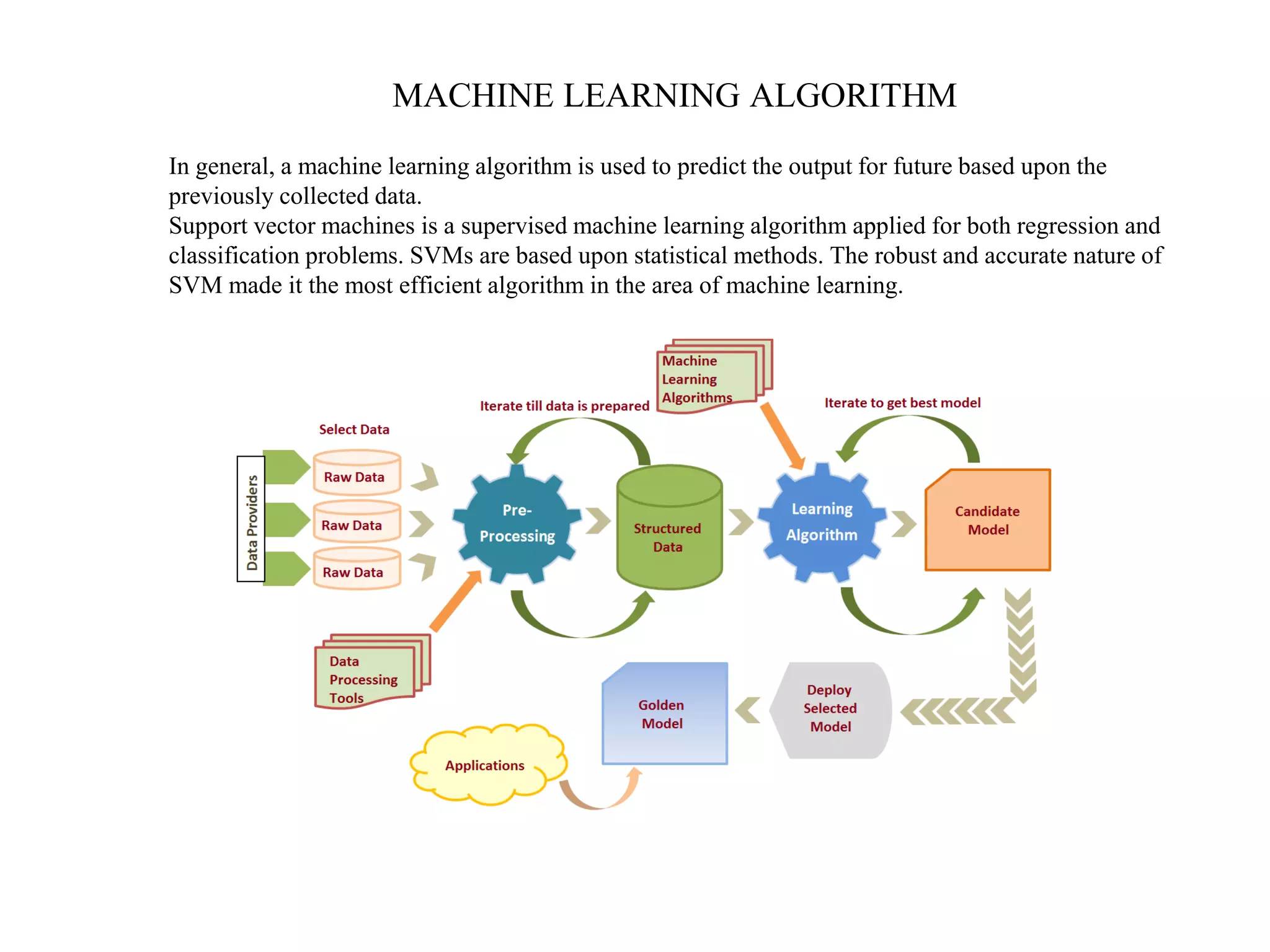
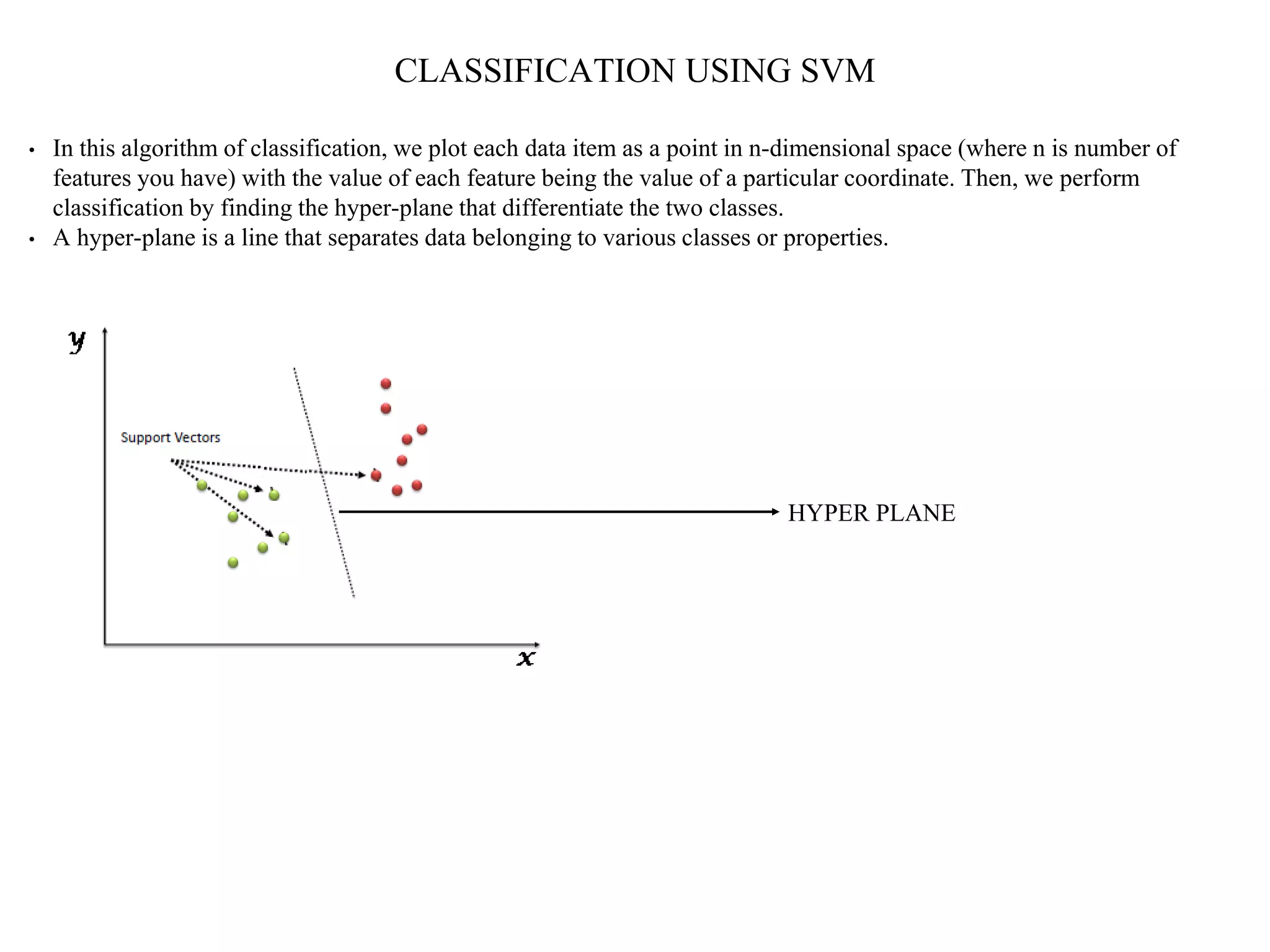
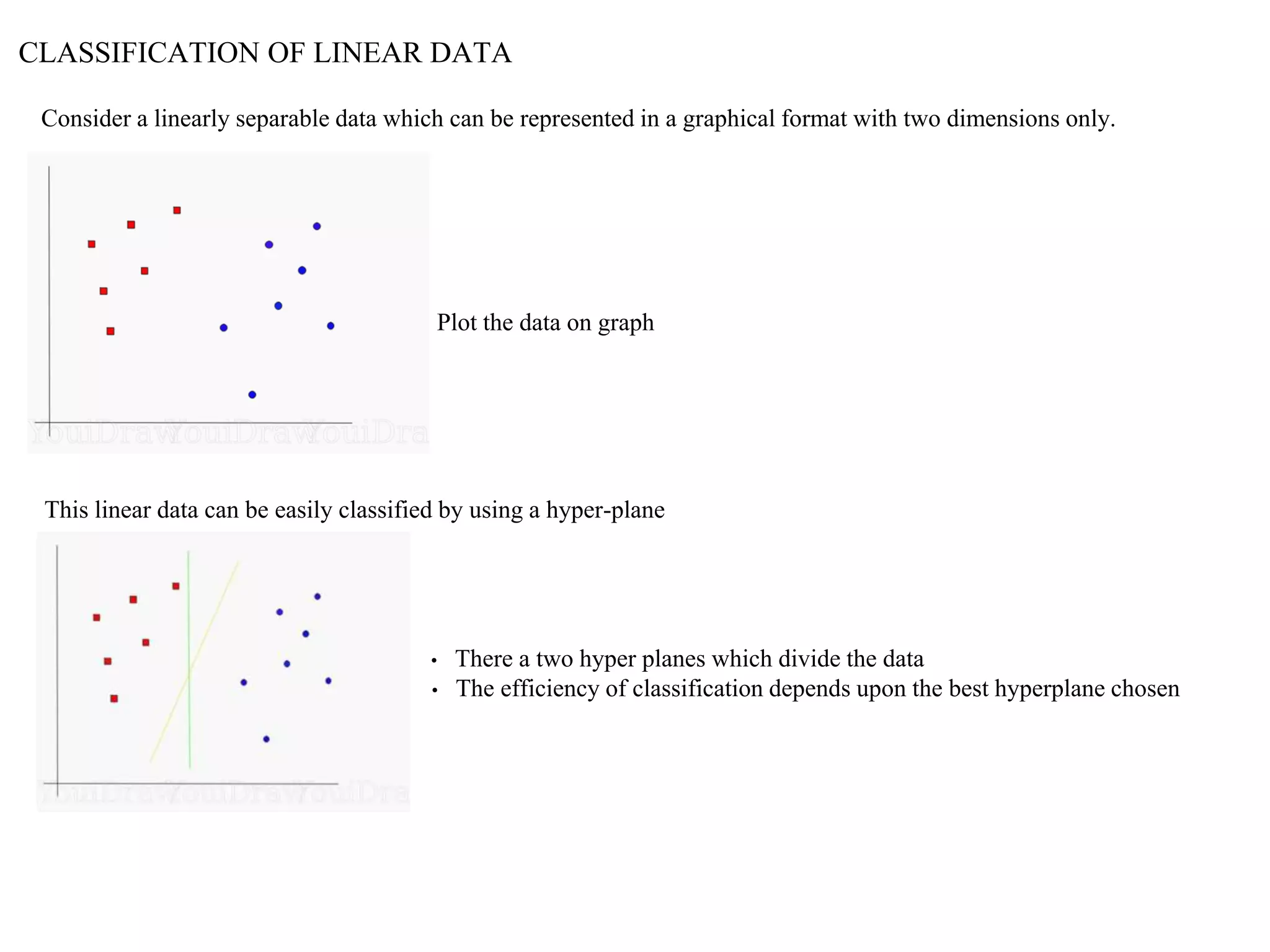
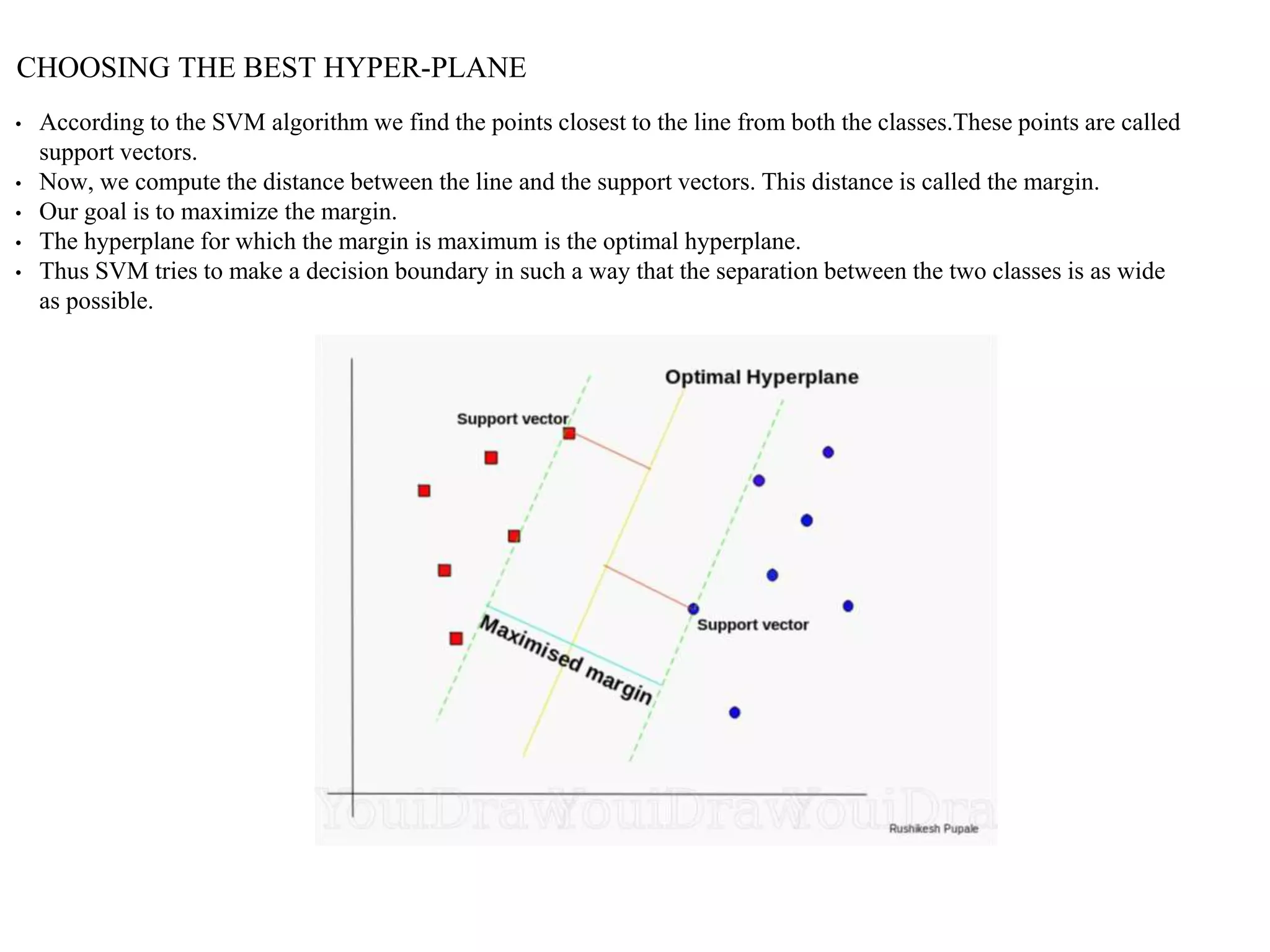
