



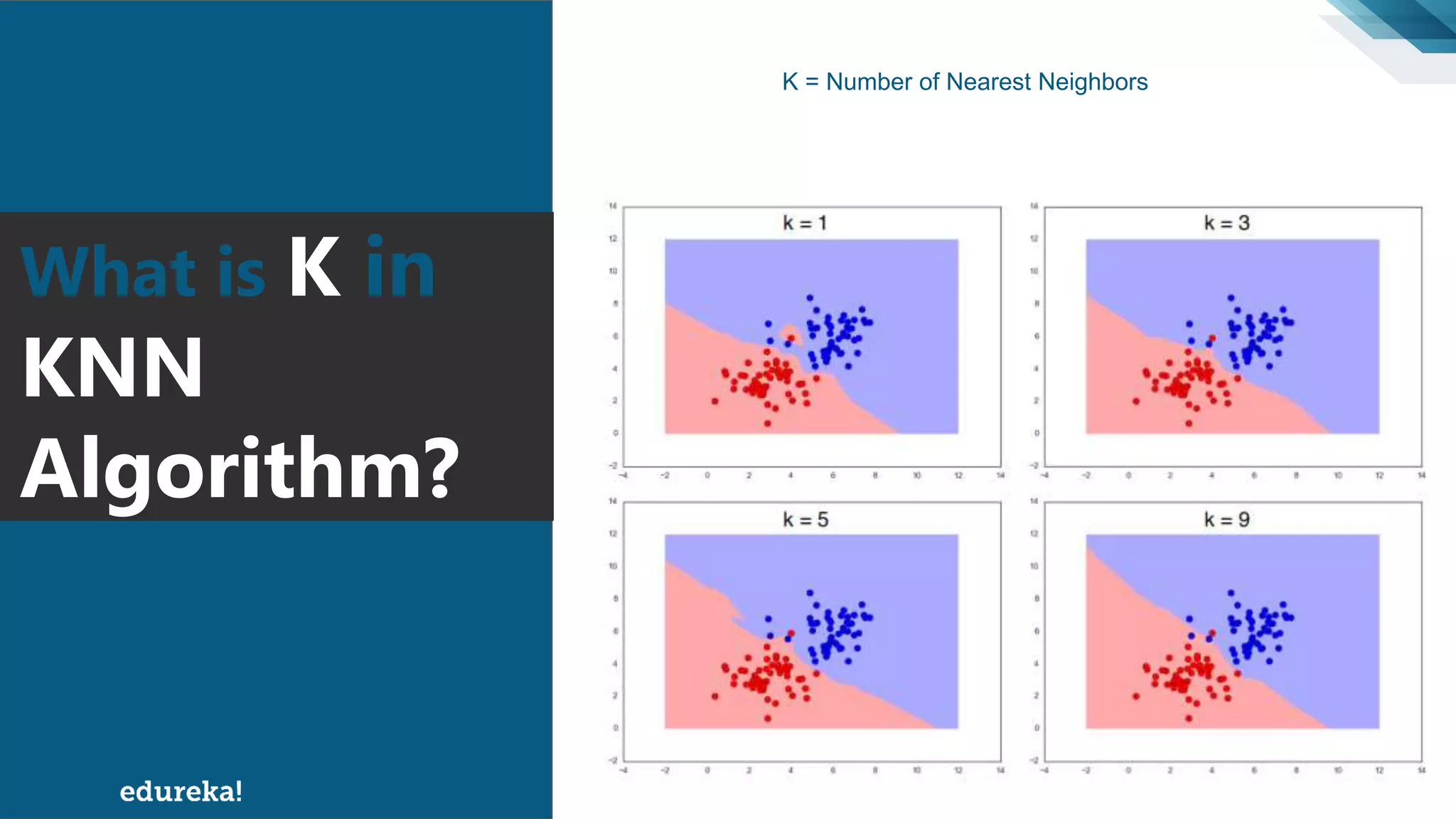
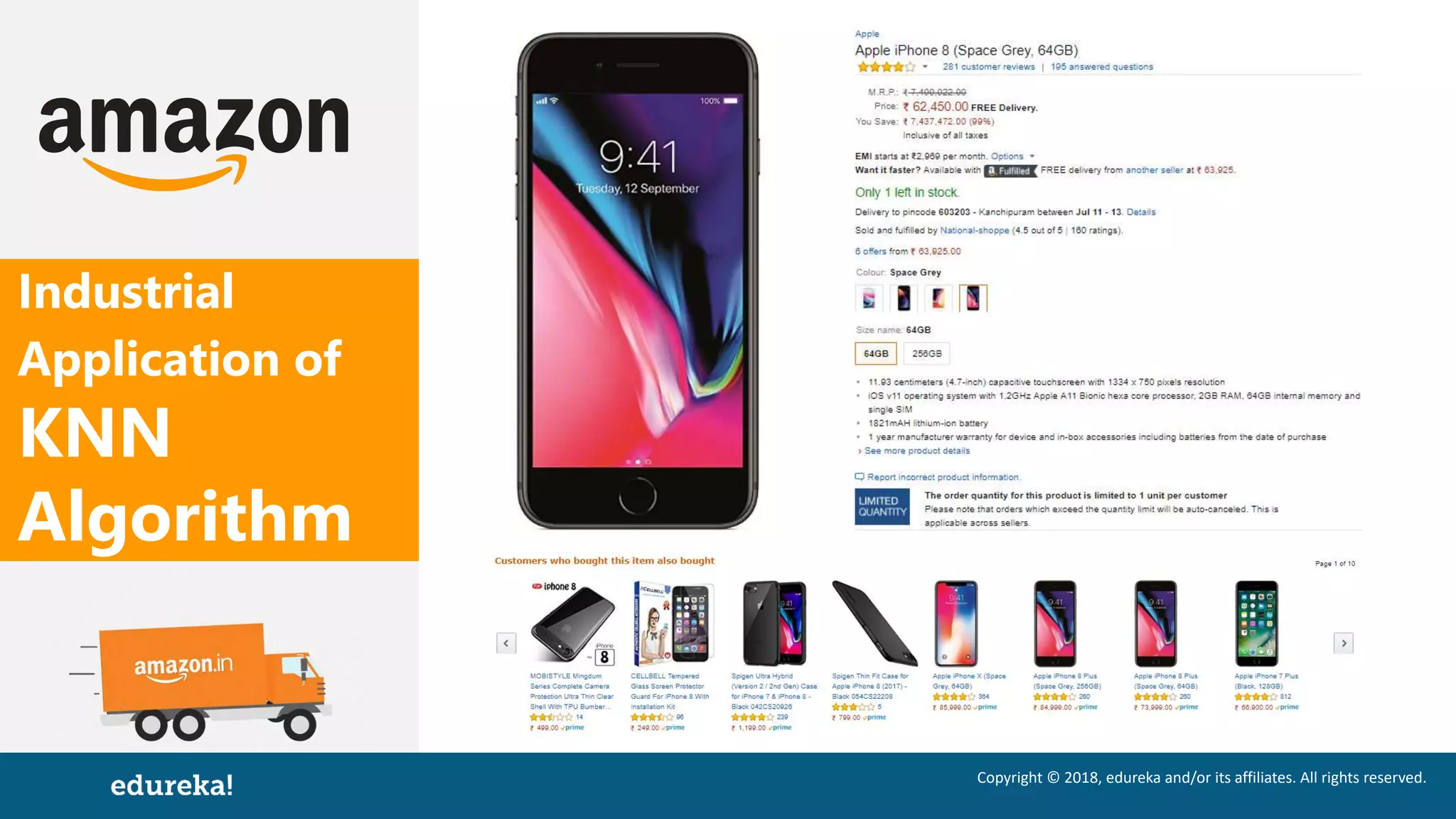
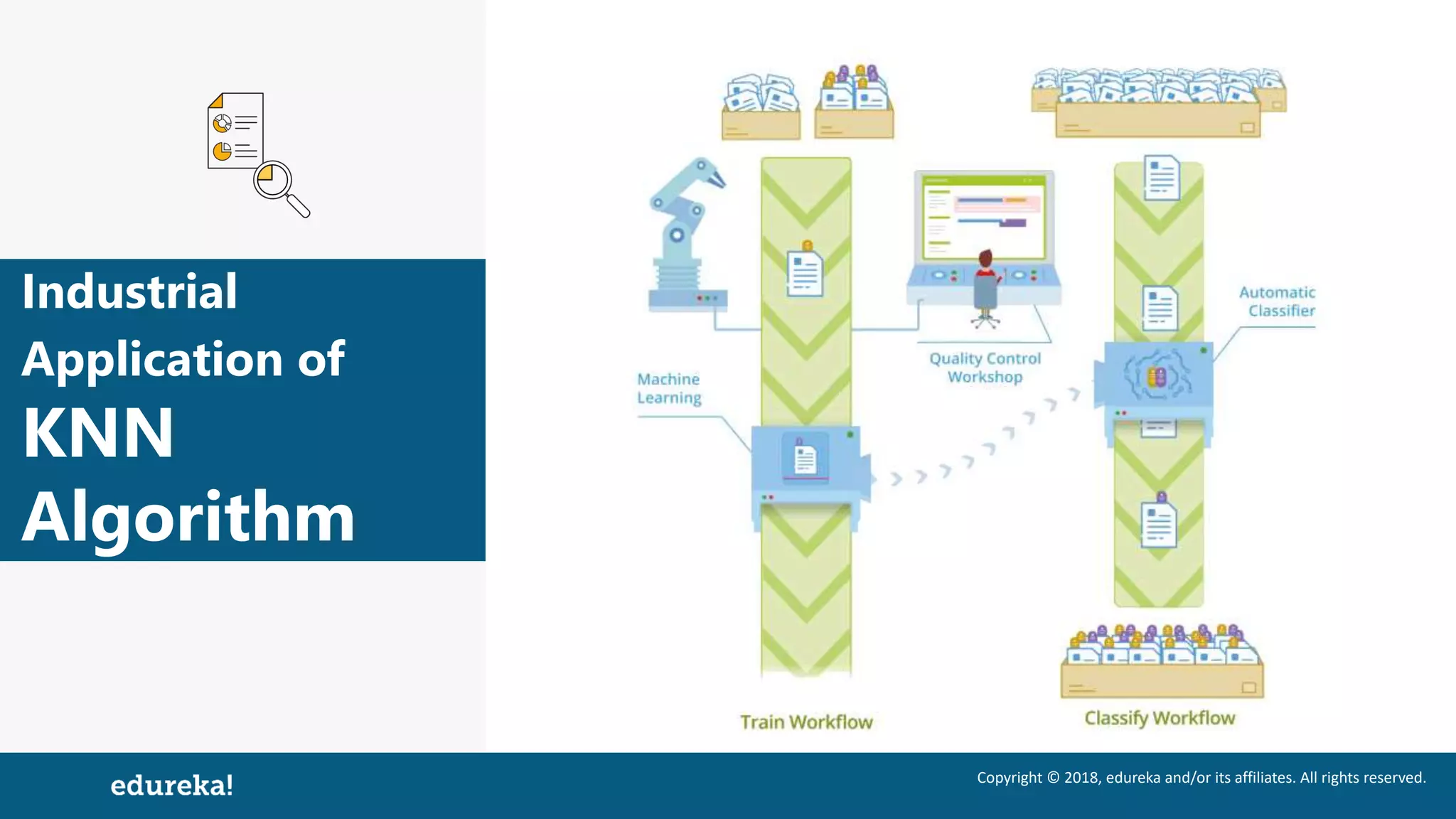
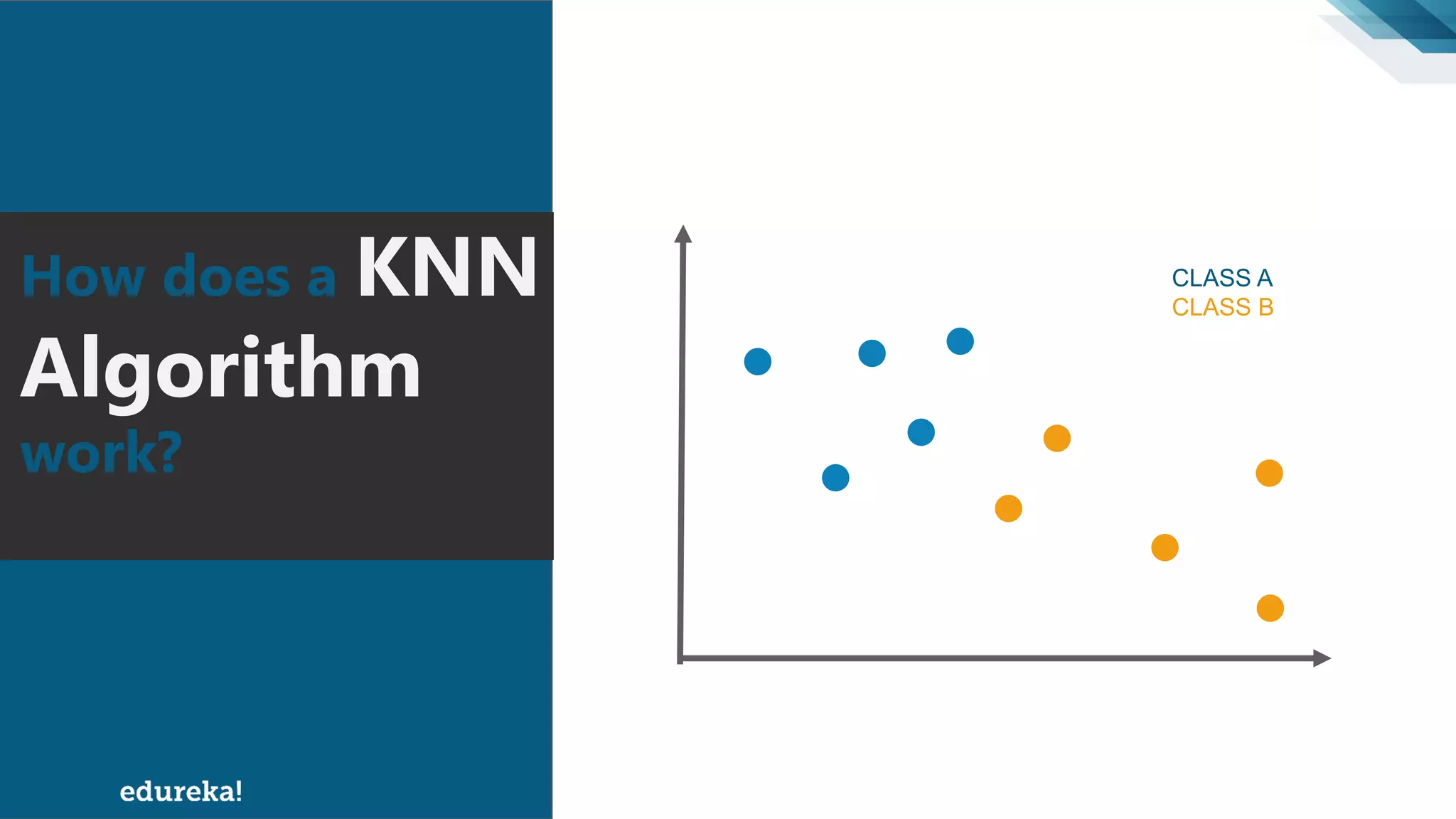
