

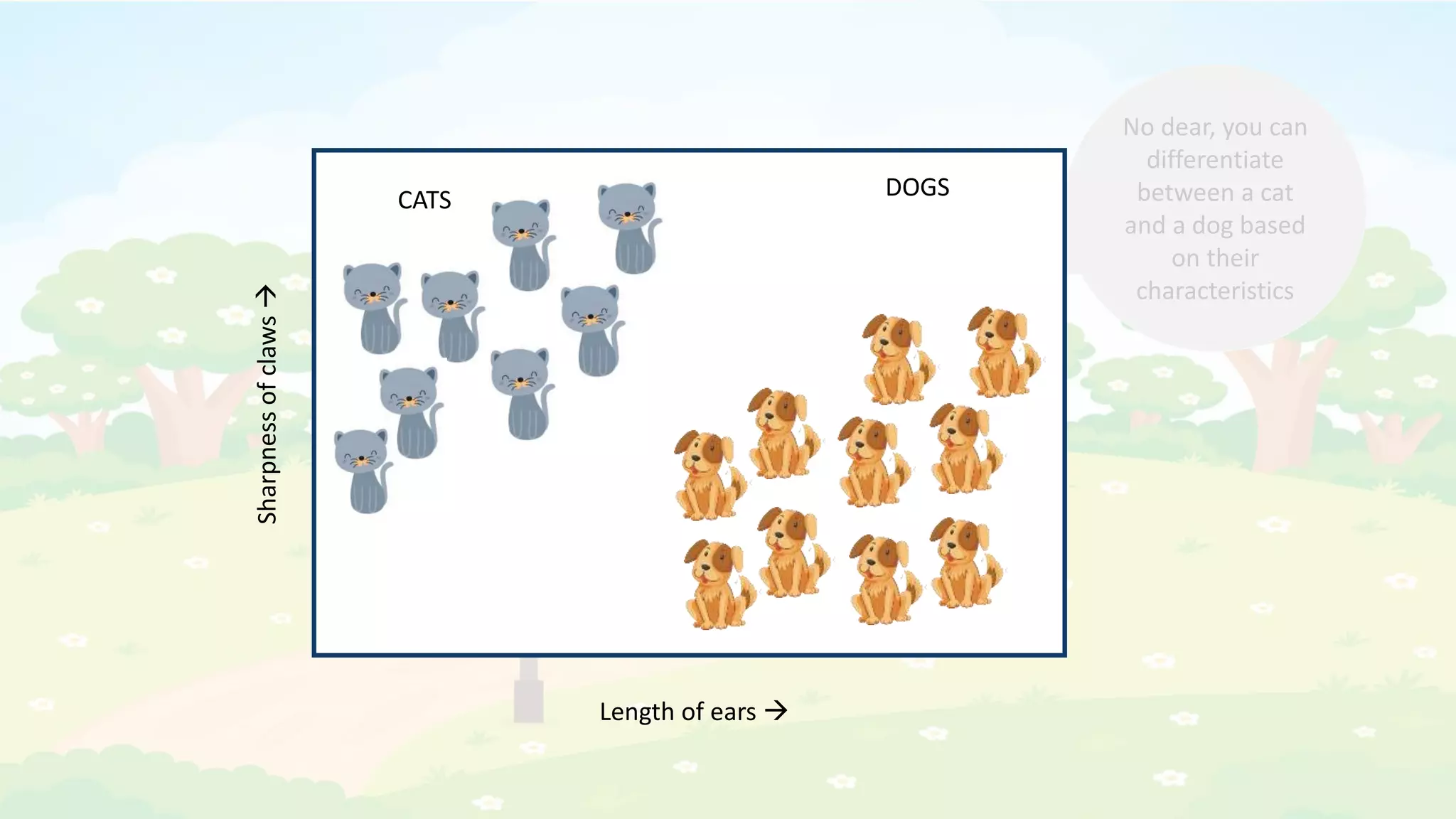

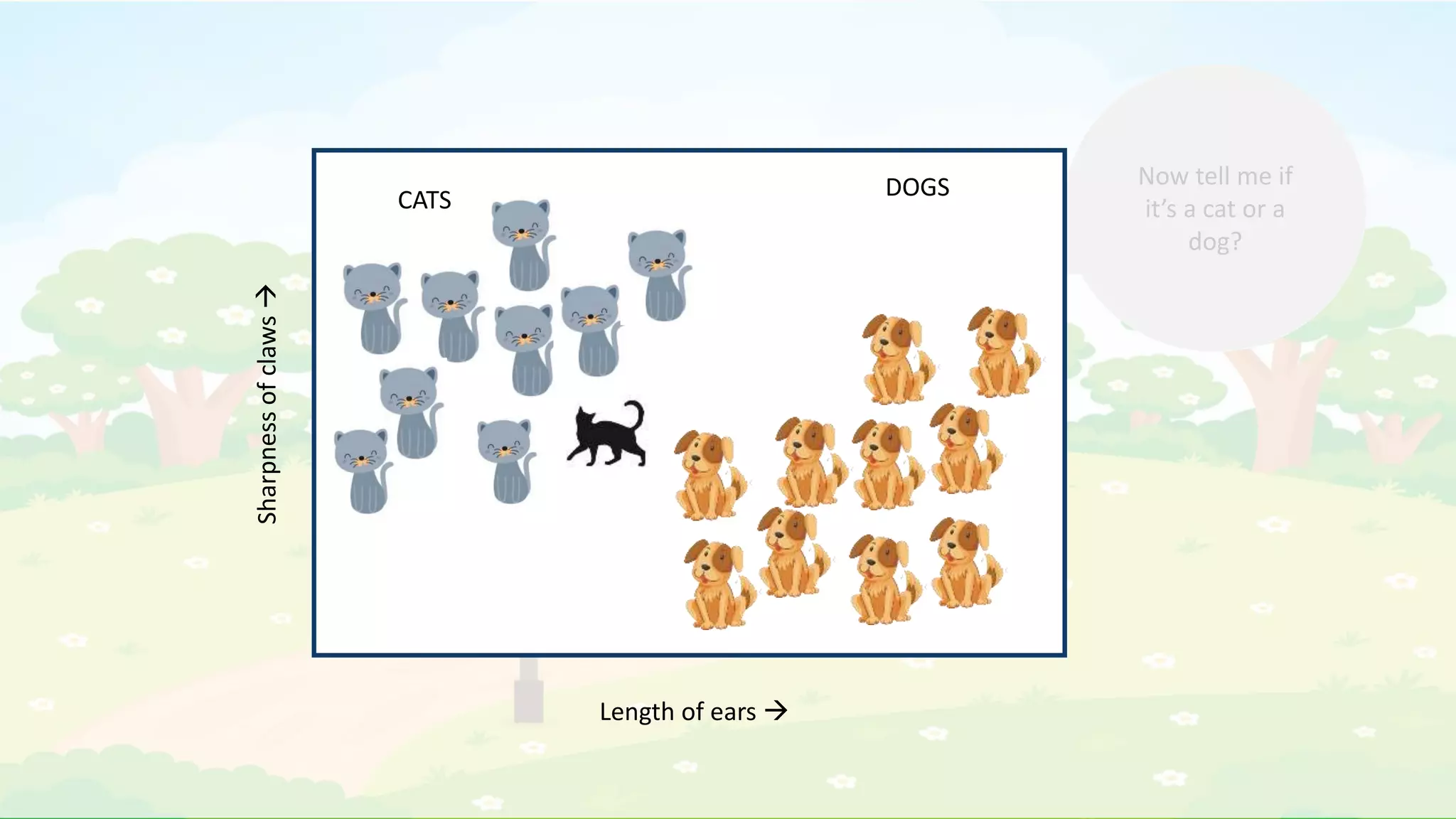

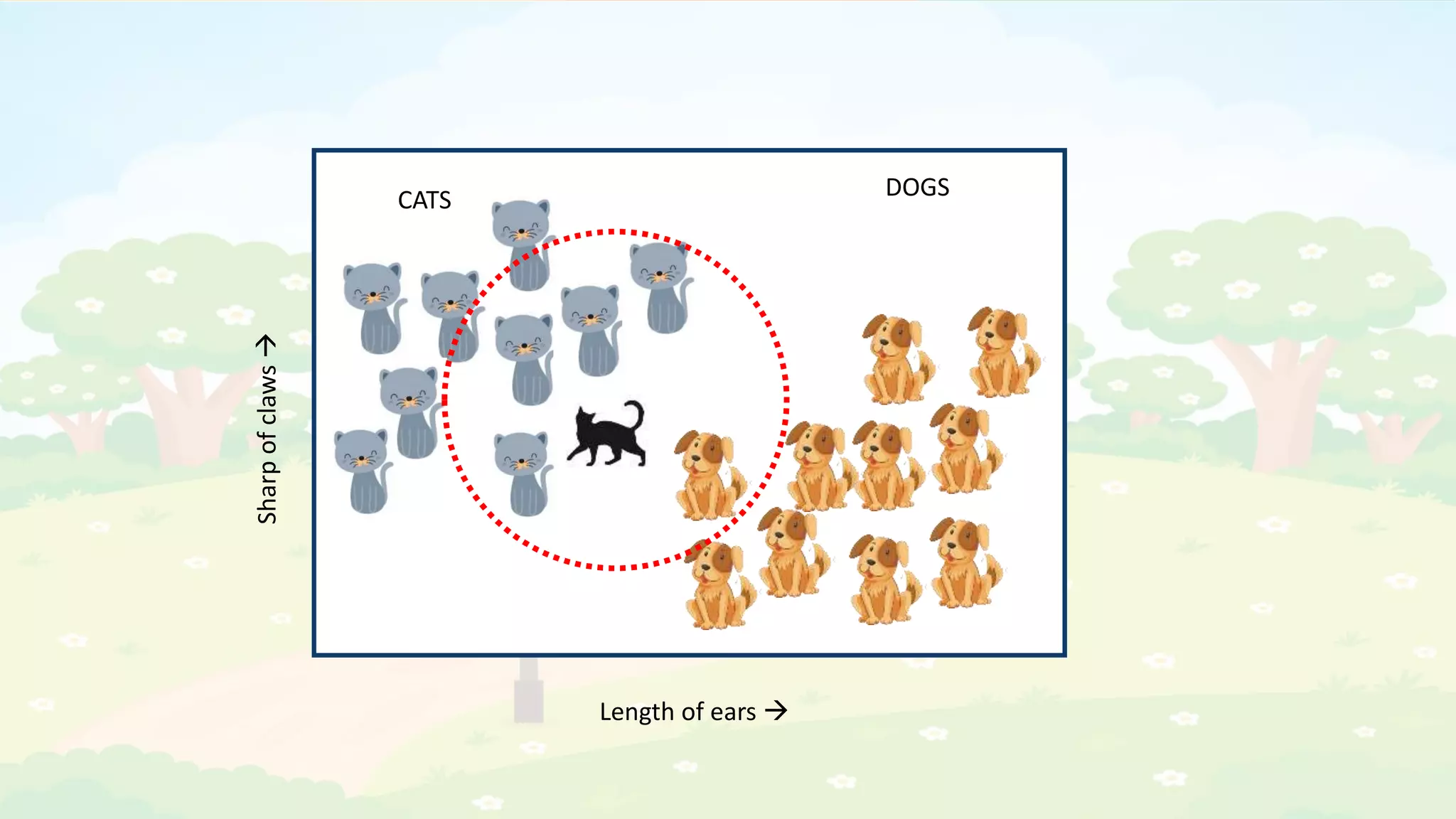
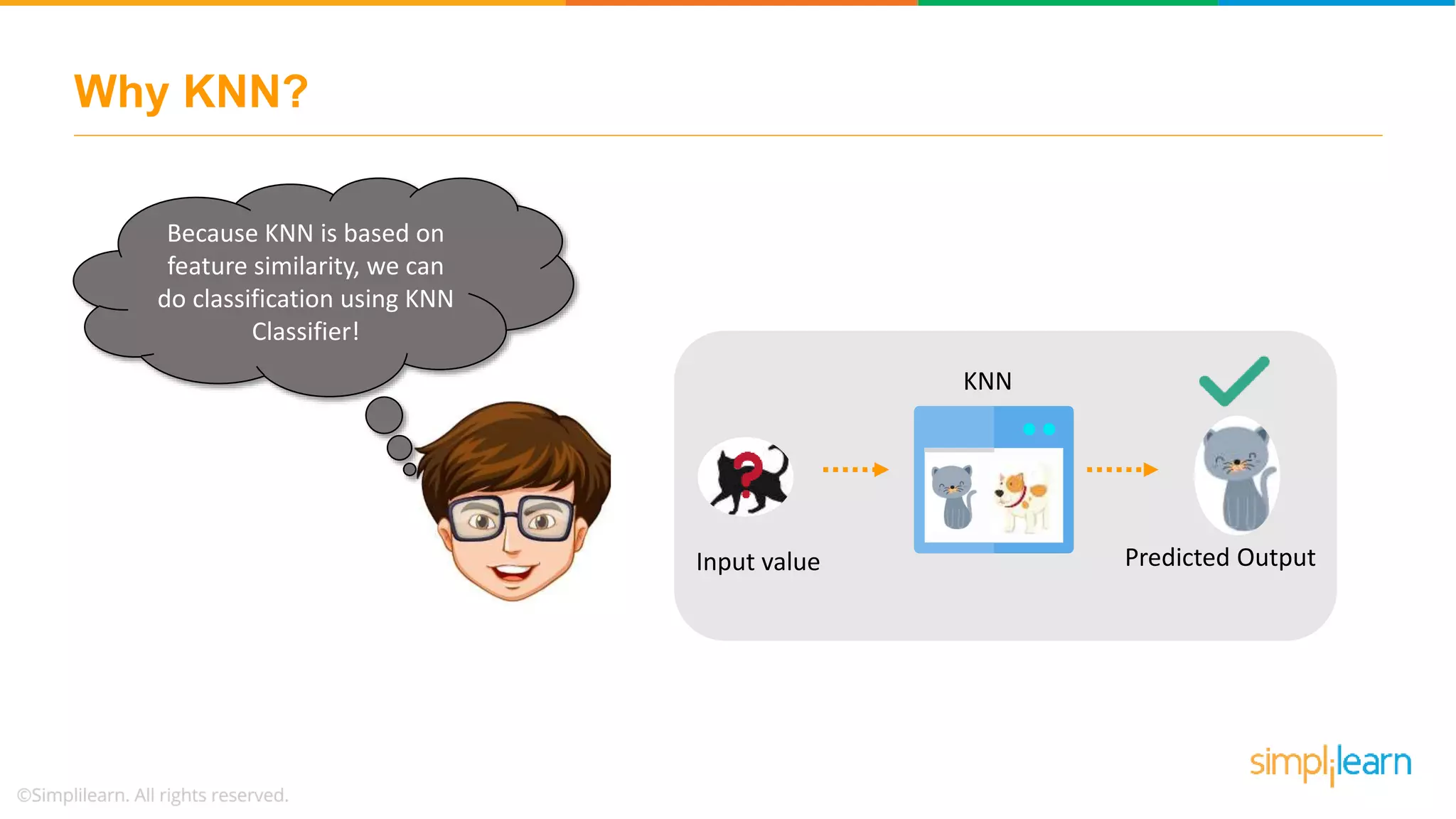
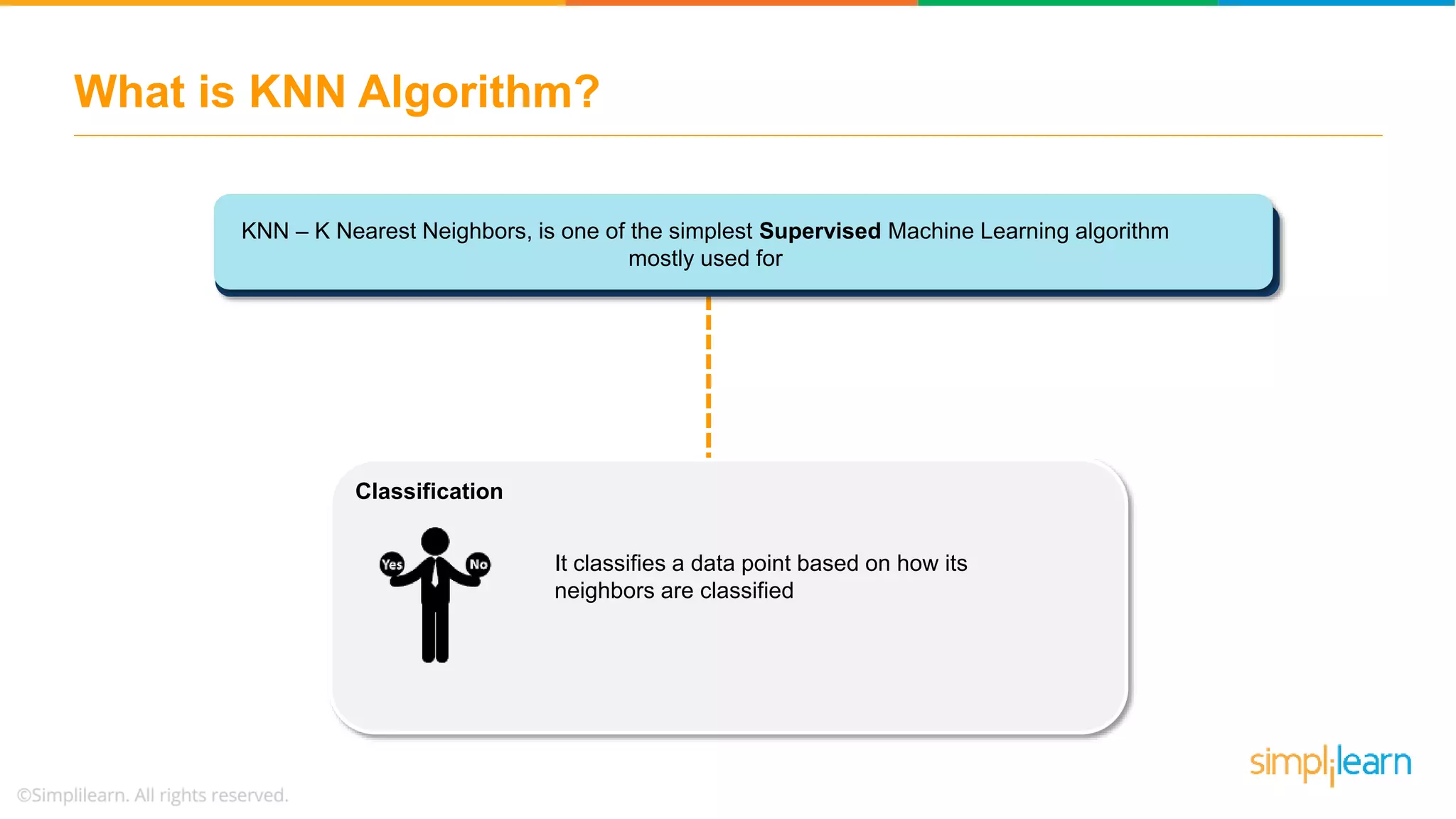
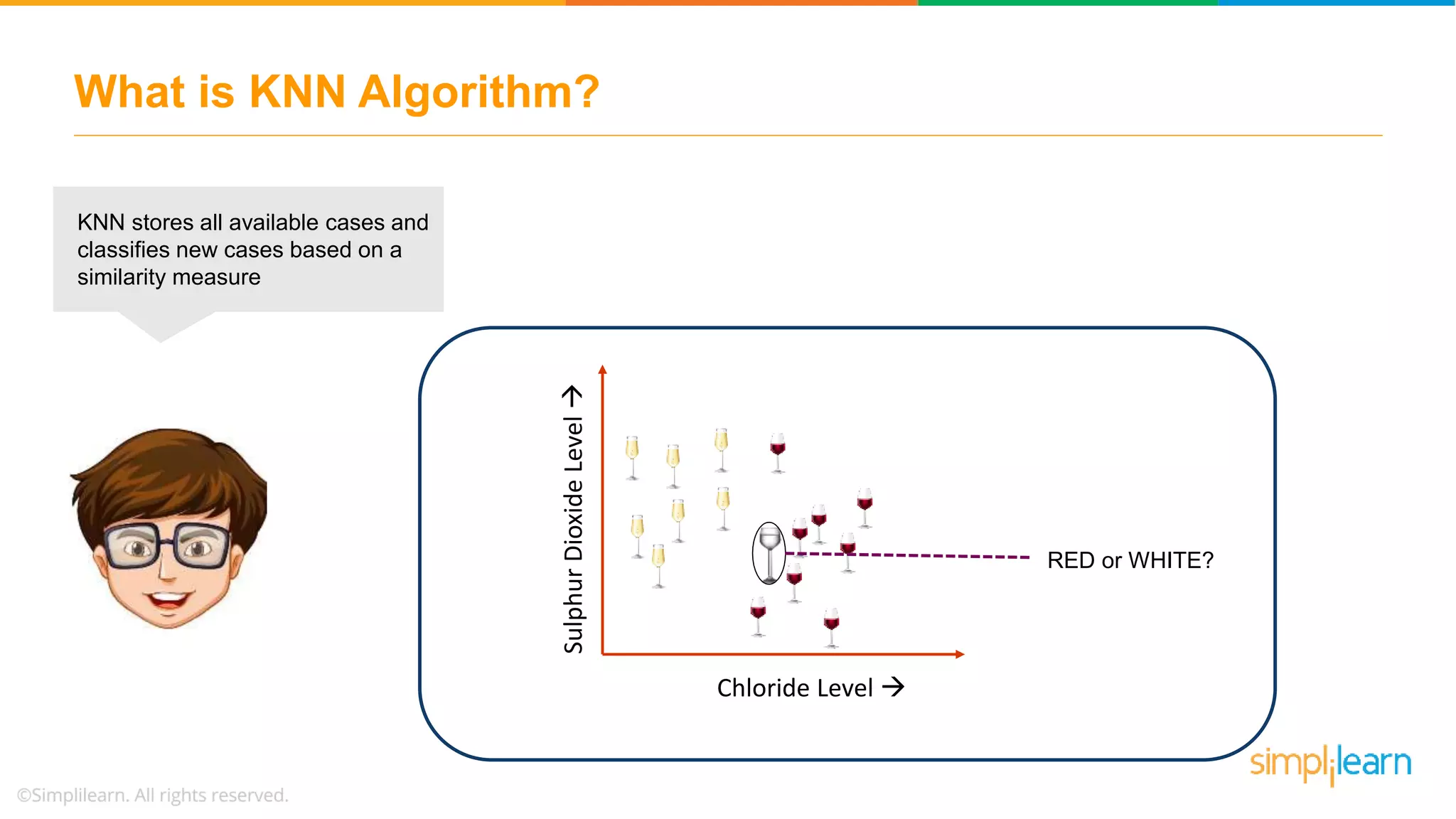
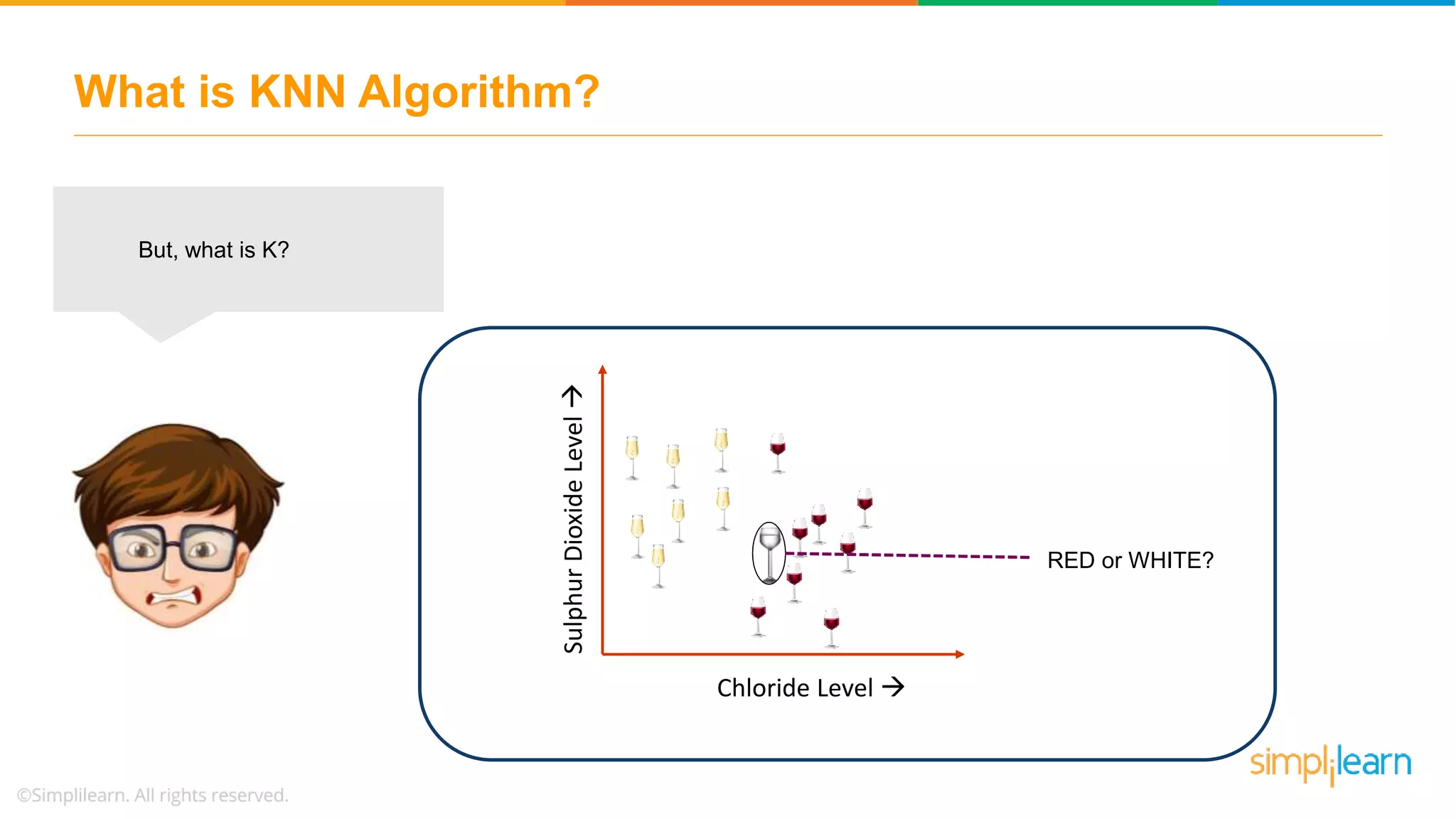