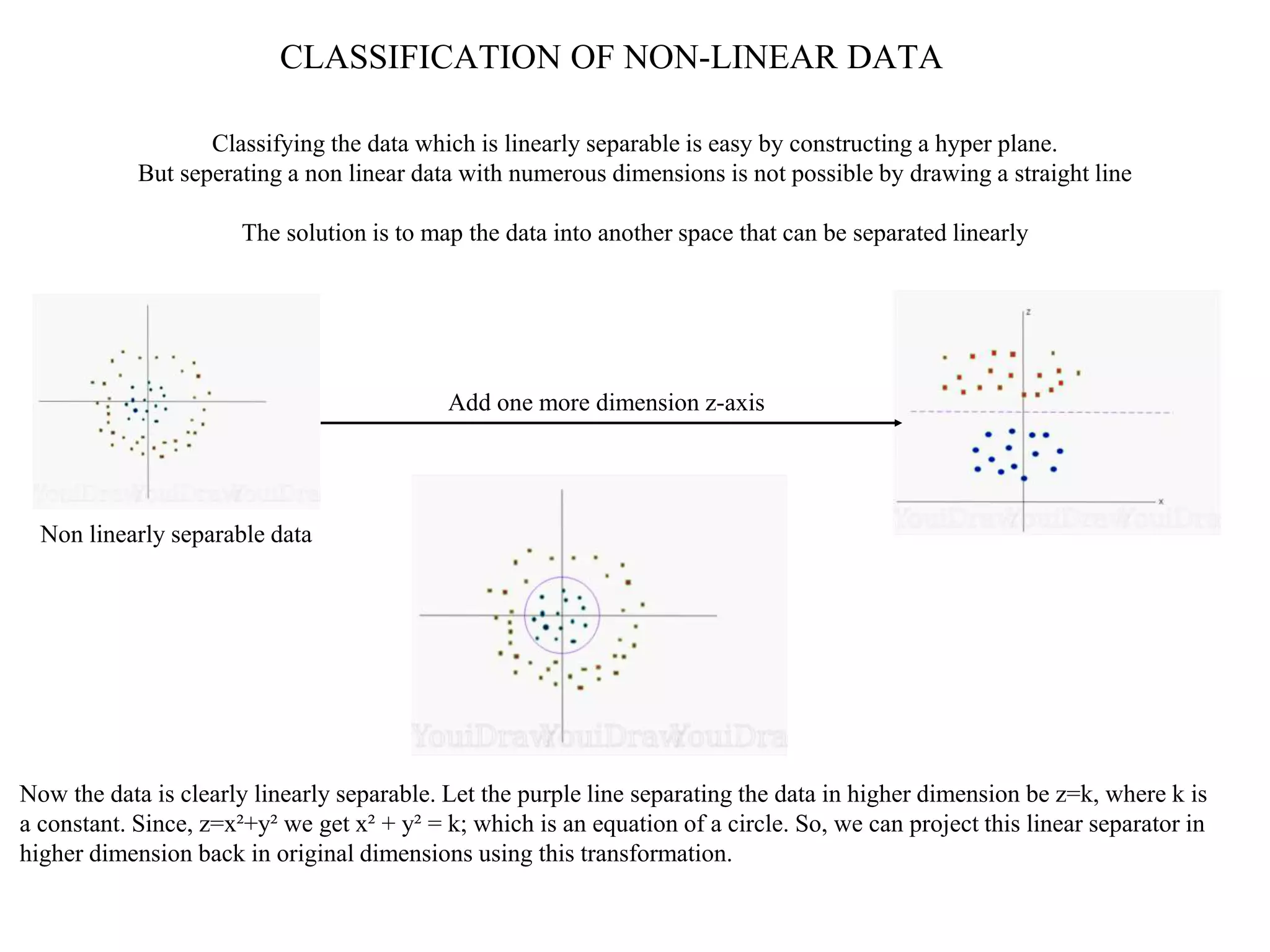
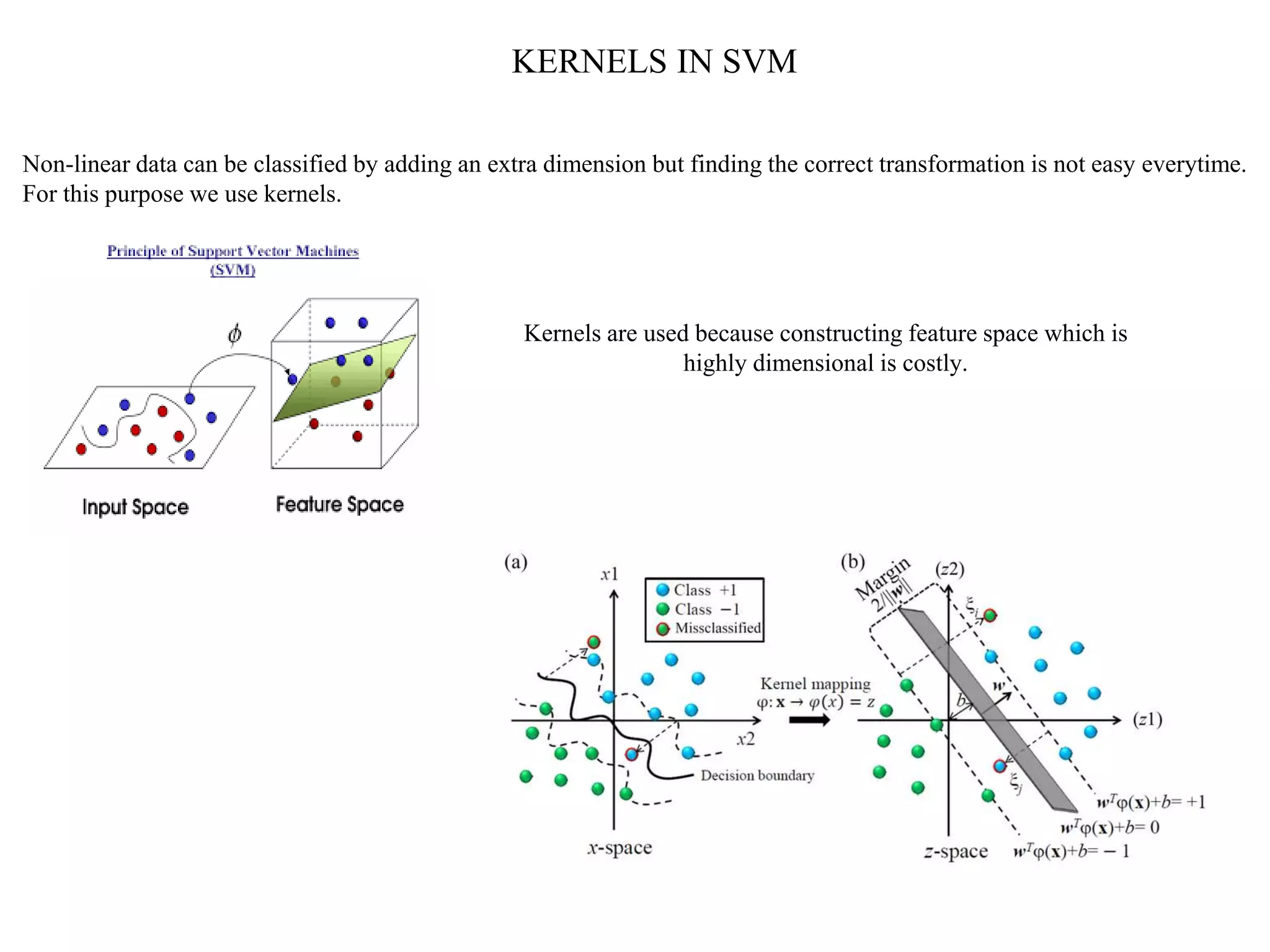
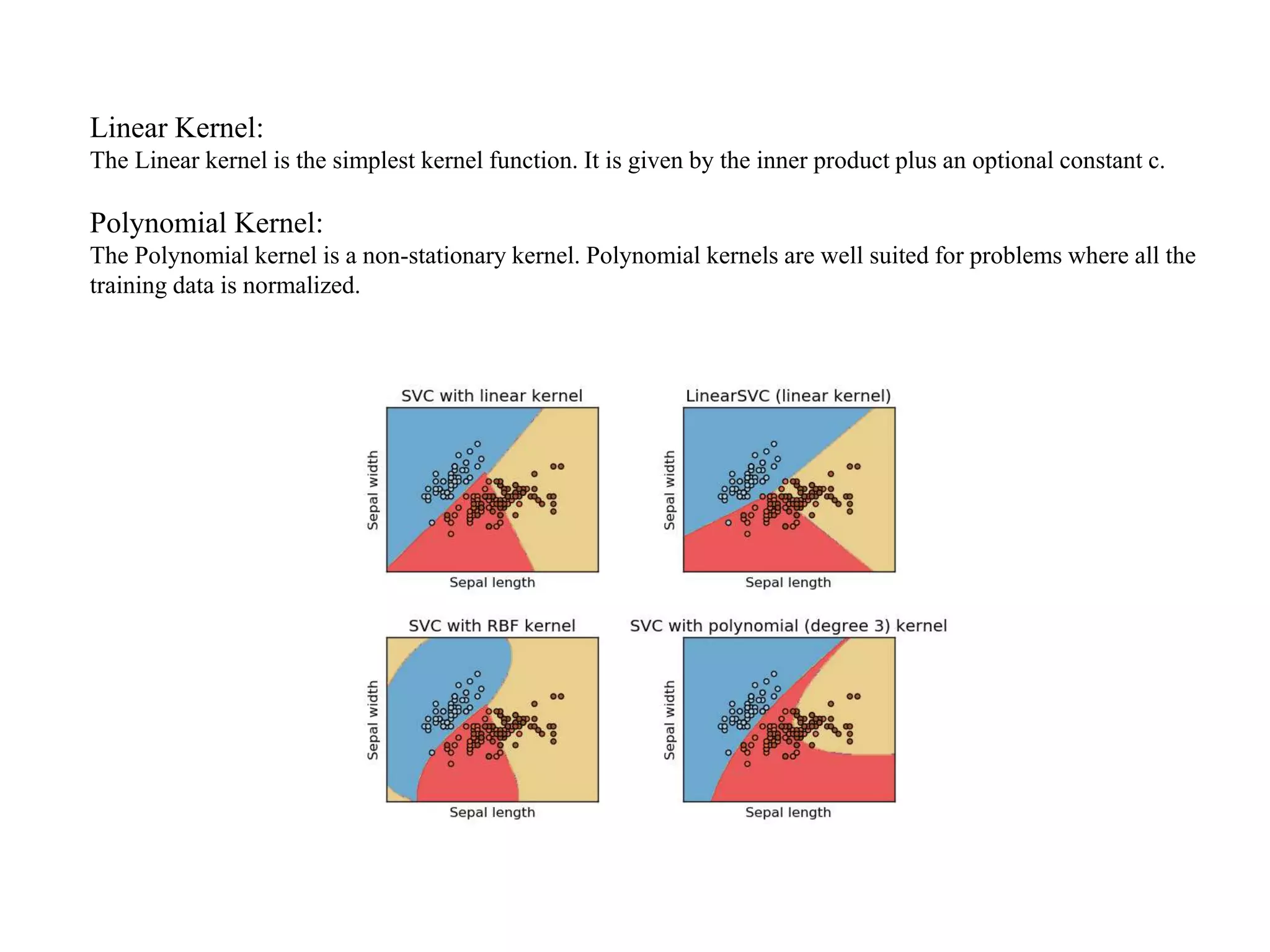
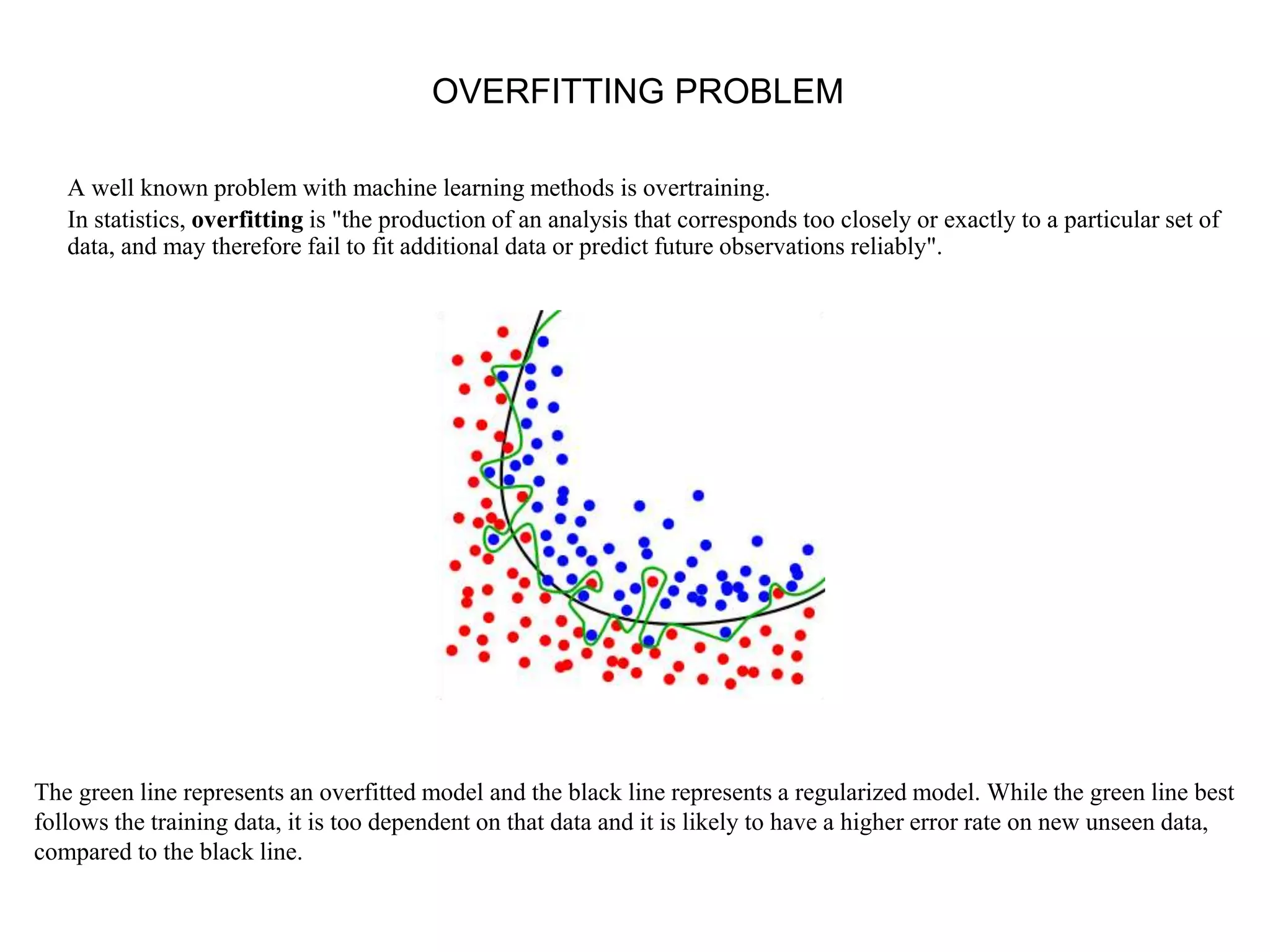
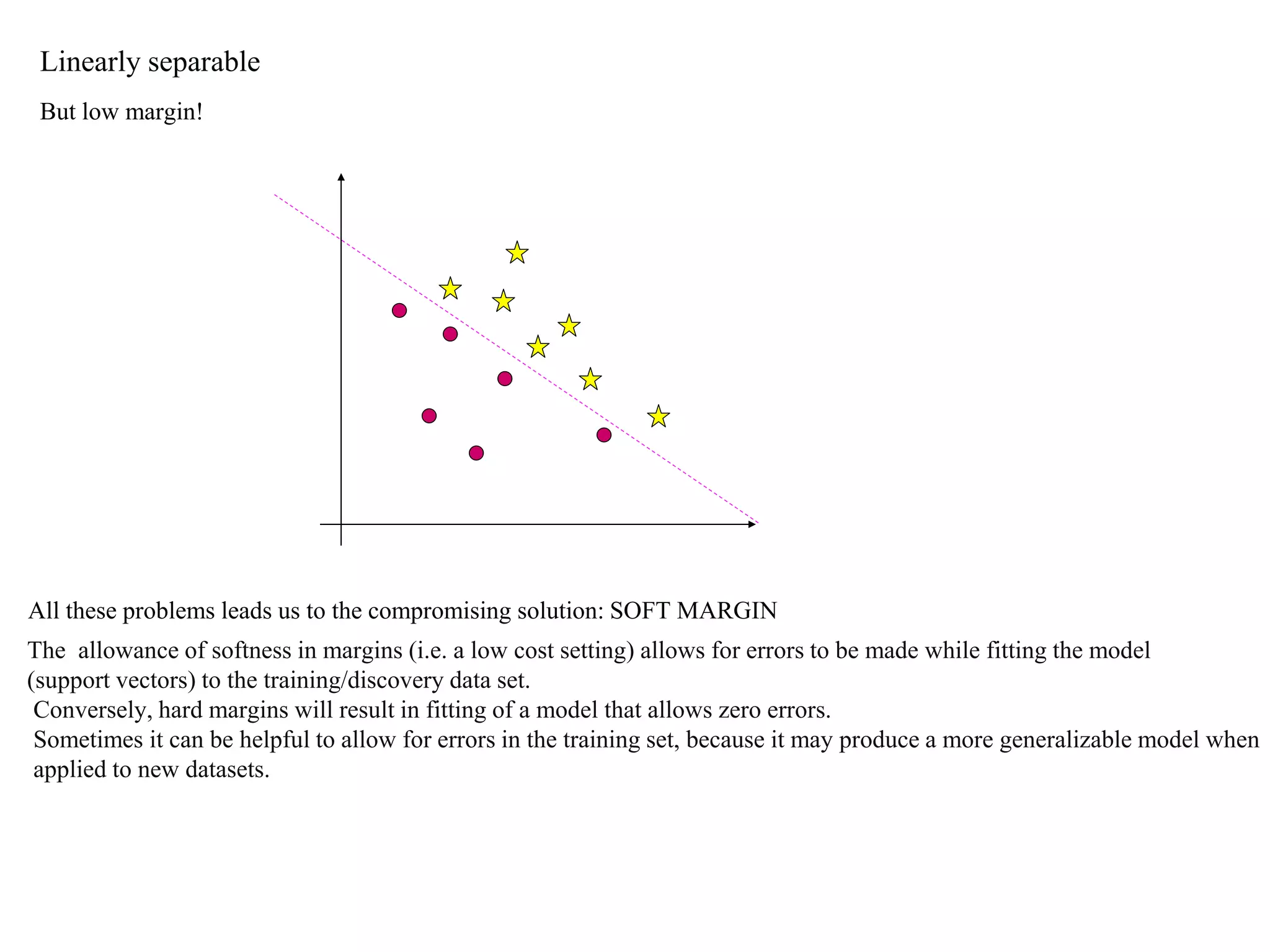