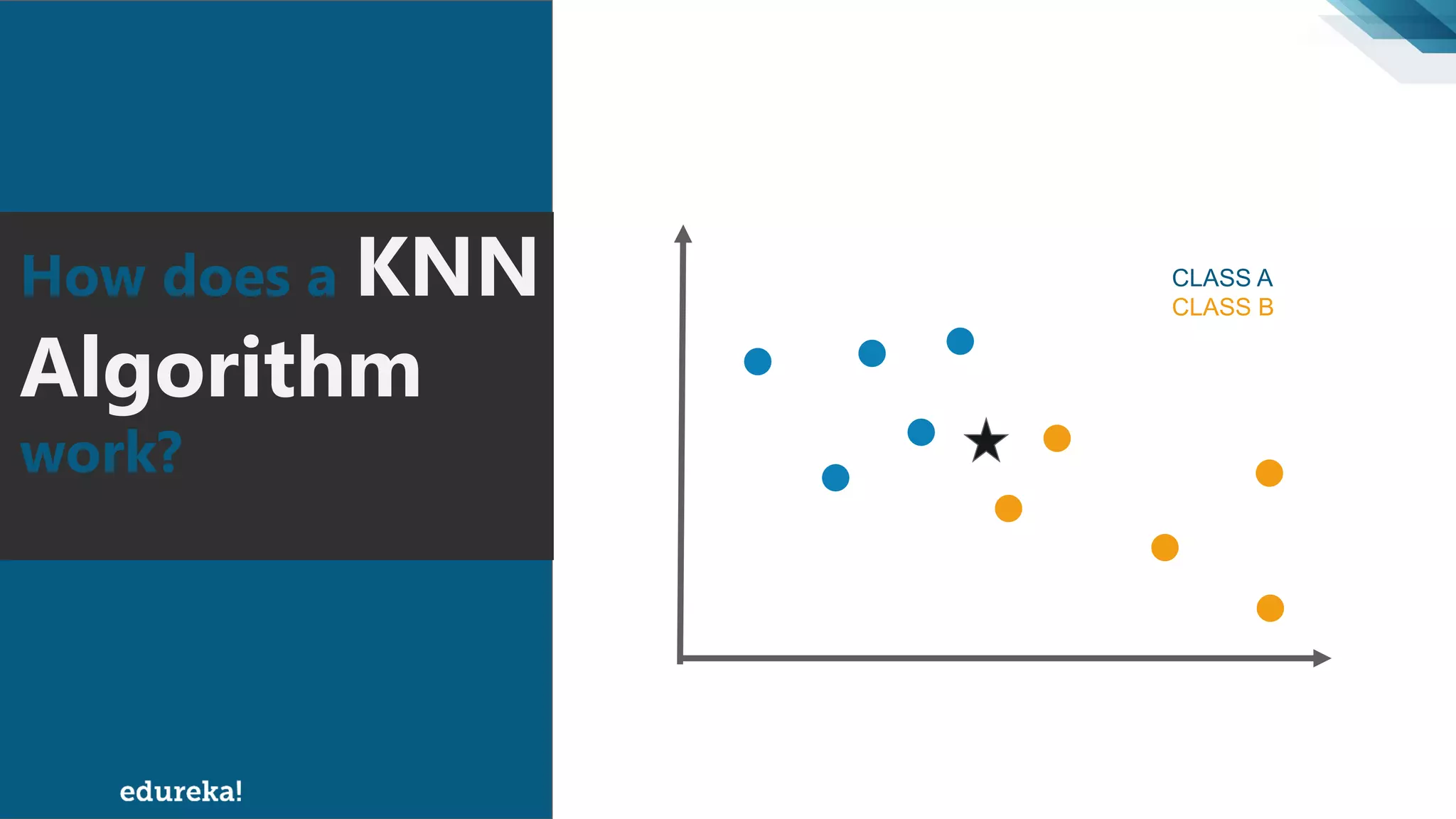
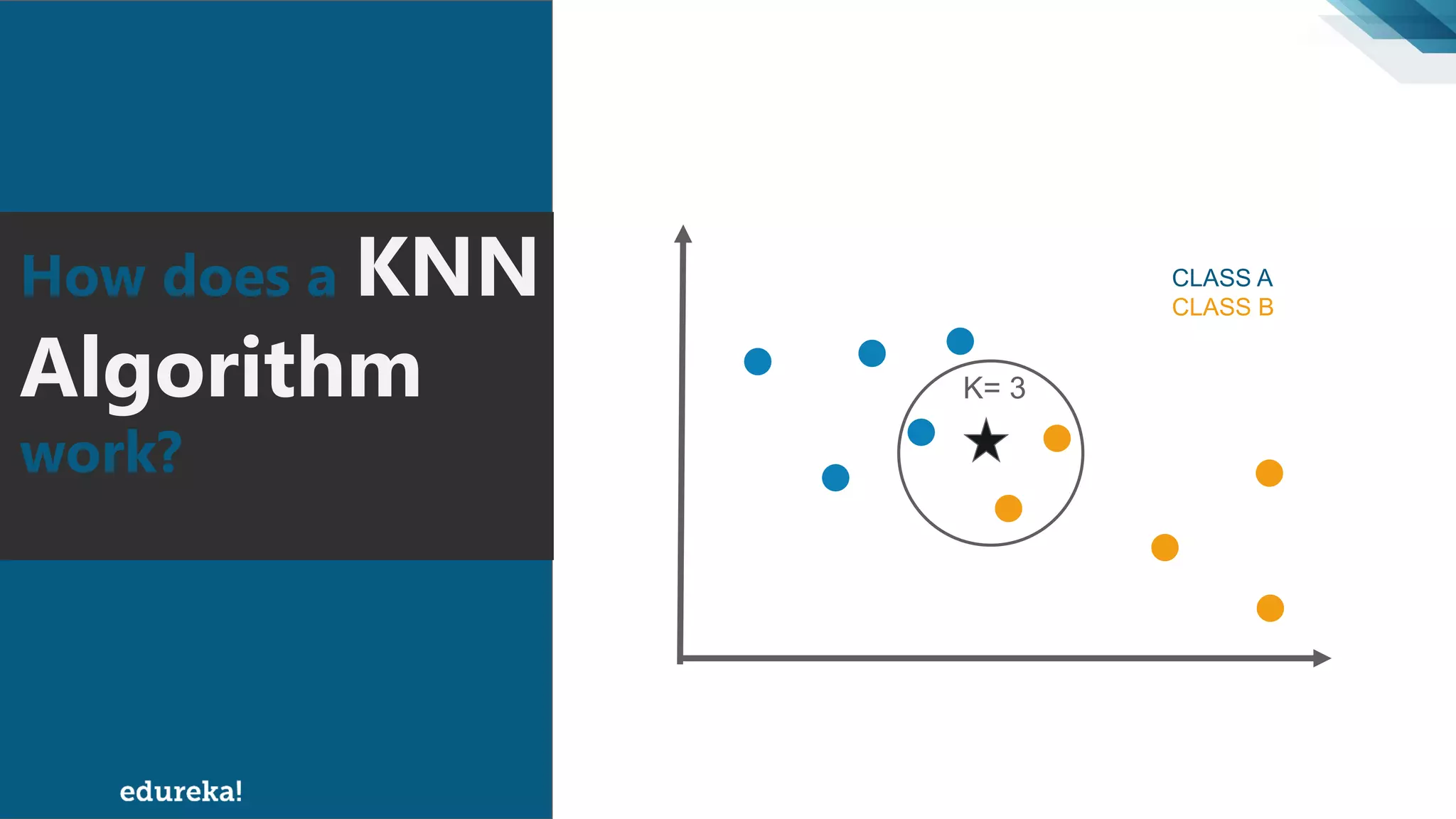
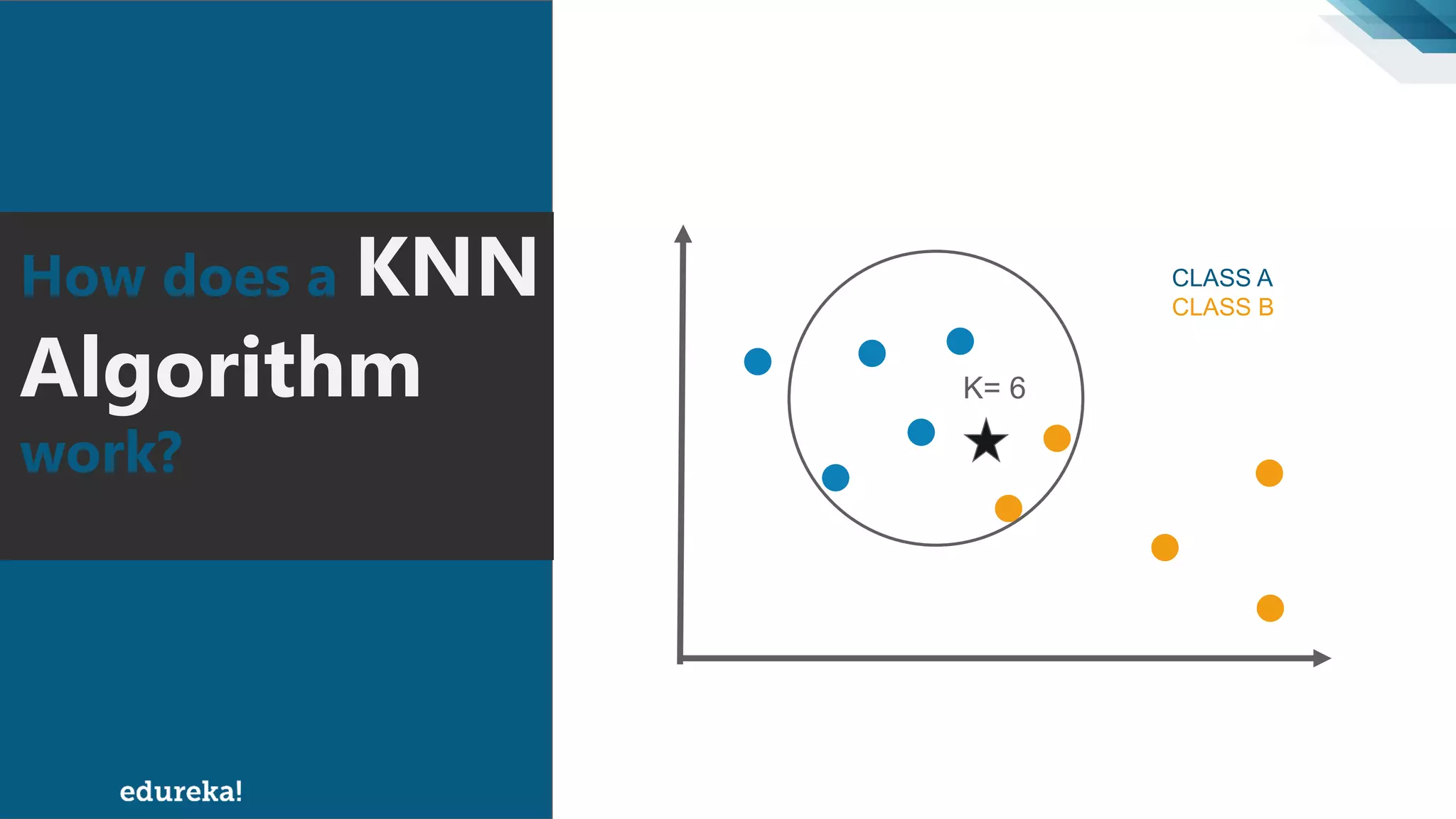
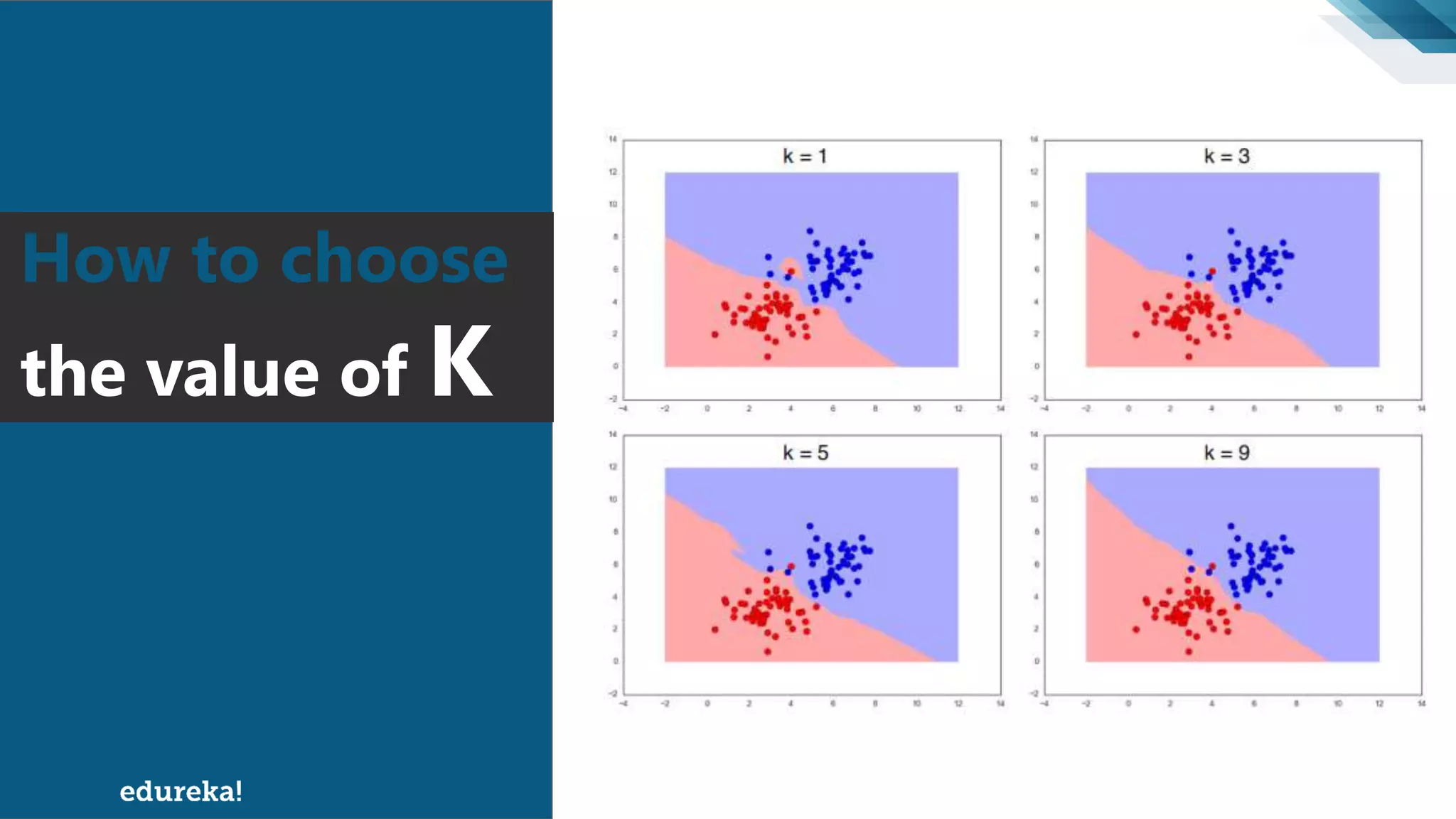