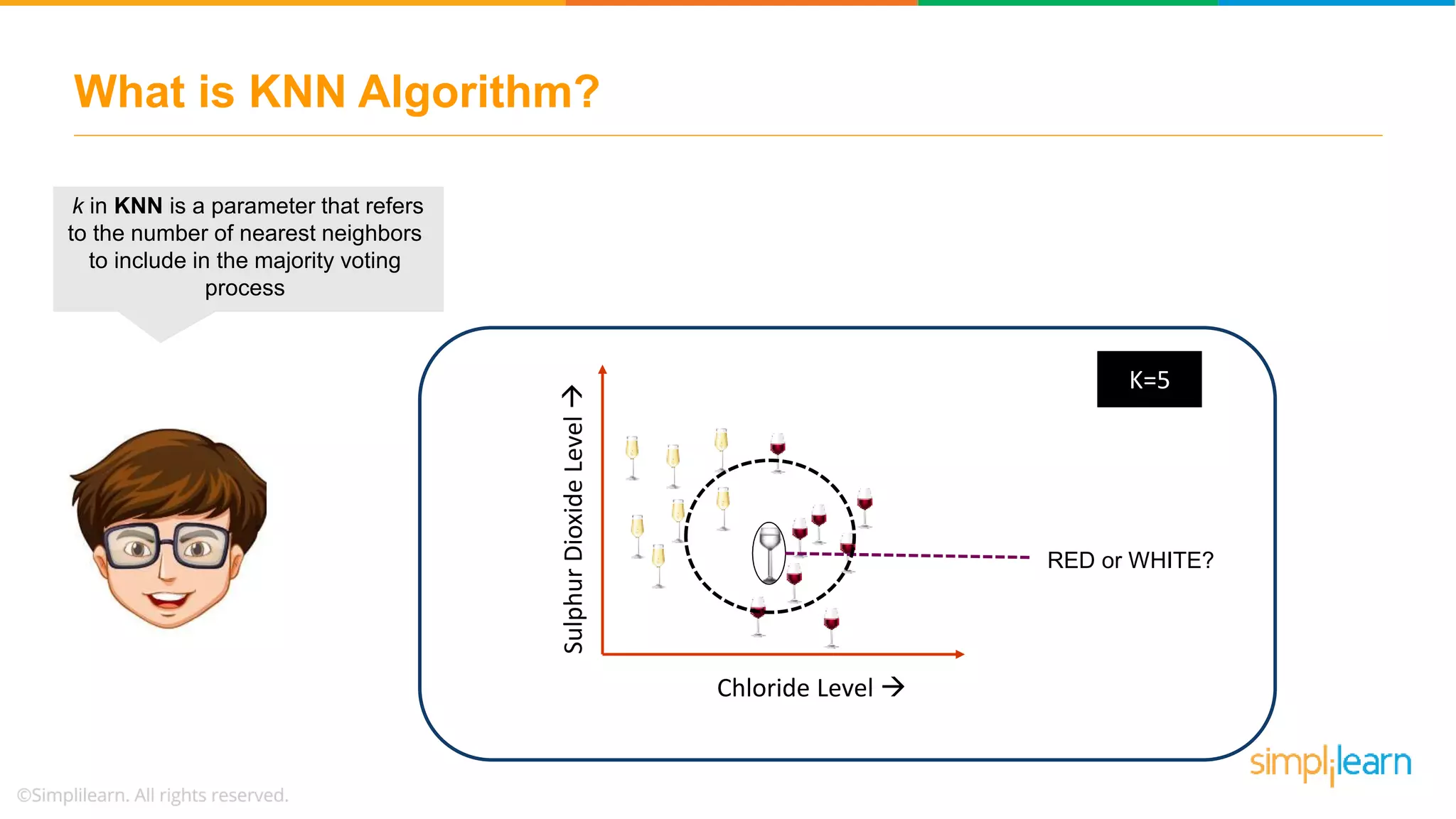
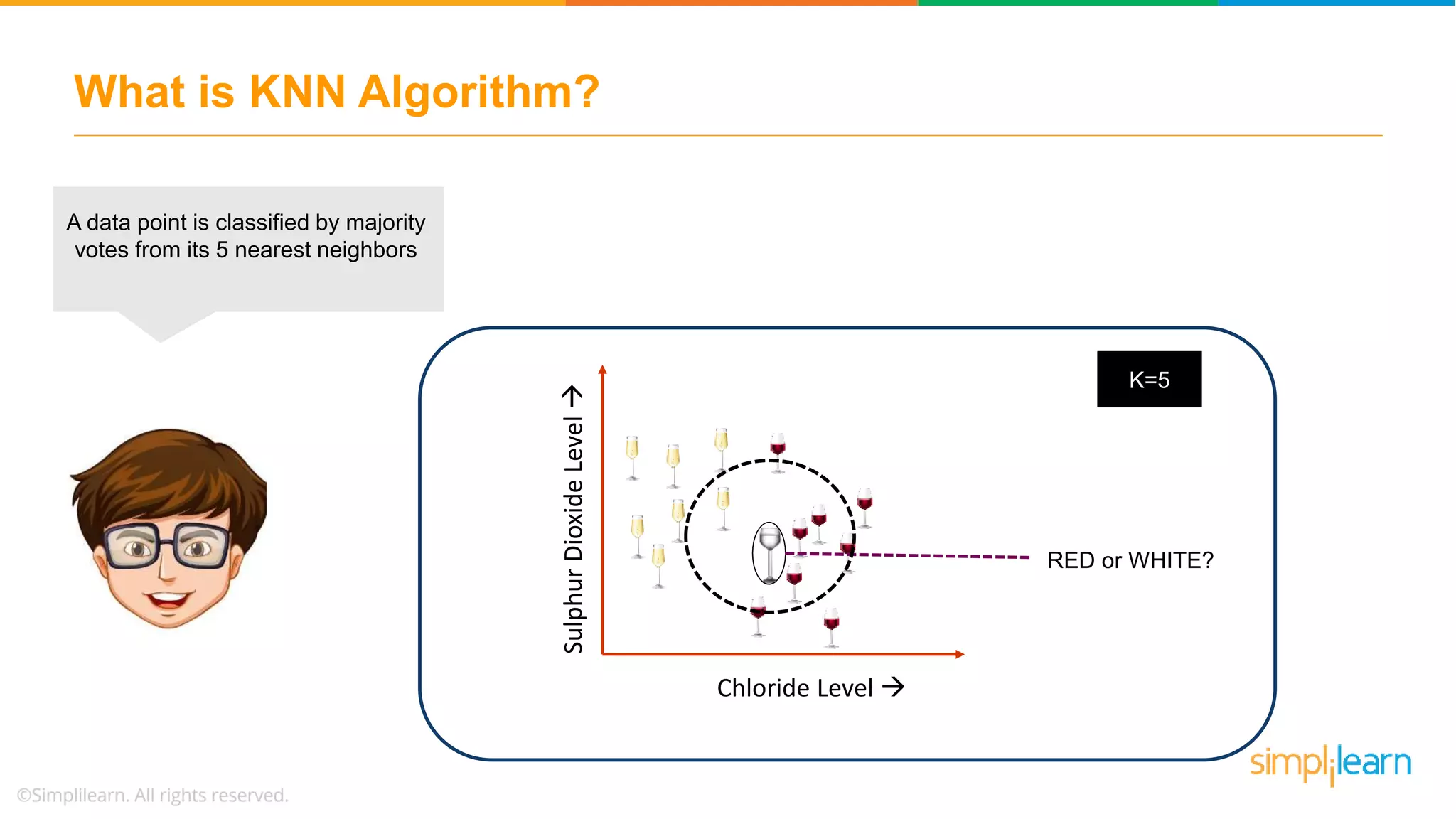
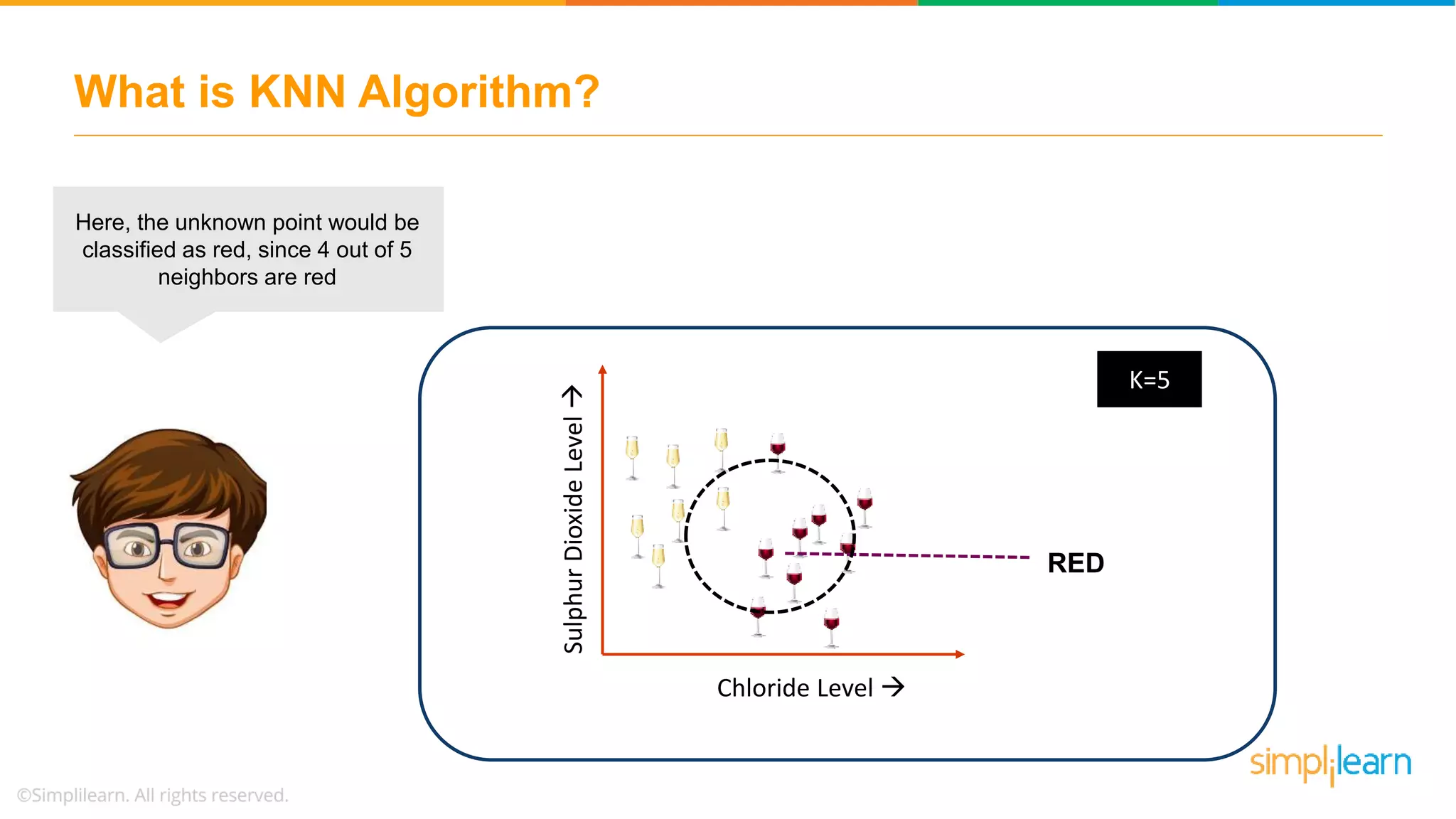
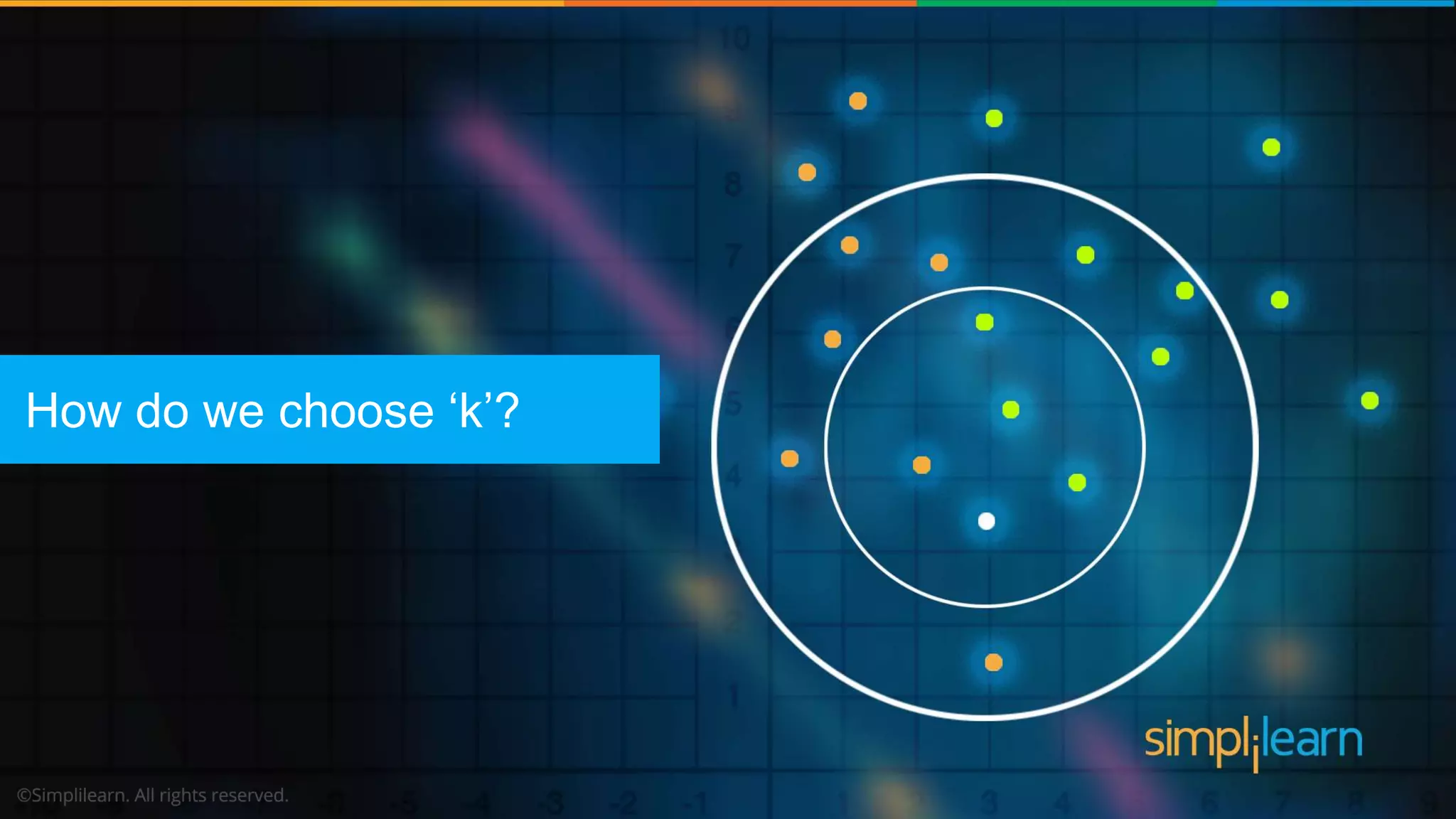

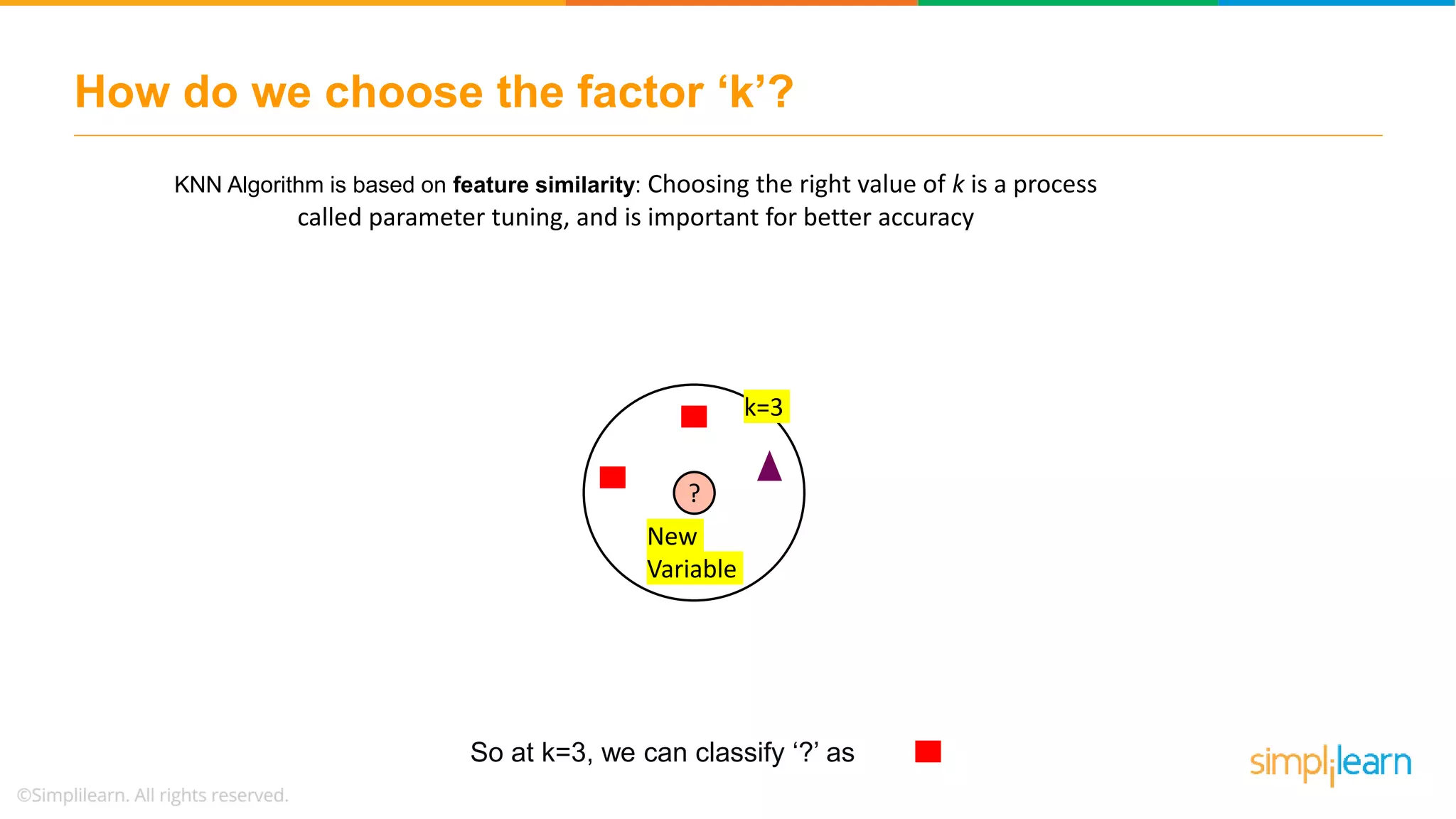
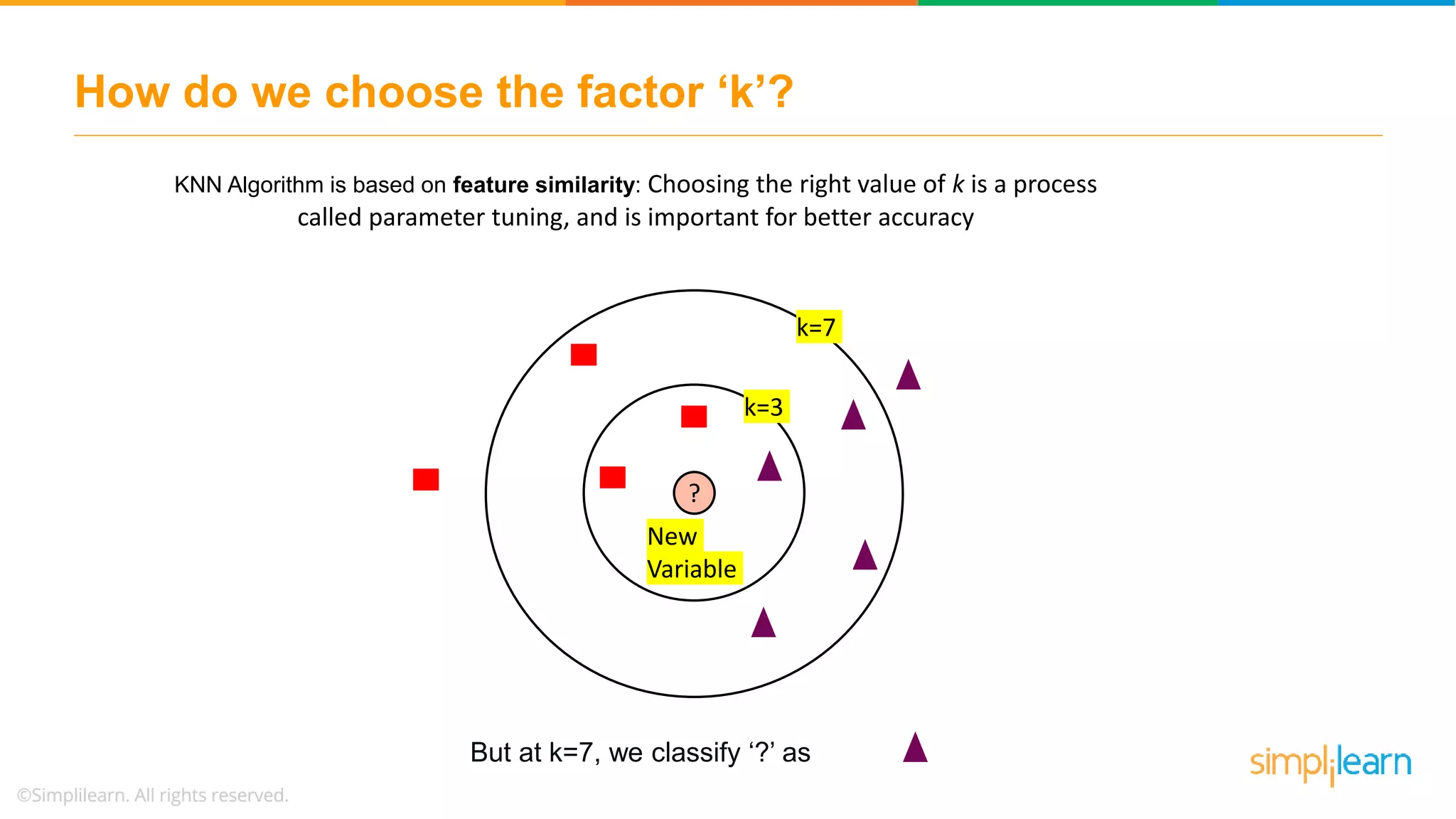
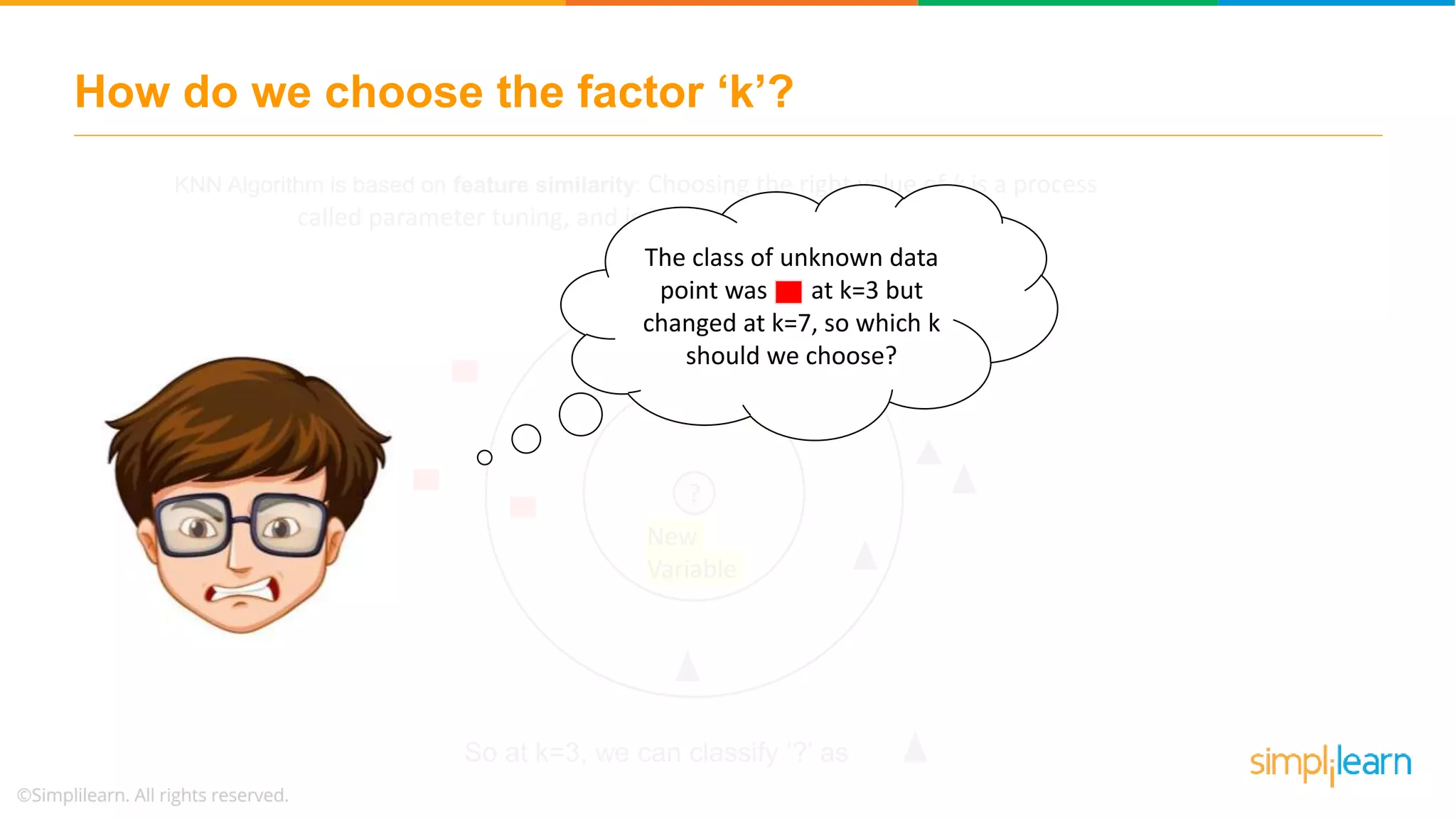