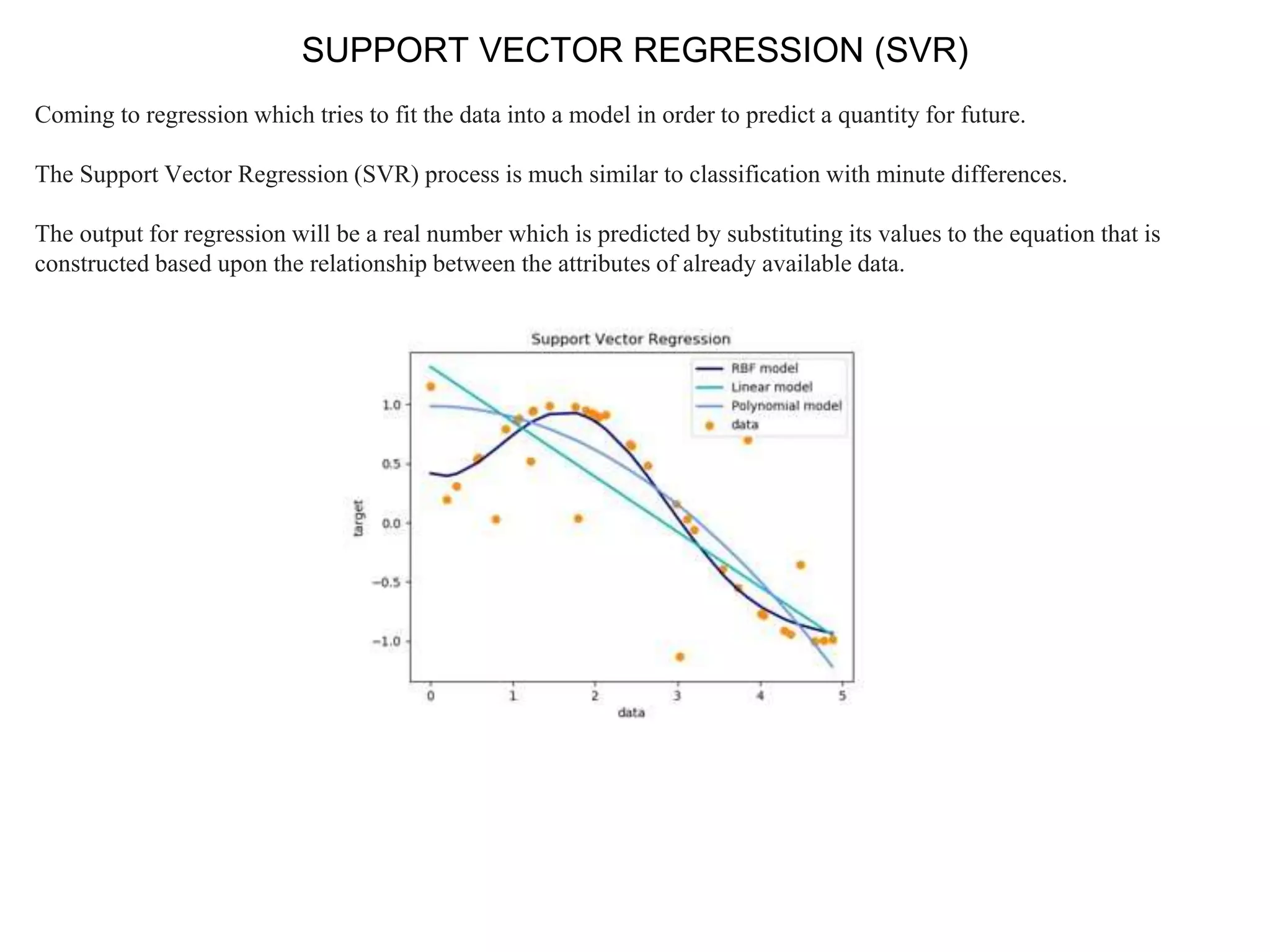
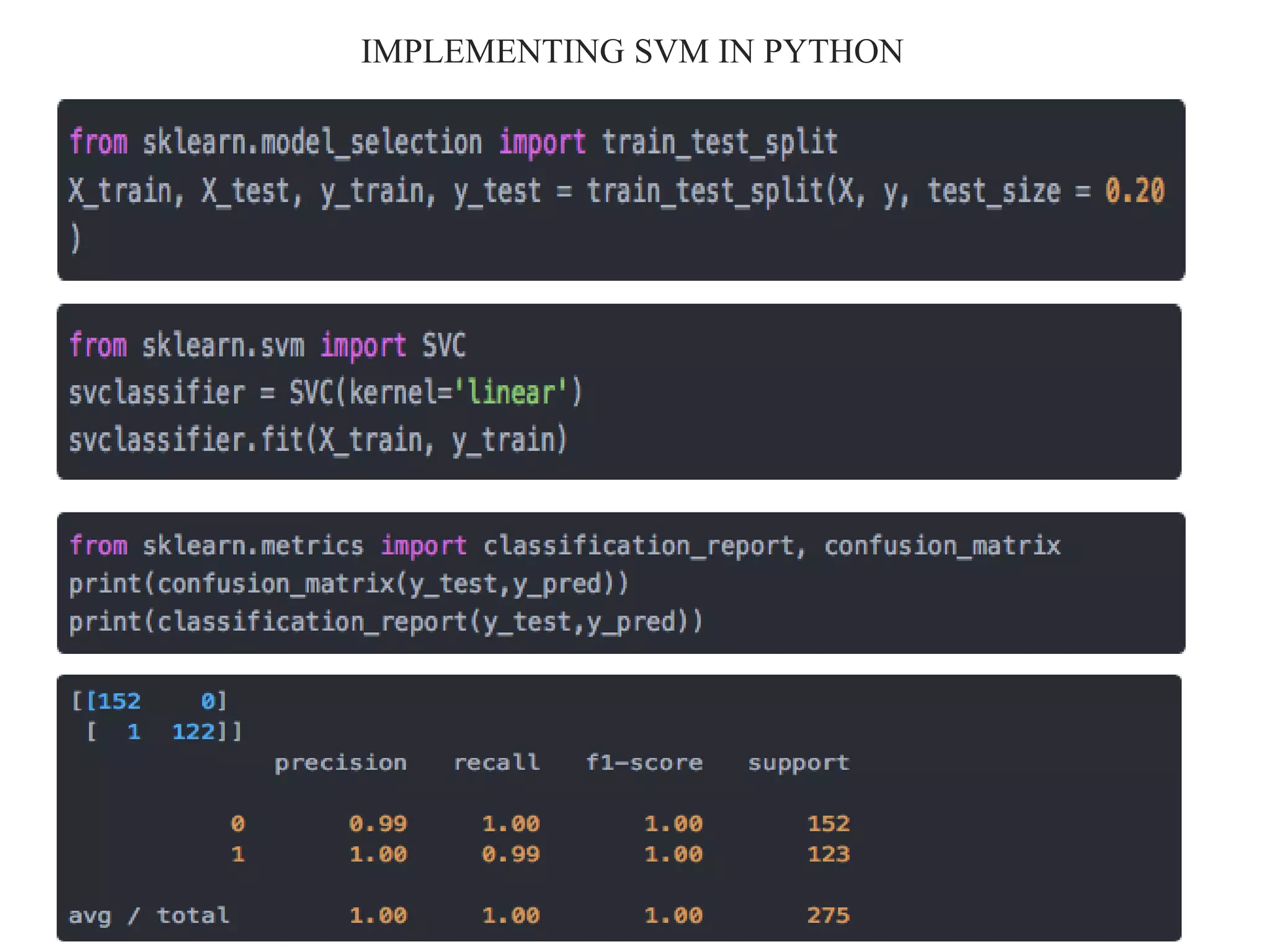
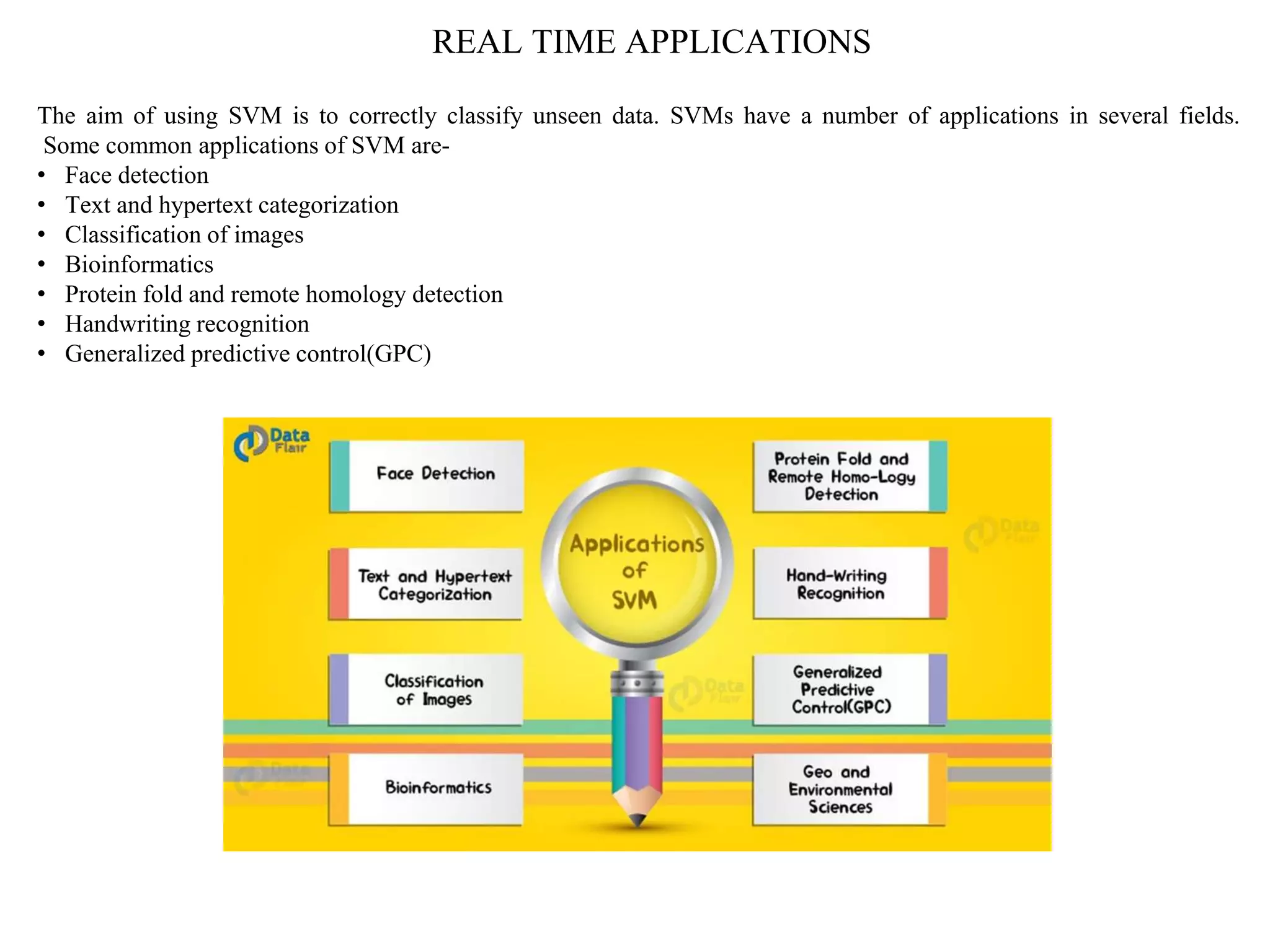
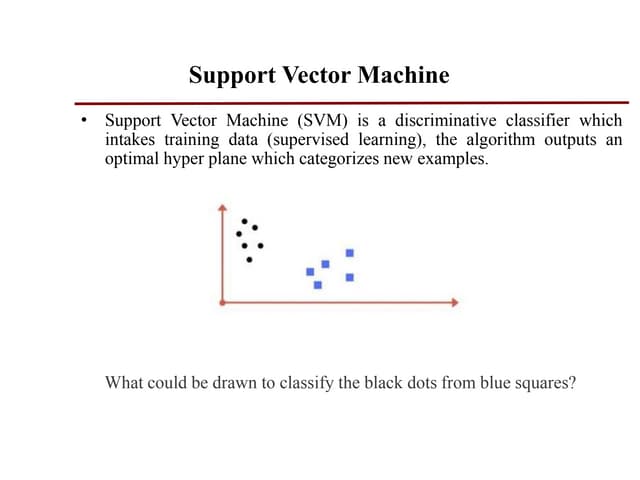
This document provides an overview of support vector machines (SVMs), a supervised machine learning algorithm used for both classification and regression problems. It explains that SVMs work by finding the optimal hyperplane that separates classes of data by the maximum margin. For non-linear classification, the data is first mapped to a higher dimensional space using kernel functions like polynomial or Gaussian kernels. The document discusses issues like overfitting and soft margins, and notes applications of SVMs in areas like face detection, text categorization, and bioinformatics.



























































![SVM[Support vector Machine] Machine learning](https://cdn.slidesharecdn.com/ss_thumbnails/svm-250403184638-1cd9afdb-thumbnail.jpg?width=640&height=640&fit=bounds)



























![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)