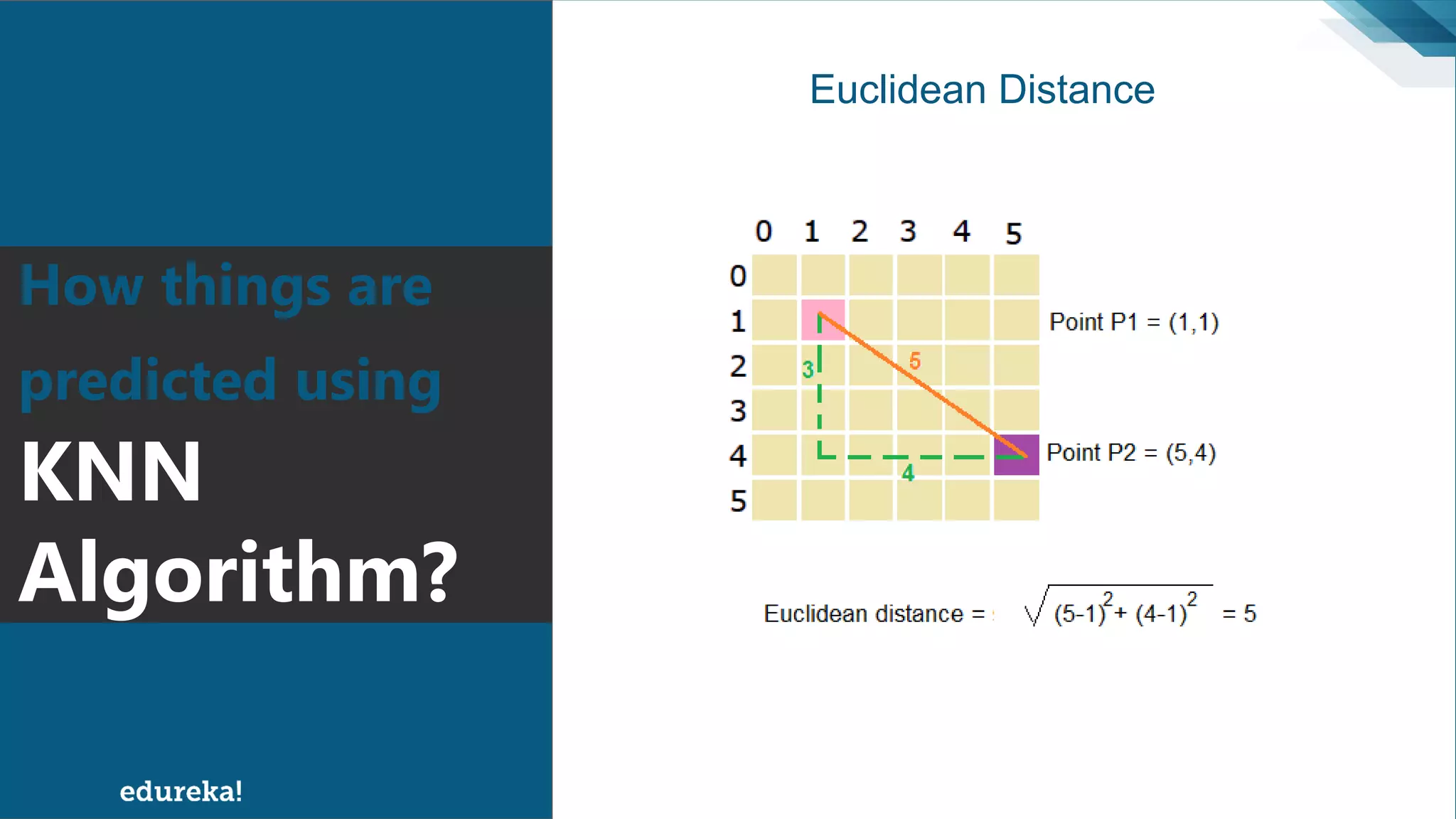
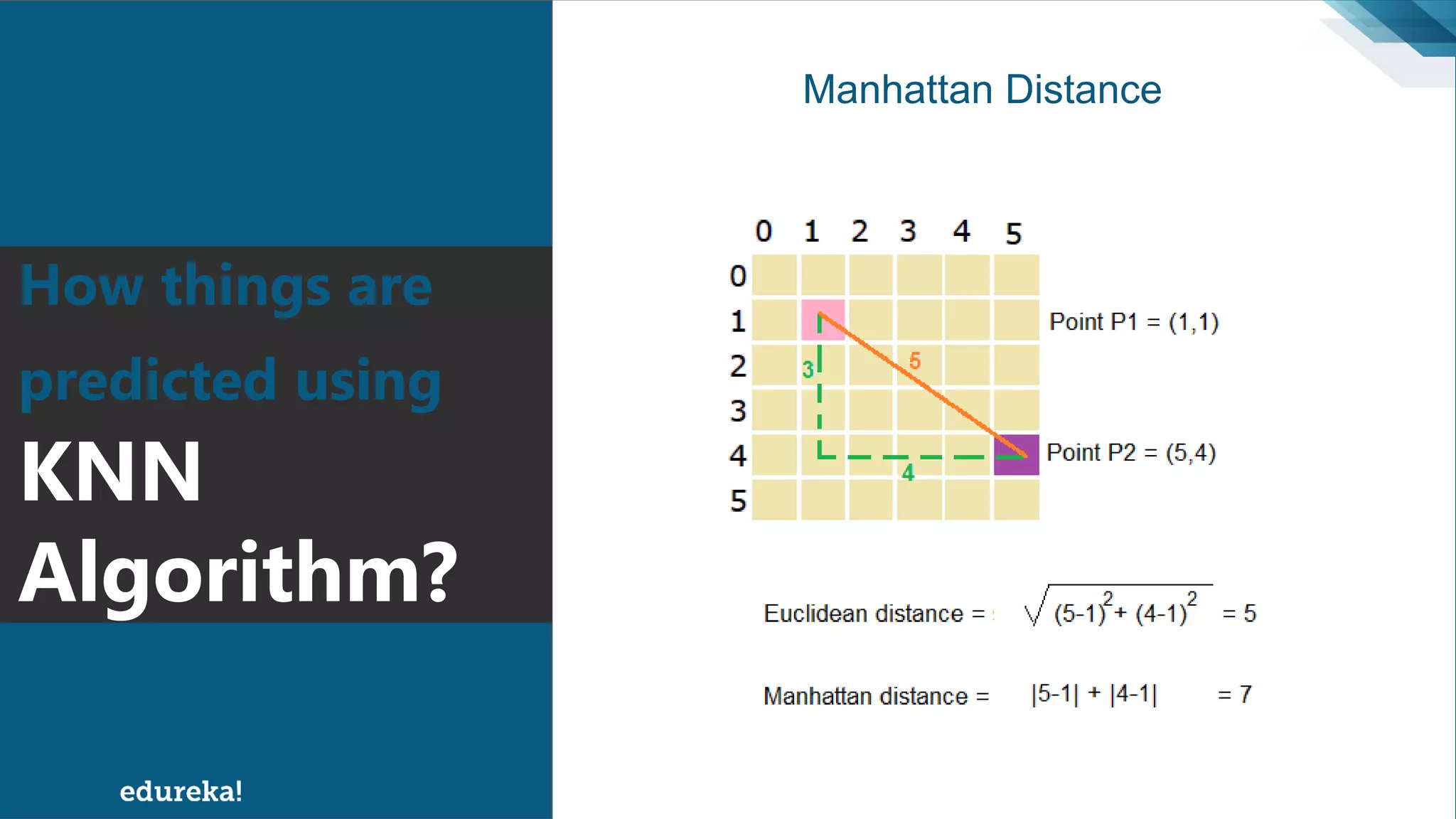



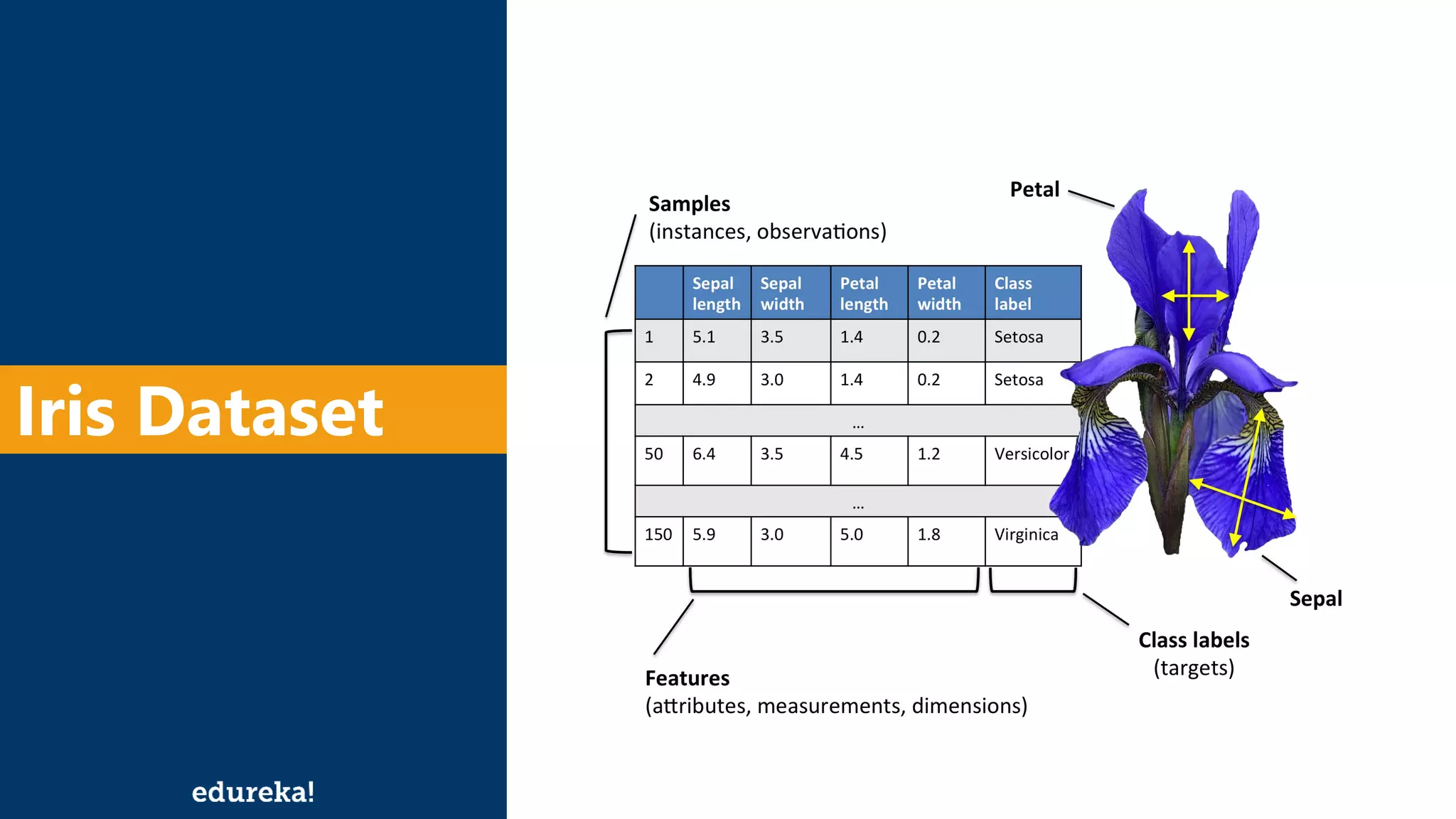




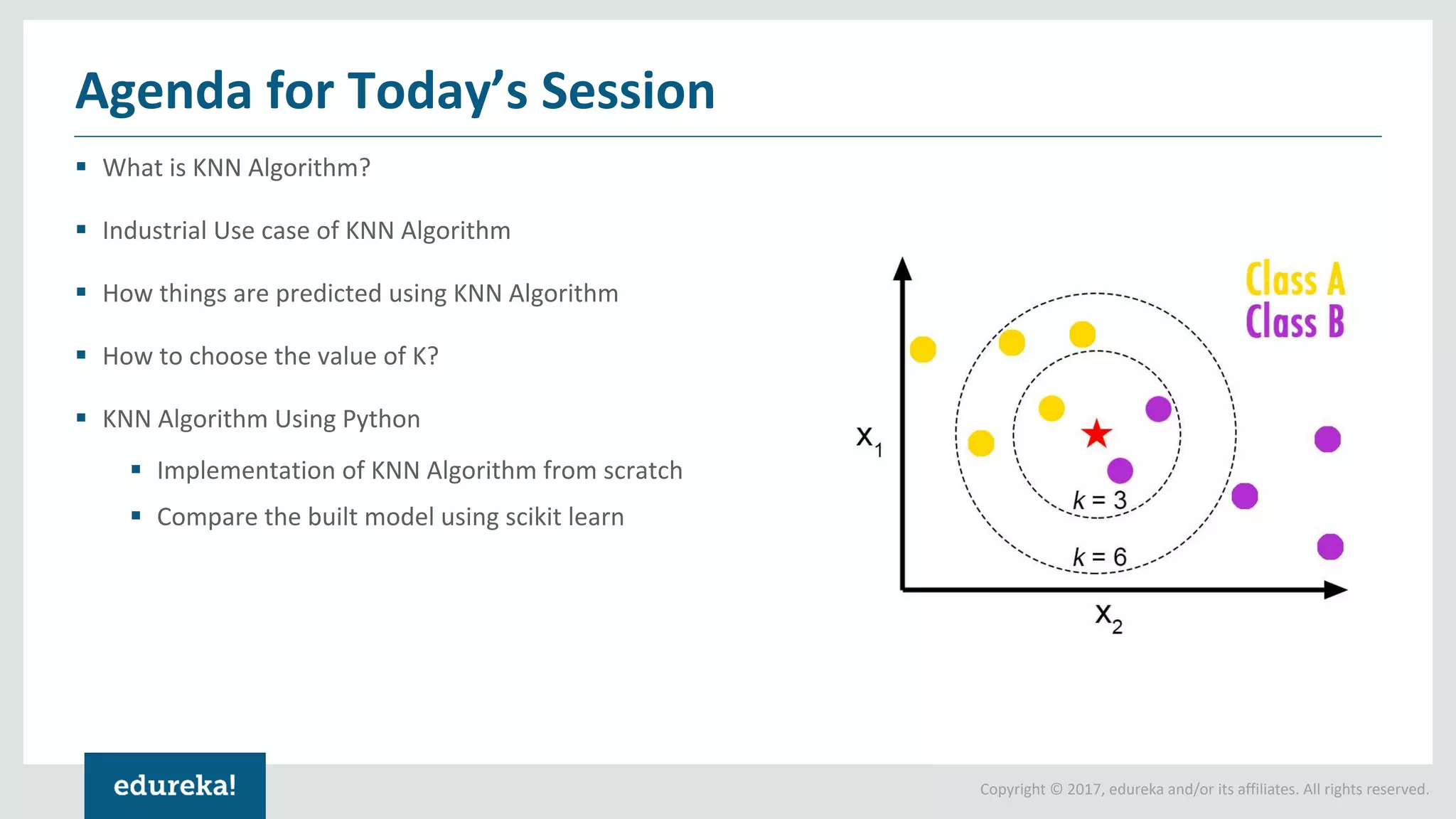


















The document discusses the K-Nearest Neighbors (KNN) algorithm, which classifies new data based on similarity to existing cases. It covers topics such as choosing the value of 'k', industrial applications, and implementation in Python, alongside methods to predict outcomes using different distance metrics like Euclidean and Manhattan distances. The process of handling data, including dataset preparation and evaluating prediction accuracy, is also outlined.





























![k-nearestneighborknn-231215171119-a5cfb915.pptx [Read-Only].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/k-nearestneighborknn-231215171119-a5cfb915-251010013925-09814a4b-thumbnail.jpg?width=640&height=640&fit=bounds)
















































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)