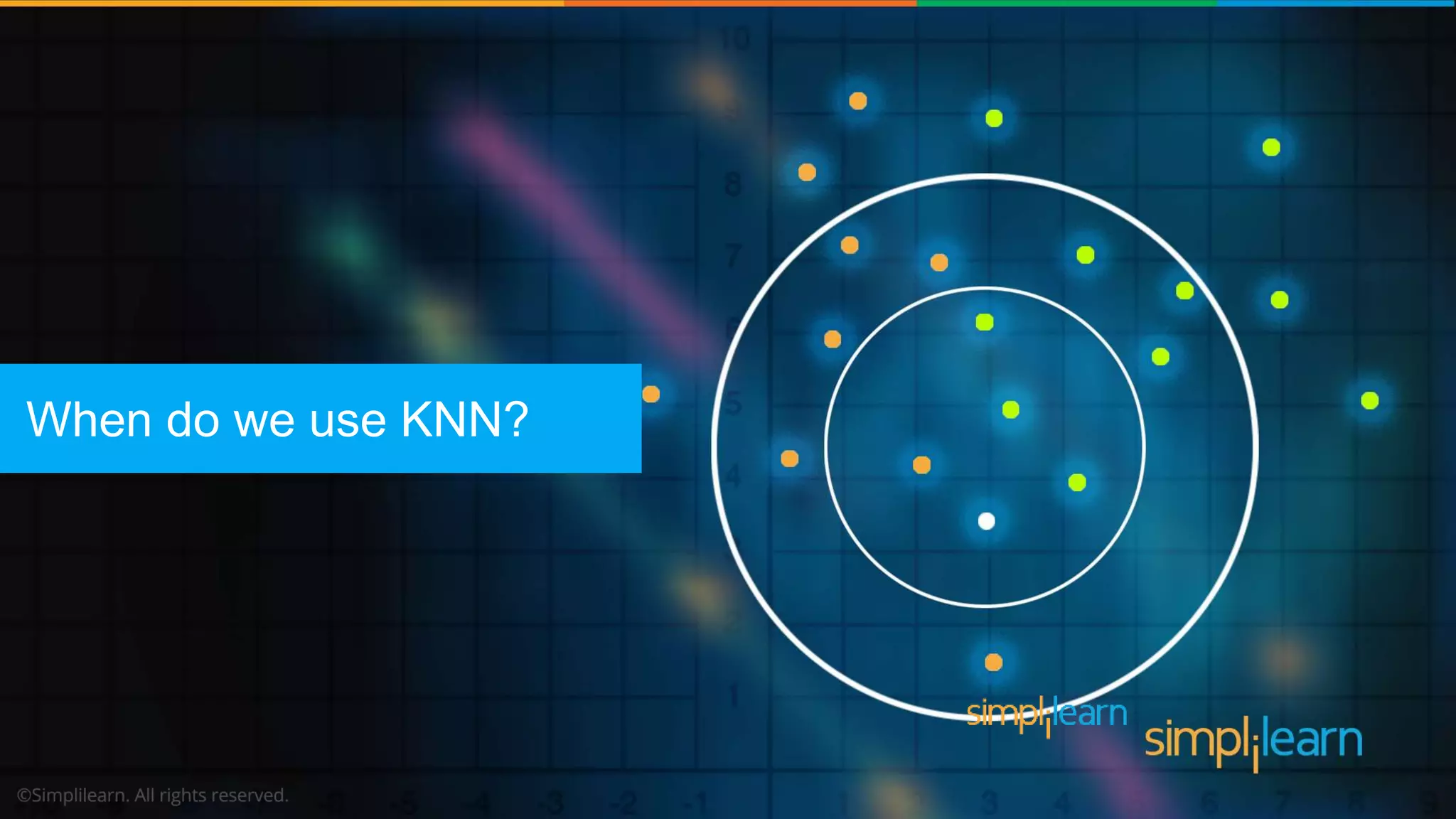
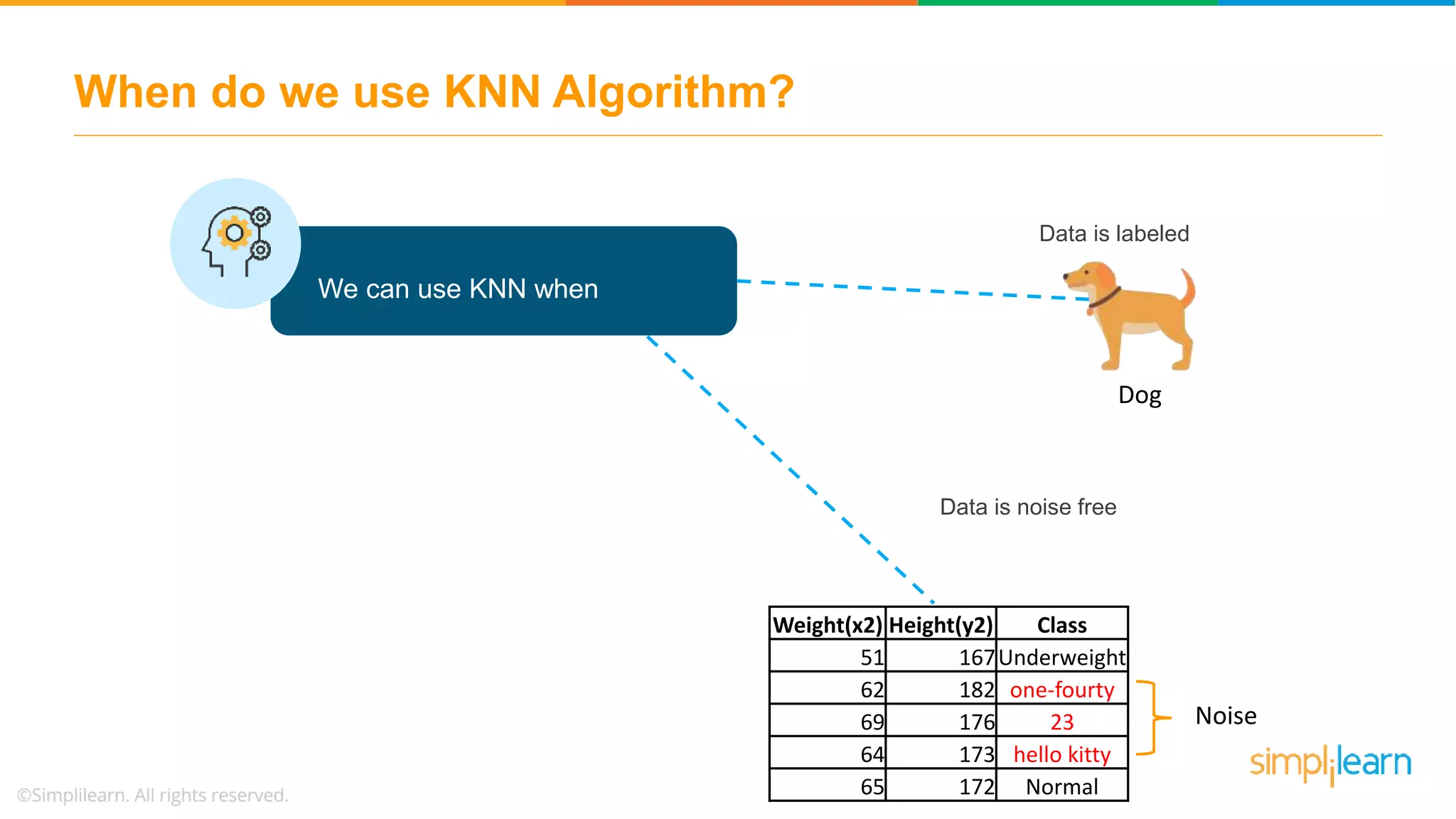
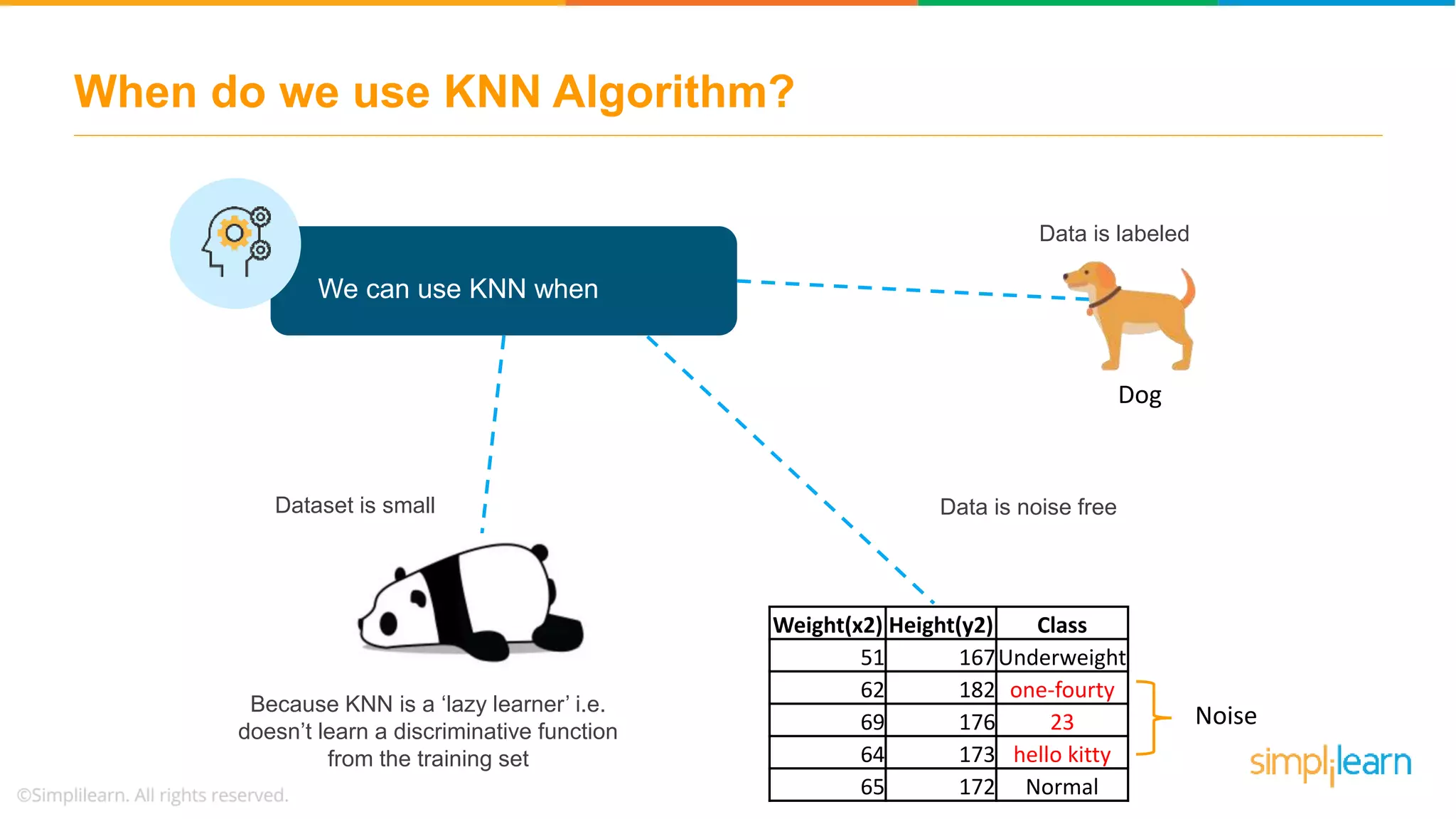

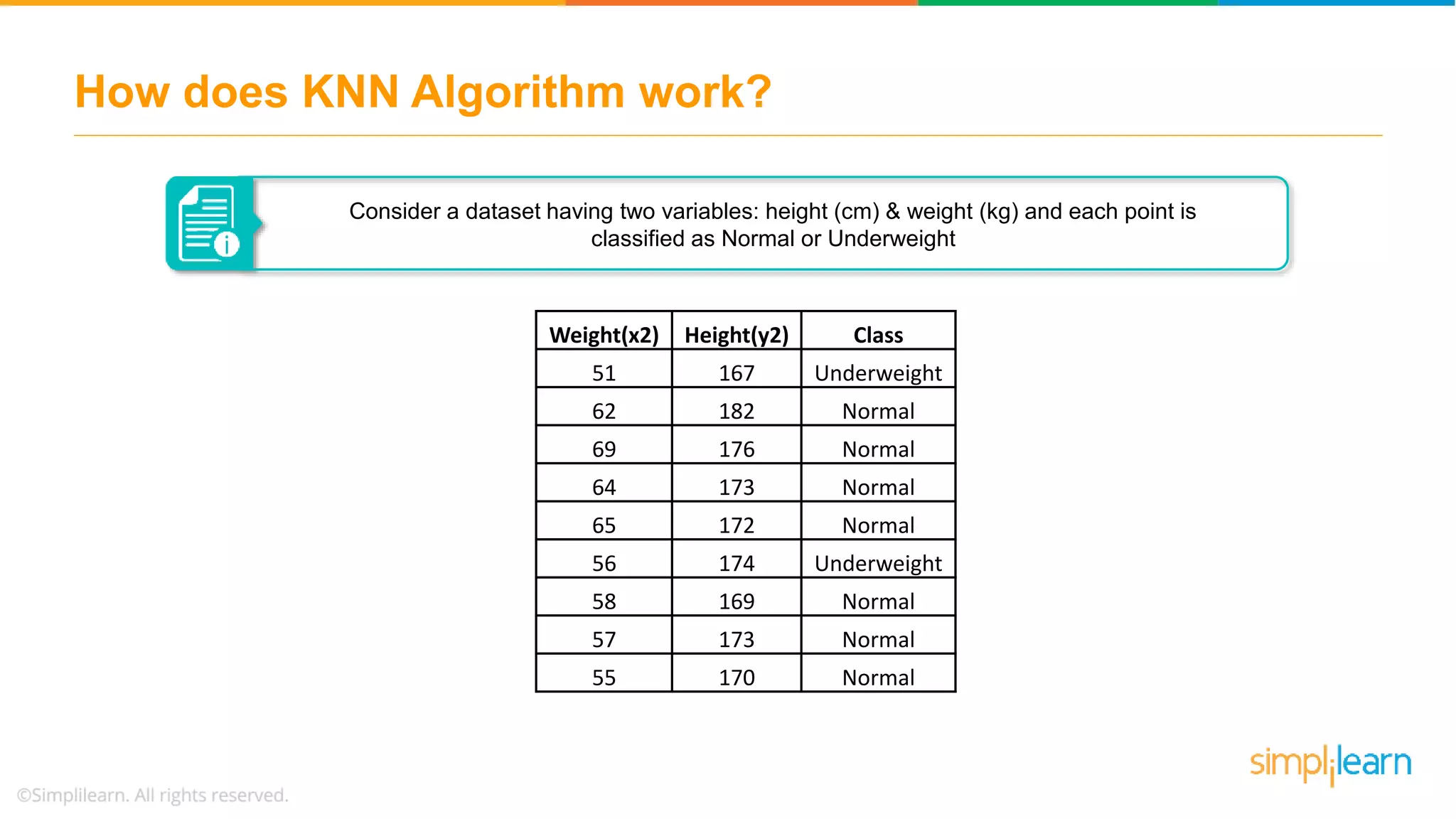


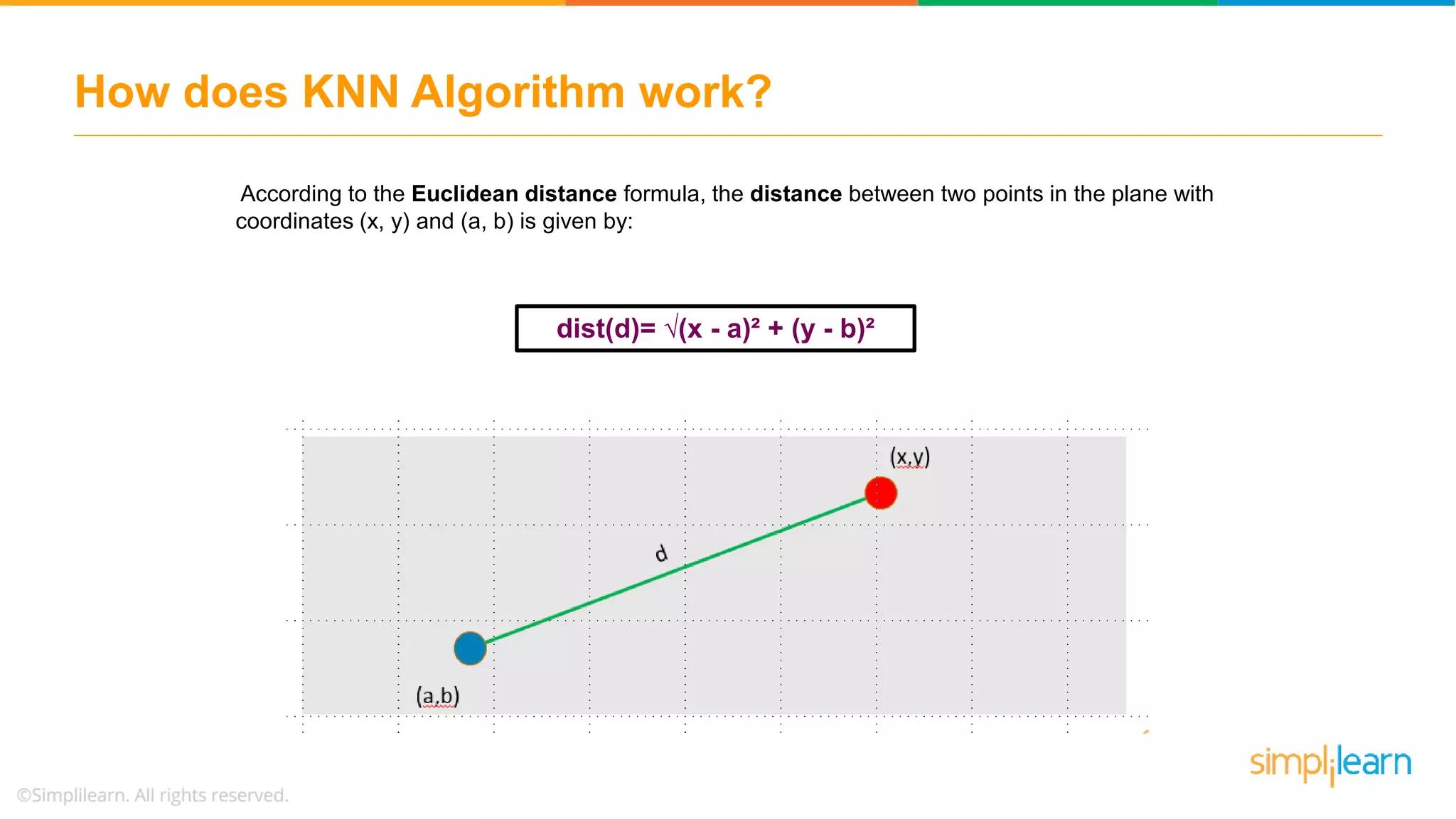
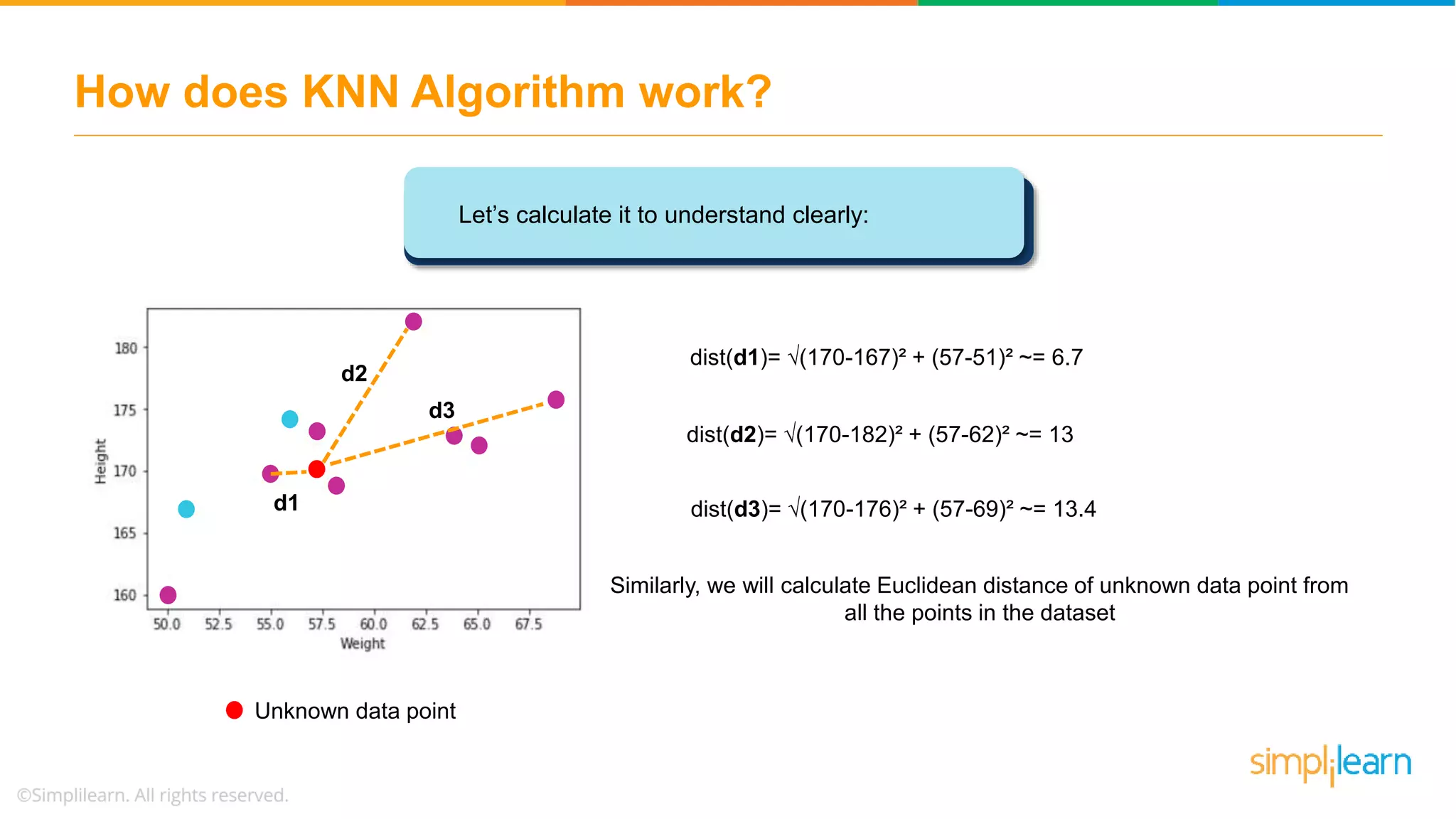
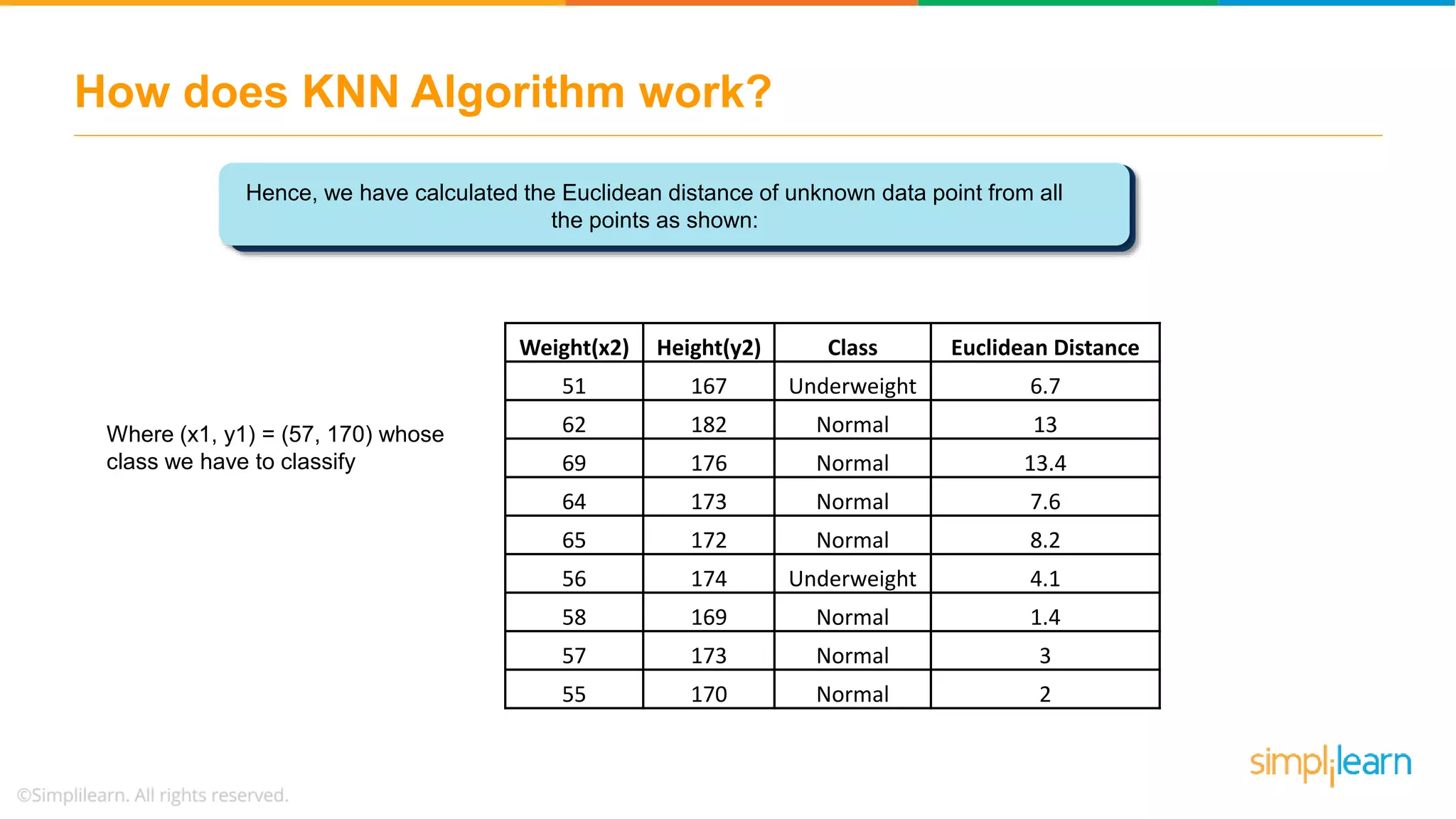
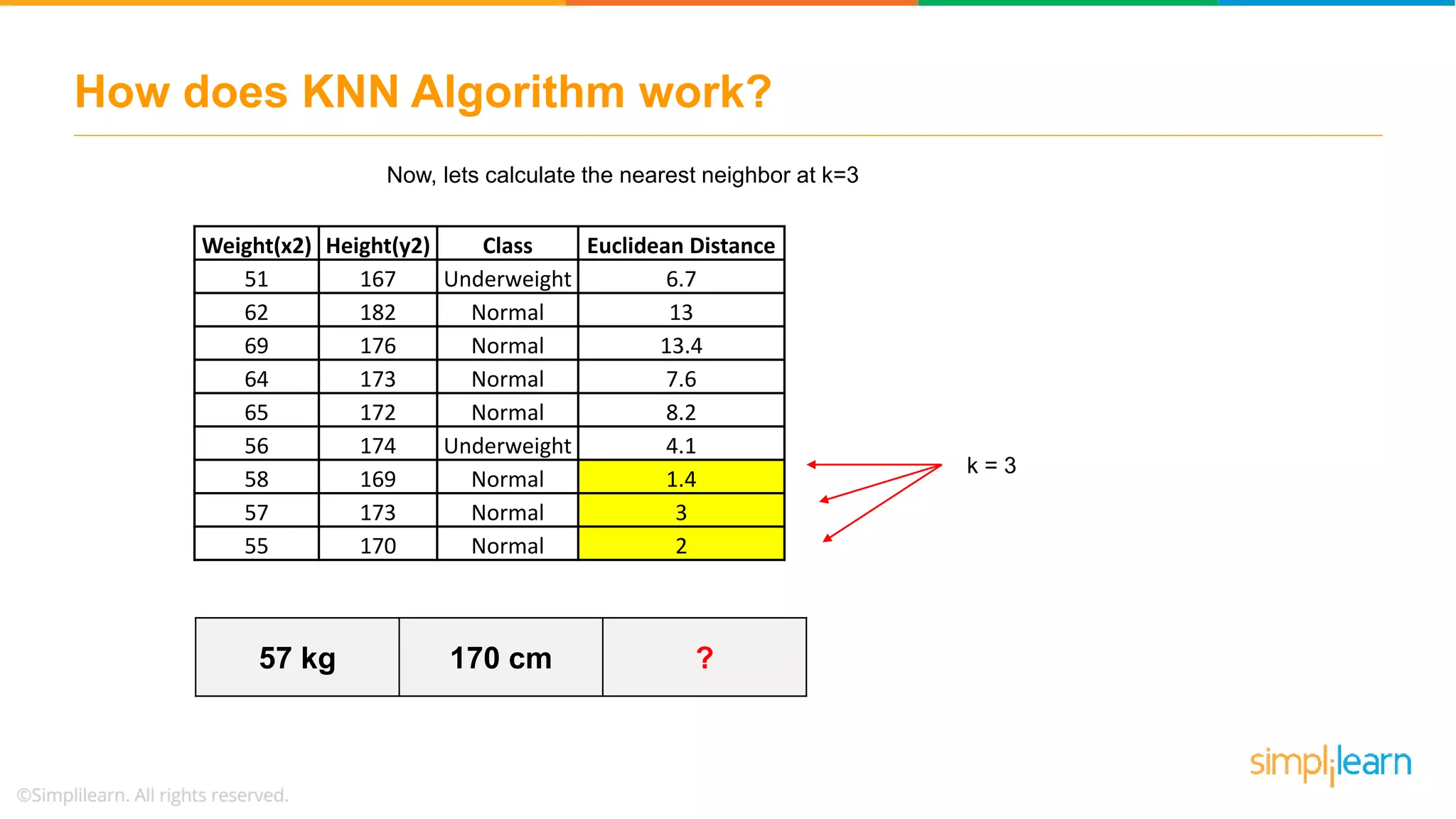
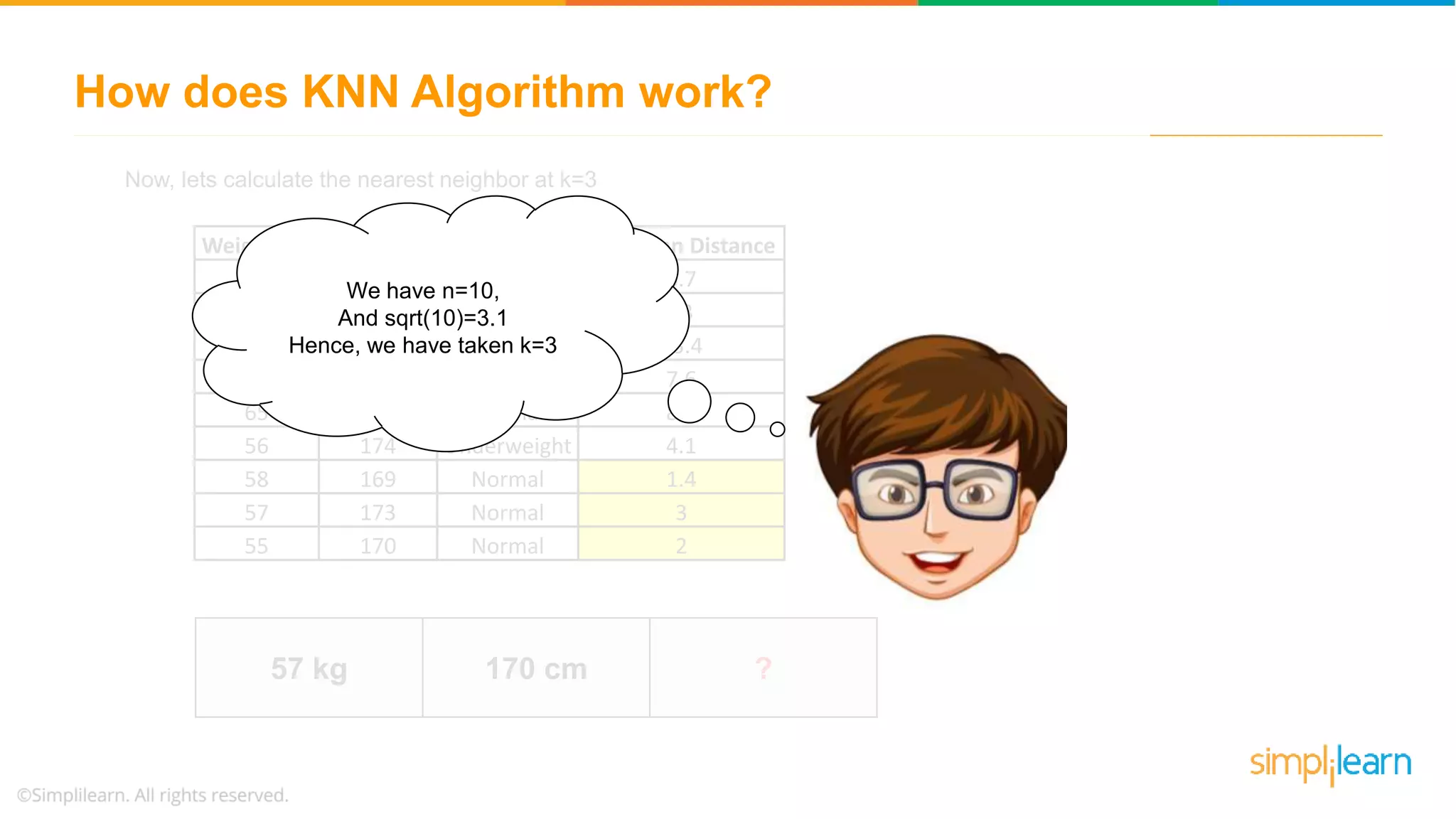


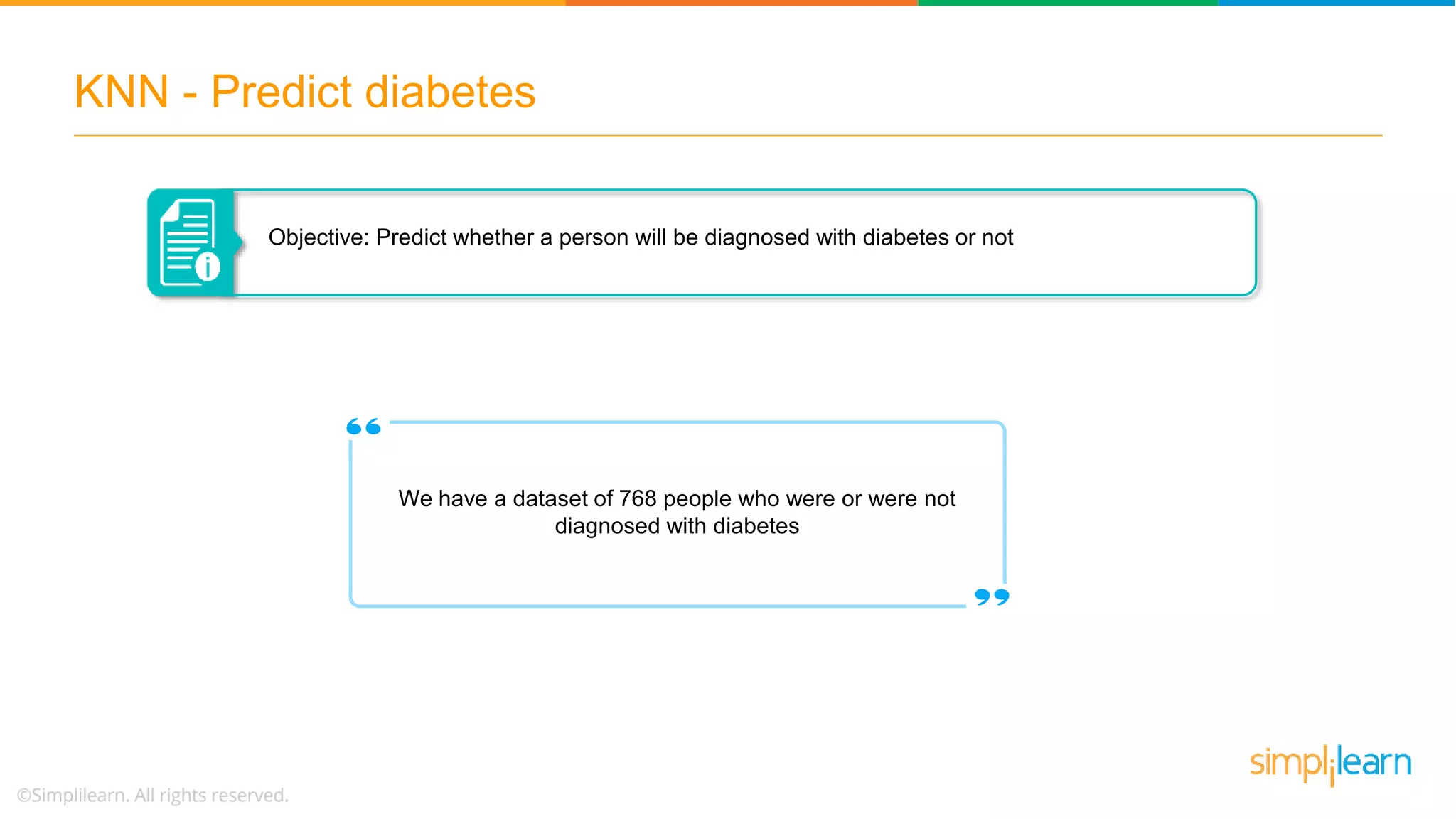

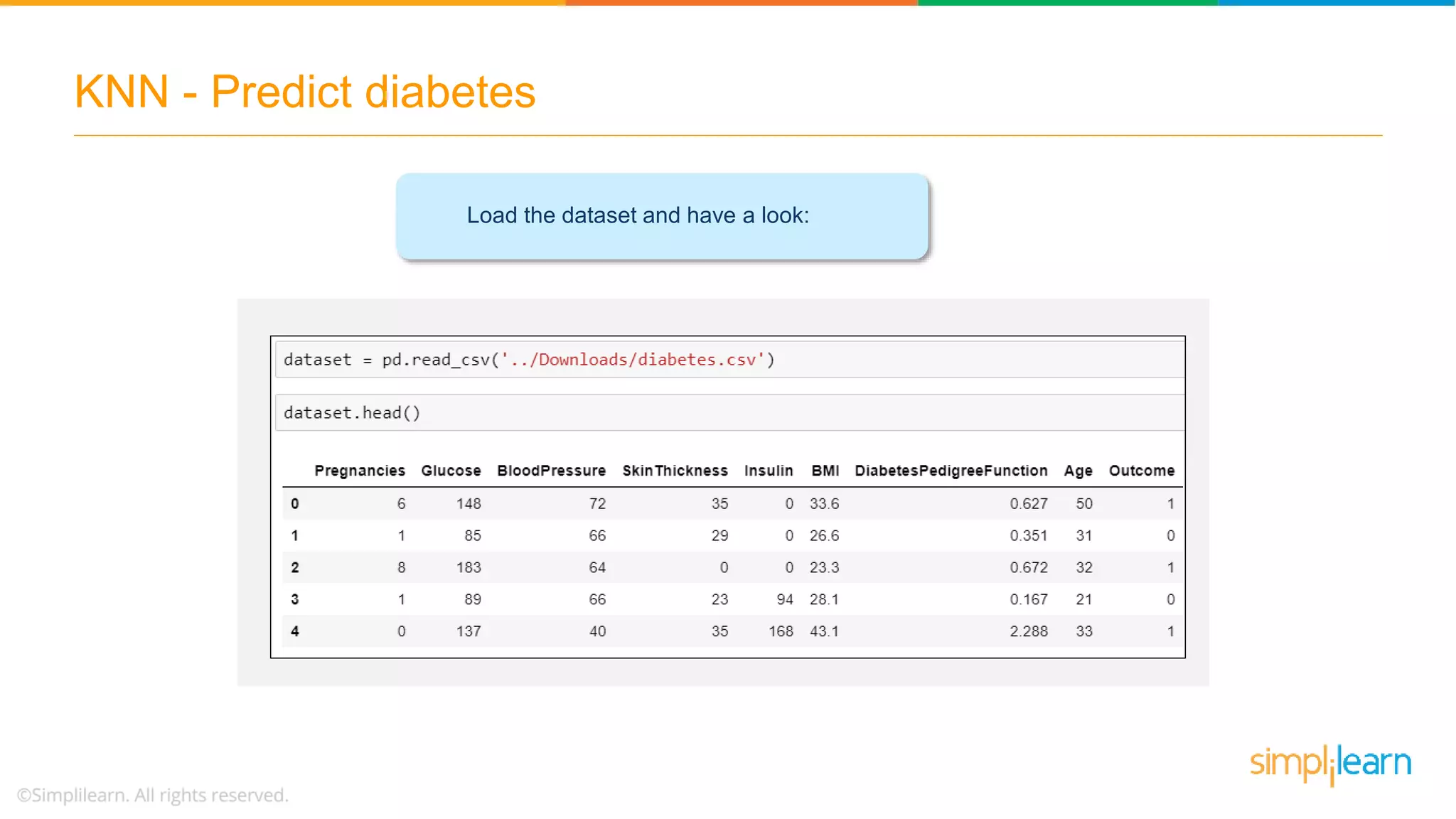
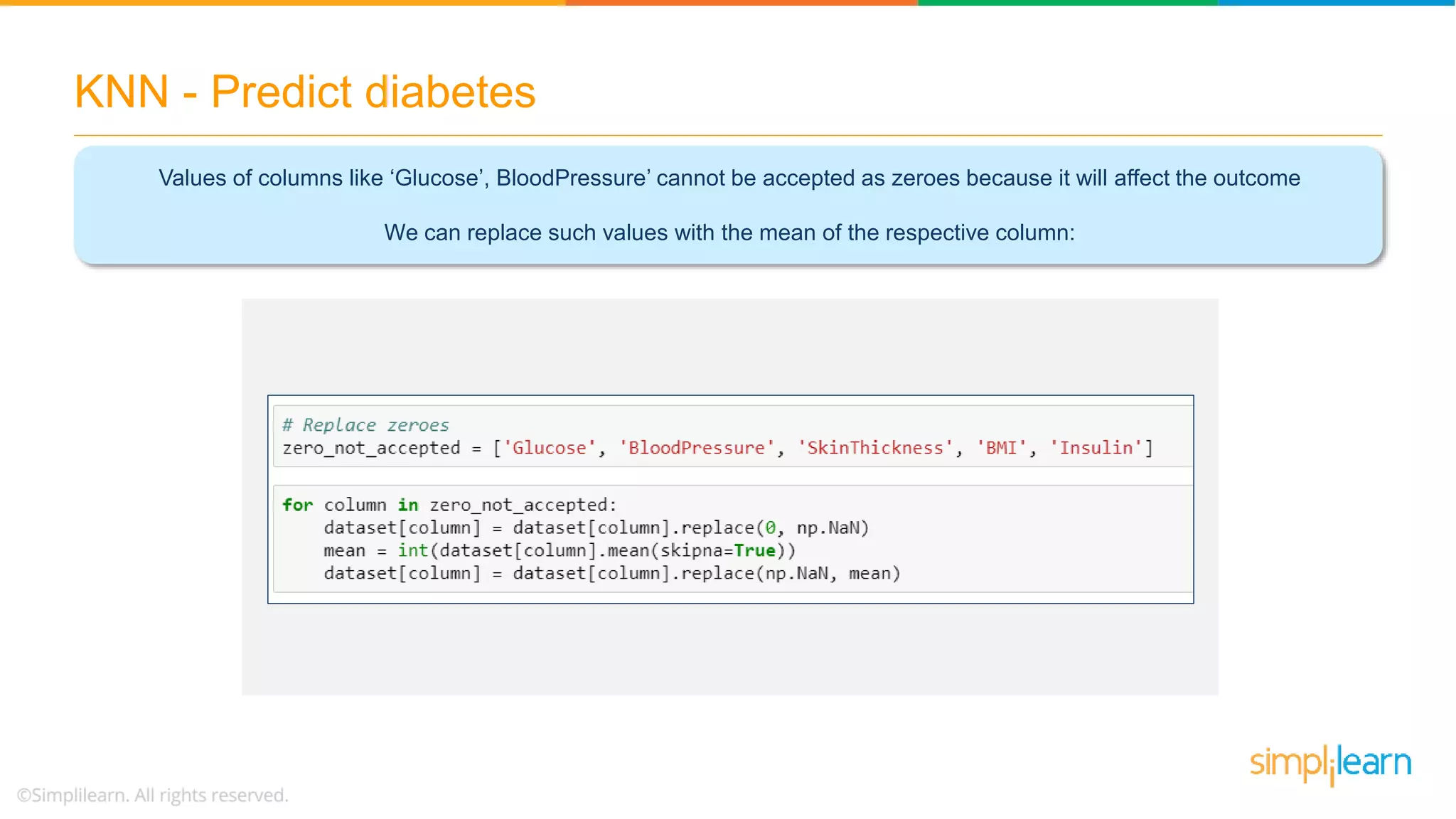
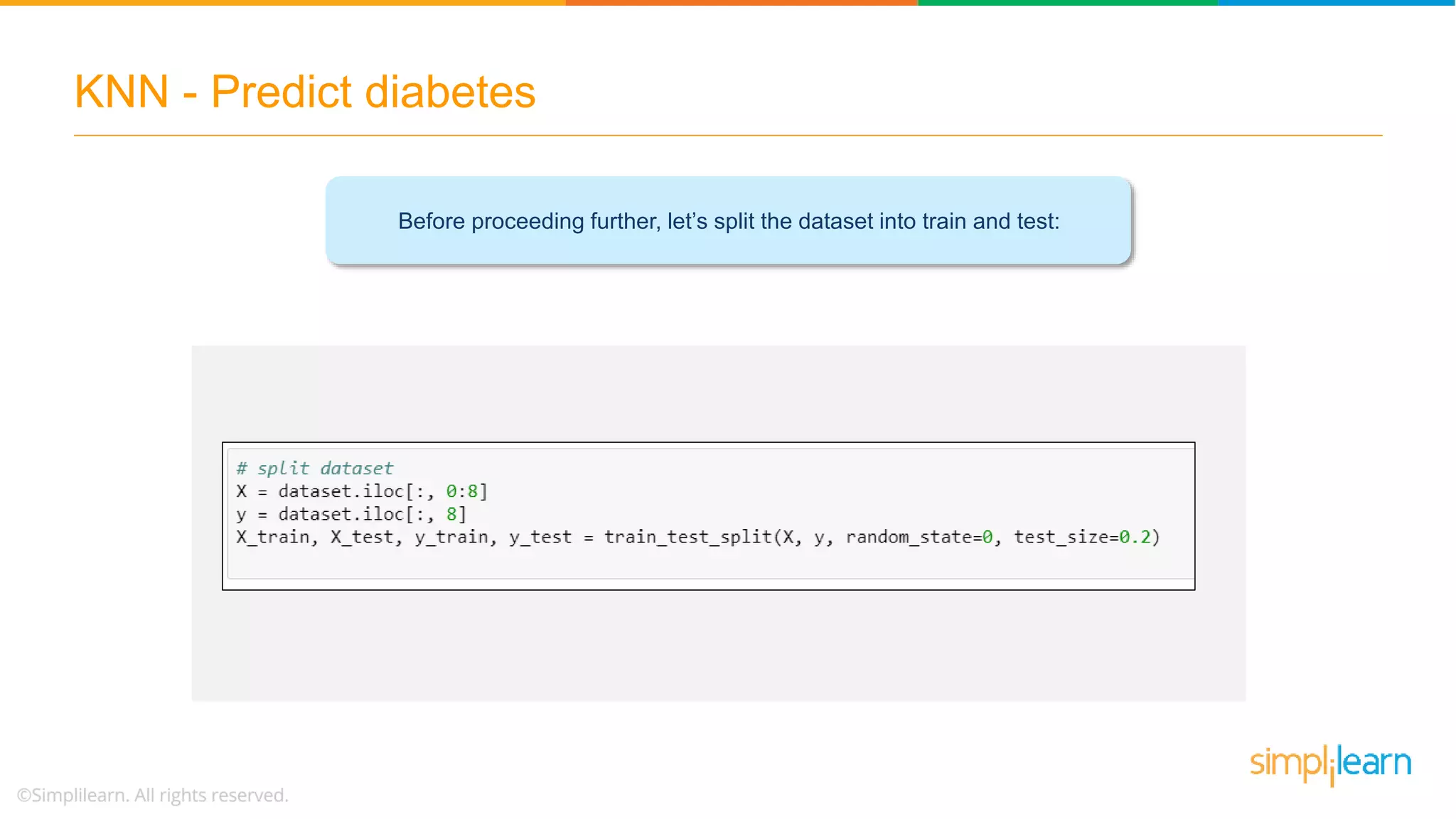
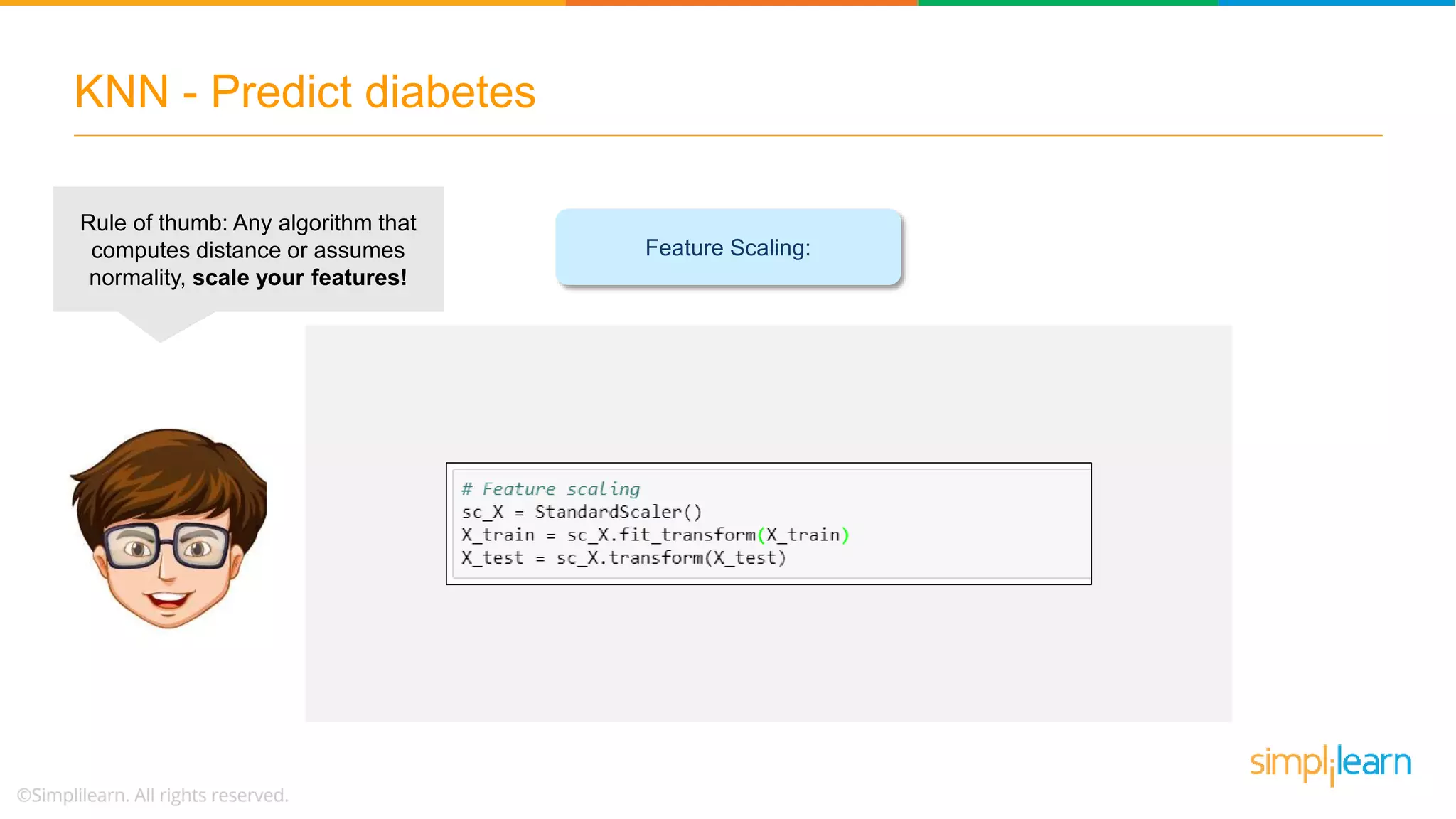
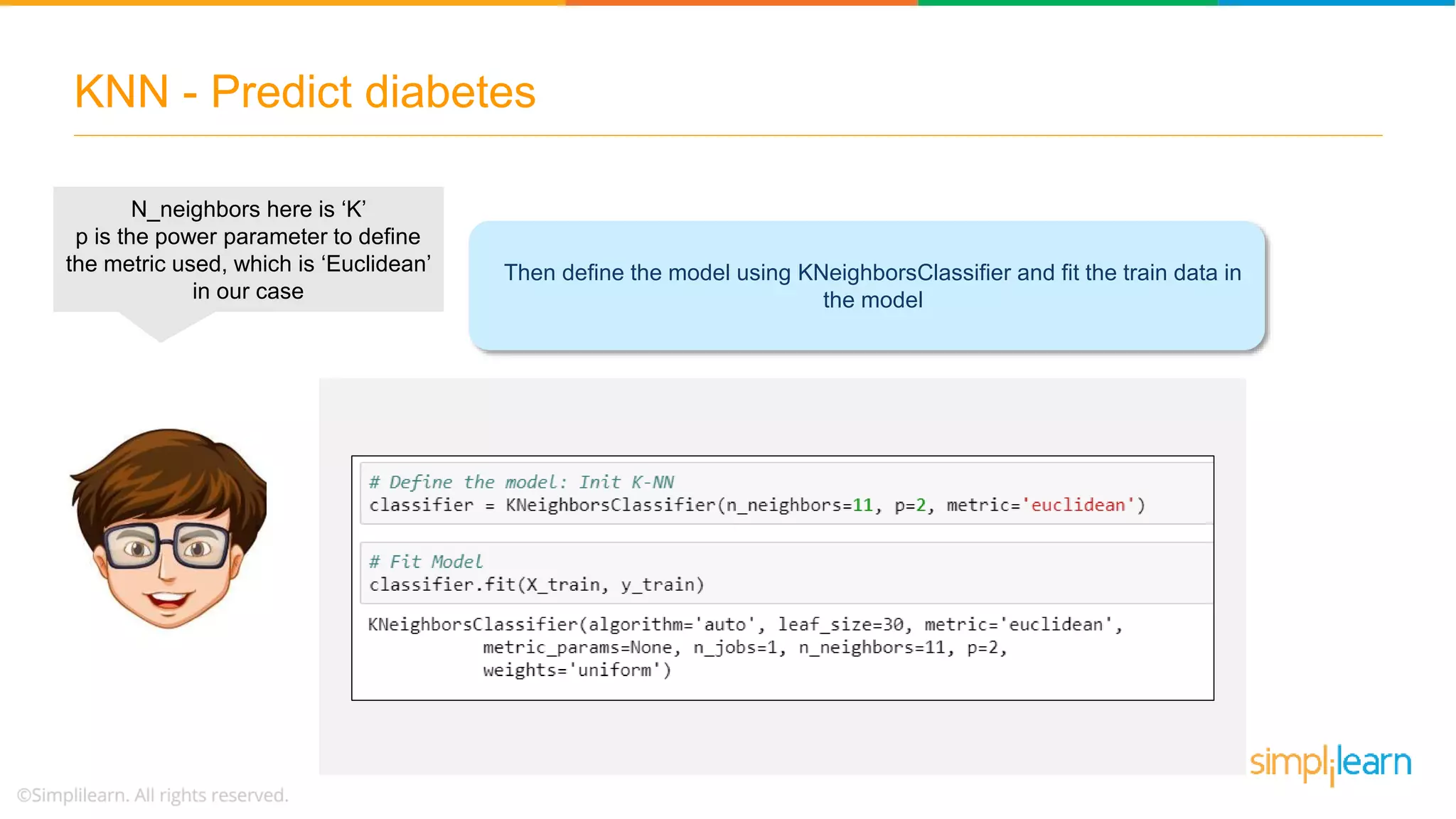

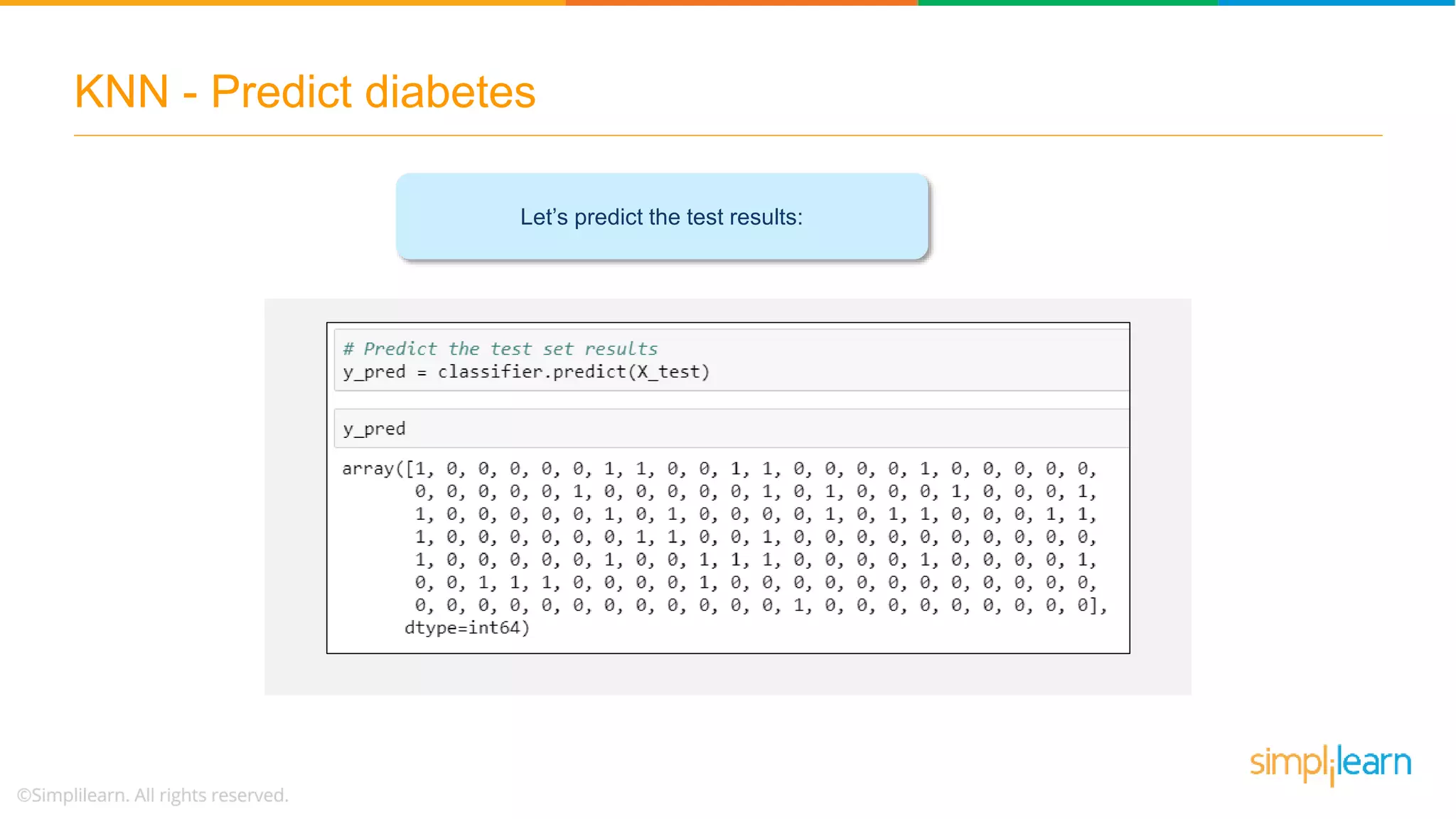
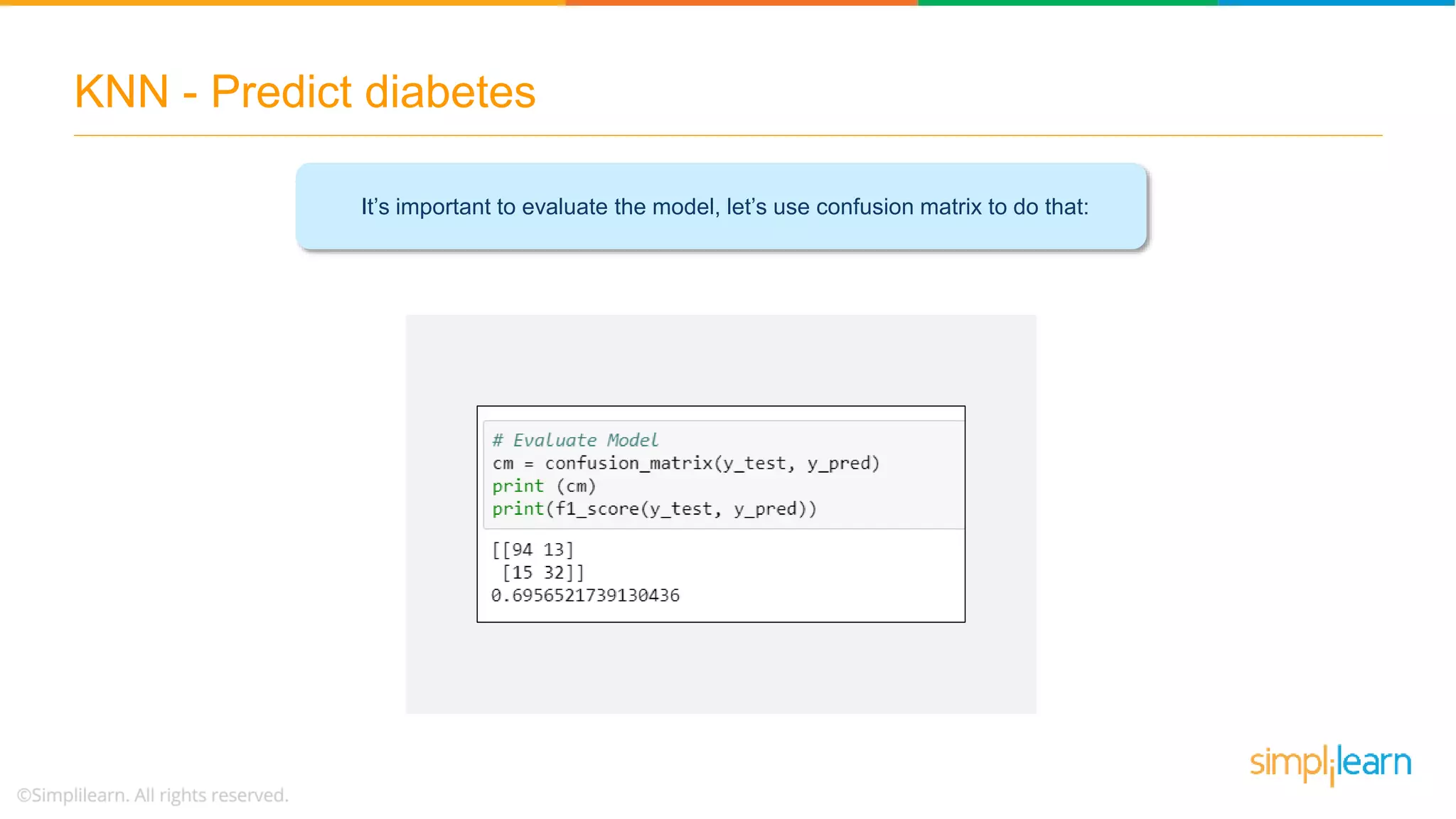
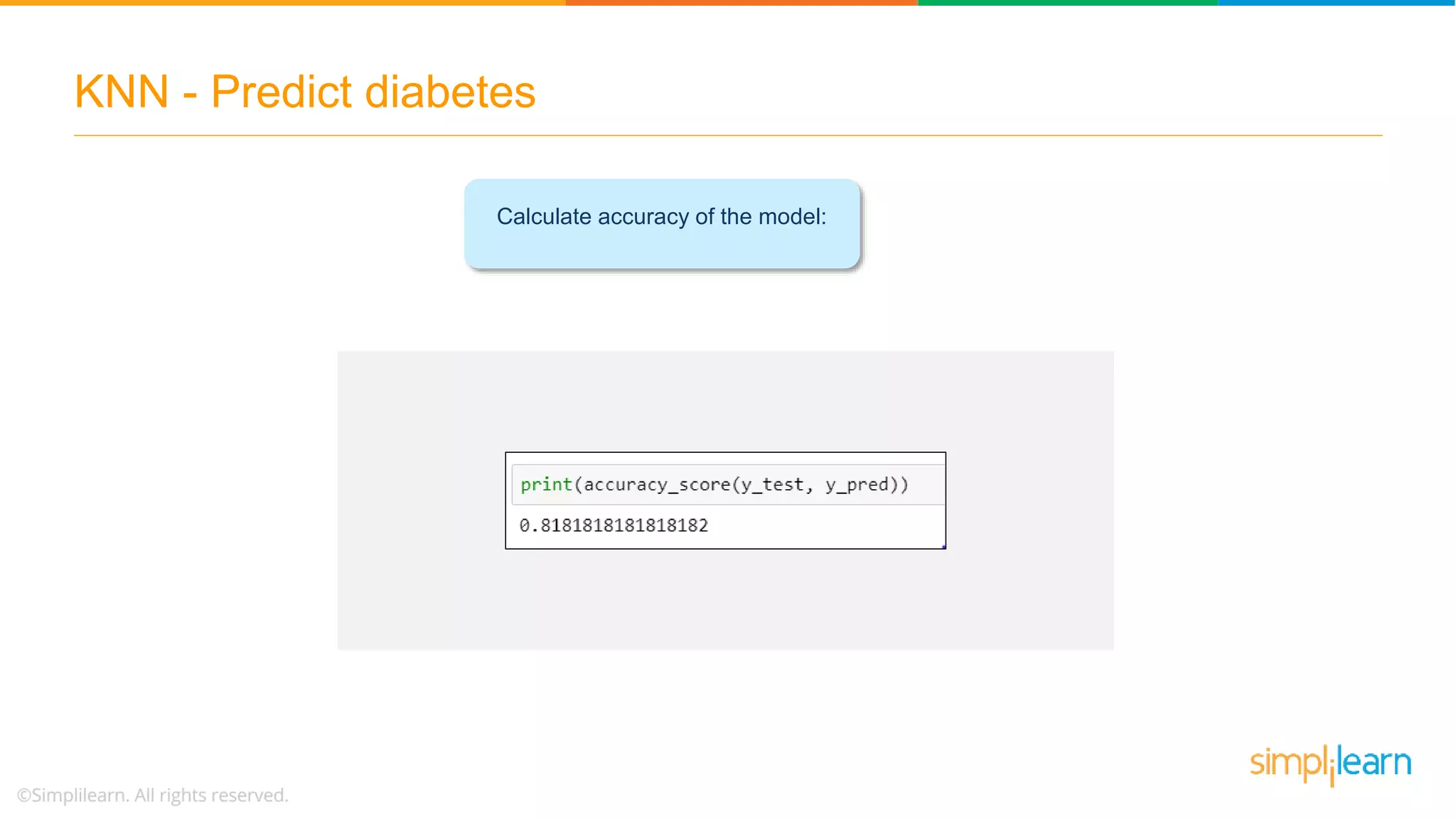
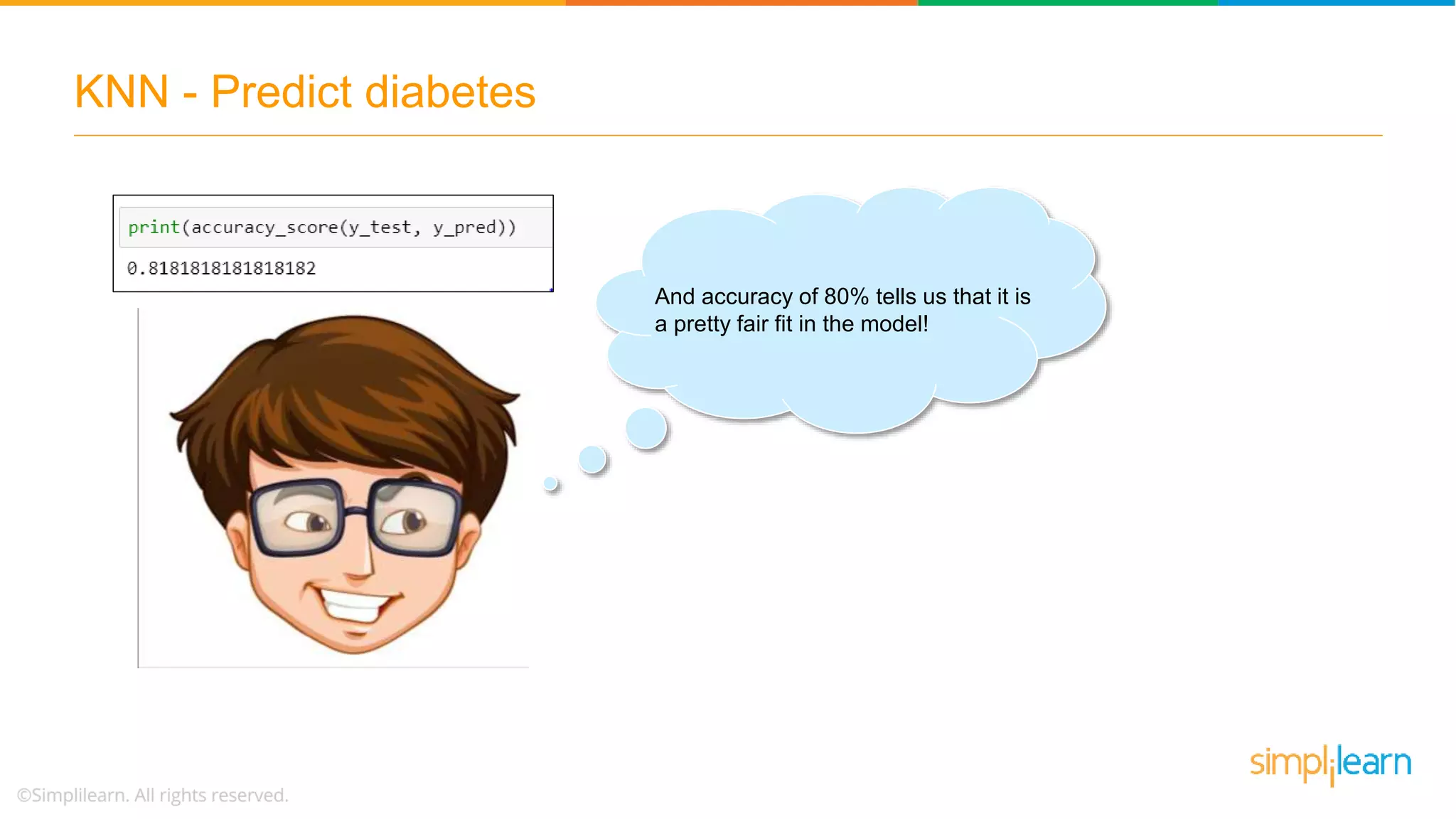
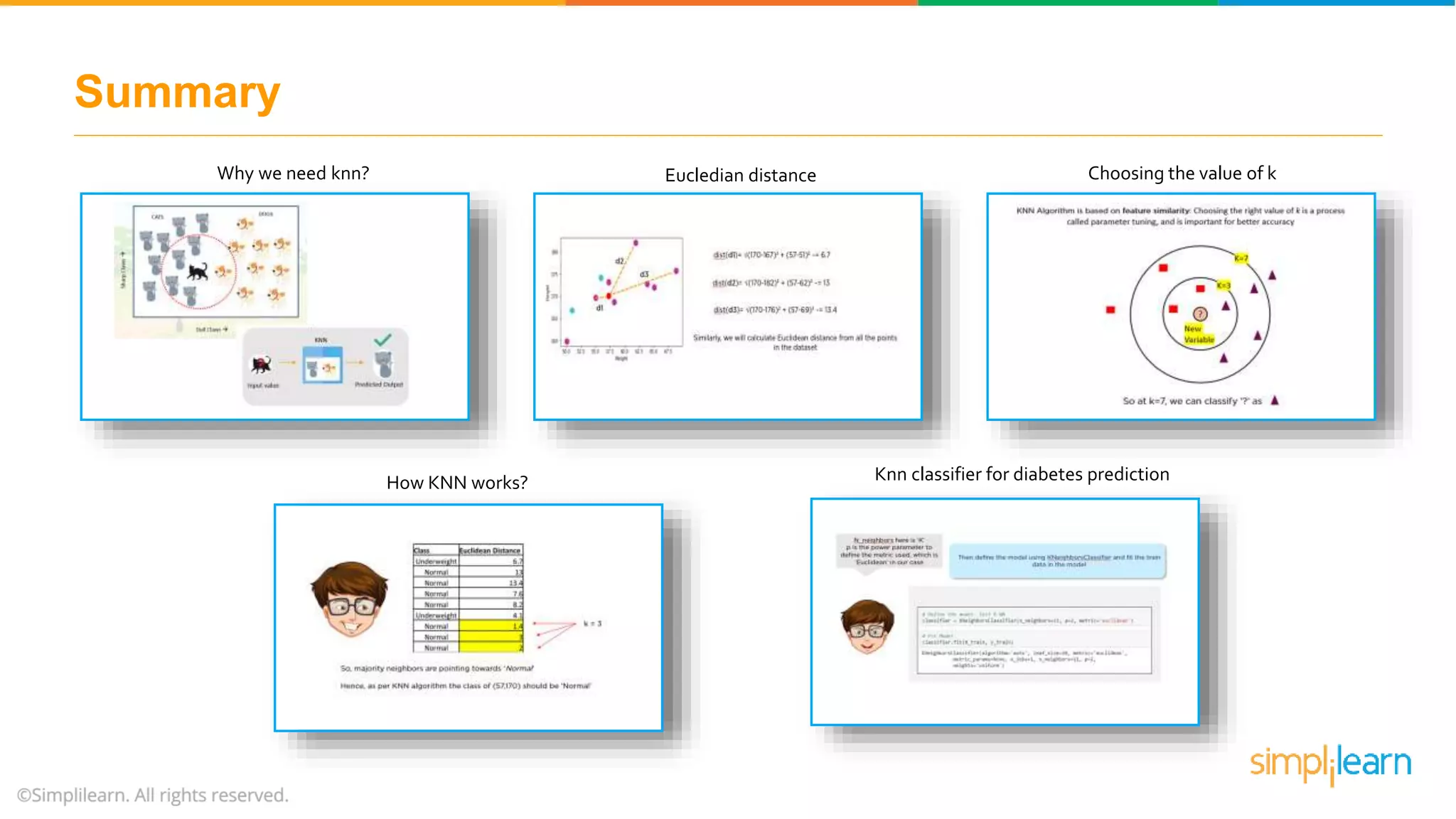



























































The document explains the K-Nearest Neighbors (KNN) algorithm, a simple supervised machine learning method used for classification based on feature similarity. It covers the selection of the parameter 'k', how to handle noise in data, the use of Euclidean distance for finding nearest neighbors, and a specific use case of predicting diabetes with KNN. The document concludes with a summary of KNN's functionality, its relevance in data classification, and performance evaluation metrics.































![k-nearestneighborknn-231215171119-a5cfb915.pptx [Read-Only].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/k-nearestneighborknn-231215171119-a5cfb915-251010013925-09814a4b-thumbnail.jpg?width=640&height=640&fit=bounds)























































